 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Vision Transformer for Action Units Detection
Mar 20, 2023
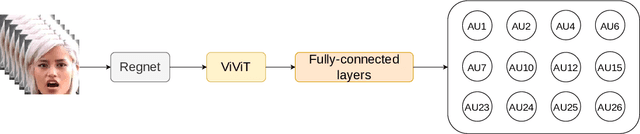
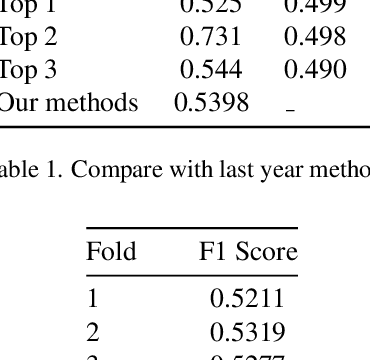
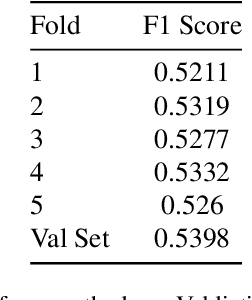
Facial Action Units detection (FAUs) represents a fine-grained classification problem that involves identifying different units on the human face, as defined by the Facial Action Coding System. In this paper, we present a simple yet efficient Vision Transformer-based approach for addressing the task of Action Units (AU) detection in the context of Affective Behavior Analysis in-the-wild (ABAW) competition. We employ the Video Vision Transformer(ViViT) Network to capture the temporal facial change in the video. Besides, to reduce massive size of the Vision Transformers model, we replace the ViViT feature extraction layers with the CNN backbone (Regnet). Our model outperform the baseline model of ABAW 2023 challenge, with a notable 14% difference in result. Furthermore, the achieved results are comparable to those of the top three teams in the previous ABAW 2022 challenge.
CelebV-HQ: A Large-Scale Video Facial Attributes Dataset
Jul 25, 2022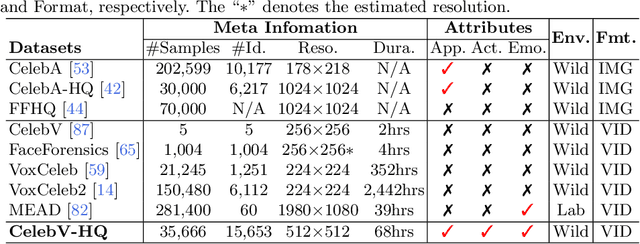
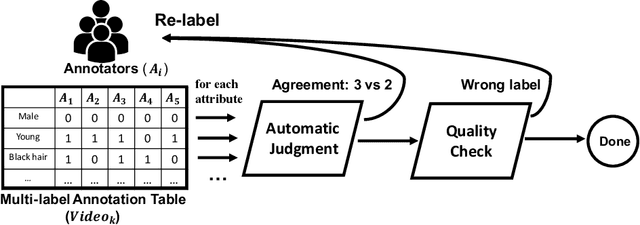

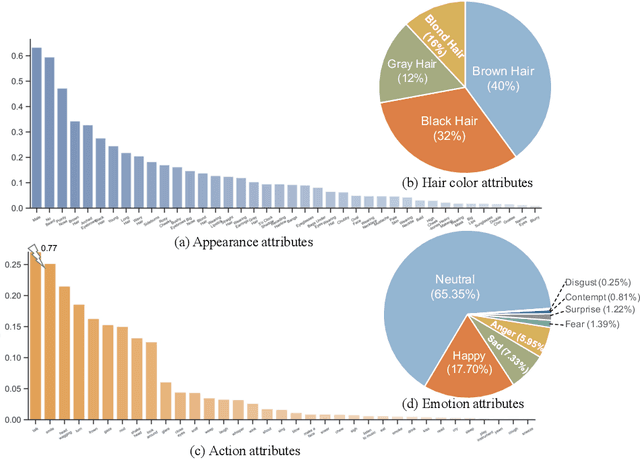
Large-scale datasets have played indispensable roles in the recent success of face generation/editing and significantly facilitated the advances of emerging research fields. However, the academic community still lacks a video dataset with diverse facial attribute annotations, which is crucial for the research on face-related videos. In this work, we propose a large-scale, high-quality, and diverse video dataset with rich facial attribute annotations, named the High-Quality Celebrity Video Dataset (CelebV-HQ). CelebV-HQ contains 35,666 video clips with the resolution of 512x512 at least, involving 15,653 identities. All clips are labeled manually with 83 facial attributes, covering appearance, action, and emotion. We conduct a comprehensive analysis in terms of age, ethnicity, brightness stability, motion smoothness, head pose diversity, and data quality to demonstrate the diversity and temporal coherence of CelebV-HQ. Besides, its versatility and potential are validated on two representative tasks, i.e., unconditional video generation and video facial attribute editing. Furthermore, we envision the future potential of CelebV-HQ, as well as the new opportunities and challenges it would bring to related research directions. Data, code, and models are publicly available. Project page: https://celebv-hq.github.io.
