 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"magic": models, code, and papers
MAGIC: Multi-scale Heterogeneity Analysis and Clustering for Brain Diseases
Jul 10, 2020
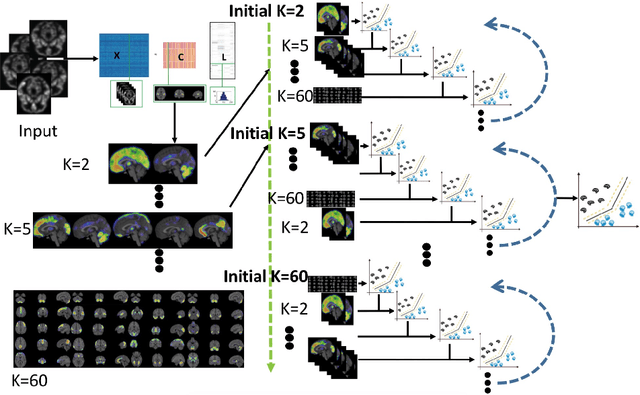
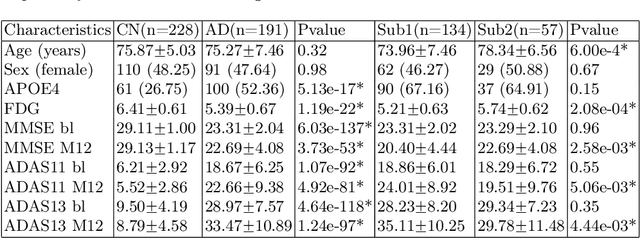
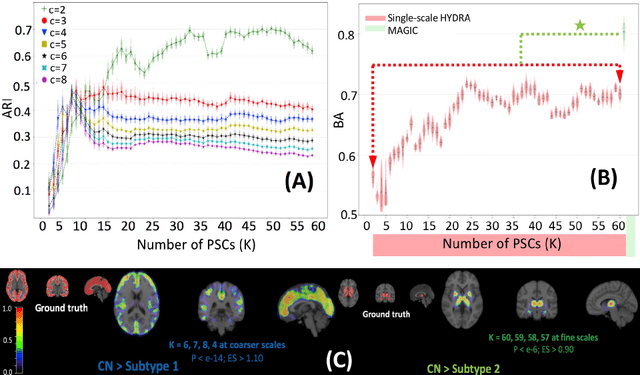
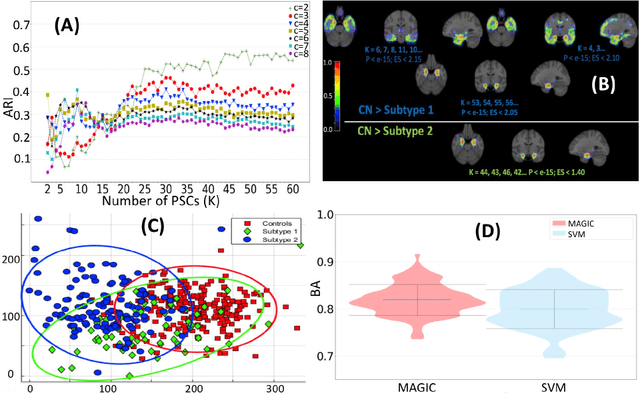
There is a growing amount of clinical, anatomical and functional evidence for the heterogeneous presentation of neuropsychiatric and neurodegenerative diseases such as schizophrenia and Alzheimers Disease (AD). Elucidating distinct subtypes of diseases allows a better understanding of neuropathogenesis and enables the possibility of developing targeted treatment programs. Recent semi-supervised clustering techniques have provided a data-driven way to understand disease heterogeneity. However, existing methods do not take into account that subtypes of the disease might present themselves at different spatial scales across the brain. Here, we introduce a novel method, MAGIC, to uncover disease heterogeneity by leveraging multi-scale clustering. We first extract multi-scale patterns of structural covariance (PSCs) followed by a semi-supervised clustering with double cyclic block-wise optimization across different scales of PSCs. We validate MAGIC using simulated heterogeneous neuroanatomical data and demonstrate its clinical potential by exploring the heterogeneity of AD using T1 MRI scans of 228 cognitively normal (CN) and 191 patients. Our results indicate two main subtypes of AD with distinct atrophy patterns that consist of both fine-scale atrophy in the hippocampus as well as large-scale atrophy in cortical regions. The evidence for the heterogeneity is further corroborated by the clinical evaluation of two subtypes, which indicates that there is a subpopulation of AD patients that tend to be younger and decline faster in cognitive performance relative to the other subpopulation, which tends to be older and maintains a relatively steady decline in cognitive abilities.
