 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Facial Affect Recognition based on Transformer Encoder and Audiovisual Fusion for the ABAW5 Challenge
Mar 20, 2023
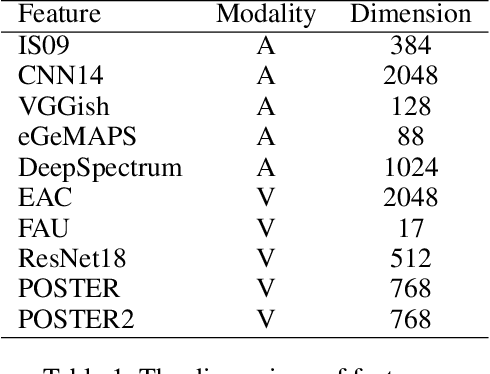
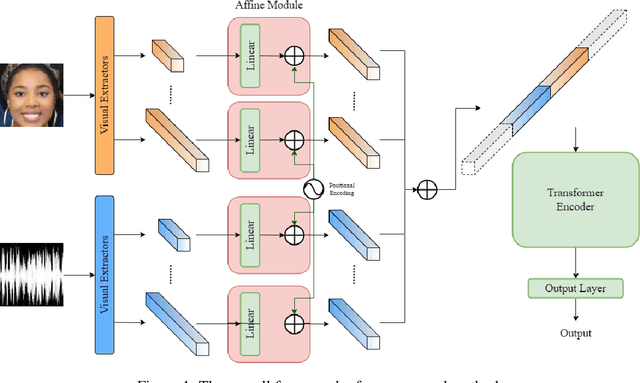
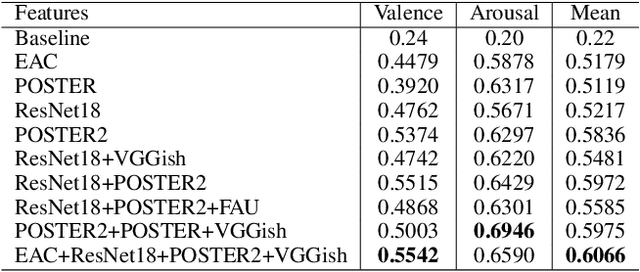
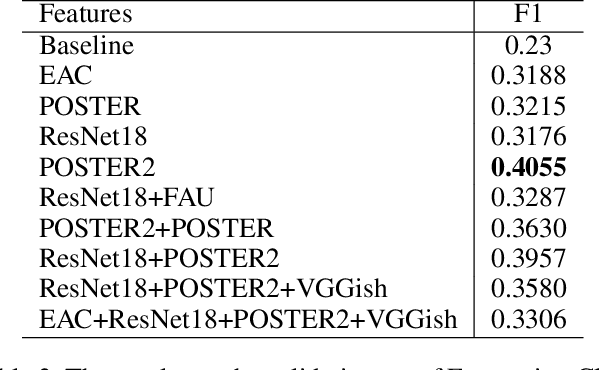
In this paper, we present our solutions for the 5th Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW), which includes four sub-challenges of Valence-Arousal (VA) Estimation, Expression (Expr) Classification, Action Unit (AU) Detection and Emotional Reaction Intensity (ERI) Estimation. The 5th ABAW competition focuses on facial affect recognition utilizing different modalities and datasets. In our work, we extract powerful audio and visual features using a large number of sota models. These features are fused by Transformer Encoder and TEMMA. Besides, to avoid the possible impact of large dimensional differences between various features, we design an Affine Module to align different features to the same dimension. Extensive experiments demonstrate that the superiority of the proposed method. For the VA Estimation sub-challenge, our method obtains the mean Concordance Correlation Coefficient (CCC) of 0.6066. For the Expression Classification sub-challenge, the average F1 Score is 0.4055. For the AU Detection sub-challenge, the average F1 Score is 0.5296. For the Emotional Reaction Intensity Estimation sub-challenge, the average pearson's correlations coefficient on the validation set is 0.3968. All of the results of four sub-challenges outperform the baseline with a large margin.
