 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
FFHQ-UV: Normalized Facial UV-Texture Dataset for 3D Face Reconstruction
Nov 25, 2022
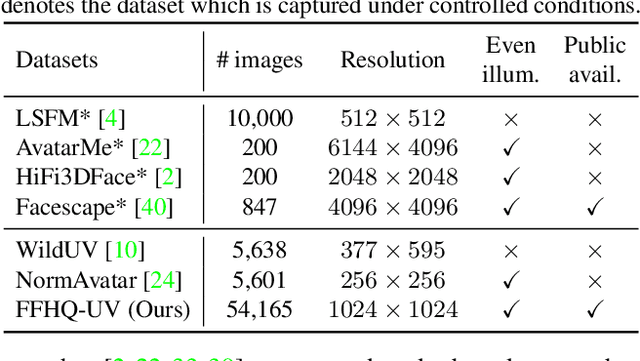

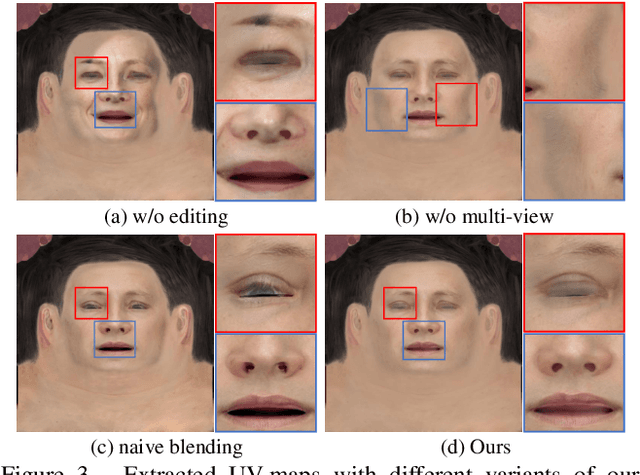

We present a large-scale facial UV-texture dataset that contains over 50,000 high-quality texture UV-maps with even illuminations, neutral expressions, and cleaned facial regions, which are desired characteristics for rendering realistic 3D face models under different lighting conditions. The dataset is derived from a large-scale face image dataset namely FFHQ, with the help of our fully automatic and robust UV-texture production pipeline. Our pipeline utilizes the recent advances in StyleGAN-based facial image editing approaches to generate multi-view normalized face images from single-image inputs. An elaborated UV-texture extraction, correction, and completion procedure is then applied to produce high-quality UV-maps from the normalized face images. Compared with existing UV-texture datasets, our dataset has more diverse and higher-quality texture maps. We further train a GAN-based texture decoder as the nonlinear texture basis for parametric fitting based 3D face reconstruction. Experiments show that our method improves the reconstruction accuracy over state-of-the-art approaches, and more importantly, produces high-quality texture maps that are ready for realistic renderings. The dataset, code, and pre-trained texture decoder are publicly available at https://github.com/csbhr/FFHQ-UV.