Predicting Human Card Selection in Magic: The Gathering with Contextual Preference Ranking
May 25, 2021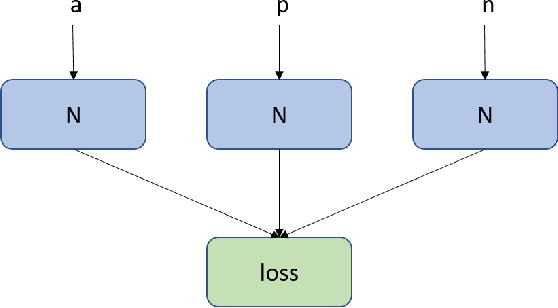
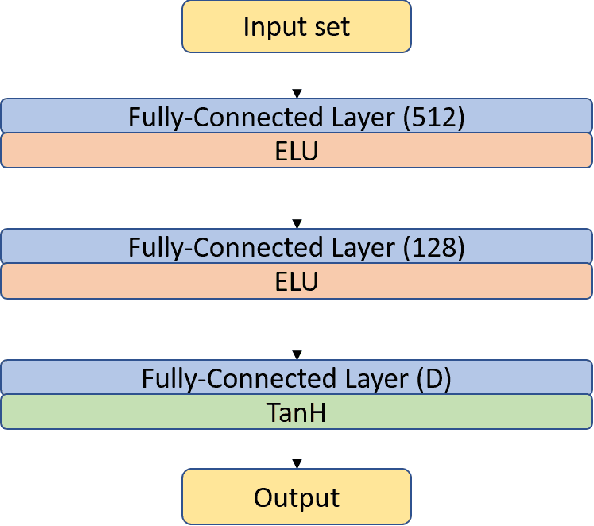
Drafting, i.e., the selection of a subset of items from a larger candidate set, is a key element of many games and related problems. It encompasses team formation in sports or e-sports, as well as deck selection in many modern card games. The key difficulty of drafting is that it is typically not sufficient to simply evaluate each item in a vacuum and to select the best items. The evaluation of an item depends on the context of the set of items that were already selected earlier, as the value of a set is not just the sum of the values of its members - it must include a notion of how well items go together. In this paper, we study drafting in the context of the card game Magic: The Gathering. We propose the use of a contextual preference network, which learns to compare two possible extensions of a given deck of cards. We demonstrate that the resulting network is better able to evaluate card decks in this game than previous attempts.
In Search of Insights, Not Magic Bullets: Towards Demystification of the Model Selection Dilemma in Heterogeneous Treatment Effect Estimation
Feb 06, 2023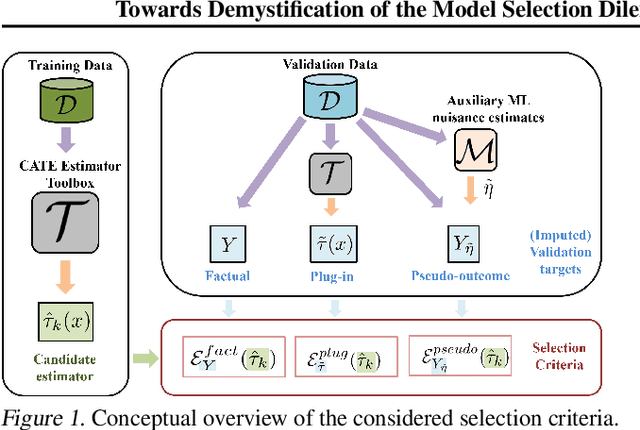
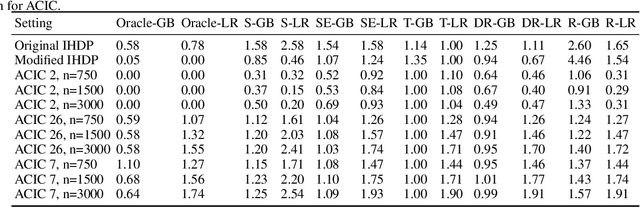

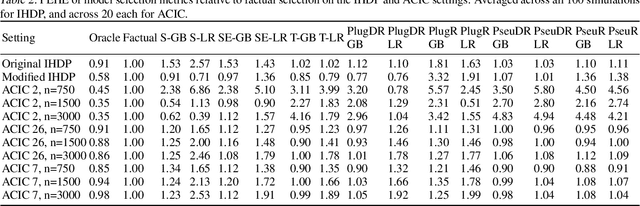
Personalized treatment effect estimates are often of interest in high-stakes applications -- thus, before deploying a model estimating such effects in practice, one needs to be sure that the best candidate from the ever-growing machine learning toolbox for this task was chosen. Unfortunately, due to the absence of counterfactual information in practice, it is usually not possible to rely on standard validation metrics for doing so, leading to a well-known model selection dilemma in the treatment effect estimation literature. While some solutions have recently been investigated, systematic understanding of the strengths and weaknesses of different model selection criteria is still lacking. In this paper, instead of attempting to declare a global `winner', we therefore empirically investigate success- and failure modes of different selection criteria. We highlight that there is a complex interplay between selection strategies, candidate estimators and the DGP used for testing, and provide interesting insights into the relative (dis)advantages of different criteria alongside desiderata for the design of further illuminating empirical studies in this context.
