 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music generation": models, code, and papers
Music Generation by Deep Learning - Challenges and Directions
Sep 30, 2018

In addition to traditional tasks such as prediction, classification and translation, deep learning is receiving growing attention as an approach for music generation, as witnessed by recent research groups such as Magenta at Google and CTRL (Creator Technology Research Lab) at Spotify. The motivation is in using the capacity of deep learning architectures and training techniques to automatically learn musical styles from arbitrary musical corpora and then to generate samples from the estimated distribution. However, a direct application of deep learning to generate content rapidly reaches limits as the generated content tends to mimic the training set without exhibiting true creativity. Moreover, deep learning architectures do not offer direct ways for controlling generation (e.g., imposing some tonality or other arbitrary constraints). Furthermore, deep learning architectures alone are autistic automata which generate music autonomously without human user interaction, far from the objective of interactively assisting musicians to compose and refine music. Issues such as: control, structure, creativity and interactivity are the focus of our analysis. In this paper, we select some limitations of a direct application of deep learning to music generation, analyze why the issues are not fulfilled and how to address them by possible approaches. Various examples of recent systems are cited as examples of promising directions.
The Effect of Explicit Structure Encoding of Deep Neural Networks for Symbolic Music Generation
Nov 20, 2018
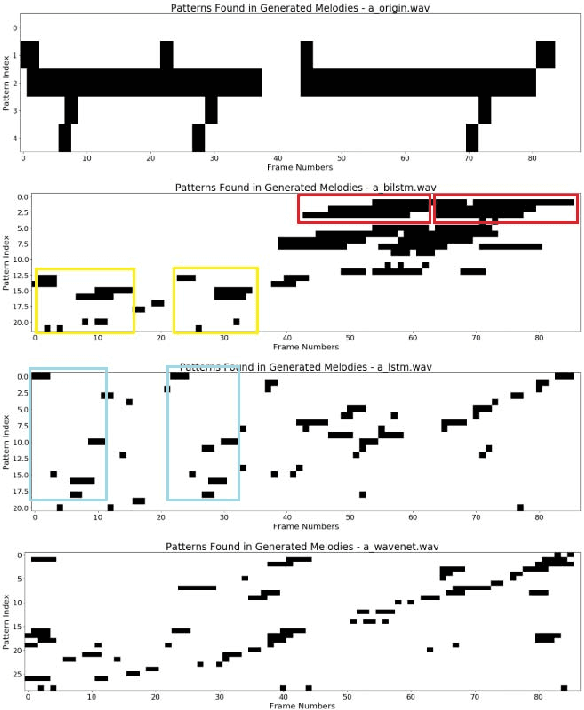
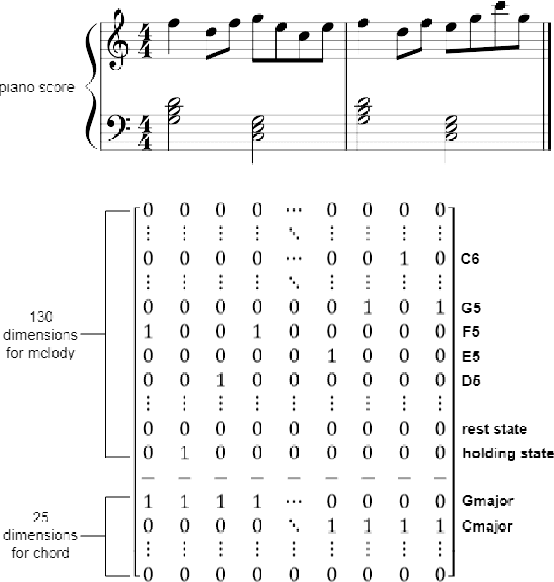
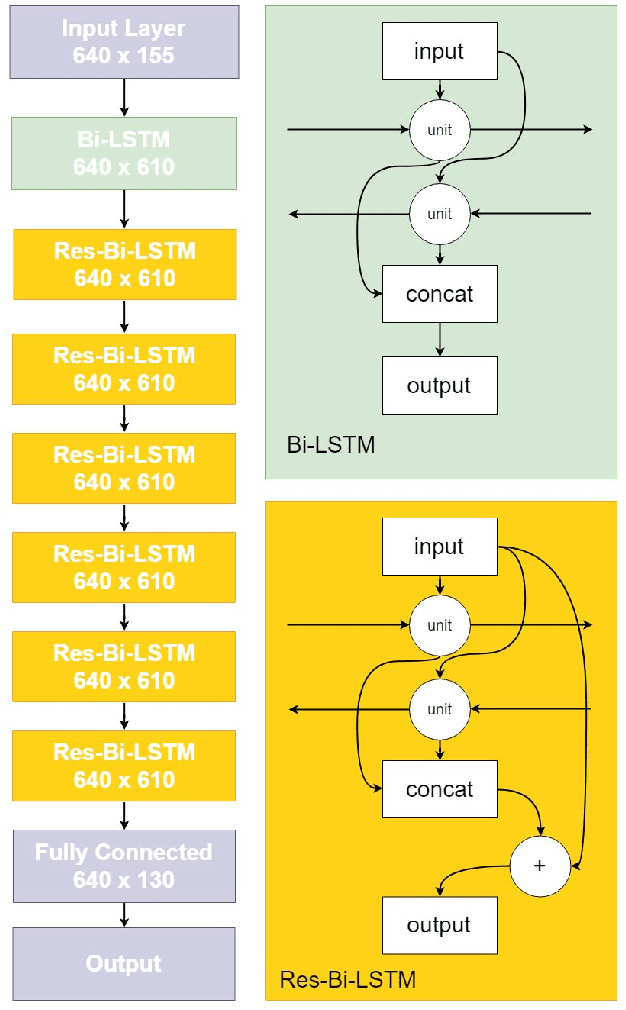
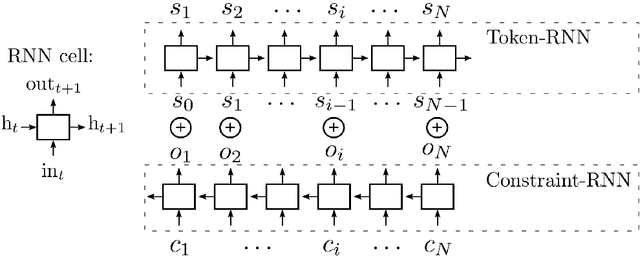
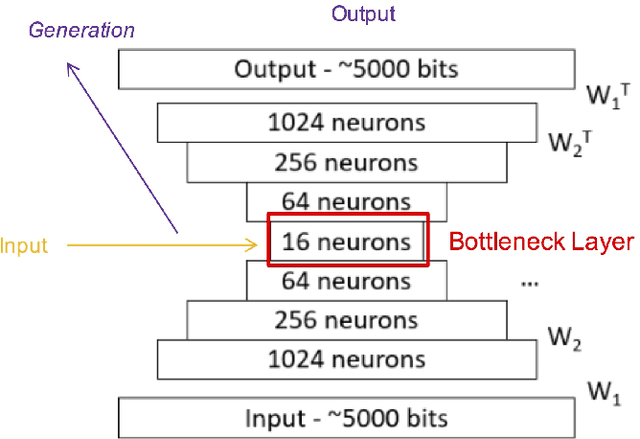
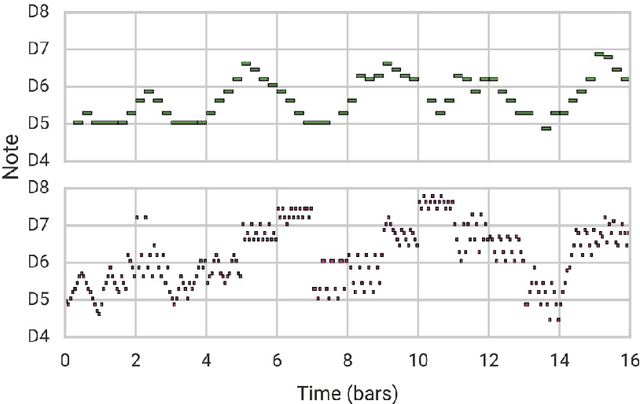
With recent breakthroughs in artificial neural networks, deep generative models have become one of the leading techniques for computational creativity. Despite very promising progress on image and short sequence generation, symbolic music generation remains a challenging problem since the structure of compositions are usually complicated. In this study, we attempt to solve the melody generation problem constrained by the given chord progression. This music meta-creation problem can also be incorporated into a plan recognition system with user inputs and predictive structural outputs. In particular, we explore the effect of explicit architectural encoding of musical structure via comparing two sequential generative models: LSTM (a type of RNN) and WaveNet (dilated temporal-CNN). As far as we know, this is the first study of applying WaveNet to symbolic music generation, as well as the first systematic comparison between temporal-CNN and RNN for music generation. We conduct a survey for evaluation in our generations and implemented Variable Markov Oracle in music pattern discovery. Experimental results show that to encode structure more explicitly using a stack of dilated convolution layers improved the performance significantly, and a global encoding of underlying chord progression into the generation procedure gains even more.
