 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music generation": models, code, and papers
MIDI-Sandwich: Multi-model Multi-task Hierarchical Conditional VAE-GAN networks for Symbolic Single-track Music Generation
Jul 04, 2019
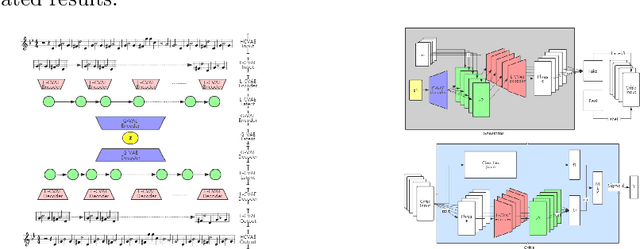
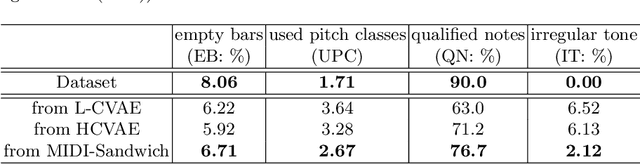
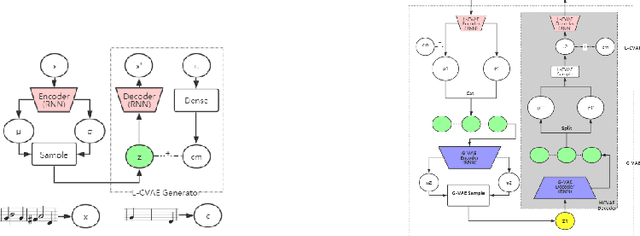
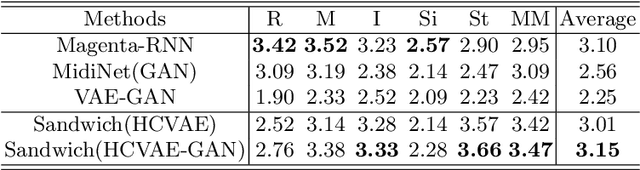
Most existing neural network models for music generation explore how to generate music bars, then directly splice the music bars into a song. However, these methods do not explore the relationship between the bars, and the connected song as a whole has no musical form structure and sense of musical direction. To address this issue, we propose a Multi-model Multi-task Hierarchical Conditional VAE-GAN (Variational Autoencoder-Generative adversarial networks) networks, named MIDI-Sandwich, which combines musical knowledge, such as musical form, tonic, and melodic motion. The MIDI-Sandwich has two submodels: Hierarchical Conditional Variational Autoencoder (HCVAE) and Hierarchical Conditional Generative Adversarial Network (HCGAN). The HCVAE uses hierarchical structure. The underlying layer of HCVAE uses Local Conditional Variational Autoencoder (L-CVAE) to generate a music bar which is pre-specified by the First and Last Notes (FLN). The upper layer of HCVAE uses Global Variational Autoencoder(G-VAE) to analyze the latent vector sequence generated by the L-CVAE encoder, to explore the musical relationship between the bars, and to produce the song pieced together by multiple music bars generated by the L-CVAE decoder, which makes the song both have musical structure and sense of direction. At the same time, the HCVAE shares a part of itself with the HCGAN to further improve the performance of the generated music. The MIDI-Sandwich is validated on the Nottingham dataset and is able to generate a single-track melody sequence (17x8 beats), which is superior to the length of most of the generated models (8 to 32 beats). Meanwhile, by referring to the experimental methods of many classical kinds of literature, the quality evaluation of the generated music is performed. The above experiments prove the validity of the model.
