 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music generation": models, code, and papers
QuiKo: A Quantum Beat Generation Application
Apr 09, 2022
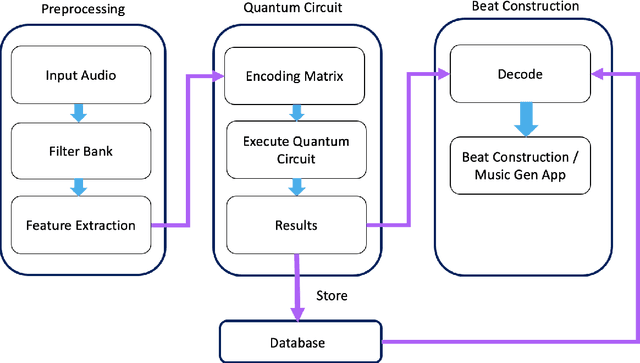
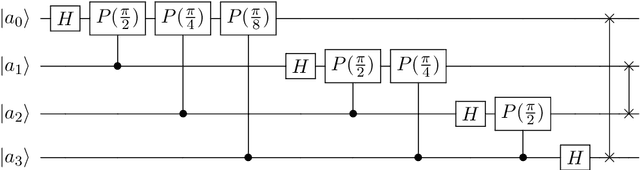
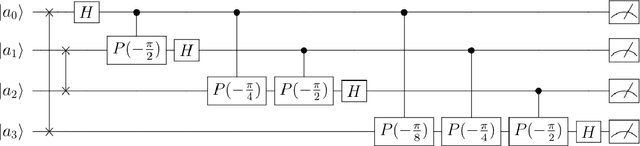
In this chapter a quantum music generation application called QuiKo will be discussed. It combines existing quantum algorithms with data encoding methods from quantum machine learning to build drum and audio sample patterns from a database of audio tracks. QuiKo leverages the physical properties and characteristics of quantum computers to generate what can be referred to as Soft Rules proposed by Alexis Kirke. These rules take advantage of the noise produced by quantum devices to develop flexible rules and grammars for quantum music generation. These properties include qubit decoherence and phase kickback due controlled quantum gates within the quantum circuit. QuiKo builds upon the concept of soft rules in quantum music generation and takes it a step further. It attempts to mimic and react to an external musical inputs, similar to the way that human musicians play and compose with one another. Audio signals are used as inputs into the system. Feature extraction is then performed on the signal to identify the harmonic and percussive elements. This information is then encoded onto the quantum circuit. Measurements of the quantum circuit are then taken providing results in the form of probability distributions for external music applications to use to build the new drum patterns.
Symphony Generation with Permutation Invariant Language Model
May 10, 2022
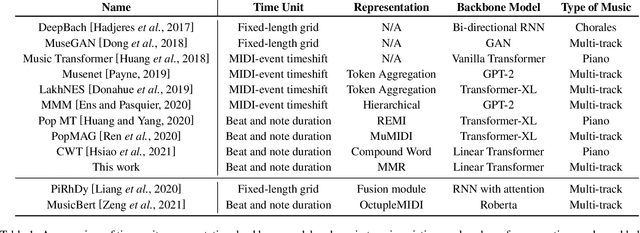
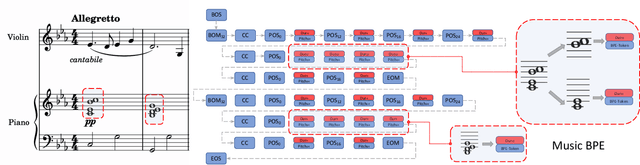
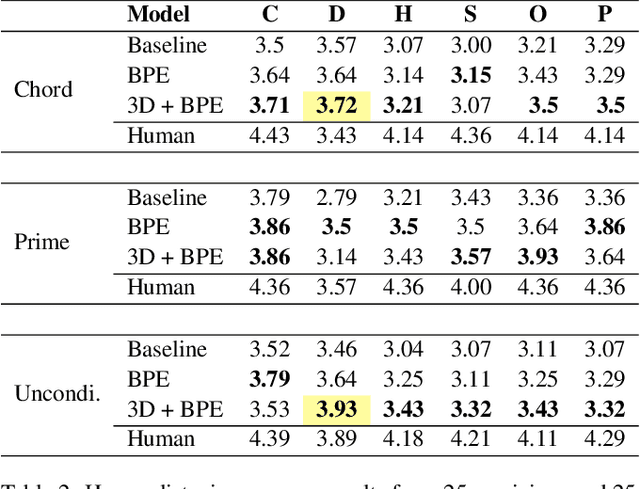
In this work, we present a symbolic symphony music generation solution, SymphonyNet, based on a permutation invariant language model. To bridge the gap between text generation and symphony generation task, we propose a novel Multi-track Multi-instrument Repeatable (MMR) representation with particular 3-D positional embedding and a modified Byte Pair Encoding algorithm (Music BPE) for music tokens. A novel linear transformer decoder architecture is introduced as a backbone for modeling extra-long sequences of symphony tokens. Meanwhile, we train the decoder to learn automatic orchestration as a joint task by masking instrument information from the input. We also introduce a large-scale symbolic symphony dataset for the advance of symphony generation research. Our empirical results show that our proposed approach can generate coherent, novel, complex and harmonious symphony compared to human composition, which is the pioneer solution for multi-track multi-instrument symbolic music generation.