Dance Generation by Sound Symbolic Words
Jun 06, 2023

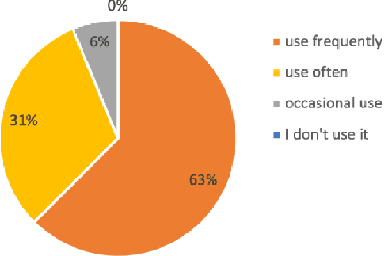
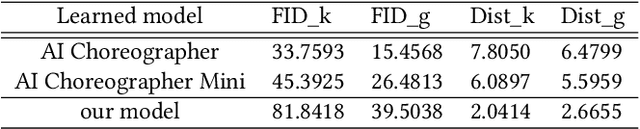
This study introduces a novel approach to generate dance motions using onomatopoeia as input, with the aim of enhancing creativity and diversity in dance generation. Unlike text and music, onomatopoeia conveys rhythm and meaning through abstract word expressions without constraints on expression and without need for specialized knowledge. We adapt the AI Choreographer framework and employ the Sakamoto system, a feature extraction method for onomatopoeia focusing on phonemes and syllables. Additionally, we present a new dataset of 40 onomatopoeia-dance motion pairs collected through a user survey. Our results demonstrate that the proposed method enables more intuitive dance generation and can create dance motions using sound-symbolic words from a variety of languages, including those without onomatopoeia. This highlights the potential for diverse dance creation across different languages and cultures, accessible to a wider audience. Qualitative samples from our model can be found at: https://sites.google.com/view/onomatopoeia-dance/home/.
Multi-Genre Music Transformer -- Composing Full Length Musical Piece
Jan 06, 2023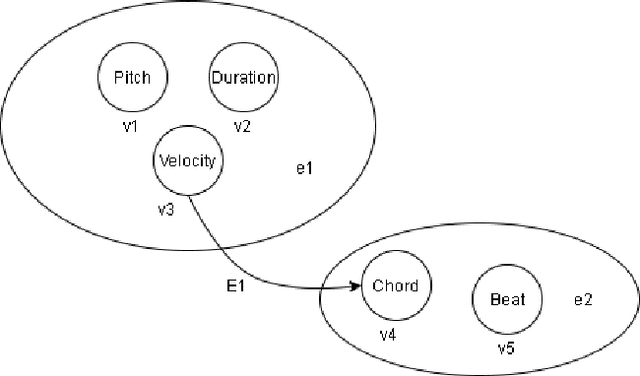

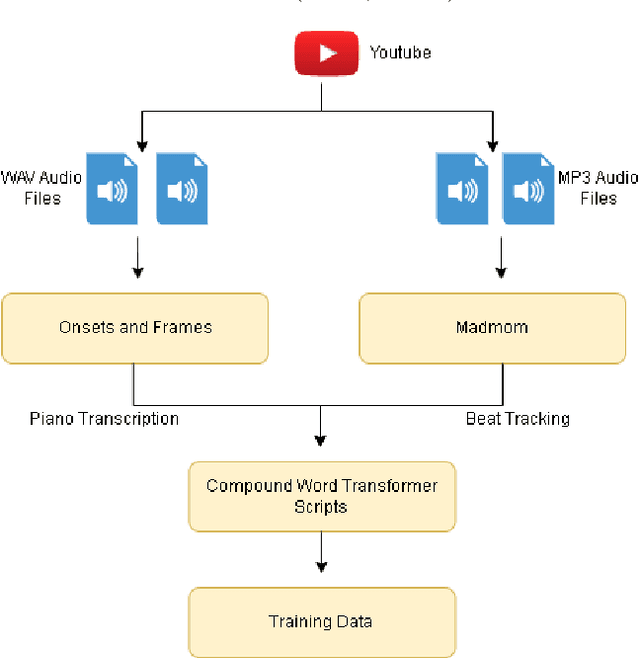
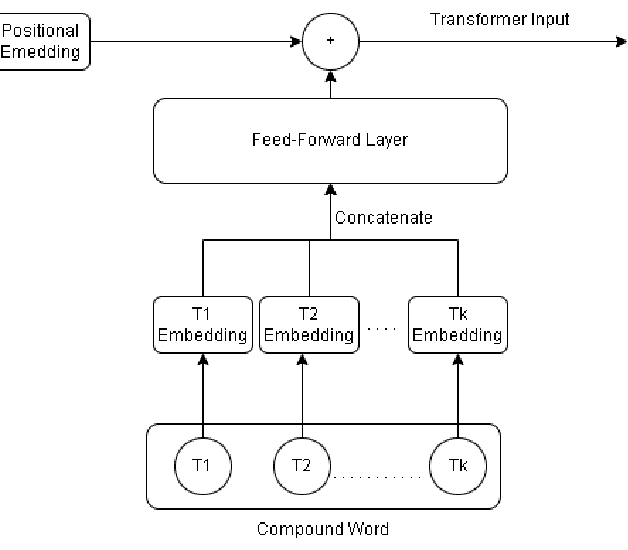
In the task of generating music, the art factor plays a big role and is a great challenge for AI. Previous work involving adversarial training to produce new music pieces and modeling the compatibility of variety in music (beats, tempo, musical stems) demonstrated great examples of learning this task. Though this was limited to generating mashups or learning features from tempo and key distributions