 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music generation": models, code, and papers
MIDI-Sandwich2: RNN-based Hierarchical Multi-modal Fusion Generation VAE networks for multi-track symbolic music generation
Sep 08, 2019
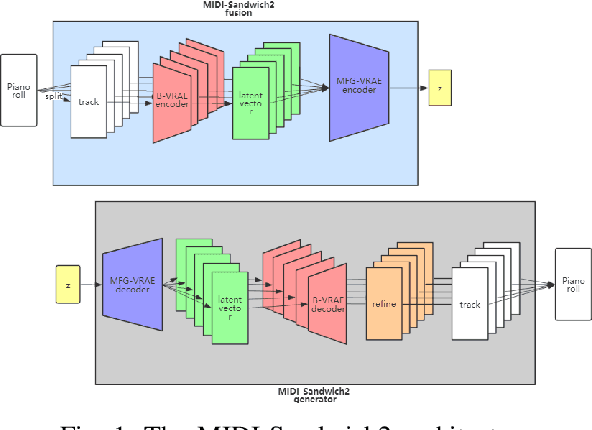

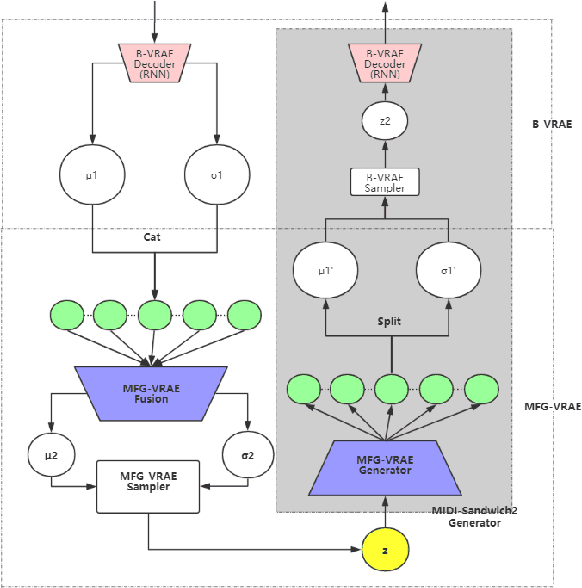
Currently, almost all the multi-track music generation models use the Convolutional Neural Network (CNN) to build the generative model, while the Recurrent Neural Network (RNN) based models can not be applied in this task. In view of the above problem, this paper proposes a RNN-based Hierarchical Multi-modal Fusion Generation Variational Autoencoder (VAE) network, MIDI-Sandwich2, for multi-track symbolic music generation. Inspired by VQ-VAE2, MIDI-Sandwich2 expands the dimension of the original hierarchical model by using multiple independent Binary Variational Autoencoder (BVAE) models without sharing weights to process the information of each track. Then, with multi-modal fusion technology, the upper layer named Multi-modal Fusion Generation VAE (MFG-VAE) combines the latent space vectors generated by the respective tracks, and uses the decoder to perform the ascending dimension reconstruction to simulate the inverse operation of multi-modal fusion, multi-modal generation, so as to realize the RNN-based multi-track symbolic music generation. For the multi-track format pianoroll, we also improve the output binarization method of MuseGAN, which solves the problem that the refinement step of the original scheme is difficult to differentiate and the gradient is hard to descent, making the generated song more expressive. The model is validated on the Lakh Pianoroll Dataset (LPD) multi-track dataset. Compared to the MuseGAN, MIDI-Sandwich2 can not only generate harmonious multi-track music, the generation quality is also close to the state of the art level. At the same time, by using the VAE to restore songs, the semi-generated songs reproduced by the MIDI-Sandwich2 are more beautiful than the pure autogeneration music generated by MuseGAN. Both the code and the audition audio samples are open source on https://github.com/LiangHsia/MIDI-S2.
