 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
End-to-end Face-swapping via Adaptive Latent Representation Learning
Mar 07, 2023



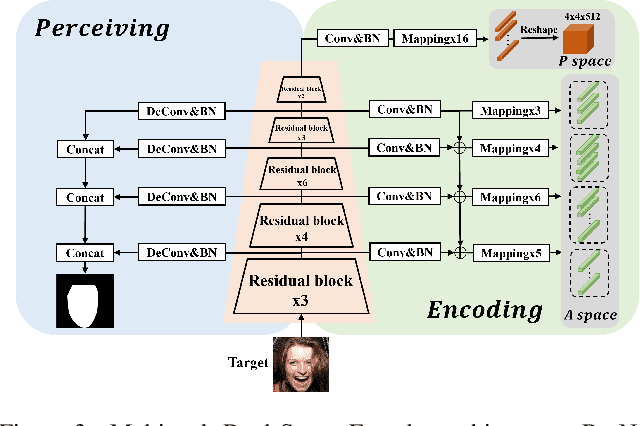
Taking full advantage of the excellent performance of StyleGAN, style transfer-based face swapping methods have been extensively investigated recently. However, these studies require separate face segmentation and blending modules for successful face swapping, and the fixed selection of the manipulated latent code in these works is reckless, thus degrading face swapping quality, generalizability, and practicability. This paper proposes a novel and end-to-end integrated framework for high resolution and attribute preservation face swapping via Adaptive Latent Representation Learning. Specifically, we first design a multi-task dual-space face encoder by sharing the underlying feature extraction network to simultaneously complete the facial region perception and face encoding. This encoder enables us to control the face pose and attribute individually, thus enhancing the face swapping quality. Next, we propose an adaptive latent codes swapping module to adaptively learn the mapping between the facial attributes and the latent codes and select effective latent codes for improved retention of facial attributes. Finally, the initial face swapping image generated by StyleGAN2 is blended with the facial region mask generated by our encoder to address the background blur problem. Our framework integrating facial perceiving and blending into the end-to-end training and testing process can achieve high realistic face-swapping on wild faces without segmentation masks. Experimental results demonstrate the superior performance of our approach over state-of-the-art methods.
Target Active Speaker Detection with Audio-visual Cues
May 22, 2023
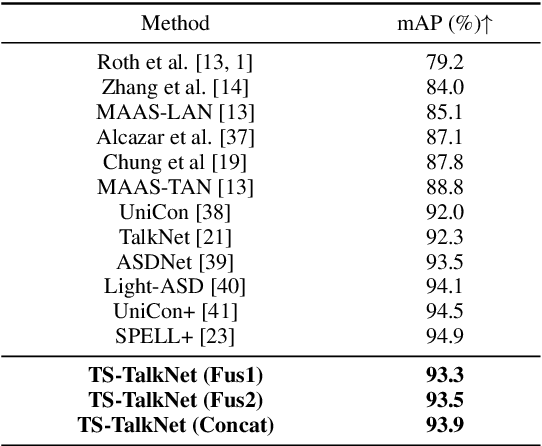
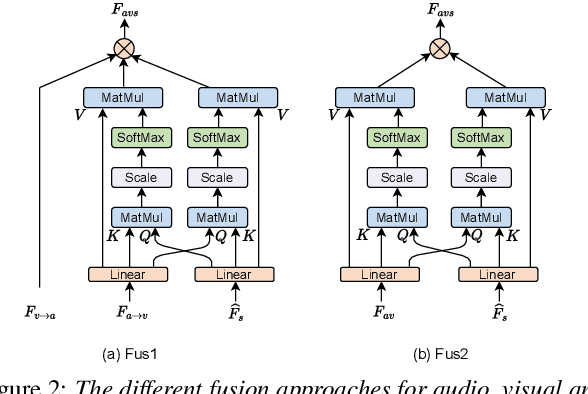
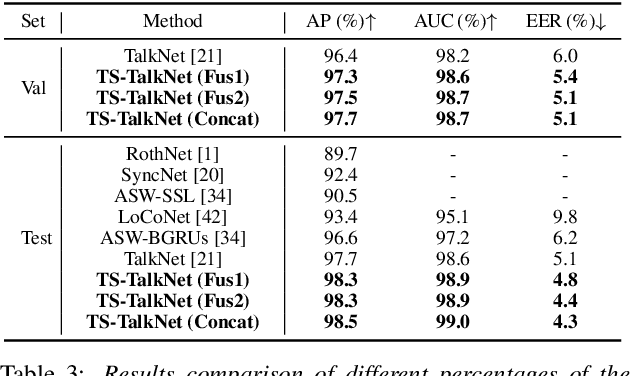
In active speaker detection (ASD), we would like to detect whether an on-screen person is speaking based on audio-visual cues. Previous studies have primarily focused on modeling audio-visual synchronization cue, which depends on the video quality of the lip region of a speaker. In real-world applications, it is possible that we can also have the reference speech of the on-screen speaker. To benefit from both facial cue and reference speech, we propose the Target Speaker TalkNet (TS-TalkNet), which leverages a pre-enrolled speaker embedding to complement the