 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
EmoTalk: Speech-driven emotional disentanglement for 3D face animation
Mar 20, 2023
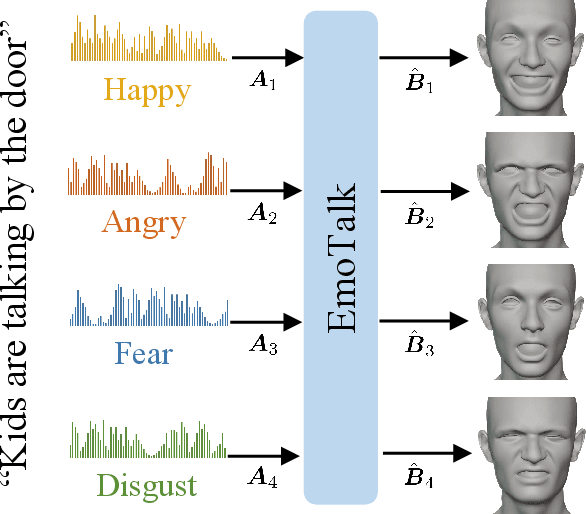

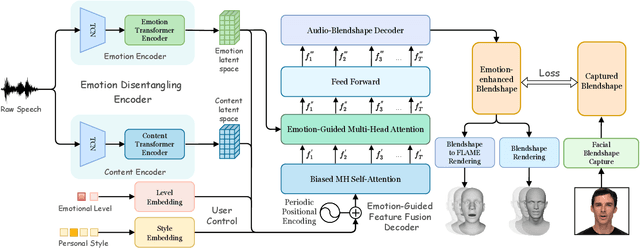
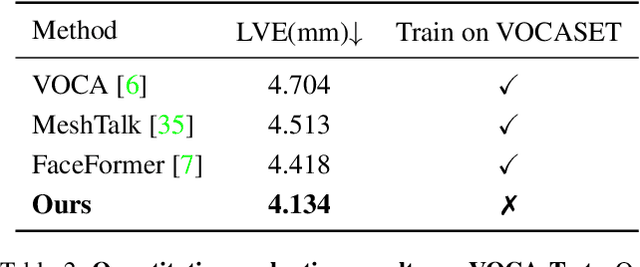
Speech-driven 3D face animation aims to generate realistic facial expressions that match the speech content and emotion. However, existing methods often neglect emotional facial expressions or fail to disentangle them from speech content. To address this issue, this paper proposes an end-to-end neural network to disentangle different emotions in speech so as to generate rich 3D facial expressions. Specifically, we introduce the emotion disentangling encoder (EDE) to disentangle the emotion and content in the speech by cross-reconstructed speech signals with different emotion labels. Then an emotion-guided feature fusion decoder is employed to generate a 3D talking face with enhanced emotion. The decoder is driven by the disentangled identity, emotional, and content embeddings so as to generate controllable personal and emotional styles. Finally, considering the scarcity of the 3D emotional talking face data, we resort to the supervision of facial blendshapes, which enables the reconstruction of plausible 3D faces from 2D emotional data, and contribute a large-scale 3D emotional talking face dataset (3D-ETF) to train the network. Our experiments and user studies demonstrate that our approach outperforms state-of-the-art methods and exhibits more diverse facial movements. We recommend watching the supplementary video: https://ziqiaopeng.github.io/emotalk
Facial Misrecognition Systems: Simple Weight Manipulations Force DNNs to Err Only on Specific Persons
Jan 08, 2023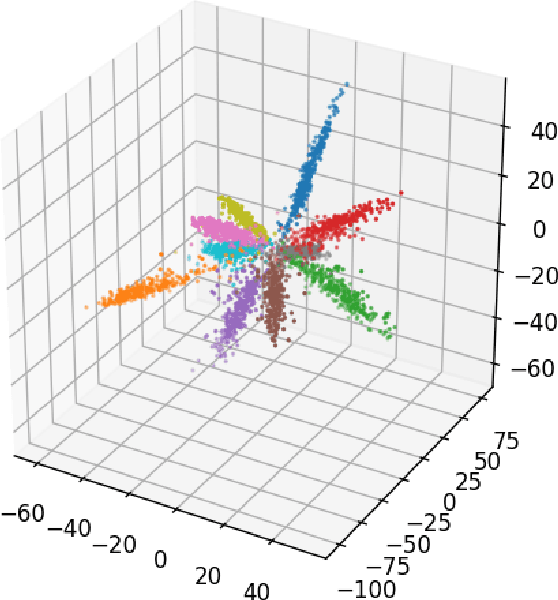
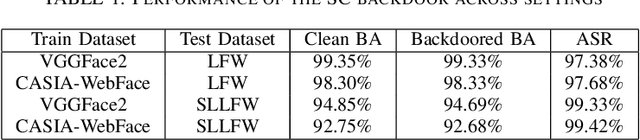
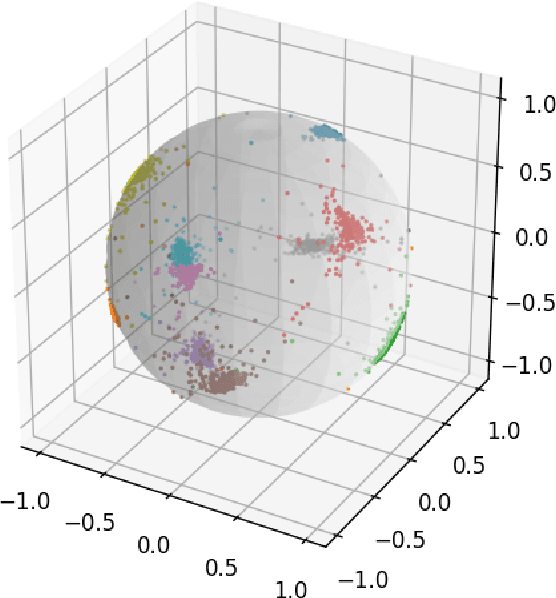
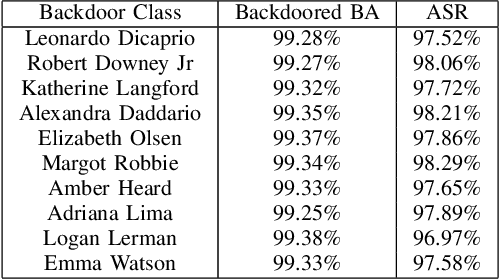
