 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
FFHQ-UV: Normalized Facial UV-Texture Dataset for 3D Face Reconstruction
Nov 25, 2022
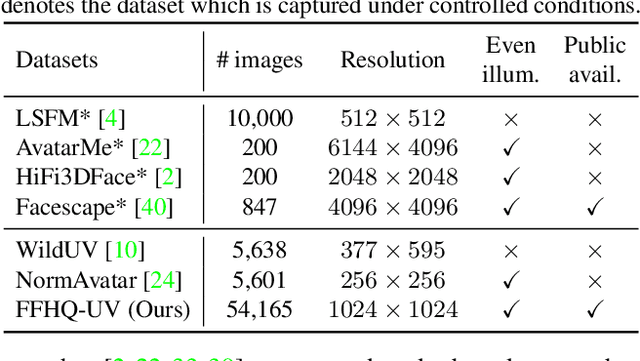

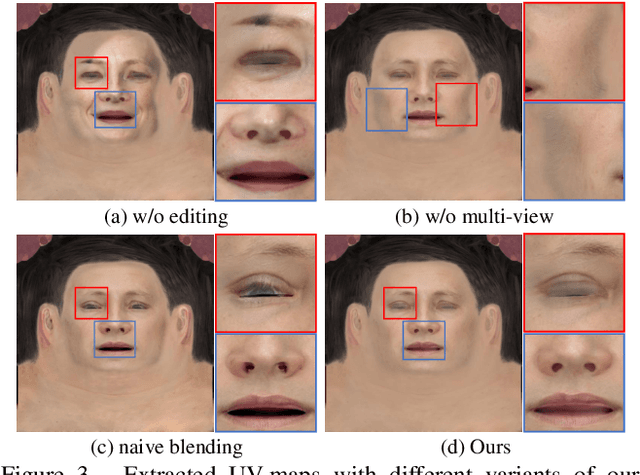

We present a large-scale facial UV-texture dataset that contains over 50,000 high-quality texture UV-maps with even illuminations, neutral expressions, and cleaned facial regions, which are desired characteristics for rendering realistic 3D face models under different lighting conditions. The dataset is derived from a large-scale face image dataset namely FFHQ, with the help of our fully automatic and robust UV-texture production pipeline. Our pipeline utilizes the recent advances in StyleGAN-based facial image editing approaches to generate multi-view normalized face images from single-image inputs. An elaborated UV-texture extraction, correction, and completion procedure is then applied to produce high-quality UV-maps from the normalized face images. Compared with existing UV-texture datasets, our dataset has more diverse and higher-quality texture maps. We further train a GAN-based texture decoder as the nonlinear texture basis for parametric fitting based 3D face reconstruction. Experiments show that our method improves the reconstruction accuracy over state-of-the-art approaches, and more importantly, produces high-quality texture maps that are ready for realistic renderings. The dataset, code, and pre-trained texture decoder are publicly available at https://github.com/csbhr/FFHQ-UV.
