 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
That's What I Said: Fully-Controllable Talking Face Generation
Apr 06, 2023

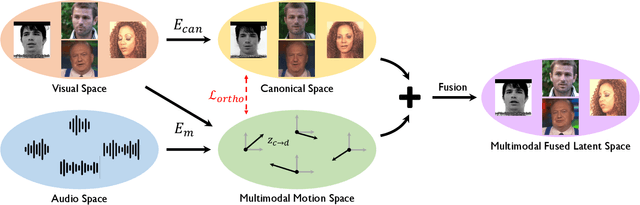

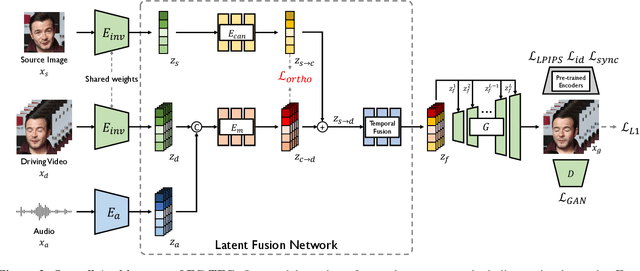
The goal of this paper is to synthesise talking faces with controllable facial motions. To achieve this goal, we propose two key ideas. The first is to establish a canonical space where every face has the same motion patterns but different identities. The second is to navigate a multimodal motion space that only represents motion-related features while eliminating identity information. To disentangle identity and motion, we introduce an orthogonality constraint between the two different latent spaces. From this, our method can generate natural-looking talking faces with fully controllable facial attributes and accurate lip synchronisation. Extensive experiments demonstrate that our method achieves state-of-the-art results in terms of both visual quality and lip-sync score. To the best of our knowledge, we are the first to develop a talking face generation framework that can accurately manifest full target facial motions including lip, head pose, and eye movements in the generated video without any additional supervision beyond RGB video with audio.
TalkCLIP: Talking Head Generation with Text-Guided Expressive Speaking Styles
Apr 01, 2023
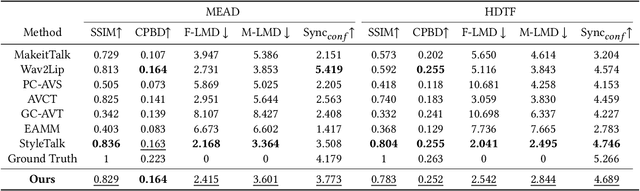
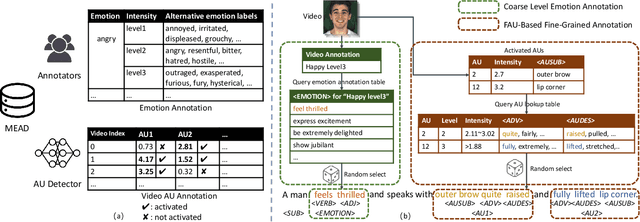
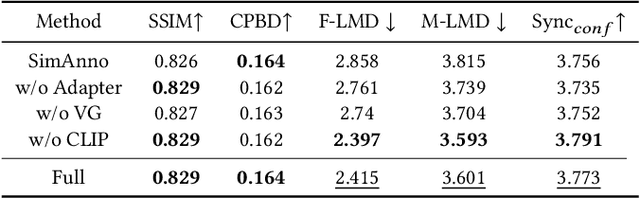
In order to produce facial-expression-specified talking head videos, previous audio-driven one-shot talking head methods need to use a reference video with a matching speaking style (i.e., facial expressions). However, finding videos with a desired style may not be easy, potentially restricting their application. In this work, we propose an expression-controllable one-shot talking head method, dubbed TalkCLIP, where the expression in a speech is specified by the natural language. This would significantly ease the difficulty of searching for a video with a desired speaking style. Here, we first construct a text-video paired talking head dataset, in which each video has alternative prompt-alike descriptions. Specifically, our descriptions involve coarse-level emotion annotations and facial action unit (AU) based fine-grained annotations. Then, we introduce a CLIP-based style encoder that first projects natural language descriptions to the CLIP text embedding space and then aligns the textual embeddings to the representations of speaking styles. As extensive textual knowledge has been encoded by CLIP, our method can even generalize to infer a speaking style whose description has not been seen during training. Extensive experiments demonstrate that our method achieves the advanced capability of generating photo-realistic talking heads with vivid facial expressions guided by text descriptions.
