 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music generation": models, code, and papers
HumTrans: A Novel Open-Source Dataset for Humming Melody Transcription and Beyond
Sep 18, 2023
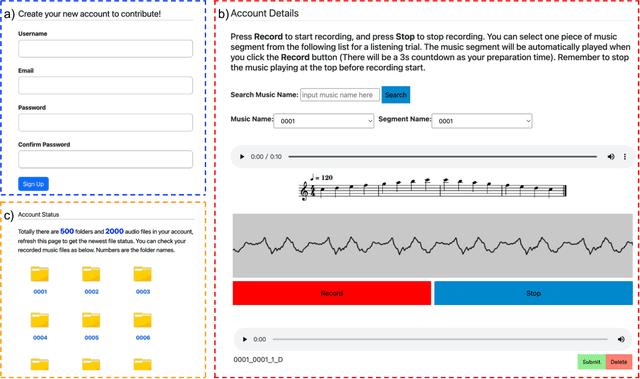
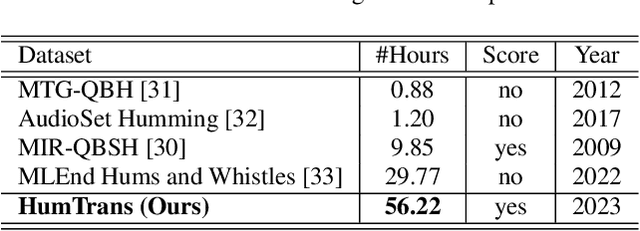
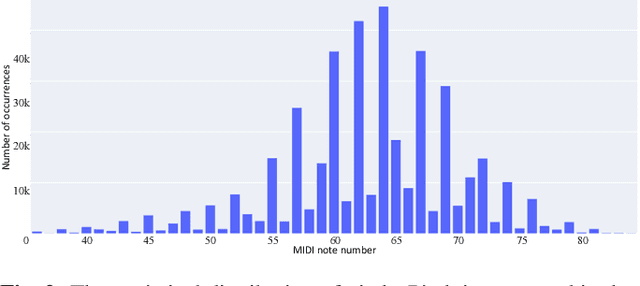
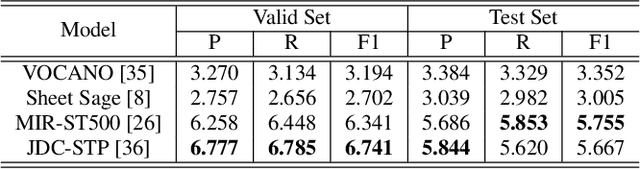
This paper introduces the HumTrans dataset, which is publicly available and primarily designed for humming melody transcription. The dataset can also serve as a foundation for downstream tasks such as humming melody based music generation. It consists of 500 musical compositions of different genres and languages, with each composition divided into multiple segments. In total, the dataset comprises 1000 music segments. To collect this humming dataset, we employed 10 college students, all of whom are either music majors or proficient in playing at least one musical instrument. Each of them hummed every segment twice using the web recording interface provided by our designed website. The humming recordings were sampled at a frequency of 44,100 Hz. During the humming session, the main interface provides a musical score for students to reference, with the melody audio playing simultaneously to aid in capturing both melody and rhythm. The dataset encompasses approximately 56.22 hours of audio, making it the largest known humming dataset to date. The dataset will be released on Hugging Face, and we will provide a GitHub repository containing baseline results and evaluation codes.