Inserting Anybody in Diffusion Models via Celeb Basis
Jun 01, 2023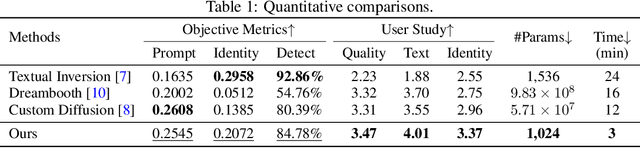
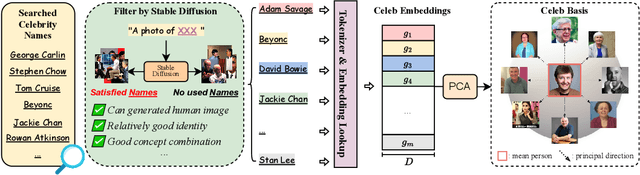
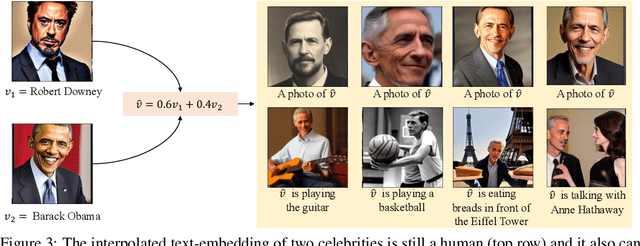
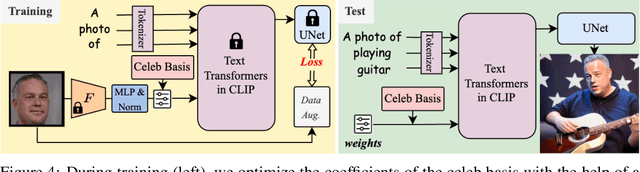
Exquisite demand exists for customizing the pretrained large text-to-image model, $\textit{e.g.}$, Stable Diffusion, to generate innovative concepts, such as the users themselves. However, the newly-added concept from previous customization methods often shows weaker combination abilities than the original ones even given several images during training. We thus propose a new personalization method that allows for the seamless integration of a unique individual into the pre-trained diffusion model using just $\textbf{one facial photograph}$ and only $\textbf{1024 learnable parameters}$ under $\textbf{3 minutes}$. So as we can effortlessly generate stunning images of this person in any pose or position, interacting with anyone and doing anything imaginable from text prompts. To achieve this, we first analyze and build a well-defined celeb basis from the embedding space of the pre-trained large text encoder. Then, given one facial photo as the target identity, we generate its own embedding by optimizing the weight of this basis and locking all other parameters. Empowered by the proposed celeb basis, the new identity in our customized model showcases a better concept combination ability than previous personalization methods. Besides, our model can also learn several new identities at once and interact with each other where the previous customization model fails to. The code will be released.
Global-to-local Expression-aware Embeddings for Facial Action Unit Detection
Oct 28, 2022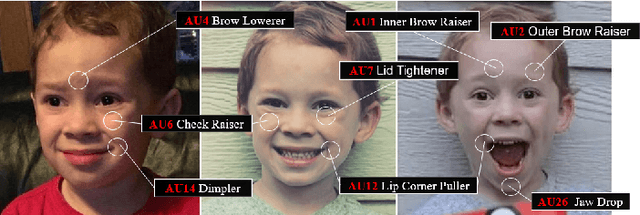
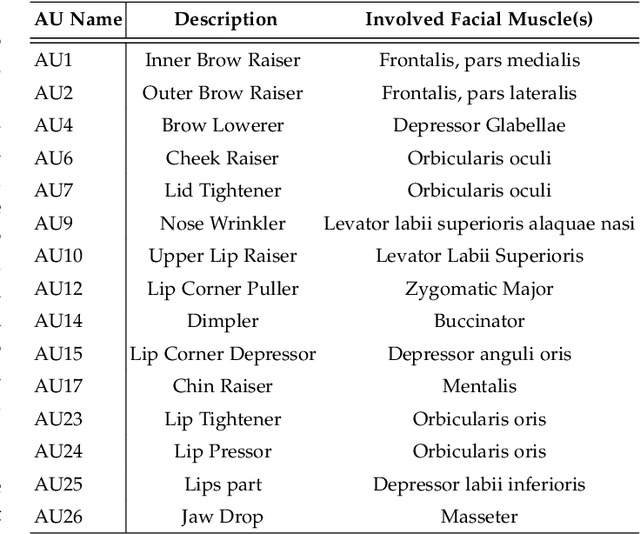
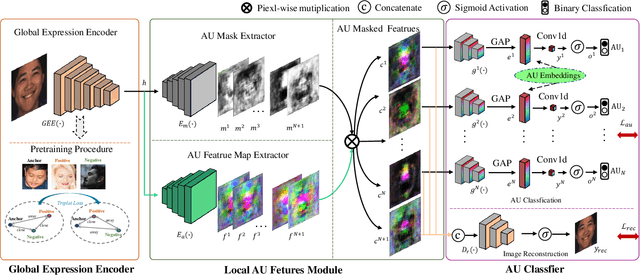
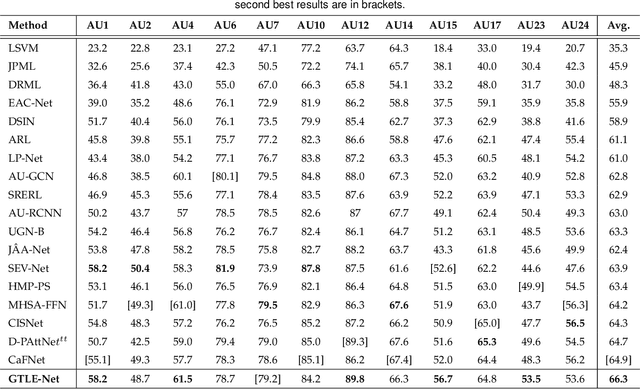