Global-to-local Expression-aware Embeddings for Facial Action Unit Detection
Oct 28, 2022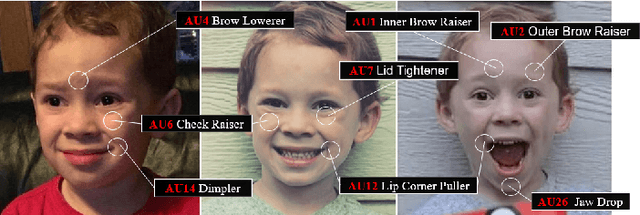
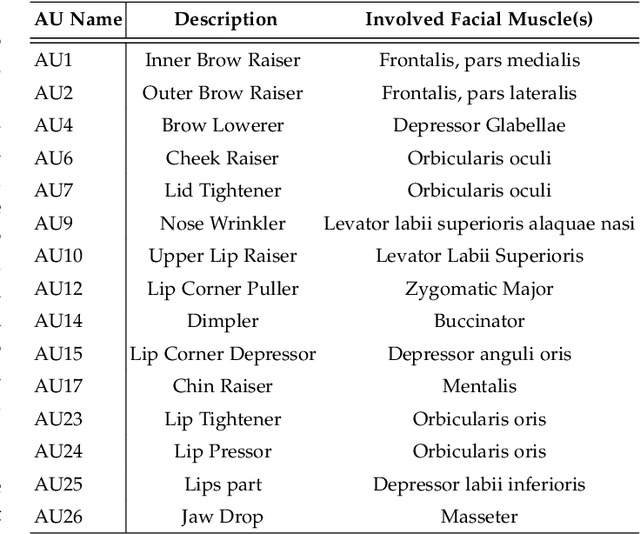
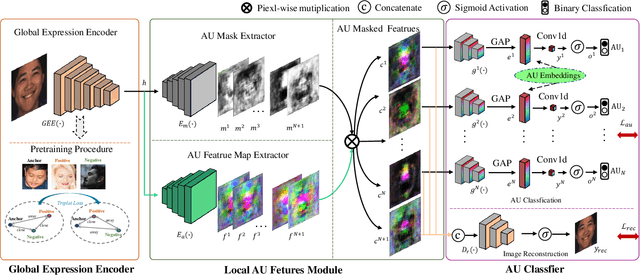
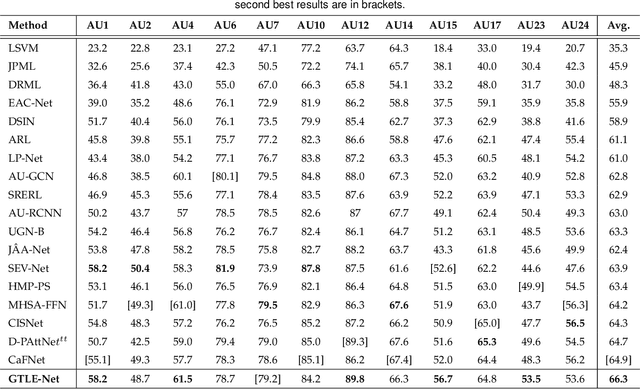
Expressions and facial action units (AUs) are two levels of facial behavior descriptors. Expression auxiliary information has been widely used to improve the AU detection performance. However, most existing expression representations can only describe pre-determined discrete categories (e.g., Angry, Disgust, Happy, Sad, etc.) and cannot capture subtle expression transformations like AUs. In this paper, we propose a novel fine-grained \textsl{Global Expression representation Encoder} to capture subtle and continuous facial movements, to promote AU detection. To obtain such a global expression representation, we propose to train an expression embedding model on a large-scale expression dataset according to global expression similarity. Moreover, considering the local definition of AUs, it is essential to extract local AU features. Therefore, we design a \textsl{Local AU Features Module} to generate local facial features for each AU. Specifically, it consists of an AU feature map extractor and a corresponding AU mask extractor. First, the two extractors transform the global expression representation into AU feature maps and masks, respectively. Then, AU feature maps and their corresponding AU masks are multiplied to generate AU masked features focusing on local facial region. Finally, the AU masked features are fed into an AU classifier for judging the AU occurrence. Extensive experiment results demonstrate the superiority of our proposed method. Our method validly outperforms previous works and achieves state-of-the-art performances on widely-used face datasets, including BP4D, DISFA, and BP4D+.
