 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music generation": models, code, and papers
Evaluating Co-Creativity using Total Information Flow
Feb 09, 2024
Co-creativity in music refers to two or more musicians or musical agents interacting with one another by composing or improvising music. However, this is a very subjective process and each musician has their own preference as to which improvisation is better for some context. In this paper, we aim to create a measure based on total information flow to quantitatively evaluate the co-creativity process in music. In other words, our measure is an indication of how "good" a creative musical process is. Our main hypothesis is that a good musical creation would maximize information flow between the participants captured by music voices recorded in separate tracks. We propose a method to compute the information flow using pre-trained generative models as entropy estimators. We demonstrate how our method matches with human perception using a qualitative study.
Efficient bandwidth extension of musical signals using a differentiable harmonic plus noise model
Nov 27, 2023The task of bandwidth extension addresses the generation of missing high frequencies of audio signals based on knowledge of the low-frequency part of the sound. This task applies to various problems, such as audio coding or audio restoration. In this article, we focus on efficient bandwidth extension of monophonic and polyphonic musical signals using a differentiable digital signal processing (DDSP) model. Such a model is composed of a neural network part with relatively few parameters trained to infer the parameters of a differentiable digital signal processing model, which efficiently generates the output full-band audio signal. We first address bandwidth extension of monophonic signals, and then propose two methods to explicitely handle polyphonic signals. The benefits of the proposed models are first demonstrated on monophonic and polyphonic synthetic data against a baseline and a deep-learning-based resnet model. The models are next evaluated on recorded monophonic and polyphonic data, for a wide variety of instruments and musical genres. We show that all proposed models surpass a higher complexity deep learning model for an objective metric computed in the frequency domain. A MUSHRA listening test confirms the superiority of the proposed approach in terms of perceptual quality.
Quantized GAN for Complex Music Generation from Dance Videos
Apr 01, 2022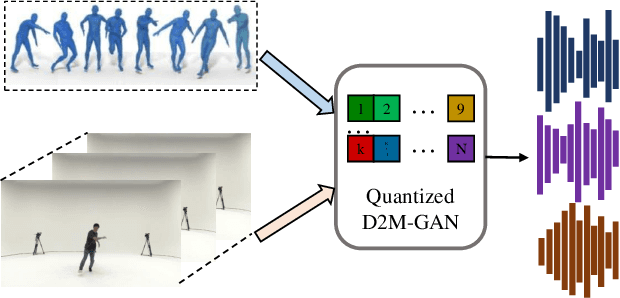