Generating music with sentiment using Transformer-GANs
Dec 21, 2022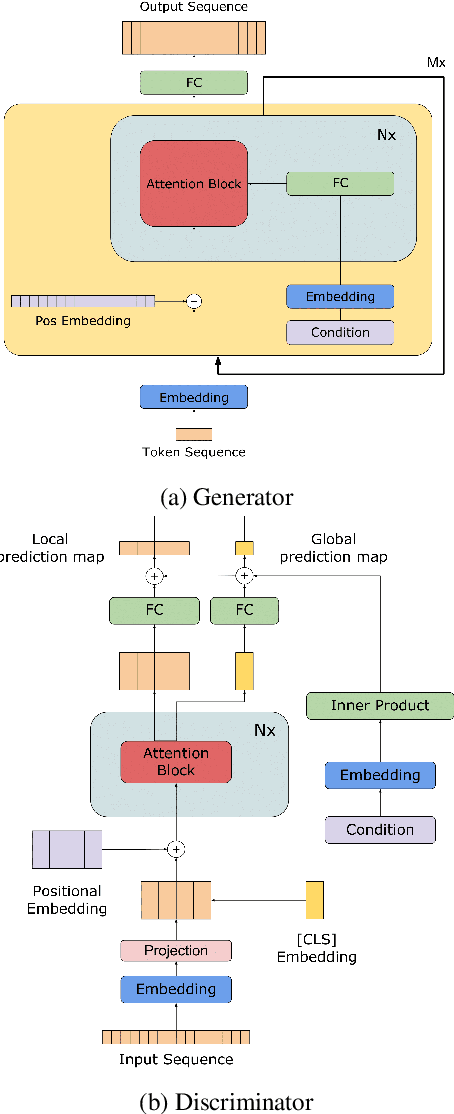
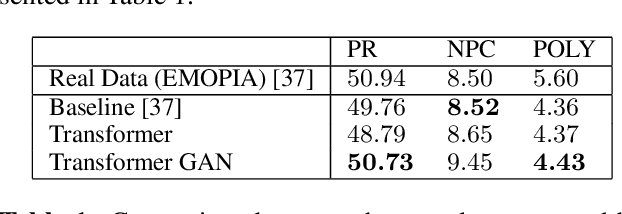
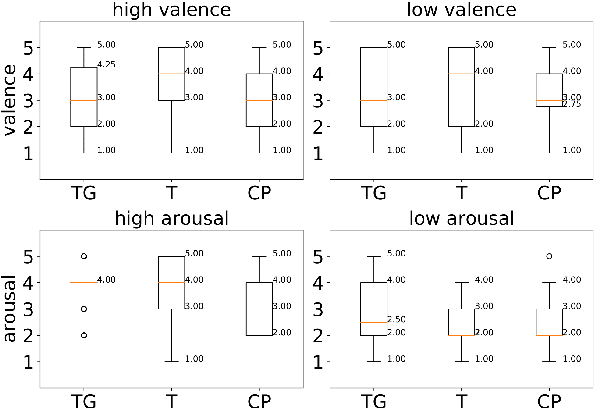
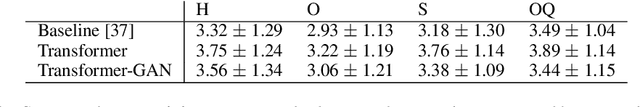
The field of Automatic Music Generation has seen significant progress thanks to the advent of Deep Learning. However, most of these results have been produced by unconditional models, which lack the ability to interact with their users, not allowing them to guide the generative process in meaningful and practical ways. Moreover, synthesizing music that remains coherent across longer timescales while still capturing the local aspects that make it sound ``realistic'' or ``human-like'' is still challenging. This is due to the large computational requirements needed to work with long sequences of data, and also to limitations imposed by the training schemes that are often employed. In this paper, we propose a generative model of symbolic music conditioned by data retrieved from human sentiment. The model is a Transformer-GAN trained with labels that correspond to different configurations of the valence and arousal dimensions that quantitatively represent human affective states. We try to tackle both of the problems above by employing an efficient linear version of Attention and using a Discriminator both as a tool to improve the overall quality of the generated music and its ability to follow the conditioning signals.
