 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
FlowFace++: Explicit Semantic Flow-supervised End-to-End Face Swapping
Jun 26, 2023



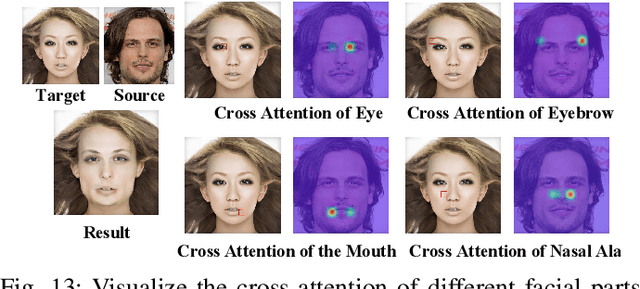
This work proposes a novel face-swapping framework FlowFace++, utilizing explicit semantic flow supervision and end-to-end architecture to facilitate shape-aware face-swapping. Specifically, our work pretrains a facial shape discriminator to supervise the face swapping network. The discriminator is shape-aware and relies on a semantic flow-guided operation to explicitly calculate the shape discrepancies between the target and source faces, thus optimizing the face swapping network to generate highly realistic results. The face swapping network is a stack of a pre-trained face-masked autoencoder (MAE), a cross-attention fusion module, and a convolutional decoder. The MAE provides a fine-grained facial image representation space, which is unified for the target and source faces and thus facilitates final realistic results. The cross-attention fusion module carries out the source-to-target face swapping in a fine-grained latent space while preserving other attributes of the target image (e.g. expression, head pose, hair, background, illumination, etc). Lastly, the convolutional decoder further synthesizes the swapping results according to the face-swapping latent embedding from the cross-attention fusion module. Extensive quantitative and qualitative experiments on in-the-wild faces demonstrate that our FlowFace++ outperforms the state-of-the-art significantly, particularly while the source face is obstructed by uneven lighting or angle offset.
INCLG: Inpainting for Non-Cleft Lip Generation with a Multi-Task Image Processing Network
May 17, 2023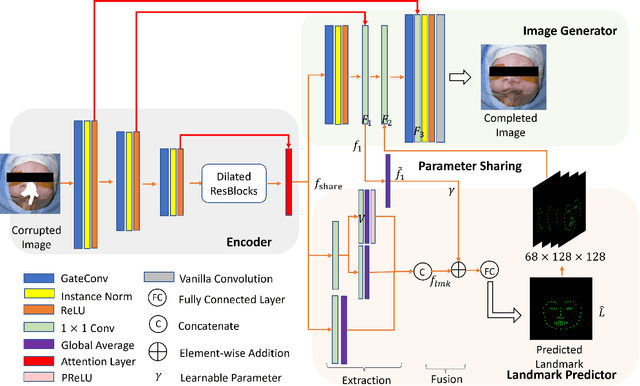
We present a software that predicts non-cleft facial images for patients with cleft lip, thereby facilitating the understanding, awareness and discussion of cleft lip surgeries. To protect patients privacy, we design a software framework using image inpainting, which does not require cleft lip images for training, thereby mitigating the risk of model leakage. We implement a novel multi-task architecture that predicts both the non-cleft facial image and facial landmarks, resulting in better performance as evaluated by surgeons. The software is implemented with PyTorch and is usable with consumer-level color images with a fast prediction speed, enabling effective deployment.