audio-visual synchronization cue in detecting whether the target speaker is speaking. Our framework outperforms the popular model, TalkNet on two datasets, achieving absolute improvements of 1.6\% in mAP on the AVA-ActiveSpeaker validation set, and 0.8\%, 0.4\%, and 0.8\% in terms of AP, AUC and EER on the ASW test set, respectively. Code is available at \href{https://github.com/Jiang-Yidi/TS-TalkNet/}{\color{red}{https://github.com/Jiang-Yidi/TS-TalkNet/}}.
Generative Watermarking Against Unauthorized Subject-Driven Image Synthesis
Jun 13, 2023
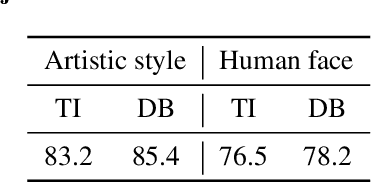
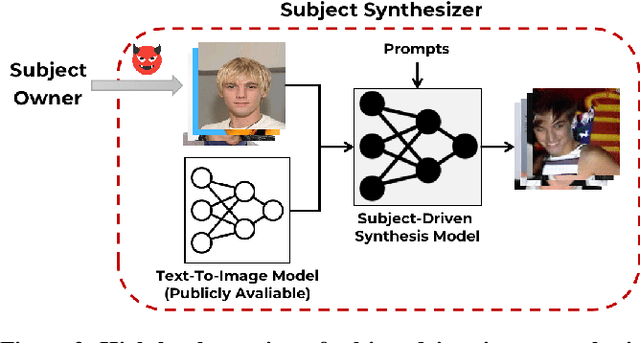
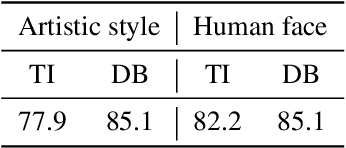
Large text-to-image models have shown remarkable performance in synthesizing high-quality images. In particular, the subject-driven model makes it possible to personalize the image synthesis for a specific subject, e.g., a human face or an artistic style, by fine-tuning the generic text-to-image model with a few images from that subject. Nevertheless, misuse of subject-driven image synthesis may violate the authority of subject owners. For example, malicious users may use subject-driven synthesis to mimic specific artistic styles or to create fake facial images without authorization. To protect subject owners against such misuse, recent attempts have commonly relied on adversarial examples to indiscriminately disrupt subject-driven image synthesis. However, this essentially prevents any benign use of subject-driven synthesis based on protected images. In this paper, we take a different angle and aim at protection without sacrificing the utility of protected images for general synthesis purposes. Specifically, we propose GenWatermark, a novel watermark system based on jointly learning a watermark generator and a detector. In particular, to help the watermark survive the subject-driven synthesis, we incorporate the synthesis process in learning GenWatermark by fine-tuning the detector with synthesized images for a specific subject. This operation is shown to largely improve the watermark detection accuracy and also ensure the uniqueness of the watermark for each individual subject. Extensive experiments validate the effectiveness of GenWatermark, especially in practical scenarios with unknown models and text prompts (74% Acc.), as well as partial data watermarking (80% Acc. for 1/4 watermarking). We also demonstrate the robustness of GenWatermark to two potential countermeasures that substantially degrade the synthesis quality.