Expressions and facial action units (AUs) are two levels of facial behavior descriptors. Expression auxiliary information has been widely used to improve the AU detection performance. However, most existing expression representations can only describe pre-determined discrete categories (e.g., Angry, Disgust, Happy, Sad, etc.) and cannot capture subtle expression transformations like AUs. In this paper, we propose a novel fine-grained \textsl{Global Expression representation Encoder} to capture subtle and continuous facial movements, to promote AU detection. To obtain such a global expression representation, we propose to train an expression embedding model on a large-scale expression dataset according to global expression similarity. Moreover, considering the local definition of AUs, it is essential to extract local AU features. Therefore, we design a \textsl{Local AU Features Module} to generate local facial features for each AU. Specifically, it consists of an AU feature map extractor and a corresponding AU mask extractor. First, the two extractors transform the global expression representation into AU feature maps and masks, respectively. Then, AU feature maps and their corresponding AU masks are multiplied to generate AU masked features focusing on local facial region. Finally, the AU masked features are fed into an AU classifier for judging the AU occurrence. Extensive experiment results demonstrate the superiority of our proposed method. Our method validly outperforms previous works and achieves state-of-the-art performances on widely-used face datasets, including BP4D, DISFA, and BP4D+.
3D GAN Inversion with Facial Symmetry Prior
Nov 30, 2022
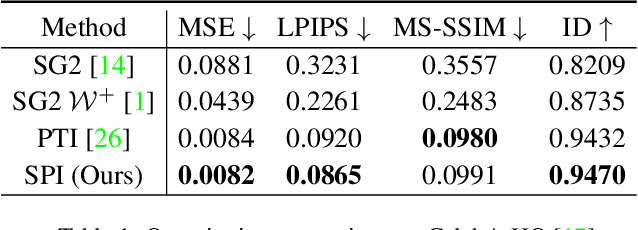
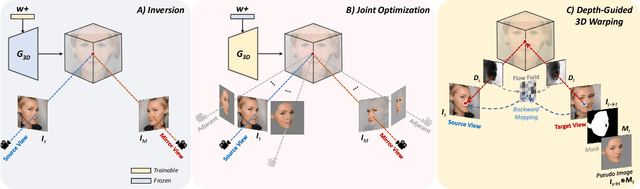
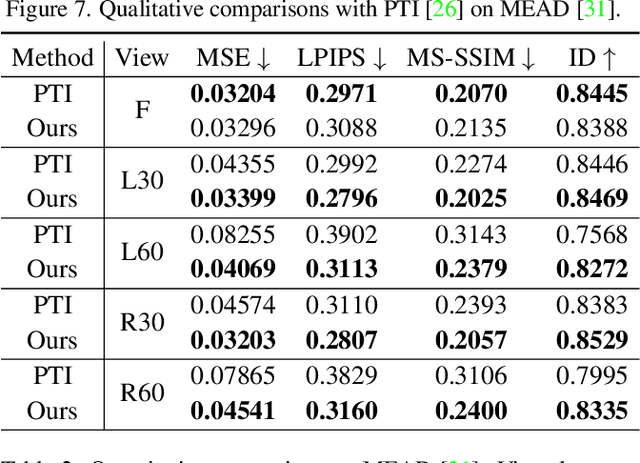
Recently, a surge of high-quality 3D-aware GANs have been proposed, which leverage the generative power of neural rendering. It is natural to associate 3D GANs with GAN inversion methods to project a real image into the generator's latent space, allowing free-view consistent synthesis and editing, referred as 3D GAN inversion. Although with the facial prior preserved in pre-trained 3D GANs, reconstructing a 3D portrait with only one monocular image is still an ill-pose problem. The straightforward application of 2D GAN inversion methods focuses on texture similarity only while ignoring the correctness of 3D geometry shapes. It may raise geometry collapse