 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music generation": models, code, and papers
AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head
Apr 25, 2023
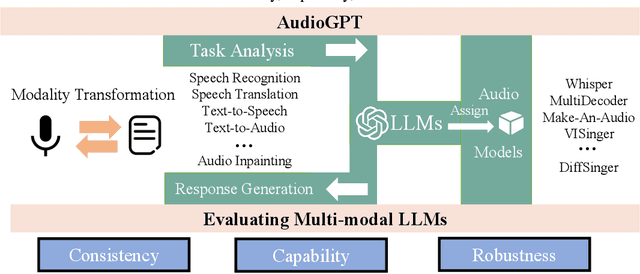

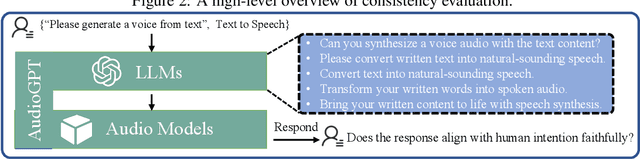

Large language models (LLMs) have exhibited remarkable capabilities across a variety of domains and tasks, challenging our understanding of learning and cognition. Despite the recent success, current LLMs are not capable of processing complex audio information or conducting spoken conversations (like Siri or Alexa). In this work, we propose a multi-modal AI system named AudioGPT, which complements LLMs (i.e., ChatGPT) with 1) foundation models to process complex audio information and solve numerous understanding and generation tasks; and 2) the input/output interface (ASR, TTS) to support spoken dialogue. With an increasing demand to evaluate multi-modal LLMs of human intention understanding and cooperation with foundation models, we outline the principles and processes and test AudioGPT in terms of consistency, capability, and robustness. Experimental results demonstrate the capabilities of AudioGPT in solving AI tasks with speech, music, sound, and talking head understanding and generation in multi-round dialogues, which empower humans to create rich and diverse audio content with unprecedented ease. Our system is publicly available at \url{https://github.com/AIGC-Audio/AudioGPT}.
Deep Learning Techniques for Music Generation - A Survey
Sep 05, 2017


This book is a survey and an analysis of different ways of using deep learning (deep artificial neural networks) to generate musical content. At first, we propose a methodology based on four dimensions for our analysis: - objective - What musical content is to be generated? (e.g., melody, accompaniment...); - representation - What are the information formats used for the corpus and for the expected generated output? (e.g., MIDI, piano roll, text...); - architecture - What type of deep neural network is to be used? (e.g., recurrent network, autoencoder, generative adversarial networks...); - strategy - How to model and control the process of generation (e.g., direct feedforward, sampling, unit selection...). For each dimension, we conduct a comparative analysis of various models and techniques. For the strategy dimension, we propose some tentative typology of possible approaches and mechanisms. This classification is bottom-up, based on the analysis of many existing deep-learning based systems for music generation, which are described in this book. The last part of the book includes discussion and prospects.
