 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music generation": models, code, and papers
Unsupervised Source Separation By Steering Pretrained Music Models
Oct 25, 2021
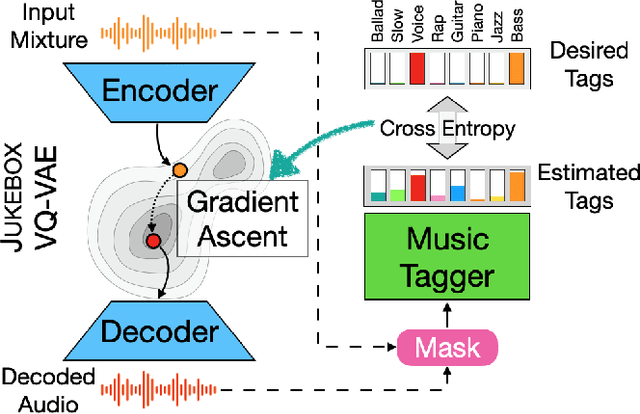
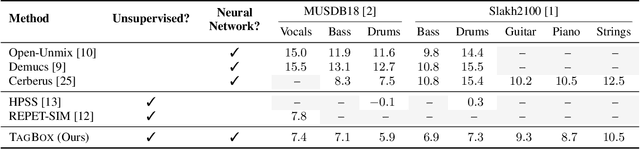
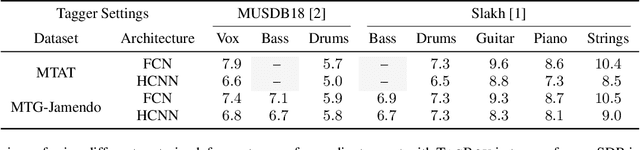
We showcase an unsupervised method that repurposes deep models trained for music generation and music tagging for audio source separation, without any retraining. An audio generation model is conditioned on an input mixture, producing a latent encoding of the audio used to generate audio. This generated audio is fed to a pretrained music tagger that creates source labels. The cross-entropy loss between the tag distribution for the generated audio and a predefined distribution for an isolated source is used to guide gradient ascent in the (unchanging) latent space of the generative model. This system does not update the weights of the generative model or the tagger, and only relies on moving through the generative model's latent space to produce separated sources. We use OpenAI's Jukebox as the pretrained generative model, and we couple it with four kinds of pretrained music taggers (two architectures and two tagging datasets). Experimental results on two source separation datasets, show this approach can produce separation estimates for a wider variety of sources than any tested supervised or unsupervised system. This work points to the vast and heretofore untapped potential of large pretrained music models for audio-to-audio tasks like source separation.
It's Raw! Audio Generation with State-Space Models
Feb 20, 2022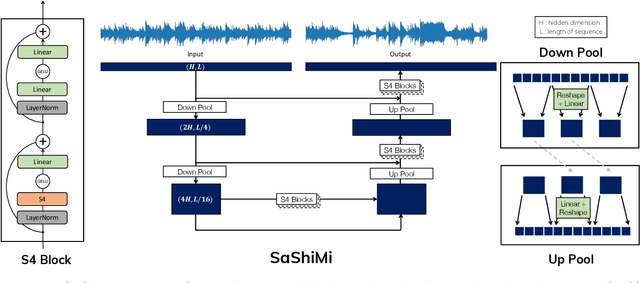

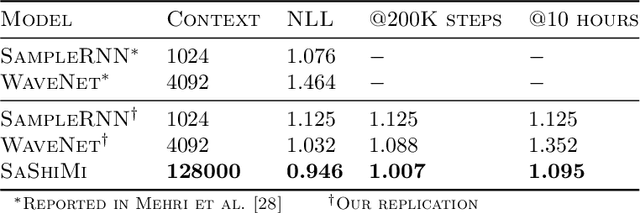
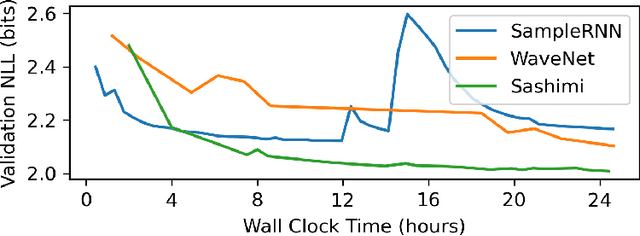
Developing architectures suitable for modeling raw audio is a challenging problem due to the high sampling rates of audio waveforms. Standard sequence modeling approaches like RNNs and CNNs have previously been tailored to fit the demands of audio, but the resultant architectures make undesirable computational tradeoffs and struggle to model waveforms