Adaptive Local-Global Relational Network for Facial Action Units Recognition and Facial Paralysis Estimation
Mar 03, 2022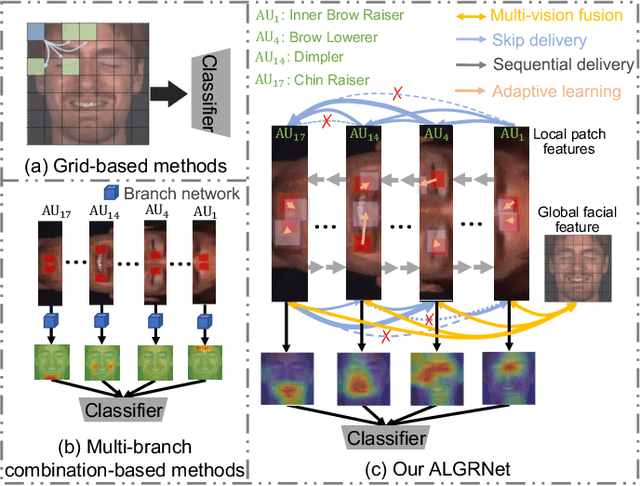
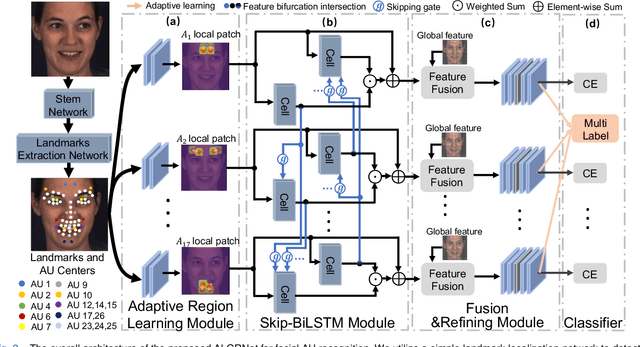
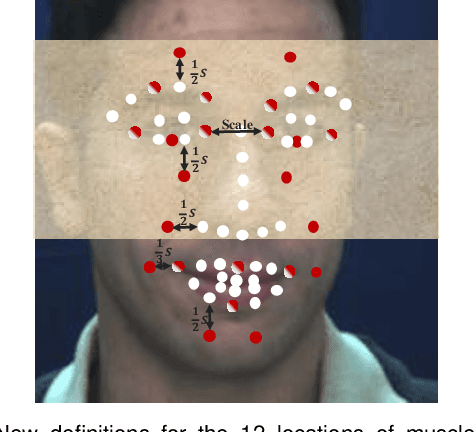
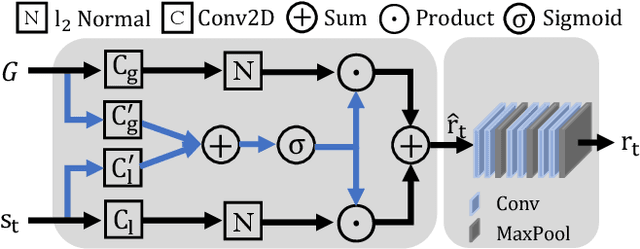
Facial action units (AUs) refer to a unique set of facial muscle movements at certain facial locations defined by the Facial Action Coding System (FACS), which can be used for describing nearly any anatomically possible facial expression. Many existing facial action units (AUs) recognition approaches often enhance the AU representation by combining local features from multiple independent branches, each corresponding to a different AU, which usually neglect potential mutual assistance and exclusion relationship between AU branches or simply employ a pre-defined and fixed knowledge-graph as a prior. In addition, extracting features from pre-defined AU regions of regular shapes limits the representation ability. In this paper, we propose a novel Adaptive Local-Global Relational Network (ALGRNet) for facial AU recognition and apply it to facial paralysis estimation. ALGRNet mainly consists of three novel structures, i.e., an adaptive region learning module which learns the adaptive muscle regions based on the detected landmarks, a skip-BiLSTM module which models the latent mutual assistance and exclusion relationship among local AU features, and a feature fusion\&refining module which explores the complementarity between local AUs and the whole face for the local AU refinement. In order to evaluate our proposed method, we migrated ALGRNet to a facial paralysis dataset which is collected and annotated by medical professionals. Experiments on the BP4D and DISFA AU datasets show that the proposed approach outperforms the state-of-the-art methods by a large margin. Additionally, we also demonstrated the effectiveness of the proposed ALGRNet in applications to facial paralysis estimation.
