 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"magic": models, code, and papers
On the statistical complexity of quantum circuits
Jan 15, 2021

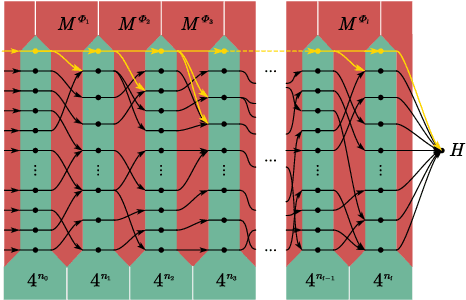
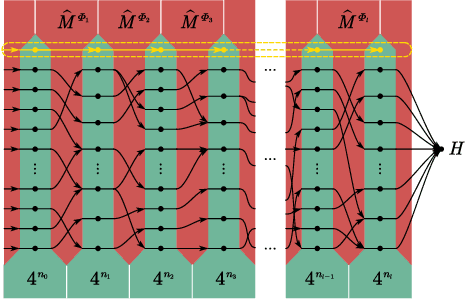
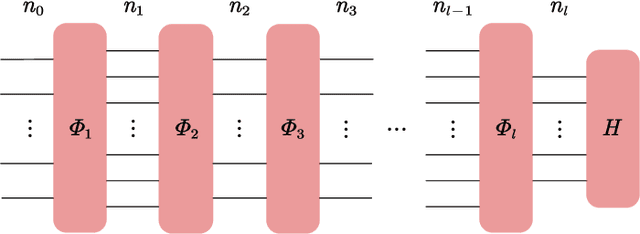
In theoretical machine learning, the statistical complexity is a notion that measures the richness of a hypothesis space. In this work, we apply a particular measure of statistical complexity, namely the Rademacher complexity, to the quantum circuit model in quantum computation and study how the statistical complexity depends on various quantum circuit parameters. In particular, we investigate the dependence of the statistical complexity on the resources, depth, width, and the number of input and output registers of a quantum circuit. To study how the statistical complexity scales with resources in the circuit, we introduce a resource measure of magic based on the $(p,q)$ group norm, which quantifies the amount of magic in the quantum channels associated with the circuit. These dependencies are investigated in the following two settings: (i) where the entire quantum circuit is treated as a single quantum channel, and (ii) where each layer of the quantum circuit is treated as a separate quantum channel. The bounds we obtain can be used to constrain the capacity of quantum neural networks in terms of their depths and widths as well as the resources in the network.
NeuralMagicEye: Learning to See and Understand the Scene Behind an Autostereogram
Dec 31, 2020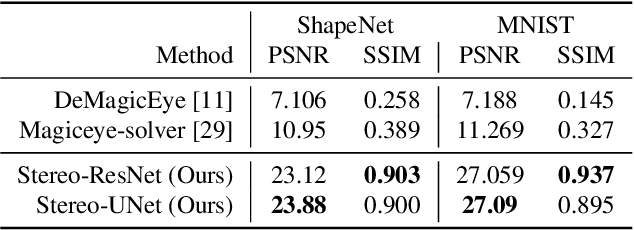
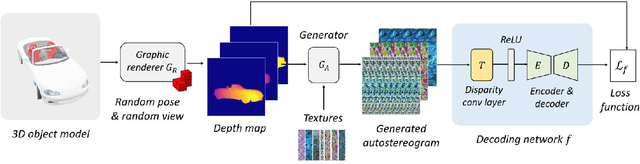
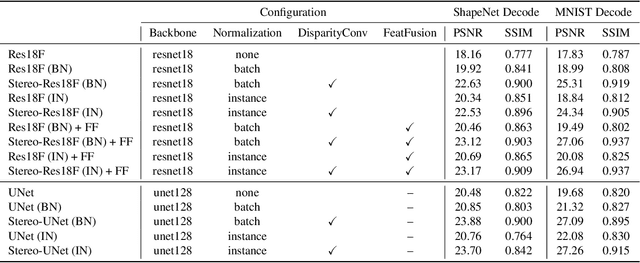
