 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music generation": models, code, and papers
The challenge of realistic music generation: modelling raw audio at scale
Jun 26, 2018
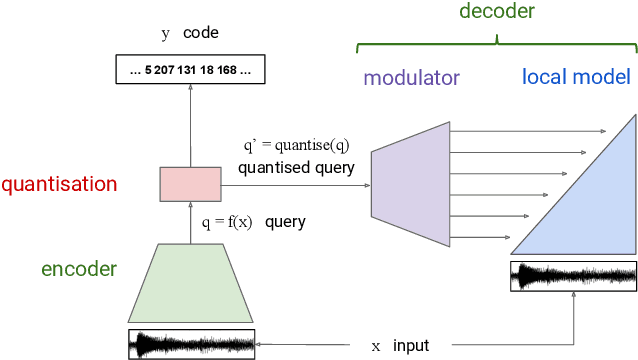
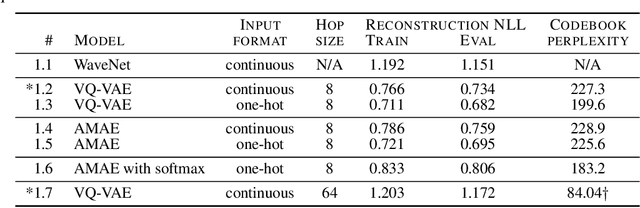
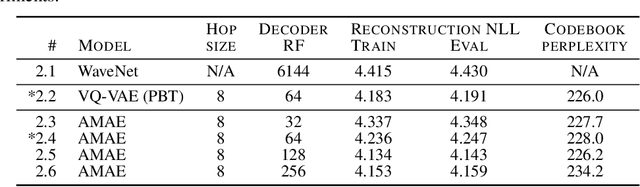
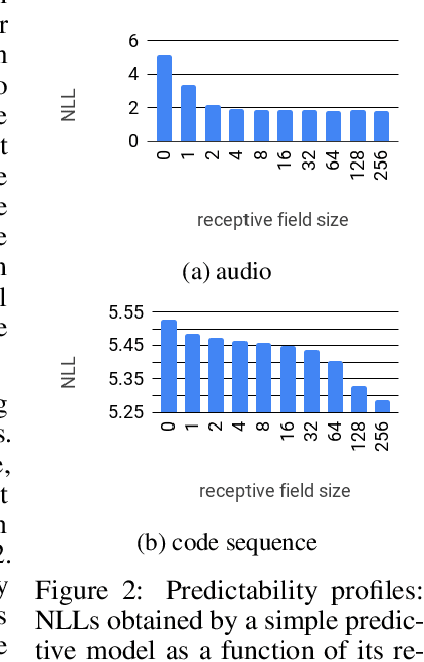
Realistic music generation is a challenging task. When building generative models of music that are learnt from data, typically high-level representations such as scores or MIDI are used that abstract away the idiosyncrasies of a particular performance. But these nuances are very important for our perception of musicality and realism, so in this work we embark on modelling music in the raw audio domain. It has been shown that autoregressive models excel at generating raw audio waveforms of speech, but when applied to music, we find them biased towards capturing local signal structure at the expense of modelling long-range correlations. This is problematic because music exhibits structure at many different timescales. In this work, we explore autoregressive discrete autoencoders (ADAs) as a means to enable autoregressive models to capture long-range correlations in waveforms. We find that they allow us to unconditionally generate piano music directly in the raw audio domain, which shows stylistic consistency across tens of seconds.