Intensity-Aware Loss for Dynamic Facial Expression Recognition in the Wild
Aug 19, 2022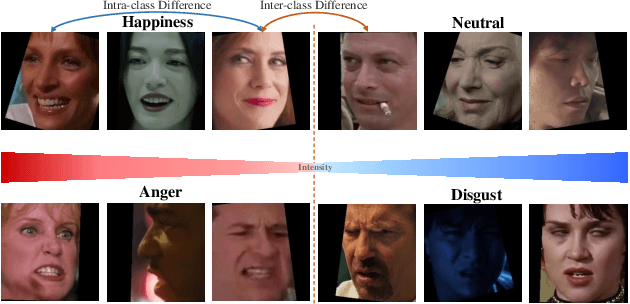
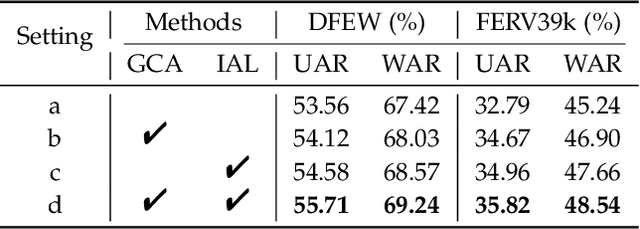
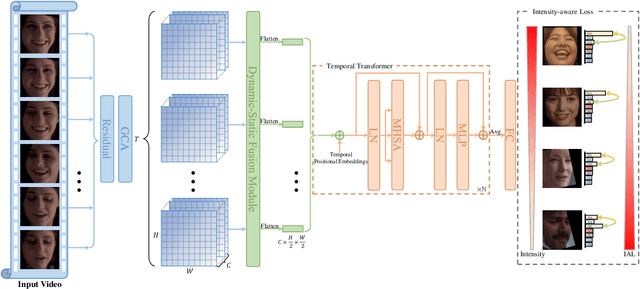
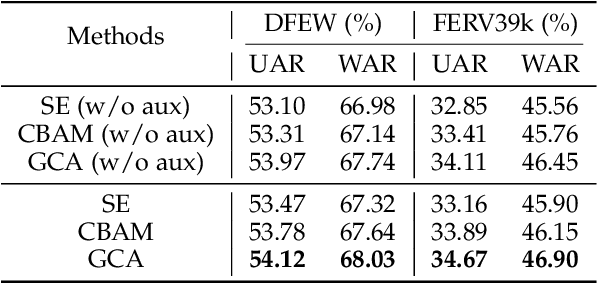
Compared with the image-based static facial expression recognition (SFER) task, the dynamic facial expression recognition (DFER) task based on video sequences is closer to the natural expression recognition scene. However, DFER is often more challenging. One of the main reasons is that video sequences often contain frames with different expression intensities, especially for the facial expressions in the real-world scenarios, while the images in SFER frequently present uniform and high expression intensities. However, if the expressions with different intensities are treated equally, the features learned by the networks will have large intra-class and small inter-class differences, which is harmful to DFER. To tackle this problem, we propose the global convolution-attention block (GCA) to rescale the channels of the feature maps. In addition, we introduce the intensity-aware loss (IAL) in the training process to help the network distinguish the samples with relatively low expression intensities. Experiments on two in-the-wild dynamic facial expression datasets (i.e., DFEW and FERV39k) indicate that our method outperforms the state-of-the-art DFER approaches. The source code will be made publicly available.