Online Game Level Generation from Music
Jul 12, 2022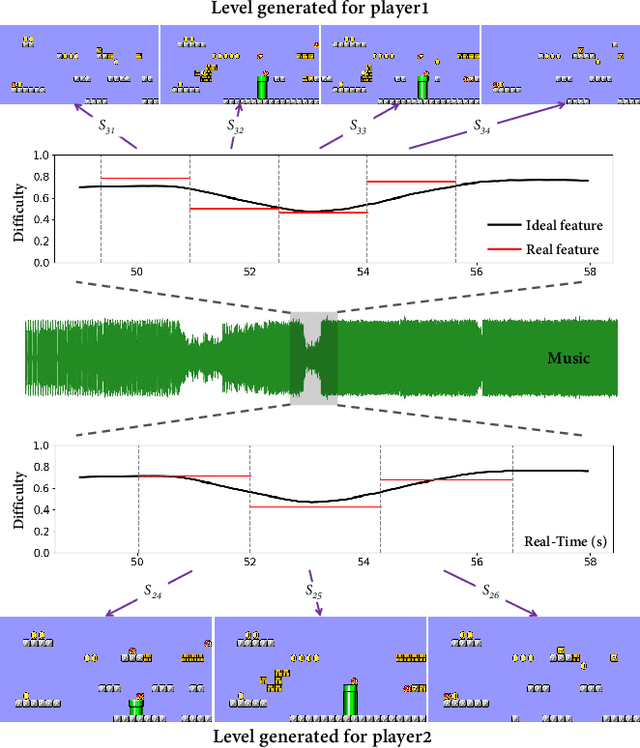
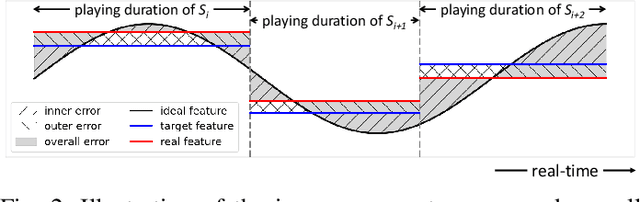
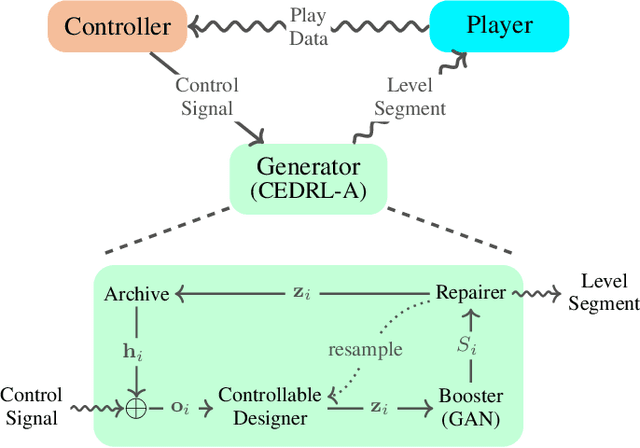
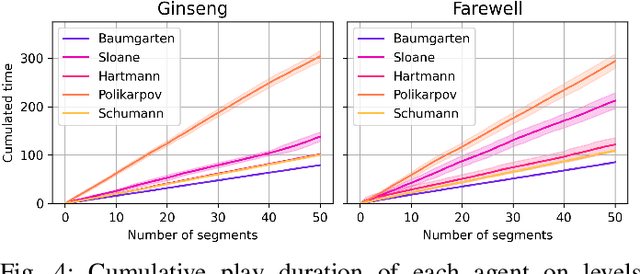
Game consists of multiple types of content, while the harmony of different content types play an essential role in game design. However, most works on procedural content generation consider only one type of content at a time. In this paper, we propose and formulate online level generation from music, in a way of matching a level feature to a music feature in real-time, while adapting to players' play speed. A generic framework named online player-adaptive procedural content generation via reinforcement learning, OPARL for short, is built upon the experience-driven reinforcement learning and controllable reinforcement learning, to enable online level generation from music. Furthermore, a novel control policy based on local search and k-nearest neighbours is proposed and integrated into OPARL to control the level generator considering the play data collected online. Results of simulation-based experiments show that our implementation of OPARL is competent to generate playable levels with difficulty degree matched to the ``energy'' dynamic of music for different artificial players in an online fashion.
Music-Driven Group Choreography
Mar 27, 2023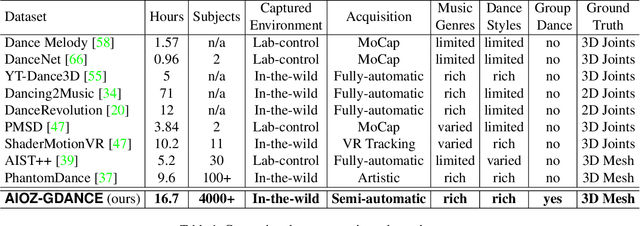
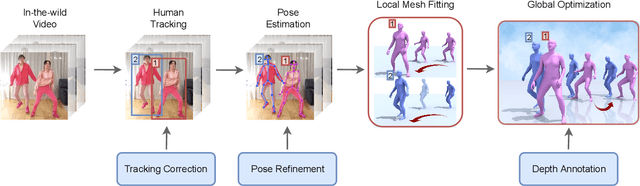
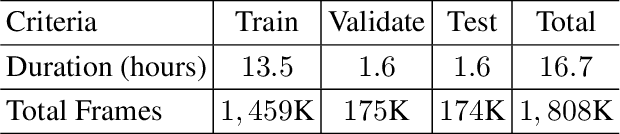
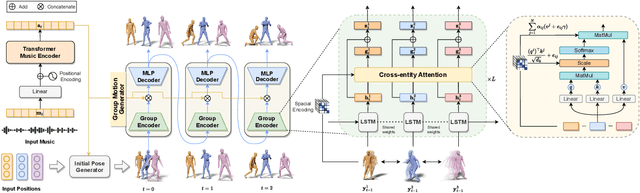
Music-driven choreography is a challenging problem with a wide variety of industrial applications. Recently, many methods have been proposed to synthesize dance motions from music for a single dancer. However, generating dance motion for a group remains an open problem. In this paper, we present $\rm AIOZ-GDANCE$, a new large-scale dataset for music-driven group dance generation. Unlike existing