 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music generation": models, code, and papers
Interactive Music Generation with Positional Constraints using Anticipation-RNNs
Sep 19, 2017
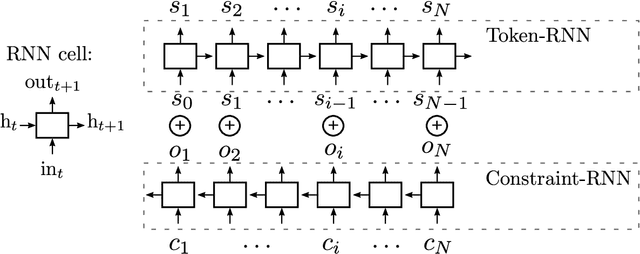

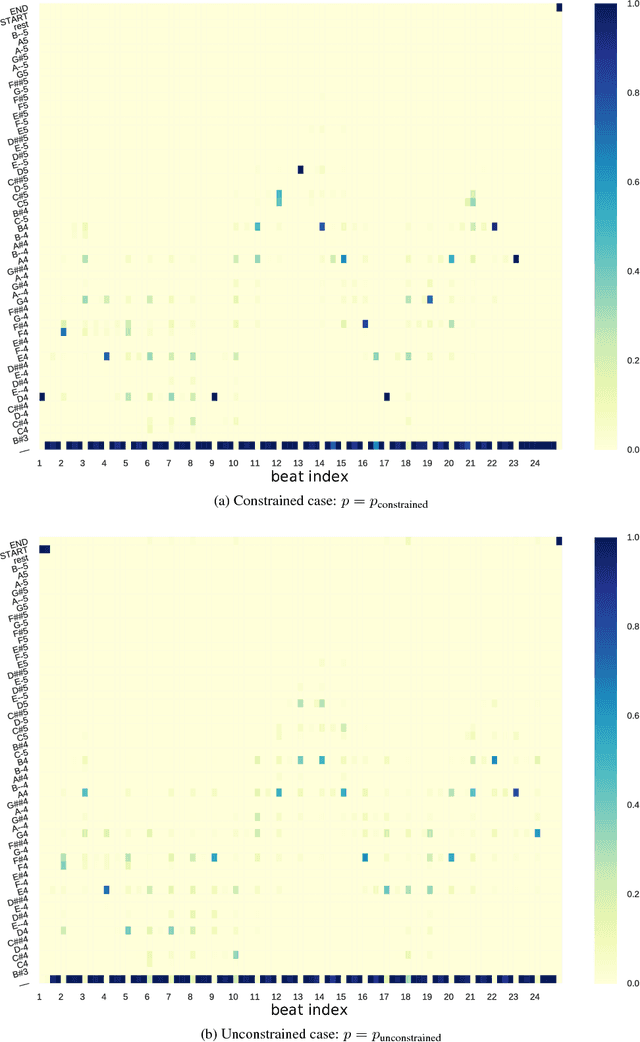
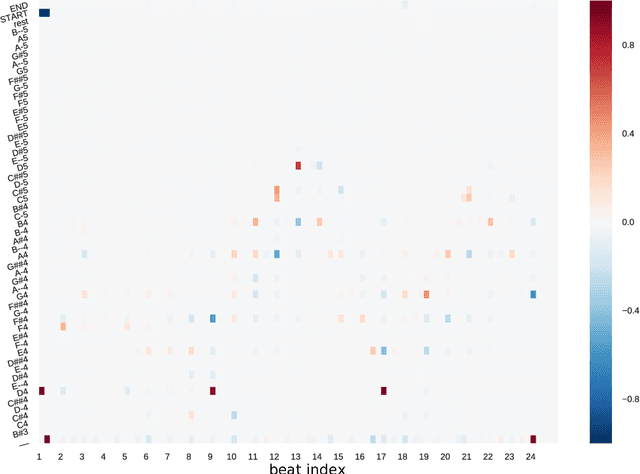
Recurrent Neural Networks (RNNS) are now widely used on sequence generation tasks due to their ability to learn long-range dependencies and to generate sequences of arbitrary length. However, their left-to-right generation procedure only allows a limited control from a potential user which makes them unsuitable for interactive and creative usages such as interactive music generation. This paper introduces a novel architecture called Anticipation-RNN which possesses the assets of the RNN-based generative models while allowing to enforce user-defined positional constraints. We demonstrate its efficiency on the task of generating melodies satisfying positional constraints in the style of the soprano parts of the J.S. Bach chorale harmonizations. Sampling using the Anticipation-RNN is of the same order of complexity than sampling from the traditional RNN model. This fast and interactive generation of musical sequences opens ways to devise real-time systems that could be used for creative purposes.
