 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"magic": models, code, and papers
Selective Magic HPSG Parsing
Jul 08, 1999
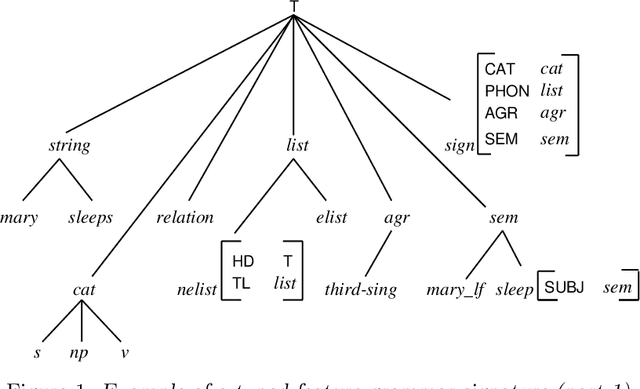
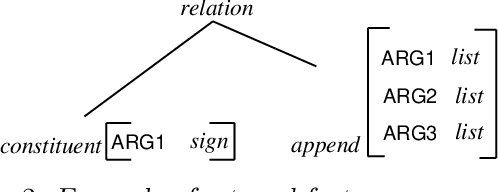
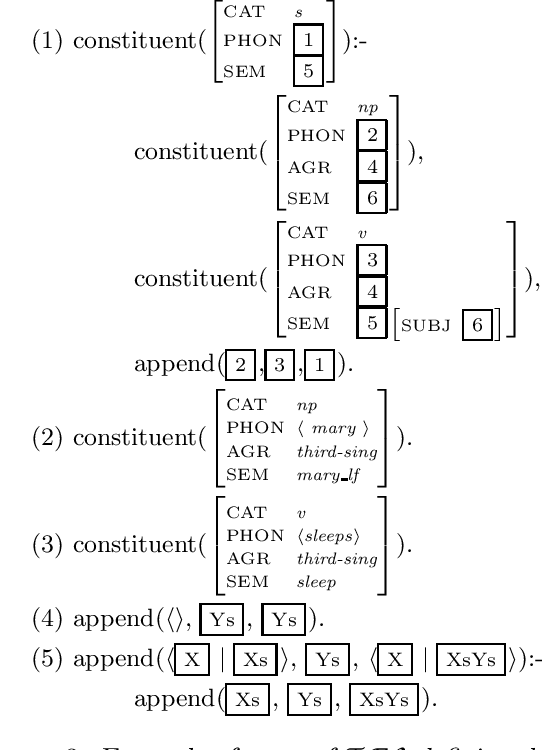
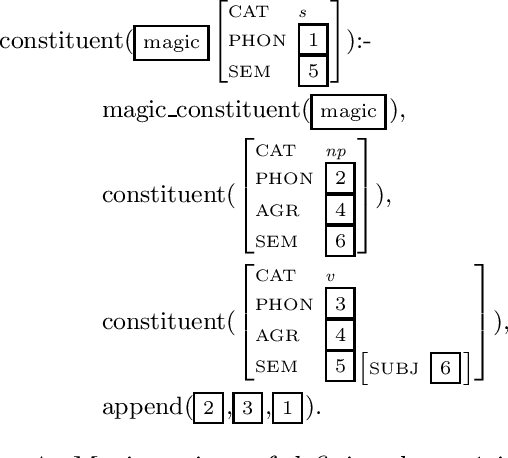
We propose a parser for constraint-logic grammars implementing HPSG that combines the advantages of dynamic bottom-up and advanced top-down control. The parser allows the user to apply magic compilation to specific constraints in a grammar which as a result can be processed dynamically in a bottom-up and goal-directed fashion. State of the art top-down processing techniques are used to deal with the remaining constraints. We discuss various aspects concerning the implementation of the parser as part of a grammar development system.