datasets that only support single dance, our new dataset contains group dance videos, hence supporting the study of group choreography. We propose a semi-autonomous labeling method with humans in the loop to obtain the 3D ground truth for our dataset. The proposed dataset consists of 16.7 hours of paired music and 3D motion from in-the-wild videos, covering 7 dance styles and 16 music genres. We show that naively applying single dance generation technique to creating group dance motion may lead to unsatisfactory results, such as inconsistent movements and collisions between dancers. Based on our new dataset, we propose a new method that takes an input music sequence and a set of 3D positions of dancers to efficiently produce multiple group-coherent choreographies. We propose new evaluation metrics for measuring group dance quality and perform intensive experiments to demonstrate the effectiveness of our method. Our project facilitates future research on group dance generation and is available at: https://aioz-ai.github.io/AIOZ-GDANCE/
An Order-Complexity Model for Aesthetic Quality Assessment of Homophony Music Performance
Apr 23, 2023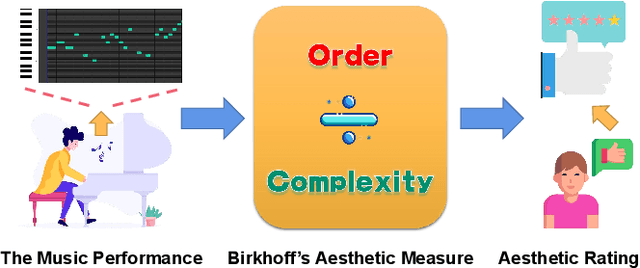

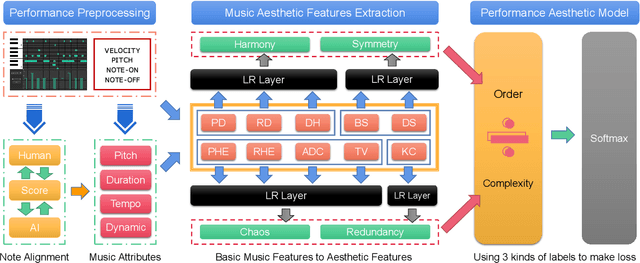

Although computational aesthetics evaluation has made certain achievements in many fields, its research of music performance remains to be explored. At present, subjective evaluation is still a ultimate method of music aesthetics research, but it will consume a lot of human and material resources. In addition, the music performance generated by AI is still mechanical, monotonous and lacking in beauty. In order to guide the generation task of AI music performance, and to improve the performance effect of human performers, this paper uses Birkhoff's aesthetic measure to propose a method of objective measurement of beauty. The main contributions of this paper are as follows: Firstly, we put forward an objective aesthetic evaluation method to measure the music performance aesthetic; Secondly, we propose 10 basic music features and 4 aesthetic music features. Experiments show that our method performs well on performance assessment.