effectively. We propose SaShiMi, a new multi-scale architecture for waveform modeling built around the recently introduced S4 model for long sequence modeling. We identify that S4 can be unstable during autoregressive generation, and provide a simple improvement to its parameterization by drawing connections to Hurwitz matrices. SaShiMi yields state-of-the-art performance for unconditional waveform generation in the autoregressive setting. Additionally, SaShiMi improves non-autoregressive generation performance when used as the backbone architecture for a diffusion model. Compared to prior architectures in the autoregressive generation setting, SaShiMi generates piano and speech waveforms which humans find more musical and coherent respectively, e.g. 2x better mean opinion scores than WaveNet on an unconditional speech generation task. On a music generation task, SaShiMi outperforms WaveNet on density estimation and speed at both training and inference even when using 3x fewer parameters. Code can be found at https://github.com/HazyResearch/state-spaces and samples at https://hazyresearch.stanford.edu/sashimi-examples.
Bach Style Music Authoring System based on Deep Learning
Oct 06, 2021

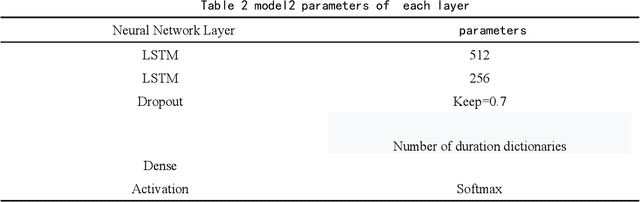
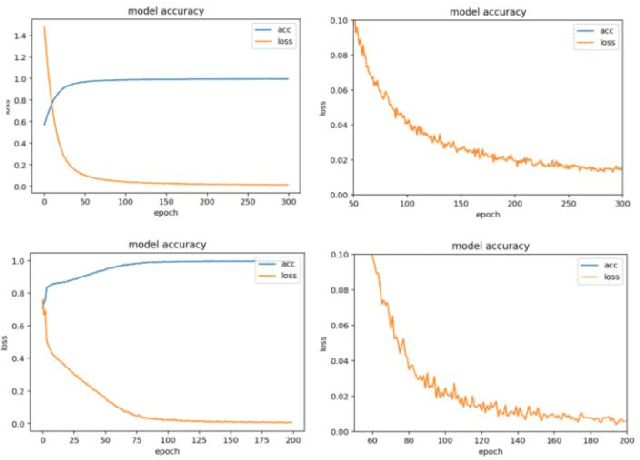
With the continuous improvement in various aspects in the field of artificial intelligence, the momentum of artificial intelligence with deep learning capabilities into the field of music is coming. The research purpose of this paper is to design a Bach style music authoring system based on deep learning. We use a LSTM neural network to train serialized and standardized music feature data. By repeated experiments, we find the optimal LSTM model which can generate imitation of Bach music. Finally the generated music is comprehensively evaluated in the form of online audition and Turing test. The repertoires which the music generation system constructed in this article are very close to the style of Bach's original music, and it is relatively difficult for ordinary people to distinguish the musics Bach authored and AI created.
