 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music generation": models, code, and papers
Review-Based Tip Generation for Music Songs
May 14, 2022


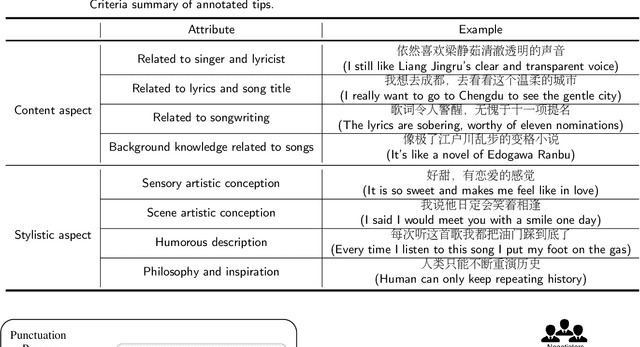
Reviews of songs play an important role in online music service platforms. Prior research shows that users can make quicker and more informed decisions when presented with meaningful song reviews. However, reviews of music songs are generally long in length and most of them are non-informative for users. It is difficult for users to efficiently grasp meaningful messages for making decisions. To solve this problem, one practical strategy is to provide tips, i.e., short, concise, empathetic, and self-contained descriptions about songs. Tips are produced from song reviews and should express non-trivial insight about the songs. To the best of our knowledge, no prior studies have explored the tip generation task in music domain. In this paper, we create a dataset named MTips for the task and propose a framework named GenTMS for automatically generating tips from song reviews. The dataset involves 8,003 Chinese tips/non-tips from 128 songs which are distributed in five different song genres. Experimental results show that GenTMS achieves top-10 precision at 85.56%, outperforming the baseline models by at least 3.34%. Besides, to simulate the practical usage of our proposed framework, we also experiment with previously-unseen songs, during which GenTMS also achieves the best performance with top-10 precision at 78.89% on average. The results demonstrate the effectiveness of the proposed framework in tip generation of the music domain.
Music Generation using Deep Learning
May 19, 2021
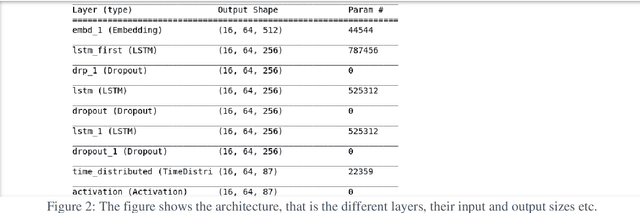
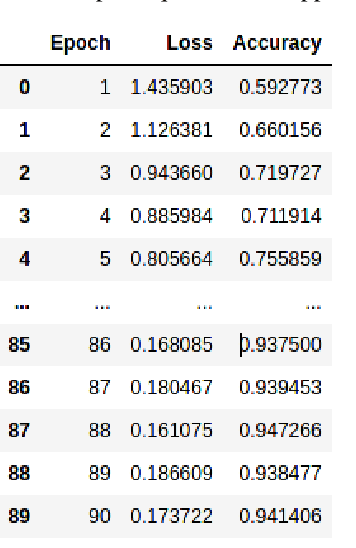
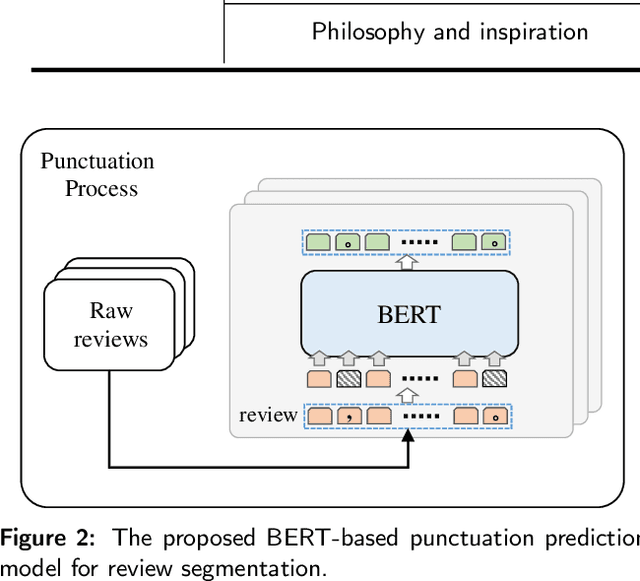
This paper explores the idea of utilising Long Short-Term Memory neural networks (LSTMNN) for the generation of musical sequences in ABC notation. The proposed approach takes ABC notations from the Nottingham dataset and encodes it to beefed as input for the neural networks. The primary objective is to input the neural networks with an arbitrary note, let the network process and augment a sequence based on the note until a good piece of music is produced. Multiple tunings have been done to amend the parameters of the network for optimal generation. The output is assessed on the basis of rhythm, harmony, and grammar accuracy.