Exploring explicit coarse-grained structure in artificial neural networks
Nov 04, 2022
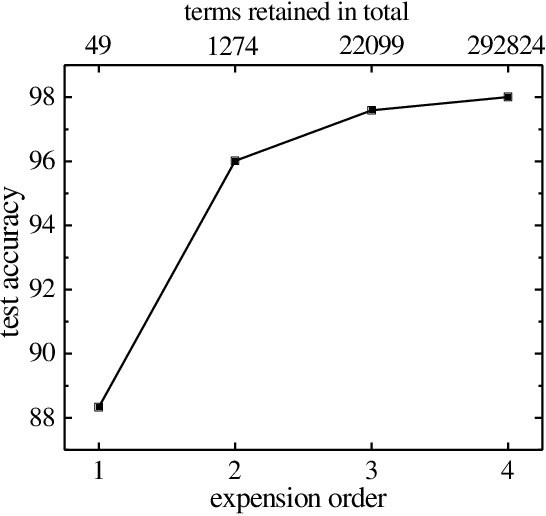
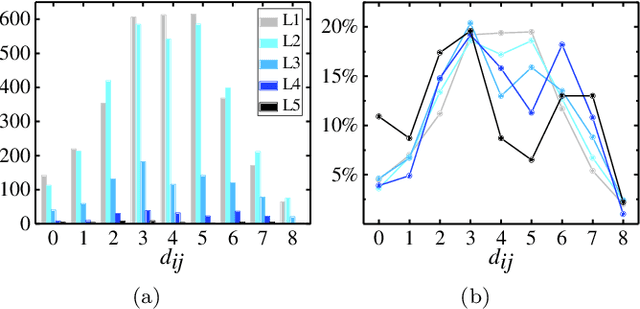
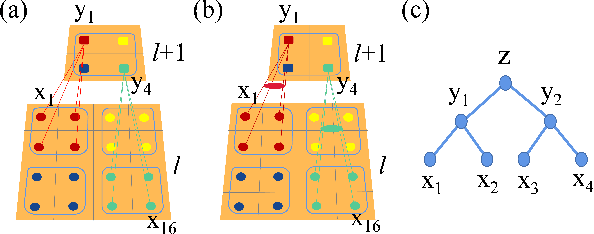
We propose to employ the hierarchical coarse-grained structure in the artificial neural networks explicitly to improve the interpretability without degrading performance. The idea has been applied in two situations. One is a neural network called TaylorNet, which aims to approximate the general mapping from input data to output result in terms of Taylor series directly, without resorting to any magic nonlinear activations. The other is a new setup for data distillation, which can perform multi-level abstraction of the input dataset and generate new data that possesses the relevant features of the original dataset and can be used as references for classification. In both cases, the coarse-grained structure plays an important role in simplifying the network and improving both the interpretability and efficiency. The validity has been demonstrated on MNIST and CIFAR-10 datasets. Further improvement and some open questions related are also discussed.