In this paper we describe how to plant novel types of backdoors in any facial recognition model based on the popular architecture of deep Siamese neural networks, by mathematically changing a small fraction of its weights (i.e., without using any additional training or optimization). These backdoors force the system to err only on specific persons which are preselected by the attacker. For example, we show how such a backdoored system can take any two images of a particular person and decide that they represent different persons (an anonymity attack), or take any two images of a particular pair of persons and decide that they represent the same person (a confusion attack), with almost no effect on the correctness of its decisions for other persons. Uniquely, we show that multiple backdoors can be independently installed by multiple attackers who may not be aware of each other's existence with almost no interference. We have experimentally verified the attacks on a FaceNet-based facial recognition system, which achieves SOTA accuracy on the standard LFW dataset of $99.35\%$. When we tried to individually anonymize ten celebrities, the network failed to recognize two of their images as being the same person in $96.97\%$ to $98.29\%$ of the time. When we tried to confuse between the extremely different looking Morgan Freeman and Scarlett Johansson, for example, their images were declared to be the same person in $91.51 \%$ of the time. For each type of backdoor, we sequentially installed multiple backdoors with minimal effect on the performance of each one (for example, anonymizing all ten celebrities on the same model reduced the success rate for each celebrity by no more than $0.91\%$). In all of our experiments, the benign accuracy of the network on other persons was degraded by no more than $0.48\%$ (and in most cases, it remained above $99.30\%$).