QuAVF: Quality-aware Audio-Visual Fusion for Ego4D Talking to Me Challenge
Jun 30, 2023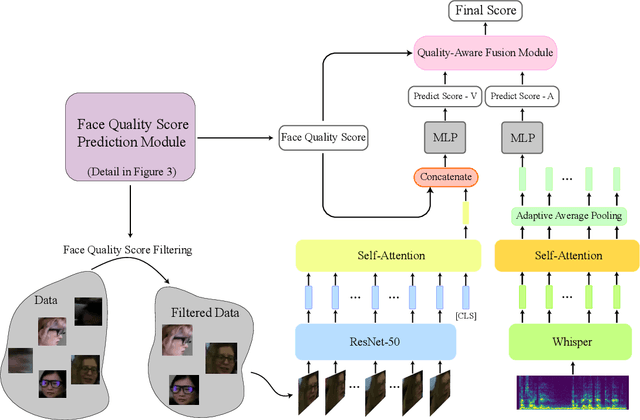
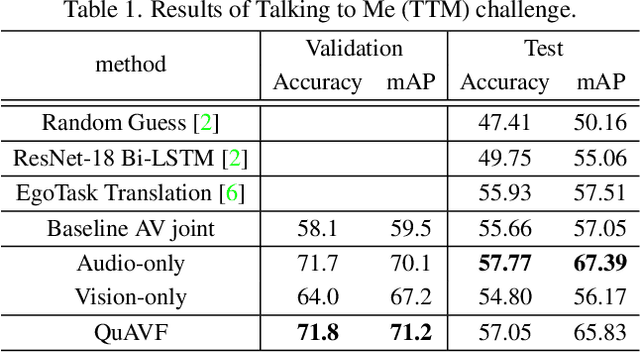
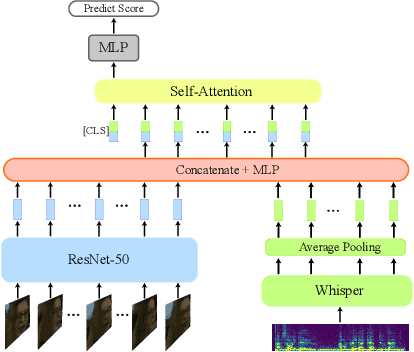

This technical report describes our QuAVF@NTU-NVIDIA submission to the Ego4D Talking to Me (TTM) Challenge 2023. Based on the observation from the TTM task and the provided dataset, we propose to use two separate models to process the input videos and audio. By doing so, we can utilize all the labeled training data, including those without bounding box labels. Furthermore, we leverage the face quality score from a facial landmark prediction model for filtering noisy face input data. The face quality score is also employed in our proposed quality-aware fusion for integrating the results from two branches. With the simple architecture design, our model achieves 67.4% mean average precision (mAP) on the test set, which ranks first on the leaderboard and outperforms the baseline method by a large margin. Code is available at: https://github.com/hsi-che-lin/Ego4D-QuAVF-TTM-CVPR23
EVM-CNN: Real-Time Contactless Heart Rate Estimation from Facial Video
Dec 25, 2022
With the increase in health consciousness, noninvasive body monitoring has aroused interest among researchers. As one of the most important pieces of physiological information, researchers have remotely estimated the heart rate (HR) from facial videos in recent years. Although progress has been made over the past few years, there are still some limitations, like the processing time increasing with accuracy and the lack of comprehensive and challenging datasets for use and comparison. Recently, it was shown that HR information can be extracted from facial videos by spatial decomposition and temporal filtering. Inspired by this, a new framework is introduced in this paper to remotely estimate the HR under realistic conditions by combining spatial and temporal filtering and a convolutional neural network. Our proposed approach shows better performance compared with the benchmark on the MMSE-HR dataset in terms of both the average HR estimation and short-time HR estimation. High consistency in short-time HR estimation is observed between our method and the ground truth.