Magic: Multi Art Genre Intelligent Choreography Dataset and Network for 3D Dance Generation
Dec 08, 2022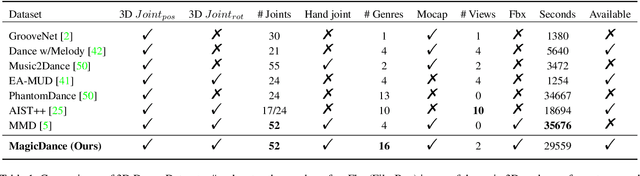
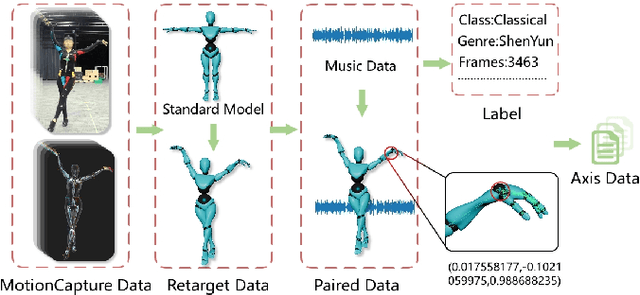
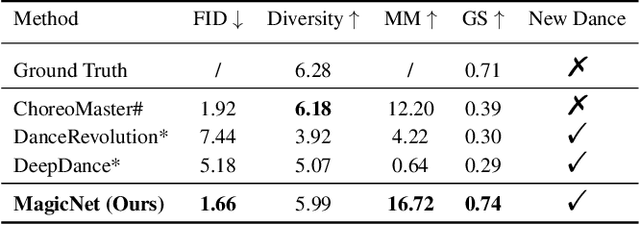
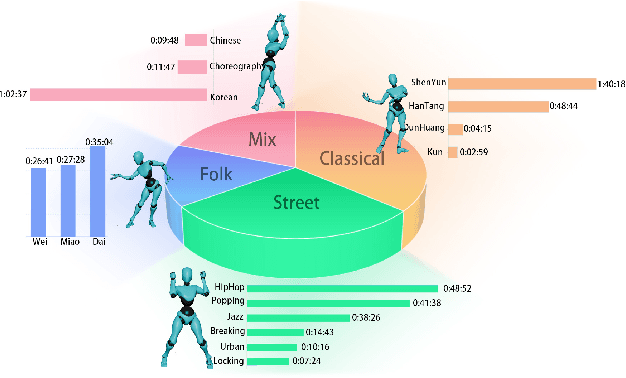
Achieving multiple genres and long-term choreography sequences from given music is a challenging task, due to the lack of a multi-genre dataset. To tackle this problem,we propose a Multi Art Genre Intelligent Choreography Dataset (MagicDance). The data of MagicDance is captured from professional dancers assisted by motion capture technicians. It has a total of 8 hours 3D motioncapture human dances with paired music, and 16 different dance genres. To the best of our knowledge, MagicDance is the 3D dance dataset with the most genres. In addition, we find that the existing two types of methods (generation-based method and synthesis-based method) can only satisfy one of the diversity and duration, but they can complement to some extent. Based on this observation, we also propose a generation-synthesis choreography network (MagicNet), which cascades a Diffusion-based 3D Diverse Dance fragments Generation Network (3DGNet) and a Genre&Coherent aware Retrieval Module (GCRM). The former can generate various dance fragments from only one music clip. The latter is utilized to select the best dance fragment generated by 3DGNet and switch them into a complete dance according to the genre and coherent matching score. Quantitative and qualitative experiments demonstrate the quality of MagicDance, and the state-of-the-art performance of MagicNet.