MELONS: generating melody with long-term structure using transformers and structure graph
Nov 03, 2021

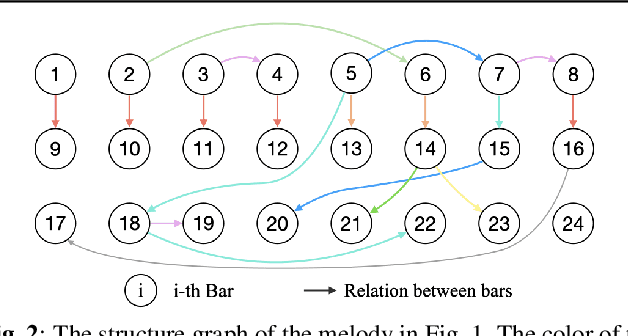
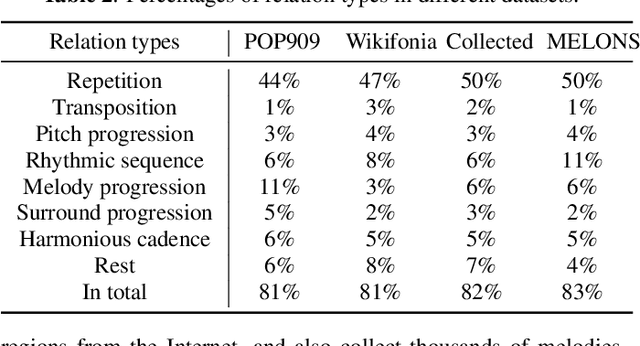
The creation of long melody sequences requires effective expression of coherent musical structure. However, there is no clear representation of musical structure. Recent works on music generation have suggested various approaches to deal with the structural information of music, but generating a full-song melody with clear long-term structure remains a challenge. In this paper, we propose MELONS, a melody generation framework based on a graph representation of music structure which consists of eight types of bar-level relations. MELONS adopts a multi-step generation method with transformer-based networks by factoring melody generation into two sub-problems: structure generation and structure conditional melody generation. Experimental results show that MELONS can produce structured melodies with high quality and rich contents.
EmotionBox: a music-element-driven emotional music generation system using Recurrent Neural Network
Dec 16, 2021
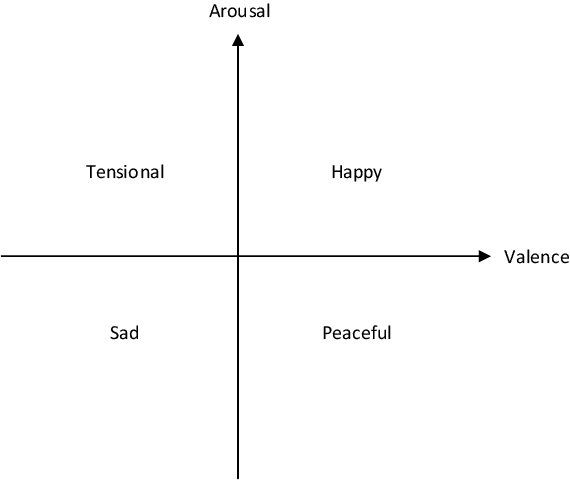
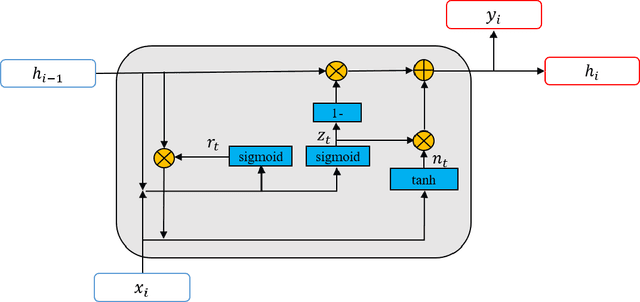
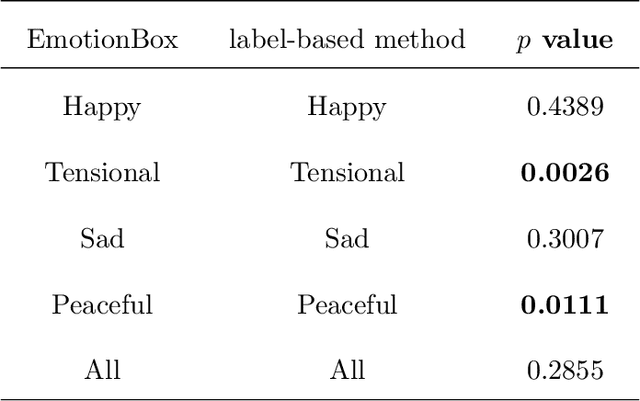
With the development of deep neural networks, automatic music composition has made great progress. Although emotional music can evoke listeners' different emotions and it is important for artistic expression, only few researches have focused on generating emotional music. This paper presents EmotionBox -an music-element-driven emotional music generator that is capable of composing music given a specific emotion, where this model does not require a music dataset labeled with emotions. Instead, pitch histogram and note density are extracted as features that represent mode and tempo respectively to control music emotions. The subjective listening tests show that the Emotionbox has a more competitive and balanced performance in arousing a specified emotion than the emotion-label-based method.