Bridging Music and Text with Crowdsourced Music Comments: A Sequence-to-Sequence Framework for Thematic Music Comments Generation
Sep 05, 2022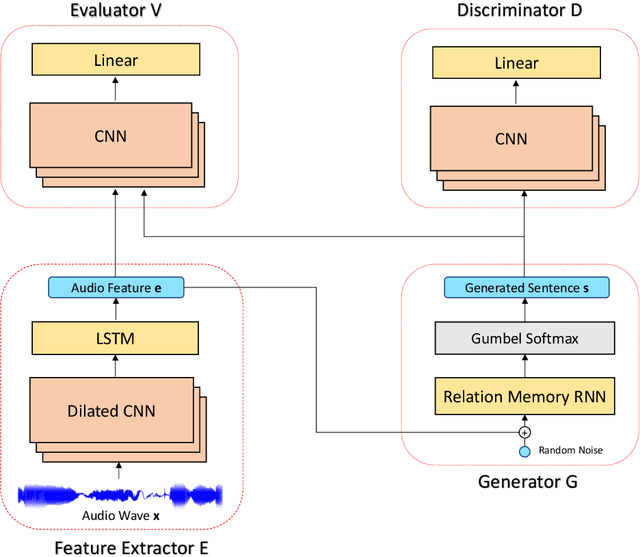
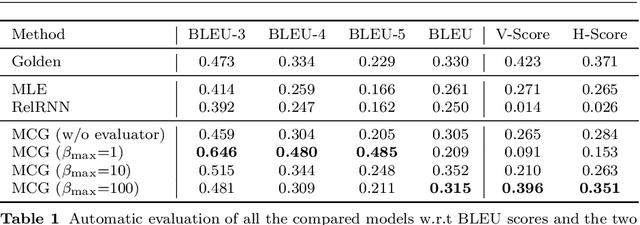
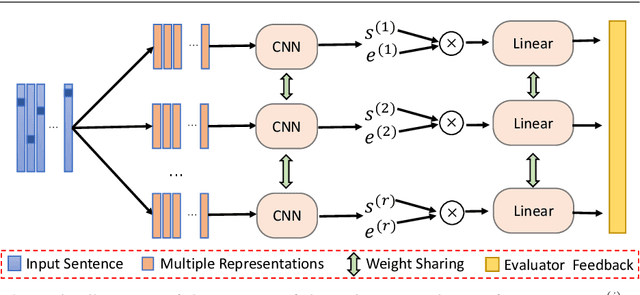

We consider a novel task of automatically generating text descriptions of music. Compared with other well-established text generation tasks such as image caption, the scarcity of well-paired music and text datasets makes it a much more challenging task. In this paper, we exploit the crowd-sourced music comments to construct a new dataset and propose a sequence-to-sequence model to generate text descriptions of music. More concretely, we use the dilated convolutional layer as the basic component of the encoder and a memory based recurrent neural network as the decoder. To enhance the authenticity and thematicity of generated texts, we further propose to fine-tune the model with a discriminator as well as a novel topic evaluator. To measure the quality of generated texts, we also propose two new evaluation metrics, which are more aligned with human evaluation than traditional metrics such as BLEU. Experimental results verify that our model is capable of generating fluent and meaningful comments while containing thematic and content information of the original music.