PopMAG: Pop Music Accompaniment Generation
Aug 18, 2020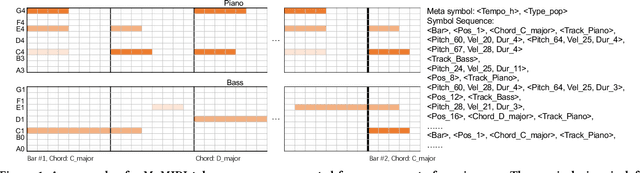

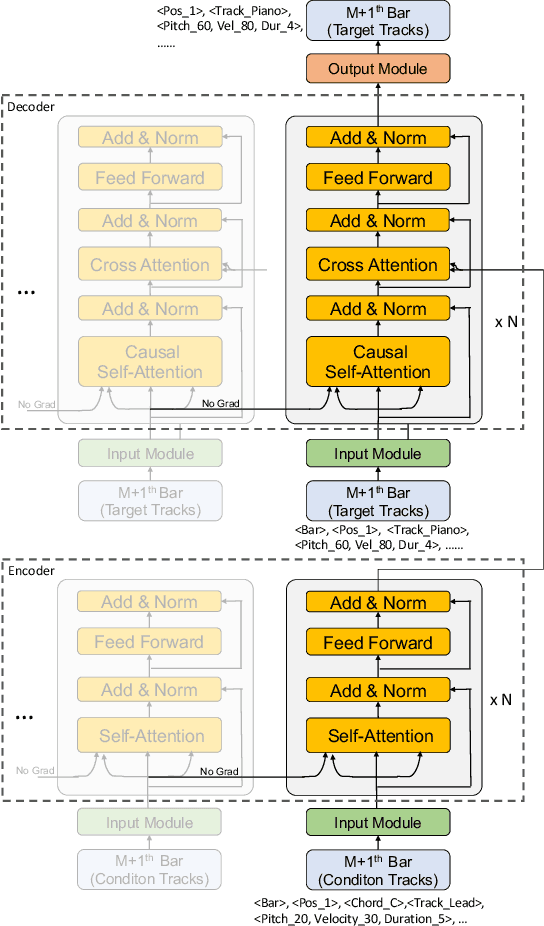
In pop music, accompaniments are usually played by multiple instruments (tracks) such as drum, bass, string and guitar, and can make a song more expressive and contagious by arranging together with its melody. Previous works usually generate multiple tracks separately and the music notes from different tracks not explicitly depend on each other, which hurts the harmony modeling. To improve harmony, in this paper, we propose a novel MUlti-track MIDI representation (MuMIDI), which enables simultaneous multi-track generation in a single sequence and explicitly models the dependency of the notes from different tracks. While this greatly improves harmony, unfortunately, it enlarges the sequence length and brings the new challenge of long-term music modeling. We further introduce two new techniques to address this challenge: 1) We model multiple note attributes (e.g., pitch, duration, velocity) of a musical note in one step instead of multiple steps, which can shorten the length of a MuMIDI sequence. 2) We introduce extra long-context as memory to capture long-term dependency in music. We call our system for pop music accompaniment generation as PopMAG. We evaluate PopMAG on multiple datasets (LMD, FreeMidi and CPMD, a private dataset of Chinese pop songs) with both subjective and objective metrics. The results demonstrate the effectiveness of PopMAG for multi-track harmony modeling and long-term context modeling. Specifically, PopMAG wins 42\%/38\%/40\% votes when comparing with ground truth musical pieces on LMD, FreeMidi and CPMD datasets respectively and largely outperforms other state-of-the-art music accompaniment generation models and multi-track MIDI representations in terms of subjective and objective metrics.