An adaptive music generation architecture for games based on the deep learning Transformer mode
Jul 04, 2022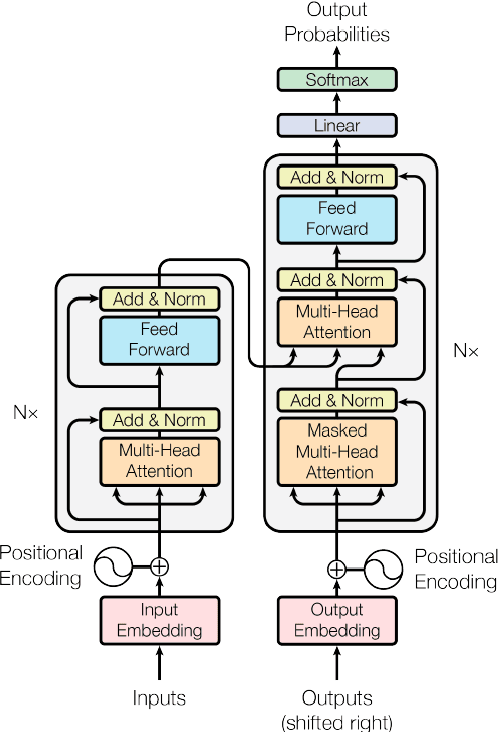
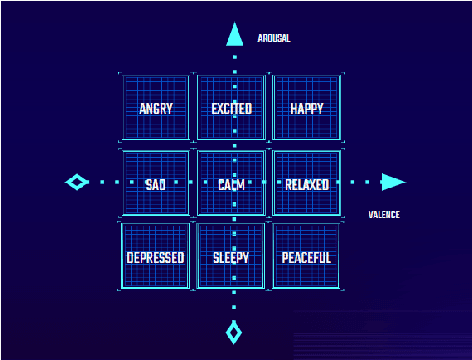
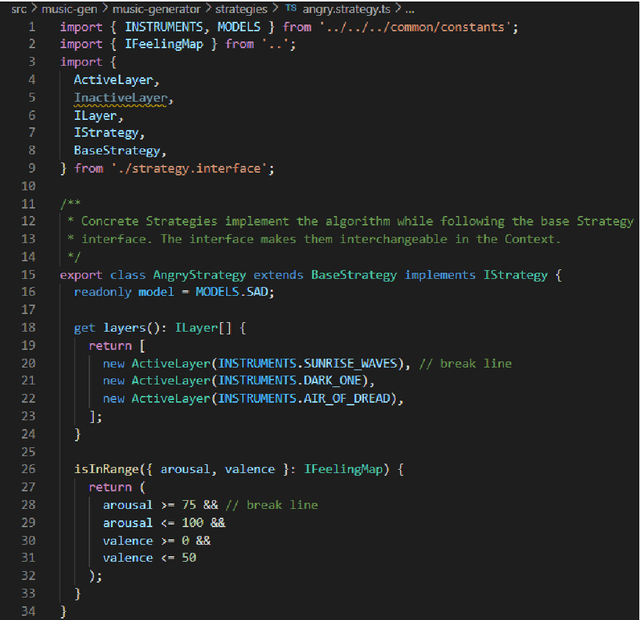
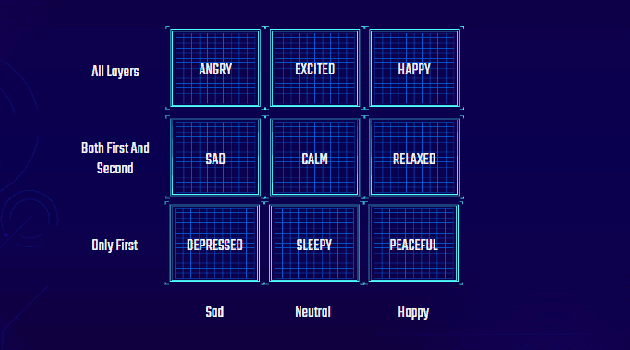
This paper presents an architecture for generating music for video games based on the Transformer deep learning model. The system generates music in various layers, following the standard layering strategy currently used by composers designing video game music. The music is adaptive to the psychological context of the player, according to the arousal-valence model. Our motivation is to customize music according to the player's tastes, who can select his preferred style of music through a set of training examples of music. We discuss current limitations and prospects for the future, such as collaborative and interactive control of the musical components.