Articulated 3D Head Avatar Generation using Text-to-Image Diffusion Models
Jul 10, 2023
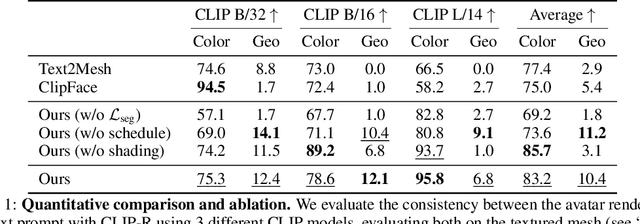

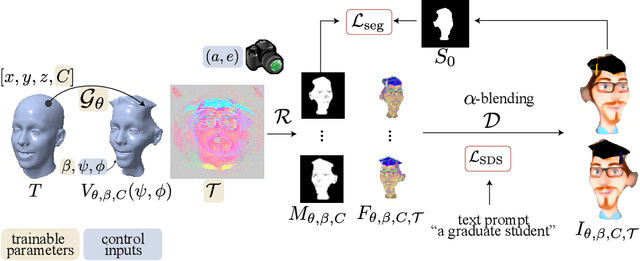
The ability to generate diverse 3D articulated head avatars is vital to a plethora of applications, including augmented reality, cinematography, and education. Recent work on text-guided 3D object generation has shown great promise in addressing these needs. These methods directly leverage pre-trained 2D text-to-image diffusion models to generate 3D-multi-view-consistent radiance fields of generic objects. However, due to the lack of geometry and texture priors, these methods have limited control over the generated 3D objects, making it difficult to operate inside a specific domain, e.g., human heads. In this work, we develop a new approach to text-guided 3D head avatar generation to address this limitation. Our framework directly operates on the geometry and texture of an articulable 3D morphable model (3DMM) of a head, and introduces novel optimization procedures to update the geometry and texture while keeping the 2D and 3D facial features aligned. The result is a 3D head avatar that is consistent with the text description and can be readily articulated using the deformation model of the 3DMM. We show that our diffusion-based articulated head avatars outperform state-of-the-art approaches for this task. The latter are typically based on CLIP, which is known to provide limited diversity of generation and accuracy for 3D object generation.
MiVOLO: Multi-input Transformer for Age and Gender Estimation
Jul 10, 2023
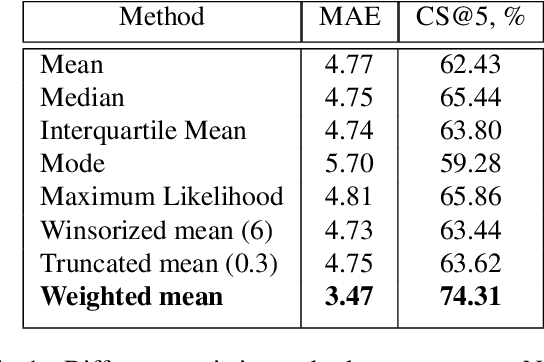
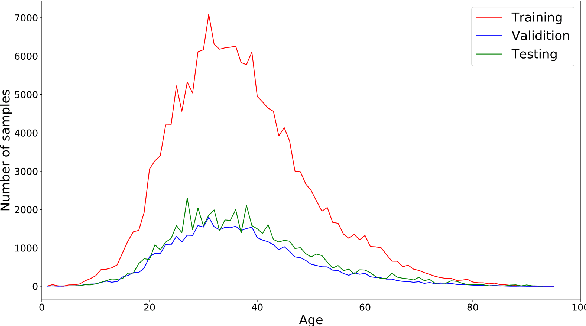
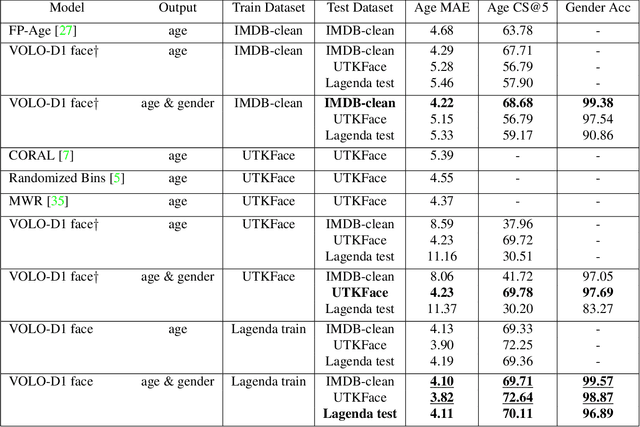
Age and gender recognition in the wild is a highly challenging task: apart from the variability of conditions, pose complexities, and varying image quality, there are cases where the face is partially or completely occluded. We present MiVOLO (Multi Input VOLO), a straightforward approach for age and gender estimation using the latest vision transformer. Our method integrates both tasks into a unified dual