* 9 pages, LaTeX with 4 postscript figures (uses avm.sty, eaclap.sty and psfig-scale.sty)
Neural Networks Models for Analyzing Magic: the Gathering Cards
Oct 08, 2018
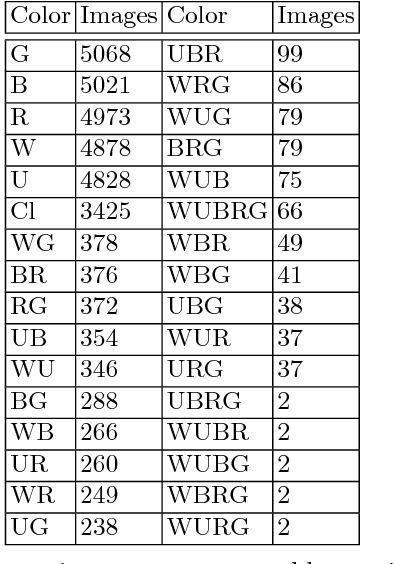
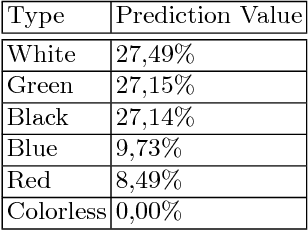

Historically, games of all kinds have often been the subject of study in scientific works of Computer Science, including the field of machine learning. By using machine learning techniques and applying them to a game with defined rules or a structured dataset, it's possible to learn and improve on the already existing techniques and methods to tackle new challenges and solve problems that are out of the ordinary. The already existing work on card games tends to focus on gameplay and card mechanics. This work aims to apply neural networks models, including Convolutional Neural Networks and Recurrent Neural Networks, in order to analyze Magic: the Gathering cards, both in terms of card text and illustrations; the card images and texts are used to train the networks in order to be able to classify them into multiple categories. The ultimate goal was to develop a methodology that could generate card text matching it to an input image, which was attained by relating the prediction values of the images and generated text across the different categories.
Time-of-Day Neural Style Transfer for Architectural Photographs
Sep 13, 2022

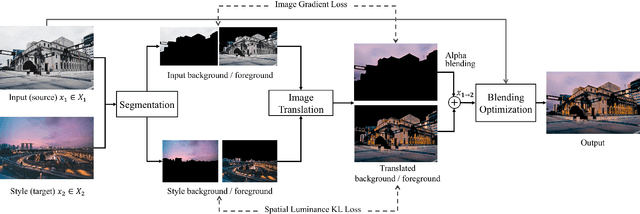

Architectural photography is a genre of photography that focuses on capturing a building or structure in the foreground with dramatic lighting in the background. Inspired by recent successes in image-to-image translation methods, we aim to perform style transfer for architectural photographs. However, the special composition in architectural photography poses great challenges for style transfer in this type of photographs. Existing neural style transfer methods treat the architectural images as a single entity, which would generate mismatched chrominance and destroy geometric features of the original architecture, yielding unrealistic lighting, wrong color rendition, and visual artifacts such as ghosting, appearance distortion, or color mismatching. In this paper, we specialize a neural style transfer method for architectural photography. Our method addresses the composition of the foreground and background in an architectural photograph in a two-branch neural network that separately considers the style transfer of the foreground and the background, respectively. Our method comprises a segmentation module, a learning-based image-to-image translation module, and an image blending optimization module. We trained our image-to-image translation neural network with a new dataset of unconstrained outdoor architectural photographs captured at different magic times of a day, utilizing additional semantic information for better chrominance matching and geometry preservation. Our experiments show that our method can produce photorealistic lighting and color rendition on both the foreground and background, and outperforms general image-to-image translation and arbitrary style transfer baselines quantitatively and qualitatively. Our code and data are available at https://github.com/hkust-vgd/architectural_style_transfer.