Museformer: Transformer with Fine- and Coarse-Grained Attention for Music Generation
Oct 19, 2022
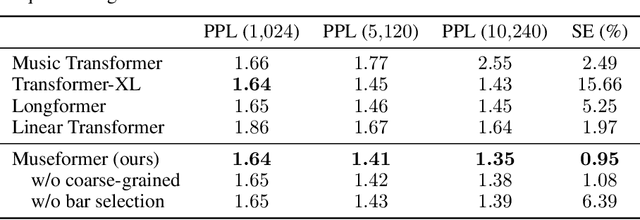
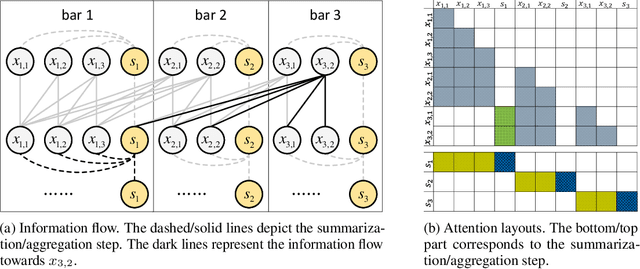
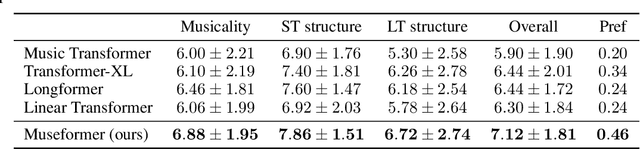
Symbolic music generation aims to generate music scores automatically. A recent trend is to use Transformer or its variants in music generation, which is, however, suboptimal, because the full attention cannot efficiently model the typically long music sequences (e.g., over 10,000 tokens), and the existing models have shortcomings in generating musical repetition structures. In this paper, we propose Museformer, a Transformer with a novel fine- and coarse-grained attention for music generation. Specifically, with the fine-grained attention, a token of a specific bar directly attends to all the tokens of the bars that are most relevant to music structures (e.g., the previous 1st, 2nd, 4th and 8th bars, selected via similarity statistics); with the coarse-grained attention, a token only attends to the summarization of the other bars rather than each token of them so as to reduce the computational cost. The advantages are two-fold. First, it can capture both music structure-related correlations via the fine-grained attention, and other contextual information via the coarse-grained attention. Second, it is efficient and can model over 3X longer music sequences compared to its full-attention counterpart. Both objective and subjective experimental results demonstrate its ability to generate long music sequences with high quality and better structures.
Music Representing Corpus Virtual: An Open Sourced Library for Explorative Music Generation, Sound Design, and Instrument Creation with Artificial Intelligence and Machine Learning
May 24, 2023
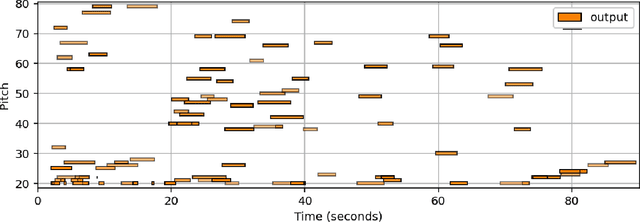

Music Representing Corpus Virtual (MRCV) is an open source software suite designed to explore the capabilities of Artificial Intelligence (AI) and Machine Learning (ML) in Music Generation, Sound Design, and Virtual Instrument Creation (MGSDIC). The software is accessible to users of varying levels of experience, with an emphasis on providing an explorative approach to MGSDIC. The main aim of MRCV is to facilitate creativity, allowing users to customize input datasets for training the neural networks, and offering a range of options for each neural network (thoroughly documented in the Github Wiki). The software suite is designed to be accessible to musicians, audio professionals, sound designers, and composers, regardless of their prior experience in AI or ML. The documentation is prepared in such a way as to abstract technical details, thereby making it easy to understand. The software is open source, meaning users can contribute to its development, and the community can collectively benefit from the insights and experience of other users.