to produce similar patterns. Compound Word Transformer was able to represent music generation task as a sequence generation challenge involving musical events defined by compound words. These musical events give a more accurate description of notes progression, chord change, harmony and the art factor. The objective of the project is to implement a Multi-Genre Transformer which learns to produce music pieces through more adaptive learning process involving more challenging task where genres or form of the composition is also considered. We built a multi-genre compound word dataset, implemented a linear transformer which was trained on this dataset. We call this Multi-Genre Transformer, which was able to generate full length new musical pieces which is diverse and comparable to original tracks. The model trains 2-5 times faster than other models discussed.
Symbolic music generation conditioned on continuous-valued emotions
Mar 30, 2022
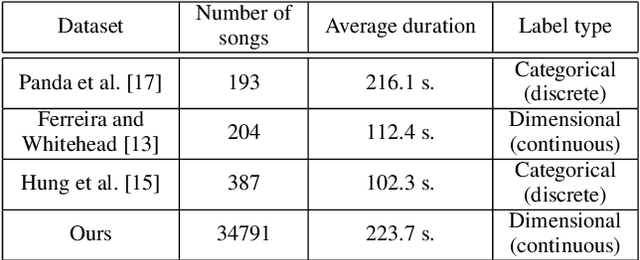
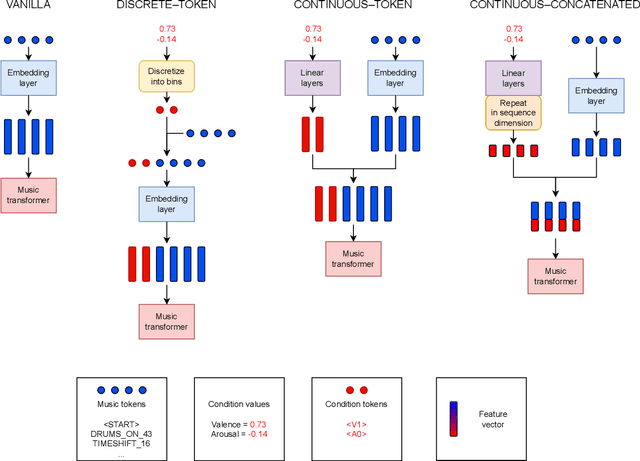
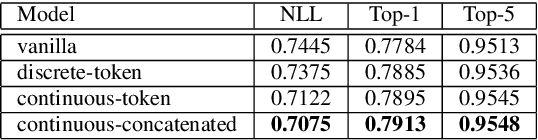
In this paper we present a new approach for the generation of multi-instrument symbolic music driven by musical emotion. The principal novelty of our approach centres on conditioning a state-of-the-art transformer based on continuous-valued valence and arousal labels. In addition, we provide a new large-scale dataset of symbolic music paired with emotion labels in terms of valence and arousal. We evaluate our approach in a quantitative manner in two ways, first by measuring its note prediction accuracy, and second via a regression task in the valence-arousal plane. Our results demonstrate that our proposed approaches outperform conditioning using control tokens which is representative of the current state of the art.