Improving Generalization of Deep Reinforcement Learning-based TSP Solvers
Oct 06, 2021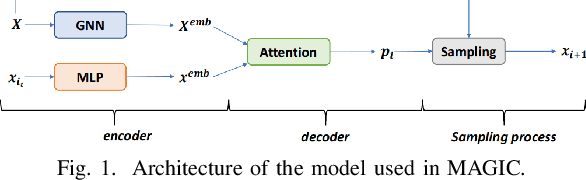
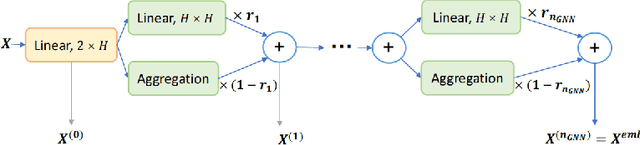
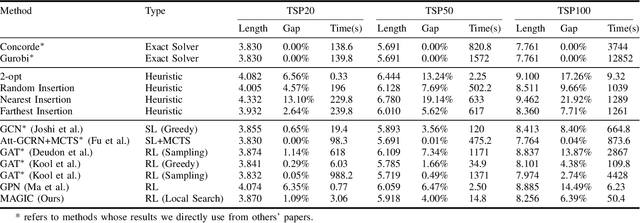
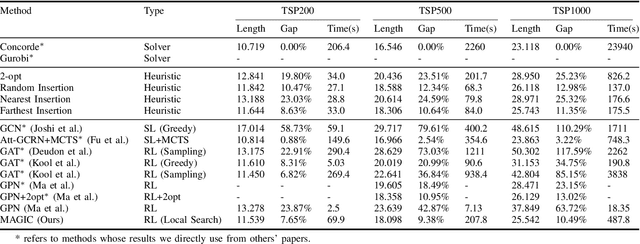
Recent work applying deep reinforcement learning (DRL) to solve traveling salesman problems (TSP) has shown that DRL-based solvers can be fast and competitive with TSP heuristics for small instances, but do not generalize well to larger instances. In this work, we propose a novel approach named MAGIC that includes a deep learning architecture and a DRL training method. Our architecture, which integrates a multilayer perceptron, a graph neural network, and an attention model, defines a stochastic policy that sequentially generates a TSP solution. Our training method includes several innovations: (1) we interleave DRL policy gradient updates with local search (using a new local search technique), (2) we use a novel simple baseline, and (3) we apply curriculum learning. Finally, we empirically demonstrate that MAGIC is superior to other DRL-based methods on random TSP instances, both in terms of performance and generalizability. Moreover, our method compares favorably against TSP heuristics and other state-of-the-art approach in terms of performance and computational time.
Motion Planning and Control for Multi Vehicle Autonomous Racing at High Speeds
Jul 22, 2022
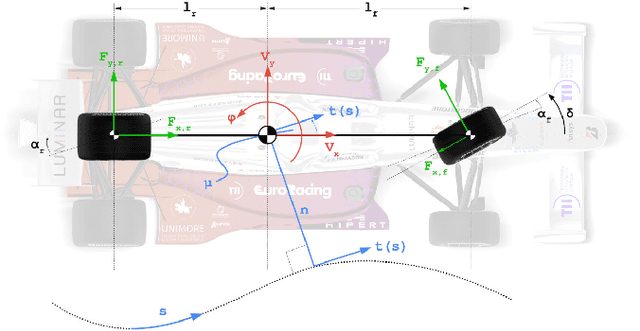
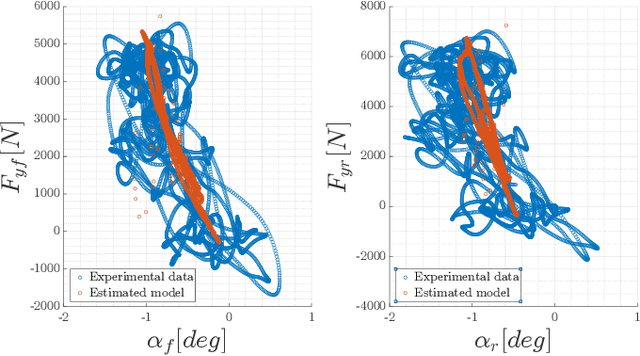
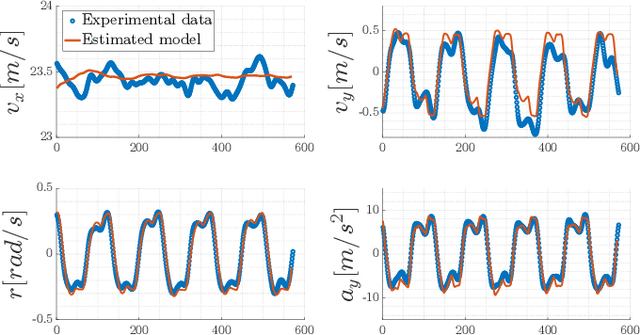
This paper presents a multi-layer motion planning and control architecture for autonomous racing, capable of avoiding static obstacles, performing active overtakes, and reaching velocities above 75 $m/s$. The used offline global trajectory generation and the online model predictive controller are highly based on optimization and dynamic models of the vehicle, where