FIGARO: Generating Symbolic Music with Fine-Grained Artistic Control
Feb 01, 2022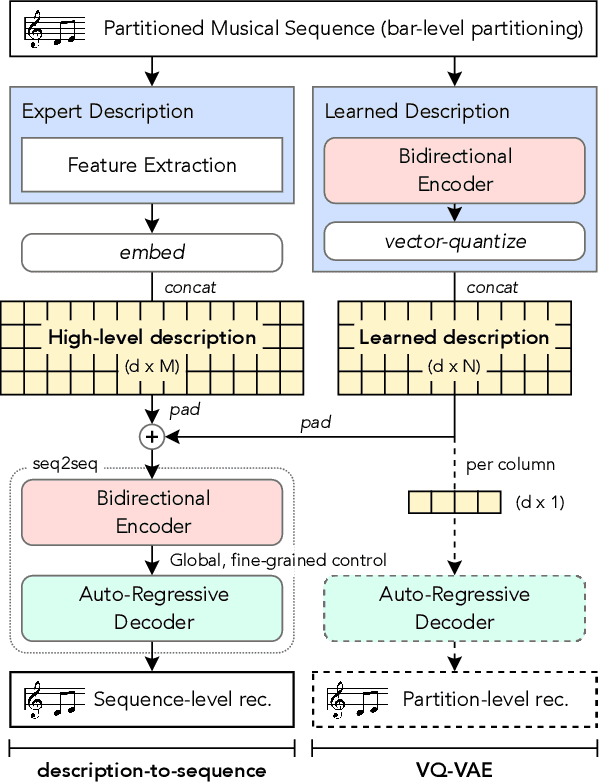

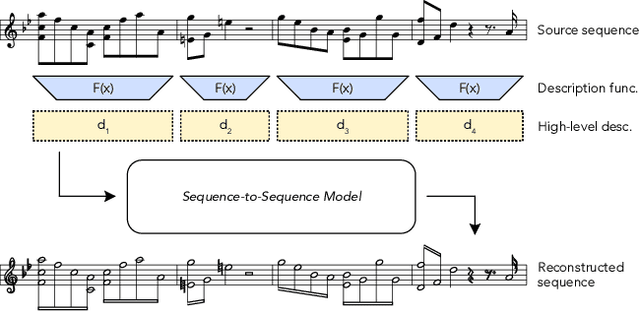
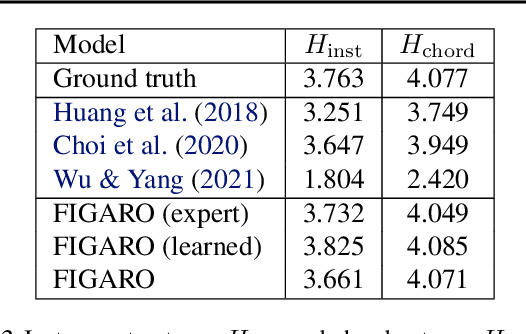
Generating music with deep neural networks has been an area of active research in recent years. While the quality of generated samples has been steadily increasing, most methods are only able to exert minimal control over the generated sequence, if any. We propose the self-supervised description-to-sequence task, which allows for fine-grained controllable generation on a global level. We do so by extracting high-level features about the target sequence and learning the conditional distribution of sequences given the corresponding high-level description in a sequence-to-sequence modelling setup. We train FIGARO (FIne-grained music Generation via Attention-based, RObust control) by applying description-to-sequence modelling to symbolic music. By combining learned high level features with domain knowledge, which acts as a strong inductive bias, the model achieves state-of-the-art results in controllable symbolic music generation and generalizes well beyond the training distribution.
Conditional Vector Graphics Generation for Music Cover Images
May 15, 2022
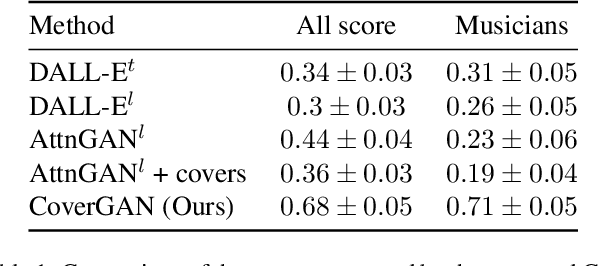

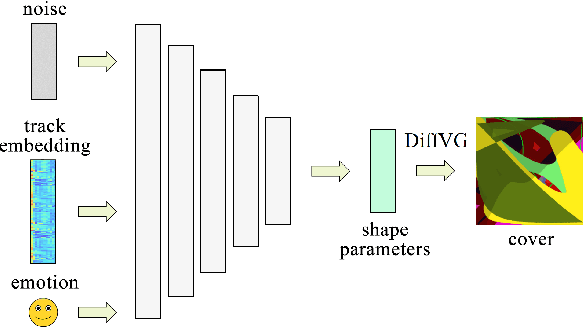
Generative Adversarial Networks (GAN) have motivated a rapid growth of the domain of computer image synthesis. As almost all the existing image synthesis algorithms consider an image as a pixel matrix, the high-resolution image synthesis is complicated.A good alternative can be vector images. However, they belong to the highly sophisticated parametric space, which is a restriction for solving the task of synthesizing vector graphics by GANs. In this paper, we consider a specific application domain that softens this restriction dramatically allowing the usage of vector image synthesis. Music cover images should meet the requirements of Internet streaming services and printing standards, which imply high resolution of graphic materials without any additional requirements on the content of such images. Existing music cover image generation services do not analyze tracks themselves; however, some services mostly consider only genre tags. To generate music covers as vector images that reflect the music and consist of simple geometric objects, we suggest