Relightify: Relightable 3D Faces from a Single Image via Diffusion Models
May 10, 2023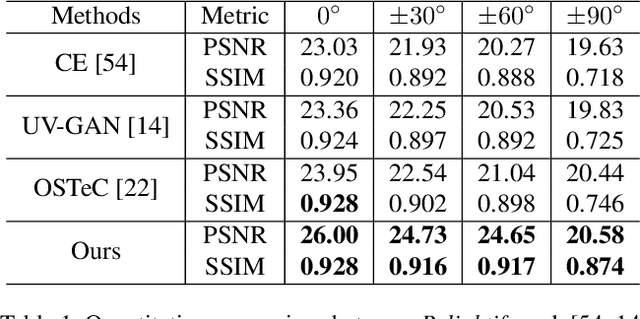
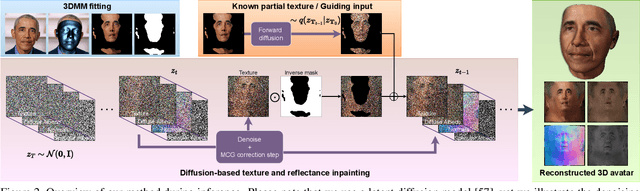


Following the remarkable success of diffusion models on image generation, recent works have also demonstrated their impressive ability to address a number of inverse problems in an unsupervised way, by properly constraining the sampling process based on a conditioning input. Motivated by this, in this paper, we present the first approach to use diffusion models as a prior for highly accurate 3D facial BRDF reconstruction from a single image. We start by leveraging a high-quality UV dataset of facial reflectance (diffuse and specular albedo and normals), which we render under varying illumination settings to simulate natural RGB textures and, then, train an unconditional diffusion model on concatenated pairs of rendered textures and reflectance components. At test time, we fit a 3D morphable model to the given image and unwrap the face in a partial UV texture. By sampling from the diffusion model, while retaining the observed texture part intact, the model inpaints not only the self-occluded areas but also the unknown reflectance components, in a single sequence of denoising steps. In contrast to existing methods, we directly acquire the observed texture from the input image, thus, resulting in more faithful and consistent reflectance estimation. Through a series of qualitative and quantitative comparisons, we demonstrate superior performance in both texture completion as well as reflectance reconstruction tasks.
Kinship Representation Learning with Face Componential Relation
Apr 22, 2023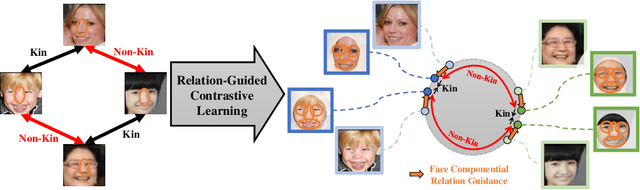
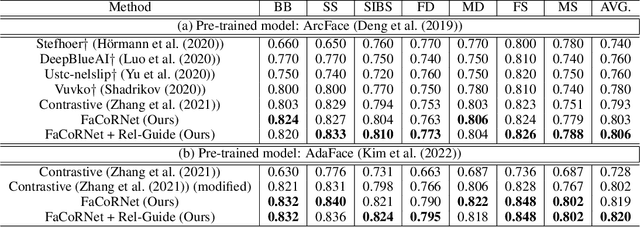
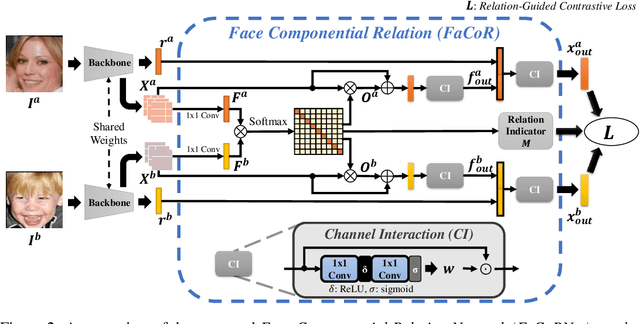
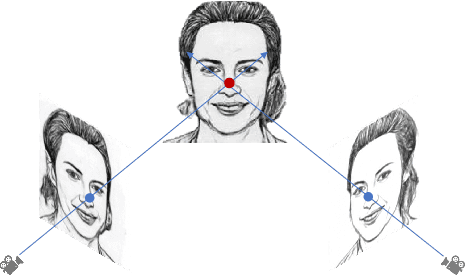
Kinship recognition aims to determine whether the subjects in two facial images are kin or non-kin, which is an emerging and challenging problem. However, most previous methods focus on heuristic designs without considering the spatial correlation between face images. In this paper, we aim to learn discriminative kinship representations embedded with the relation information between face components (e.g., eyes, nose, etc.). To achieve this goal, we propose the Face Componential Relation Network, which learns the relationship between face components among images with a cross-attention mechanism, which automatically learns the important facial regions for kinship recognition. Moreover, we propose Face Componential Relation Network (FaCoRNet), which adapts the loss function by the guidance from cross-attention to learn more discriminative feature representations. The proposed FaCoRNet outperforms previous state-of-the-art methods by large margins for the largest public kinship recognition FIW benchmark. The code will be publicly released upon acceptance.