the tires and camber effects are represented in an extended version of the basic Pacejka Magic Formula. The proposed single-track model is identified and validated using multi-body motorsport libraries which allow simulating the vehicle dynamics properly, especially useful when real experimental data are missing. The fundamental regularization terms and constraints of the controller are tuned to reduce the rate of change of the inputs while assuring an acceptable velocity and path tracking. The motion planning strategy consists of a Fren\'et-Frame-based planner which considers a forecast of the opponent produced by a Kalman filter. The planner chooses the collision-free path and velocity profile to be tracked on a 3 seconds horizon to realize different goals such as following and overtaking. The proposed solution has been applied on a Dallara AV-21 racecar and tested at oval race tracks achieving lateral accelerations up to 25 $m/s^{2}$.
Exploring Classic Quantitative Strategies
Feb 23, 2022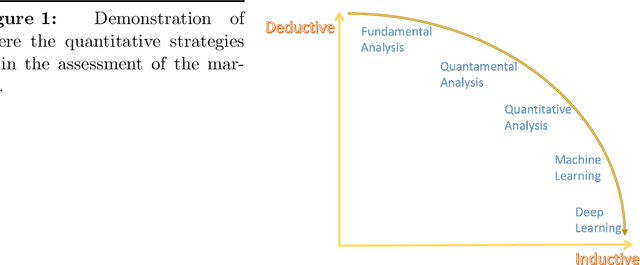
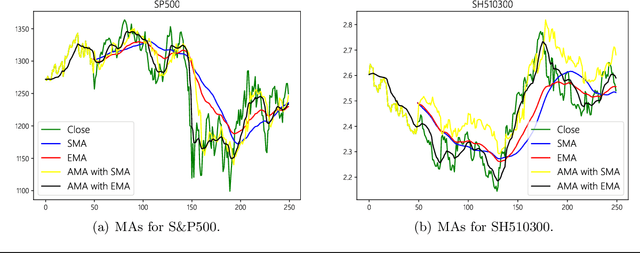
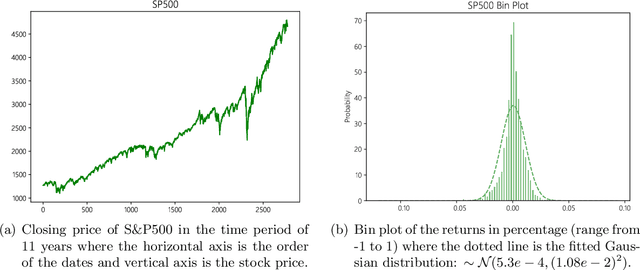
The goal of this paper is to debunk and dispel the magic behind the black-box quantitative strategies. It aims to build a solid foundation on how and why the techniques work. This manuscript crystallizes this knowledge by deriving from simple intuitions, the mathematics behind the strategies. This tutorial doesn't shy away from addressing both the formal and informal aspects of quantitative strategies. By doing so, it hopes to provide readers with a deeper understanding of these techniques as well as the when, the how and the why of applying these techniques. The strategies are presented in terms of both S\&P500 and SH510300 data sets. However, the results from the tests are just examples of how the methods work; no claim is made on the suggestion of real market positions.