a GAN-based algorithm called CoverGAN. The assessment of resulting images is based on their correspondence to the music compared with AttnGAN and DALL-E text-to-image generation according to title or lyrics. Moreover, the significance of the patterns found by CoverGAN has been evaluated in terms of the correspondence of the generated cover images to the musical tracks. Listeners evaluate the music covers generated by the proposed algorithm as quite satisfactory and corresponding to the tracks. Music cover images generation code and demo are available at https://github.com/IzhanVarsky/CoverGAN.
MuseGAN: Multi-track Sequential Generative Adversarial Networks for Symbolic Music Generation and Accompaniment
Nov 24, 2017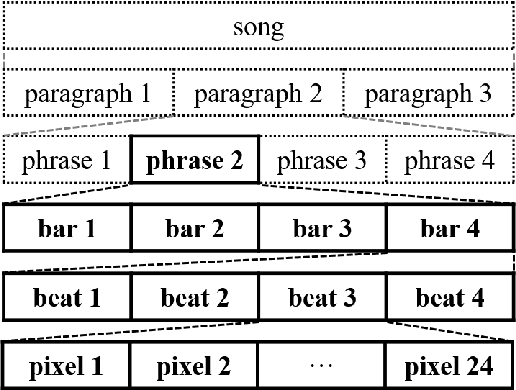
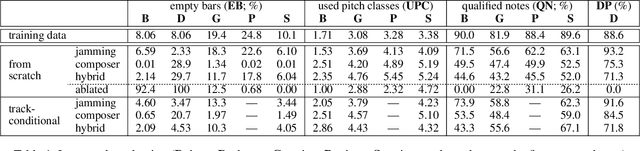
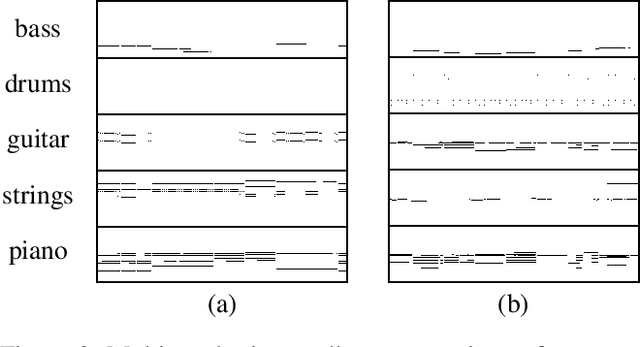
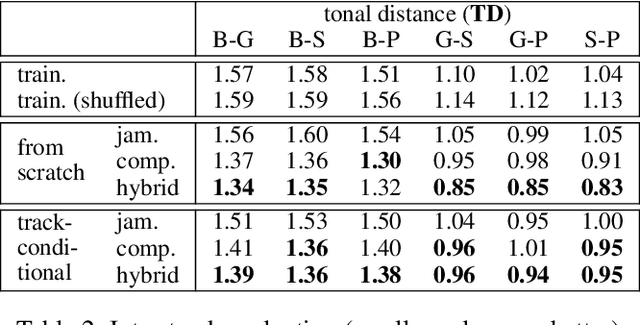
Generating music has a few notable differences from generating images and videos. First, music is an art of time, necessitating a temporal model. Second, music is usually composed of multiple instruments/tracks with their own temporal dynamics, but collectively they unfold over time interdependently. Lastly, musical notes are often grouped into chords, arpeggios or melodies in polyphonic music, and thereby introducing a chronological ordering of notes is not naturally suitable. In this paper, we propose three models for symbolic multi-track music generation under the framework of generative adversarial networks (GANs). The three models, which differ in the underlying assumptions and accordingly the network architectures, are referred to as the jamming model, the composer model and the hybrid model. We trained the proposed models on a dataset of over one hundred thousand bars of rock music and applied them to generate piano-rolls of five tracks: bass, drums, guitar, piano and strings. A few intra-track and inter-track objective metrics are also proposed to evaluate the generative results, in addition to a subjective user study. We show that our models can generate coherent music of four bars right from scratch (i.e. without human inputs). We also extend our models to human-AI cooperative music generation: given a specific track composed by human, we can generate four additional tracks to accompany it. All code, the dataset and the rendered audio samples are available at https://salu133445.github.io/musegan/ .