A Unified Framework for Multimodal, Multi-Part Human Motion Synthesis
Nov 28, 2023The field has made significant progress in synthesizing realistic human motion driven by various modalities. Yet, the need for different methods to animate various body parts according to different control signals limits the scalability of these techniques in practical scenarios. In this paper, we introduce a cohesive and scalable approach that consolidates multimodal (text, music, speech) and multi-part (hand, torso) human motion generation. Our methodology unfolds in several steps: We begin by quantizing the motions of diverse body parts into separate codebooks tailored to their respective domains. Next, we harness the robust capabilities of pre-trained models to transcode multimodal signals into a shared latent space. We then translate these signals into discrete motion tokens by iteratively predicting subsequent tokens to form a complete sequence. Finally, we reconstruct the continuous actual motion from this tokenized sequence. Our method frames the multimodal motion generation challenge as a token prediction task, drawing from specialized codebooks based on the modality of the control signal. This approach is inherently scalable, allowing for the easy integration of new modalities. Extensive experiments demonstrated the effectiveness of our design, emphasizing its potential for broad application.
ERNIE-Music: Text-to-Waveform Music Generation with Diffusion Models
Feb 09, 2023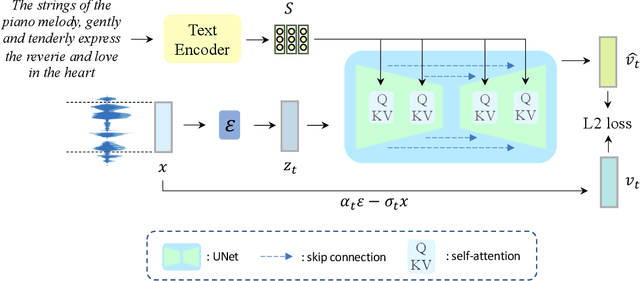

In recent years, there has been an increased popularity in image and speech generation using diffusion models. However, directly generating music waveforms from free-form text prompts is still under-explored. In this paper, we propose the first text-to-waveform music generation model that can receive arbitrary texts using diffusion models. We incorporate the free-form textual prompt as the condition to guide the waveform generation process of diffusion models. To solve the problem of lacking such text-music parallel data, we collect a dataset of text-music pairs from the Internet with weak supervision. Besides, we compare the effect of two prompt formats of conditioning texts (music tags and free-form texts) and prove the superior performance of our method in terms of text-music relevance. We further demonstrate that our generated music in the waveform domain outperforms previous works by a large margin in terms of diversity, quality, and text-music relevance.