Quantum Natural Language Generation on Near-Term Devices
Nov 01, 2022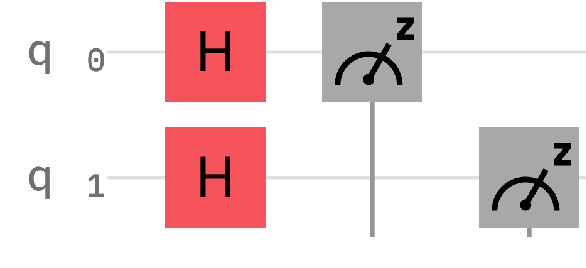
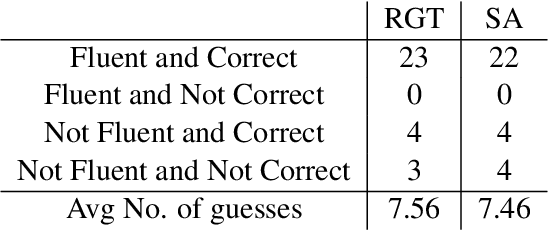
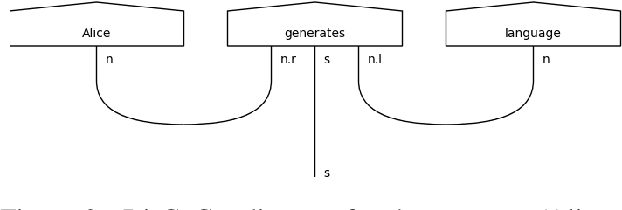
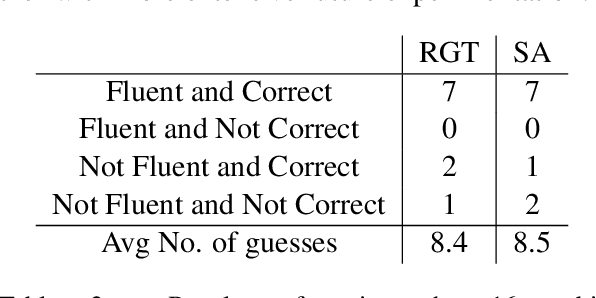
The emergence of noisy medium-scale quantum devices has led to proof-of-concept applications for quantum computing in various domains. Examples include Natural Language Processing (NLP) where sentence classification experiments have been carried out, as well as procedural generation, where tasks such as geopolitical map creation, and image manipulation have been performed. We explore applications at the intersection of these two areas by designing a hybrid quantum-classical algorithm for sentence generation. Our algorithm is based on the well-known simulated annealing technique for combinatorial optimisation. An implementation is provided and used to demonstrate successful sentence generation on both simulated and real quantum hardware. A variant of our algorithm can also be used for music generation. This paper aims to be self-contained, introducing all the necessary background on NLP and quantum computing along the way.
Music SketchNet: Controllable Music Generation via Factorized Representations of Pitch and Rhythm
Aug 04, 2020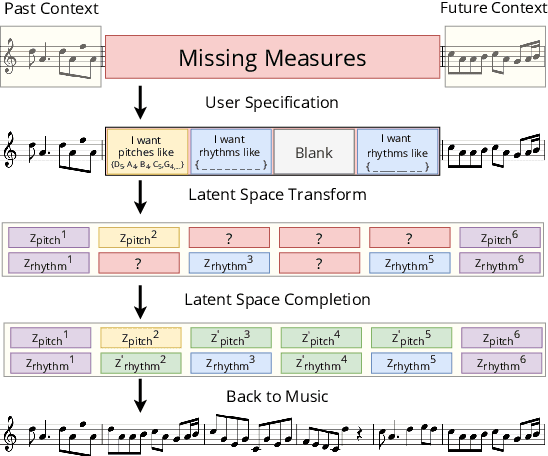
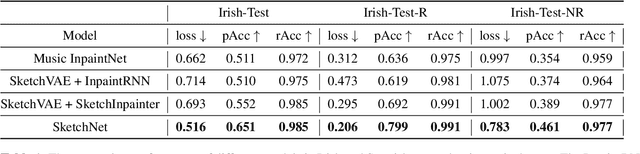
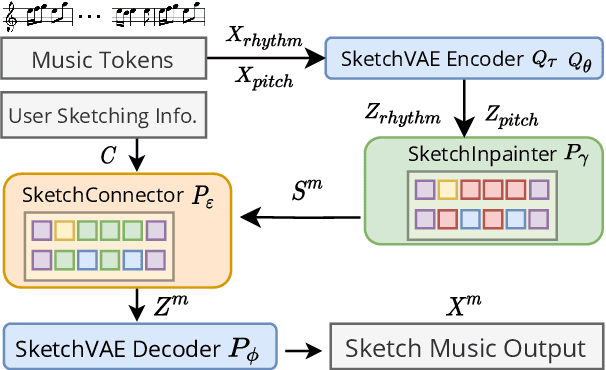
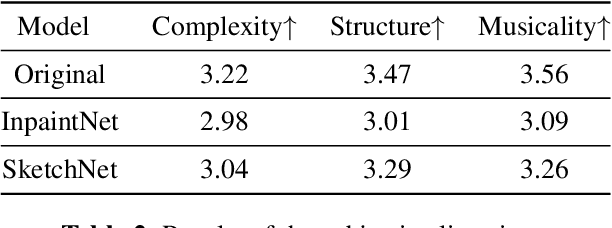
Drawing an analogy with automatic image completion systems, we propose Music SketchNet, a neural network framework that allows users to specify partial musical ideas guiding automatic music generation. We focus on generating the missing measures in incomplete monophonic musical pieces, conditioned on surrounding context, and optionally guided by user-specified pitch and rhythm snippets. First, we introduce SketchVAE, a novel variational autoencoder that explicitly factorizes rhythm and pitch contour to form the basis of our proposed model. Then we introduce two discriminative architectures, SketchInpainter and SketchConnector, that