ViTASD: Robust Vision Transformer Baselines for Autism Spectrum Disorder Facial Diagnosis
Oct 30, 2022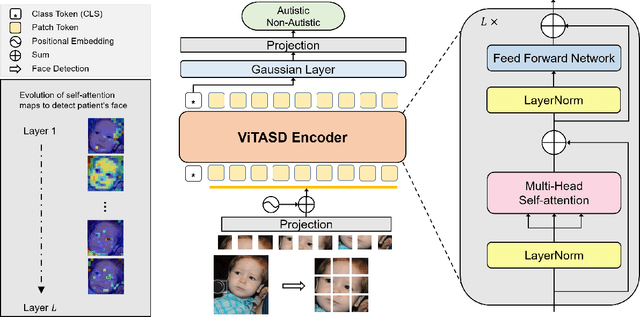
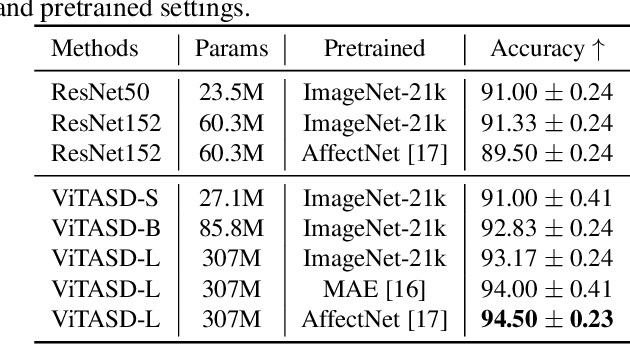
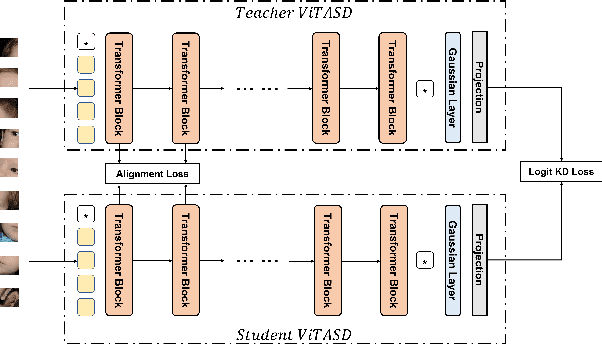

Autism spectrum disorder (ASD) is a lifelong neurodevelopmental disorder with very high prevalence around the world. Research progress in the field of ASD facial analysis in pediatric patients has been hindered due to a lack of well-established baselines. In this paper, we propose the use of the Vision Transformer (ViT) for the computational analysis of pediatric ASD. The presented model, known as ViTASD, distills knowledge from large facial expression datasets and offers model structure transferability. Specifically, ViTASD employs a vanilla ViT to extract features from patients' face images and adopts a lightweight decoder with a Gaussian Process layer to enhance the robustness for ASD analysis. Extensive experiments conducted on standard ASD facial analysis benchmarks show that our method outperforms all of the representative approaches in ASD facial analysis, while the ViTASD-L achieves a new state-of-the-art. Our code and pretrained models are available at https://github.com/IrohXu/ViTASD.