The challenge of realistic music generation: modelling raw audio at scale
Jun 26, 2018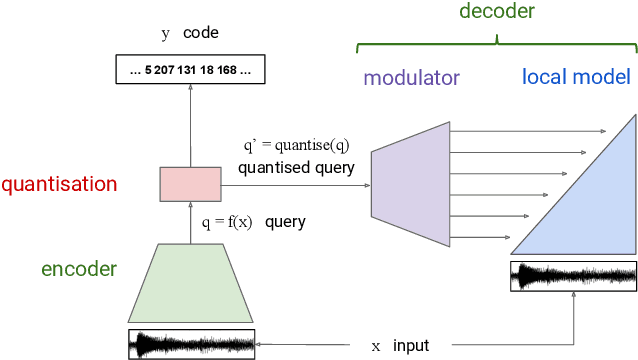
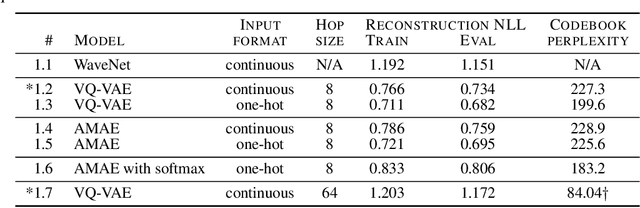
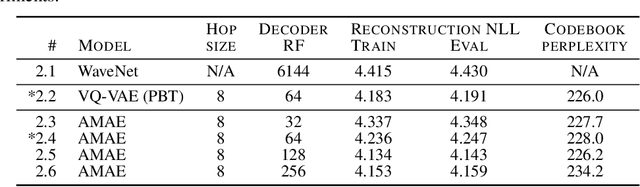
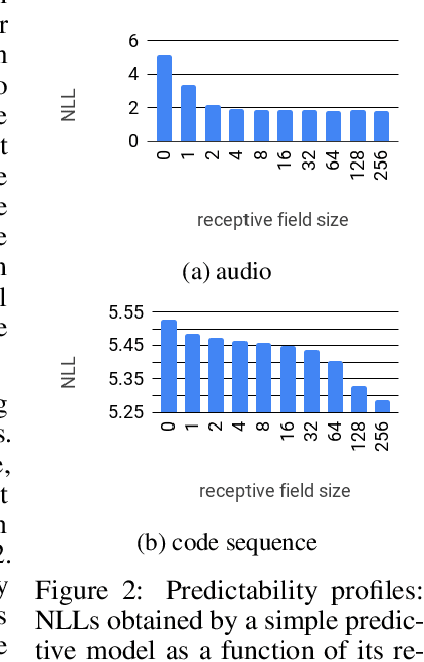
Realistic music generation is a challenging task. When building generative models of music that are learnt from data, typically high-level representations such as scores or MIDI are used that abstract away the idiosyncrasies of a particular performance. But these nuances are very important for our perception of musicality and realism, so in this work we embark on modelling music in the raw audio domain. It has been shown that autoregressive models excel at generating raw audio waveforms of speech, but when applied to music, we find them biased towards capturing local signal structure at the expense of modelling long-range correlations. This is problematic because music exhibits structure at many different timescales. In this work, we explore autoregressive discrete autoencoders (ADAs) as a means to enable autoregressive models to capture long-range correlations in waveforms. We find that they allow us to unconditionally generate piano music directly in the raw audio domain, which shows stylistic consistency across tens of seconds.