effects, especially when reconstructing a side face under an extreme pose. Besides, the synthetic results in novel views are prone to be blurry. In this work, we propose a novel method to promote 3D GAN inversion by introducing facial symmetry prior. We design a pipeline and constraints to make full use of the pseudo auxiliary view obtained via image flipping, which helps obtain a robust and reasonable geometry shape during the inversion process. To enhance texture fidelity in unobserved viewpoints, pseudo labels from depth-guided 3D warping can provide extra supervision. We design constraints aimed at filtering out conflict areas for optimization in asymmetric situations. Comprehensive quantitative and qualitative evaluations on image reconstruction and editing demonstrate the superiority of our method.
High-Res Facial Appearance Capture from Polarized Smartphone Images
Dec 02, 2022
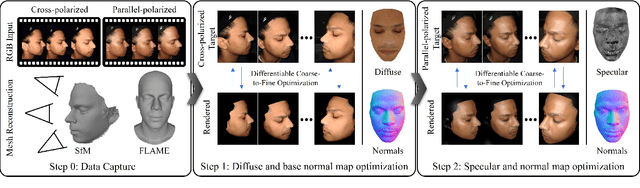
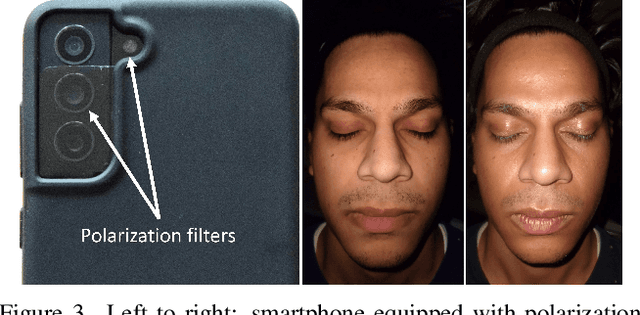
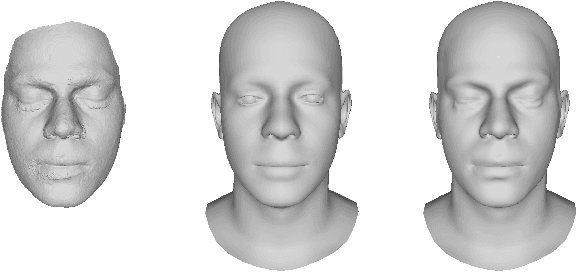
We propose a novel method for high-quality facial texture reconstruction from RGB images using a novel capturing routine based on a single smartphone which we equip with an inexpensive polarization foil. Specifically, we turn the flashlight into a polarized light source and add a polarization filter on top of the camera. Leveraging this setup, we capture the face of a subject with cross-polarized and parallel-polarized light. For each subject, we record two short sequences in a dark environment under flash illumination with different light polarization using the modified smartphone. Based on these observations, we reconstruct an explicit surface mesh of the face using structure from motion. We then exploit the camera and light co-location within a differentiable renderer to optimize the facial textures using an analysis-by-synthesis approach. Our method optimizes for high-resolution normal textures, diffuse albedo, and specular albedo using a coarse-to-fine optimization scheme. We show that the optimized textures can be used in a standard rendering pipeline to synthesize high-quality photo-realistic 3D digital humans in novel environments.