in conjunction perform the guided music completion, filling in representations for the missing measures conditioned on surrounding context and user-specified snippets. We evaluate SketchNet on a standard dataset of Irish folk music and compare with models from recent works. When used for music completion, our approach outperforms the state-of-the-art both in terms of objective metrics and subjective listening tests. Finally, we demonstrate that our model can successfully incorporate user-specified snippets during the generation process.
QuiKo: A Quantum Beat Generation Application
Apr 09, 2022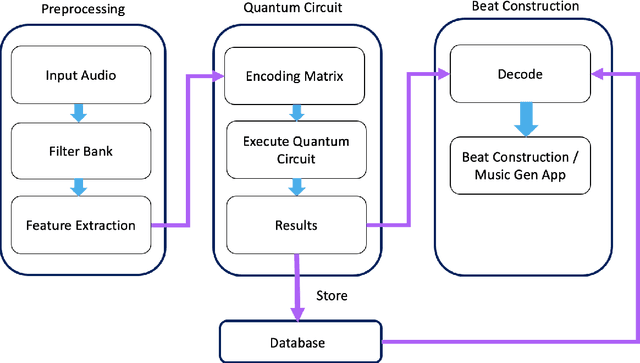
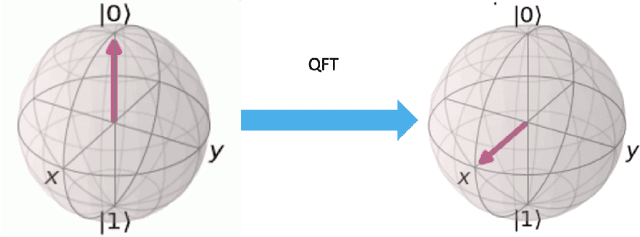
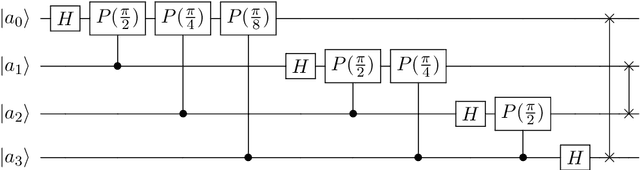
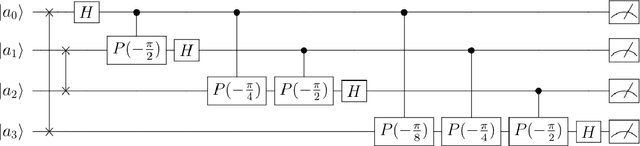
In this chapter a quantum music generation application called QuiKo will be discussed. It combines existing quantum algorithms with data encoding methods from quantum machine learning to build drum and audio sample patterns from a database of audio tracks. QuiKo leverages the physical properties and characteristics of quantum computers to generate what can be referred to as Soft Rules proposed by Alexis Kirke. These rules take advantage of the noise produced by quantum devices to develop flexible rules and grammars for quantum music generation. These properties include qubit decoherence and phase kickback due controlled quantum gates within the quantum circuit. QuiKo builds upon the concept of soft rules in quantum music generation and takes it a step further. It attempts to mimic and react to an external musical inputs, similar to the way that human musicians play and compose with one another. Audio signals are used as inputs into the system. Feature extraction is then performed on the signal to identify the harmonic and percussive elements. This information is then encoded onto the quantum circuit. Measurements of the quantum circuit are then taken providing results in the form of probability distributions for external music applications to use to build the new drum patterns.
