 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Do predictability factors towards signing avatars hold across cultures?
Jul 05, 2023
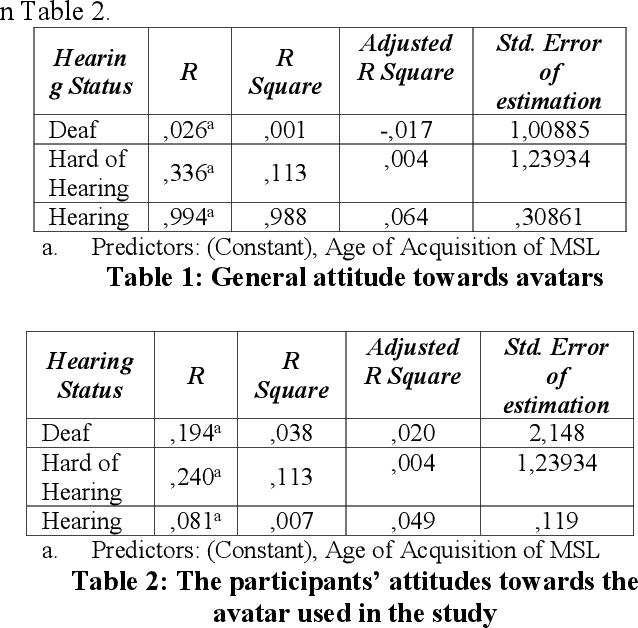
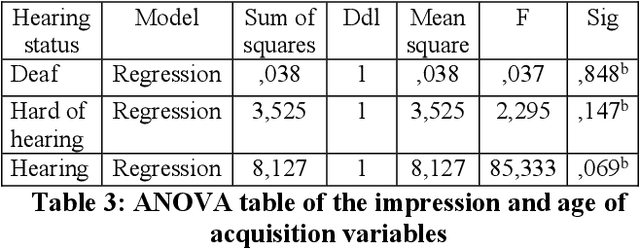
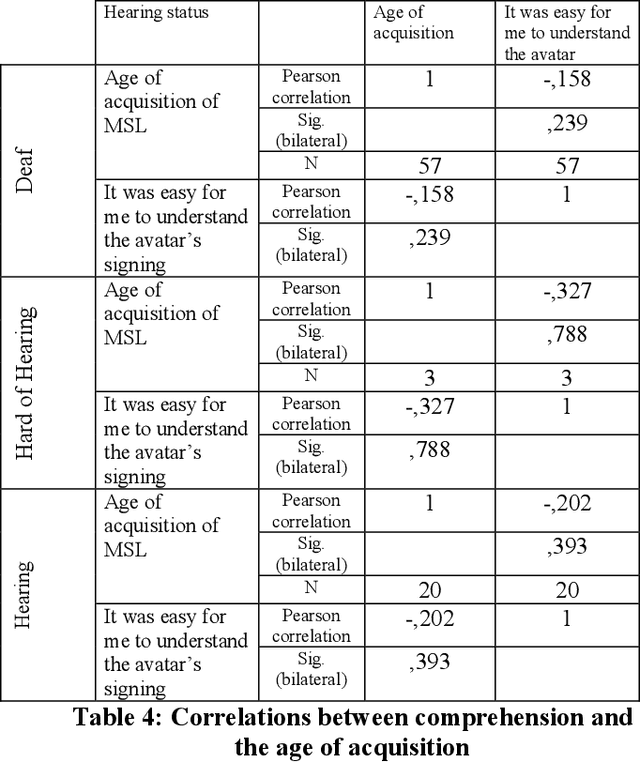
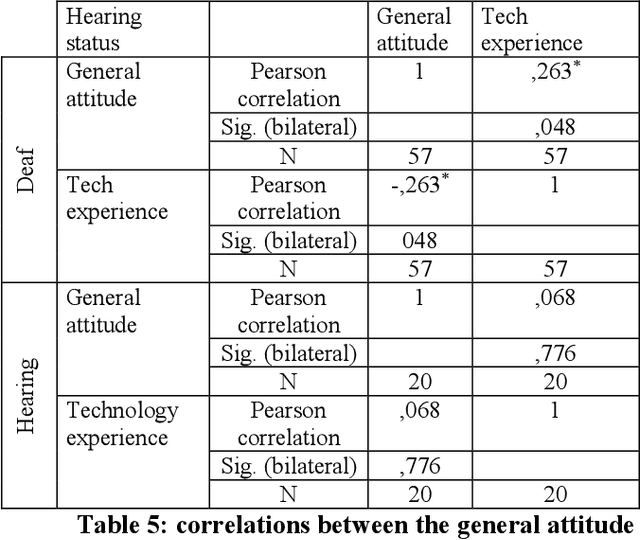
Avatar technology can offer accessibility possibilities and improve the Deaf-and-Hard of Hearing sign language users access to communication, education and services, such as the healthcare system. However, sign language users acceptance of signing avatars as well as their attitudes towards them vary and depend on many factors. Furthermore, research on avatar technology is mostly done by researchers who are not Deaf. The study examines the extent to which intrinsic or extrinsic factors contribute to predict the attitude towards avatars across cultures. Intrinsic factors include the characteristics of the avatar, such as appearance, movements and facial expressions. Extrinsic factors include users technology experience, their hearing status, age and their sign language fluency. This work attempts to answer questions such as, if lower attitude ratings are related to poor technology experience with ASL users, for example, is that also true for Moroccan Sign Language (MSL) users? For the purposes of the study, we designed a questionnaire to understand MSL users attitude towards avatars. Three groups of participants were surveyed: Deaf (57), Hearing (20) and Hard-of-Hearing (3). The results of our study were then compared with those reported in other relevant studies.
* 5 pages, Proceedings of the ICASSP 2023 8th Workshop on Sign Language Translation and Avatar Technology, Rhodes Island, Greece, June 10, 2023