Child Face Recognition at Scale: Synthetic Data Generation and Performance Benchmark
Apr 23, 2023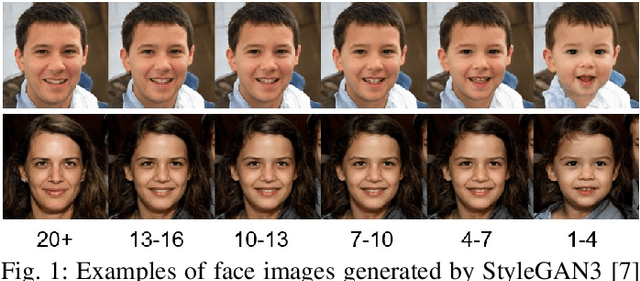


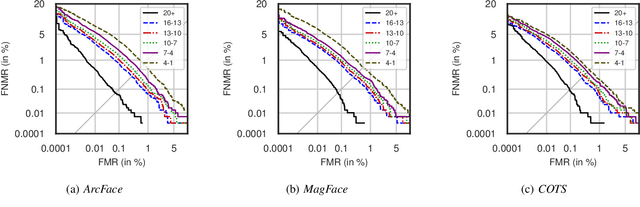
We address the need for a large-scale database of children's faces by using generative adversarial networks (GANs) and face age progression (FAP) models to synthesize a realistic dataset referred to as HDA-SynChildFaces. To this end, we proposed a processing pipeline that initially utilizes StyleGAN3 to sample adult subjects, which are subsequently progressed to children of varying ages using InterFaceGAN. Intra-subject variations, such as facial expression and pose, are created by further manipulating the subjects in their latent space. Additionally, the presented pipeline allows to evenly distribute the races of subjects, allowing to generate a balanced and fair dataset with respect to race distribution. The created HDA-SynChildFaces consists of 1,652 subjects and a total of 188,832 images, each subject being present at various ages and with many different intra-subject variations. Subsequently, we evaluates the performance of various facial recognition systems on the generated database and compare the results of adults and children at different ages. The study reveals that children consistently perform worse than adults, on all tested systems, and the degradation in performance is proportional to age. Additionally, our study uncovers some biases in the recognition systems, with Asian and Black subjects and females performing worse than White and Latino Hispanic subjects and males.
Facial Action Unit Recognition Based on Transfer Learning
Mar 25, 2022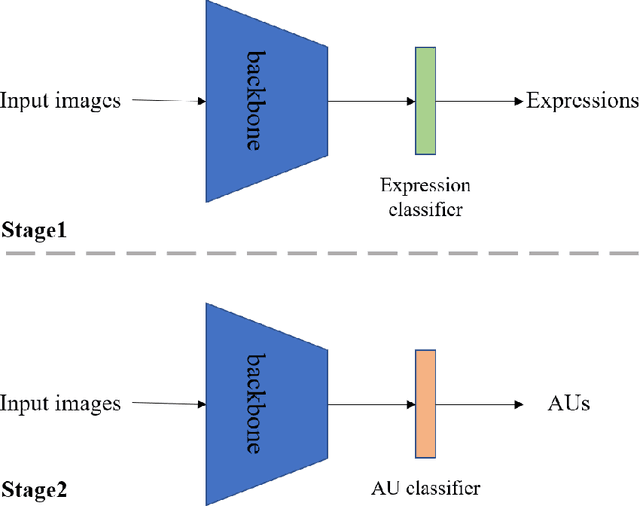
Facial action unit recognition is an important task for facial analysis. Owing to the complex collection environment, facial action unit recognition in the wild is still challenging. The 3rd competition on affective behavior analysis in-the-wild (ABAW) has provided large amount of facial images with facial action unit annotations. In this paper, we introduce a facial action unit recognition method based on transfer learning. We first use available facial images with expression labels to train the feature extraction network. Then we fine-tune the network for facial action unit recognition.