Generating Efficient Training Data via LLM-based Attribute Manipulation
Jul 14, 2023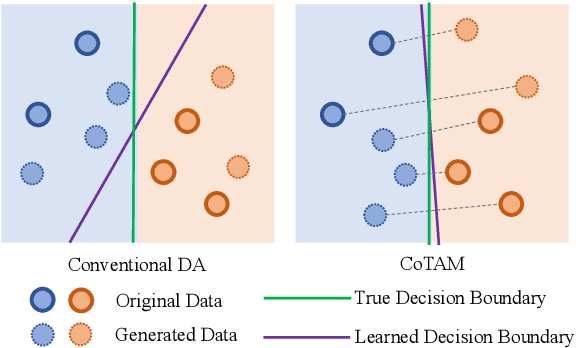
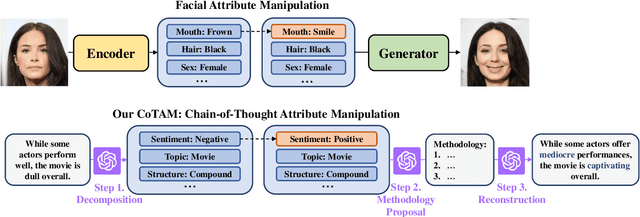
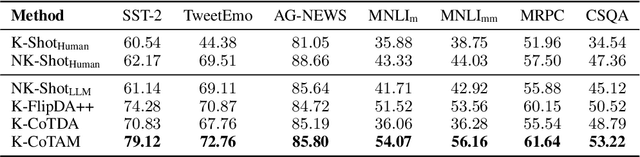
In this paper, we propose a novel method, Chain-of-Thoughts Attribute Manipulation (CoTAM), to guide few-shot learning by carefully crafted data from Large Language Models (LLMs). The main idea is to create data with changes only in the attribute targeted by the task. Inspired by facial attribute manipulation, our approach generates label-switched data by leveraging LLMs to manipulate task-specific attributes and reconstruct new sentences in a controlled manner. Instead of conventional latent representation controlling, we implement chain-of-thoughts decomposition and reconstruction to adapt the procedure to LLMs. Extensive results on text classification and other tasks verify the advantage of CoTAM over other LLM-based text generation methods with the same number of training examples. Analysis visualizes the attribute manipulation effectiveness of CoTAM and presents the potential of LLM-guided learning with even less supervision.
StyleGAN3: Generative Networks for Improving the Equivariance of Translation and Rotation
Jul 08, 2023
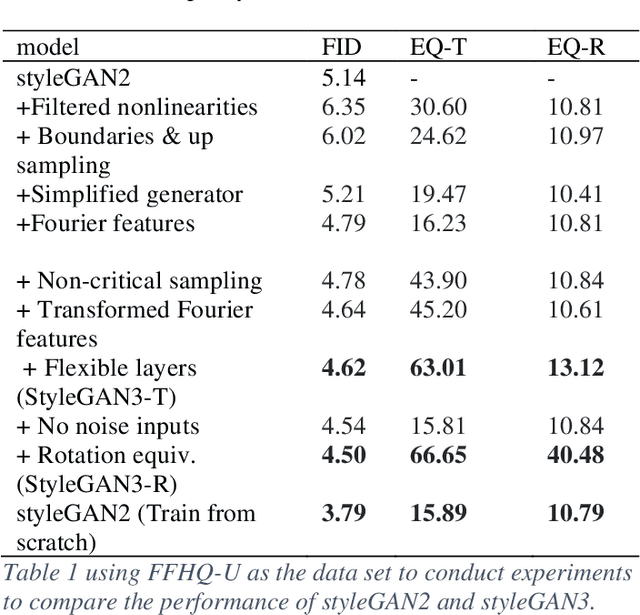
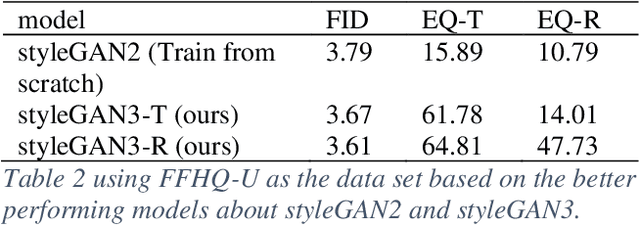

StyleGAN can use style to affect facial posture and identity features, and noise to affect hair, wrinkles, skin color and other details. Among these, the outcomes of the picture processing will vary slightly between different versions of styleGAN. As a result, the comparison of performance differences between styleGAN2 and the two modified versions of styleGAN3 will be the main focus of this study. We used the FFHQ dataset as the dataset and FID, EQ-T, and EQ-R were used to be the assessment of the model. In the end, we discovered that Stylegan3 version is a better generative network to improve the equivariance. Our findings have a positive impact on the creation of animation and videos.