MiVOLO: Multi-input Transformer for Age and Gender Estimation
Jul 10, 2023
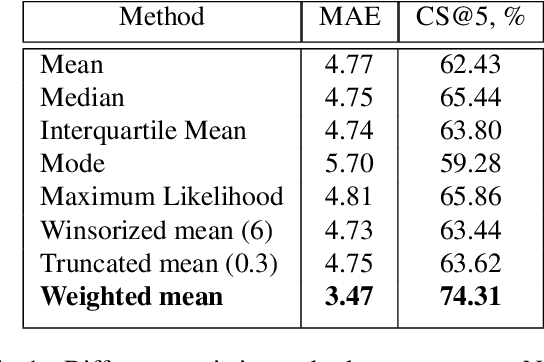
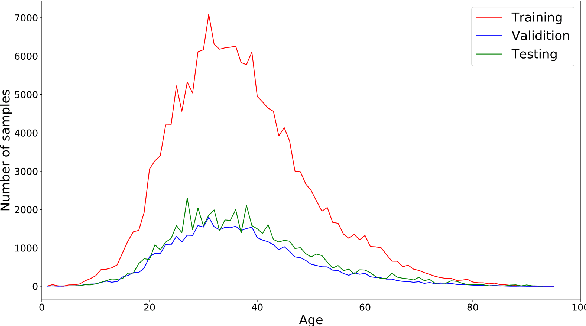
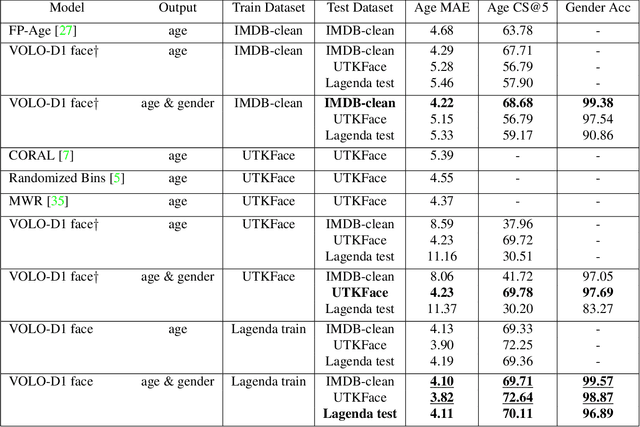
Age and gender recognition in the wild is a highly challenging task: apart from the variability of conditions, pose complexities, and varying image quality, there are cases where the face is partially or completely occluded. We present MiVOLO (Multi Input VOLO), a straightforward approach for age and gender estimation using the latest vision transformer. Our method integrates both tasks into a unified dual input/output model, leveraging not only facial information but also person image data. This improves the generalization ability of our model and enables it to deliver satisfactory results even when the face is not visible in the image. To evaluate our proposed model, we conduct experiments on four popular benchmarks and achieve state-of-the-art performance, while demonstrating real-time processing capabilities. Additionally, we introduce a novel benchmark based on images from the Open Images Dataset. The ground truth annotations for this benchmark have been meticulously generated by human annotators, resulting in high accuracy answers due to the smart aggregation of votes. Furthermore, we compare our model's age recognition performance with human-level accuracy and demonstrate that it significantly outperforms humans across a majority of age ranges. Finally, we grant public access to our models, along with the code for validation and inference. In addition, we provide extra annotations for used datasets and introduce our new benchmark.