Semantic-aware Generation of Multi-view Portrait Drawings
May 04, 2023

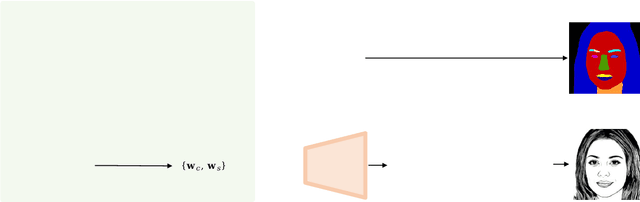
Neural radiance fields (NeRF) based methods have shown amazing performance in synthesizing 3D-consistent photographic images, but fail to generate multi-view portrait drawings. The key is that the basic assumption of these methods -- a surface point is consistent when rendered from different views -- doesn't hold for drawings. In a portrait drawing, the appearance of a facial point may changes when viewed from different angles. Besides, portrait drawings usually present little 3D information and suffer from insufficient training data. To combat this challenge, in this paper, we propose a Semantic-Aware GEnerator (SAGE) for synthesizing multi-view portrait drawings. Our motivation is that facial semantic labels are view-consistent and correlate with drawing techniques. We therefore propose to collaboratively synthesize multi-view semantic maps and the corresponding portrait drawings. To facilitate training, we design a semantic-aware domain translator, which generates portrait drawings based on features of photographic faces. In addition, use data augmentation via synthesis to mitigate collapsed results. We apply SAGE to synthesize multi-view portrait drawings in diverse artistic styles. Experimental results show that SAGE achieves significantly superior or highly competitive performance, compared to existing 3D-aware image synthesis methods. The codes are available at https://github.com/AiArt-HDU/SAGE.
NeuFace: Realistic 3D Neural Face Rendering from Multi-view Images
Mar 27, 2023
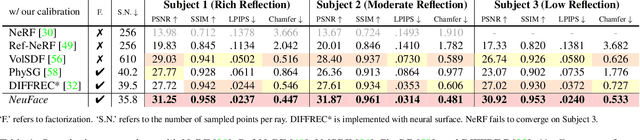
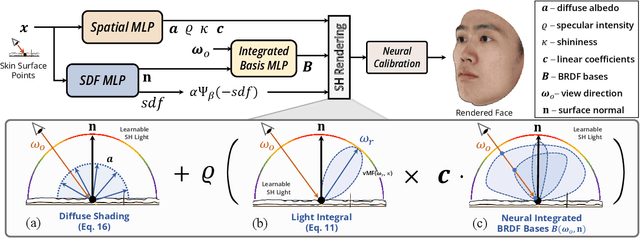
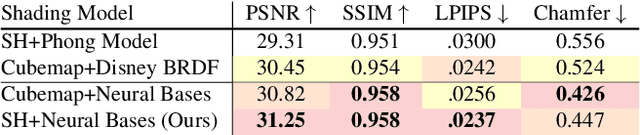
Realistic face rendering from multi-view images is beneficial to various computer vision and graphics applications. Due to the complex spatially-varying reflectance properties and geometry characteristics of faces, however, it remains challenging to recover 3D facial representations both faithfully and efficiently in the current studies. This paper presents a novel 3D face rendering model, namely NeuFace, to learn accurate and physically-meaningful underlying 3D representations by neural rendering techniques. It naturally incorporates the neural BRDFs into physically based rendering, capturing sophisticated facial geometry and appearance clues in a collaborative manner. Specifically, we introduce an approximated BRDF integration and a simple yet new low-rank prior, which effectively lower the ambiguities and boost the performance of the facial BRDFs. Extensive experiments demonstrate the superiority of NeuFace in human face rendering, along with a decent generalization ability to common objects.