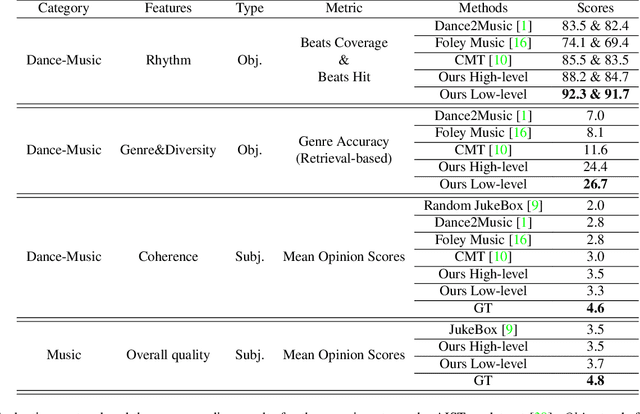
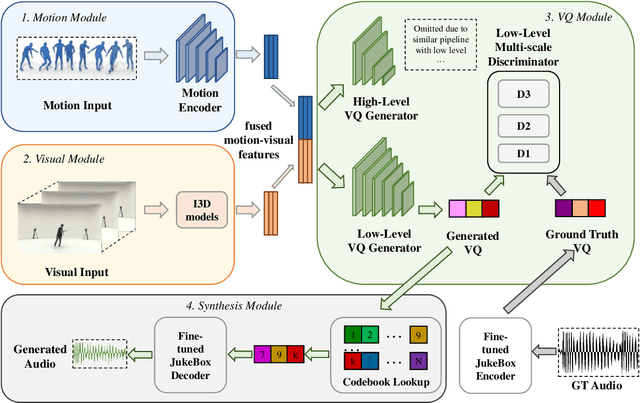
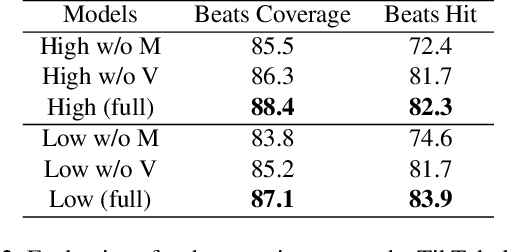
We present Dance2Music-GAN (D2M-GAN), a novel adversarial multi-modal framework that generates complex musical samples conditioned on dance videos. Our proposed framework takes dance video frames and human body motion as input, and learns to generate music samples that plausibly accompany the corresponding input. Unlike most existing conditional music generation works that generate specific types of mono-instrumental sounds using symbolic audio representations (e.g., MIDI), and that heavily rely on pre-defined musical synthesizers, in this work we generate dance music in complex styles (e.g., pop, breakdancing, etc.) by employing a Vector Quantized (VQ) audio representation, and leverage both its generality and the high abstraction capacity of its symbolic and continuous counterparts. By performing an extensive set of experiments on multiple datasets, and following a comprehensive evaluation protocol, we assess the generative quality of our approach against several alternatives. The quantitative results, which measure the music consistency, beats correspondence, and music diversity, clearly demonstrate the effectiveness of our proposed method. Last but not least, we curate a challenging dance-music dataset of in-the-wild TikTok videos, which we use to further demonstrate the efficacy of our approach in real-world applications - and which we hope to serve as a starting point for relevant future research.
Symbolic music generation conditioned on continuous-valued emotions
Mar 30, 2022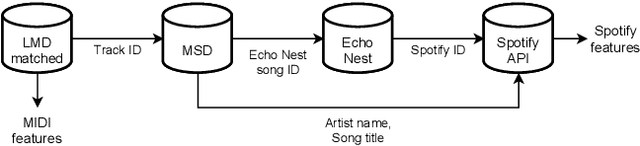
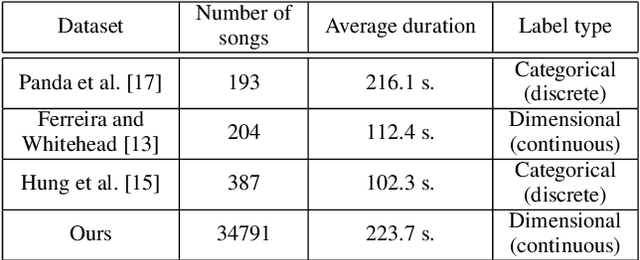
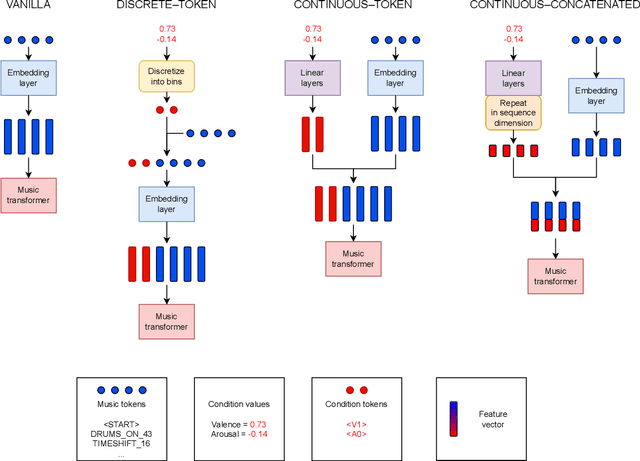
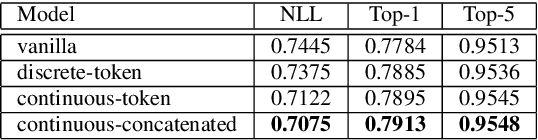
In this paper we present a new approach for the generation of multi-instrument symbolic music driven by musical emotion. The principal novelty of our approach centres on conditioning a state-of-the-art transformer based on continuous-valued valence and arousal labels. In addition, we provide a new large-scale dataset of symbolic music paired with emotion labels in terms of valence and arousal. We evaluate our approach in a quantitative manner in two ways, first by measuring its note prediction accuracy, and second via a regression task in the valence-arousal plane. Our results demonstrate that our proposed approaches outperform conditioning using control tokens which is representative of the current state of the art.