A-Muze-Net: Music Generation by Composing the Harmony based on the Generated Melody
Nov 25, 2021
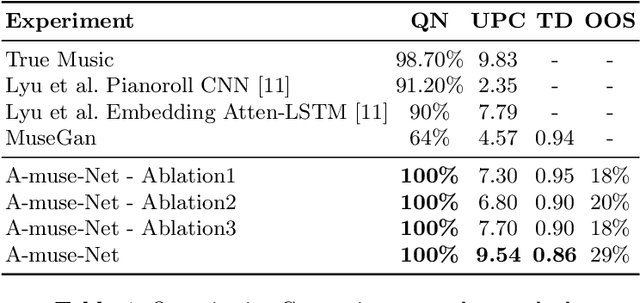
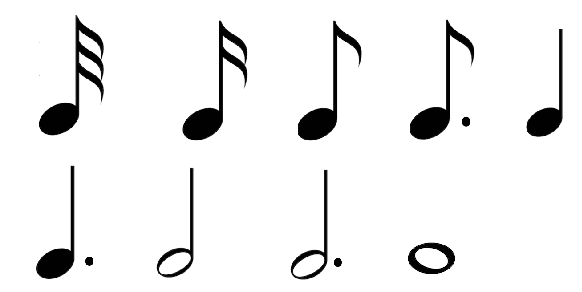

We present a method for the generation of Midi files of piano music. The method models the right and left hands using two networks, where the left hand is conditioned on the right hand. This way, the melody is generated before the harmony. The Midi is represented in a way that is invariant to the musical scale, and the melody is represented, for the purpose of conditioning the harmony, by the content of each bar, viewed as a chord. Finally, notes are added randomly, based on this chord representation, in order to enrich the generated audio. Our experiments show a significant improvement over the state of the art for training on such datasets, and demonstrate the contribution of each of the novel components.
Dance2Music: Automatic Dance-driven Music Generation
Jul 20, 2021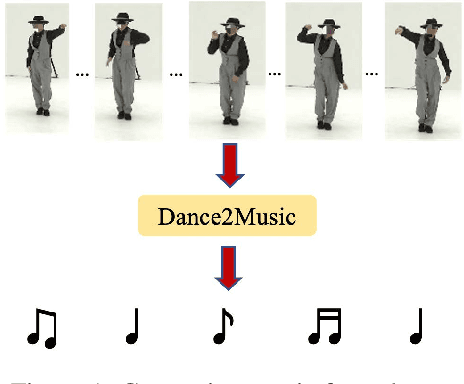
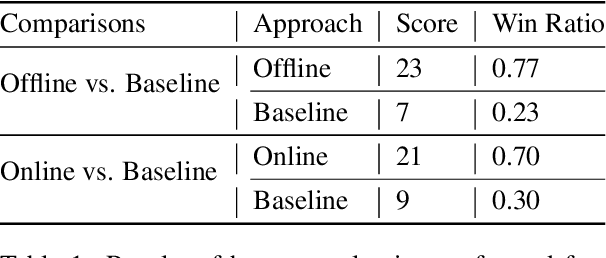

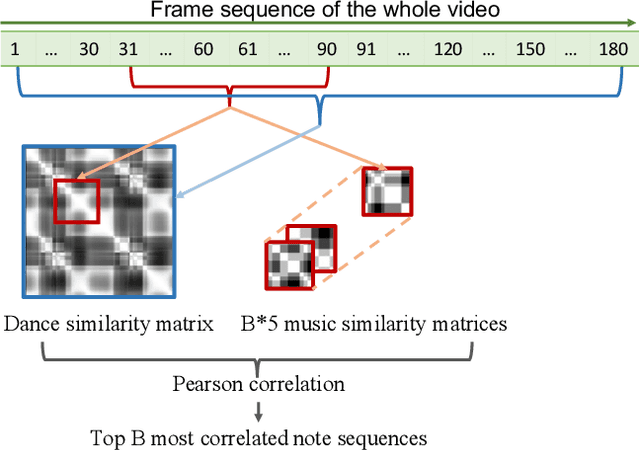
Dance and music typically go hand in hand. The complexities in dance, music, and their synchronisation make them fascinating to study from a computational creativity perspective. While several works have looked at generating dance for a given music, automatically generating music for a given dance remains under-explored. This capability could have several creative expression and entertainment applications. We present some early explorations in this direction. We present a search-based offline approach that generates music after processing the entire dance video and an online approach that uses a deep neural network to generate music on-the-fly as the video proceeds. We compare these approaches to a strong heuristic baseline via human studies and present our findings. We have integrated our online approach in a live demo! A video of the demo can be found here: https://sites.google.com/view/dance2music/live-demo.