Efficient Neural Architecture Search for Emotion Recognition
Mar 23, 2023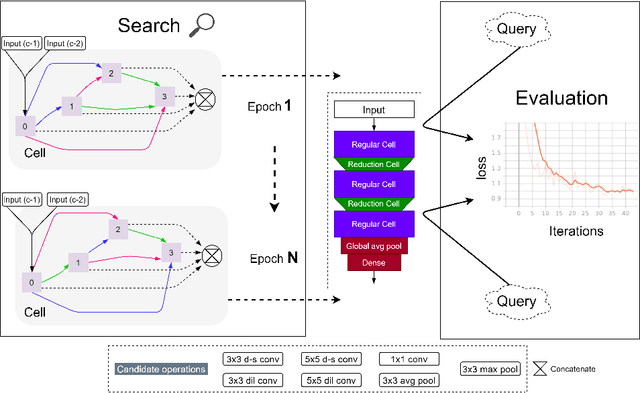
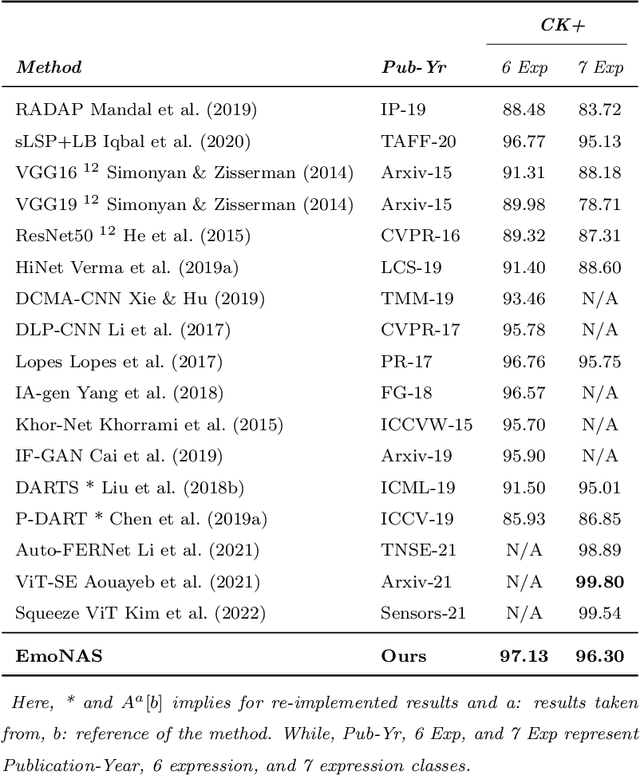

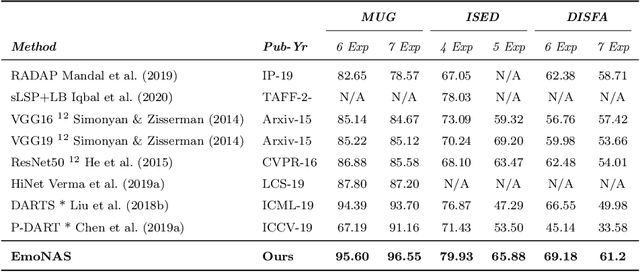
Automated human emotion recognition from facial expressions is a well-studied problem and still remains a very challenging task. Some efficient or accurate deep learning models have been presented in the literature. However, it is quite difficult to design a model that is both efficient and accurate at the same time. Moreover, identifying the minute feature variations in facial regions for both macro and micro-expressions requires expertise in network design. In this paper, we proposed to search for a highly efficient and robust neural architecture for both macro and micro-level facial expression recognition. To the best of our knowledge, this is the first attempt to design a NAS-based solution for both macro and micro-expression recognition. We produce lightweight models with a gradient-based architecture search algorithm. To maintain consistency between macro and micro-expressions, we utilize dynamic imaging and convert microexpression sequences into a single frame, preserving the spatiotemporal features in the facial regions. The EmoNAS has evaluated over 13 datasets (7 macro expression datasets: CK+, DISFA, MUG, ISED, OULU-VIS CASIA, FER2013, RAF-DB, and 6 micro-expression datasets: CASME-I, CASME-II, CAS(ME)2, SAMM, SMIC, MEGC2019 challenge). The proposed models outperform the existing state-of-the-art methods and perform very well in terms of speed and space complexity.