AI solutions for drafting in Magic: the Gathering
Sep 03, 2020

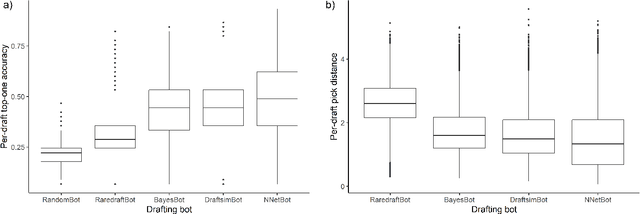
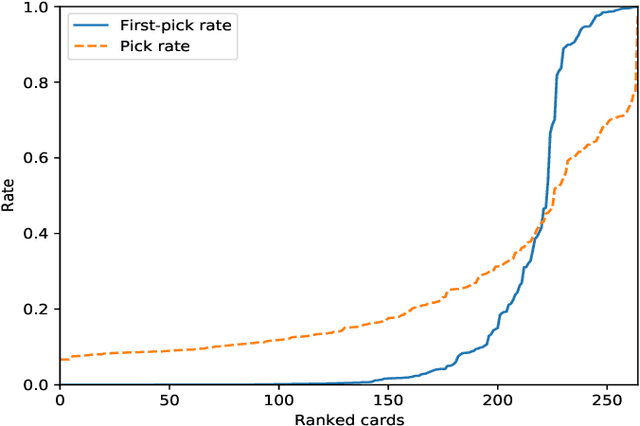
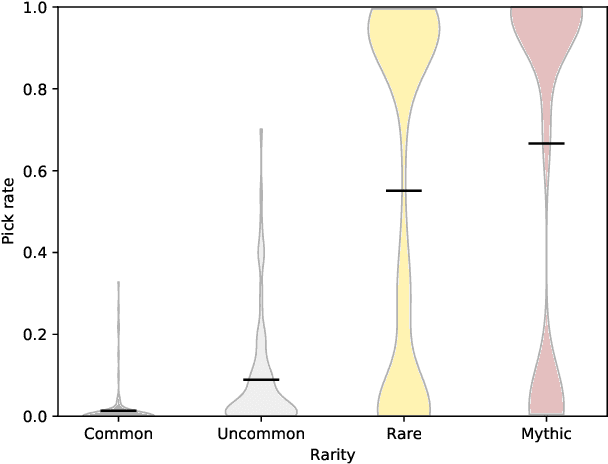
Drafting in Magic: the Gathering is a sub-game of a larger trading card game, where several players progressively build decks by picking cards from a common pool. Drafting poses an interesting problem for game-playing and AI research due to its large search space, mechanical complexity, multiplayer nature, and hidden information. Despite this, drafting remains understudied in part due to a lack of high-quality, public datasets. To rectify this problem, we present a dataset of over 100,000 simulated, anonymized human drafts collected from Draftsim.com. Additionally, we propose four diverse strategies for drafting agents, including a primitive heuristic agent, an expert-tuned complex heuristic agent, a Naive Bayes agent, and a deep neural network agent. We benchmark their ability to emulate human drafting, and show that the deep neural network agent outperforms all other agents, while Naive Bayes and expert-tuned agents outperform simple heuristics. We analyze the accuracy of AI agents across the timeline of a draft, for different cards, and in terms of approximating subtle inconsistencies of human behavior, and describe unique strengths and weaknesses for each agent. This work helps to identify next steps in the creation of humanlike drafting agents, and can serve as a set of useful benchmarks for the next generation of drafting bots.
Piloting Copilot and Codex: Hot Temperature, Cold Prompts, or Black Magic?
Oct 26, 2022
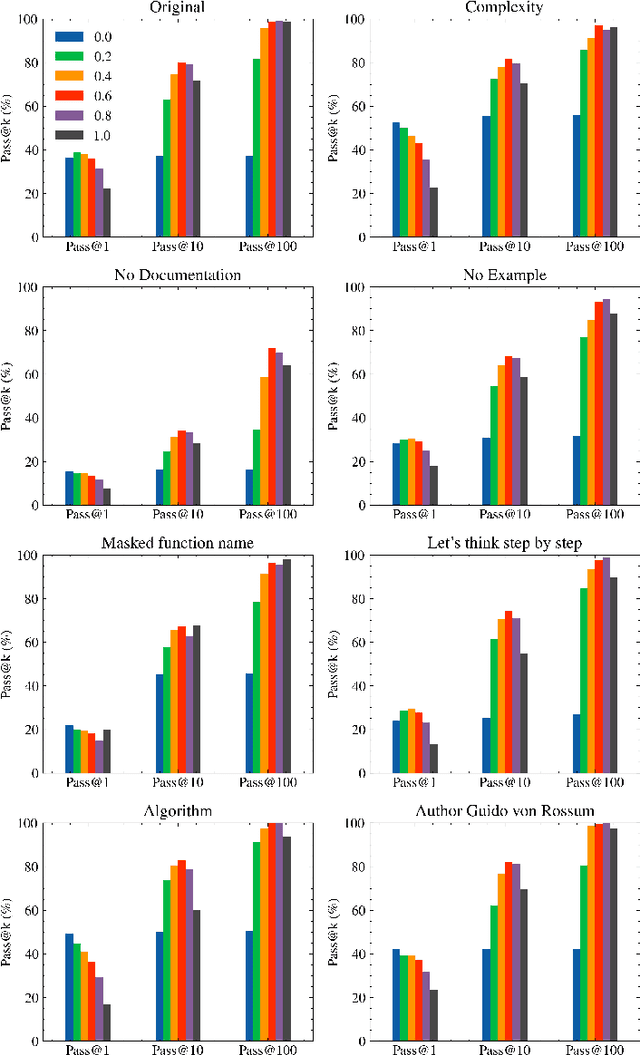
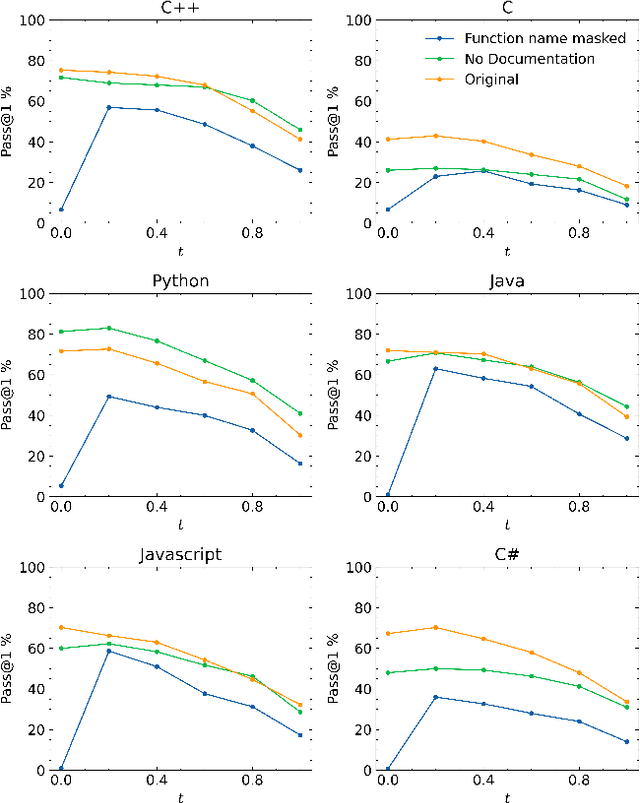