Interactive Music Generation with Positional Constraints using Anticipation-RNNs
Sep 19, 2017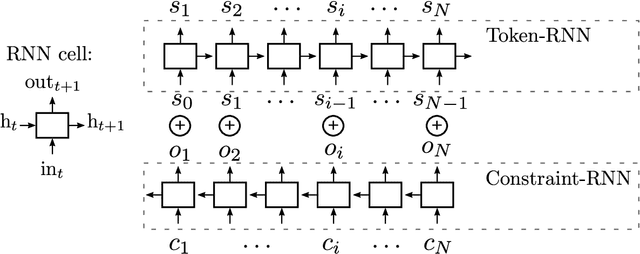

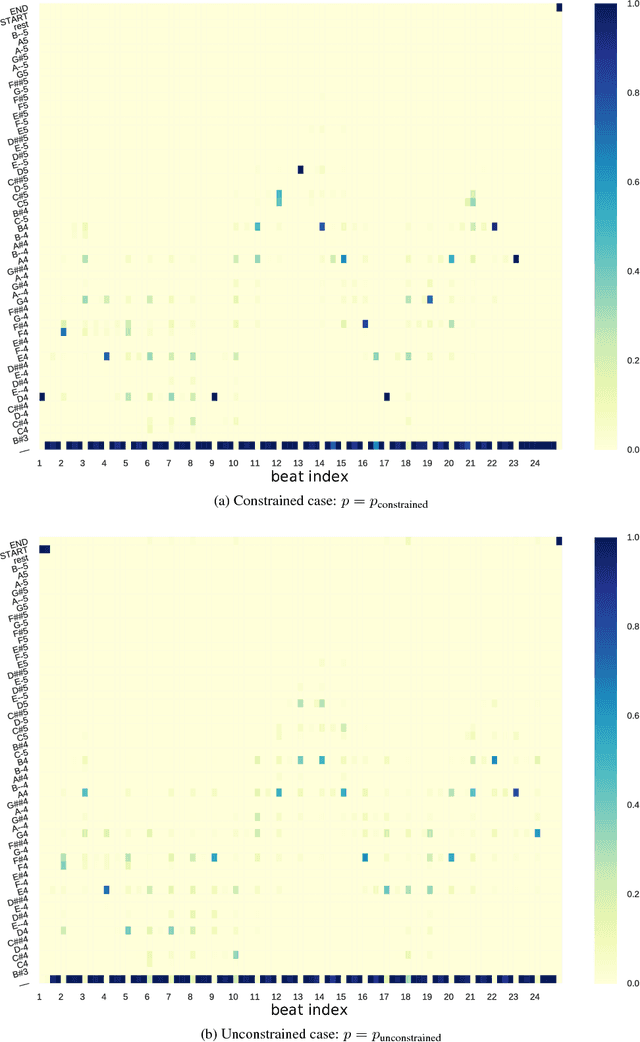
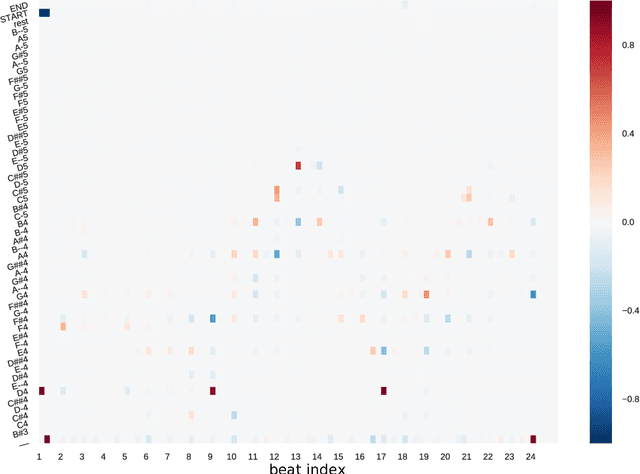
Recurrent Neural Networks (RNNS) are now widely used on sequence generation tasks due to their ability to learn long-range dependencies and to generate sequences of arbitrary length. However, their left-to-right generation procedure only allows a limited control from a potential user which makes them unsuitable for interactive and creative usages such as interactive music generation. This paper introduces a novel architecture called Anticipation-RNN which possesses the assets of the RNN-based generative models while allowing to enforce user-defined positional constraints. We demonstrate its efficiency on the task of generating melodies satisfying positional constraints in the style of the soprano parts of the J.S. Bach chorale harmonizations. Sampling using the Anticipation-RNN is of the same order of complexity than sampling from the traditional RNN model. This fast and interactive generation of musical sequences opens ways to devise real-time systems that could be used for creative purposes.
PopMAG: Pop Music Accompaniment Generation
Aug 18, 2020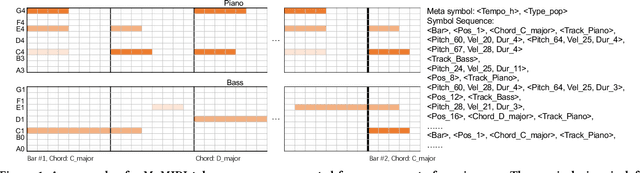

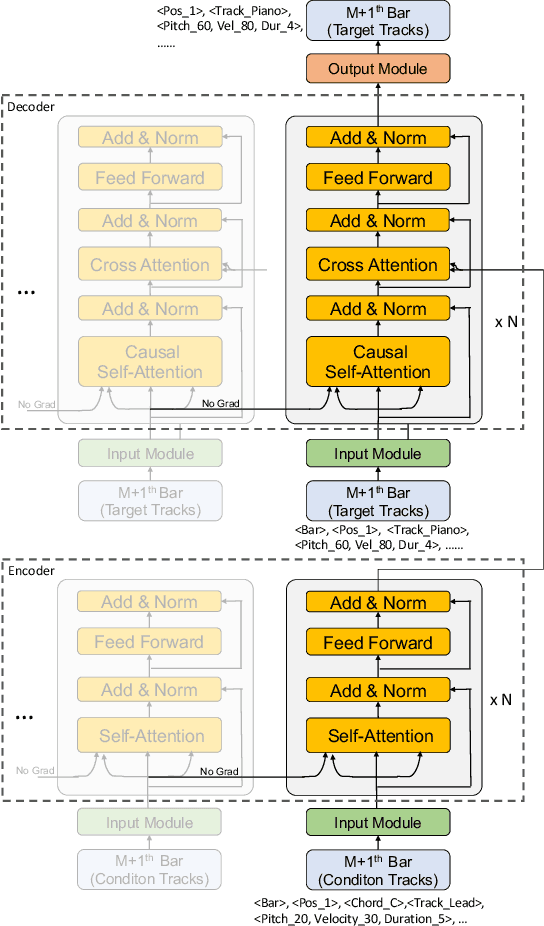
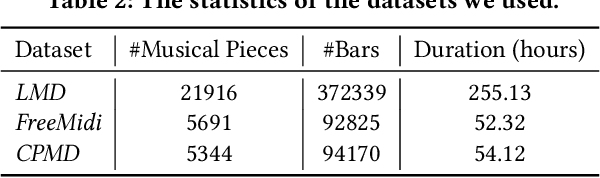