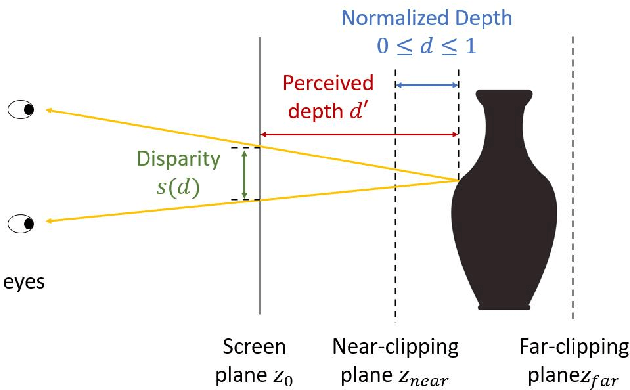
An autostereogram, a.k.a. magic eye image, is a single-image stereogram that can create visual illusions of 3D scenes from 2D textures. This paper studies an interesting question that whether a deep CNN can be trained to recover the depth behind an autostereogram and understand its content. The key to the autostereogram magic lies in the stereopsis - to solve such a problem, a model has to learn to discover and estimate disparity from the quasi-periodic textures. We show that deep CNNs embedded with disparity convolution, a novel convolutional layer proposed in this paper that simulates stereopsis and encodes disparity, can nicely solve such a problem after being sufficiently trained on a large 3D object dataset in a self-supervised fashion. We refer to our method as ``NeuralMagicEye''. Experiments show that our method can accurately recover the depth behind autostereograms with rich details and gradient smoothness. Experiments also show the completely different working mechanisms for autostereogram perception between neural networks and human eyes. We hope this research can help people with visual impairments and those who have trouble viewing autostereograms. Our code is available at \url{https://jiupinjia.github.io/neuralmagiceye/}.
Magic Sets for Disjunctive Datalog Programs
Apr 27, 2012
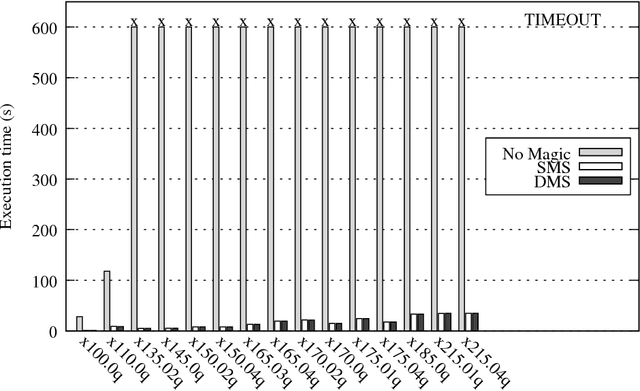
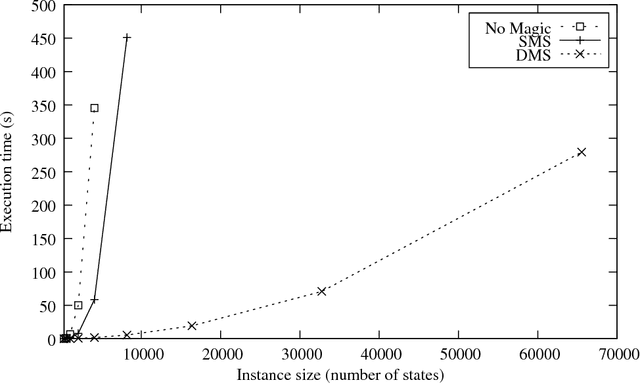
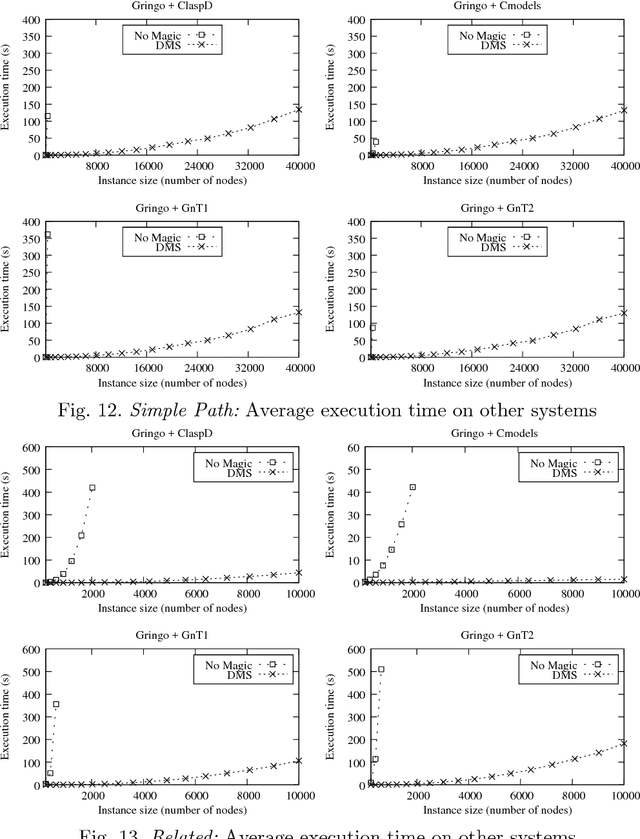