3D Magic Mirror: Clothing Reconstruction from a Single Image via a Causal Perspective
Apr 27, 2022
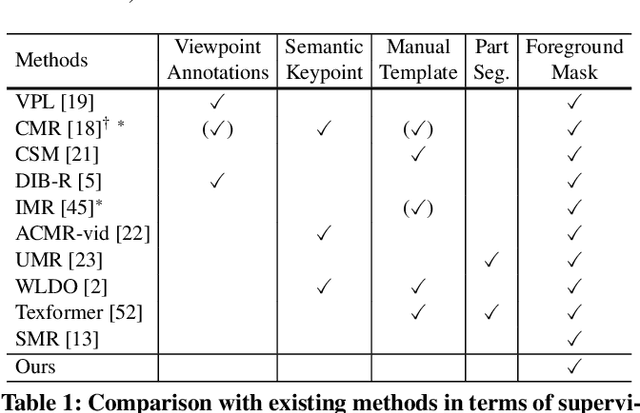
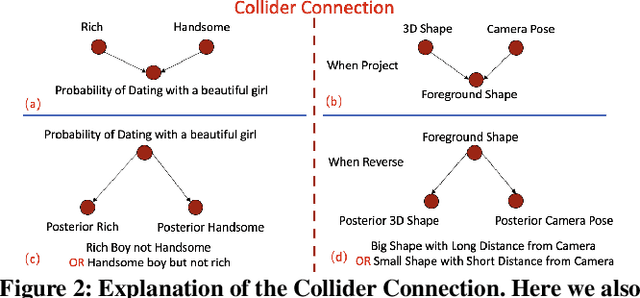

This research aims to study a self-supervised 3D clothing reconstruction method, which recovers the geometry shape, and texture of human clothing from a single 2D image. Compared with existing methods, we observe that three primary challenges remain: (1) the conventional template-based methods are limited to modeling non-rigid clothing objects, e.g., handbags and dresses, which are common in fashion images; (2) 3D ground-truth meshes of clothing are usually inaccessible due to annotation difficulties and time costs. (3) It remains challenging to simultaneously optimize four reconstruction factors, i.e., camera viewpoint, shape, texture, and illumination. The inherent ambiguity compromises the model training, such as the dilemma between a large shape with a remote camera or a small shape with a close camera. In an attempt to address the above limitations, we propose a causality-aware self-supervised learning method to adaptively reconstruct 3D non-rigid objects from 2D images without 3D annotations. In particular, to solve the inherent ambiguity among four implicit variables, i.e., camera position, shape, texture, and illumination, we study existing works and introduce an explainable structural causal map (SCM) to build our model. The proposed model structure follows the spirit of the causal map, which explicitly considers the prior template in the camera estimation and shape prediction. When optimization, the causality intervention tool, i.e., two expectation-maximization loops, is deeply embedded in our algorithm to (1) disentangle four encoders and (2) help the prior template update. Extensive experiments on two 2D fashion benchmarks, e.g., ATR, and Market-HQ, show that the proposed method could yield high-fidelity 3D reconstruction. Furthermore, we also verify the scalability of the proposed method on a fine-grained bird dataset, i.e., CUB.