Is Disentanglement enough? On Latent Representations for Controllable Music Generation
Aug 01, 2021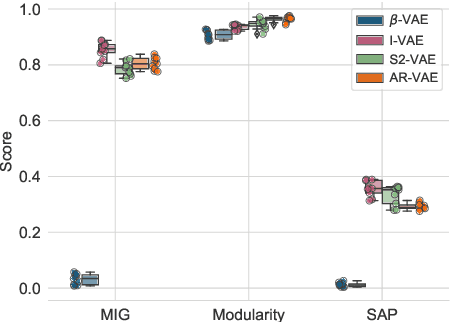
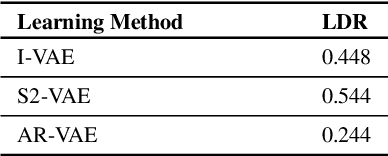
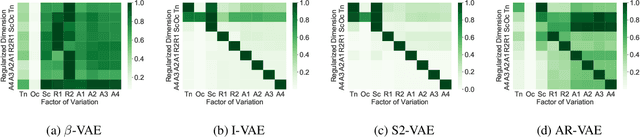
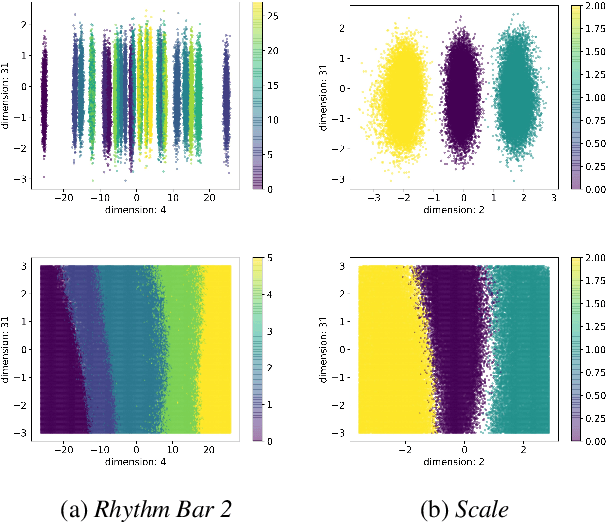
Improving controllability or the ability to manipulate one or more attributes of the generated data has become a topic of interest in the context of deep generative models of music. Recent attempts in this direction have relied on learning disentangled representations from data such that the underlying factors of variation are well separated. In this paper, we focus on the relationship between disentanglement and controllability by conducting a systematic study using different supervised disentanglement learning algorithms based on the Variational Auto-Encoder (VAE) architecture. Our experiments show that a high degree of disentanglement can be achieved by using different forms of supervision to train a strong discriminative encoder. However, in the absence of a strong generative decoder, disentanglement does not necessarily imply controllability. The structure of the latent space with respect to the VAE-decoder plays an important role in boosting the ability of a generative model to manipulate different attributes. To this end, we also propose methods and metrics to help evaluate the quality of a latent space with respect to the afforded degree of controllability.