Explainable Human-centered Traits from Head Motion and Facial Expression Dynamics
Feb 20, 2023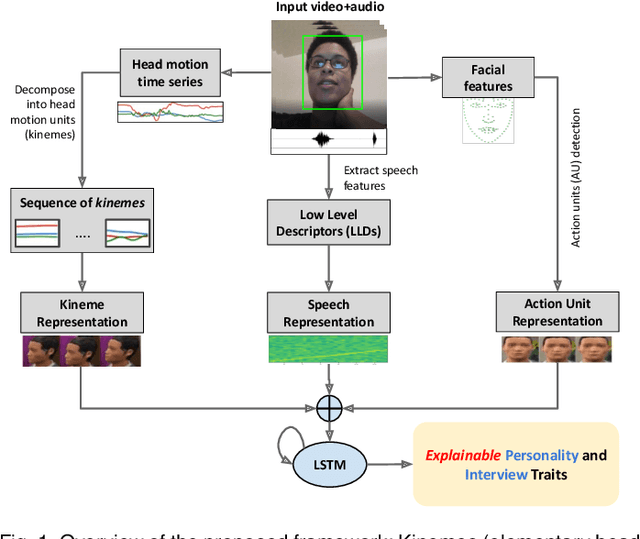
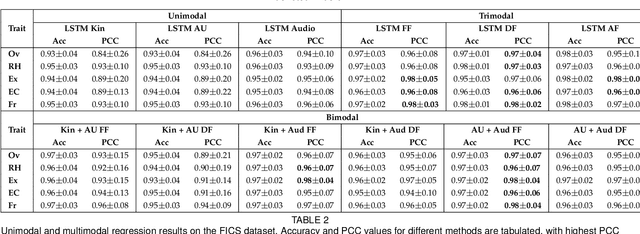
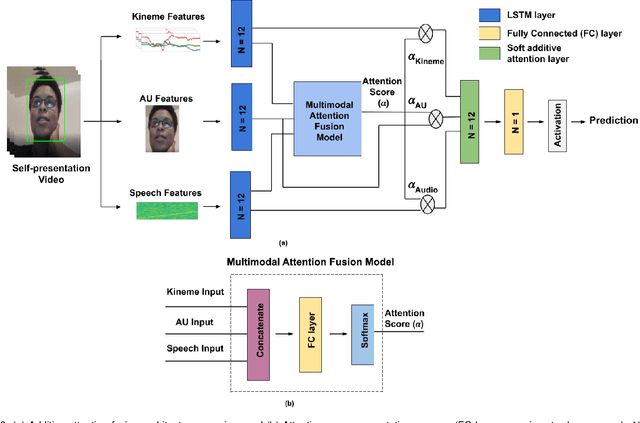
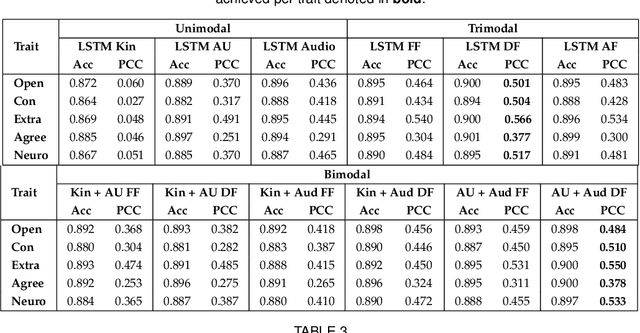
We explore the efficacy of multimodal behavioral cues for explainable prediction of personality and interview-specific traits. We utilize elementary head-motion units named kinemes, atomic facial movements termed action units and speech features to estimate these human-centered traits. Empirical results confirm that kinemes and action units enable discovery of multiple trait-specific behaviors while also enabling explainability in support of the predictions. For fusing cues, we explore decision and feature-level fusion, and an additive attention-based fusion strategy which quantifies the relative importance of the three modalities for trait prediction. Examining various long-short term memory (LSTM) architectures for classification and regression on the MIT Interview and First Impressions Candidate Screening (FICS) datasets, we note that: (1) Multimodal approaches outperform unimodal counterparts; (2) Efficient trait predictions and plausible explanations are achieved with both unimodal and multimodal approaches, and (3) Following the thin-slice approach, effective trait prediction is achieved even from two-second behavioral snippets.