In pop music, accompaniments are usually played by multiple instruments (tracks) such as drum, bass, string and guitar, and can make a song more expressive and contagious by arranging together with its melody. Previous works usually generate multiple tracks separately and the music notes from different tracks not explicitly depend on each other, which hurts the harmony modeling. To improve harmony, in this paper, we propose a novel MUlti-track MIDI representation (MuMIDI), which enables simultaneous multi-track generation in a single sequence and explicitly models the dependency of the notes from different tracks. While this greatly improves harmony, unfortunately, it enlarges the sequence length and brings the new challenge of long-term music modeling. We further introduce two new techniques to address this challenge: 1) We model multiple note attributes (e.g., pitch, duration, velocity) of a musical note in one step instead of multiple steps, which can shorten the length of a MuMIDI sequence. 2) We introduce extra long-context as memory to capture long-term dependency in music. We call our system for pop music accompaniment generation as PopMAG. We evaluate PopMAG on multiple datasets (LMD, FreeMidi and CPMD, a private dataset of Chinese pop songs) with both subjective and objective metrics. The results demonstrate the effectiveness of PopMAG for multi-track harmony modeling and long-term context modeling. Specifically, PopMAG wins 42\%/38\%/40\% votes when comparing with ground truth musical pieces on LMD, FreeMidi and CPMD datasets respectively and largely outperforms other state-of-the-art music accompaniment generation models and multi-track MIDI representations in terms of subjective and objective metrics.
The challenge of realistic music generation: modelling raw audio at scale
Jun 26, 2018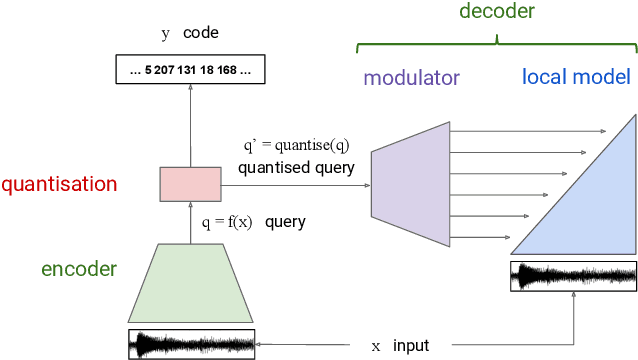
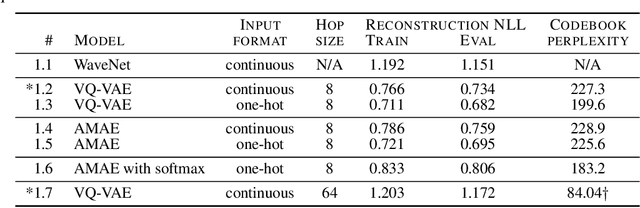
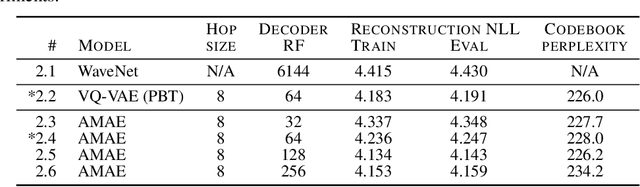
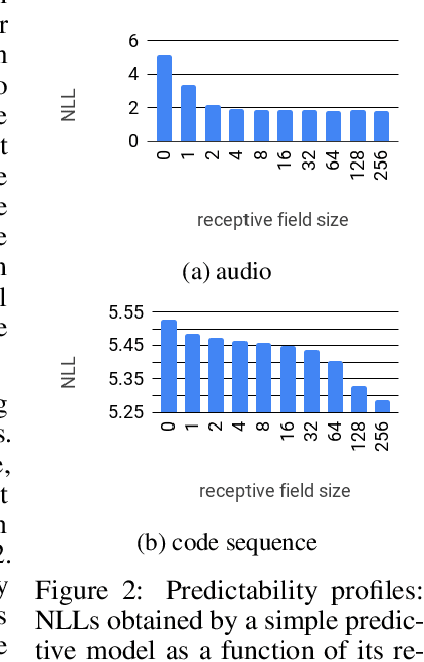
Realistic music generation is a challenging task. When building generative models of music that are learnt from data, typically high-level representations such as scores or MIDI are used that abstract away the idiosyncrasies of a particular performance. But these nuances are very important for our perception of musicality and realism, so in this work we embark on modelling music in the raw audio domain. It has been shown that autoregressive models excel at generating raw audio waveforms of speech, but when applied to music, we find them biased towards capturing local signal structure at the expense of modelling long-range correlations. This is problematic because music exhibits structure at many different timescales. In this work, we explore autoregressive discrete autoencoders (ADAs) as a means to enable autoregressive models to capture long-range correlations in waveforms. We find that they allow us to unconditionally generate piano music directly in the raw audio domain, which shows stylistic consistency across tens of seconds.