Symphony Generation with Permutation Invariant Language Model
May 10, 2022
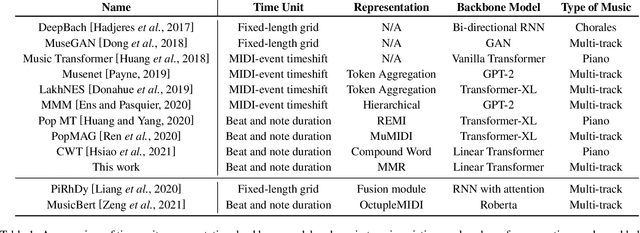
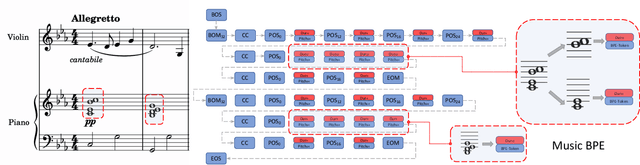
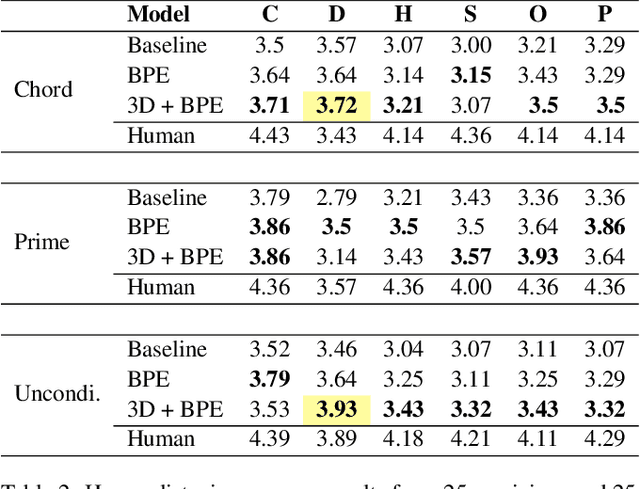
In this work, we present a symbolic symphony music generation solution, SymphonyNet, based on a permutation invariant language model. To bridge the gap between text generation and symphony generation task, we propose a novel Multi-track Multi-instrument Repeatable (MMR) representation with particular 3-D positional embedding and a modified Byte Pair Encoding algorithm (Music BPE) for music tokens. A novel linear transformer decoder architecture is introduced as a backbone for modeling extra-long sequences of symphony tokens. Meanwhile, we train the decoder to learn automatic orchestration as a joint task by masking instrument information from the input. We also introduce a large-scale symbolic symphony dataset for the advance of symphony generation research. Our empirical results show that our proposed approach can generate coherent, novel, complex and harmonious symphony compared to human composition, which is the pioneer solution for multi-track multi-instrument symbolic music generation.