MARBLE: Music Audio Representation Benchmark for Universal Evaluation
Jun 21, 2023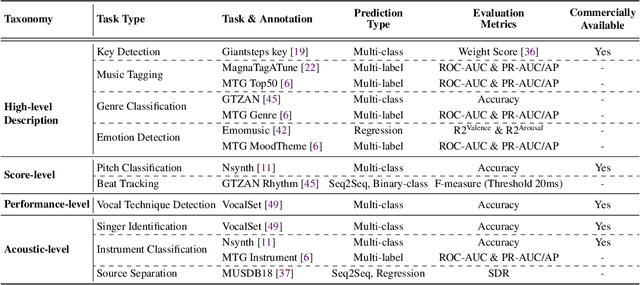
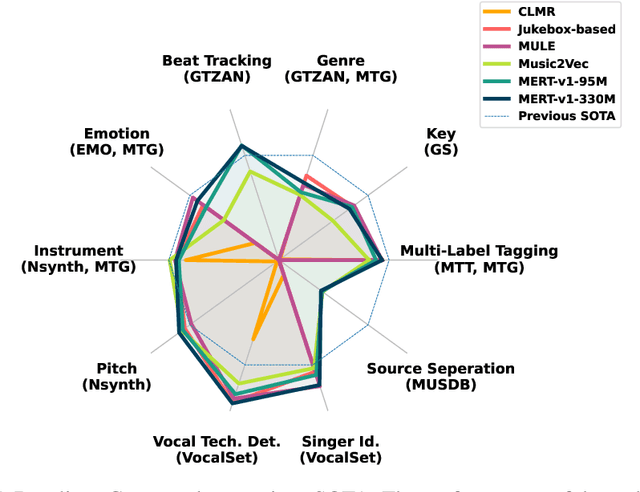
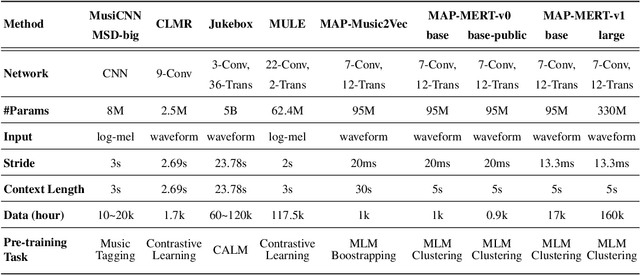
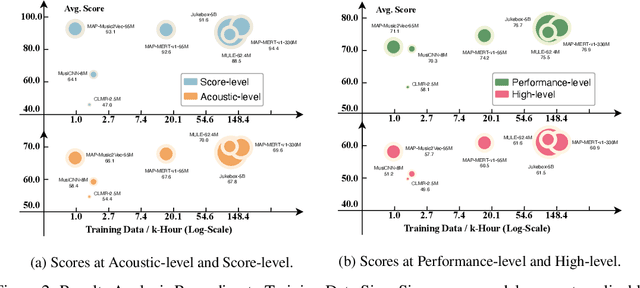
In the era of extensive intersection between art and Artificial Intelligence (AI), such as image generation and fiction co-creation, AI for music remains relatively nascent, particularly in music understanding. This is evident in the limited work on deep music representations, the scarcity of large-scale datasets, and the absence of a universal and community-driven benchmark. To address this issue, we introduce the Music Audio Representation Benchmark for universaL Evaluation, termed MARBLE. It aims to provide a benchmark for various Music Information Retrieval (MIR) tasks by defining a comprehensive taxonomy with four hierarchy levels, including acoustic, performance, score, and high-level description. We then establish a unified protocol based on 14 tasks on 8 public-available datasets, providing a fair and standard assessment of representations of all open-sourced pre-trained models developed on music recordings as baselines. Besides, MARBLE offers an easy-to-use, extendable, and reproducible suite for the community, with a clear statement on copyright issues on datasets. Results suggest recently proposed large-scale pre-trained musical language models perform the best in most tasks, with room for further improvement. The leaderboard and toolkit repository are published at https://marble-bm.shef.ac.uk to promote future music AI research.
