 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music generation": models, code, and papers
Codified audio language modeling learns useful representations for music information retrieval
Jul 12, 2021
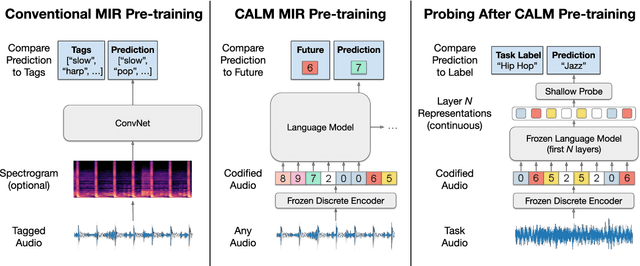
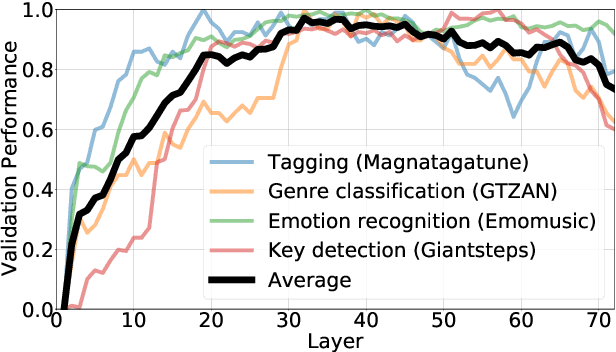

We demonstrate that language models pre-trained on codified (discretely-encoded) music audio learn representations that are useful for downstream MIR tasks. Specifically, we explore representations from Jukebox (Dhariwal et al. 2020): a music generation system containing a language model trained on codified audio from 1M songs. To determine if Jukebox's representations contain useful information for MIR, we use them as input features to train shallow models on several MIR tasks. Relative to representations from conventional MIR models which are pre-trained on tagging, we find that using representations from Jukebox as input features yields 30% stronger performance on average across four MIR tasks: tagging, genre classification, emotion recognition, and key detection. For key detection, we observe that representations from Jukebox are considerably stronger than those from models pre-trained on tagging, suggesting that pre-training via codified audio language modeling may address blind spots in conventional approaches. We interpret the strength of Jukebox's representations as evidence that modeling audio instead of tags provides richer representations for MIR.
MuseMorphose: Full-Song and Fine-Grained Music Style Transfer with Just One Transformer VAE
May 10, 2021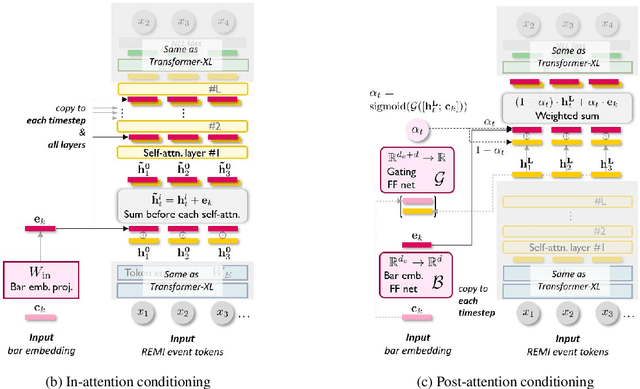

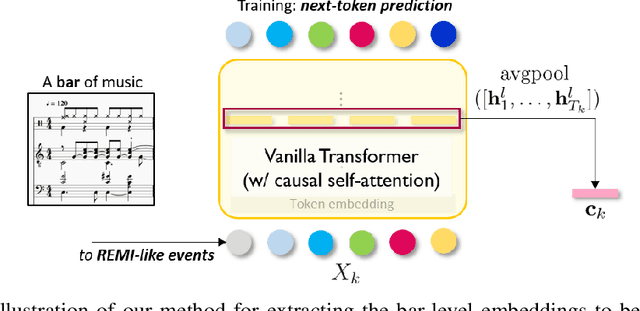

Transformers and variational autoencoders (VAE) have been extensively employed for symbolic (e.g., MIDI) domain music generation. While the former boast an impressive capability in modeling long sequences, the latter allow users to willingly exert control over different parts (e.g., bars) of the music to be generated. In this paper, we are interested in bringing the two together to construct a single model that exhibits both strengths. The task is split into two steps. First, we equip Transformer decoders with the ability to accept segment-level, time-varying conditions during sequence generation. Subsequently, we combine the developed and tested in-attention decoder with a Transformer encoder, and train the resulting MuseMorphose model with the VAE objective to achieve style transfer of long musical pieces, in which users can specify musical attributes including rhythmic intensity and polyphony (i.e., harmonic fullness) they desire, down to the bar level. Experiments show that MuseMorphose outperforms recurrent neural network (RNN) based prior art on numerous widely-used metrics for style transfer tasks.