input/output model, leveraging not only facial information but also person image data. This improves the generalization ability of our model and enables it to deliver satisfactory results even when the face is not visible in the image. To evaluate our proposed model, we conduct experiments on four popular benchmarks and achieve state-of-the-art performance, while demonstrating real-time processing capabilities. Additionally, we introduce a novel benchmark based on images from the Open Images Dataset. The ground truth annotations for this benchmark have been meticulously generated by human annotators, resulting in high accuracy answers due to the smart aggregation of votes. Furthermore, we compare our model's age recognition performance with human-level accuracy and demonstrate that it significantly outperforms humans across a majority of age ranges. Finally, we grant public access to our models, along with the code for validation and inference. In addition, we provide extra annotations for used datasets and introduce our new benchmark.
Visual-Aware Text-to-Speech
Jun 21, 2023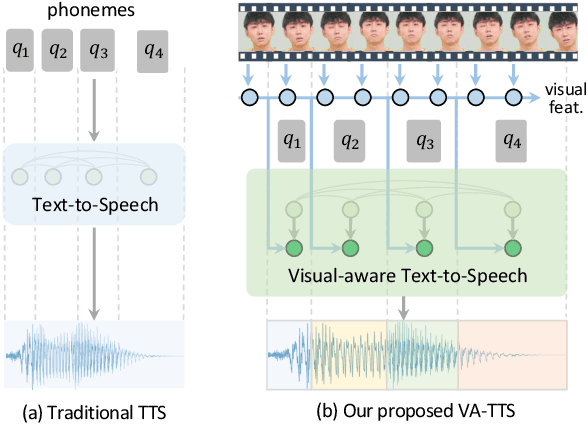
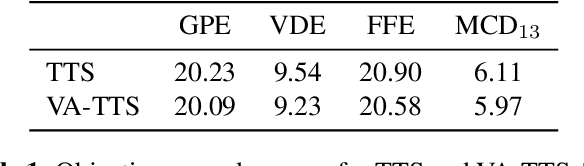
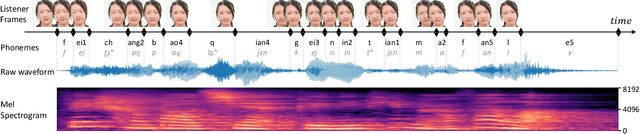
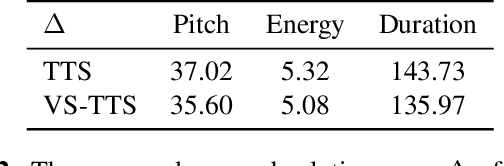
Dynamically synthesizing talking speech that actively responds to a listening head is critical during the face-to-face interaction. For example, the speaker could take advantage of the listener's facial expression to adjust the tones, stressed syllables, or pauses. In this work, we present a new visual-aware text-to-speech (VA-TTS) task to synthesize speech conditioned on both textual inputs and sequential visual feedback (e.g., nod, smile) of the listener in face-to-face communication. Different from traditional text-to-speech, VA-TTS highlights the impact of visual modality. On this newly-minted task, we devise a baseline model to fuse phoneme linguistic information and listener visual signals for speech synthesis. Extensive experiments on multimodal conversation dataset ViCo-X verify our proposal for generating more natural audio with scenario-appropriate rhythm and prosody.