Music Generation Using an LSTM
Mar 23, 2022Over the past several years, deep learning for sequence modeling has grown in popularity. To achieve this goal, LSTM network structures have proven to be very useful for making predictions for the next output in a series. For instance, a smartphone predicting the next word of a text message could use an LSTM. We sought to demonstrate an approach of music generation using Recurrent Neural Networks (RNN). More specifically, a Long Short-Term Memory (LSTM) neural network. Generating music is a notoriously complicated task, whether handmade or generated, as there are a myriad of components involved. Taking this into account, we provide a brief synopsis of the intuition, theory, and application of LSTMs in music generation, develop and present the network we found to best achieve this goal, identify and address issues and challenges faced, and include potential future improvements for our network.
MR4MR: Mixed Reality for Melody Reincarnation
Sep 15, 2022


There is a long history of an effort made to explore musical elements with the entities and spaces around us, such as musique concr\`ete and ambient music. In the context of computer music and digital art, interactive experiences that concentrate on the surrounding objects and physical spaces have also been designed. In recent years, with the development and popularization of devices, an increasing number of works have been designed in Extended Reality to create such musical experiences. In this paper, we describe MR4MR, a sound installation work that allows users to experience melodies produced from interactions with their surrounding space in the context of Mixed Reality (MR). Using HoloLens, an MR head-mounted display, users can bump virtual objects that emit sound against real objects in their surroundings. Then, by continuously creating a melody following the sound made by the object and re-generating randomly and gradually changing melody using music generation machine learning models, users can feel their ambient melody "reincarnating".
Debiased Cross-modal Matching for Content-based Micro-video Background Music Recommendation