Articulated 3D Head Avatar Generation using Text-to-Image Diffusion Models
Jul 10, 2023
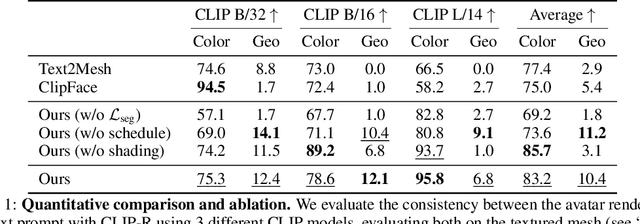

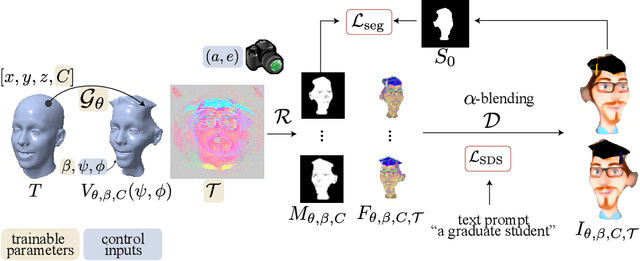
The ability to generate diverse 3D articulated head avatars is vital to a plethora of applications, including augmented reality, cinematography, and education. Recent work on text-guided 3D object generation has shown great promise in addressing these needs. These methods directly leverage pre-trained 2D text-to-image diffusion models to generate 3D-multi-view-consistent radiance fields of generic objects. However, due to the lack of geometry and texture priors, these methods have limited control over the generated 3D objects, making it difficult to operate inside a specific domain, e.g., human heads. In this work, we develop a new approach to text-guided 3D head avatar generation to address this limitation. Our framework directly operates on the geometry and texture of an articulable 3D morphable model (3DMM) of a head, and introduces novel optimization procedures to update the geometry and texture while keeping the 2D and 3D facial features aligned. The result is a 3D head avatar that is consistent with the text description and can be readily articulated using the deformation model of the 3DMM. We show that our diffusion-based articulated head avatars outperform state-of-the-art approaches for this task. The latter are typically based on CLIP, which is known to provide limited diversity of generation and accuracy for 3D object generation.