* accepted as oral and top 3% paper by ICASSP 2023
3D GAN Inversion with Facial Symmetry Prior
Nov 30, 2022
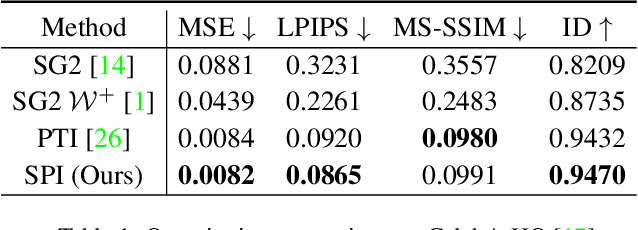
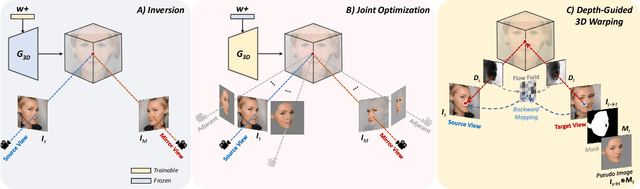
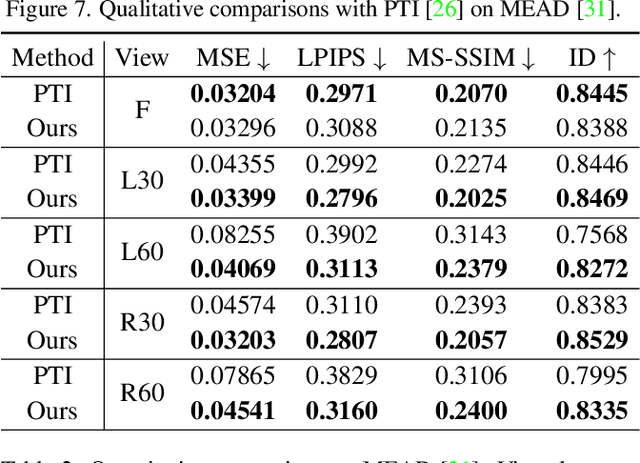
Recently, a surge of high-quality 3D-aware GANs have been proposed, which leverage the generative power of neural rendering. It is natural to associate 3D GANs with GAN inversion methods to project a real image into the generator's latent space, allowing free-view consistent synthesis and editing, referred as 3D GAN inversion. Although with the facial prior preserved in pre-trained 3D GANs, reconstructing a 3D portrait with only one monocular image is still an ill-pose problem. The straightforward application of 2D GAN inversion methods focuses on texture similarity only while ignoring the correctness of 3D geometry shapes. It may raise geometry collapse effects, especially when reconstructing a side face under an extreme pose. Besides, the synthetic results in novel views are prone to be blurry. In this work, we propose a novel method to promote 3D GAN inversion by introducing facial symmetry prior. We design a pipeline and constraints to make full use of the pseudo auxiliary view obtained via image flipping, which helps obtain a robust and reasonable geometry shape during the inversion process. To enhance texture fidelity in unobserved viewpoints, pseudo labels from depth-guided 3D warping can provide extra supervision. We design constraints aimed at filtering out conflict areas for optimization in asymmetric situations. Comprehensive quantitative and qualitative evaluations on image reconstruction and editing demonstrate the superiority of our method.