Automatic 3D Registration of Dental CBCT and Face Scan Data using 2D Projection images
May 17, 2023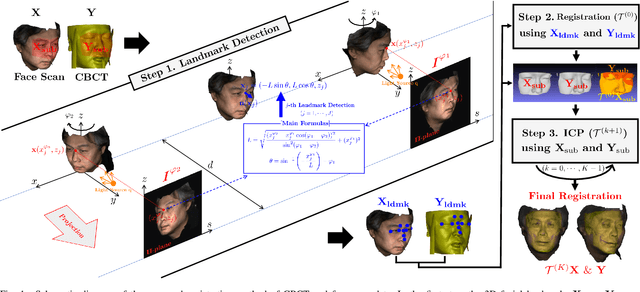
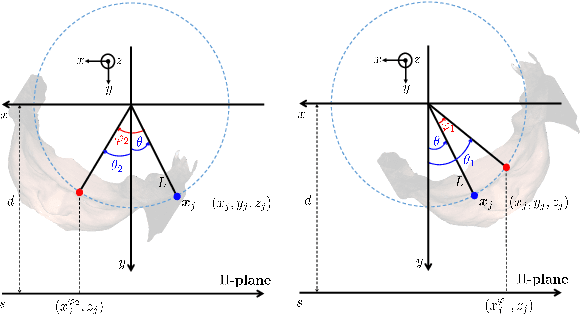
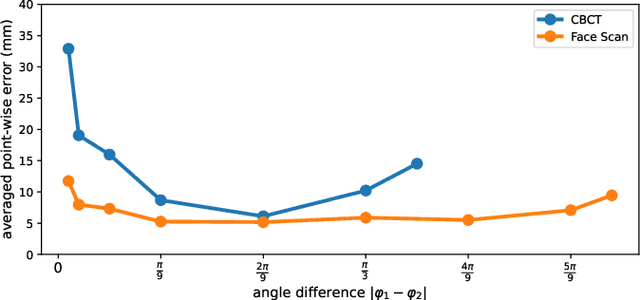

This paper presents a fully automatic registration method of dental cone-beam computed tomography (CBCT) and face scan data. It can be used for a digital platform of 3D jaw-teeth-face models in a variety of applications, including 3D digital treatment planning and orthognathic surgery. Difficulties in accurately merging facial scans and CBCT images are due to the different image acquisition methods and limited area of correspondence between the two facial surfaces. In addition, it is difficult to use machine learning techniques because they use face-related 3D medical data with radiation exposure, which are difficult to obtain for training. The proposed method addresses these problems by reusing an existing machine-learning-based 2D landmark detection algorithm in an open-source library and developing a novel mathematical algorithm that identifies paired 3D landmarks from knowledge of the corresponding 2D landmarks. A main contribution of this study is that the proposed method does not require annotated training data of facial landmarks because it uses a pre-trained facial landmark detection algorithm that is known to be robust and generalized to various 2D face image models. Note that this reduces a 3D landmark detection problem to a 2D problem of identifying the corresponding landmarks on two 2D projection images generated from two different projection angles. Here, the 3D landmarks for registration were selected from the sub-surfaces with the least geometric change under the CBCT and face scan environments. For the final fine-tuning of the registration, the Iterative Closest Point method was applied, which utilizes geometrical information around the 3D landmarks. The experimental results show that the proposed method achieved an averaged surface distance error of 0.74 mm for three pairs of CBCT and face scan datasets.