Comparision Of Adversarial And Non-Adversarial LSTM Music Generative Models
Nov 01, 2022
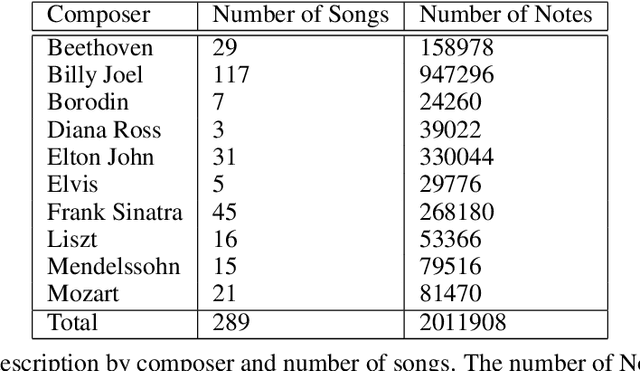
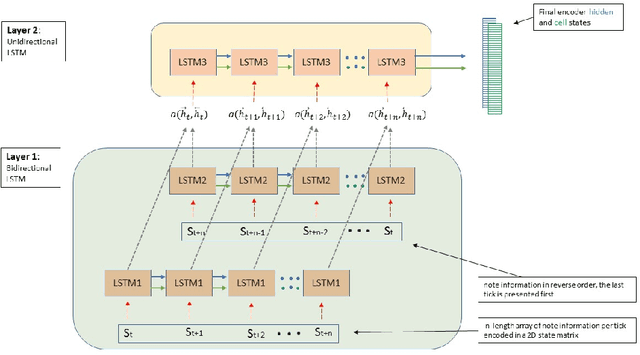
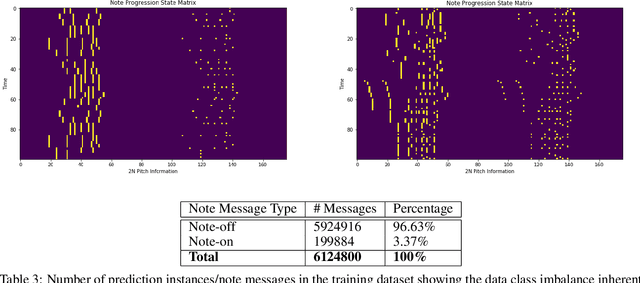
Algorithmic music composition is a way of composing musical pieces with minimal to no human intervention. While recurrent neural networks are traditionally applied to many sequence-to-sequence prediction tasks, including successful implementations of music composition, their standard supervised learning approach based on input-to-output mapping leads to a lack of note variety. These models can therefore be seen as potentially unsuitable for tasks such as music generation. Generative adversarial networks learn the generative distribution of data and lead to varied samples. This work implements and compares adversarial and non-adversarial training of recurrent neural network music composers on MIDI data. The resulting music samples are evaluated by human listeners, their preferences recorded. The evaluation indicates that adversarial training produces more aesthetically pleasing music.