Learning to Generate Music With Sentiment
Mar 09, 2021
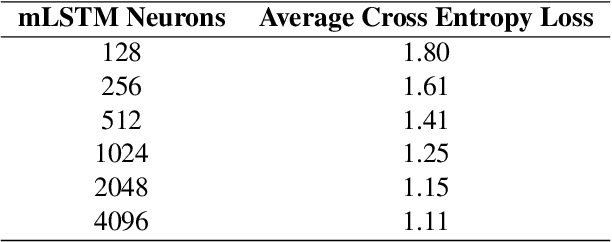
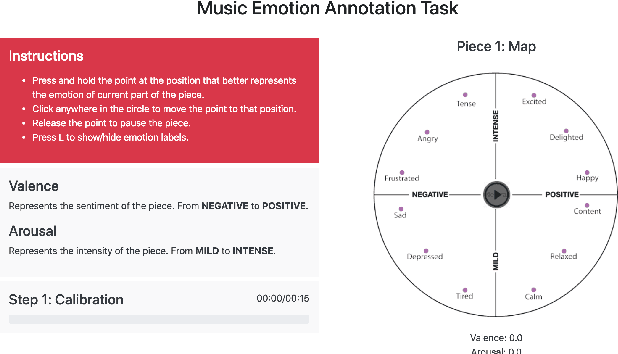
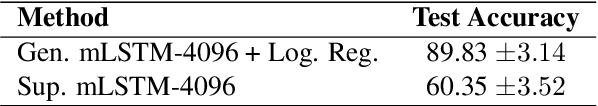
Deep Learning models have shown very promising results in automatically composing polyphonic music pieces. However, it is very hard to control such models in order to guide the compositions towards a desired goal. We are interested in controlling a model to automatically generate music with a given sentiment. This paper presents a generative Deep Learning model that can be directed to compose music with a given sentiment. Besides music generation, the same model can be used for sentiment analysis of symbolic music. We evaluate the accuracy of the model in classifying sentiment of symbolic music using a new dataset of video game soundtracks. Results show that our model is able to obtain good prediction accuracy. A user study shows that human subjects agreed that the generated music has the intended sentiment, however negative pieces can be ambiguous.
MMM : Exploring Conditional Multi-Track Music Generation with the Transformer
Aug 20, 2020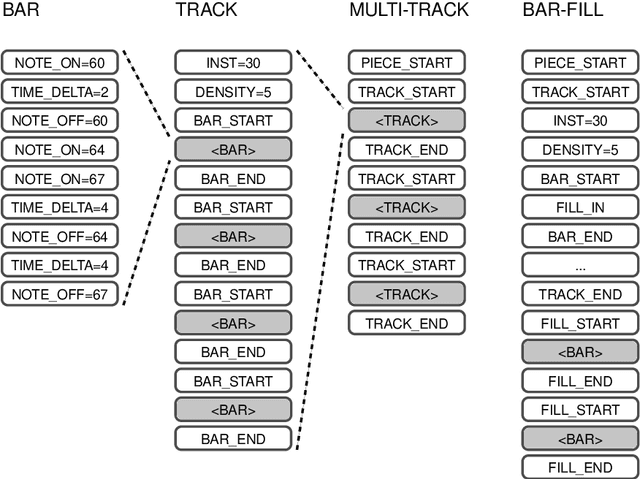
We propose the Multi-Track Music Machine (MMM), a generative system based on the Transformer architecture that is capable of generating multi-track music. In contrast to previous work, which represents musical material as a single time-ordered sequence, where the musical events corresponding to different tracks are interleaved, we create a time-ordered sequence of musical events for each track and concatenate several tracks into a single sequence. This takes advantage of the Transformer's attention-mechanism, which can adeptly handle long-term dependencies. We explore how various representations can offer the user a high degree of control at generation time, providing an interactive demo that accommodates track-level and bar-level inpainting, and offers control over track instrumentation and note density.