MusicLDM: Enhancing Novelty in Text-to-Music Generation Using Beat-Synchronous Mixup Strategies
Aug 03, 2023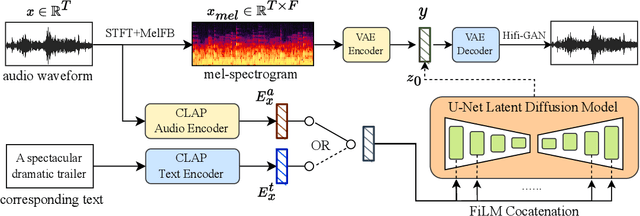
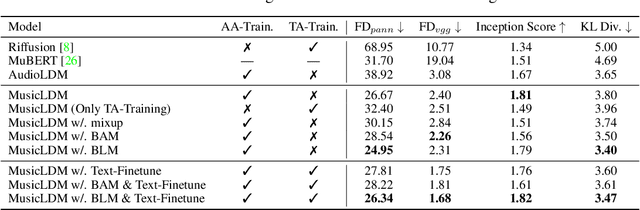
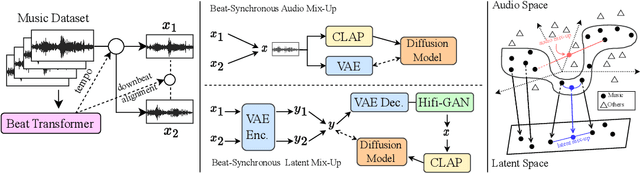
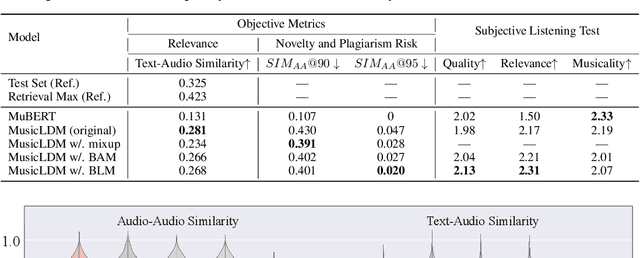
Diffusion models have shown promising results in cross-modal generation tasks, including text-to-image and text-to-audio generation. However, generating music, as a special type of audio, presents unique challenges due to limited availability of music data and sensitive issues related to copyright and plagiarism. In this paper, to tackle these challenges, we first construct a state-of-the-art text-to-music model, MusicLDM, that adapts Stable Diffusion and AudioLDM architectures to the music domain. We achieve this by retraining the contrastive language-audio pretraining model (CLAP) and the Hifi-GAN vocoder, as components of MusicLDM, on a collection of music data samples. Then, to address the limitations of training data and to avoid plagiarism, we leverage a beat tracking model and propose two different mixup strategies for data augmentation: beat-synchronous audio mixup and beat-synchronous latent mixup, which recombine training audio directly or via a latent embeddings space, respectively. Such mixup strategies encourage the model to interpolate between musical training samples and generate new music within the convex hull of the training data, making the generated music more diverse while still staying faithful to the corresponding style. In addition to popular evaluation metrics, we design several new evaluation metrics based on CLAP score to demonstrate that our proposed MusicLDM and beat-synchronous mixup strategies improve both the quality and novelty of generated music, as well as the correspondence between input text and generated music.
MusicAgent: An AI Agent for Music Understanding and Generation with Large Language Models
Oct 18, 2023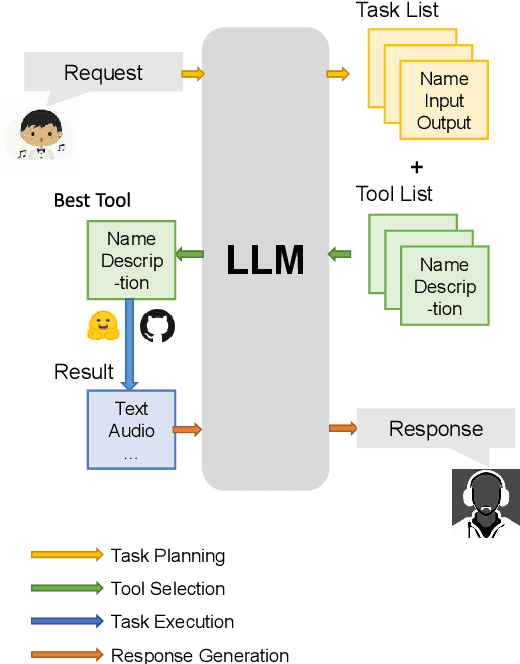
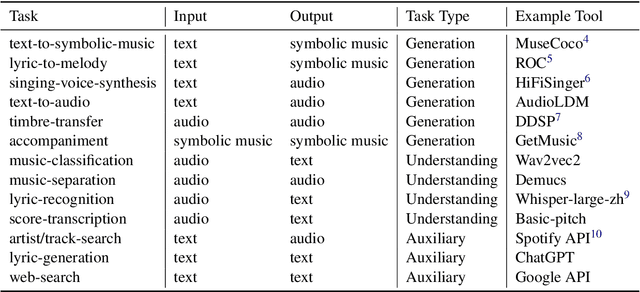
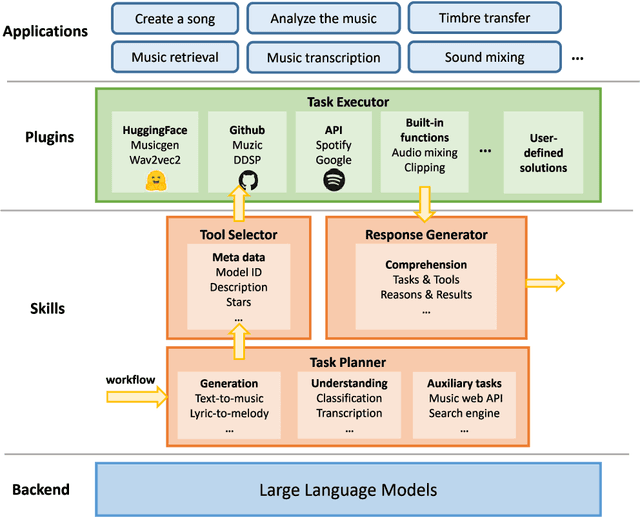
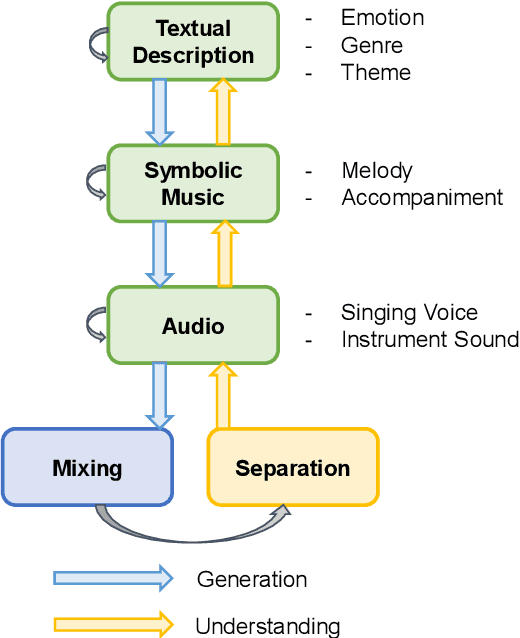