Reconstructing Personalized Semantic Facial NeRF Models From Monocular Video
Oct 12, 2022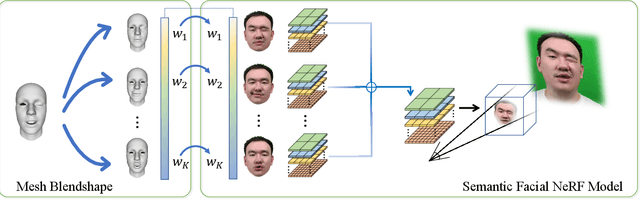

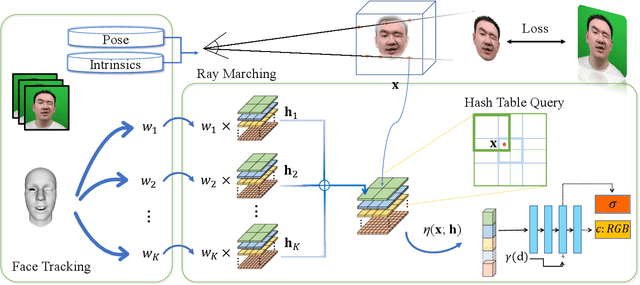
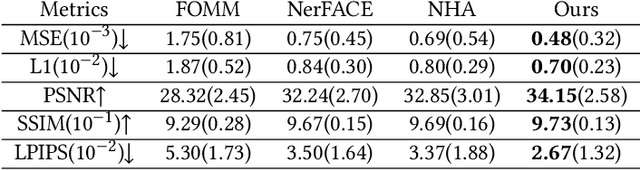
We present a novel semantic model for human head defined with neural radiance field. The 3D-consistent head model consist of a set of disentangled and interpretable bases, and can be driven by low-dimensional expression coefficients. Thanks to the powerful representation ability of neural radiance field, the constructed model can represent complex facial attributes including hair, wearings, which can not be represented by traditional mesh blendshape. To construct the personalized semantic facial model, we propose to define the bases as several multi-level voxel fields. With a short monocular RGB video as input, our method can construct the subject's semantic facial NeRF model with only ten to twenty minutes, and can render a photo-realistic human head image in tens of miliseconds with a given expression coefficient and view direction. With this novel representation, we apply it to many tasks like facial retargeting and expression editing. Experimental results demonstrate its strong representation ability and training/inference speed. Demo videos and released code are provided in our project page: https://ustc3dv.github.io/NeRFBlendShape/
* Accepted by SIGGRAPH Asia 2022 (Journal Track). Project page: https://ustc3dv.github.io/NeRFBlendShape/
ASD: Towards Attribute Spatial Decomposition for Prior-Free Facial Attribute Recognition
Oct 25, 2022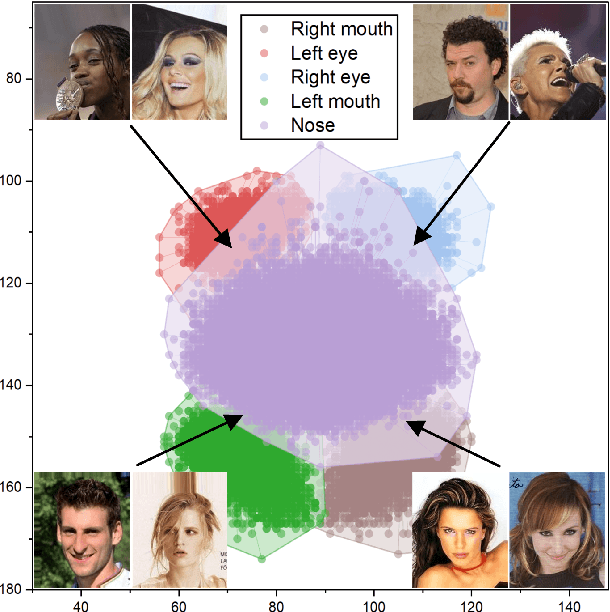
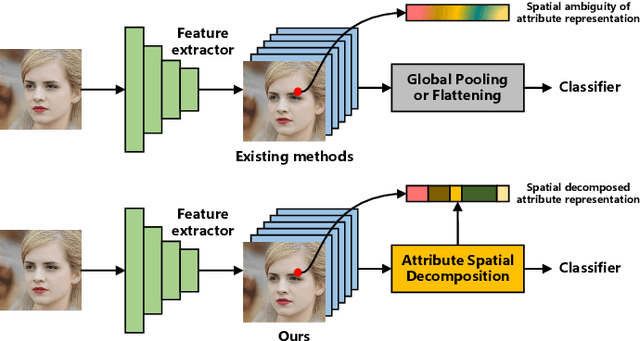
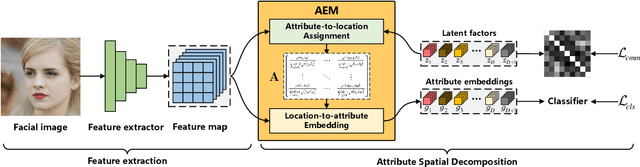
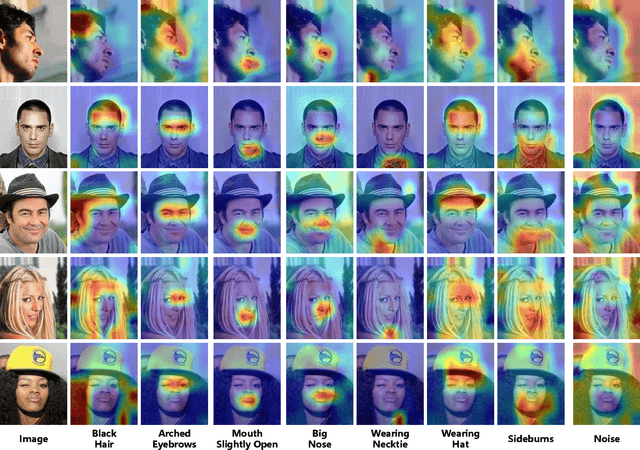
Representing the spatial properties of facial attributes is a vital challenge for facial attribute recognition (FAR). Recent advances have achieved the reliable performances for FAR, benefiting from the description of spatial properties via extra prior information. However, the extra prior information might not be always available, resulting in the restricted application scenario of the prior-based methods. Meanwhile, the spatial ambiguity