DadaGP: A Dataset of Tokenized GuitarPro Songs for Sequence Models
Jul 30, 2021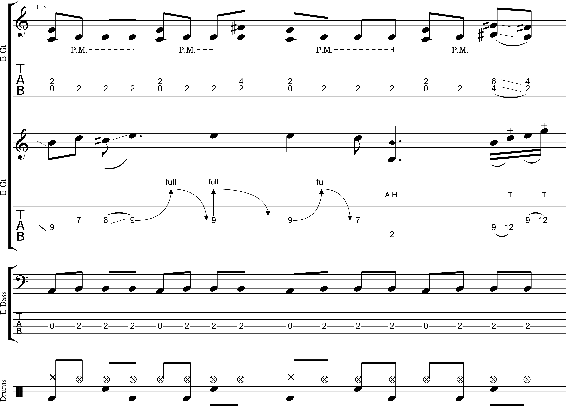

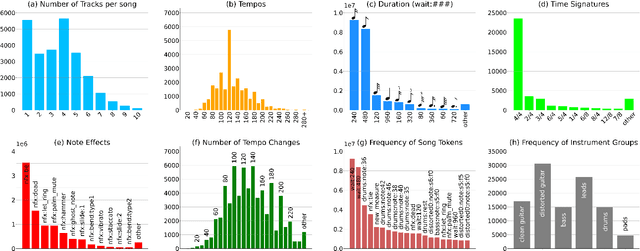
Originating in the Renaissance and burgeoning in the digital era, tablatures are a commonly used music notation system which provides explicit representations of instrument fingerings rather than pitches. GuitarPro has established itself as a widely used tablature format and software enabling musicians to edit and share songs for musical practice, learning, and composition. In this work, we present DadaGP, a new symbolic music dataset comprising 26,181 song scores in the GuitarPro format covering 739 musical genres, along with an accompanying tokenized format well-suited for generative sequence models such as the Transformer. The tokenized format is inspired by event-based MIDI encodings, often used in symbolic music generation models. The dataset is released with an encoder/decoder which converts GuitarPro files to tokens and back. We present results of a use case in which DadaGP is used to train a Transformer-based model to generate new songs in GuitarPro format. We discuss other relevant use cases for the dataset (guitar-bass transcription, music style transfer and artist/genre classification) as well as ethical implications. DadaGP opens up the possibility to train GuitarPro score generators, fine-tune models on custom data, create new styles of music, AI-powered songwriting apps, and human-AI improvisation.
Perceiving Music Quality with GANs
Jun 11, 2020
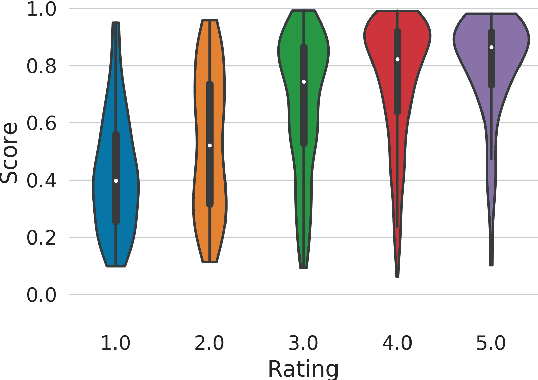
Assessing perceptual quality of musical audio signals usually requires a clean reference signal of unaltered content, hindering applications where a reference is unavailable such as for music generation. We propose training a generative adversarial network on a music library, and using its discriminator as a measure of the perceived quality of music. This method is unsupervised, needs no access to degraded material and can be tuned for various domains of music. Finally, the method is shown to have a statistically significant correlation with human ratings of music.
Subjective Evaluation of Deep Learning Models for Symbolic Music Composition
Apr 03, 2022
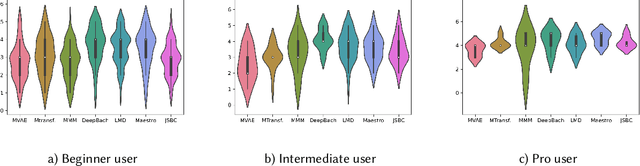
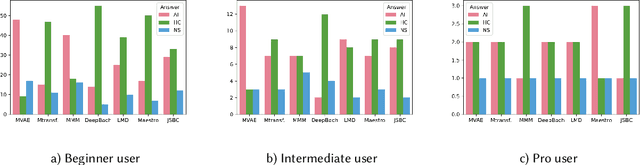
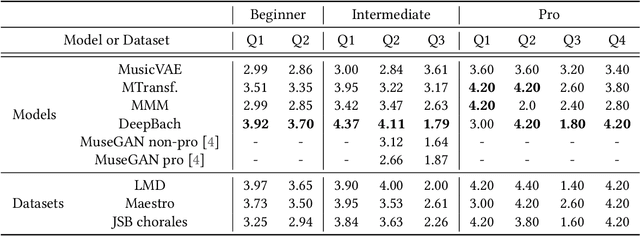
Deep learning models are typically evaluated to measure and compare their performance on a given task. The metrics that are commonly used to evaluate these models are standard metrics that are used for different tasks. In the field of music composition or generation, the standard metrics used in other fields have no clear meaning in terms of music theory. In this paper, we propose a subjective method to evaluate AI-based music composition systems by asking questions related to basic music principles to different levels of users based on their musical experience and knowledge. We use this method to compare state-of-the-art models for music composition with deep learning. We give the results of this evaluation method and we compare the responses of each user level for each evaluated model.