Music Playlist Title Generation Using Artist Information
Jan 14, 2023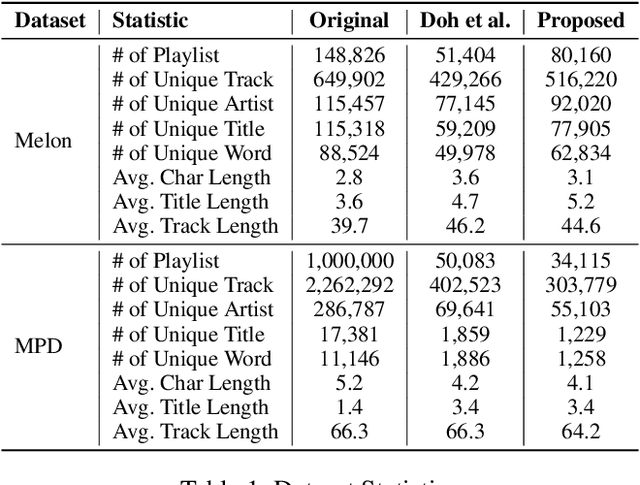
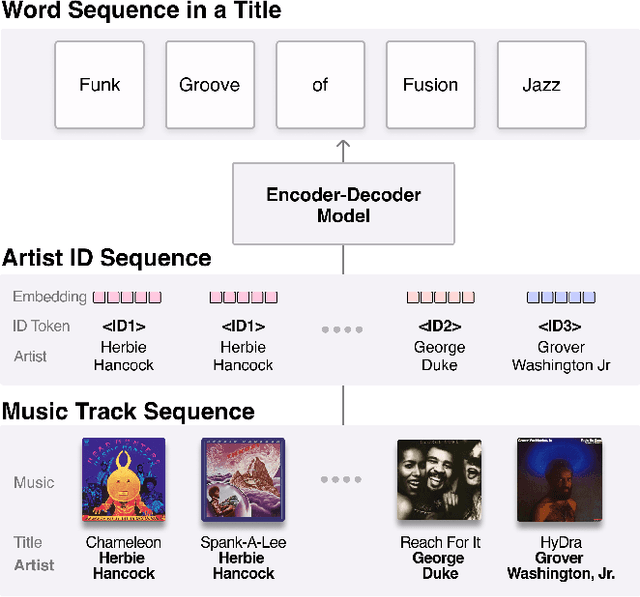

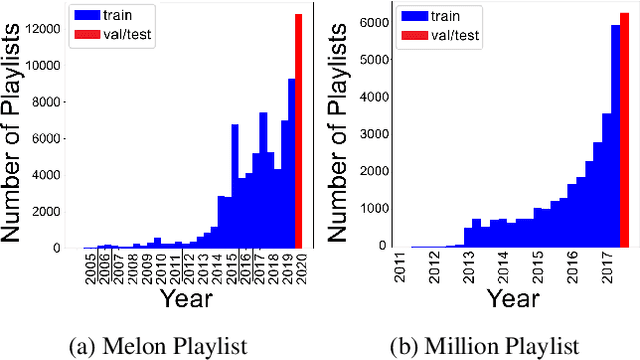
Automatically generating or captioning music playlist titles given a set of tracks is of significant interest in music streaming services as customized playlists are widely used in personalized music recommendation, and well-composed text titles attract users and help their music discovery. We present an encoder-decoder model that generates a playlist title from a sequence of music tracks. While previous work takes track IDs as tokenized input for playlist title generation, we use artist IDs corresponding to the tracks to mitigate the issue from the long-tail distribution of tracks included in the playlist dataset. Also, we introduce a chronological data split method to deal with newly-released tracks in real-world scenarios. Comparing the track IDs and artist IDs as input sequences, we show that the artist-based approach significantly enhances the performance in terms of word overlap, semantic relevance, and diversity.
SongDriver2: Real-time Emotion-based Music Arrangement with Soft Transition
May 14, 2023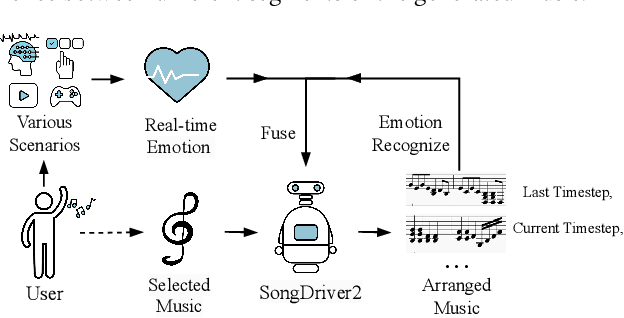
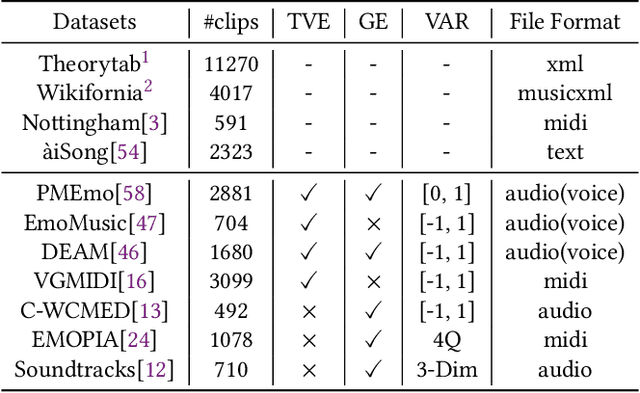
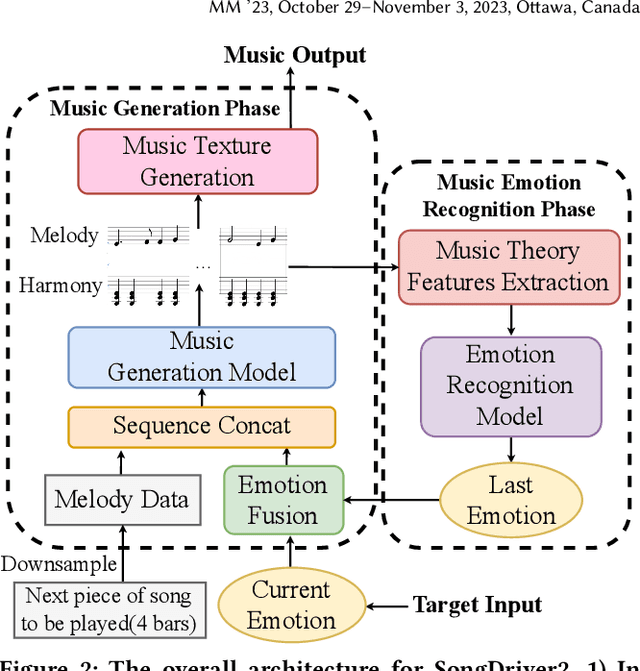

Real-time emotion-based music arrangement, which aims to transform a given music piece into another one that evokes specific emotional resonance with the user in real-time, holds significant application value in various scenarios, e.g., music therapy, video game soundtracks, and movie scores. However, balancing emotion real-time fit with soft emotion