DSFNet: Dual Space Fusion Network for Occlusion-Robust 3D Dense Face Alignment
May 19, 2023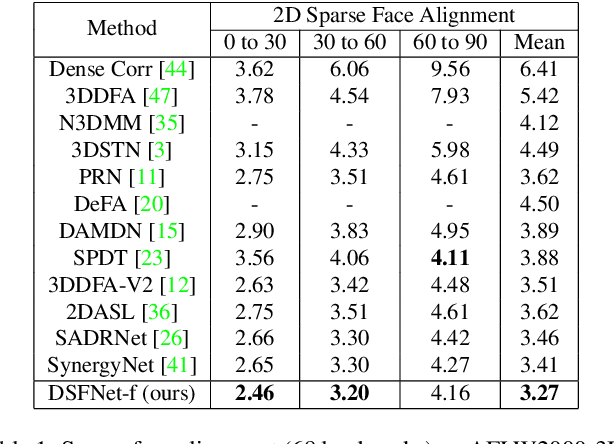
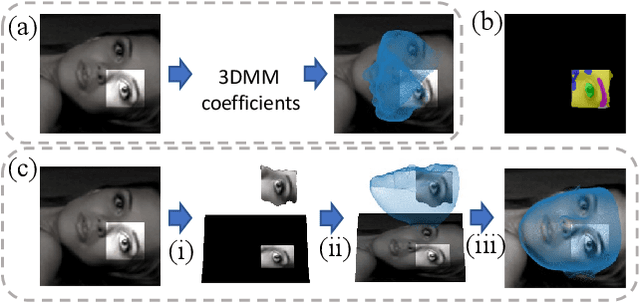
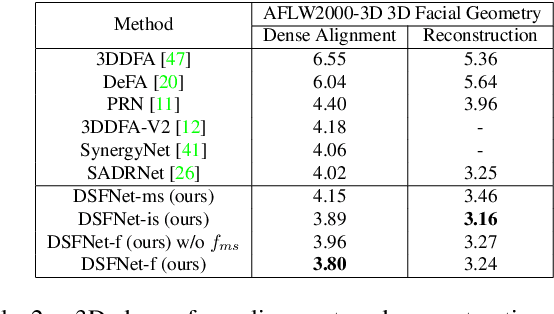
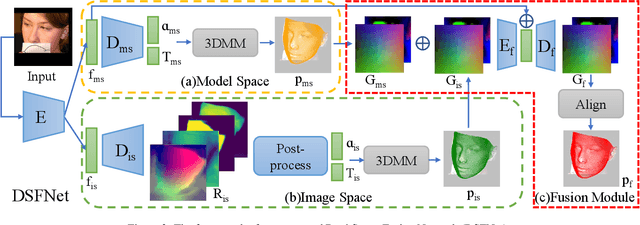
Sensitivity to severe occlusion and large view angles limits the usage scenarios of the existing monocular 3D dense face alignment methods. The state-of-the-art 3DMM-based method, directly regresses the model's coefficients, underutilizing the low-level 2D spatial and semantic information, which can actually offer cues for face shape and orientation. In this work, we demonstrate how modeling 3D facial geometry in image and model space jointly can solve the occlusion and view angle problems. Instead of predicting the whole face directly, we regress image space features in the visible facial region by dense prediction first. Subsequently, we predict our model's coefficients based on the regressed feature of the visible regions, leveraging the prior knowledge of whole face geometry from the morphable models to complete the invisible regions. We further propose a fusion network that combines the advantages of both the image and model space predictions to achieve high robustness and accuracy in unconstrained scenarios. Thanks to the proposed fusion module, our method is robust not only to occlusion and large pitch and roll view angles, which is the benefit of our image space approach, but also to noise and large yaw angles, which is the benefit of our model space method. Comprehensive evaluations demonstrate the superior performance of our method compared with the state-of-the-art methods. On the 3D dense face alignment task, we achieve 3.80% NME on the AFLW2000-3D dataset, which outperforms the state-of-the-art method by 5.5%. Code is available at https://github.com/lhyfst/DSFNet.