Can GAN originate new electronic dance music genres? -- Generating novel rhythm patterns using GAN with Genre Ambiguity Loss
Nov 25, 2020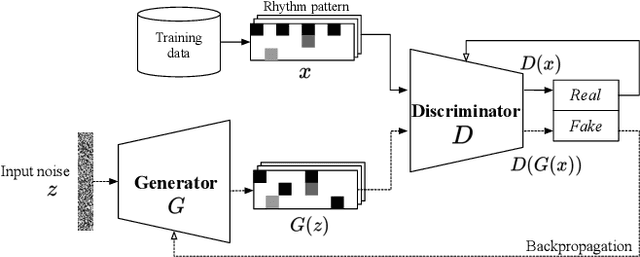

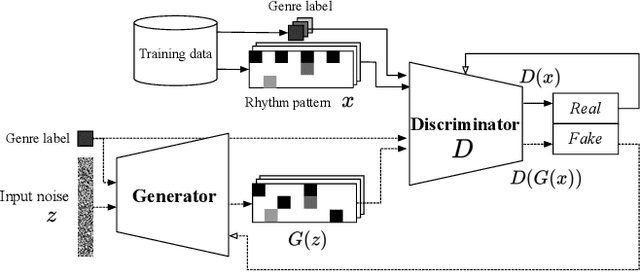
Since the introduction of deep learning, researchers have proposed content generation systems using deep learning and proved that they are competent to generate convincing content and artistic output, including music. However, one can argue that these deep learning-based systems imitate and reproduce the patterns inherent within what humans have created, instead of generating something new and creative. This paper focuses on music generation, especially rhythm patterns of electronic dance music, and discusses if we can use deep learning to generate novel rhythms, interesting patterns not found in the training dataset. We extend the framework of Generative Adversarial Networks(GAN) and encourage it to diverge from the dataset's inherent distributions by adding additional classifiers to the framework. The paper shows that our proposed GAN can generate rhythm patterns that sound like music rhythms but do not belong to any genres in the training dataset. The source code, generated rhythm patterns, and a supplementary plugin software for a popular Digital Audio Workstation software are available on our website.
MuLan: A Joint Embedding of Music Audio and Natural Language
Aug 26, 2022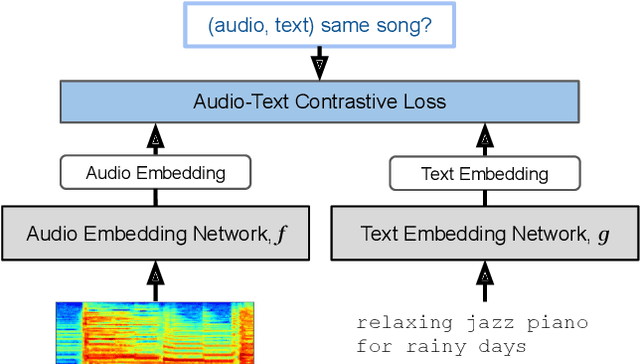


Music tagging and content-based retrieval systems have traditionally been constructed using pre-defined ontologies covering a rigid set of music attributes or text queries. This paper presents MuLan: a first attempt at a new generation of acoustic models that link music audio directly to unconstrained natural language music descriptions. MuLan takes the form of a two-tower, joint audio-text embedding model trained using 44 million music recordings (370K hours) and weakly-associated, free-form text annotations. Through its compatibility with a wide range of music genres and text styles (including conventional music tags), the resulting audio-text representation subsumes existing ontologies while graduating to true zero-shot functionalities. We demonstrate the versatility of the MuLan embeddings with a range of experiments including transfer learning, zero-shot music tagging, language understanding in the music domain, and cross-modal retrieval applications.