A Machine Learning Imaging Core using Separable FIR-IIR Filters
Jan 02, 2020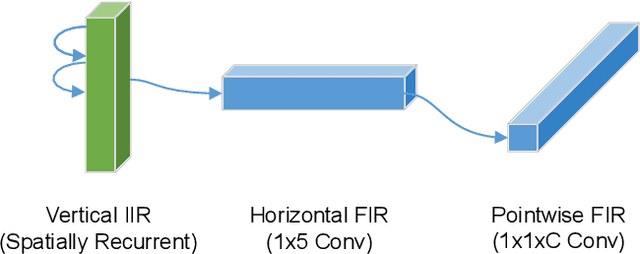
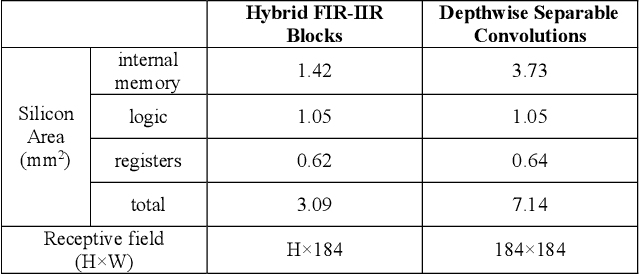
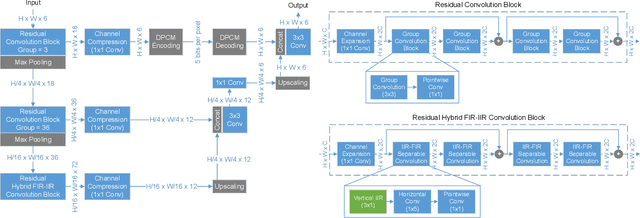
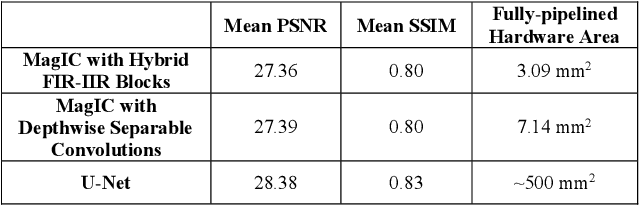
We propose fixed-function neural network hardware that is designed to perform pixel-to-pixel image transformations in a highly efficient way. We use a fully trainable, fixed-topology neural network to build a model that can perform a wide variety of image processing tasks. Our model uses compressed skip lines and hybrid FIR-IIR blocks to reduce the latency and hardware footprint. Our proposed Machine Learning Imaging Core, dubbed MagIC, uses a silicon area of ~3mm^2 (in TSMC 16nm), which is orders of magnitude smaller than a comparable pixel-wise dense prediction model. MagIC requires no DDR bandwidth, no SRAM, and practically no external memory. Each MagIC core consumes 56mW (215 mW max power) at 500MHz and achieves an energy-efficient throughput of 23TOPS/W/mm^2. MagIC can be used as a multi-purpose image processing block in an imaging pipeline, approximating compute-heavy image processing applications, such as image deblurring, denoising, and colorization, within the power and silicon area limits of mobile devices.
Gradient Descent, Stochastic Optimization, and Other Tales
May 02, 2022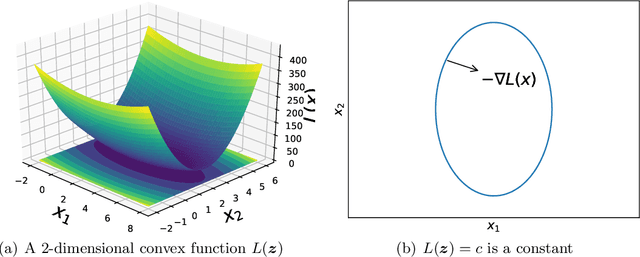
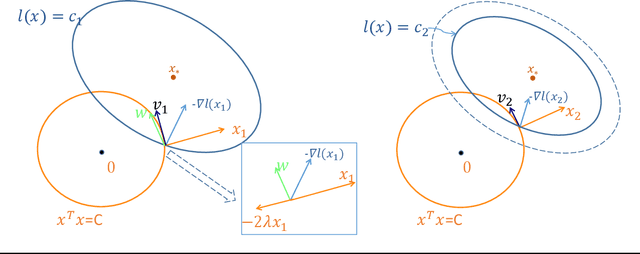

The goal of this paper is to debunk and dispel the magic behind black-box optimizers and stochastic optimizers. It aims to build a solid foundation on how and why the techniques work. This manuscript crystallizes this knowledge by deriving from simple intuitions, the mathematics behind the strategies. This tutorial doesn't shy away from addressing both the formal and informal aspects of gradient descent and stochastic optimization methods. By doing so, it hopes to provide readers with a deeper understanding of these techniques as well as the when, the how and the why of applying these algorithms. Gradient descent is one of the most popular algorithms to perform optimization and by far the most common way to optimize machine learning tasks. Its stochastic version receives attention in recent years, and this is particularly true for optimizing deep neural networks. In deep neural networks, the gradient followed by a single sample or a batch of samples is employed to save computational resources and escape from saddle points. In 1951, Robbins and Monro published \textit{A stochastic approximation method}, one of the first modern treatments on stochastic optimization that estimates local gradients with a new batch of samples. And now, stochastic optimization has become a core technology in machine learning, largely due to the development of the back propagation algorithm in fitting a neural network. The sole aim of this article is to give a self-contained introduction to concepts and mathematical tools in gradient descent and stochastic optimization.