A Classifying Variational Autoencoder with Application to Polyphonic Music Generation
Nov 19, 2017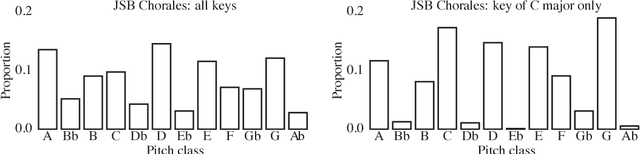
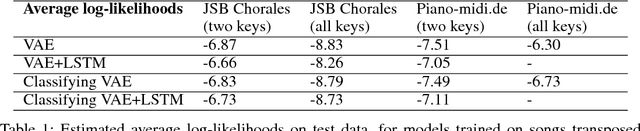
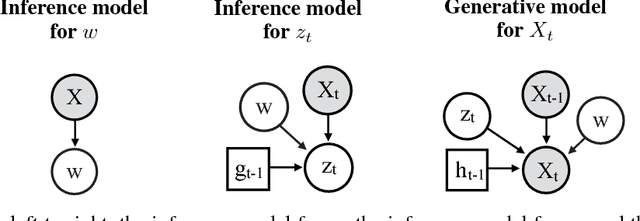
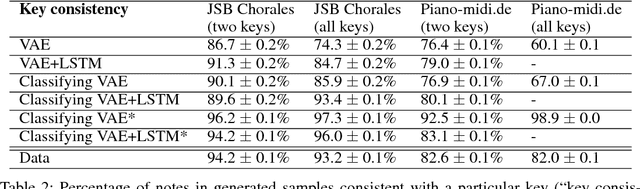
The variational autoencoder (VAE) is a popular probabilistic generative model. However, one shortcoming of VAEs is that the latent variables cannot be discrete, which makes it difficult to generate data from different modes of a distribution. Here, we propose an extension of the VAE framework that incorporates a classifier to infer the discrete class of the modeled data. To model sequential data, we can combine our Classifying VAE with a recurrent neural network such as an LSTM. We apply this model to algorithmic music generation, where our model learns to generate musical sequences in different keys. Most previous work in this area avoids modeling key by transposing data into only one or two keys, as opposed to the 10+ different keys in the original music. We show that our Classifying VAE and Classifying VAE+LSTM models outperform the corresponding non-classifying models in generating musical samples that stay in key. This benefit is especially apparent when trained on untransposed music data in the original keys.
EDGE: Editable Dance Generation From Music
Nov 27, 2022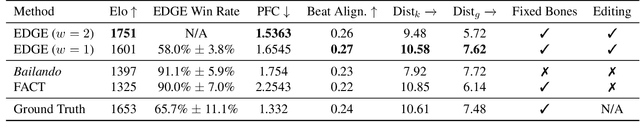
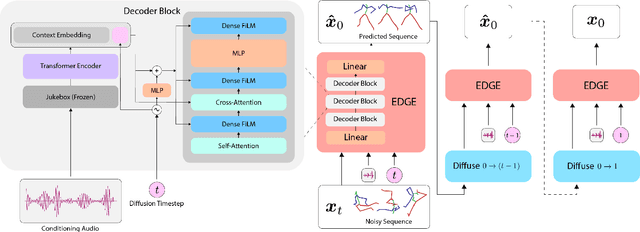
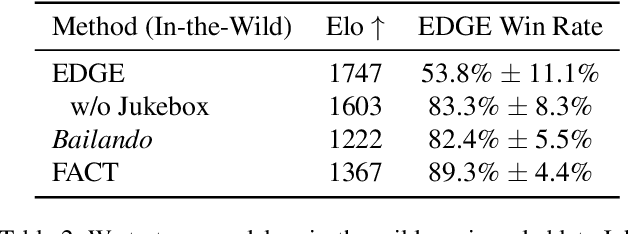
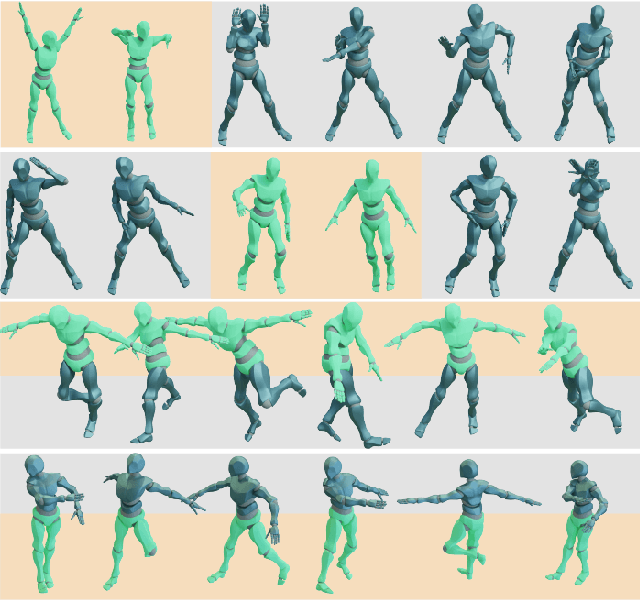
Dance is an important human art form, but creating new dances can be difficult and time-consuming. In this work, we introduce Editable Dance GEneration (EDGE), a state-of-the-art method for editable dance generation that is capable of creating realistic, physically-plausible dances while remaining faithful to the input music. EDGE uses a transformer-based diffusion model paired with Jukebox, a strong music feature extractor, and confers powerful editing capabilities well-suited to dance, including joint-wise conditioning, and