 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"magic": models, code, and papers
MAGIC-TBR: Multiview Attention Fusion for Transformer-based Bodily Behavior Recognition in Group Settings
Sep 19, 2023
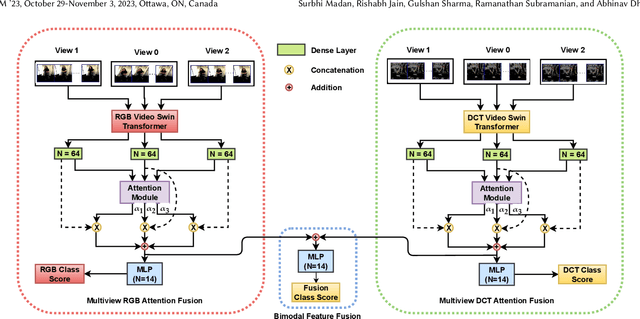



Bodily behavioral language is an important social cue, and its automated analysis helps in enhancing the understanding of artificial intelligence systems. Furthermore, behavioral language cues are essential for active engagement in social agent-based user interactions. Despite the progress made in computer vision for tasks like head and body pose estimation, there is still a need to explore the detection of finer behaviors such as gesturing, grooming, or fumbling. This paper proposes a multiview attention fusion method named MAGIC-TBR that combines features extracted from videos and their corresponding Discrete Cosine Transform coefficients via a transformer-based approach. The experiments are conducted on the BBSI dataset and the results demonstrate the effectiveness of the proposed feature fusion with multiview attention. The code is available at: https://github.com/surbhimadan92/MAGIC-TBR
Comparative Multi-View Language Grounding
Nov 14, 2023In this work, we consider the task of resolving object referents when given a comparative language description. We present a Multi-view Approach to Grounding in Context (MAGiC) that leverages transformers to pragmatically reason over both objects given multiple image views and a language description. In contrast to past efforts that attempt to connect vision and language for this task without fully considering the resulting referential context, MAGiC makes use of the comparative information by jointly reasoning over multiple views of both object referent candidates and the referring language expression. We present an analysis demonstrating that comparative reasoning contributes to SOTA performance on the SNARE object reference task.
MaGIC: Multi-modality Guided Image Completion
May 19, 2023
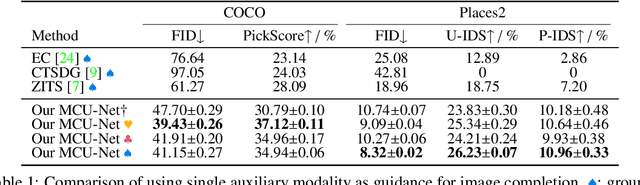
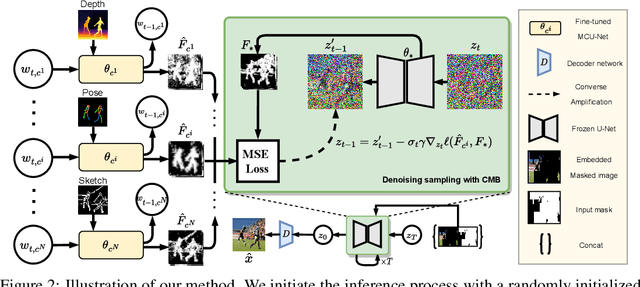
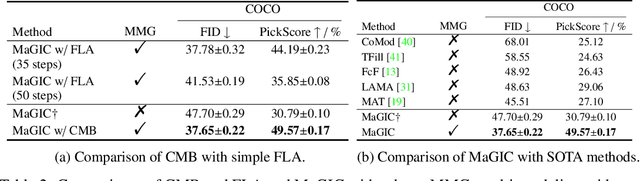
The vanilla image completion approaches are sensitive to the large missing regions due to limited available reference information for plausible generation. To mitigate this, existing methods incorporate the extra cue as a guidance for image completion. Despite improvements, these approaches are often restricted to employing a single modality (e.g., segmentation or sketch maps), which lacks scalability in leveraging multi-modality for more plausible completion. In this paper, we propose a novel, simple yet effective method for Multi-modal Guided Image Completion, dubbed MaGIC, which not only supports a wide range of single modality as the guidance (e.g., text, canny edge, sketch, segmentation, reference image, depth, and pose), but also adapts to arbitrarily customized combination of these modalities (i.e., arbitrary multi-modality) for image completion. For building MaGIC, we first introduce a modality-specific conditional U-Net (MCU-Net) that injects single-modal signal into a U-Net denoiser for single-modal guided image completion. Then, we devise a consistent modality blending (CMB) method to leverage modality signals encoded in multiple learned MCU-Nets through gradient guidance in latent space. Our CMB is training-free, and hence avoids the cumbersome joint re-training of different modalities, which is the secret of MaGIC to achieve exceptional flexibility in accommodating new modalities for completion. Experiments show the superiority of MaGIC over state-of-arts and its generalization to various completion tasks including in/out-painting and local editing. Our project with code and models is available at yeates.github.io/MaGIC-Page/.