StyleAvatar: Real-time Photo-realistic Portrait Avatar from a Single Video
May 01, 2023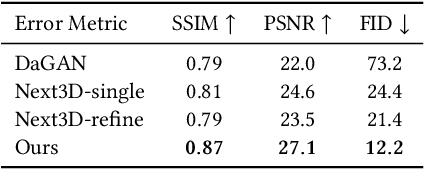
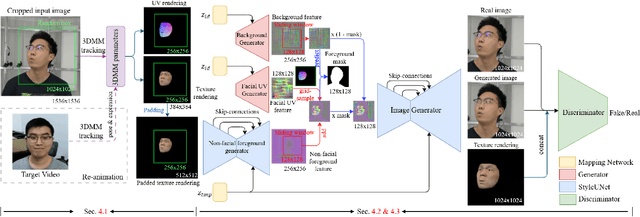
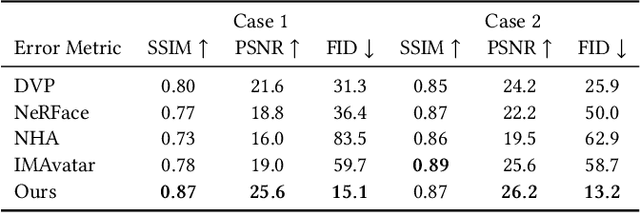

Face reenactment methods attempt to restore and re-animate portrait videos as realistically as possible. Existing methods face a dilemma in quality versus controllability: 2D GAN-based methods achieve higher image quality but suffer in fine-grained control of facial attributes compared with 3D counterparts. In this work, we propose StyleAvatar, a real-time photo-realistic portrait avatar reconstruction method using StyleGAN-based networks, which can generate high-fidelity portrait avatars with faithful expression control. We expand the capabilities of StyleGAN by introducing a compositional representation and a sliding window augmentation method, which enable faster convergence and improve translation generalization. Specifically, we divide the portrait scenes into three parts for adaptive adjustments: facial region, non-facial foreground region, and the background. Besides, our network leverages the best of UNet, StyleGAN and time coding for video learning, which enables high-quality video generation. Furthermore, a sliding window augmentation method together with a pre-training strategy are proposed to improve translation generalization and training performance, respectively. The proposed network can converge within two hours while ensuring high image quality and a forward rendering time of only 20 milliseconds. Furthermore, we propose a real-time live system, which further pushes research into applications. Results and experiments demonstrate the superiority of our method in terms of image quality, full portrait video generation, and real-time re-animation compared to existing facial reenactment methods. Training and inference code for this paper are at https://github.com/LizhenWangT/StyleAvatar.
MMNet: Multi-Collaboration and Multi-Supervision Network for Sequential Deepfake Detection
Jul 06, 2023Advanced manipulation techniques have provided criminals with opportunities to make social panic or gain illicit profits through the generation of deceptive media, such as forged face images. In response, various deepfake detection methods have been proposed to assess image authenticity. Sequential deepfake detection, which is an extension of deepfake detection, aims to identify forged facial regions with the correct sequence for recovery. Nonetheless, due to the different combinations of spatial and sequential manipulations, forged face images exhibit substantial discrepancies that severely impact detection performance. Additionally, the recovery of forged images requires knowledge of the manipulation model to implement inverse transformations, which is difficult to ascertain as relevant techniques are often concealed by attackers. To address these issues, we propose Multi-Collaboration and Multi-Supervision Network (MMNet) that handles various spatial scales and sequential permutations in forged face images and achieve recovery without requiring knowledge of the corresponding manipulation method. Furthermore, existing evaluation metrics only consider detection accuracy at a single inferring step, without accounting for the matching degree with ground-truth under continuous multiple steps. To overcome this limitation, we propose a novel evaluation metric called Complete Sequence Matching (CSM), which considers the detection accuracy at multiple inferring steps, reflecting the ability to detect integrally forged sequences. Extensive experiments on several typical datasets demonstrate that MMNet achieves state-of-the-art detection performance and independent recovery performance.