Semantics-Guided Object Removal for Facial Images: with Broad Applicability and Robust Style Preservation
Sep 29, 2022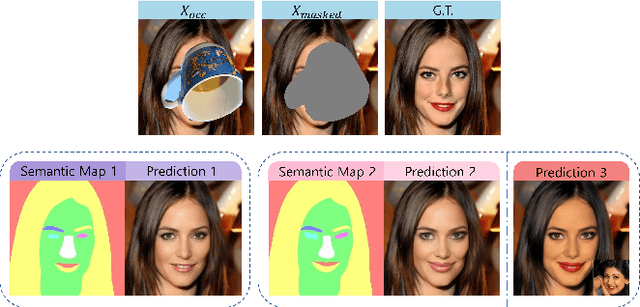

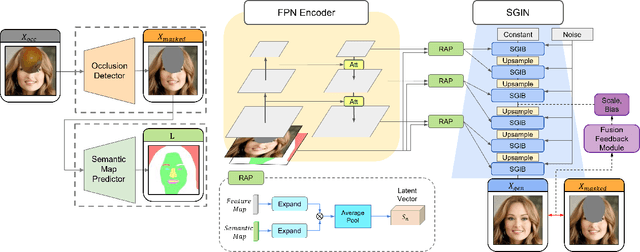
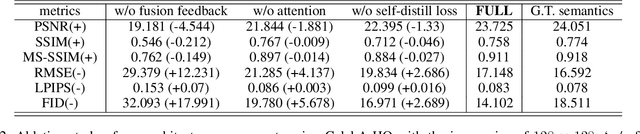
Object removal and image inpainting in facial images is a task in which objects that occlude a facial image are specifically targeted, removed, and replaced by a properly reconstructed facial image. Two different approaches utilizing U-net and modulated generator respectively have been widely endorsed for this task for their unique advantages but notwithstanding each method's innate disadvantages. U-net, a conventional approach for conditional GANs, retains fine details of unmasked regions but the style of the reconstructed image is inconsistent with the rest of the original image and only works robustly when the size of the occluding object is small enough. In contrast, the modulated generative approach can deal with a larger occluded area in an image and provides {a} more consistent style, yet it usually misses out on most of the detailed features. This trade-off between these two models necessitates an invention of a model that can be applied to any size of mask while maintaining a consistent style and preserving minute details of facial features. Here, we propose Semantics-Guided Inpainting Network (SGIN) which itself is a modification of the modulated generator, aiming to take advantage of its advanced generative capability and preserve the high-fidelity details of the original image. By using the guidance of a semantic map, our model is capable of manipulating facial features which grants direction to the one-to-many problem for further practicability.
BiTrackGAN: Cascaded CycleGANs to Constraint Face Aging
Apr 22, 2023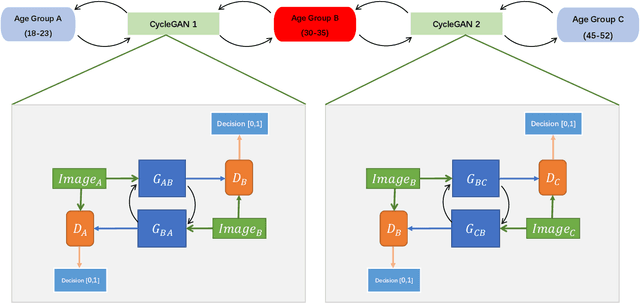


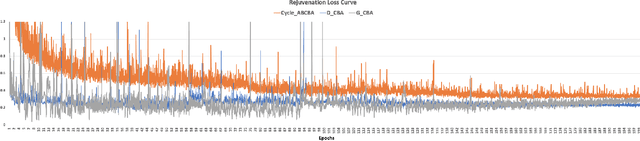
With the increased accuracy of modern computer vision technology, many access control systems are equipped with face recognition functions for faster identification. In order to maintain high recognition accuracy, it is necessary to keep the face database up-to-date. However, it is impractical to collect the latest facial picture of the system's user through human effort. Thus, we propose a bottom-up training method for our proposed network to address this challenge. Essentially, our proposed network is a translation pipeline that cascades two CycleGAN blocks (a widely used unpaired image-to-image translation generative adversarial network) called BiTrackGAN. By bottom-up training, it induces an ideal intermediate state between these two CycleGAN blocks, namely the constraint mechanism. Experimental results show that BiTrackGAN achieves more reasonable and diverse cross-age facial synthesis than other CycleGAN-related methods. As far as we know, it is a novel and effective constraint mechanism for more reason and accurate aging synthesis through the CycleGAN approach.