Taking control: Policies to address extinction risks from advanced AI
Oct 31, 2023This paper provides policy recommendations to reduce extinction risks from advanced artificial intelligence (AI). First, we briefly provide background information about extinction risks from AI. Second, we argue that voluntary commitments from AI companies would be an inappropriate and insufficient response. Third, we describe three policy proposals that would meaningfully address the threats from advanced AI: (1) establishing a Multinational AGI Consortium to enable democratic oversight of advanced AI (MAGIC), (2) implementing a global cap on the amount of computing power used to train an AI system (global compute cap), and (3) requiring affirmative safety evaluations to ensure that risks are kept below acceptable levels (gating critical experiments). MAGIC would be a secure, safety-focused, internationally-governed institution responsible for reducing risks from advanced AI and performing research to safely harness the benefits of AI. MAGIC would also maintain emergency response infrastructure (kill switch) to swiftly halt AI development or withdraw model deployment in the event of an AI-related emergency. The global compute cap would end the corporate race toward dangerous AI systems while enabling the vast majority of AI innovation to continue unimpeded. Gating critical experiments would ensure that companies developing powerful AI systems are required to present affirmative evidence that these models keep extinction risks below an acceptable threshold. After describing these recommendations, we propose intermediate steps that the international community could take to implement these proposals and lay the groundwork for international coordination around advanced AI.
Behind the Magic, MERLIM: Multi-modal Evaluation Benchmark for Large Image-Language Models
Dec 03, 2023Large Vision and Language Models have enabled significant advances in fully supervised and zero-shot vision tasks. These large pre-trained architectures serve as the baseline to what is currently known as Instruction Tuning Large Vision and Language models (IT-LVLMs). IT-LVLMs are general-purpose multi-modal assistants whose responses are modulated by natural language instructions and arbitrary visual data. Despite this versatility, IT-LVLM effectiveness in fundamental computer vision problems remains unclear, primarily due to the absence of a standardized evaluation benchmark. This paper introduces a Multi-modal Evaluation Benchmark named MERLIM, a scalable test-bed to assess the performance of IT-LVLMs on fundamental computer vision tasks. MERLIM contains over 279K image-question pairs, and has a strong focus on detecting cross-modal "hallucination" events in IT-LVLMs, where the language output refers to visual concepts that lack any effective grounding in the image. Our results show that state-of-the-art IT-LVMLs are still limited at identifying fine-grained visual concepts, object hallucinations are common across tasks, and their results are strongly biased by small variations in the input query, even if the queries have the very same semantics. Our findings also suggest that these models have weak visual groundings but they can still make adequate guesses by global visual patterns or textual biases contained in the LLM component.
Learning programs with magic values
Aug 05, 2022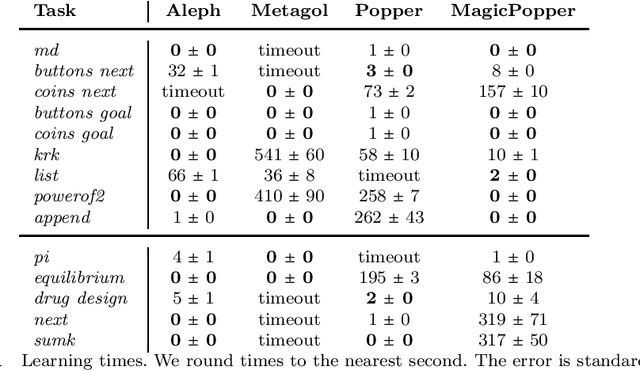
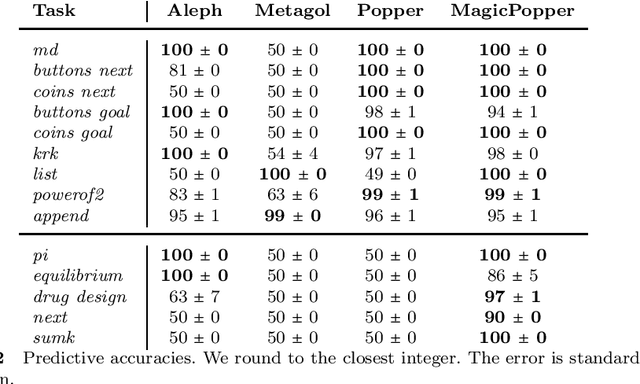
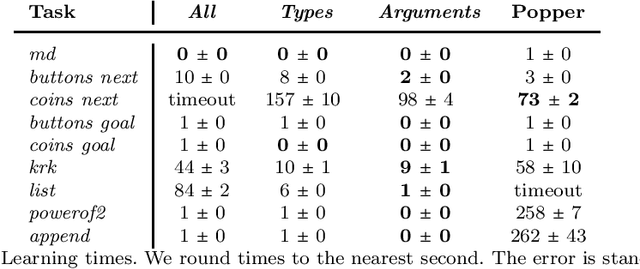