RidgeBase: A Cross-Sensor Multi-Finger Contactless Fingerprint Dataset
Jul 09, 2023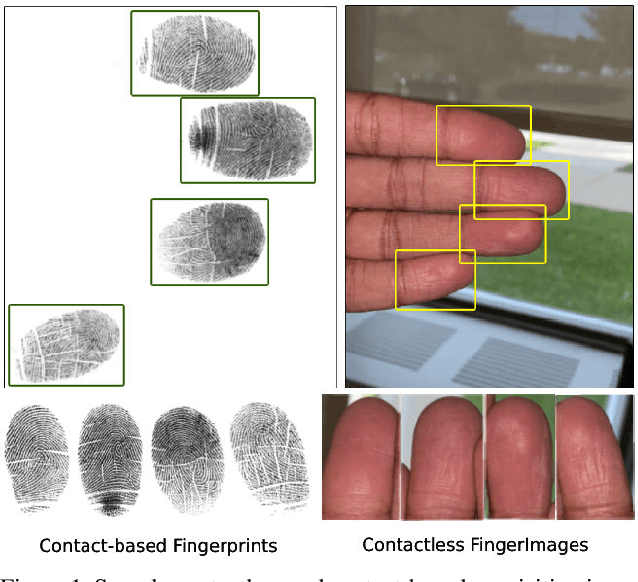


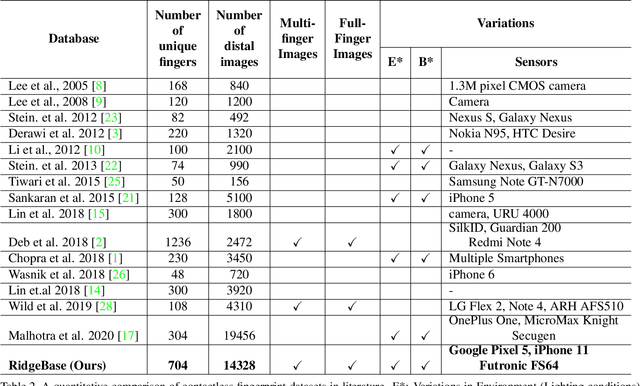
Contactless fingerprint matching using smartphone cameras can alleviate major challenges of traditional fingerprint systems including hygienic acquisition, portability and presentation attacks. However, development of practical and robust contactless fingerprint matching techniques is constrained by the limited availability of large scale real-world datasets. To motivate further advances in contactless fingerprint matching across sensors, we introduce the RidgeBase benchmark dataset. RidgeBase consists of more than 15,000 contactless and contact-based fingerprint image pairs acquired from 88 individuals under different background and lighting conditions using two smartphone cameras and one flatbed contact sensor. Unlike existing datasets, RidgeBase is designed to promote research under different matching scenarios that include Single Finger Matching and Multi-Finger Matching for both contactless- to-contactless (CL2CL) and contact-to-contactless (C2CL) verification and identification. Furthermore, due to the high intra-sample variance in contactless fingerprints belonging to the same finger, we propose a set-based matching protocol inspired by the advances in facial recognition datasets. This protocol is specifically designed for pragmatic contactless fingerprint matching that can account for variances in focus, polarity and finger-angles. We report qualitative and quantitative baseline results for different protocols using a COTS fingerprint matcher (Verifinger) and a Deep CNN based approach on the RidgeBase dataset. The dataset can be downloaded here: https://www.buffalo.edu/cubs/research/datasets/ridgebase-benchmark-dataset.html
* Paper accepted at IJCB 2022
Motion-X: A Large-scale 3D Expressive Whole-body Human Motion Dataset
Jul 03, 2023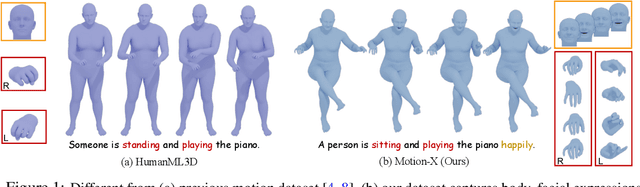
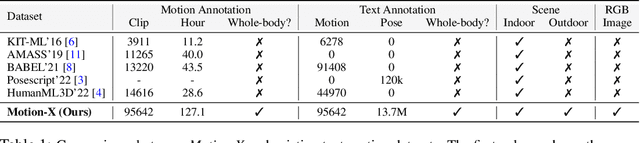
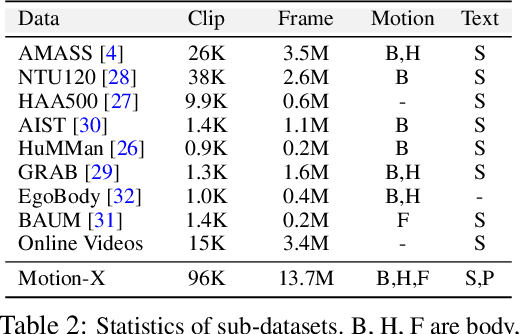
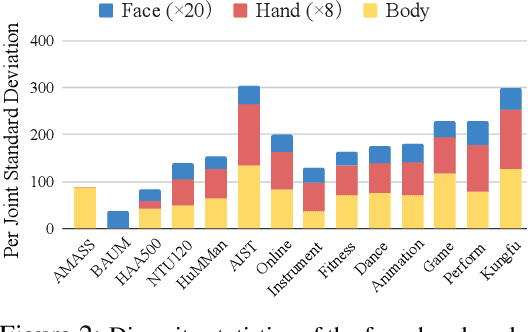