Discrete Contrastive Diffusion for Cross-Modal and Conditional Generation
Jun 15, 2022
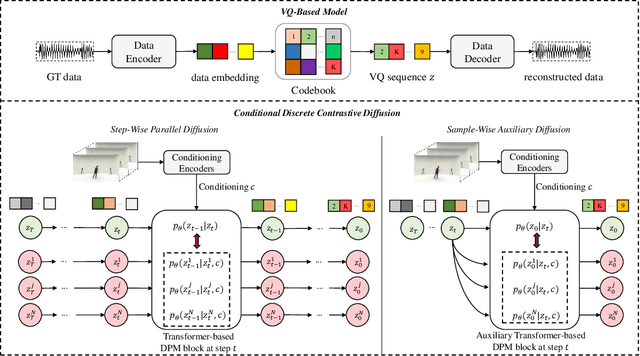

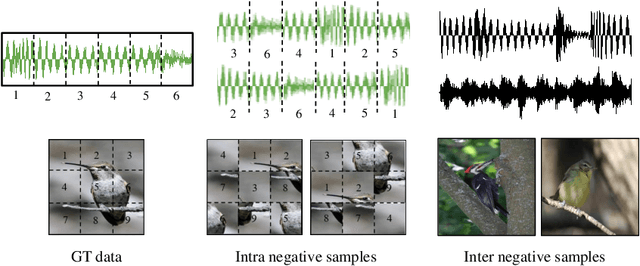
Diffusion probabilistic models (DPMs) have become a popular approach to conditional generation, due to their promising results and support for cross-modal synthesis. A key desideratum in conditional synthesis is to achieve high correspondence between the conditioning input and generated output. Most existing methods learn such relationships implicitly, by incorporating the prior into the variational lower bound. In this work, we take a different route -- we enhance input-output connections by maximizing their mutual information using contrastive learning. To this end, we introduce a Conditional Discrete Contrastive Diffusion (CDCD) loss and design two contrastive diffusion mechanisms to effectively incorporate it into the denoising process. We formulate CDCD by connecting it with the conventional variational objectives. We demonstrate the efficacy of our approach in evaluations with three diverse, multimodal conditional synthesis tasks: dance-to-music generation, text-to-image synthesis, and class-conditioned image synthesis. On each, we achieve state-of-the-art or higher synthesis quality and improve the input-output correspondence. Furthermore, the proposed approach improves the convergence of diffusion models, reducing the number of required diffusion steps by more than 35% on two benchmarks, significantly increasing the inference speed.
RL-Duet: Online Music Accompaniment Generation Using Deep Reinforcement Learning
Feb 08, 2020
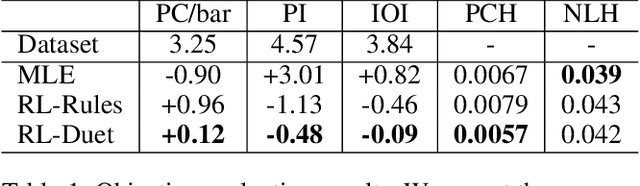

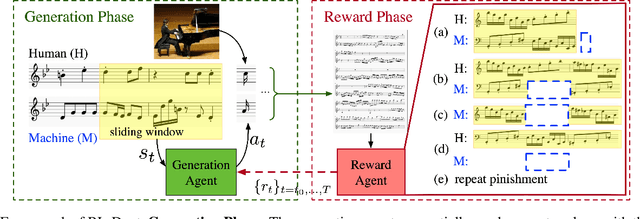
This paper presents a deep reinforcement learning algorithm for online accompaniment generation, with potential for real-time interactive human-machine duet improvisation. Different from offline music generation and harmonization, online music accompaniment requires the algorithm to respond to human input and generate the machine counterpart in a sequential order. We cast this as a reinforcement learning problem, where the generation agent learns a policy to generate a musical note (action) based on previously generated context (state). The key of this algorithm is the well-functioning reward model. Instead of defining it using music composition rules, we learn this model from monophonic and polyphonic training data. This model considers the compatibility of the machine-generated note with both the machine-generated context and the human-generated context. Experiments show that this algorithm is able to respond to the human part and generate a melodic, harmonic and diverse machine part. Subjective evaluations on preferences show that the proposed algorithm generates music pieces of higher quality than the baseline method.