Multi-Instrumentalist Net: Unsupervised Generation of Music from Body Movements
Dec 07, 2020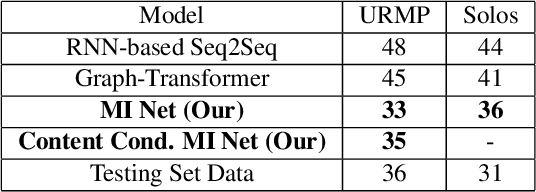
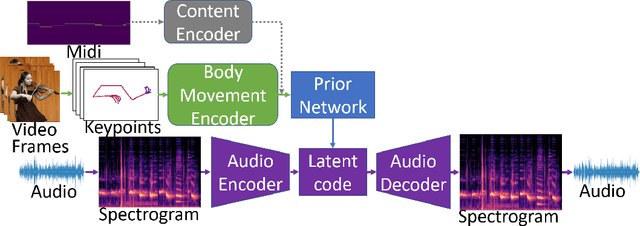
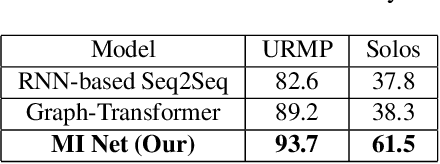

We propose a novel system that takes as an input body movements of a musician playing a musical instrument and generates music in an unsupervised setting. Learning to generate multi-instrumental music from videos without labeling the instruments is a challenging problem. To achieve the transformation, we built a pipeline named 'Multi-instrumentalistNet' (MI Net). At its base, the pipeline learns a discrete latent representation of various instruments music from log-spectrogram using a Vector Quantized Variational Autoencoder (VQ-VAE) with multi-band residual blocks. The pipeline is then trained along with an autoregressive prior conditioned on the musician's body keypoints movements encoded by a recurrent neural network. Joint training of the prior with the body movements encoder succeeds in the disentanglement of the music into latent features indicating the musical components and the instrumental features. The latent space results in distributions that are clustered into distinct instruments from which new music can be generated. Furthermore, the VQ-VAE architecture supports detailed music generation with additional conditioning. We show that a Midi can further condition the latent space such that the pipeline will generate the exact content of the music being played by the instrument in the video. We evaluate MI Net on two datasets containing videos of 13 instruments and obtain generated music of reasonable audio quality, easily associated with the corresponding instrument, and consistent with the music audio content.
High-Level Control of Drum Track Generation Using Learned Patterns of Rhythmic Interaction
Aug 02, 2019


Spurred by the potential of deep learning, computational music generation has gained renewed academic interest. A crucial issue in music generation is that of user control, especially in scenarios where the music generation process is conditioned on existing musical material. Here we propose a model for conditional kick drum track generation that takes existing musical material as input, in addition to a low-dimensional code that encodes the desired relation between the existing material and the new material to be generated. These relational codes are learned in an unsupervised manner from a music dataset. We show that codes can be sampled to create a variety of musically plausible kick drum tracks and that the model can be used to transfer kick drum patterns from one song to another. Lastly, we demonstrate that the learned codes are largely invariant to tempo and time-shift.