In this paper, we present Motion-X, a large-scale 3D expressive whole-body motion dataset. Existing motion datasets predominantly contain body-only poses, lacking facial expressions, hand gestures, and fine-grained pose descriptions. Moreover, they are primarily collected from limited laboratory scenes with textual descriptions manually labeled, which greatly limits their scalability. To overcome these limitations, we develop a whole-body motion and text annotation pipeline, which can automatically annotate motion from either single- or multi-view videos and provide comprehensive semantic labels for each video and fine-grained whole-body pose descriptions for each frame. This pipeline is of high precision, cost-effective, and scalable for further research. Based on it, we construct Motion-X, which comprises 13.7M precise 3D whole-body pose annotations (i.e., SMPL-X) covering 96K motion sequences from massive scenes. Besides, Motion-X provides 13.7M frame-level whole-body pose descriptions and 96K sequence-level semantic labels. Comprehensive experiments demonstrate the accuracy of the annotation pipeline and the significant benefit of Motion-X in enhancing expressive, diverse, and natural motion generation, as well as 3D whole-body human mesh recovery.
High-Res Facial Appearance Capture from Polarized Smartphone Images
Dec 02, 2022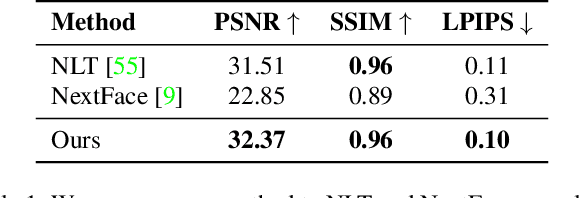
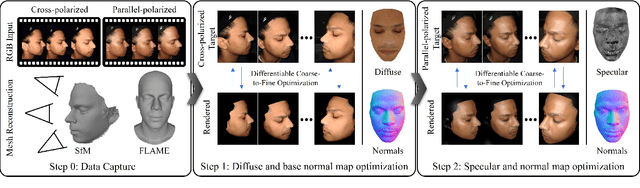
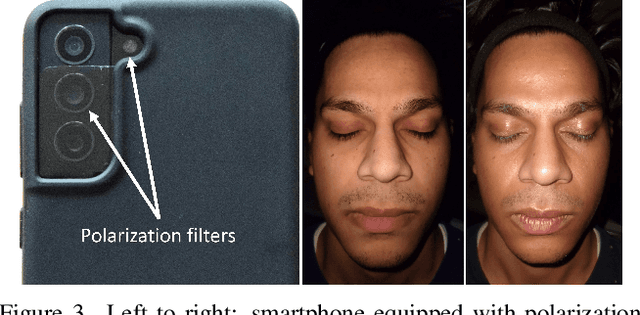
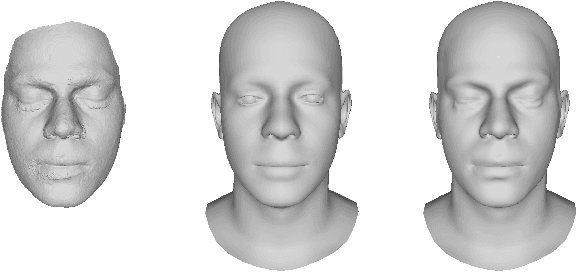
We propose a novel method for high-quality facial texture reconstruction from RGB images using a novel capturing routine based on a single smartphone which we equip with an inexpensive polarization foil. Specifically, we turn the flashlight into a polarized light source and add a polarization filter on top of the camera. Leveraging this setup, we capture the face of a subject with cross-polarized and parallel-polarized light. For each subject, we record two short sequences in a dark environment under flash illumination with different light polarization using the modified smartphone. Based on these observations, we reconstruct an explicit surface mesh of the face using structure from motion. We then exploit the camera and light co-location within a differentiable renderer to optimize the facial textures using an analysis-by-synthesis approach. Our method optimizes for high-resolution normal textures, diffuse albedo, and specular albedo using a coarse-to-fine optimization scheme. We show that the optimized textures can be used in a standard rendering pipeline to synthesize high-quality photo-realistic 3D digital humans in novel environments.