A deep-learning approach to early identification of suggested sexual harassment from videos
Jun 01, 2023Sexual harassment, sexual abuse, and sexual violence are prevalent problems in this day and age. Women's safety is an important issue that needs to be highlighted and addressed. Given this issue, we have studied each of these concerns and the factors that affect it based on images generated from movies. We have classified the three terms (harassment, abuse, and violence) based on the visual attributes present in images depicting these situations. We identified that factors such as facial expression of the victim and perpetrator and unwanted touching had a direct link to identifying the scenes containing sexual harassment, abuse and violence. We also studied and outlined how state-of-the-art explicit content detectors such as Google Cloud Vision API and Clarifai API fail to identify and categorise these images. Based on these definitions and characteristics, we have developed a first-of-its-kind dataset from various Indian movie scenes. These scenes are classified as sexual harassment, sexual abuse, or sexual violence and exported in the PASCAL VOC 1.1 format. Our dataset is annotated on the identified relevant features and can be used to develop and train a deep-learning computer vision model to identify these issues. The dataset is publicly available for research and development.
Facial Action Unit Detection and Intensity Estimation from Self-supervised Representation
Oct 28, 2022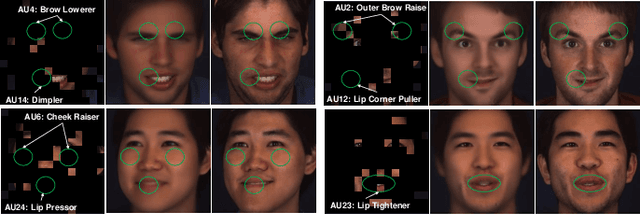
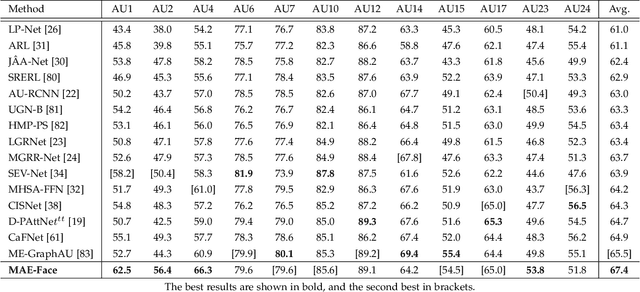
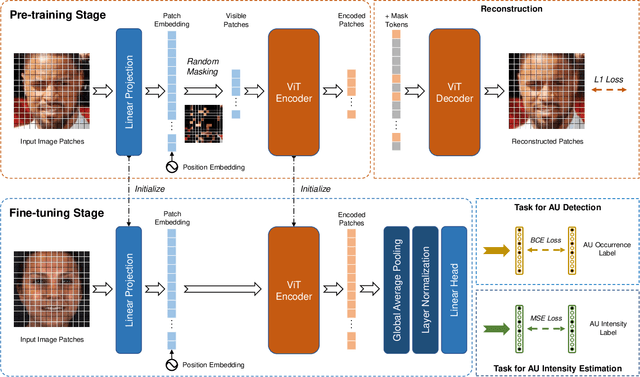

As a fine-grained and local expression behavior measurement, facial action unit (FAU) analysis (e.g., detection and intensity estimation) has been documented for its time-consuming, labor-intensive, and error-prone annotation. Thus a long-standing challenge of FAU analysis arises from the data scarcity of manual annotations, limiting the generalization ability of trained models to a large extent. Amounts of previous works have made efforts to alleviate this issue via semi/weakly supervised methods and extra auxiliary information. However, these methods still require domain knowledge and have not yet avoided the high dependency on data annotation. This paper introduces a robust facial representation model MAE-Face for AU analysis. Using masked autoencoding as the self-supervised pre-training approach, MAE-Face first learns a high-capacity model from a feasible collection of face images without additional data annotations. Then after being fine-tuned on AU datasets, MAE-Face exhibits convincing performance for both AU detection and AU intensity estimation, achieving a new state-of-the-art on nearly all the evaluation results. Further investigation shows that MAE-Face achieves decent performance even when fine-tuned on only 1\% of the AU training set, strongly proving its robustness and generalization performance.