Facial Expression Recognition using Vanilla ViT backbones with MAE Pretraining
Jul 22, 2022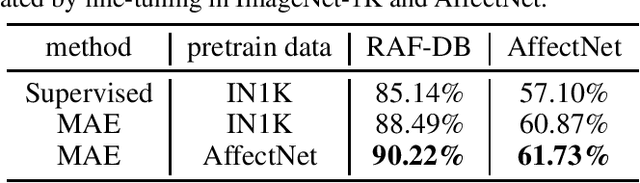
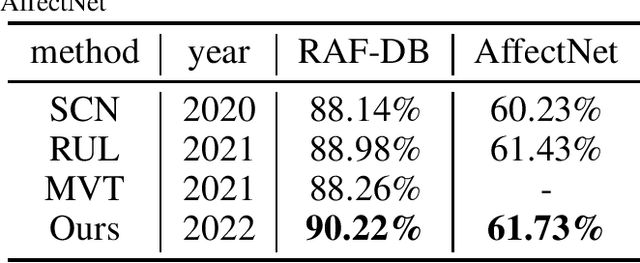
Humans usually convey emotions voluntarily or involuntarily by facial expressions. Automatically recognizing the basic expression (such as happiness, sadness, and neutral) from a facial image, i.e., facial expression recognition (FER), is extremely challenging and attracts much research interests. Large scale datasets and powerful inference models have been proposed to address the problem. Though considerable progress has been made, most of the state of the arts employing convolutional neural networks (CNNs) or elaborately modified Vision Transformers (ViTs) depend heavily on upstream supervised pretraining. Transformers are taking place the domination of CNNs in more and more computer vision tasks. But they usually need much more data to train, since they use less inductive biases compared with CNNs. To explore whether a vanilla ViT without extra training samples from upstream tasks is able to achieve competitive accuracy, we use a plain ViT with MAE pretraining to perform the FER task. Specifically, we first pretrain the original ViT as a Masked Autoencoder (MAE) on a large facial expression dataset without expression labels. Then, we fine-tune the ViT on popular facial expression datasets with expression labels. The presented method is quite competitive with 90.22\% on RAF-DB, 61.73\% on AfectNet and can serve as a simple yet strong ViT-based baseline for FER studies.
GAN-based Facial Attribute Manipulation
Oct 23, 2022
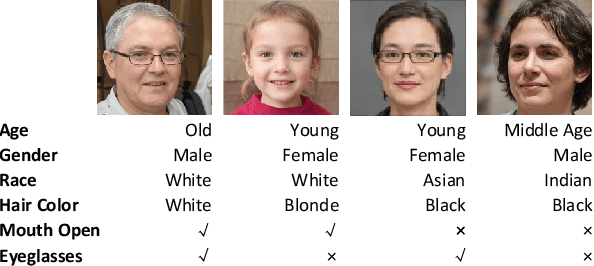
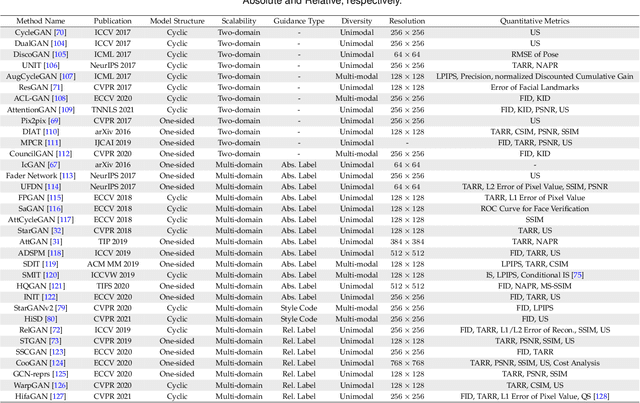
Facial Attribute Manipulation (FAM) aims to aesthetically modify a given face image to render desired attributes, which has received significant attention due to its broad practical applications ranging from digital entertainment to biometric forensics. In the last decade, with the remarkable success of Generative Adversarial Networks (GANs) in synthesizing realistic images, numerous GAN-based models have been proposed to solve FAM with various problem formulation approaches and guiding information representations. This paper presents a comprehensive survey of GAN-based FAM methods with a focus on summarizing their principal motivations and technical details. The main contents of this survey include: (i) an introduction to the research background and basic concepts related to FAM, (ii) a systematic review of GAN-based FAM methods in three main categories, and (iii) an in-depth discussion of important properties of FAM methods, open issues, and future research directions. This survey not only builds a good starting point for researchers new to this field but also serves as a reference for the vision community.