in-betweening. We introduce a new metric for physical plausibility, and evaluate dance quality generated by our method extensively through (1) multiple quantitative metrics on physical plausibility, beat alignment, and diversity benchmarks, and more importantly, (2) a large-scale user study, demonstrating a significant improvement over previous state-of-the-art methods. Qualitative samples from our model can be found at our website.
Beyond Markov Chains, Towards Adaptive Memristor Network-based Music Generation
Feb 04, 2013

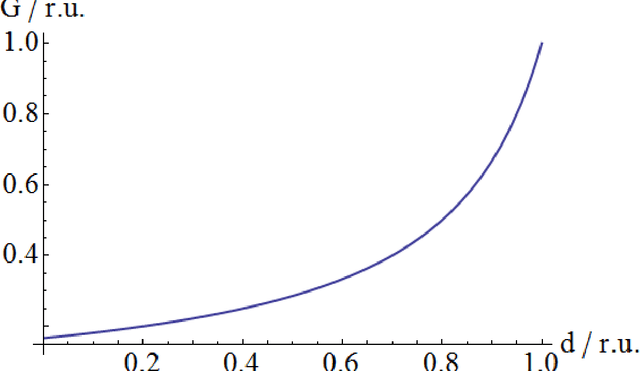

We undertook a study of the use of a memristor network for music generation, making use of the memristor's memory to go beyond the Markov hypothesis. Seed transition matrices are created and populated using memristor equations, and which are shown to generate musical melodies and change in style over time as a result of feedback into the transition matrix. The spiking properties of simple memristor networks are demonstrated and discussed with reference to applications of music making. The limitations of simulating composing memristor networks in von Neumann hardware is discussed and a hardware solution based on physical memristor properties is presented.
Polyphonic Music Generation by Modeling Temporal Dependencies Using a RNN-DBN
Dec 26, 2014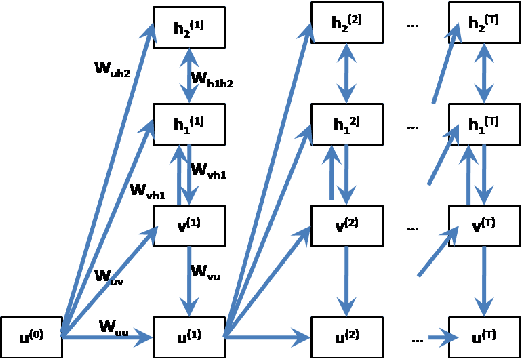
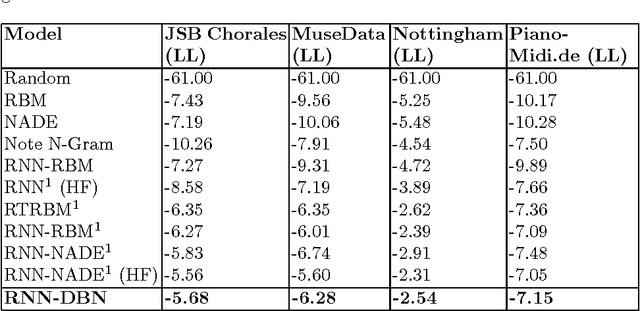
In this paper, we propose a generic technique to model temporal dependencies and sequences using a combination of a recurrent neural network and a Deep Belief Network. Our technique, RNN-DBN, is an amalgamation of the memory state of the RNN that allows it to provide temporal information and a multi-layer DBN that helps in high level representation of the data. This makes RNN-DBNs ideal for sequence generation. Further, the use of a DBN in conjunction with the RNN makes this model capable of significantly more complex data representation than an RBM. We apply this technique to the task of polyphonic music generation.