A Classifying Variational Autoencoder with Application to Polyphonic Music Generation
Nov 19, 2017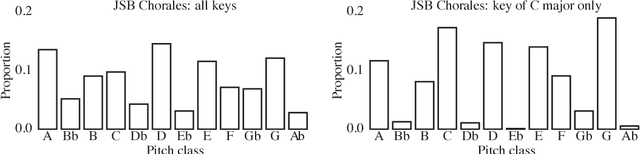
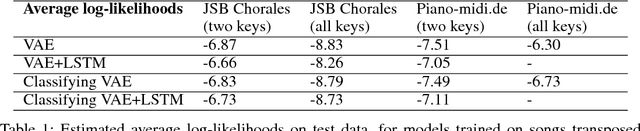
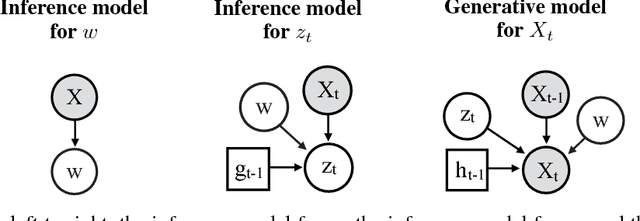
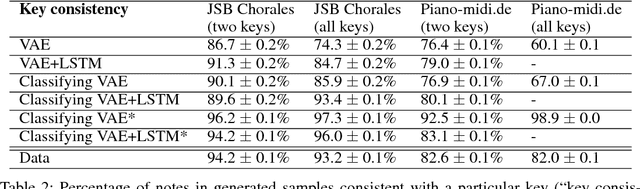
The variational autoencoder (VAE) is a popular probabilistic generative model. However, one shortcoming of VAEs is that the latent variables cannot be discrete, which makes it difficult to generate data from different modes of a distribution. Here, we propose an extension of the VAE framework that incorporates a classifier to infer the discrete class of the modeled data. To model sequential data, we can combine our Classifying VAE with a recurrent neural network such as an LSTM. We apply this model to algorithmic music generation, where our model learns to generate musical sequences in different keys. Most previous work in this area avoids modeling key by transposing data into only one or two keys, as opposed to the 10+ different keys in the original music. We show that our Classifying VAE and Classifying VAE+LSTM models outperform the corresponding non-classifying models in generating musical samples that stay in key. This benefit is especially apparent when trained on untransposed music data in the original keys.
Regeneration Learning: A Learning Paradigm for Data Generation
Jan 21, 2023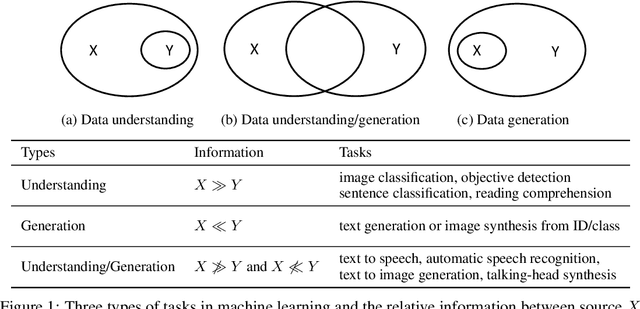
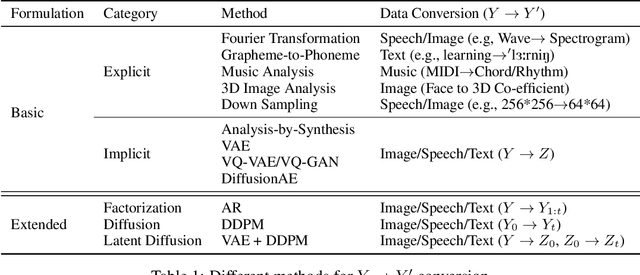


Machine learning methods for conditional data generation usually build a mapping from source conditional data X to target data Y. The target Y (e.g., text, speech, music, image, video) is usually high-dimensional and complex, and contains information that does not exist in source data, which hinders effective and efficient learning on the source-target mapping. In this paper, we present a learning paradigm called regeneration learning for data generation, which first generates Y' (an abstraction/representation of Y) from X and then generates Y from Y'. During training, Y' is obtained from Y through either handcrafted rules or self-supervised learning and is used to learn X-->Y' and Y'-->Y. Regeneration learning extends the concept of representation learning to data generation tasks, and can be regarded as a counterpart of traditional representation learning, since 1) regeneration learning handles the abstraction (Y') of the target data Y for data generation while traditional representation learning handles the abstraction (X') of source data X for data understanding; 2) both the processes of Y'-->Y in regeneration learning and X-->X' in representation learning can be learned in a self-supervised way (e.g., pre-training); 3) both the mappings from X to Y' in regeneration learning and from X' to Y in representation learning are simpler than the direct mapping from X to Y. We show that regeneration learning can be a widely-used paradigm for data generation (e.g., text generation, speech recognition, speech synthesis, music composition, image generation, and video generation) and can provide valuable insights into developing data generation methods.