Target Active Speaker Detection with Audio-visual Cues
May 26, 2023
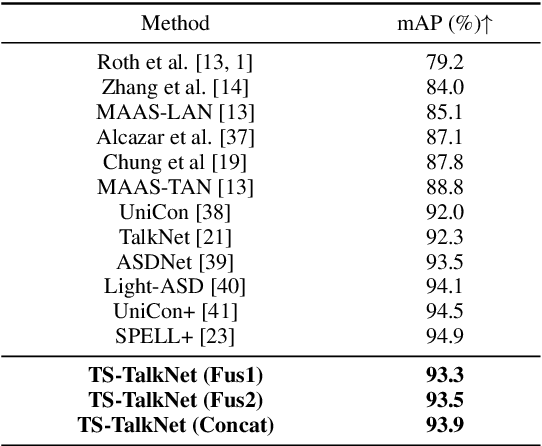
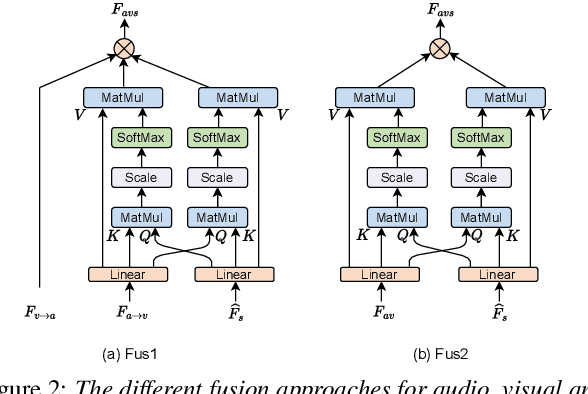
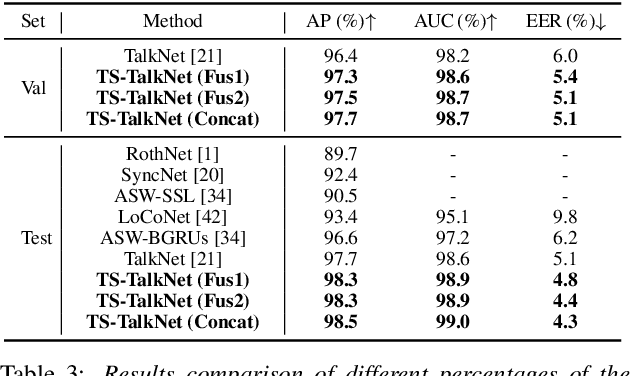
In active speaker detection (ASD), we would like to detect whether an on-screen person is speaking based on audio-visual cues. Previous studies have primarily focused on modeling audio-visual synchronization cue, which depends on the video quality of the lip region of a speaker. In real-world applications, it is possible that we can also have the reference speech of the on-screen speaker. To benefit from both facial cue and reference speech, we propose the Target Speaker TalkNet (TS-TalkNet), which leverages a pre-enrolled speaker embedding to complement the audio-visual synchronization cue in detecting whether the target speaker is speaking. Our framework outperforms the popular model, TalkNet on two datasets, achieving absolute improvements of 1.6\% in mAP on the AVA-ActiveSpeaker validation set, and 0.8\%, 0.4\%, and 0.8\% in terms of AP, AUC and EER on the ASW test set, respectively. Code is available at \href{https://github.com/Jiang-Yidi/TS-TalkNet/}{\color{red}{https://github.com/Jiang-Yidi/TS-TalkNet/}}.