Unsupervised Source Separation By Steering Pretrained Music Models
Oct 25, 2021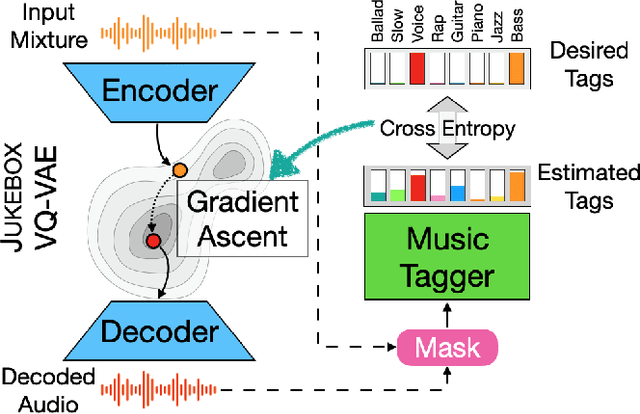
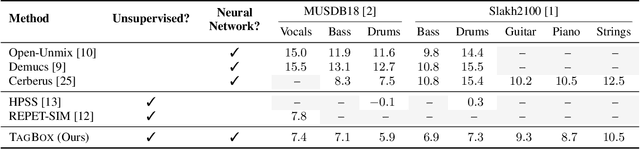
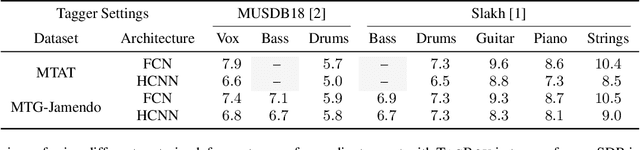
We showcase an unsupervised method that repurposes deep models trained for music generation and music tagging for audio source separation, without any retraining. An audio generation model is conditioned on an input mixture, producing a latent encoding of the audio used to generate audio. This generated audio is fed to a pretrained music tagger that creates source labels. The cross-entropy loss between the tag distribution for the generated audio and a predefined distribution for an isolated source is used to guide gradient ascent in the (unchanging) latent space of the generative model. This system does not update the weights of the generative model or the tagger, and only relies on moving through the generative model's latent space to produce separated sources. We use OpenAI's Jukebox as the pretrained generative model, and we couple it with four kinds of pretrained music taggers (two architectures and two tagging datasets). Experimental results on two source separation datasets, show this approach can produce separation estimates for a wider variety of sources than any tested supervised or unsupervised system. This work points to the vast and heretofore untapped potential of large pretrained music models for audio-to-audio tasks like source separation.
It's Raw! Audio Generation with State-Space Models
Feb 20, 2022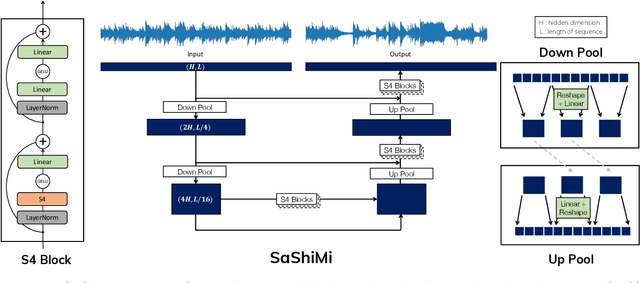

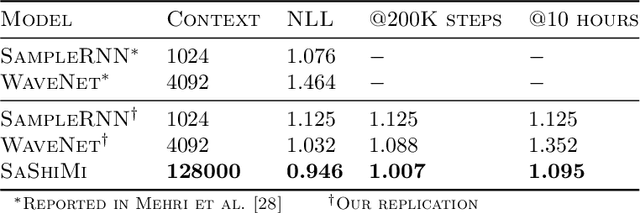
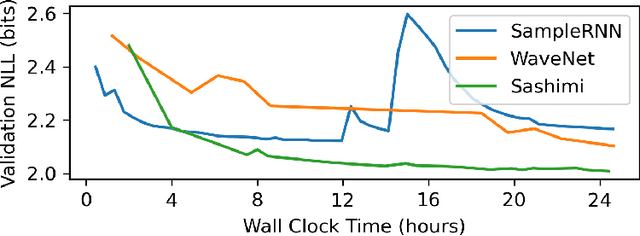
Developing architectures suitable for modeling raw audio is a challenging problem due to the high sampling rates of audio waveforms. Standard sequence modeling approaches like RNNs and CNNs have previously been tailored to fit the demands of audio, but the resultant architectures make undesirable computational tradeoffs and struggle to model waveforms effectively. We propose SaShiMi, a new multi-scale architecture for waveform modeling built around the recently introduced S4 model for long sequence modeling. We identify that S4 can be unstable during autoregressive generation, and provide a simple improvement to its parameterization by drawing connections to Hurwitz matrices. SaShiMi yields state-of-the-art performance for unconditional waveform generation in the autoregressive setting. Additionally, SaShiMi improves non-autoregressive generation performance when used as the backbone architecture for a diffusion model. Compared to prior architectures in the autoregressive generation setting, SaShiMi generates piano and speech waveforms which humans find more musical and coherent respectively, e.g. 2x better mean opinion scores than WaveNet on an unconditional speech generation task. On a music generation task, SaShiMi outperforms WaveNet on density estimation and speed at both training and inference even when using 3x fewer parameters. Code can be found at https://github.com/HazyResearch/state-spaces and samples at https://hazyresearch.stanford.edu/sashimi-examples.