In this paper, a new technique for the optimization of (partially) bound queries over disjunctive Datalog programs with stratified negation is presented. The technique exploits the propagation of query bindings and extends the Magic Set (MS) optimization technique. An important feature of disjunctive Datalog is nonmonotonicity, which calls for nondeterministic implementations, such as backtracking search. A distinguishing characteristic of the new method is that the optimization can be exploited also during the nondeterministic phase. In particular, after some assumptions have been made during the computation, parts of the program may become irrelevant to a query under these assumptions. This allows for dynamic pruning of the search space. In contrast, the effect of the previously defined MS methods for disjunctive Datalog is limited to the deterministic portion of the process. In this way, the potential performance gain by using the proposed method can be exponential, as could be observed empirically. The correctness of MS is established thanks to a strong relationship between MS and unfounded sets that has not been studied in the literature before. This knowledge allows for extending the method also to programs with stratified negation in a natural way. The proposed method has been implemented in DLV and various experiments have been conducted. Experimental results on synthetic data confirm the utility of MS for disjunctive Datalog, and they highlight the computational gain that may be obtained by the new method w.r.t. the previously proposed MS methods for disjunctive Datalog programs. Further experiments on real-world data show the benefits of MS within an application scenario that has received considerable attention in recent years, the problem of answering user queries over possibly inconsistent databases originating from integration of autonomous sources of information.