* 8 pages, A4, 1 figure, 1 table, ICANN 2014 oral presentation. arXiv admin note: text overlap with arXiv:1206.6392 by other authors
Music Harmony Generation, through Deep Learning and Using a Multi-Objective Evolutionary Algorithm
Feb 16, 2021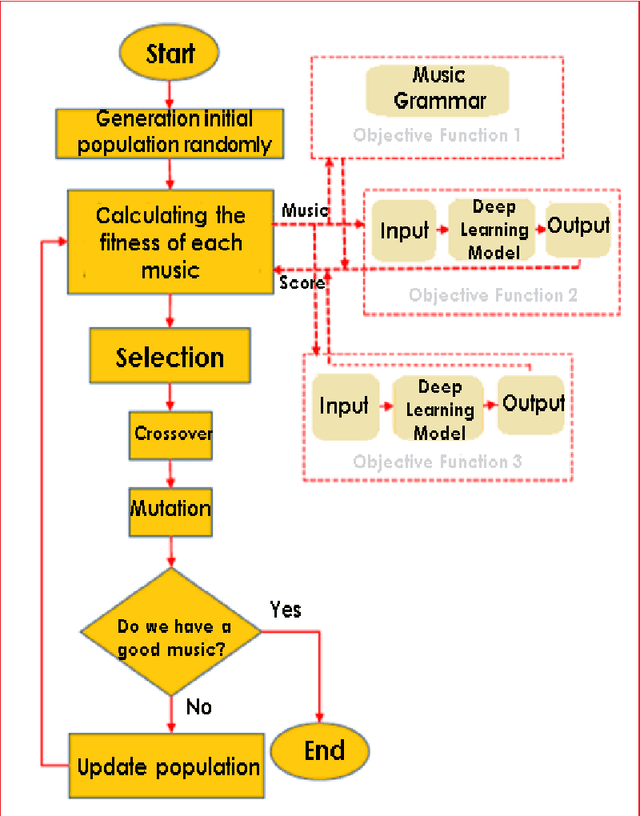
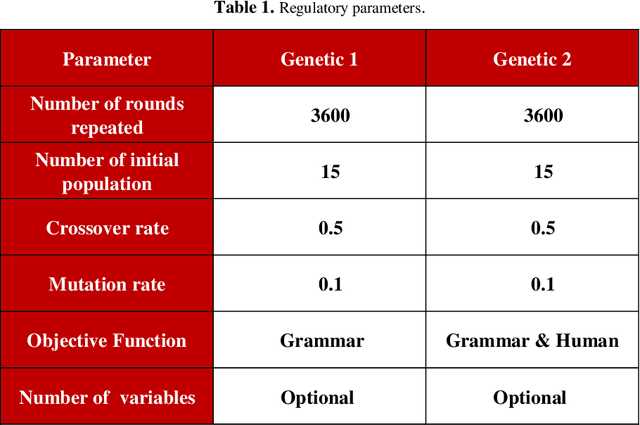
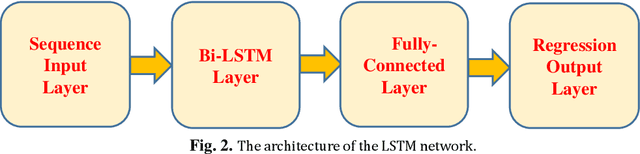
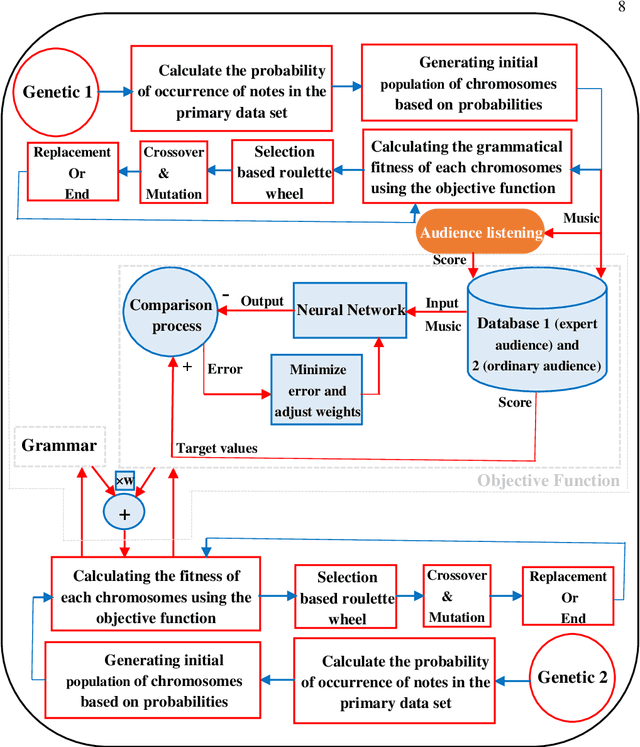
Automatic music generation has become an epicenter research topic for many scientists in artificial intelligence, who are also interested in the music industry. Being a balanced combination of math and art, music in collaboration with A.I. can simplify the generation process for new musical pieces, and ease the interpretation of it to a tangible level. On the other hand, the artistic nature of music and its mingling with the senses and feelings of the composer makes the artificial generation and mathematical modeling of it infeasible. In fact, there are no clear evaluation measures that can combine the objective music grammar and structure with the subjective audience satisfaction goal. Also, original music contains different elements that it is inevitable to put together. Therefore, in this paper, a method based on a genetic multi-objective evolutionary optimization algorithm for the generation of polyphonic music (melody with rhythm and harmony or appropriate chords) is introduced in which three specific goals determine the qualifications of the music generated. One of the goals is the rules and regulations of music, which, along with the other two goals, including the scores of music