Facial Misrecognition Systems: Simple Weight Manipulations Force DNNs to Err Only on Specific Persons
Jan 08, 2023
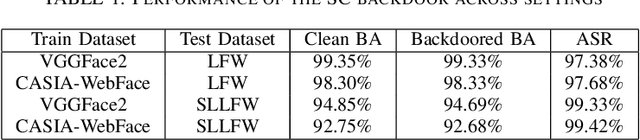
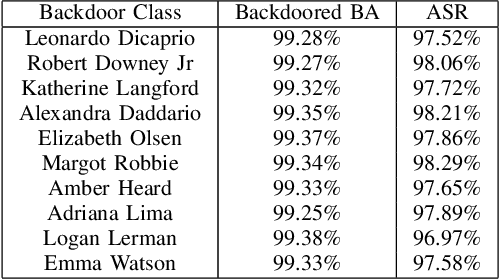
In this paper we describe how to plant novel types of backdoors in any facial recognition model based on the popular architecture of deep Siamese neural networks, by mathematically changing a small fraction of its weights (i.e., without using any additional training or optimization). These backdoors force the system to err only on specific persons which are preselected by the attacker. For example, we show how such a backdoored system can take any two images of a particular person and decide that they represent different persons (an anonymity attack), or take any two images of a particular pair of persons and decide that they represent the same person (a confusion attack), with almost no effect on the correctness of its decisions for other persons. Uniquely, we show that multiple backdoors can be independently installed by multiple attackers who may not be aware of each other's existence with almost no interference. We have experimentally verified the attacks on a FaceNet-based facial recognition system, which achieves SOTA accuracy on the standard LFW dataset of $99.35\%$. When we tried to individually anonymize ten celebrities, the network failed to recognize two of their images as being the same person in $96.97\%$ to $98.29\%$ of the time. When we tried to confuse between the extremely different looking Morgan Freeman and Scarlett Johansson, for example, their images were declared to be the same person in $91.51 \%$ of the time. For each type of backdoor, we sequentially installed multiple backdoors with minimal effect on the performance of each one (for example, anonymizing all ten celebrities on the same model reduced the success rate for each celebrity by no more than $0.91\%$). In all of our experiments, the benign accuracy of the network on other persons was degraded by no more than $0.48\%$ (and in most cases, it remained above $99.30\%$).