Quaternion Orthogonal Transformer for Facial Expression Recognition in the Wild
Mar 14, 2023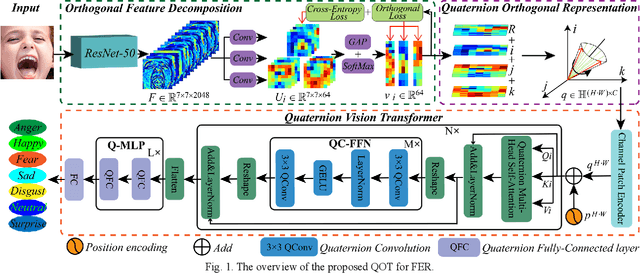
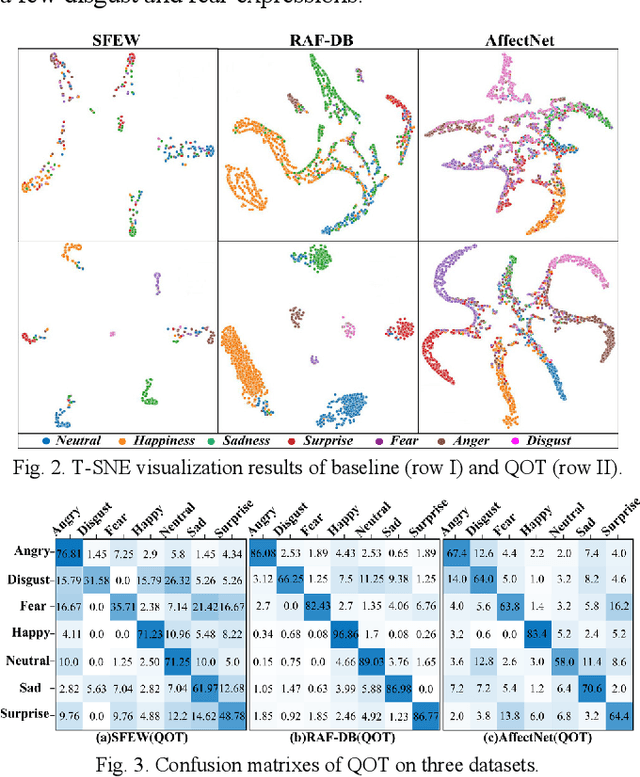
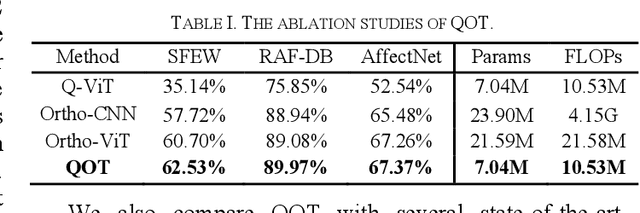
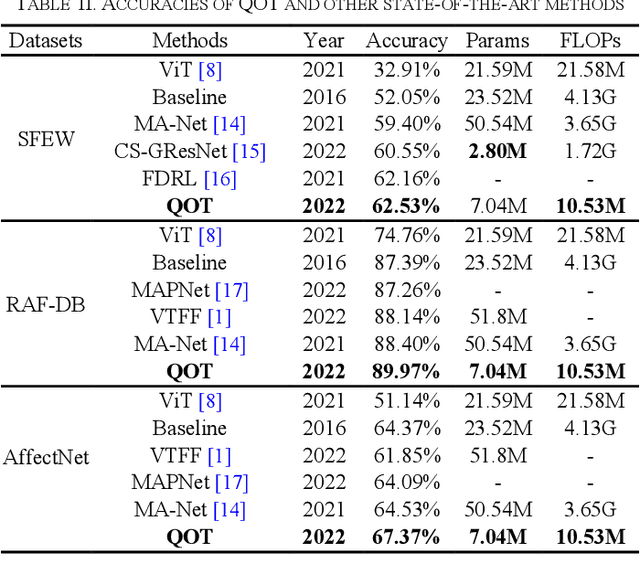
Facial expression recognition (FER) is a challenging topic in artificial intelligence. Recently, many researchers have attempted to introduce Vision Transformer (ViT) to the FER task. However, ViT cannot fully utilize emotional features extracted from raw images and requires a lot of computing resources. To overcome these problems, we propose a quaternion orthogonal transformer (QOT) for FER. Firstly, to reduce redundancy among features extracted from pre-trained ResNet-50, we use the orthogonal loss to decompose and compact these features into three sets of orthogonal sub-features. Secondly, three orthogonal sub-features are integrated into a quaternion matrix, which maintains the correlations between different orthogonal components. Finally, we develop a quaternion vision transformer (Q-ViT) for feature classification. The Q-ViT adopts quaternion operations instead of the original operations in ViT, which improves the final accuracies with fewer parameters. Experimental results on three in-the-wild FER datasets show that the proposed QOT outperforms several state-of-the-art models and reduces the computations.
SqueezerFaceNet: Reducing a Small Face Recognition CNN Even More Via Filter Pruning
Jul 20, 2023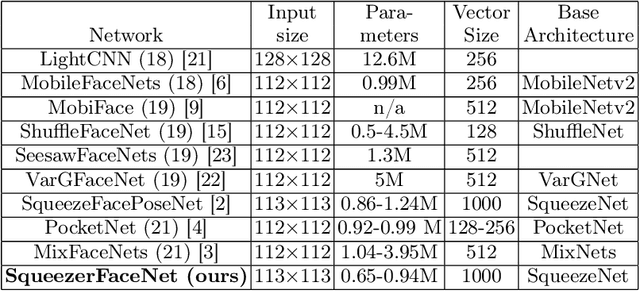


The widespread use of mobile devices for various digital services has created a need for reliable and real-time person authentication. In this context, facial recognition technologies have emerged as a dependable method for verifying users due to the prevalence of cameras in mobile devices and their integration into everyday applications. The rapid advancement of deep Convolutional Neural Networks (CNNs) has led to numerous face verification architectures. However, these models are often large and impractical for mobile