experts and ordinary listeners, fits the cycle of evolution to get the most optimal response. The scoring of experts and listeners separately is modeled using a Bi-LSTM neural network and has been incorporated in the fitness function of the algorithm. The results show that the proposed method is able to generate difficult and pleasant pieces with desired styles and lengths, along with harmonic sounds that follow the grammar while attracting the listener, at the same time.
cMelGAN: An Efficient Conditional Generative Model Based on Mel Spectrograms
May 15, 2022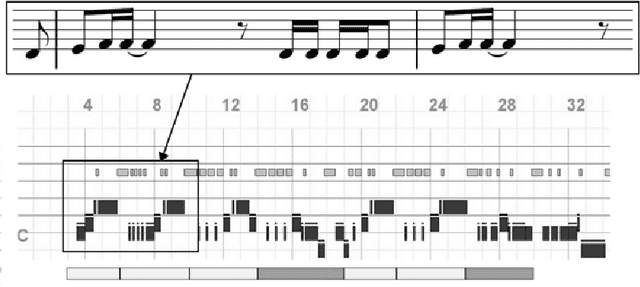
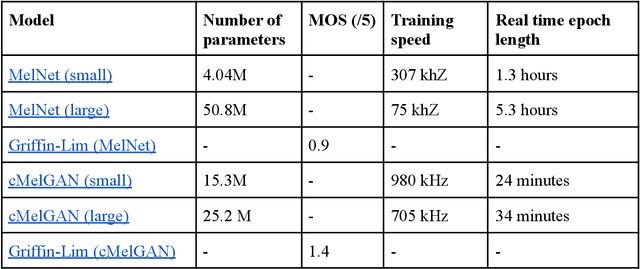

Analysing music in the field of machine learning is a very difficult problem with numerous constraints to consider. The nature of audio data, with its very high dimensionality and widely varying scales of structure, is one of the primary reasons why it is so difficult to model. There are many applications of machine learning in music, like the classifying the mood of a piece of music, conditional music generation, or popularity prediction. The goal for this project was to develop a genre-conditional generative model of music based on Mel spectrograms and evaluate its performance by comparing it to existing generative music models that use note-based representations. We initially implemented an autoregressive, RNN-based generative model called MelNet . However, due to its slow speed and low fidelity output, we decided to create a new, fully convolutional architecture that is based on the MelGAN [4] and conditional GAN architectures, called cMelGAN.