transition is a challenge due to the fine-grained and mutable nature of the target emotion. Existing studies mainly focus on achieving emotion real-time fit, while the issue of soft transition remains understudied, affecting the overall emotional coherence of the music. In this paper, we propose SongDriver2 to address this balance. Specifically, we first recognize the last timestep's music emotion and then fuse it with the current timestep's target input emotion. The fused emotion then serves as the guidance for SongDriver2 to generate the upcoming music based on the input melody data. To adjust music similarity and emotion real-time fit flexibly, we downsample the original melody and feed it into the generation model. Furthermore, we design four music theory features to leverage domain knowledge to enhance emotion information and employ semi-supervised learning to mitigate the subjective bias introduced by manual dataset annotation. According to the evaluation results, SongDriver2 surpasses the state-of-the-art methods in both objective and subjective metrics. These results demonstrate that SongDriver2 achieves real-time fit and soft transitions simultaneously, enhancing the coherence of the generated music.
A Domain-Knowledge-Inspired Music Embedding Space and a Novel Attention Mechanism for Symbolic Music Modeling
Dec 02, 2022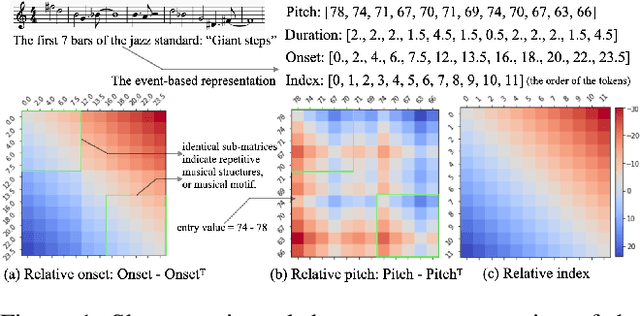
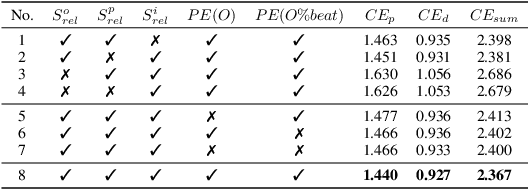
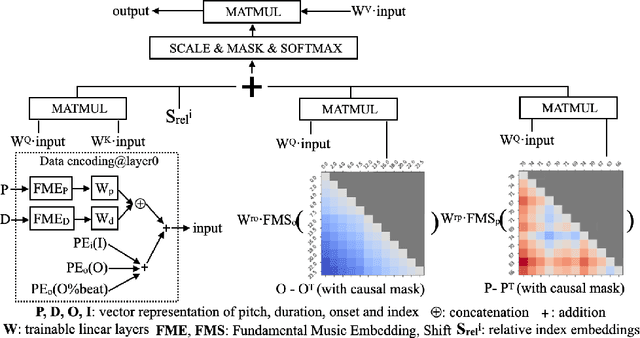
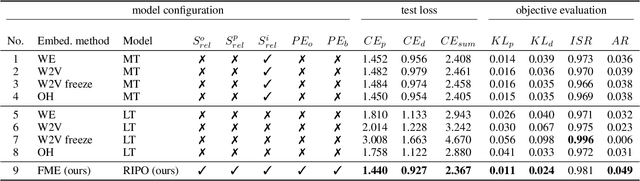
Following the success of the transformer architecture in the natural language domain, transformer-like architectures have been widely applied to the domain of symbolic music recently. Symbolic music and text, however, are two different modalities. Symbolic music contains multiple attributes, both absolute attributes (e.g., pitch) and relative attributes (e.g., pitch interval). These relative attributes shape human perception