MeloForm: Generating Melody with Musical Form based on Expert Systems and Neural Networks
Aug 30, 2022
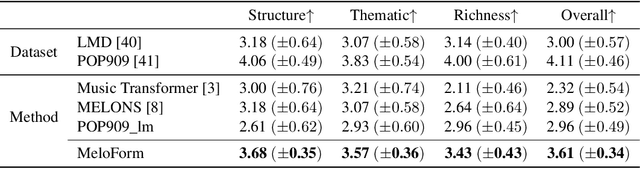
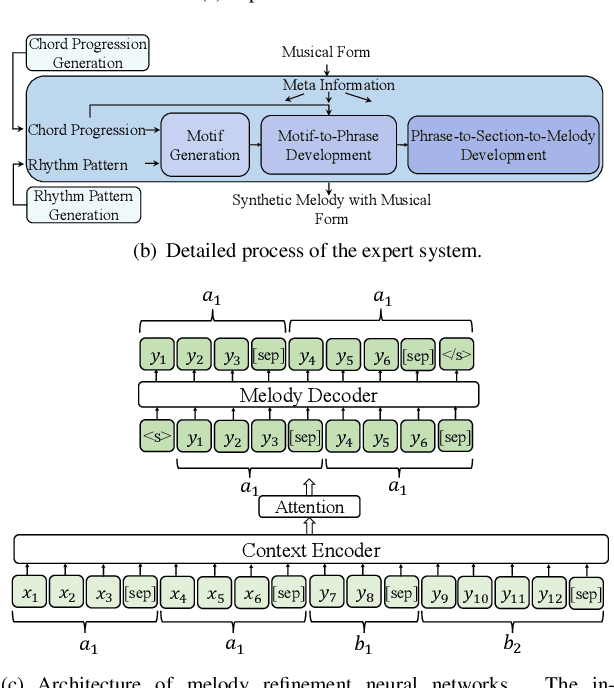
Human usually composes music by organizing elements according to the musical form to express music ideas. However, for neural network-based music generation, it is difficult to do so due to the lack of labelled data on musical form. In this paper, we develop MeloForm, a system that generates melody with musical form using expert systems and neural networks. Specifically, 1) we design an expert system to generate a melody by developing musical elements from motifs to phrases then to sections with repetitions and variations according to pre-given musical form; 2) considering the generated melody is lack of musical richness, we design a Transformer based refinement model to improve the melody without changing its musical form. MeloForm enjoys the advantages of precise musical form control by expert systems and musical richness learning via neural models. Both subjective and objective experimental evaluations demonstrate that MeloForm generates melodies with precise musical form control with 97.79% accuracy, and outperforms baseline systems in terms of subjective evaluation score by 0.75, 0.50, 0.86 and 0.89 in structure, thematic, richness and overall quality, without any labelled musical form data. Besides, MeloForm can support various kinds of forms, such as verse and chorus form, rondo form, variational form, sonata form, etc.
An adaptive music generation architecture for games based on the deep learning Transformer mode
Jul 04, 2022
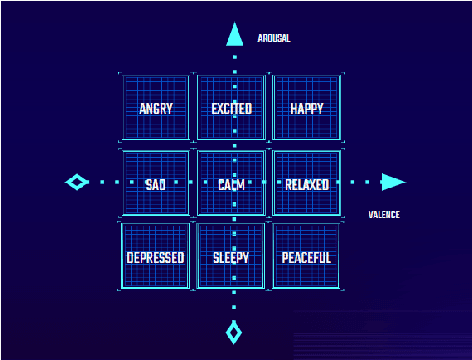
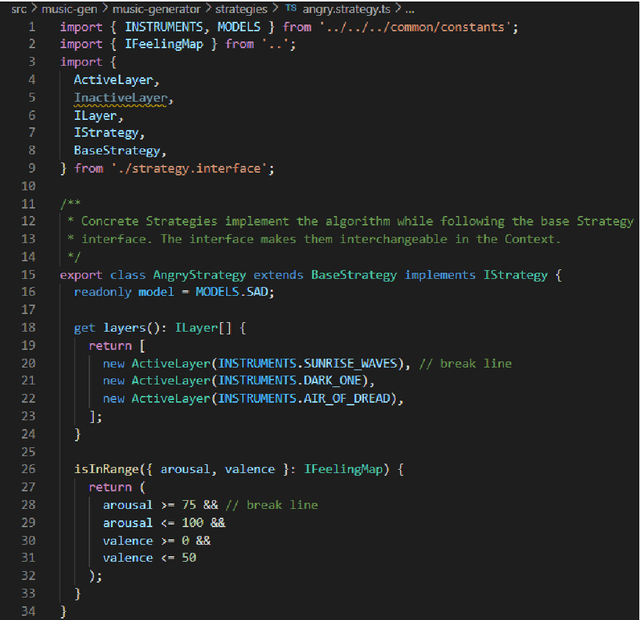
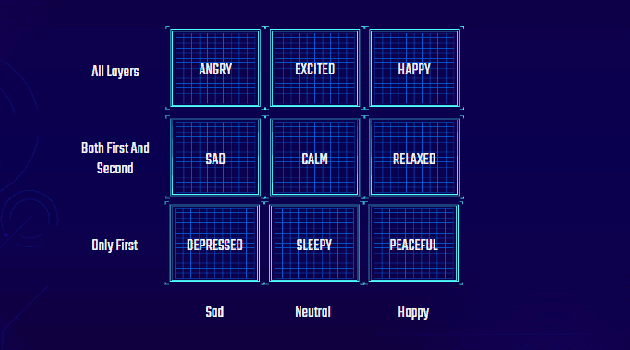