Gender Stereotyping Impact in Facial Expression Recognition
Oct 11, 2022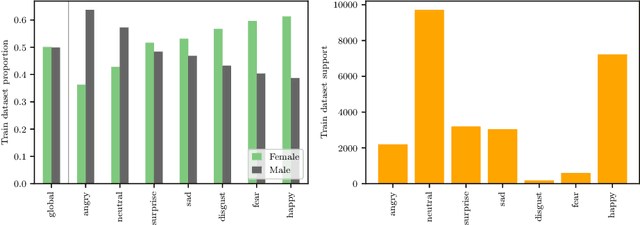
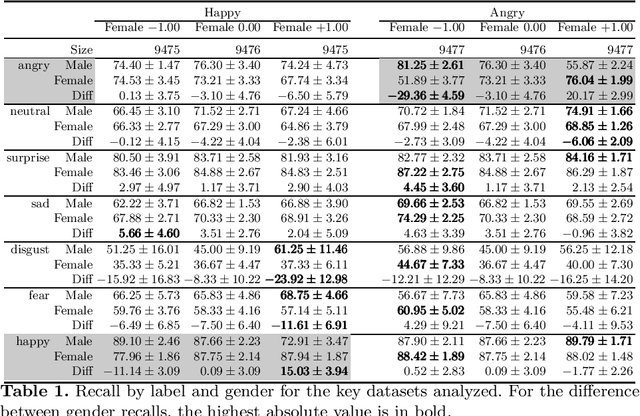
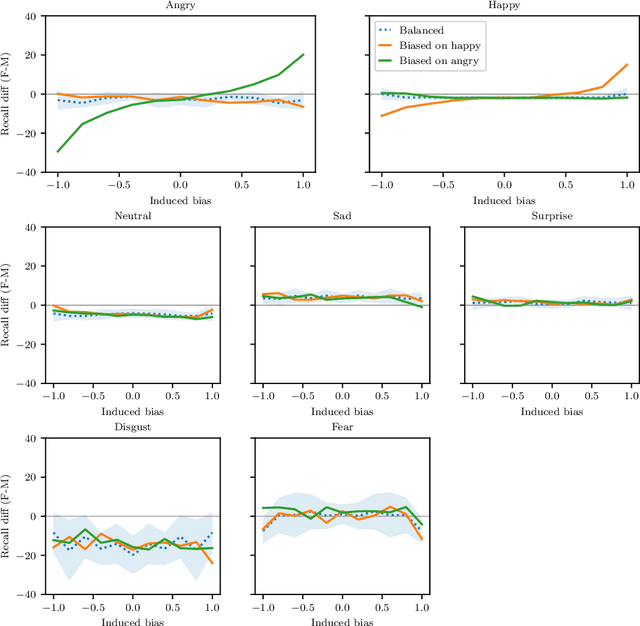
Facial Expression Recognition (FER) uses images of faces to identify the emotional state of users, allowing for a closer interaction between humans and autonomous systems. Unfortunately, as the images naturally integrate some demographic information, such as apparent age, gender, and race of the subject, these systems are prone to demographic bias issues. In recent years, machine learning-based models have become the most popular approach to FER. These models require training on large datasets of facial expression images, and their generalization capabilities are strongly related to the characteristics of the dataset. In publicly available FER datasets, apparent gender representation is usually mostly balanced, but their representation in the individual label is not, embedding social stereotypes into the datasets and generating a potential for harm. Although this type of bias has been overlooked so far, it is important to understand the impact it may have in the context of FER. To do so, we use a popular FER dataset, FER+, to generate derivative datasets with different amounts of stereotypical bias by altering the gender proportions of certain labels. We then proceed to measure the discrepancy between the performance of the models trained on these datasets for the apparent gender groups. We observe a discrepancy in the recognition of certain emotions between genders of up to $29 \%$ under the worst bias conditions. Our results also suggest a safety range for stereotypical bias in a dataset that does not appear to produce stereotypical bias in the resulting model. Our findings support the need for a thorough bias analysis of public datasets in problems like FER, where a global balance of demographic representation can still hide other types of bias that harm certain demographic groups.