of facial attributes caused by inherent spatial diversities of facial parts is ignored. To address these issues, we propose a prior-free method for attribute spatial decomposition (ASD), mitigating the spatial ambiguity of facial attributes without any extra prior information. Specifically, assignment-embedding module (AEM) is proposed to enable the procedure of ASD, which consists of two operations: attribute-to-location assignment and location-to-attribute embedding. The attribute-to-location assignment first decomposes the feature map based on latent factors, assigning the magnitude of attribute components on each spatial location. Then, the assigned attribute components from all locations to represent the global-level attribute embeddings. Furthermore, correlation matrix minimization (CMM) is introduced to enlarge the discriminability of attribute embeddings. Experimental results demonstrate the superiority of ASD compared with state-of-the-art prior-based methods, while the reliable performance of ASD for the case of limited training data is further validated.
Visual-Aware Text-to-Speech
Jun 21, 2023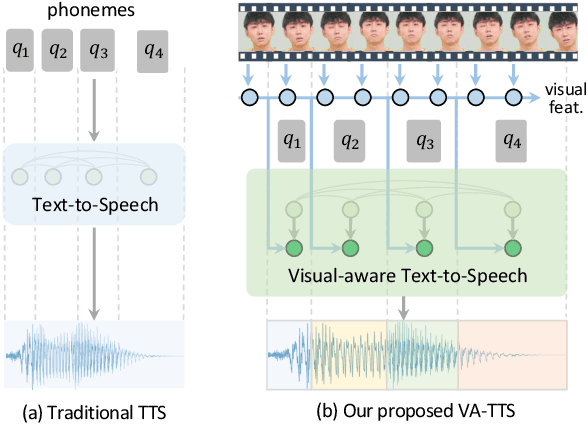
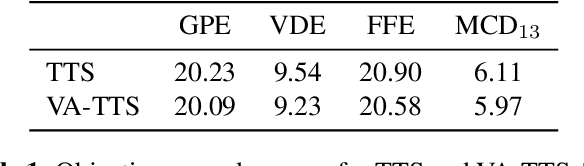
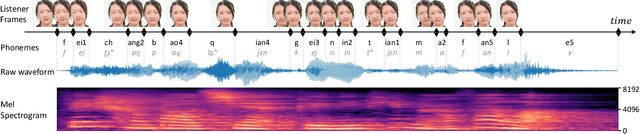
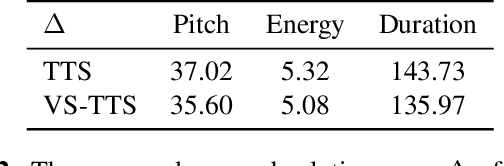
Dynamically synthesizing talking speech that actively responds to a listening head is critical during the face-to-face interaction. For example, the speaker could take advantage of the listener's facial expression to adjust the tones, stressed syllables, or pauses. In this work, we present a new visual-aware text-to-speech (VA-TTS) task to synthesize speech conditioned on both textual inputs and sequential visual feedback (e.g., nod, smile) of the listener in face-to-face communication. Different from traditional text-to-speech, VA-TTS highlights the impact of visual modality. On this newly-minted task, we devise a baseline model to fuse phoneme linguistic information and listener visual signals for speech synthesis. Extensive experiments on multimodal conversation dataset ViCo-X verify our proposal for generating more natural audio with scenario-appropriate rhythm and prosody.