Depth Without the Magic: Inductive Bias of Natural Gradient Descent
Nov 22, 2021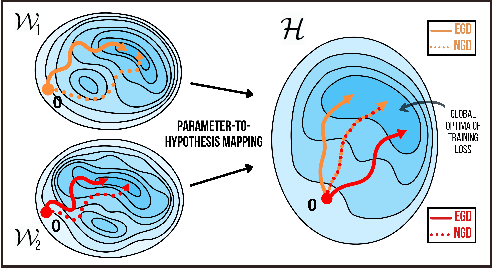
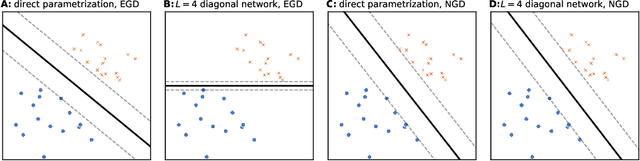
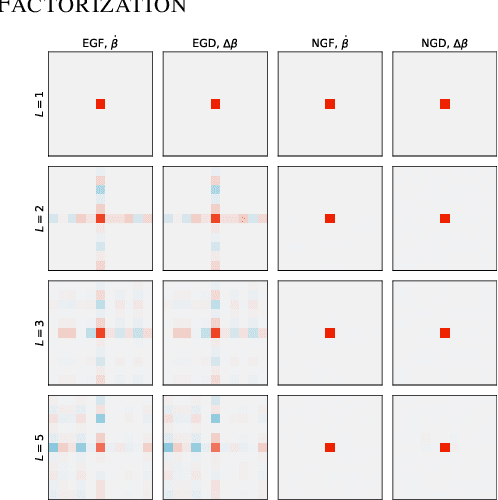
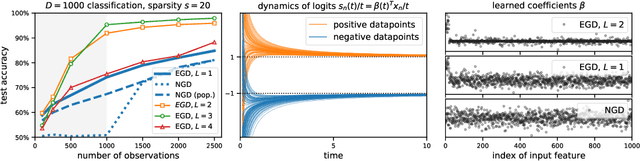
In gradient descent, changing how we parametrize the model can lead to drastically different optimization trajectories, giving rise to a surprising range of meaningful inductive biases: identifying sparse classifiers or reconstructing low-rank matrices without explicit regularization. This implicit regularization has been hypothesised to be a contributing factor to good generalization in deep learning. However, natural gradient descent is approximately invariant to reparameterization, it always follows the same trajectory and finds the same optimum. The question naturally arises: What happens if we eliminate the role of parameterization, which solution will be found, what new properties occur? We characterize the behaviour of natural gradient flow in deep linear networks for separable classification under logistic loss and deep matrix factorization. Some of our findings extend to nonlinear neural networks with sufficient but finite over-parametrization. We demonstrate that there exist learning problems where natural gradient descent fails to generalize, while gradient descent with the right architecture performs well.