EmoSet: A Large-scale Visual Emotion Dataset with Rich Attributes
Jul 16, 2023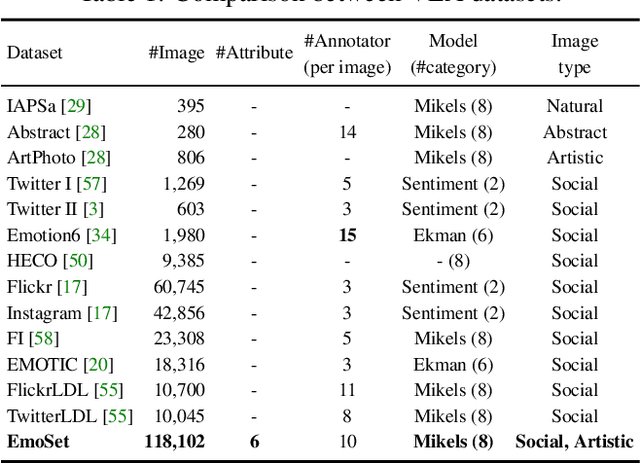
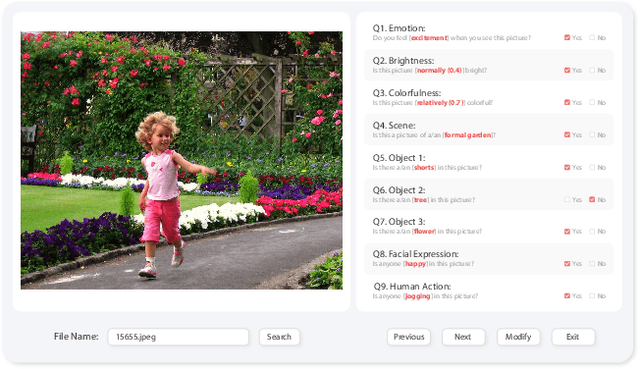
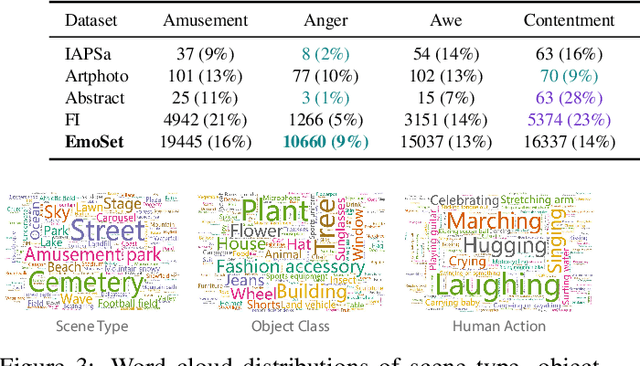
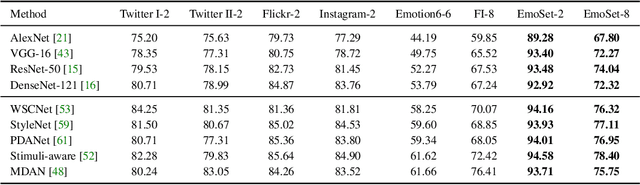
Visual Emotion Analysis (VEA) aims at predicting people's emotional responses to visual stimuli. This is a promising, yet challenging, task in affective computing, which has drawn increasing attention in recent years. Most of the existing work in this area focuses on feature design, while little attention has been paid to dataset construction. In this work, we introduce EmoSet, the first large-scale visual emotion dataset annotated with rich attributes, which is superior to existing datasets in four aspects: scale, annotation richness, diversity, and data balance. EmoSet comprises 3.3 million images in total, with 118,102 of these images carefully labeled by human annotators, making it five times larger than the largest existing dataset. EmoSet includes images from social networks, as well as artistic images, and it is well balanced between different emotion categories. Motivated by psychological studies, in addition to emotion category, each image is also annotated with a set of describable emotion attributes: brightness, colorfulness, scene type, object class, facial expression, and human action, which can help understand visual emotions in a precise and interpretable way. The relevance of these emotion attributes is validated by analyzing the correlations between them and visual emotion, as well as by designing an attribute module to help visual emotion recognition. We believe EmoSet will bring some key insights and encourage further research in visual emotion analysis and understanding. The data and code will be released after the publication of this work.