of musical motifs. These important relative attributes, however, are mostly ignored in existing symbolic music modeling methods with the main reason being the lack of a musically-meaningful embedding space where both the absolute and relative embeddings of the symbolic music tokens can be efficiently represented. In this paper, we propose the Fundamental Music Embedding (FME) for symbolic music based on a bias-adjusted sinusoidal encoding within which both the absolute and the relative attributes can be embedded and the fundamental musical properties (e.g., translational invariance) are explicitly preserved. Taking advantage of the proposed FME, we further propose a novel attention mechanism based on the relative index, pitch and onset embeddings (RIPO attention) such that the musical domain knowledge can be fully utilized for symbolic music modeling. Experiment results show that our proposed model: RIPO transformer which utilizes FME and RIPO attention outperforms the state-of-the-art transformers (i.e., music transformer, linear transformer) in a melody completion task. Moreover, using the RIPO transformer in a downstream music generation task, we notice that the notorious degeneration phenomenon no longer exists and the music generated by the RIPO transformer outperforms the music generated by state-of-the-art transformer models in both subjective and objective evaluations.
AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head
Apr 25, 2023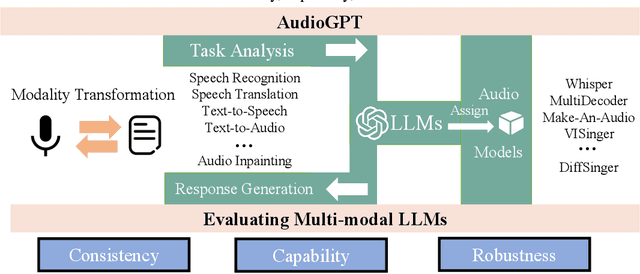

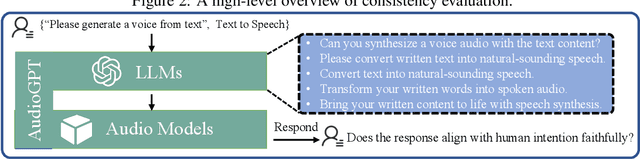

Large language models (LLMs) have exhibited remarkable capabilities across a variety of domains and tasks, challenging our understanding of learning and cognition. Despite the recent success, current LLMs are not capable of processing complex audio information or conducting spoken conversations (like Siri or Alexa). In this work, we propose a multi-modal AI system named AudioGPT, which