applications, reaching sizes of hundreds of megabytes with millions of parameters. We address this issue by developing SqueezerFaceNet, a light face recognition network which less than 1M parameters. This is achieved by applying a network pruning method based on Taylor scores, where filters with small importance scores are removed iteratively. Starting from an already small network (of 1.24M) based on SqueezeNet, we show that it can be further reduced (up to 40%) without an appreciable loss in performance. To the best of our knowledge, we are the first to evaluate network pruning methods for the task of face recognition.
Multiple Appropriate Facial Reaction Generation in Dyadic Interaction Settings: What, Why and How?
Feb 14, 2023
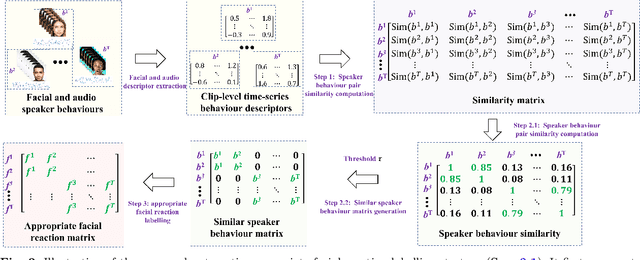
According to the Stimulus Organism Response (SOR) theory, all human behavioral reactions are stimulated by context, where people will process the received stimulus and produce an appropriate reaction. This implies that in a specific context for a given input stimulus, a person can react differently according to their internal state and other contextual factors. Analogously, in dyadic interactions, humans communicate using verbal and nonverbal cues, where a broad spectrum of listeners' non-verbal reactions might be appropriate for responding to a specific speaker behaviour. There already exists a body of work that investigated the problem of automatically generating an appropriate reaction for a given input. However, none attempted to automatically generate multiple appropriate reactions in the context of dyadic interactions and evaluate the appropriateness of those reactions using objective measures. This paper starts by defining the facial Multiple Appropriate Reaction Generation (fMARG) task for the first time in the literature and proposes a new set of objective evaluation metrics to evaluate the appropriateness of the generated reactions. The paper subsequently introduces a framework to predict, generate, and evaluate multiple appropriate facial reactions.