This paper presents an architecture for generating music for video games based on the Transformer deep learning model. The system generates music in various layers, following the standard layering strategy currently used by composers designing video game music. The music is adaptive to the psychological context of the player, according to the arousal-valence model. Our motivation is to customize music according to the player's tastes, who can select his preferred style of music through a set of training examples of music. We discuss current limitations and prospects for the future, such as collaborative and interactive control of the musical components.
Beyond Markov Chains, Towards Adaptive Memristor Network-based Music Generation
Feb 04, 2013

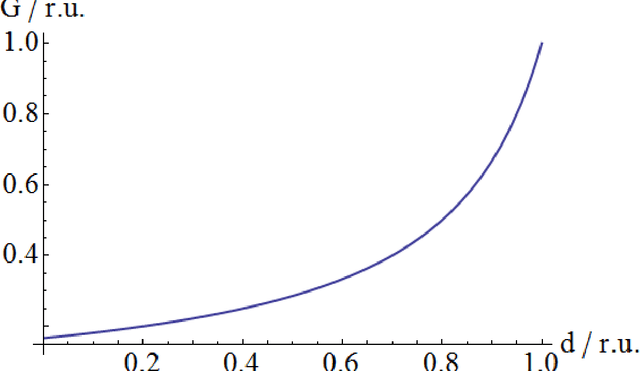

We undertook a study of the use of a memristor network for music generation, making use of the memristor's memory to go beyond the Markov hypothesis. Seed transition matrices are created and populated using memristor equations, and which are shown to generate musical melodies and change in style over time as a result of feedback into the transition matrix. The spiking properties of simple memristor networks are demonstrated and discussed with reference to applications of music making. The limitations of simulating composing memristor networks in von Neumann hardware is discussed and a hardware solution based on physical memristor properties is presented.
EDGE: Editable Dance Generation From Music
Nov 27, 2022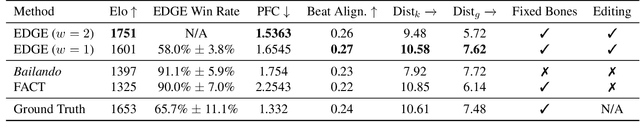
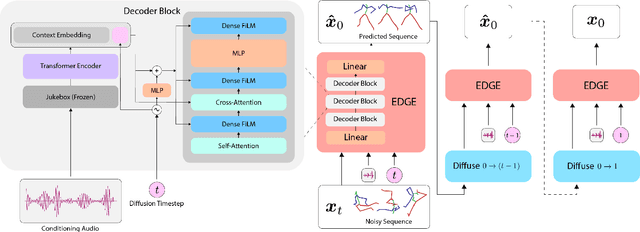
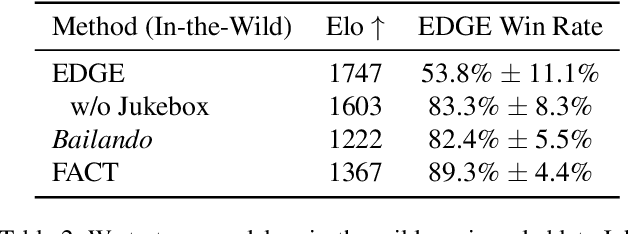
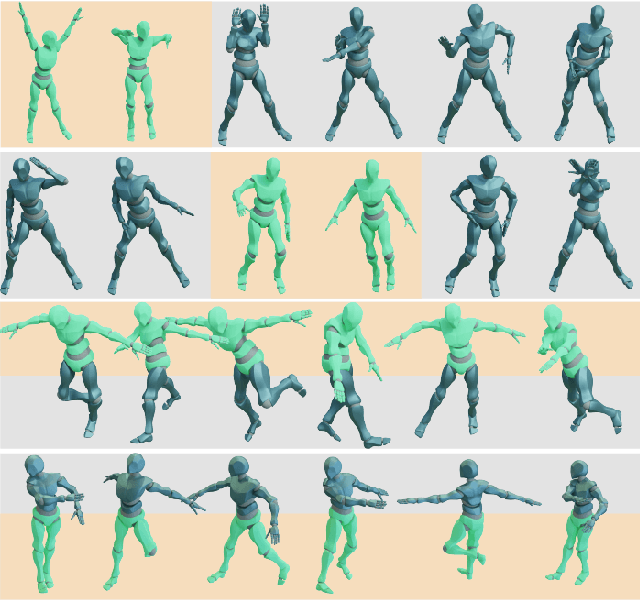