complements LLMs (i.e., ChatGPT) with 1) foundation models to process complex audio information and solve numerous understanding and generation tasks; and 2) the input/output interface (ASR, TTS) to support spoken dialogue. With an increasing demand to evaluate multi-modal LLMs of human intention understanding and cooperation with foundation models, we outline the principles and processes and test AudioGPT in terms of consistency, capability, and robustness. Experimental results demonstrate the capabilities of AudioGPT in solving AI tasks with speech, music, sound, and talking head understanding and generation in multi-round dialogues, which empower humans to create rich and diverse audio content with unprecedented ease. Our system is publicly available at \url{https://github.com/AIGC-Audio/AudioGPT}.
MR4MR: Mixed Reality for Melody Reincarnation
Sep 15, 2022


There is a long history of an effort made to explore musical elements with the entities and spaces around us, such as musique concr\`ete and ambient music. In the context of computer music and digital art, interactive experiences that concentrate on the surrounding objects and physical spaces have also been designed. In recent years, with the development and popularization of devices, an increasing number of works have been designed in Extended Reality to create such musical experiences. In this paper, we describe MR4MR, a sound installation work that allows users to experience melodies produced from interactions with their surrounding space in the context of Mixed Reality (MR). Using HoloLens, an MR head-mounted display, users can bump virtual objects that emit sound against real objects in their surroundings. Then, by continuously creating a melody following the sound made by the object and re-generating randomly and gradually changing melody using music generation machine learning models, users can feel their ambient melody "reincarnating".