Language models are promising solutions for tackling increasing complex problems. In software engineering, they recently attracted attention in code assistants, with programs automatically written in a given programming language from a programming task description in natural language. They have the potential to save time and effort when writing code. However, these systems are currently poorly understood, preventing them from being used optimally. In this paper, we investigate the various input parameters of two language models, and conduct a study to understand if variations of these input parameters (e.g. programming task description and the surrounding context, creativity of the language model, number of generated solutions) can have a significant impact on the quality of the generated programs. We design specific operators for varying input parameters and apply them over two code assistants (Copilot and Codex) and two benchmarks representing algorithmic problems (HumanEval and LeetCode). Our results showed that varying the input parameters can significantly improve the performance of language models. However, there is a tight dependency when varying the temperature, the prompt and the number of generated solutions, making potentially hard for developers to properly control the parameters to obtain an optimal result. This work opens opportunities to propose (automated) strategies for improving performance.
Magic for Filter Optimization in Dynamic Bottom-up Processing
Apr 29, 1996
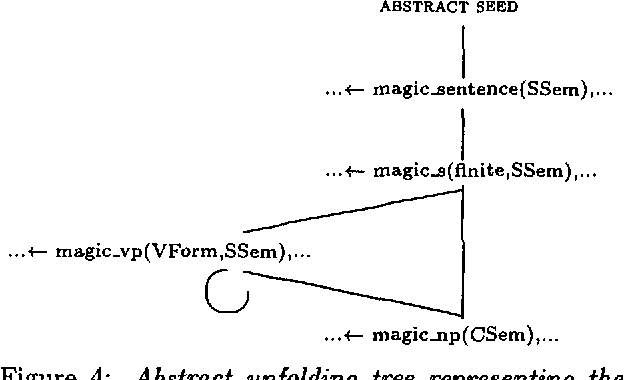

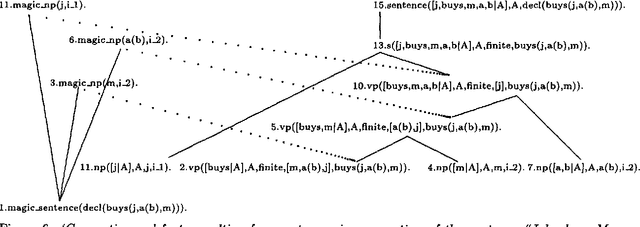
Off-line compilation of logic grammars using Magic allows an incorporation of filtering into the logic underlying the grammar. The explicit definite clause characterization of filtering resulting from Magic compilation allows processor independent and logically clean optimizations of dynamic bottom-up processing with respect to goal-directedness. Two filter optimizations based on the program transformation technique of Unfolding are discussed which are of practical and theoretical interest.