Magic dust for cross-lingual adaptation of monolingual wav2vec-2.0
Oct 07, 2021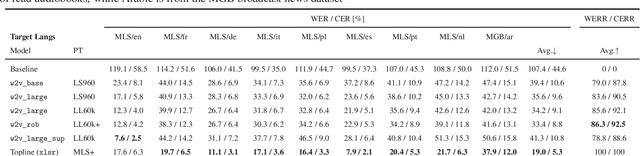
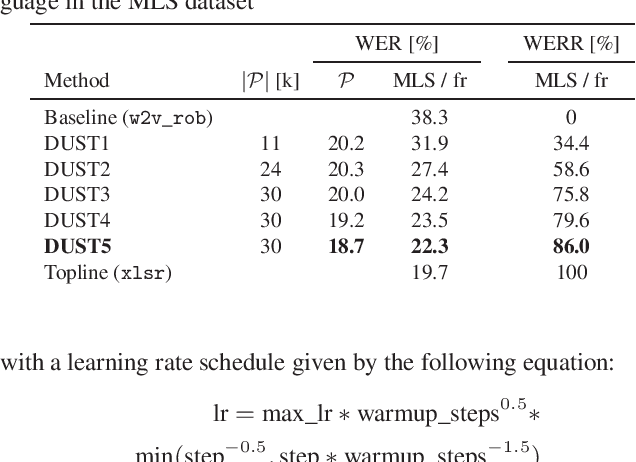
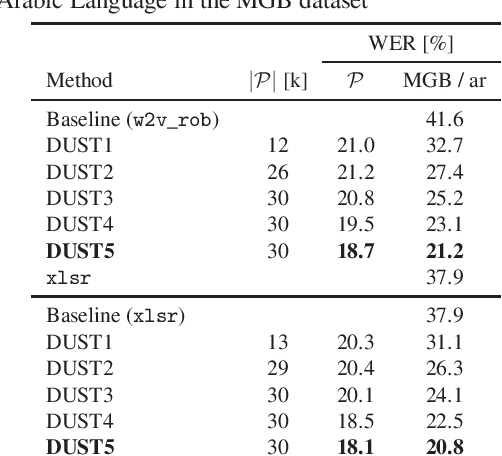
We propose a simple and effective cross-lingual transfer learning method to adapt monolingual wav2vec-2.0 models for Automatic Speech Recognition (ASR) in resource-scarce languages. We show that a monolingual wav2vec-2.0 is a good few-shot ASR learner in several languages. We improve its performance further via several iterations of Dropout Uncertainty-Driven Self-Training (DUST) by using a moderate-sized unlabeled speech dataset in the target language. A key finding of this work is that the adapted monolingual wav2vec-2.0 achieves similar performance as the topline multilingual XLSR model, which is trained on fifty-three languages, on the target language ASR task.
Overlapping Community Detection in Temporal Text Networks
Jan 13, 2021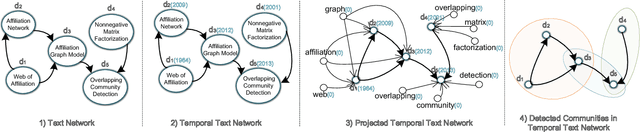
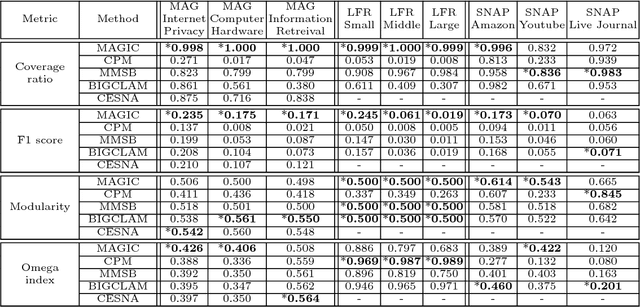
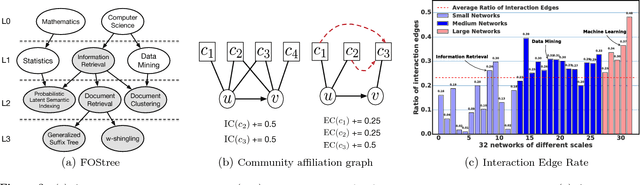

Analyzing the groups in the network based on same attributes, functions or connections between nodes is a way to understand network information. The task of discovering a series of node groups is called community detection. Generally, two types of information can be utilized to fulfill this task, i.e., the link structures and the node attributes. The temporal text network is a special kind of network that contains both sources of information. Typical representatives include online blog networks, the World Wide Web (WWW) and academic citation networks. In this paper, we study the problem of overlapping community detection in temporal text network. By examining 32 large temporal text networks, we find a lot of edges connecting two nodes with no common community and discover that nodes in the same community share similar textual contents. This scenario cannot be quantitatively modeled by practically all existing community detection methods. Motivated by these empirical observations, we propose MAGIC (Model Affiliation Graph with Interacting Communities), a generative model which captures community interactions and considers the information from both link structures and node attributes. Our experiments on 3 types of datasets show that MAGIC achieves large improvements over 4 state-of-the-art methods in terms of 4 widely-used metrics.