Flat latent manifolds for music improvisation between human and machine
Feb 23, 2022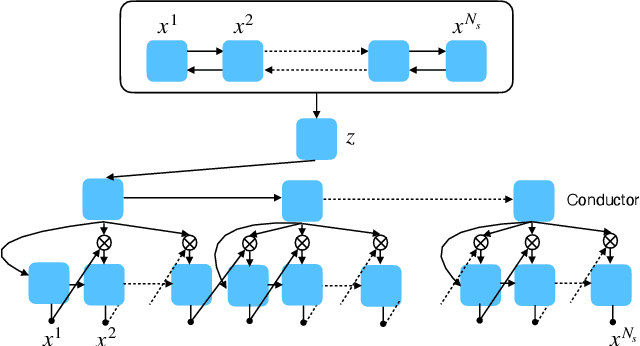
The use of machine learning in artistic music generation leads to controversial discussions of the quality of art, for which objective quantification is nonsensical. We therefore consider a music-generating algorithm as a counterpart to a human musician, in a setting where reciprocal improvisation is to lead to new experiences, both for the musician and the audience. To obtain this behaviour, we resort to the framework of recurrent Variational Auto-Encoders (VAE) and learn to generate music, seeded by a human musician. In the learned model, we generate novel musical sequences by interpolation in latent space. Standard VAEs however do not guarantee any form of smoothness in their latent representation. This translates into abrupt changes in the generated music sequences. To overcome these limitations, we regularise the decoder and endow the latent space with a flat Riemannian manifold, i.e., a manifold that is isometric to the Euclidean space. As a result, linearly interpolating in the latent space yields realistic and smooth musical changes that fit the type of machine--musician interactions we aim for. We provide empirical evidence for our method via a set of experiments on music datasets and we deploy our model for an interactive jam session with a professional drummer. The live performance provides qualitative evidence that the latent representation can be intuitively interpreted and exploited by the drummer to drive the interplay. Beyond the musical application, our approach showcases an instance of human-centred design of machine-learning models, driven by interpretability and the interaction with the end user.
A Survey on Audio Synthesis and Audio-Visual Multimodal Processing
Aug 01, 2021
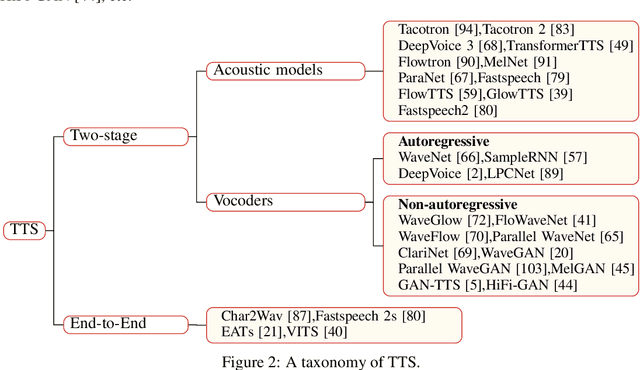
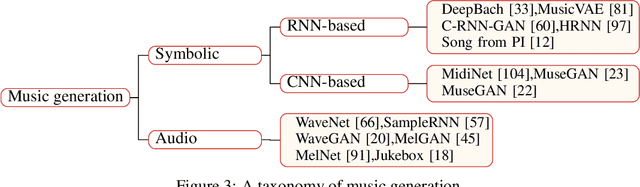
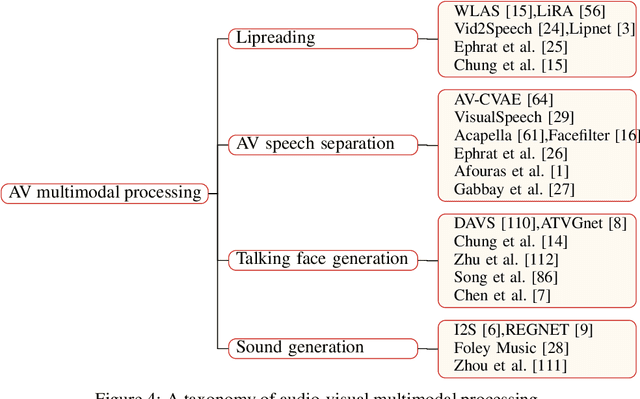
With the development of deep learning and artificial intelligence, audio synthesis has a pivotal role in the area of machine learning and shows strong applicability in the industry. Meanwhile, significant efforts have been dedicated by researchers to handle multimodal tasks at present such as audio-visual multimodal processing. In this paper, we conduct a survey on audio synthesis and audio-visual multimodal processing, which helps understand current research and future trends. This review focuses on text to speech(TTS), music generation and some tasks that combine visual and acoustic information. The corresponding technical methods are comprehensively classified and introduced, and their future development trends are prospected. This survey can provide some guidance for researchers who are interested in the areas like audio synthesis and audio-visual multimodal processing.