DifFIQA: Face Image Quality Assessment Using Denoising Diffusion Probabilistic Models
May 09, 2023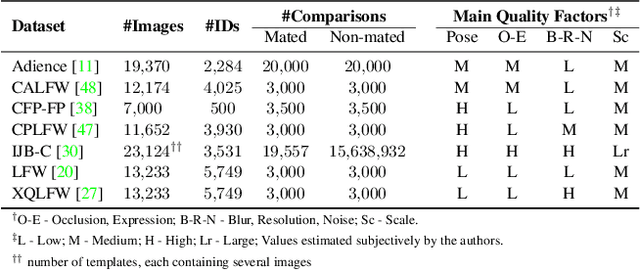
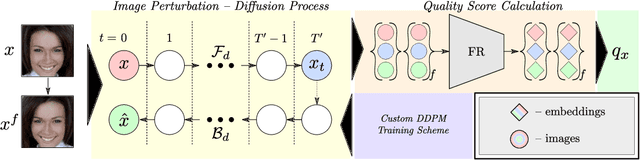
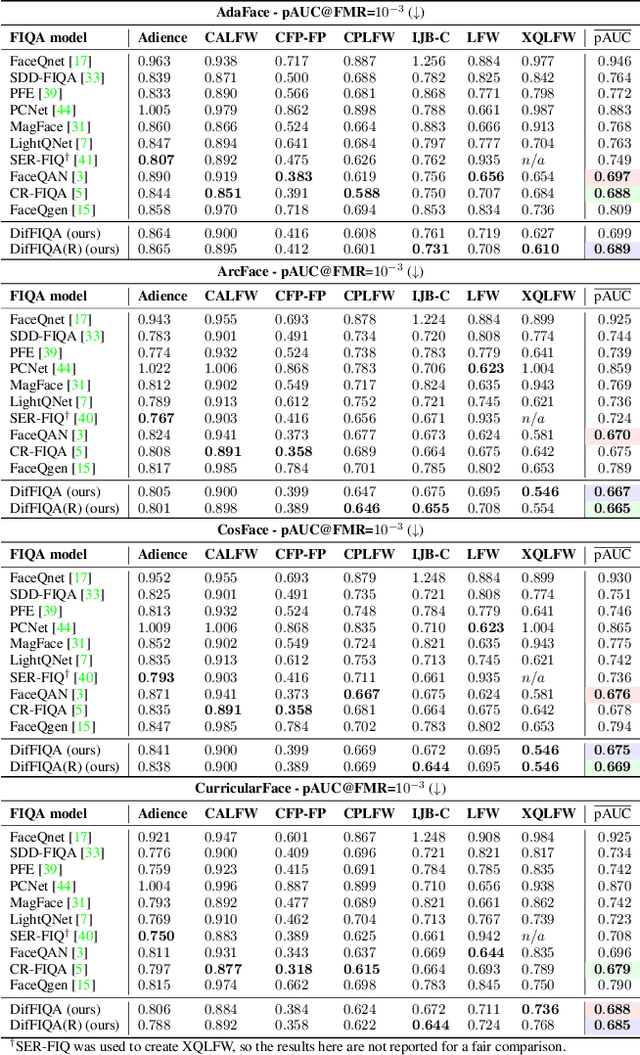

Modern face recognition (FR) models excel in constrained scenarios, but often suffer from decreased performance when deployed in unconstrained (real-world) environments due to uncertainties surrounding the quality of the captured facial data. Face image quality assessment (FIQA) techniques aim to mitigate these performance degradations by providing FR models with sample-quality predictions that can be used to reject low-quality samples and reduce false match errors. However, despite steady improvements, ensuring reliable quality estimates across facial images with diverse characteristics remains challenging. In this paper, we present a powerful new FIQA approach, named DifFIQA, which relies on denoising diffusion probabilistic models (DDPM) and ensures highly competitive results. The main idea behind the approach is to utilize the forward and backward processes of DDPMs to perturb facial images and quantify the impact of these perturbations on the corresponding image embeddings for quality prediction. Because the diffusion-based perturbations are computationally expensive, we also distill the knowledge encoded in DifFIQA into a regression-based quality predictor, called DifFIQA(R), that balances performance and execution time. We evaluate both models in comprehensive experiments on 7 datasets, with 4 target FR models and against 10 state-of-the-art FIQA techniques with highly encouraging results. The source code will be made publicly available.