Zero-shot racially balanced dataset generation using an existing biased StyleGAN2
May 12, 2023
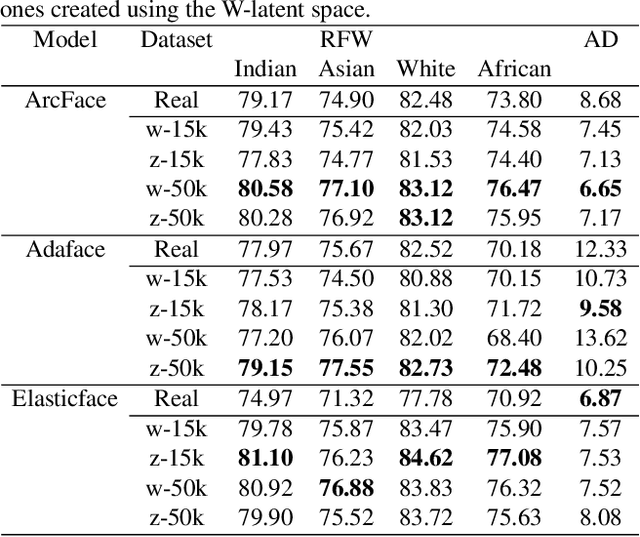

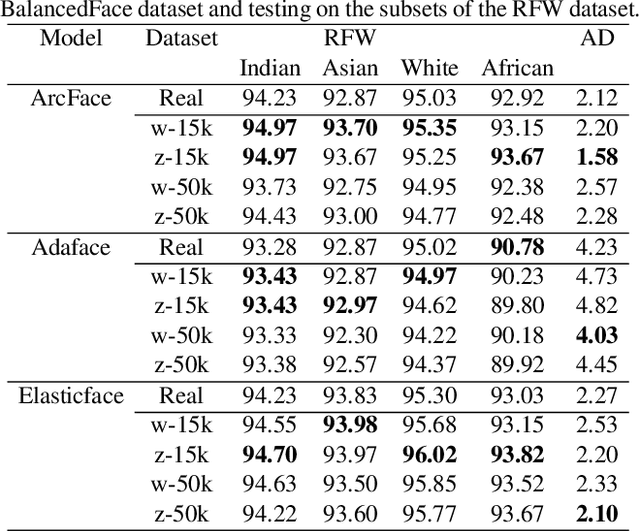
Facial recognition systems have made significant strides thanks to data-heavy deep learning models, but these models rely on large privacy-sensitive datasets. Unfortunately, many of these datasets lack diversity in terms of ethnicity and demographics, which can lead to biased models that can have serious societal and security implications. To address these issues, we propose a methodology that leverages the biased generative model StyleGAN2 to create demographically diverse images of synthetic individuals. The synthetic dataset is created using a novel evolutionary search algorithm that targets specific demographic groups. By training face recognition models with the resulting balanced dataset containing 50,000 identities per race (13.5 million images in total), we can improve their performance and minimize biases that might have been present in a model trained on a real dataset.