* accepted as oral and top 3% paper by ICASSP 2023
RidgeBase: A Cross-Sensor Multi-Finger Contactless Fingerprint Dataset
Jul 09, 2023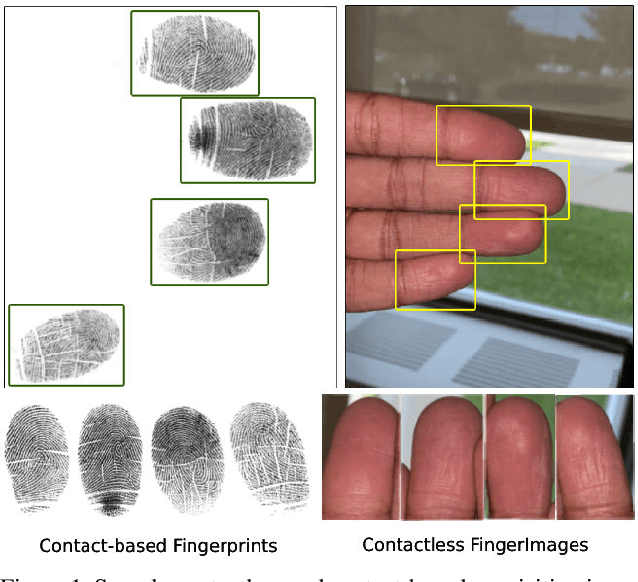


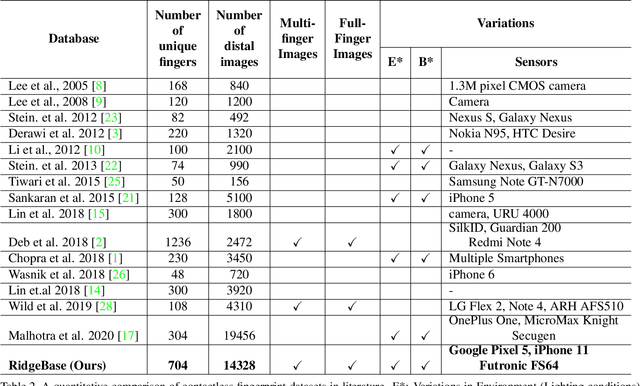
Contactless fingerprint matching using smartphone cameras can alleviate major challenges of traditional fingerprint systems including hygienic acquisition, portability and presentation attacks. However, development of practical and robust contactless fingerprint matching techniques is constrained by the limited availability of large scale real-world datasets. To motivate further advances in contactless fingerprint matching across sensors, we introduce the RidgeBase benchmark dataset. RidgeBase consists of more than 15,000 contactless and contact-based fingerprint image pairs acquired from 88 individuals under different background and lighting conditions using two smartphone cameras and one flatbed contact sensor. Unlike existing datasets, RidgeBase is designed to promote research under different matching scenarios that include Single Finger Matching and Multi-Finger Matching for both contactless- to-contactless (CL2CL) and contact-to-contactless (C2CL) verification and identification. Furthermore, due to the high intra-sample variance in contactless fingerprints belonging to the same finger, we propose a set-based matching protocol inspired by the advances in facial recognition datasets. This protocol is specifically designed for pragmatic contactless fingerprint matching that can account for variances in focus, polarity and finger-angles. We report qualitative and quantitative baseline results for different protocols using a COTS fingerprint matcher (Verifinger) and a Deep CNN based approach on the RidgeBase dataset. The dataset can be downloaded here: https://www.buffalo.edu/cubs/research/datasets/ridgebase-benchmark-dataset.html