Online Game Level Generation from Music
Jul 12, 2022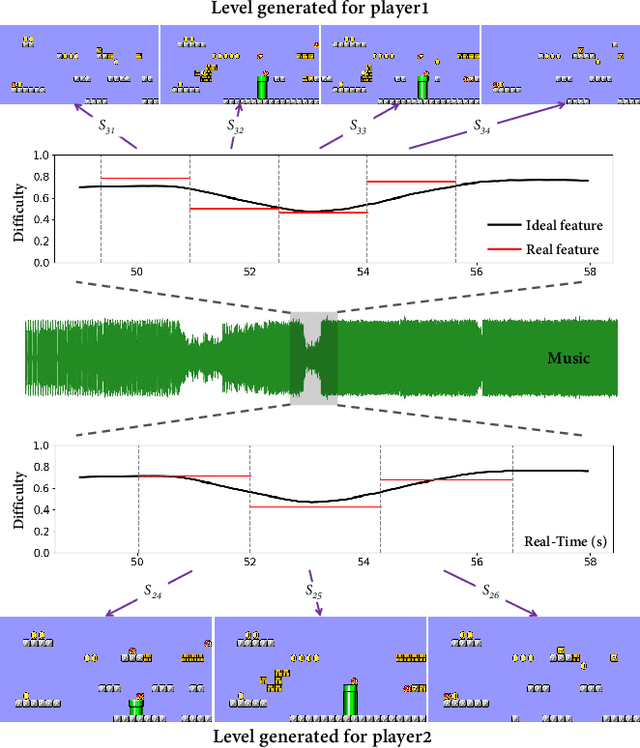
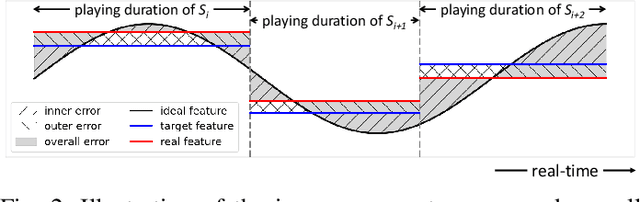
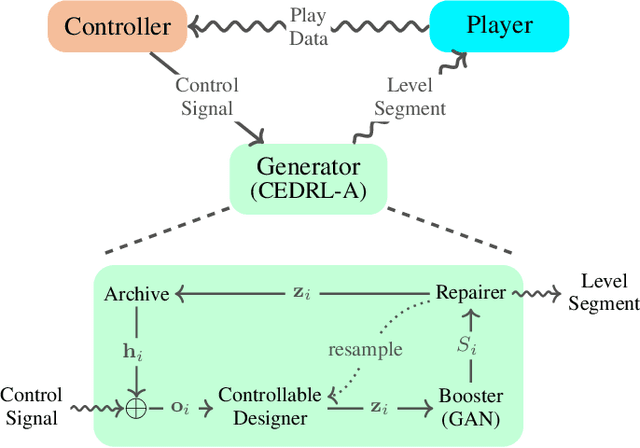
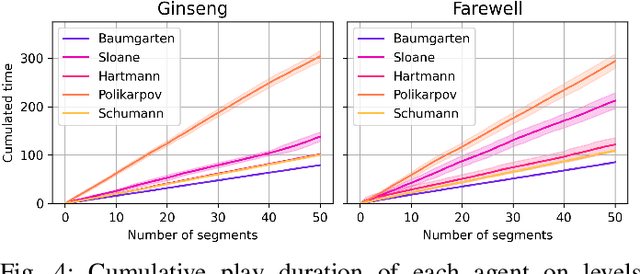
Game consists of multiple types of content, while the harmony of different content types play an essential role in game design. However, most works on procedural content generation consider only one type of content at a time. In this paper, we propose and formulate online level generation from music, in a way of matching a level feature to a music feature in real-time, while adapting to players' play speed. A generic framework named online player-adaptive procedural content generation via reinforcement learning, OPARL for short, is built upon the experience-driven reinforcement learning and controllable reinforcement learning, to enable online level generation from music. Furthermore, a novel control policy based on local search and k-nearest neighbours is proposed and integrated into OPARL to control the level generator considering the play data collected online. Results of simulation-based experiments show that our implementation of OPARL is competent to generate playable levels with difficulty degree matched to the ``energy'' dynamic of music for different artificial players in an online fashion.