AvatarBooth: High-Quality and Customizable 3D Human Avatar Generation
Jun 16, 2023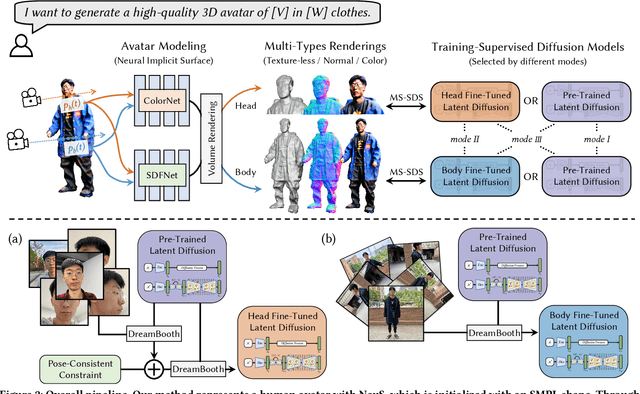
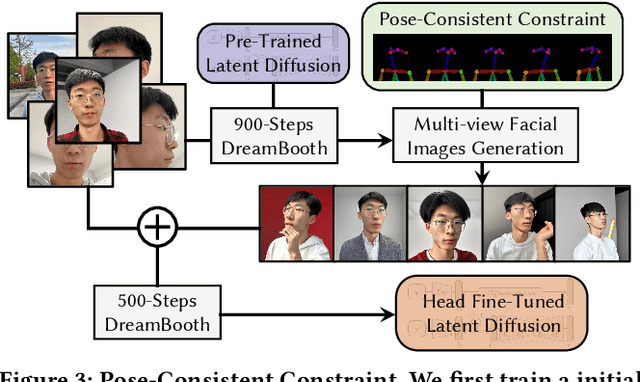


We introduce AvatarBooth, a novel method for generating high-quality 3D avatars using text prompts or specific images. Unlike previous approaches that can only synthesize avatars based on simple text descriptions, our method enables the creation of personalized avatars from casually captured face or body images, while still supporting text-based model generation and editing. Our key contribution is the precise avatar generation control by using dual fine-tuned diffusion models separately for the human face and body. This enables us to capture intricate details of facial appearance, clothing, and accessories, resulting in highly realistic avatar generations. Furthermore, we introduce pose-consistent constraint to the optimization process to enhance the multi-view consistency of synthesized head images from the diffusion model and thus eliminate interference from uncontrolled human poses. In addition, we present a multi-resolution rendering strategy that facilitates coarse-to-fine supervision of 3D avatar generation, thereby enhancing the performance of the proposed system. The resulting avatar model can be further edited using additional text descriptions and driven by motion sequences. Experiments show that AvatarBooth outperforms previous text-to-3D methods in terms of rendering and geometric quality from either text prompts or specific images. Please check our project website at https://zeng-yifei.github.io/avatarbooth_page/.
EmoTalk: Speech-driven emotional disentanglement for 3D face animation
Mar 20, 2023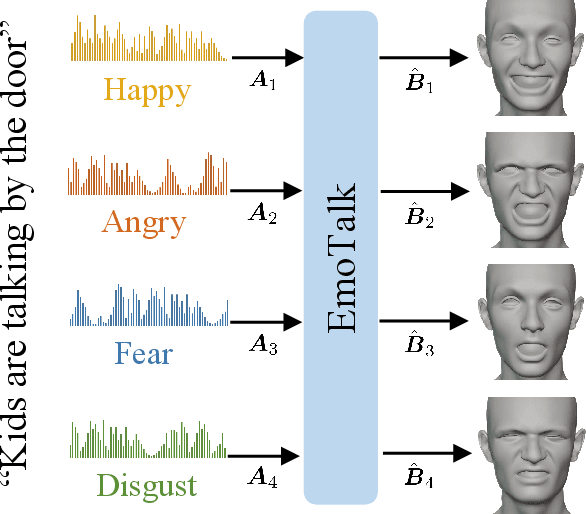

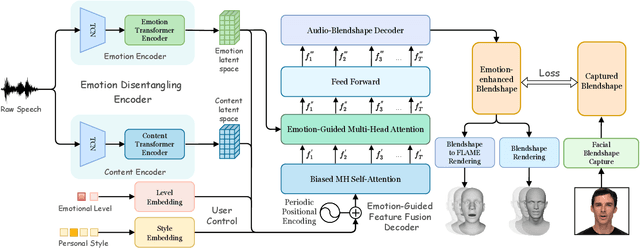
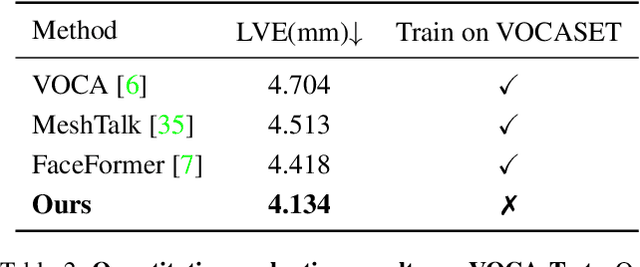
Speech-driven 3D face animation aims to generate realistic facial expressions that match the speech content and emotion. However, existing methods often neglect emotional facial expressions or fail to disentangle them from speech content. To address this issue, this paper proposes an end-to-end neural network to disentangle different emotions in speech so as to generate rich 3D facial expressions. Specifically, we introduce the emotion disentangling encoder (EDE) to disentangle the emotion and content in the speech by cross-reconstructed speech signals with different emotion labels. Then an emotion-guided feature fusion decoder