Aug 07, 2022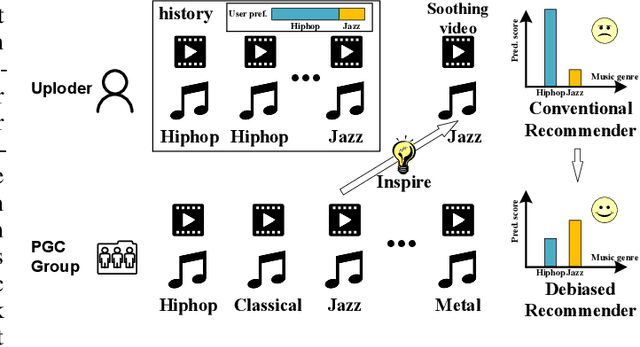
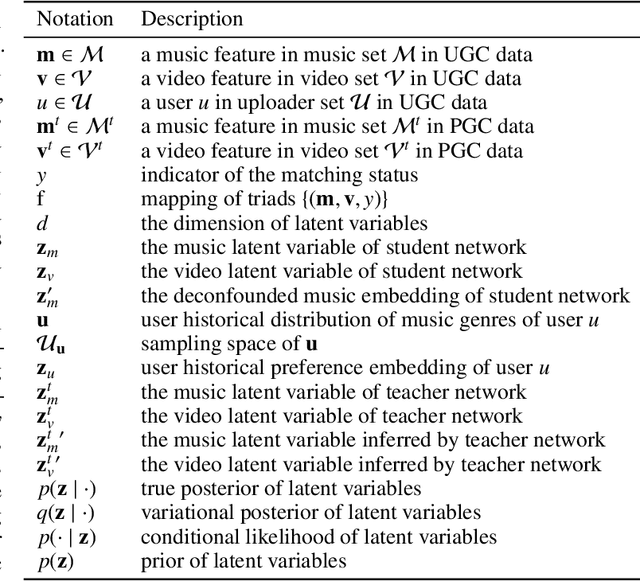
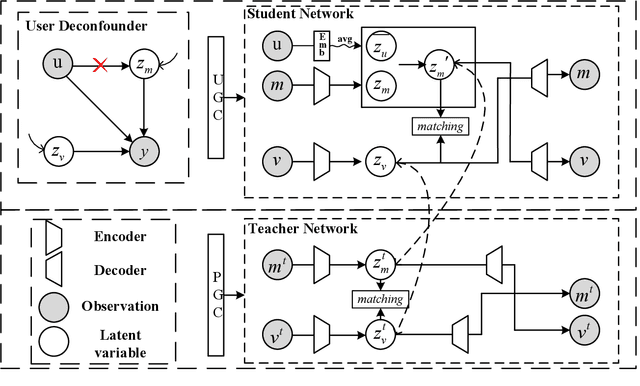

Micro-video background music recommendation is a complicated task where the matching degree between videos and uploader-selected background music is a major issue. However, the selection of the user-generated content (UGC) is biased caused by knowledge limitations and historical preferences among music of each uploader. In this paper, we propose a Debiased Cross-Modal (DebCM) matching model to alleviate the influence of such selection bias. Specifically, we design a teacher-student network to utilize the matching of segments of music videos, which is professional-generated content (PGC) with specialized music-matching techniques, to better alleviate the bias caused by insufficient knowledge of users. The PGC data is captured by a teacher network to guide the matching of uploader-selected UGC data of the student network by KL-based knowledge transfer. In addition, uploaders' personal preferences of music genres are identified as confounders that spuriously correlate music embeddings and background music selections, resulting in the learned recommender system to over-recommend music from the majority groups. To resolve such confounders in the UGC data of the student network, backdoor adjustment is utilized to deconfound the spurious correlation between music embeddings and prediction scores. We further utilize Monte Carlo (MC) estimator with batch-level average as the approximations to avoid integrating the entire confounder space calculated by the adjustment. Extensive experiments on the TT-150k-genre dataset demonstrate the effectiveness of the proposed method towards the selection bias. The code is publicly available on: \url{https://github.com/jing-1/DebCM}.
QuiKo: A Quantum Beat Generation Application
Apr 09, 2022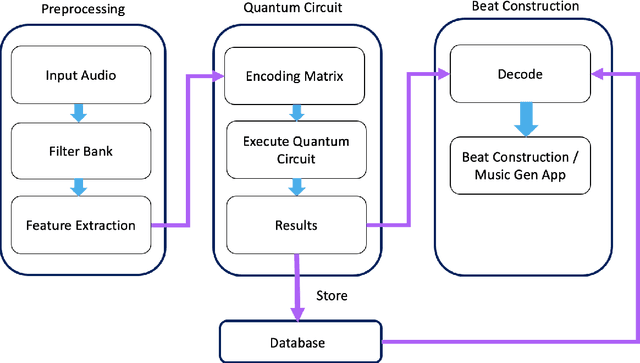
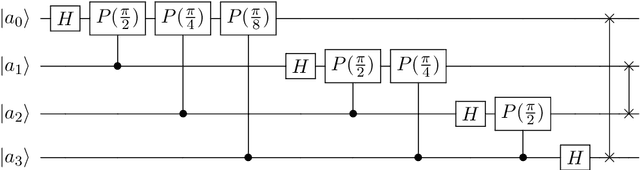
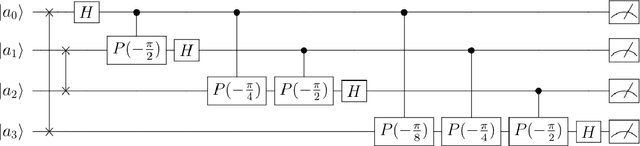