Less is More: Facial Landmarks can Recognize a Spontaneous Smile
Oct 09, 2022
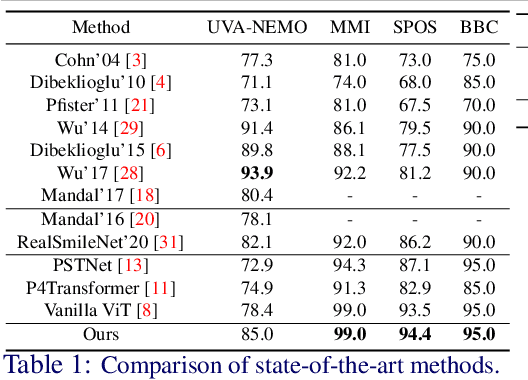
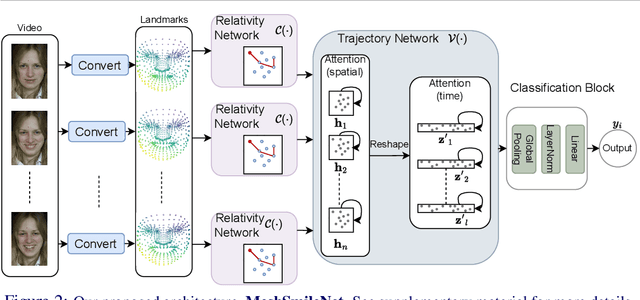
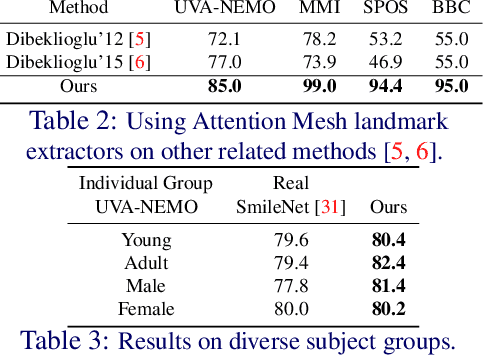
Smile veracity classification is a task of interpreting social interactions. Broadly, it distinguishes between spontaneous and posed smiles. Previous approaches used hand-engineered features from facial landmarks or considered raw smile videos in an end-to-end manner to perform smile classification tasks. Feature-based methods require intervention from human experts on feature engineering and heavy pre-processing steps. On the contrary, raw smile video inputs fed into end-to-end models bring more automation to the process with the cost of considering many redundant facial features (beyond landmark locations) that are mainly irrelevant to smile veracity classification. It remains unclear to establish discriminative features from landmarks in an end-to-end manner. We present a MeshSmileNet framework, a transformer architecture, to address the above limitations. To eliminate redundant facial features, our landmarks input is extracted from Attention Mesh, a pre-trained landmark detector. Again, to discover discriminative features, we consider the relativity and trajectory of the landmarks. For the relativity, we aggregate facial landmark that conceptually formats a curve at each frame to establish local spatial features. For the trajectory, we estimate the movements of landmark composed features across time by self-attention mechanism, which captures pairwise dependency on the trajectory of the same landmark. This idea allows us to achieve state-of-the-art performances on UVA-NEMO, BBC, MMI Facial Expression, and SPOS datasets.