is employed to generate a 3D talking face with enhanced emotion. The decoder is driven by the disentangled identity, emotional, and content embeddings so as to generate controllable personal and emotional styles. Finally, considering the scarcity of the 3D emotional talking face data, we resort to the supervision of facial blendshapes, which enables the reconstruction of plausible 3D faces from 2D emotional data, and contribute a large-scale 3D emotional talking face dataset (3D-ETF) to train the network. Our experiments and user studies demonstrate that our approach outperforms state-of-the-art methods and exhibits more diverse facial movements. We recommend watching the supplementary video: https://ziqiaopeng.github.io/emotalk
Semantics-Guided Object Removal for Facial Images: with Broad Applicability and Robust Style Preservation
Sep 29, 2022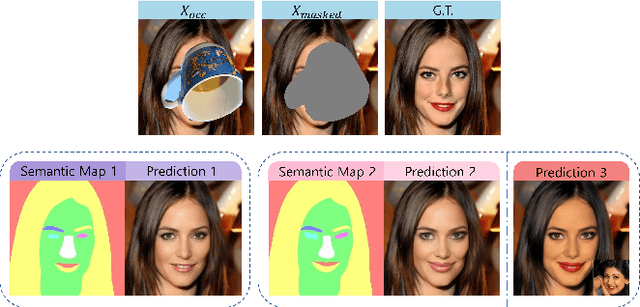

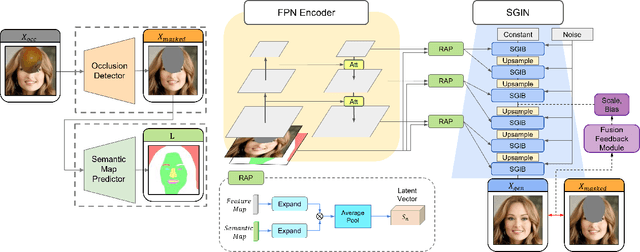
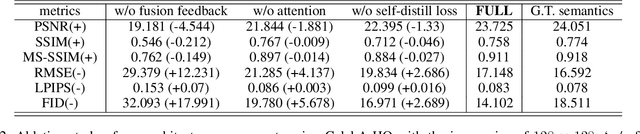
Object removal and image inpainting in facial images is a task in which objects that occlude a facial image are specifically targeted, removed, and replaced by a properly reconstructed facial image. Two different approaches utilizing U-net and modulated generator respectively have been widely endorsed for this task for their unique advantages but notwithstanding each method's innate disadvantages. U-net, a conventional approach for conditional GANs, retains fine details of unmasked regions but the style of the reconstructed image is inconsistent with the rest of the original image and only works robustly when the size of the occluding object is small enough. In contrast, the modulated generative approach can deal with a larger occluded area in an image and provides {a} more consistent style, yet it usually misses out on most of the detailed features. This trade-off between these two models necessitates an invention of a model that can be applied to any size of mask while maintaining a consistent style and preserving minute details of facial features. Here, we propose Semantics-Guided Inpainting Network (SGIN) which itself is a modification of the modulated generator, aiming to take advantage of its advanced generative capability and preserve the high-fidelity details of the original image. By using the guidance of a semantic map, our model is capable of manipulating facial features which grants direction to the one-to-many problem for further practicability.