In this chapter a quantum music generation application called QuiKo will be discussed. It combines existing quantum algorithms with data encoding methods from quantum machine learning to build drum and audio sample patterns from a database of audio tracks. QuiKo leverages the physical properties and characteristics of quantum computers to generate what can be referred to as Soft Rules proposed by Alexis Kirke. These rules take advantage of the noise produced by quantum devices to develop flexible rules and grammars for quantum music generation. These properties include qubit decoherence and phase kickback due controlled quantum gates within the quantum circuit. QuiKo builds upon the concept of soft rules in quantum music generation and takes it a step further. It attempts to mimic and react to an external musical inputs, similar to the way that human musicians play and compose with one another. Audio signals are used as inputs into the system. Feature extraction is then performed on the signal to identify the harmonic and percussive elements. This information is then encoded onto the quantum circuit. Measurements of the quantum circuit are then taken providing results in the form of probability distributions for external music applications to use to build the new drum patterns.
Re-creation of Creations: A New Paradigm for Lyric-to-Melody Generation
Aug 18, 2022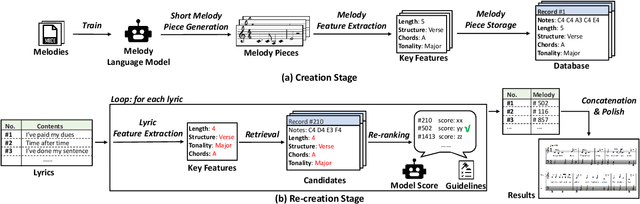
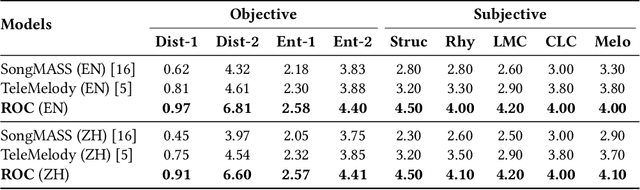
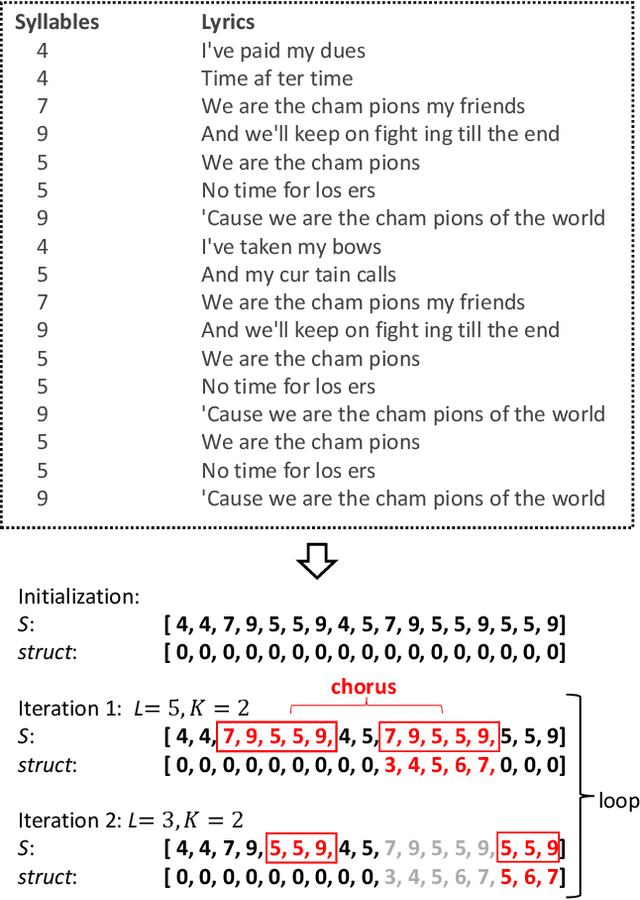
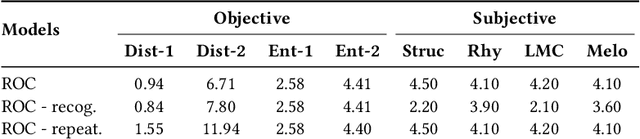
Lyric-to-melody generation is an important task in songwriting, and is also quite challenging due to its distinctive characteristics: the generated melodies should not only follow good musical patterns, but also align with features in lyrics such as rhythms and structures. These characteristics cannot be well handled by neural generation models that learn lyric-to-melody mapping in an end-to-end way, due to several issues: (1) lack of aligned lyric-melody training data to sufficiently learn lyric-melody feature alignment; (2) lack of controllability in generation to explicitly guarantee the lyric-melody feature alignment. In this paper, we propose Re-creation of Creations (ROC), a new paradigm for lyric-to-melody generation that