A Classifying Variational Autoencoder with Application to Polyphonic Music Generation
Nov 19, 2017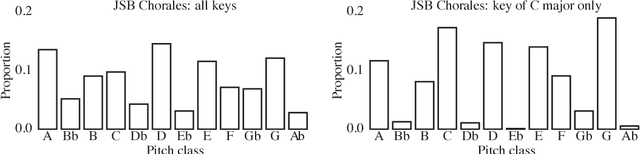
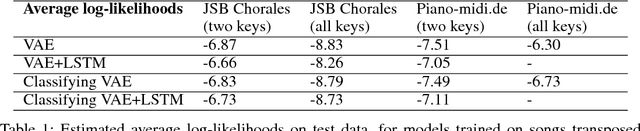
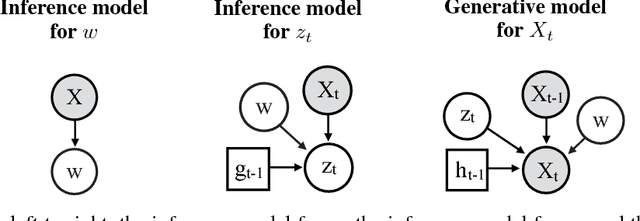
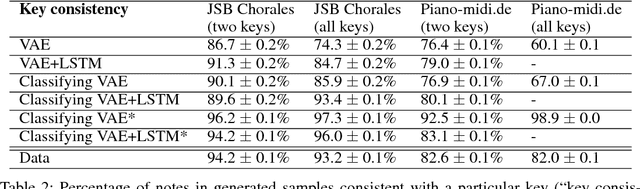
The variational autoencoder (VAE) is a popular probabilistic generative model. However, one shortcoming of VAEs is that the latent variables cannot be discrete, which makes it difficult to generate data from different modes of a distribution. Here, we propose an extension of the VAE framework that incorporates a classifier to infer the discrete class of the modeled data. To model sequential data, we can combine our Classifying VAE with a recurrent neural network such as an LSTM. We apply this model to algorithmic music generation, where our model learns to generate musical sequences in different keys. Most previous work in this area avoids modeling key by transposing data into only one or two keys, as opposed to the 10+ different keys in the original music. We show that our Classifying VAE and Classifying VAE+LSTM models outperform the corresponding non-classifying models in generating musical samples that stay in key. This benefit is especially apparent when trained on untransposed music data in the original keys.