* Paper accepted at IJCB 2022
Motion-X: A Large-scale 3D Expressive Whole-body Human Motion Dataset
Jul 03, 2023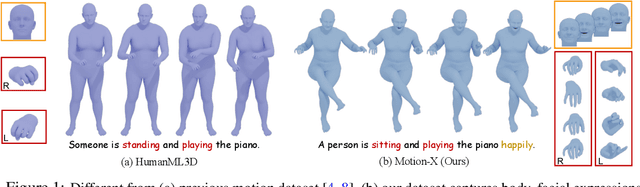
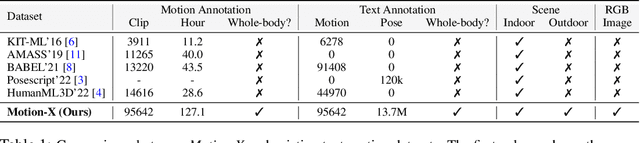
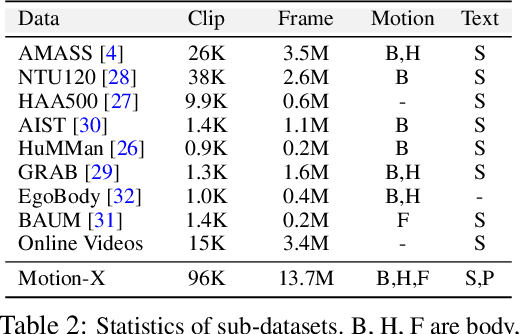
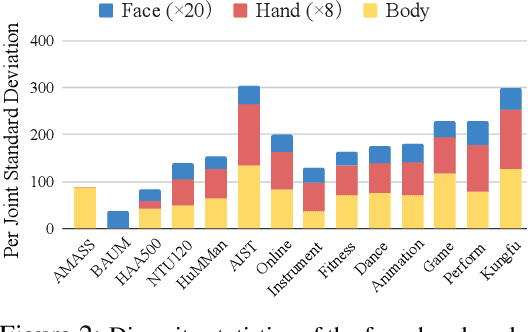
In this paper, we present Motion-X, a large-scale 3D expressive whole-body motion dataset. Existing motion datasets predominantly contain body-only poses, lacking facial expressions, hand gestures, and fine-grained pose descriptions. Moreover, they are primarily collected from limited laboratory scenes with textual descriptions manually labeled, which greatly limits their scalability. To overcome these limitations, we develop a whole-body motion and text annotation pipeline, which can automatically annotate motion from either single- or multi-view videos and provide comprehensive semantic labels for each video and fine-grained whole-body pose descriptions for each frame. This pipeline is of high precision, cost-effective, and scalable for further research. Based on it, we construct Motion-X, which comprises 13.7M precise 3D whole-body pose annotations (i.e., SMPL-X) covering 96K motion sequences from massive scenes. Besides, Motion-X provides 13.7M frame-level whole-body pose descriptions and 96K sequence-level semantic labels. Comprehensive experiments demonstrate the accuracy of the annotation pipeline and the significant benefit of Motion-X in enhancing expressive, diverse, and natural motion generation, as well as 3D whole-body human mesh recovery.