addresses the above issues through a generation-retrieval pipeline. Specifically, our paradigm has two stages: (1) creation stage, where a huge amount of music pieces are generated by a neural-based melody language model and indexed in a database through several key features (e.g., chords, tonality, rhythm, and structural information including chorus or verse); (2) re-creation stage, where melodies are recreated by retrieving music pieces from the database according to the key features from lyrics and concatenating best music pieces based on composition guidelines and melody language model scores. Our new paradigm has several advantages: (1) It only needs unpaired melody data to train melody language model, instead of paired lyric-melody data in previous models. (2) It achieves good lyric-melody feature alignment in lyric-to-melody generation. Experiments on English and Chinese datasets demonstrate that ROC outperforms previous neural based lyric-to-melody generation models on both objective and subjective metrics.
MusIAC: An extensible generative framework for Music Infilling Applications with multi-level Control
Feb 11, 2022
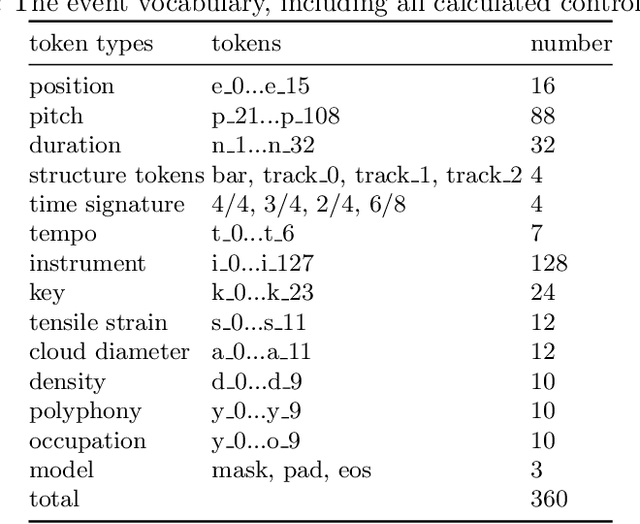


We present a novel music generation framework for music infilling, with a user friendly interface. Infilling refers to the task of generating musical sections given the surrounding multi-track music. The proposed transformer-based framework is extensible for new control tokens as the added music control tokens such as tonal tension per bar and track polyphony level in this work. We explore the effects of including several musically meaningful control tokens, and evaluate the results using objective metrics related to pitch and rhythm. Our results demonstrate that adding additional control tokens helps to generate music with stronger stylistic similarities to the original music. It also provides the user with more control to change properties like the music texture and tonal tension in each bar compared to previous research which only provided control for track density. We present the model in a Google Colab notebook to enable interactive generation.