MidiNet: A Convolutional Generative Adversarial Network for Symbolic-domain Music Generation
Jul 18, 2017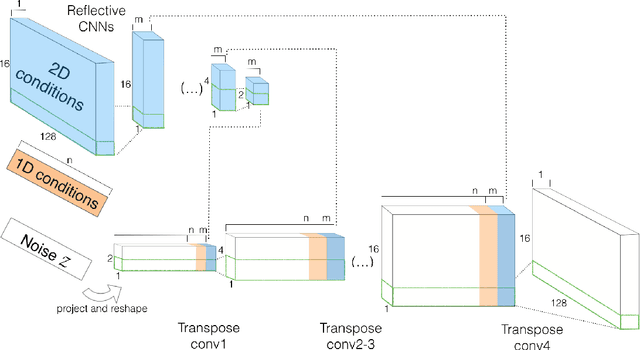
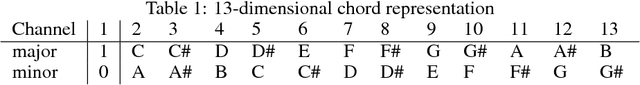

Most existing neural network models for music generation use recurrent neural networks. However, the recent WaveNet model proposed by DeepMind shows that convolutional neural networks (CNNs) can also generate realistic musical waveforms in the audio domain. Following this light, we investigate using CNNs for generating melody (a series of MIDI notes) one bar after another in the symbolic domain. In addition to the generator, we use a discriminator to learn the distributions of melodies, making it a generative adversarial network (GAN). Moreover, we propose a novel conditional mechanism to exploit available prior knowledge, so that the model can generate melodies either from scratch, by following a chord sequence, or by conditioning on the melody of previous bars (e.g. a priming melody), among other possibilities. The resulting model, named MidiNet, can be expanded to generate music with multiple MIDI channels (i.e. tracks). We conduct a user study to compare the melody of eight-bar long generated by MidiNet and by Google's MelodyRNN models, each time using the same priming melody. Result shows that MidiNet performs comparably with MelodyRNN models in being realistic and pleasant to listen to, yet MidiNet's melodies are reported to be much more interesting.
MusIAC: An extensible generative framework for Music Infilling Applications with multi-level Control
Feb 11, 2022
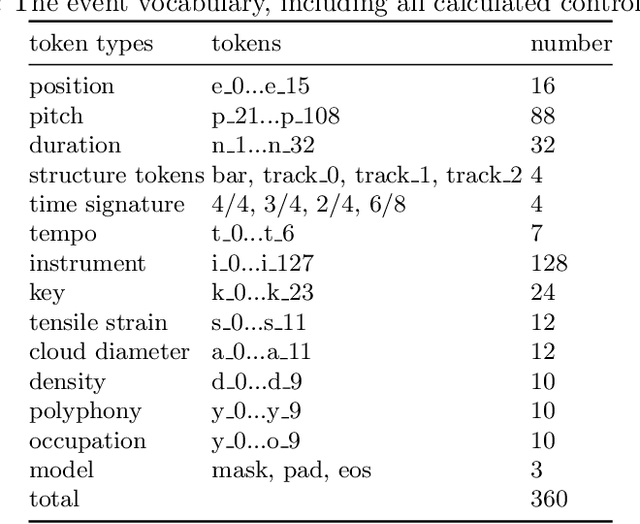


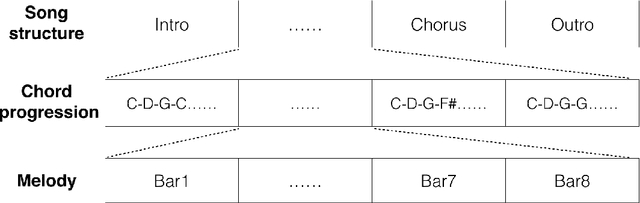
We present a novel music generation framework for music infilling, with a user friendly interface. Infilling refers to the task of generating musical sections given the surrounding multi-track music. The proposed transformer-based framework is extensible for new control tokens as the added music control tokens such as tonal tension per bar and track polyphony level in this work. We explore the effects of including several musically meaningful control tokens, and evaluate the results using objective metrics related to pitch and rhythm. Our results demonstrate that adding additional control tokens helps to generate music with stronger stylistic similarities to the original music. It also provides the user with more control to change properties like the music texture and tonal tension in each bar compared to previous research which only provided control for track density. We present the model in a Google Colab notebook to enable interactive generation.