AI-empowered music processing is a diverse field that encompasses dozens of tasks, ranging from generation tasks (e.g., timbre synthesis) to comprehension tasks (e.g., music classification). For developers and amateurs, it is very difficult to grasp all of these task to satisfy their requirements in music processing, especially considering the huge differences in the representations of music data and the model applicability across platforms among various tasks. Consequently, it is necessary to build a system to organize and integrate these tasks, and thus help practitioners to automatically analyze their demand and call suitable tools as solutions to fulfill their requirements. Inspired by the recent success of large language models (LLMs) in task automation, we develop a system, named MusicAgent, which integrates numerous music-related tools and an autonomous workflow to address user requirements. More specifically, we build 1) toolset that collects tools from diverse sources, including Hugging Face, GitHub, and Web API, etc. 2) an autonomous workflow empowered by LLMs (e.g., ChatGPT) to organize these tools and automatically decompose user requests into multiple sub-tasks and invoke corresponding music tools. The primary goal of this system is to free users from the intricacies of AI-music tools, enabling them to concentrate on the creative aspect. By granting users the freedom to effortlessly combine tools, the system offers a seamless and enriching music experience.
MusiLingo: Bridging Music and Text with Pre-trained Language Models for Music Captioning and Query Response
Sep 15, 2023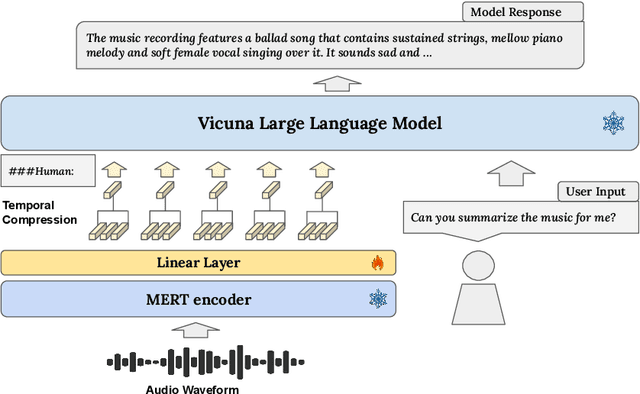

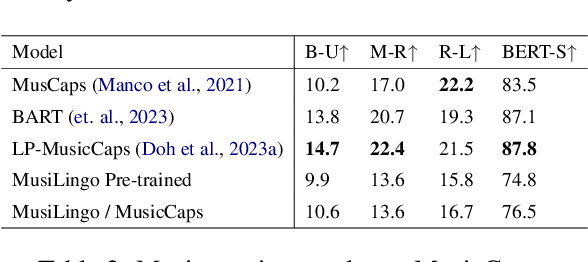
Large Language Models (LLMs) have shown immense potential in multimodal applications, yet the convergence of textual and musical domains remains relatively unexplored. To address this gap, we present MusiLingo, a novel system for music caption generation and music-related query responses. MusiLingo employs a single projection layer to align music representations from the pre-trained frozen music audio model MERT with the frozen LLaMA language model, bridging the gap between music audio and textual contexts. We train it on an extensive music caption dataset and fine-tune it with instructional data. Due to the scarcity of high-quality music Q&A datasets, we created the MusicInstruct (MI) dataset from MusicCaps, tailored for open-ended music inquiries. Empirical evaluations demonstrate its competitive performance in generating music captions and composing music-related Q&A pairs. Our introduced dataset enables notable advancements beyond previous ones.