Performance Analysis and Evaluation of Cloud Vision Emotion APIs
Mar 23, 2023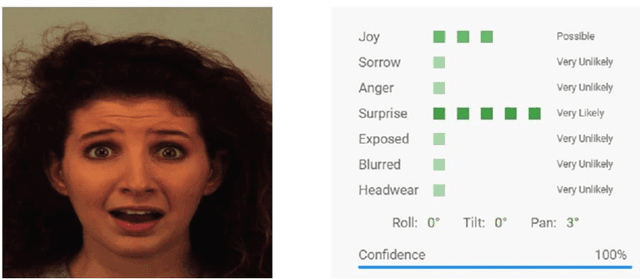


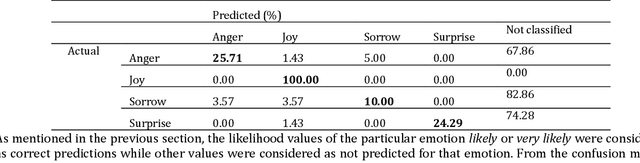
Facial expression is a way of communication that can be used to interact with computers or other electronic devices and the recognition of emotion from faces is an emerging practice with application in many fields. There are many cloud-based vision application programming interfaces available that recognize emotion from facial images and video. In this article, the performances of two well-known APIs were compared using a public dataset of 980 images of facial emotions. For these experiments, a client program was developed which iterates over the image set, calls the cloud services, and caches the results of the emotion detection for each image. The performance was evaluated in each class of emotions using prediction accuracy. It has been found that the prediction accuracy for each emotion varies according to the cloud service being used. Similarly, each service provider presents a strong variation of performance according to the class being analyzed, as can be seen with more detail in this artilects.
Masked Student Dataset of Expressions
Apr 07, 2023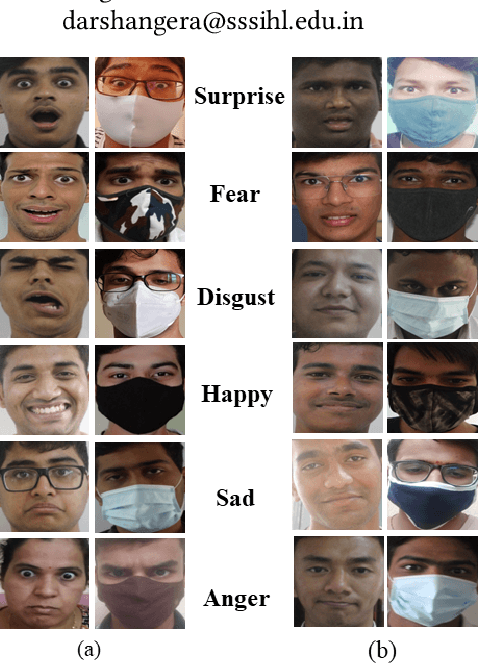

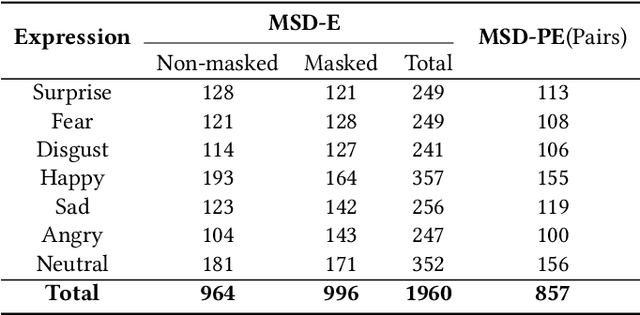
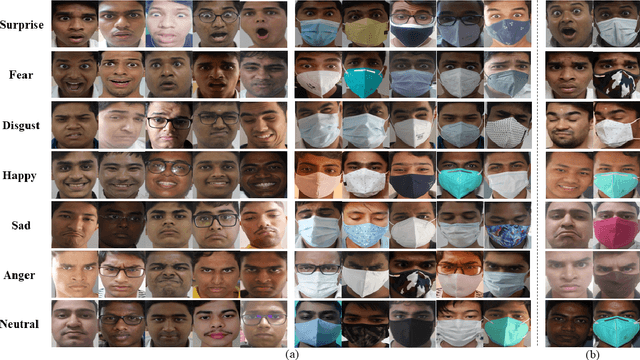
Facial expression recognition (FER) algorithms work well in constrained environments with little or no occlusion of the face. However, real-world face occlusion is prevalent, most notably with the need to use a face mask in the current Covid-19 scenario. While there are works on the problem of occlusion in FER, little has been done before on the particular face mask scenario. Moreover, the few works in this area largely use synthetically created masked FER datasets. Motivated by these challenges posed by the pandemic to FER, we present a novel dataset, the Masked Student Dataset of Expressions or MSD-E, consisting of 1,960 real-world non-masked and masked facial expression images collected from 142 