* 8 pages LaTeX (uses aclap.sty)
Selective Magic HPSG Parsing
Jul 08, 1999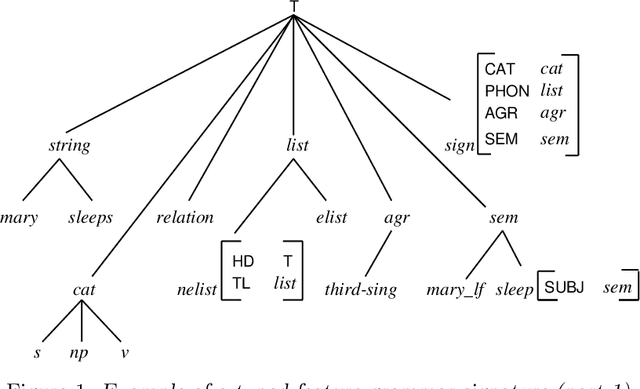
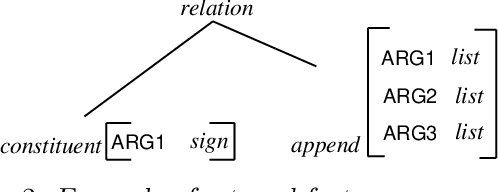
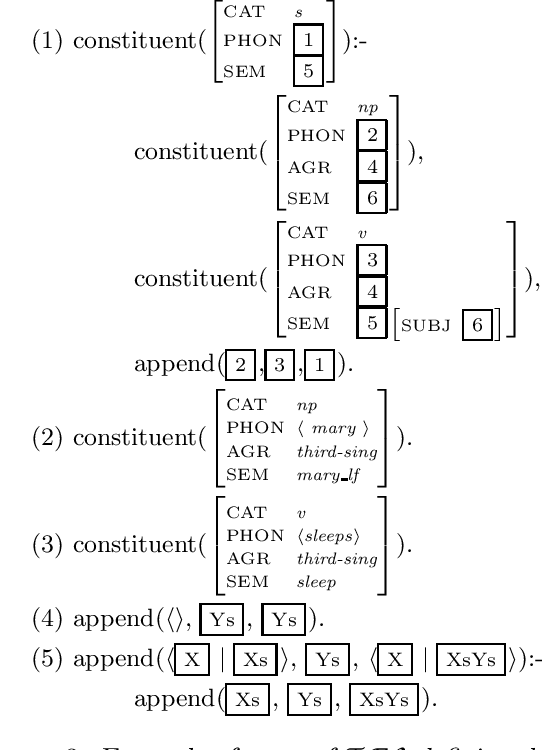
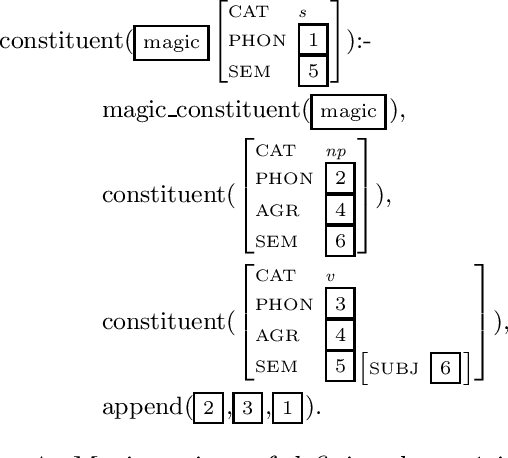
We propose a parser for constraint-logic grammars implementing HPSG that combines the advantages of dynamic bottom-up and advanced top-down control. The parser allows the user to apply magic compilation to specific constraints in a grammar which as a result can be processed dynamically in a bottom-up and goal-directed fashion. State of the art top-down processing techniques are used to deal with the remaining constraints. We discuss various aspects concerning the implementation of the parser as part of a grammar development system.
* 9 pages, LaTeX with 4 postscript figures (uses avm.sty, eaclap.sty and psfig-scale.sty)