Symbolic & Acoustic: Multi-domain Music Emotion Modeling for Instrumental Music
Aug 28, 2023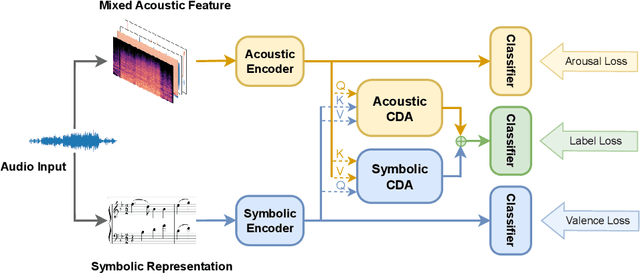
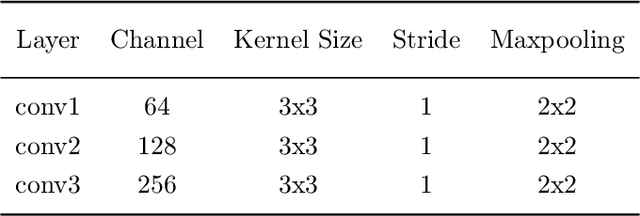

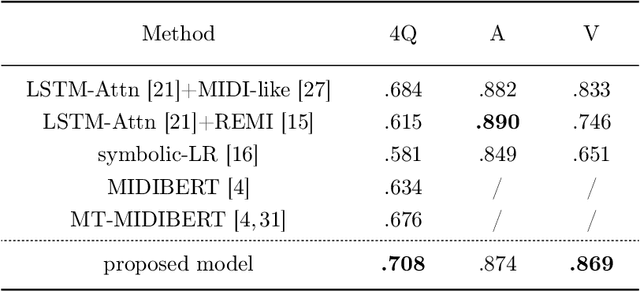
Music Emotion Recognition involves the automatic identification of emotional elements within music tracks, and it has garnered significant attention due to its broad applicability in the field of Music Information Retrieval. It can also be used as the upstream task of many other human-related tasks such as emotional music generation and music recommendation. Due to existing psychology research, music emotion is determined by multiple factors such as the Timbre, Velocity, and Structure of the music. Incorporating multiple factors in MER helps achieve more interpretable and finer-grained methods. However, most prior works were uni-domain and showed weak consistency between arousal modeling performance and valence modeling performance. Based on this background, we designed a multi-domain emotion modeling method for instrumental music that combines symbolic analysis and acoustic analysis. At the same time, because of the rarity of music data and the difficulty of labeling, our multi-domain approach can make full use of limited data. Our approach was implemented and assessed using the publicly available piano dataset EMOPIA, resulting in a notable improvement over our baseline model with a 2.4% increase in overall accuracy, establishing its state-of-the-art performance.