Multitrack Music Transformer: Learning Long-Term Dependencies in Music with Diverse Instruments
Jul 14, 2022
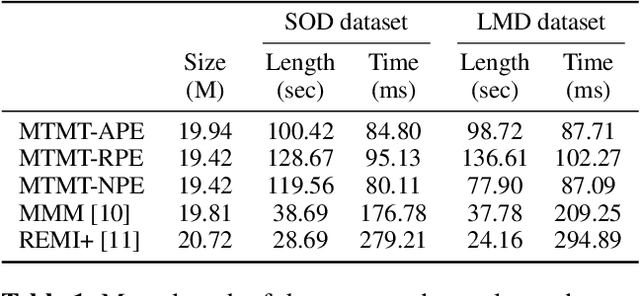
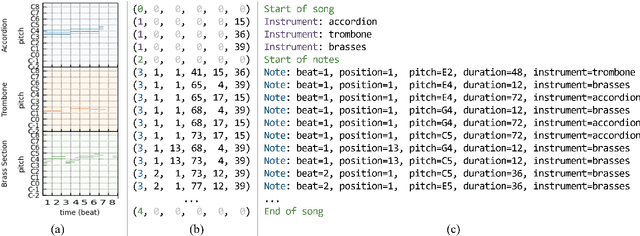
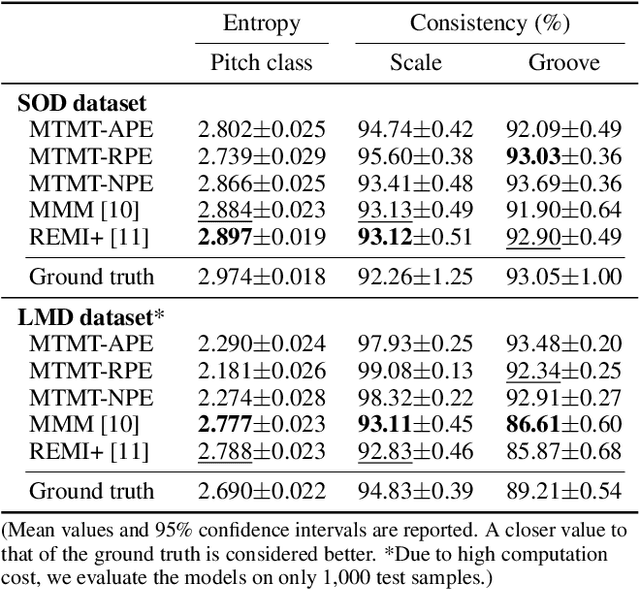
Existing approaches for generating multitrack music with transformer models have been limited to either a small set of instruments or short music segments. This is partly due to the memory requirements of the lengthy input sequences necessitated by existing representations for multitrack music. In this work, we propose a compact representation that allows a diverse set of instruments while keeping a short sequence length. Using our proposed representation, we present the Multitrack Music Transformer (MTMT) for learning long-term dependencies in multitrack music. In a subjective listening test, our proposed model achieves competitive quality on unconditioned generation against two baseline models. We also show that our proposed model can generate samples that are twice as long as those produced by the baseline models, and, further, can do so in half the inference time. Moreover, we propose a new measure for analyzing musical self-attentions and show that the trained model learns to pay less attention to notes that form a dissonant interval with the current note, yet attending more to notes that are 4N beats away from current. Finally, our findings provide a novel foundation for future work exploring longer-form multitrack music generation and improving self-attentions for music. All source code and audio samples can be found at https://salu133445.github.io/mtmt/ .