End-to-End Machine Learning Framework for Facial AU Detection in Intensive Care Units
Nov 12, 2022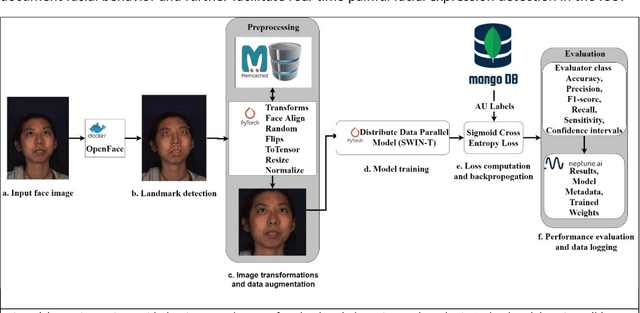
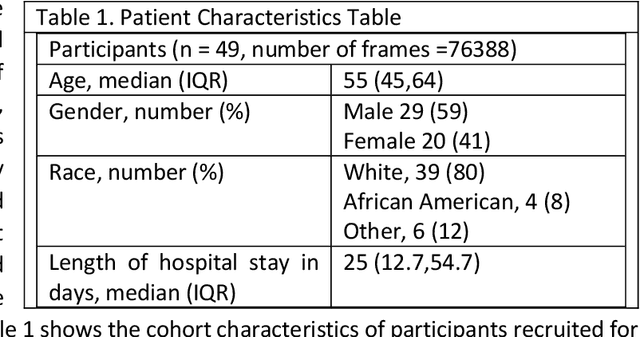

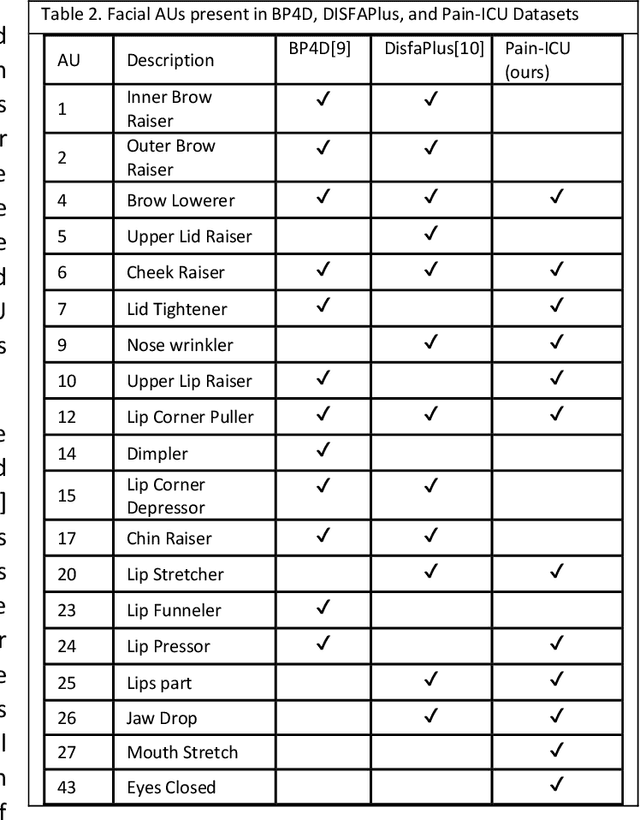
Pain is a common occurrence among patients admitted to Intensive Care Units. Pain assessment in ICU patients still remains a challenge for clinicians and ICU staff, specifically in cases of non-verbal sedated, mechanically ventilated, and intubated patients. Current manual observation-based pain assessment tools are limited by the frequency of pain observations administered and are subjective to the observer. Facial behavior is a major component in observation-based tools. Furthermore, previous literature shows the feasibility of painful facial expression detection using facial action units (AUs). However, these approaches are limited to controlled or semi-controlled environments and have never been validated in clinical settings. In this study, we present our Pain-ICU dataset, the largest dataset available targeting facial behavior analysis in the dynamic ICU environment. Our dataset comprises 76,388 patient facial image frames annotated with AUs obtained from 49 adult patients admitted to ICUs at the University of Florida Health Shands hospital. In this work, we evaluated two vision transformer models, namely ViT and SWIN, for AU detection on our Pain-ICU dataset and also external datasets. We developed a completely end-to-end AU detection pipeline with the objective of performing real-time AU detection in the ICU. The SWIN transformer Base variant achieved 0.88 F1-score and 0.85 accuracy on the held-out test partition of the Pain-ICU dataset.