A Survey on Artificial Intelligence for Music Generation: Agents, Domains and Perspectives
Nov 03, 2022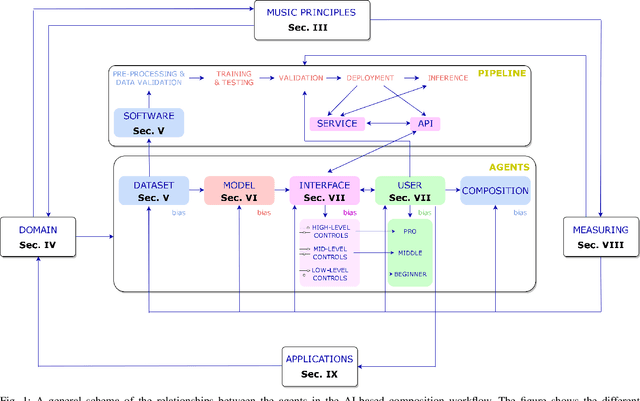
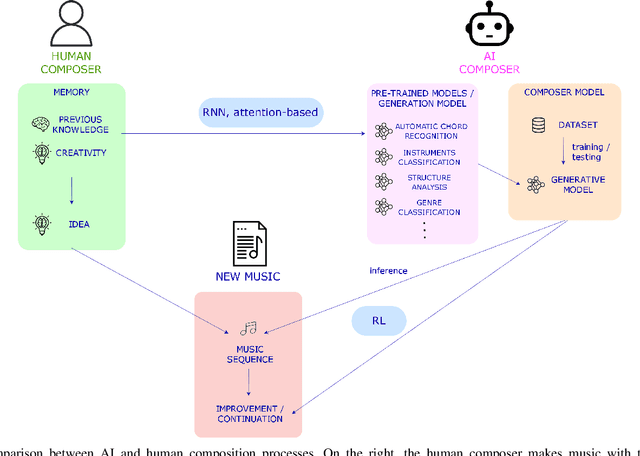
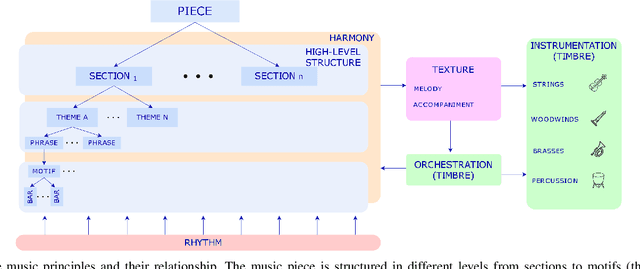
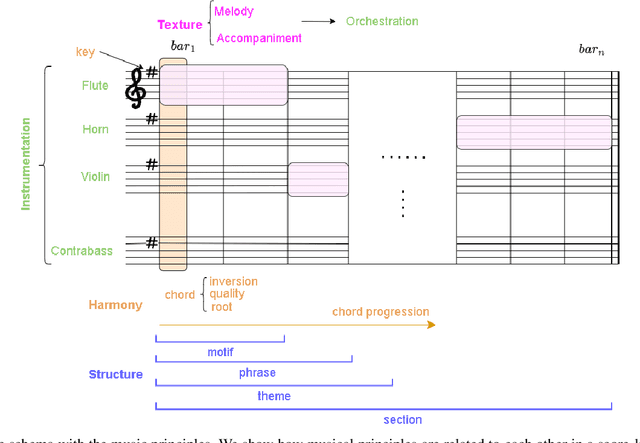
Music is one of the Gardner's intelligences in his theory of multiple intelligences. How humans perceive and understand music is still being studied and is crucial to develop artificial intelligence models that imitate such processes. Music generation with Artificial Intelligence is an emerging field that is gaining much attention in the recent years. In this paper, we describe how humans compose music and how new AI systems could imitate such process by comparing past and recent advances in the field with music composition techniques. To understand how AI models and algorithms generate music and the potential applications that might appear in the future, we explore, analyze and describe the agents that take part of the music generation process: the datasets, models, interfaces, the users and the generated music. We mention possible applications that might benefit from this field and we also propose new trends and future research directions that could be explored in the future.