AvatarFusion: Zero-shot Generation of Clothing-Decoupled 3D Avatars Using 2D Diffusion
Jul 13, 2023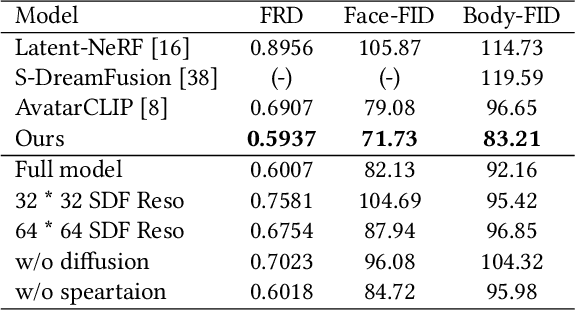
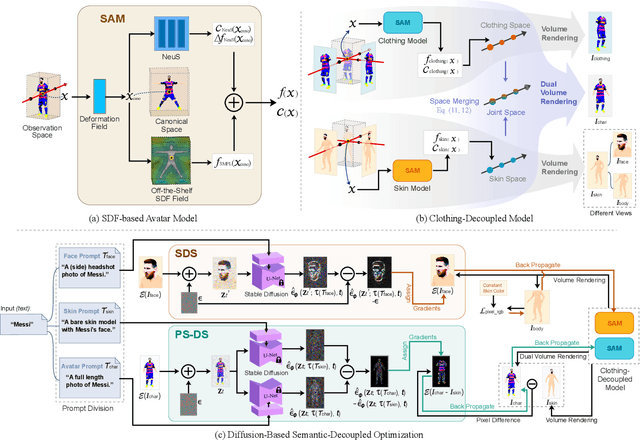


Large-scale pre-trained vision-language models allow for the zero-shot text-based generation of 3D avatars. The previous state-of-the-art method utilized CLIP to supervise neural implicit models that reconstructed a human body mesh. However, this approach has two limitations. Firstly, the lack of avatar-specific models can cause facial distortion and unrealistic clothing in the generated avatars. Secondly, CLIP only provides optimization direction for the overall appearance, resulting in less impressive results. To address these limitations, we propose AvatarFusion, the first framework to use a latent diffusion model to provide pixel-level guidance for generating human-realistic avatars while simultaneously segmenting clothing from the avatar's body. AvatarFusion includes the first clothing-decoupled neural implicit avatar model that employs a novel Dual Volume Rendering strategy to render the decoupled skin and clothing sub-models in one space. We also introduce a novel optimization method, called Pixel-Semantics Difference-Sampling (PS-DS), which semantically separates the generation of body and clothes, and generates a variety of clothing styles. Moreover, we establish the first benchmark for zero-shot text-to-avatar generation. Our experimental results demonstrate that our framework outperforms previous approaches, with significant improvements observed in all metrics. Additionally, since our model is clothing-decoupled, we can exchange the clothes of avatars. Code will be available on Github.
A Comprehensive Multi-scale Approach for Speech and Dynamics Synchrony in Talking Head Generation
Jul 04, 2023
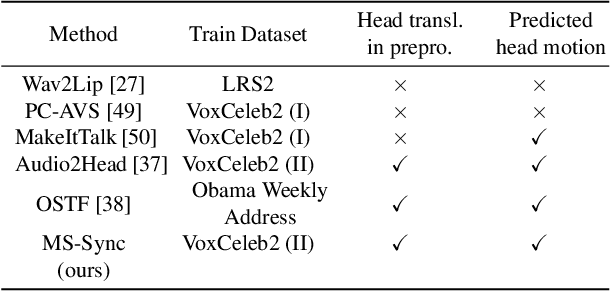
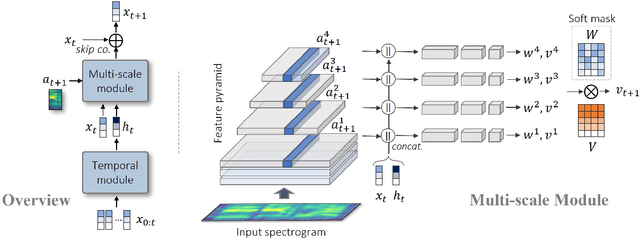
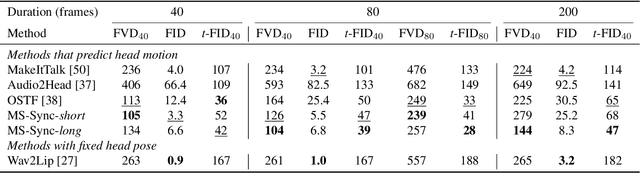