Music Composition with Deep Learning: A Review
Sep 07, 2021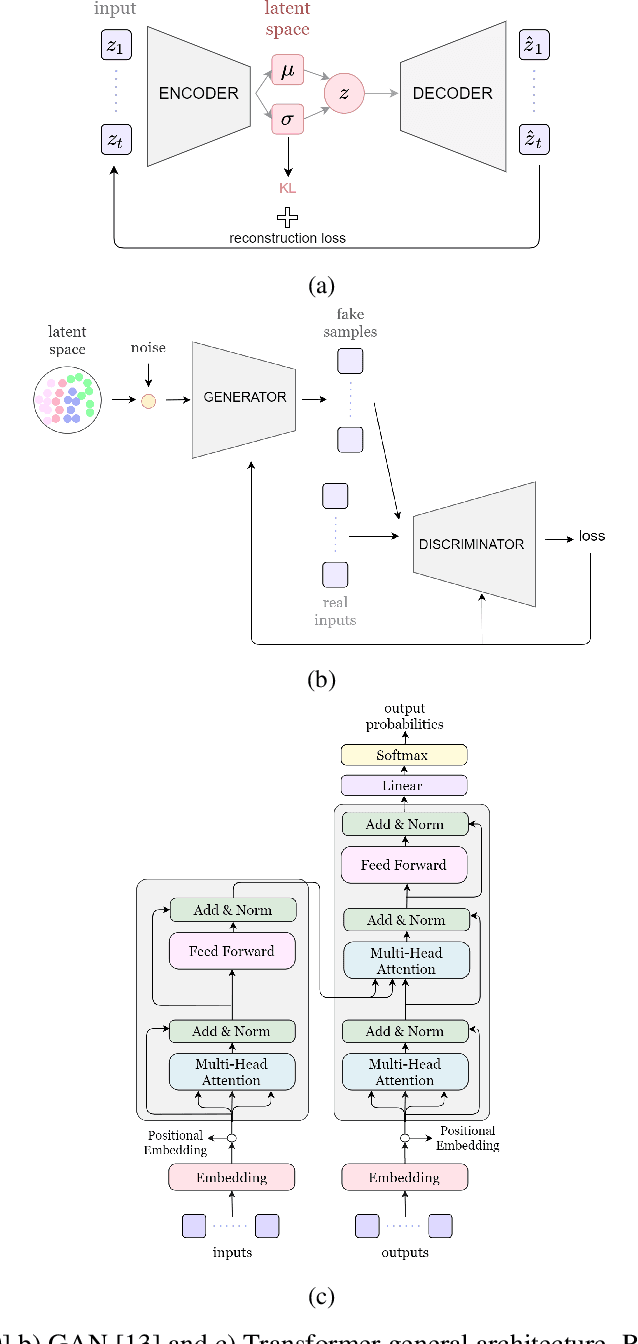
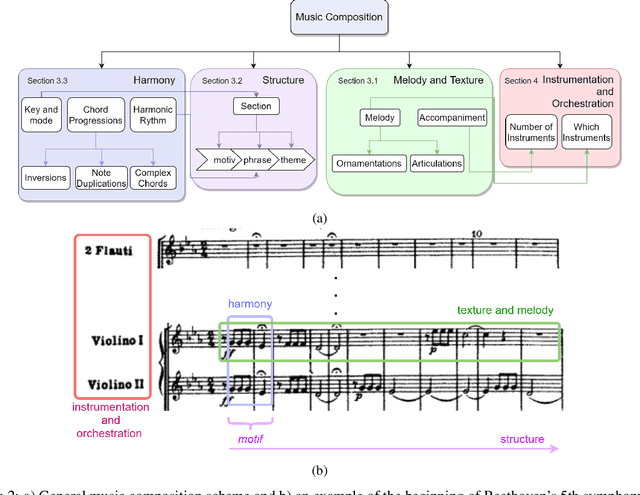
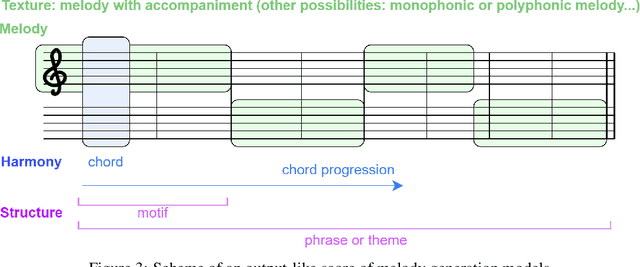
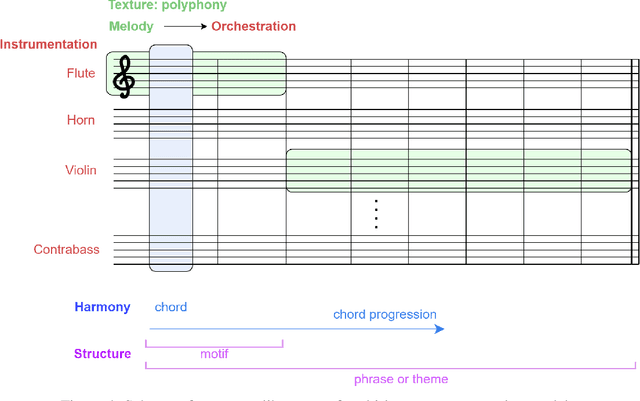
Generating a complex work of art such as a musical composition requires exhibiting true creativity that depends on a variety of factors that are related to the hierarchy of musical language. Music generation have been faced with Algorithmic methods and recently, with Deep Learning models that are being used in other fields such as Computer Vision. In this paper we want to put into context the existing relationships between AI-based music composition models and human musical composition and creativity processes. We give an overview of the recent Deep Learning models for music composition and we compare these models to the music composition process from a theoretical point of view. We have tried to answer some of the most relevant open questions for this task by analyzing the ability of current Deep Learning models to generate music with creativity or the similarity between AI and human composition processes, among others.