Dance is an important human art form, but creating new dances can be difficult and time-consuming. In this work, we introduce Editable Dance GEneration (EDGE), a state-of-the-art method for editable dance generation that is capable of creating realistic, physically-plausible dances while remaining faithful to the input music. EDGE uses a transformer-based diffusion model paired with Jukebox, a strong music feature extractor, and confers powerful editing capabilities well-suited to dance, including joint-wise conditioning, and in-betweening. We introduce a new metric for physical plausibility, and evaluate dance quality generated by our method extensively through (1) multiple quantitative metrics on physical plausibility, beat alignment, and diversity benchmarks, and more importantly, (2) a large-scale user study, demonstrating a significant improvement over previous state-of-the-art methods. Qualitative samples from our model can be found at our website.
Polyphonic Music Generation by Modeling Temporal Dependencies Using a RNN-DBN
Dec 26, 2014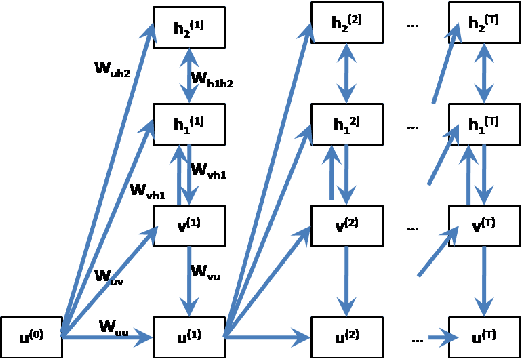
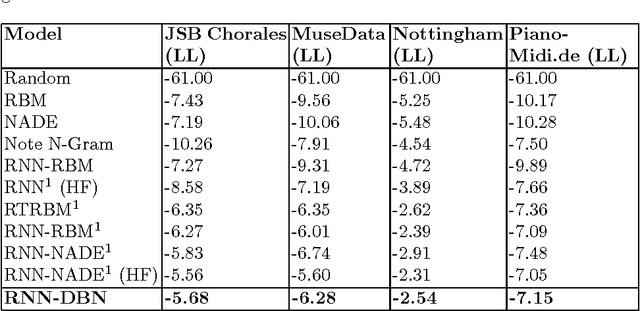
In this paper, we propose a generic technique to model temporal dependencies and sequences using a combination of a recurrent neural network and a Deep Belief Network. Our technique, RNN-DBN, is an amalgamation of the memory state of the RNN that allows it to provide temporal information and a multi-layer DBN that helps in high level representation of the data. This makes RNN-DBNs ideal for sequence generation. Further, the use of a DBN in conjunction with the RNN makes this model capable of significantly more complex data representation than an RBM. We apply this technique to the task of polyphonic music generation.
* 8 pages, A4, 1 figure, 1 table, ICANN 2014 oral presentation. arXiv admin note: text overlap with arXiv:1206.6392 by other authors