Inserting Anybody in Diffusion Models via Celeb Basis
Jun 01, 2023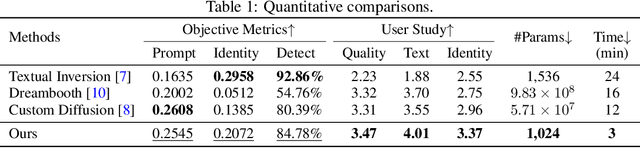
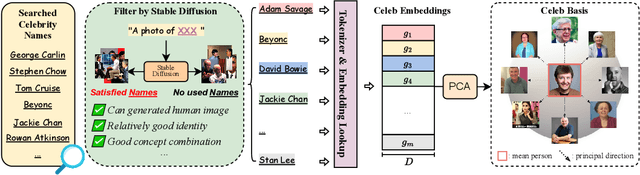
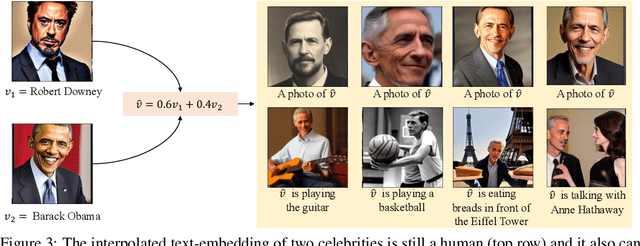
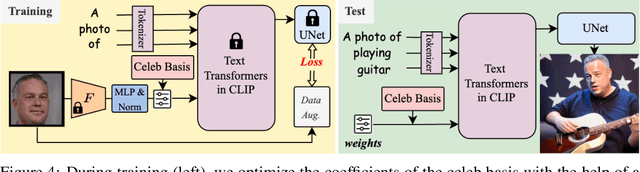
Exquisite demand exists for customizing the pretrained large text-to-image model, $\textit{e.g.}$, Stable Diffusion, to generate innovative concepts, such as the users themselves. However, the newly-added concept from previous customization methods often shows weaker combination abilities than the original ones even given several images during training. We thus propose a new personalization method that allows for the seamless integration of a unique individual into the pre-trained diffusion model using just $\textbf{one facial photograph}$ and only $\textbf{1024 learnable parameters}$ under $\textbf{3 minutes}$. So as we can effortlessly generate stunning images of this person in any pose or position, interacting with anyone and doing anything imaginable from text prompts. To achieve this, we first analyze and build a well-defined celeb basis from the embedding space of the pre-trained large text encoder. Then, given one facial photo as the target identity, we generate its own embedding by optimizing the weight of this basis and locking all other parameters. Empowered by the proposed celeb basis, the new identity in our customized model showcases a better concept combination ability than previous personalization methods. Besides, our model can also learn several new identities at once and interact with each other where the previous customization model fails to. The code will be released.