A Benchmarking Initiative for Audio-Domain Music Generation Using the Freesound Loop Dataset
Aug 03, 2021
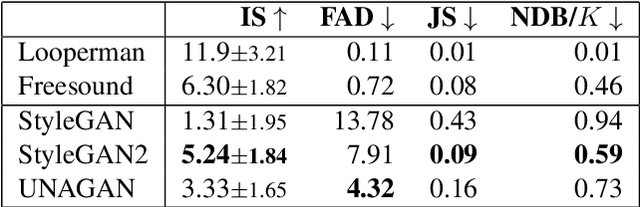
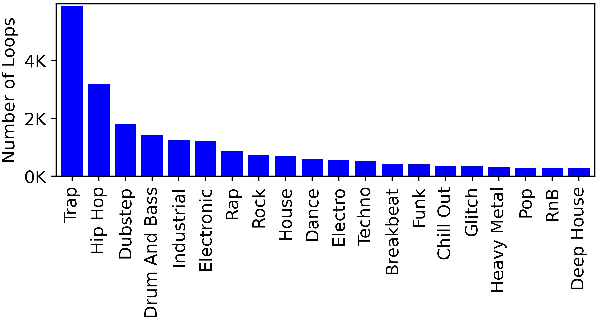

This paper proposes a new benchmark task for generat-ing musical passages in the audio domain by using thedrum loops from the FreeSound Loop Dataset, which arepublicly re-distributable. Moreover, we use a larger col-lection of drum loops from Looperman to establish fourmodel-based objective metrics for evaluation, releasingthese metrics as a library for quantifying and facilitatingthe progress of musical audio generation. Under this eval-uation framework, we benchmark the performance of threerecent deep generative adversarial network (GAN) mod-els we customize to generate loops, including StyleGAN,StyleGAN2, and UNAGAN. We also report a subjectiveevaluation of these models. Our evaluation shows that theone based on StyleGAN2 performs the best in both objec-tive and subjective metrics.