Optimal Transport-based Identity Matching for Identity-invariant Facial Expression Recognition
Sep 25, 2022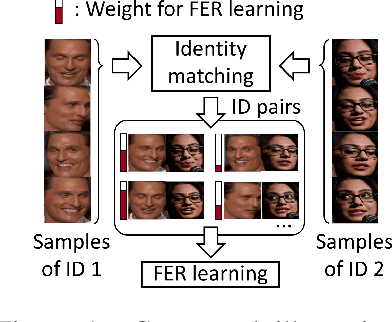
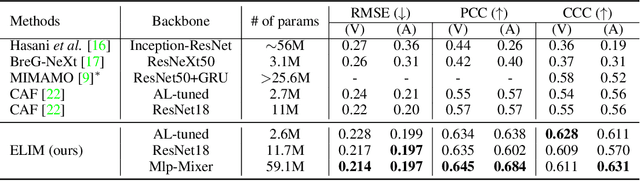
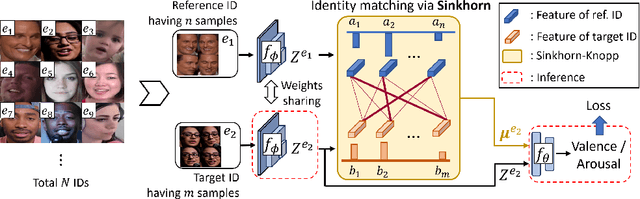
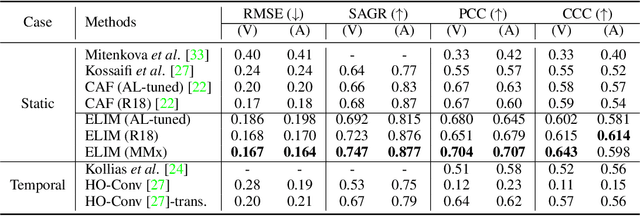
Identity-invariant facial expression recognition (FER) has been one of the challenging computer vision tasks. Since conventional FER schemes do not explicitly address the inter-identity variation of facial expressions, their neural network models still operate depending on facial identity. This paper proposes to quantify the inter-identity variation by utilizing pairs of similar expressions explored through a specific matching process. We formulate the identity matching process as an Optimal Transport (OT) problem. Specifically, to find pairs of similar expressions from different identities, we define the inter-feature similarity as a transportation cost. Then, optimal identity matching to find the optimal flow with minimum transportation cost is performed by Sinkhorn-Knopp iteration. The proposed matching method is not only easy to plug in to other models, but also requires only acceptable computational overhead. Extensive simulations prove that the proposed FER method improves the PCC/CCC performance by up to 10\% or more compared to the runner-up on wild datasets. The source code and software demo are available at https://github.com/kdhht2334/ELIM_FER.