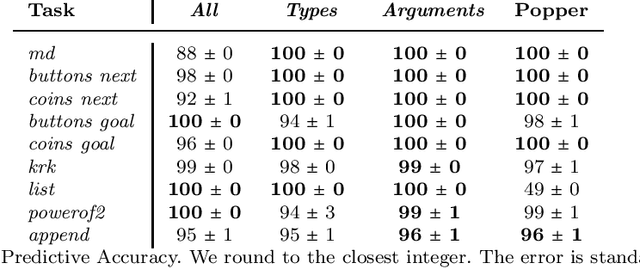
A magic value in a program is a constant symbol that is essential for the execution of the program but has no clear explanation for its choice. Learning programs with magic values is difficult for existing program synthesis approaches. To overcome this limitation, we introduce an inductive logic programming approach to efficiently learn programs with magic values. Our experiments on diverse domains, including program synthesis, drug design, and game playing, show that our approach can (i) outperform existing approaches in terms of predictive accuracies and learning times, (ii) learn magic values from infinite domains, such as the value of pi, and (iii) scale to domains with millions of constant symbols.
Unlocking Metasurface Practicality for B5G Networks: AI-assisted RIS Planning
Oct 16, 2023The advent of reconfigurable intelligent surfaces(RISs) brings along significant improvements for wireless technology on the verge of beyond-fifth-generation networks (B5G).The proven flexibility in influencing the propagation environment opens up the possibility of programmatically altering the wireless channel to the advantage of network designers, enabling the exploitation of higher-frequency bands for superior throughput overcoming the challenging electromagnetic (EM) propagation properties at these frequency bands. However, RISs are not magic bullets. Their employment comes with significant complexity, requiring ad-hoc deployments and management operations to come to fruition. In this paper, we tackle the open problem of bringing RISs to the field, focusing on areas with little or no coverage. In fact, we present a first-of-its-kind deep reinforcement learning (DRL) solution, dubbed as D-RISA, which trains a DRL agent and, in turn, obtain san optimal RIS deployment. We validate our framework in the indoor scenario of the Rennes railway station in France, assessing the performance of our algorithm against state-of-the-art (SOA) approaches. Our benchmarks showcase better coverage, i.e., 10-dB increase in minimum signal-to-noise ratio (SNR), at lower computational time (up to -25 percent) while improving scalability towards denser network deployments.
MAGIC: Microlensing Analysis Guided by Intelligent Computation
Jun 16, 2022
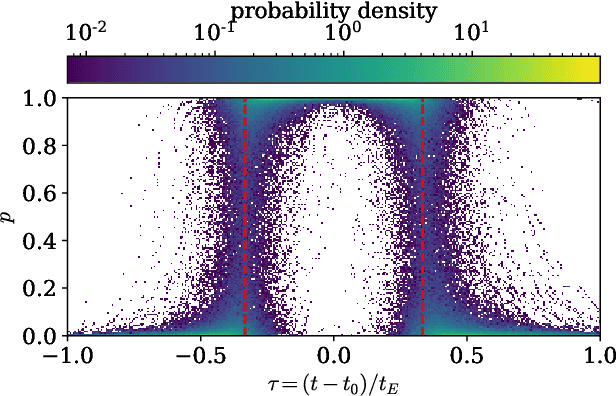

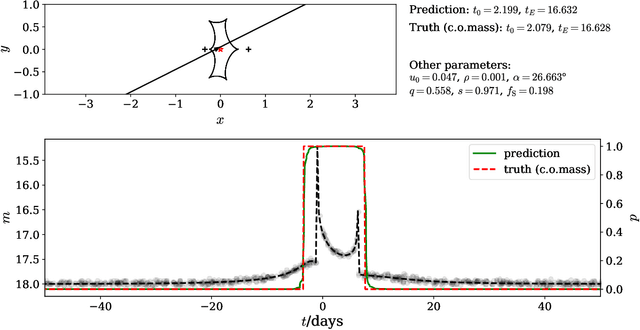
The modeling of binary microlensing light curves via the standard sampling-based method can be challenging, because of the time-consuming light curve computation and the pathological likelihood landscape in the high-dimensional parameter space. In this work, we present MAGIC, which is a machine learning framework to efficiently and accurately infer the microlensing parameters of binary events with realistic data quality. In MAGIC, binary microlensing parameters are divided into two groups and inferred separately with different neural networks. The key feature of MAGIC is the introduction of neural controlled differential equation, which provides the capability to handle light curves with irregular sampling and large data gaps. Based on simulated light curves, we show that MAGIC can achieve fractional uncertainties of a few percent on the binary mass ratio and separation. We also test MAGIC on a real microlensing event. MAGIC is able to locate the degenerate solutions even when large data gaps are introduced. As irregular samplings are common in astronomical surveys, our method also has implications to other studies that involve time series.