individuals. Along with the issue of obfuscated facial features, we illustrate how other subtler issues in masked FER are represented in our dataset. We then provide baseline results using ResNet-18, finding that its performance dips in the non-masked case when trained for FER in the presence of masks. To tackle this, we test two training paradigms: contrastive learning and knowledge distillation, and find that they increase the model's performance in the masked scenario while maintaining its non-masked performance. We further visualise our results using t-SNE plots and Grad-CAM, demonstrating that these paradigms capitalise on the limited features available in the masked scenario. Finally, we benchmark SOTA methods on MSD-E.
RePFormer: Refinement Pyramid Transformer for Robust Facial Landmark Detection
Jul 08, 2022
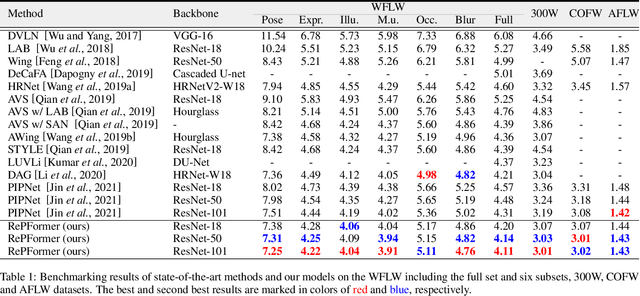
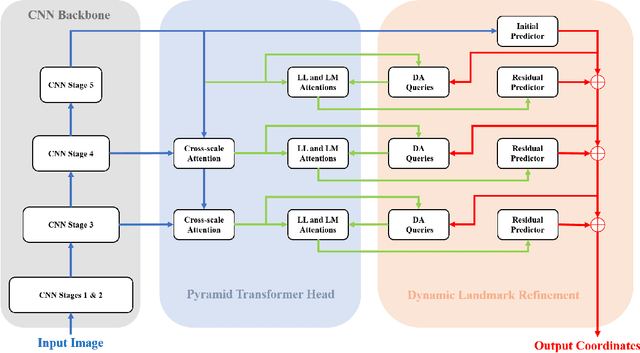
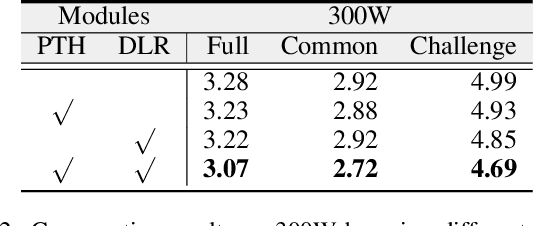
This paper presents a Refinement Pyramid Transformer (RePFormer) for robust facial landmark detection. Most facial landmark detectors focus on learning representative image features. However, these CNN-based feature representations are not robust enough to handle complex real-world scenarios due to ignoring the internal structure of landmarks, as well as the relations between landmarks and context. In this work, we formulate the facial landmark detection task as refining landmark queries along pyramid memories. Specifically, a pyramid transformer head (PTH) is introduced to build both homologous relations among landmarks and heterologous relations between landmarks and cross-scale contexts. Besides, a dynamic landmark refinement (DLR) module is designed to decompose the landmark regression into an end-to-end refinement procedure, where the dynamically aggregated queries are transformed to residual coordinates predictions. Extensive experimental results on four facial landmark detection benchmarks and their various subsets demonstrate the superior performance and high robustness of our framework.