Generative Disco: Text-to-Video Generation for Music Visualization
Apr 17, 2023



Visuals are a core part of our experience of music, owing to the way they can amplify the emotions and messages conveyed through the music. However, creating music visualization is a complex, time-consuming, and resource-intensive process. We introduce Generative Disco, a generative AI system that helps generate music visualizations with large language models and text-to-image models. Users select intervals of music to visualize and then parameterize that visualization by defining start and end prompts. These prompts are warped between and generated according to the beat of the music for audioreactive video. We introduce design patterns for improving generated videos: "transitions", which express shifts in color, time, subject, or style, and "holds", which encourage visual emphasis and consistency. A study with professionals showed that the system was enjoyable, easy to explore, and highly expressive. We conclude on use cases of Generative Disco for professionals and how AI-generated content is changing the landscape of creative work.
Unsupervised Melody-to-Lyric Generation
May 30, 2023

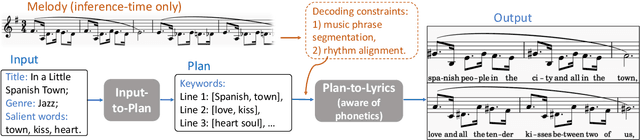

Automatic melody-to-lyric generation is a task in which song lyrics are generated to go with a given melody. It is of significant practical interest and more challenging than unconstrained lyric generation as the music imposes additional constraints onto the lyrics. The training data is limited as most songs are copyrighted, resulting in models that underfit the complicated cross-modal relationship between melody and lyrics. In this work, we propose a method for generating high-quality lyrics without training on any aligned melody-lyric data. Specifically, we design a hierarchical lyric generation framework that first generates a song outline and second the complete lyrics. The framework enables disentanglement of training (based purely on text) from inference (melody-guided text generation) to circumvent the shortage of parallel data. We leverage the segmentation and rhythm alignment between melody and lyrics to compile the given melody into decoding constraints as guidance during inference. The two-step hierarchical design also enables content control via the lyric outline, a much-desired feature for democratizing collaborative song creation. Experimental results show that our model can generate high-quality lyrics that are more on-topic, singable, intelligible, and coherent than strong baselines, for example SongMASS, a SOTA model trained on a parallel dataset, with a 24% relative overall quality improvement based on human ratings. O
YM2413-MDB: A Multi-Instrumental FM Video Game Music Dataset with Emotion Annotations
Nov 14, 2022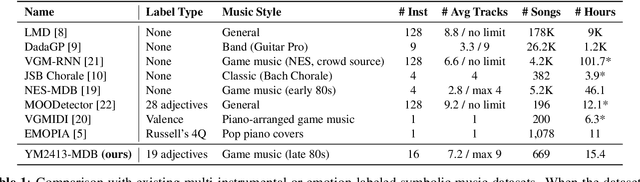
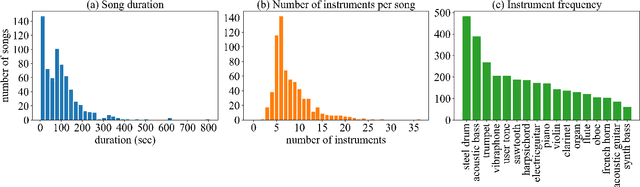
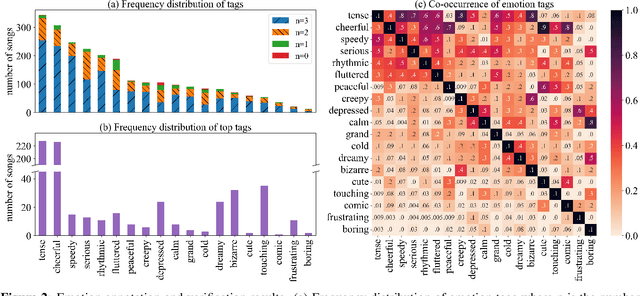

Existing multi-instrumental datasets tend to be biased toward pop and classical music. In addition, they generally lack high-level annotations such as emotion tags. In this paper, we propose YM2413-MDB, an 80s FM video game music dataset with multi-label emotion annotations. It includes 669 audio and MIDI files of music from Sega and MSX PC games in the 80s using YM2413, a programmable sound generator based on FM. The collected game music is arranged with a subset of 15 monophonic instruments and one drum instrument. They were converted from binary commands of the YM2413 sound chip. Each song was labeled with 19 emotion tags by two annotators and validated by three verifiers to obtain refined tags. We provide the baseline models and results for emotion recognition and emotion-conditioned symbolic music generation using YM2413-MDB.