Optimal Transport-based Identity Matching for Identity-invariant Facial Expression Recognition
Sep 25, 2022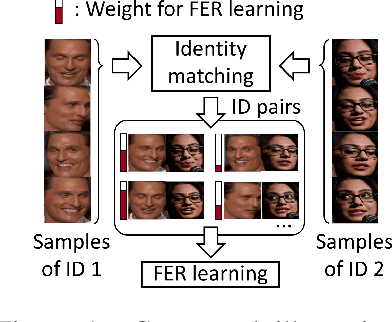
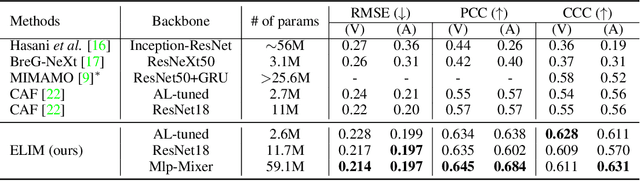
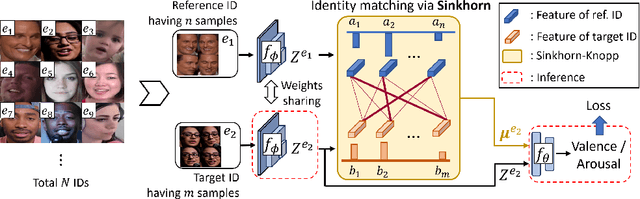
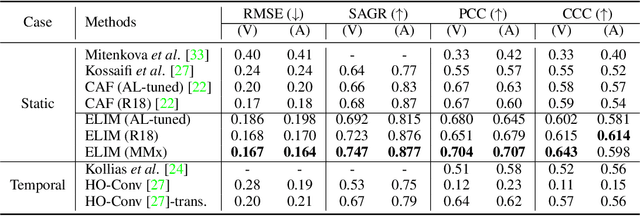
Identity-invariant facial expression recognition (FER) has been one of the challenging computer vision tasks. Since conventional FER schemes do not explicitly address the inter-identity variation of facial expressions, their neural network models still operate depending on facial identity. This paper proposes to quantify the inter-identity variation by utilizing pairs of similar expressions explored through a specific matching process. We formulate the identity matching process as an Optimal Transport (OT) problem. Specifically, to find pairs of similar expressions from different identities, we define the inter-feature similarity as a transportation cost. Then, optimal identity matching to find the optimal flow with minimum transportation cost is performed by Sinkhorn-Knopp iteration. The proposed matching method is not only easy to plug in to other models, but also requires only acceptable computational overhead. Extensive simulations prove that the proposed FER method improves the PCC/CCC performance by up to 10\% or more compared to the runner-up on wild datasets. The source code and software demo are available at https://github.com/kdhht2334/ELIM_FER.
Multi-task Cross Attention Network in Facial Behavior Analysis
Jul 21, 2022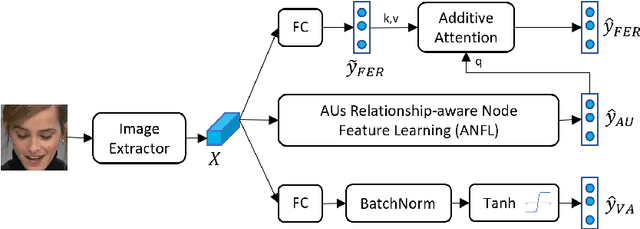

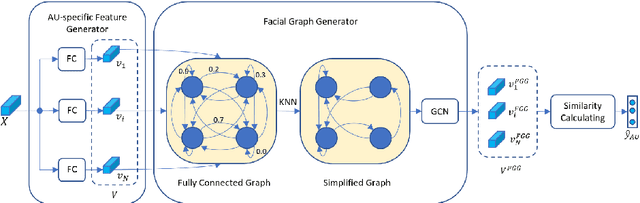
Facial behavior analysis is a broad topic with various categories such as facial emotion recognition, age and gender recognition, ... Many studies focus on individual tasks while the multi-task learning approach is still open and requires more research. In this paper, we present our solution and experiment result for the Multi-Task Learning challenge of the Affective Behavior Analysis in-the-wild competition. The challenge is a combination of three tasks: action unit detection, facial expression recognition and valance-arousal estimation. To address this challenge, we introduce a cross-attentive module to improve multi-task learning performance. Additionally, a facial graph is applied to capture the association among action units. As a result, we achieve the evaluation measure of 1.24 on the validation data provided by the organizers, which is better than the baseline result of 0.30.