Mini-DALLE3: Interactive Text to Image by Prompting Large Language Models
Oct 12, 2023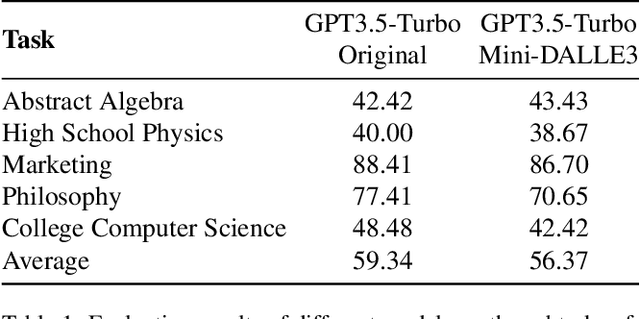
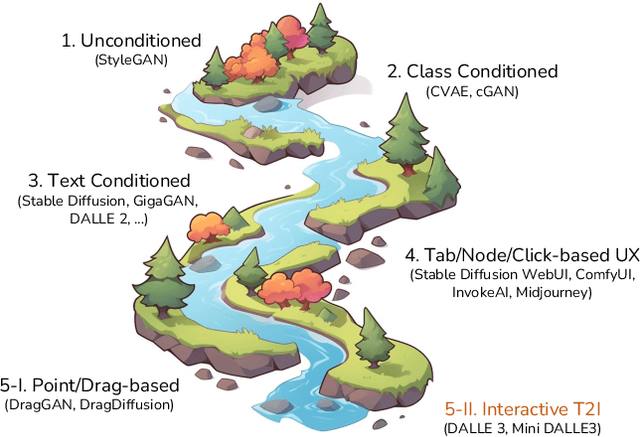
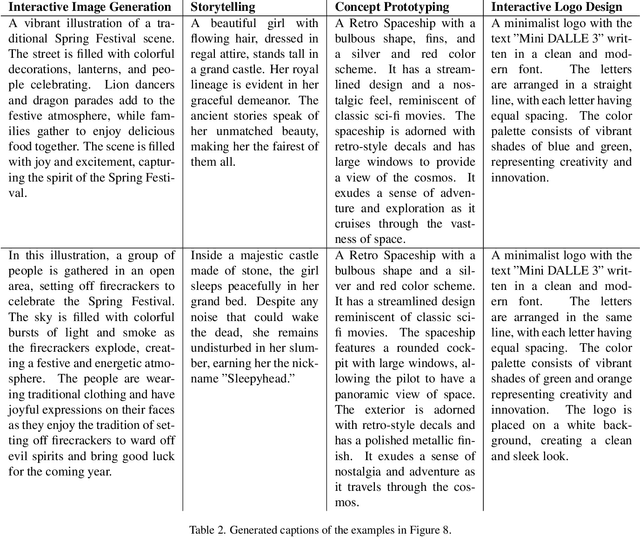

The revolution of artificial intelligence content generation has been rapidly accelerated with the booming text-to-image (T2I) diffusion models. Within just two years of development, it was unprecedentedly of high-quality, diversity, and creativity that the state-of-the-art models could generate. However, a prevalent limitation persists in the effective communication with these popular T2I models, such as Stable Diffusion, using natural language descriptions. This typically makes an engaging image hard to obtain without expertise in prompt engineering with complex word compositions, magic tags, and annotations. Inspired by the recently released DALLE3 - a T2I model directly built-in ChatGPT that talks human language, we revisit the existing T2I systems endeavoring to align human intent and introduce a new task - interactive text to image (iT2I), where people can interact with LLM for interleaved high-quality image generation/edit/refinement and question answering with stronger images and text correspondences using natural language. In addressing the iT2I problem, we present a simple approach that augments LLMs for iT2I with prompting techniques and off-the-shelf T2I models. We evaluate our approach for iT2I in a variety of common-used scenarios under different LLMs, e.g., ChatGPT, LLAMA, Baichuan, and InternLM. We demonstrate that our approach could be a convenient and low-cost way to introduce the iT2I ability for any existing LLMs and any text-to-image models without any training while bringing little degradation on LLMs' inherent capabilities in, e.g., question answering and code generation. We hope this work could draw broader attention and provide inspiration for boosting user experience in human-machine interactions alongside the image quality of the next-generation T2I systems.