Animating still face images with deep generative models using a speech input signal is an active research topic and has seen important recent progress. However, much of the effort has been put into lip syncing and rendering quality while the generation of natural head motion, let alone the audio-visual correlation between head motion and speech, has often been neglected. In this work, we propose a multi-scale audio-visual synchrony loss and a multi-scale autoregressive GAN to better handle short and long-term correlation between speech and the dynamics of the head and lips. In particular, we train a stack of syncer models on multimodal input pyramids and use these models as guidance in a multi-scale generator network to produce audio-aligned motion unfolding over diverse time scales. Our generator operates in the facial landmark domain, which is a standard low-dimensional head representation. The experiments show significant improvements over the state of the art in head motion dynamics quality and in multi-scale audio-visual synchrony both in the landmark domain and in the image domain.
Reconstructing Personalized Semantic Facial NeRF Models From Monocular Video
Oct 12, 2022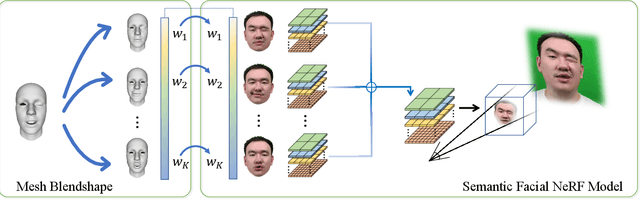

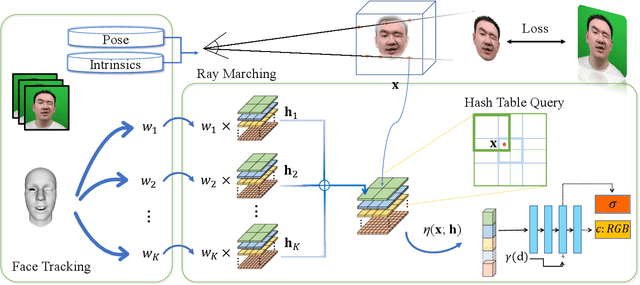
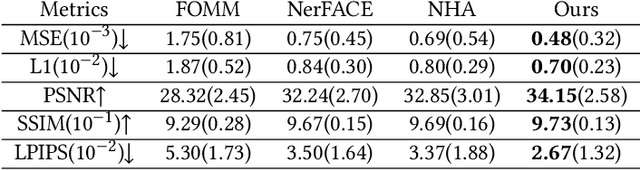
We present a novel semantic model for human head defined with neural radiance field. The 3D-consistent head model consist of a set of disentangled and interpretable bases, and can be driven by low-dimensional expression coefficients. Thanks to the powerful representation ability of neural radiance field, the constructed model can represent complex facial attributes including hair, wearings, which can not be represented by traditional mesh blendshape. To construct the personalized semantic facial model, we propose to define the bases as several multi-level voxel fields. With a short monocular RGB video as input, our method can construct the subject's semantic facial NeRF model with only ten to twenty minutes, and can render a photo-realistic human head image in tens of miliseconds with a given expression coefficient and view direction. With this novel representation, we apply it to many tasks like facial retargeting and expression editing. Experimental results demonstrate its strong representation ability and training/inference speed. Demo videos and released code are provided in our project page: https://ustc3dv.github.io/NeRFBlendShape/
* Accepted by SIGGRAPH Asia 2022 (Journal Track). Project page: https://ustc3dv.github.io/NeRFBlendShape/