Polynomial magic! Hermite polynomials for private data generation
Jun 09, 2021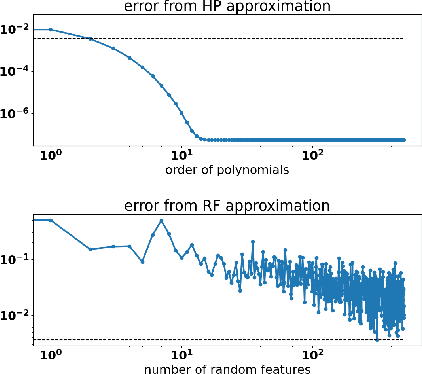

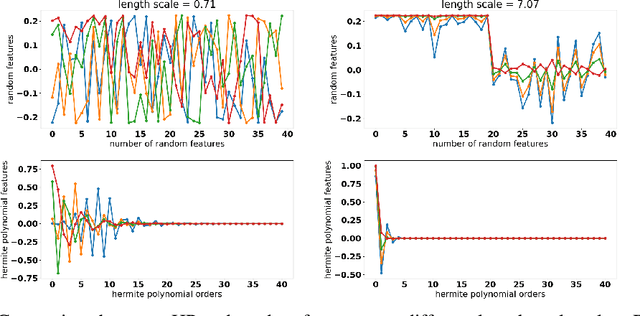
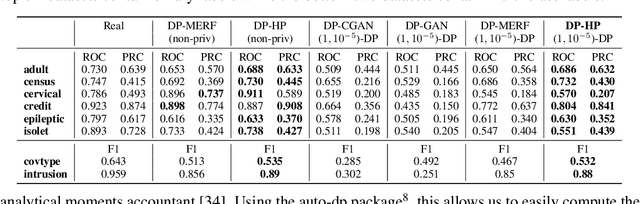
Kernel mean embedding is a useful tool to compare probability measures. Despite its usefulness, kernel mean embedding considers infinite-dimensional features, which are challenging to handle in the context of differentially private data generation. A recent work proposes to approximate the kernel mean embedding of data distribution using finite-dimensional random features, where the sensitivity of the features becomes analytically tractable. More importantly, this approach significantly reduces the privacy cost, compared to other known privatization methods (e.g., DP-SGD), as the approximate kernel mean embedding of the data distribution is privatized only once and can then be repeatedly used during training of a generator without incurring any further privacy cost. However, the required number of random features is excessively high, often ten thousand to a hundred thousand, which worsens the sensitivity of the approximate kernel mean embedding. To improve the sensitivity, we propose to replace random features with Hermite polynomial features. Unlike the random features, the Hermite polynomial features are ordered, where the features at the low orders contain more information on the distribution than those at the high orders. Hence, a relatively low order of Hermite polynomial features can more accurately approximate the mean embedding of the data distribution compared to a significantly higher number of random features. As a result, using the Hermite polynomial features, we significantly improve the privacy-accuracy trade-off, reflected in the high quality and diversity of the generated data, when tested on several heterogeneous tabular datasets, as well as several image benchmark datasets.