Bach Style Music Authoring System based on Deep Learning
Oct 06, 2021

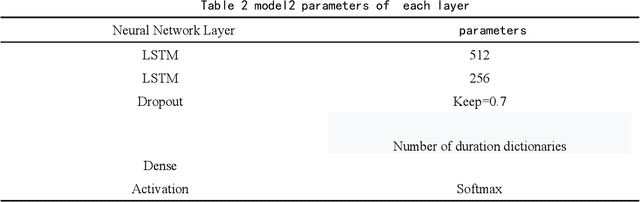
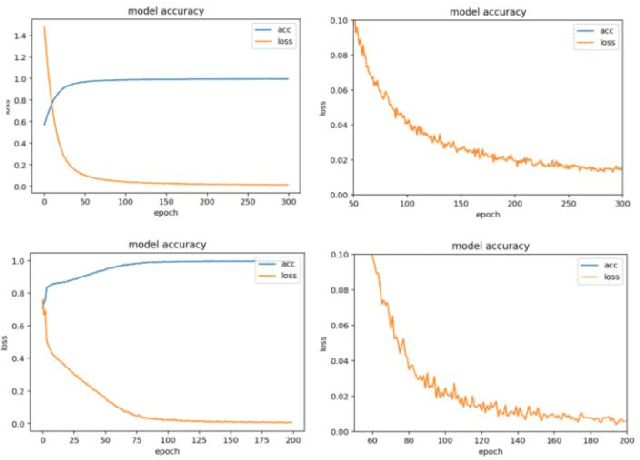
With the continuous improvement in various aspects in the field of artificial intelligence, the momentum of artificial intelligence with deep learning capabilities into the field of music is coming. The research purpose of this paper is to design a Bach style music authoring system based on deep learning. We use a LSTM neural network to train serialized and standardized music feature data. By repeated experiments, we find the optimal LSTM model which can generate imitation of Bach music. Finally the generated music is comprehensively evaluated in the form of online audition and Turing test. The repertoires which the music generation system constructed in this article are very close to the style of Bach's original music, and it is relatively difficult for ordinary people to distinguish the musics Bach authored and AI created.
Multi-Instrumentalist Net: Unsupervised Generation of Music from Body Movements
Dec 07, 2020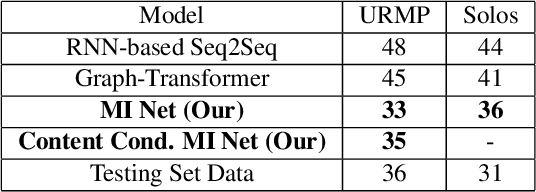
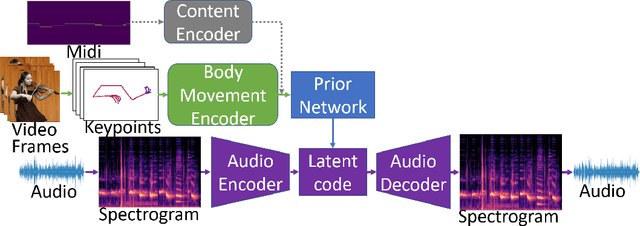
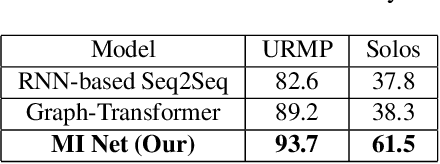

We propose a novel system that takes as an input body movements of a musician playing a musical instrument and generates music in an unsupervised setting. Learning to generate multi-instrumental music from videos without labeling the instruments is a challenging problem. To achieve the transformation, we built a pipeline named 'Multi-instrumentalistNet' (MI Net). At its base, the pipeline learns a discrete latent representation of various instruments music from log-spectrogram using a Vector Quantized Variational Autoencoder (VQ-VAE) with multi-band residual blocks. The pipeline is then trained along with an autoregressive prior conditioned on the musician's body keypoints movements encoded by a recurrent neural network. Joint training of the prior with the body movements encoder succeeds in the disentanglement of the music into latent features indicating the musical components and the instrumental features. The latent space results in distributions that are clustered into distinct instruments from which new music can be generated. Furthermore, the VQ-VAE architecture supports detailed music generation with additional conditioning. We show that a Midi can further condition the latent space such that the pipeline will generate the exact content of the music being played by the instrument in the video. We evaluate MI Net on two datasets containing videos of 13 instruments and obtain generated music of reasonable audio quality, easily associated with the corresponding instrument, and consistent with the music audio content.