On Developing Facial Stress Analysis and Expression Recognition Platform
Sep 16, 2022

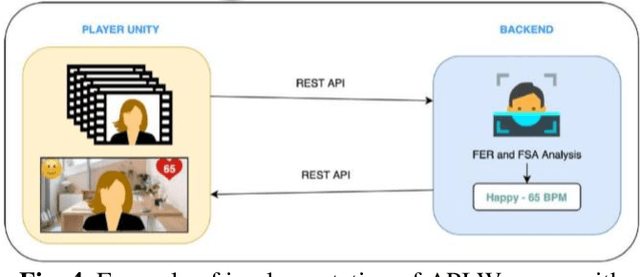
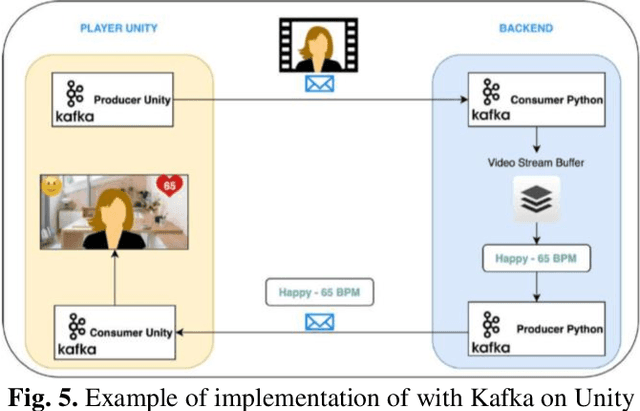
This work represents the experimental and development process of system facial expression recognition and facial stress analysis algorithms for an immersive digital learning platform. The system retrieves from users web camera and evaluates it using artificial neural network (ANN) algorithms. The ANN output signals can be used to score and improve the learning process. Adapting an ANN to a new system can require a significant implementation effort or the need to repeat the ANN training. There are also limitations related to the minimum hardware required to run an ANN. To overpass these constraints, some possible implementations of facial expression recognition and facial stress analysis algorithms in real-time systems are presented. The implementation of the new solution has made it possible to improve the accuracy in the recognition of facial expressions and also to increase their response speed. Experimental results showed that using the developed algorithms allow to detect the heart rate with better rate in comparison with social equipment.
Inserting Anybody in Diffusion Models via Celeb Basis
Jun 01, 2023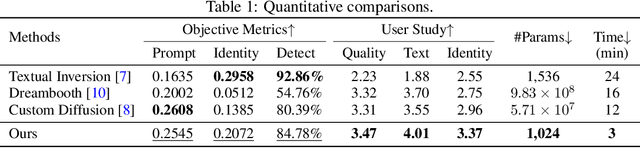
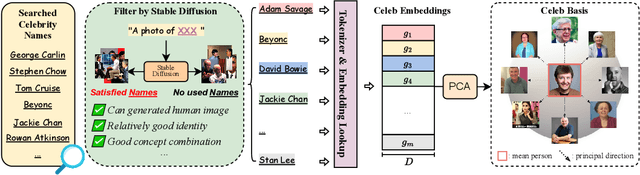
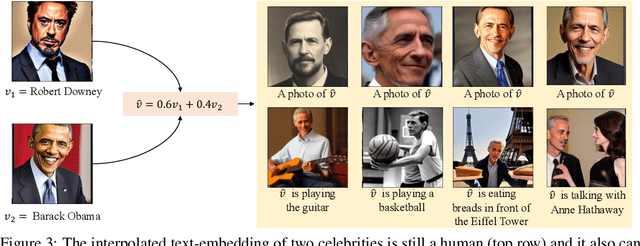
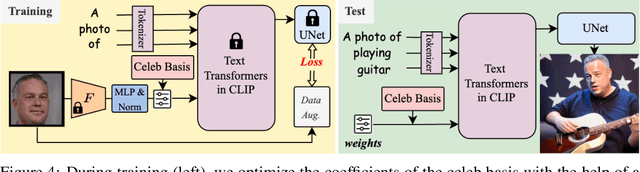
Exquisite demand exists for customizing the pretrained large text-to-image model, $\textit{e.g.}$, Stable Diffusion, to generate innovative concepts, such as the users themselves. However, the newly-added concept from previous customization methods often shows weaker combination abilities than the original ones even given several images during training. We thus propose a new personalization method that allows for the seamless integration of a unique individual into the pre-trained diffusion model using just $\textbf{one facial photograph}$ and only $\textbf{1024 learnable parameters}$ under $\textbf{3 minutes}$. So as we can effortlessly generate stunning images of this person in any pose or position, interacting with anyone and doing anything imaginable from text prompts. To achieve this, we first analyze and build a well-defined celeb basis from the embedding space of the pre-trained large text encoder. Then, given one facial photo as the target identity, we generate its own embedding by optimizing the weight of this basis and locking all other parameters. Empowered by the proposed celeb basis, the new identity in our customized model showcases a better concept combination ability than previous personalization methods. Besides, our model can also learn several new identities at once and interact with each other where the previous customization model fails to. The code will be released.