A Comparison of Contextual and Non-Contextual Preference Ranking for Set Addition Problems
Jul 09, 2021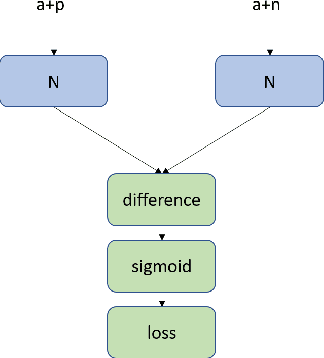
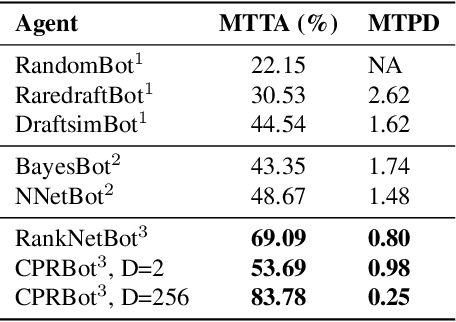
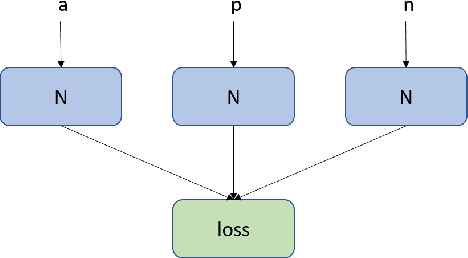
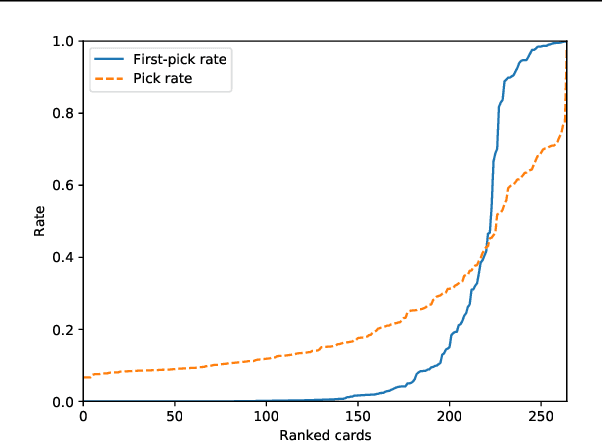
In this paper, we study the problem of evaluating the addition of elements to a set. This problem is difficult, because it can, in the general case, not be reduced to unconditional preferences between the choices. Therefore, we model preferences based on the context of the decision. We discuss and compare two different Siamese network architectures for this task: a twin network that compares the two sets resulting after the addition, and a triplet network that models the contribution of each candidate to the existing set. We evaluate the two settings on a real-world task; learning human card preferences for deck building in the collectible card game Magic: The Gathering. We show that the triplet approach achieves a better result than the twin network and that both outperform previous results on this task.
* arXiv admin note: substantial text overlap with arXiv:2105.11864
As if by magic: self-supervised training of deep despeckling networks with MERLIN
Nov 15, 2021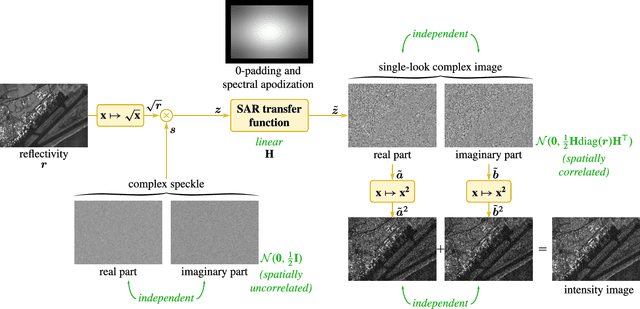
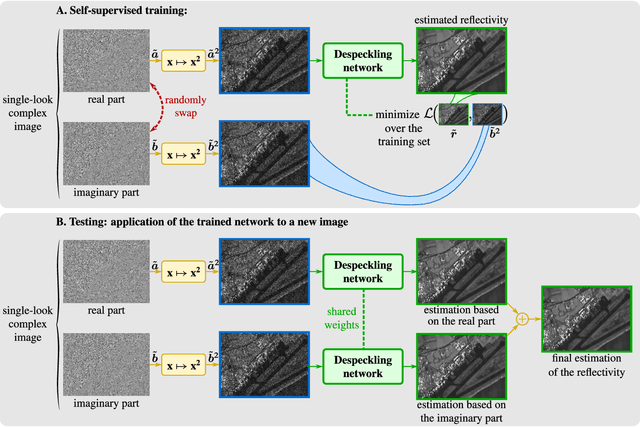


Speckle fluctuations seriously limit the interpretability of synthetic aperture radar (SAR) images. Speckle reduction has thus been the subject of numerous works spanning at least four decades. Techniques based on deep neural networks have recently achieved a new level of performance in terms of SAR image restoration quality. Beyond the design of suitable network architectures or the selection of adequate loss functions, the construction