Music-Driven Group Choreography
Mar 27, 2023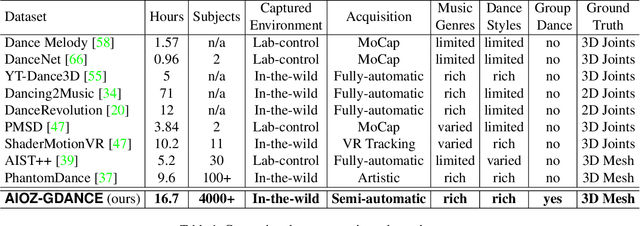
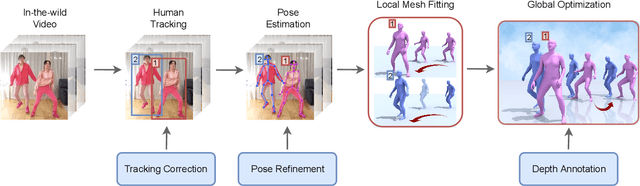
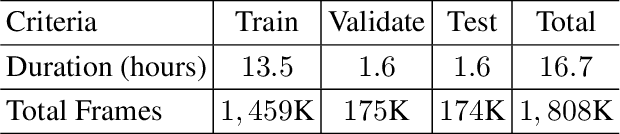
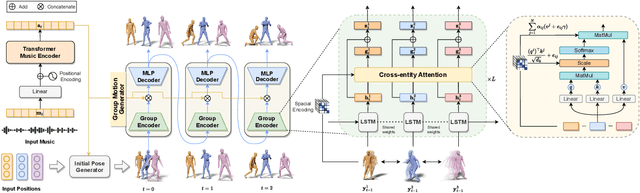
Music-driven choreography is a challenging problem with a wide variety of industrial applications. Recently, many methods have been proposed to synthesize dance motions from music for a single dancer. However, generating dance motion for a group remains an open problem. In this paper, we present $\rm AIOZ-GDANCE$, a new large-scale dataset for music-driven group dance generation. Unlike existing datasets that only support single dance, our new dataset contains group dance videos, hence supporting the study of group choreography. We propose a semi-autonomous labeling method with humans in the loop to obtain the 3D ground truth for our dataset. The proposed dataset consists of 16.7 hours of paired music and 3D motion from in-the-wild videos, covering 7 dance styles and 16 music genres. We show that naively applying single dance generation technique to creating group dance motion may lead to unsatisfactory results, such as inconsistent movements and collisions between dancers. Based on our new dataset, we propose a new method that takes an input music sequence and a set of 3D positions of dancers to efficiently produce multiple group-coherent choreographies. We propose new evaluation metrics for measuring group dance quality and perform intensive experiments to demonstrate the effectiveness of our method. Our project facilitates future research on group dance generation and is available at: https://aioz-ai.github.io/AIOZ-GDANCE/
An Order-Complexity Model for Aesthetic Quality Assessment of Homophony Music Performance
Apr 23, 2023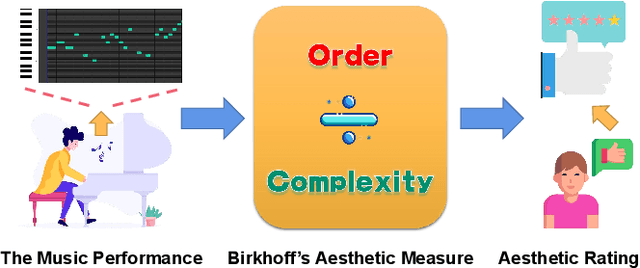

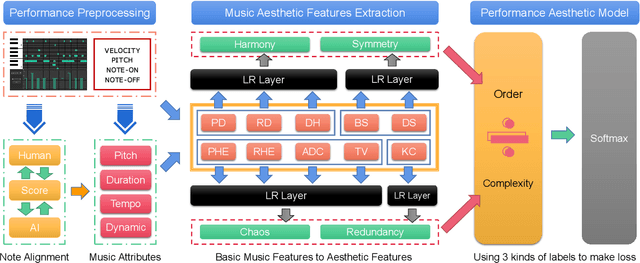

Although computational aesthetics evaluation has made certain achievements in many fields, its research of music performance remains to be explored. At present, subjective evaluation is still a ultimate method of music aesthetics research, but it will consume a lot of human and material resources. In addition, the music performance generated by AI is still mechanical, monotonous and lacking in beauty. In order to guide the generation task of AI music performance, and to improve the performance effect of human performers, this paper uses Birkhoff's aesthetic measure to propose a method of objective measurement of beauty. The main contributions of this paper are as follows: Firstly, we put forward an objective aesthetic evaluation method to measure the music performance aesthetic; Secondly, we propose 10 basic music features and 4 aesthetic music features. Experiments show that our method performs well on performance assessment.