Multi-task Cross Attention Network in Facial Behavior Analysis
Jul 21, 2022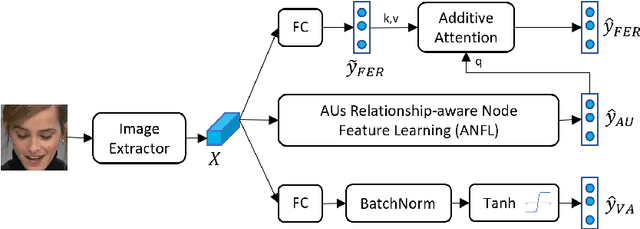

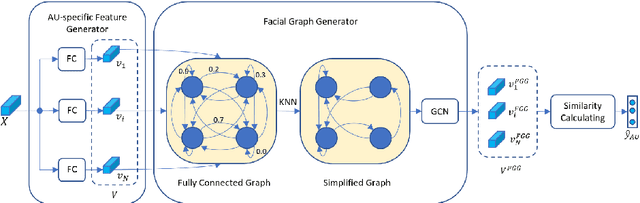
Facial behavior analysis is a broad topic with various categories such as facial emotion recognition, age and gender recognition, ... Many studies focus on individual tasks while the multi-task learning approach is still open and requires more research. In this paper, we present our solution and experiment result for the Multi-Task Learning challenge of the Affective Behavior Analysis in-the-wild competition. The challenge is a combination of three tasks: action unit detection, facial expression recognition and valance-arousal estimation. To address this challenge, we introduce a cross-attentive module to improve multi-task learning performance. Additionally, a facial graph is applied to capture the association among action units. As a result, we achieve the evaluation measure of 1.24 on the validation data provided by the organizers, which is better than the baseline result of 0.30.
Speech inpainting: Context-based speech synthesis guided by video
Jun 01, 2023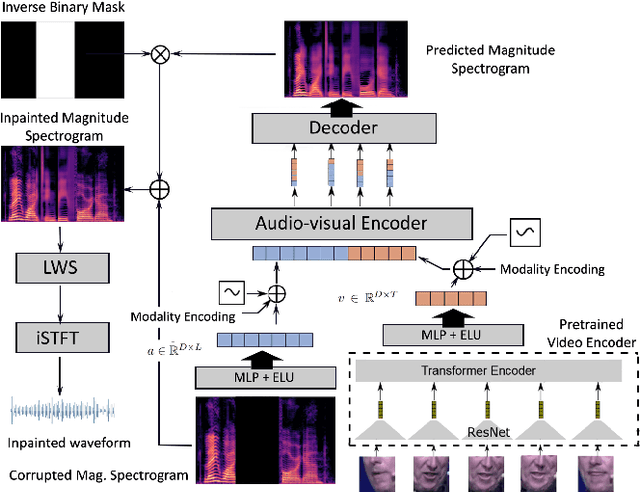
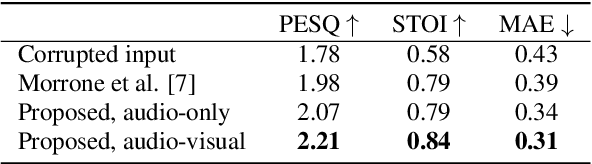
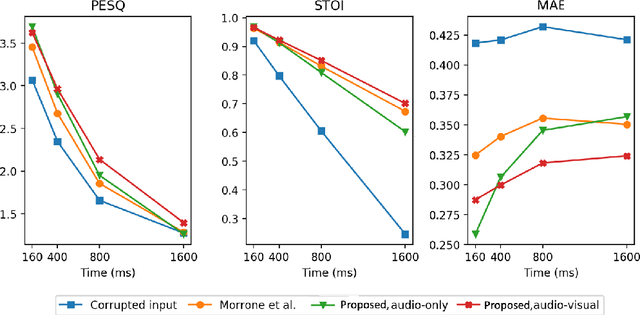

Audio and visual modalities are inherently connected in speech signals: lip movements and facial expressions are correlated with speech sounds. This motivates studies that incorporate the visual modality to enhance an acoustic speech signal or even restore missing audio information. Specifically, this paper focuses on the problem of audio-visual speech inpainting, which is the task of synthesizing the speech in a corrupted audio segment in a way that it is consistent with the corresponding visual content and the uncorrupted audio context. We present an audio-visual transformer-based deep learning model that leverages visual cues that provide information about the content of the corrupted audio. It outperforms the previous state-of-the-art audio-visual model and audio-only baselines. We also show how visual features extracted with AV-HuBERT, a large audio-visual transformer for speech recognition, are suitable for synthesizing speech.