of training sets is of uttermost importance. So far, most approaches have considered a supervised training strategy: the networks are trained to produce outputs as close as possible to speckle-free reference images. Speckle-free images are generally not available, which requires resorting to natural or optical images or the selection of stable areas in long time series to circumvent the lack of ground truth. Self-supervision, on the other hand, avoids the use of speckle-free images. We introduce a self-supervised strategy based on the separation of the real and imaginary parts of single-look complex SAR images, called MERLIN (coMplex sElf-supeRvised despeckLINg), and show that it offers a straightforward way to train all kinds of deep despeckling networks. Networks trained with MERLIN take into account the spatial correlations due to the SAR transfer function specific to a given sensor and imaging mode. By requiring only a single image, and possibly exploiting large archives, MERLIN opens the door to hassle-free as well as large-scale training of despeckling networks. The code of the trained models is made freely available at https://gitlab.telecom-paris.fr/RING/MERLIN.
Ridge Regularizaton: an Essential Concept in Data Science
May 30, 2020
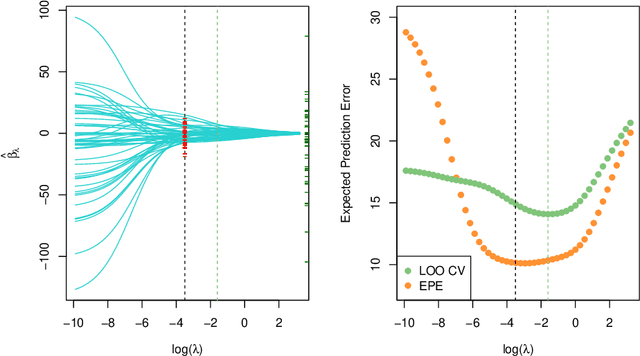
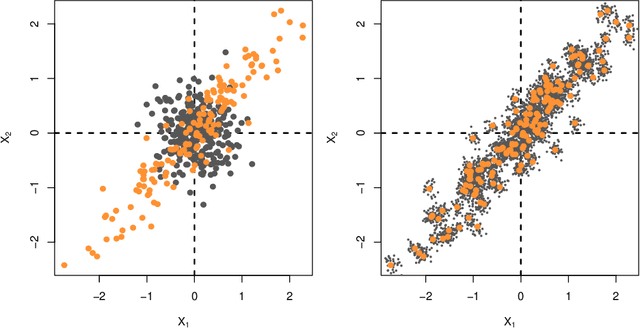
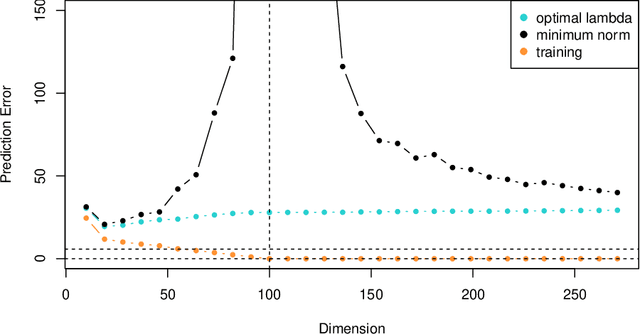
Ridge or more formally $\ell_2$ regularization shows up in many areas of statistics and machine learning. It is one of those essential devices that any good data scientist needs to master for their craft. In this brief ridge fest I have collected together some of the magic and beauty of ridge that my colleagues and I have encountered over the past 40 years in applied statistics.