Music Playlist Title Generation Using Artist Information
Jan 14, 2023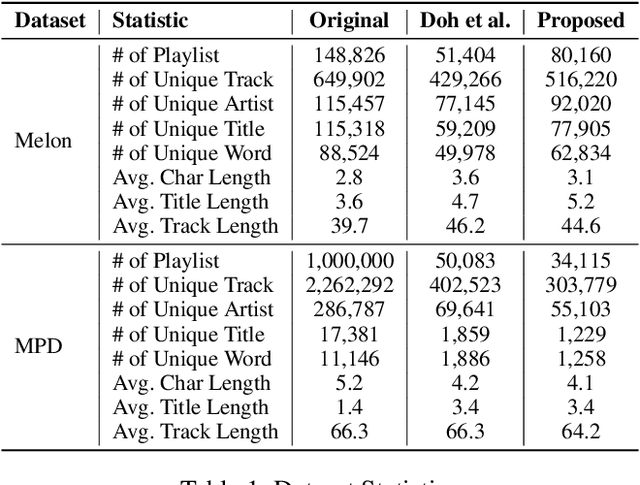
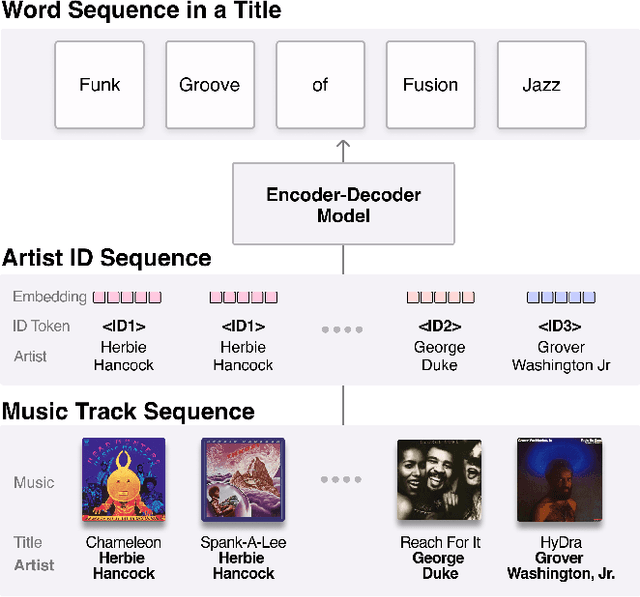

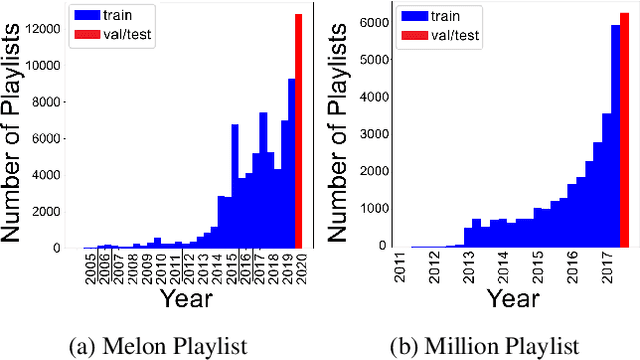
Automatically generating or captioning music playlist titles given a set of tracks is of significant interest in music streaming services as customized playlists are widely used in personalized music recommendation, and well-composed text titles attract users and help their music discovery. We present an encoder-decoder model that generates a playlist title from a sequence of music tracks. While previous work takes track IDs as tokenized input for playlist title generation, we use artist IDs corresponding to the tracks to mitigate the issue from the long-tail distribution of tracks included in the playlist dataset. Also, we introduce a chronological data split method to deal with newly-released tracks in real-world scenarios. Comparing the track IDs and artist IDs as input sequences, we show that the artist-based approach significantly enhances the performance in terms of word overlap, semantic relevance, and diversity.