Triplet Loss-less Center Loss Sampling Strategies in Facial Expression Recognition Scenarios
Feb 08, 2023
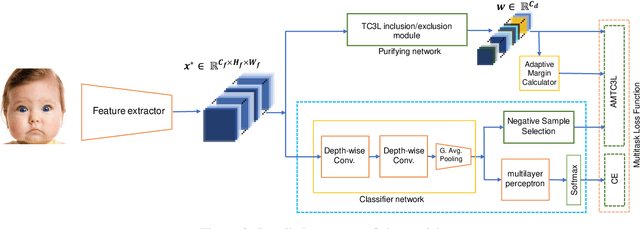
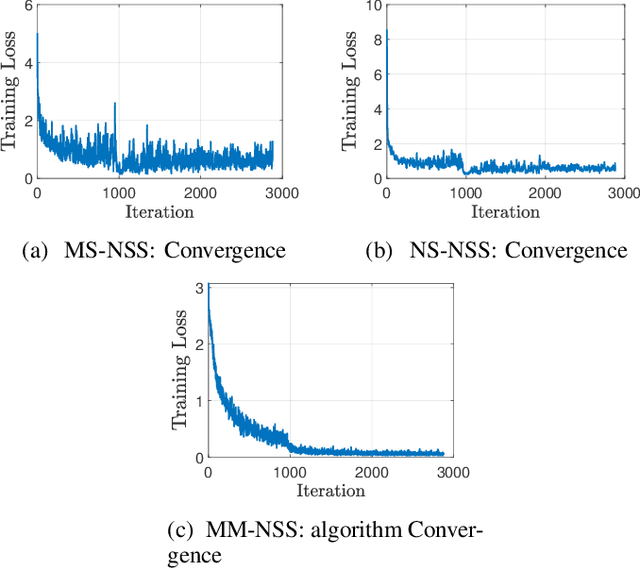
Facial expressions convey massive information and play a crucial role in emotional expression. Deep neural network (DNN) accompanied by deep metric learning (DML) techniques boost the discriminative ability of the model in facial expression recognition (FER) applications. DNN, equipped with only classification loss functions such as Cross-Entropy cannot compact intra-class feature variation or separate inter-class feature distance as well as when it gets fortified by a DML supporting loss item. The triplet center loss (TCL) function is applied on all dimensions of the sample's embedding in the embedding space. In our work, we developed three strategies: fully-synthesized, semi-synthesized, and prediction-based negative sample selection strategies. To achieve better results, we introduce a selective attention module that provides a combination of pixel-wise and element-wise attention coefficients using high-semantic deep features of input samples. We evaluated the proposed method on the RAF-DB, a highly imbalanced dataset. The experimental results reveal significant improvements in comparison to the baseline for all three negative sample selection strategies.
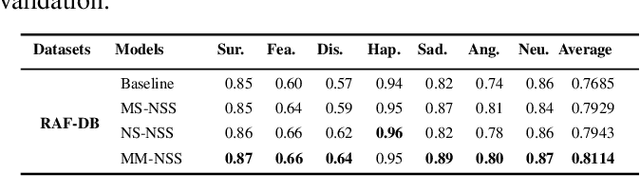
EmoSet: A Large-scale Visual Emotion Dataset with Rich Attributes
Jul 28, 2023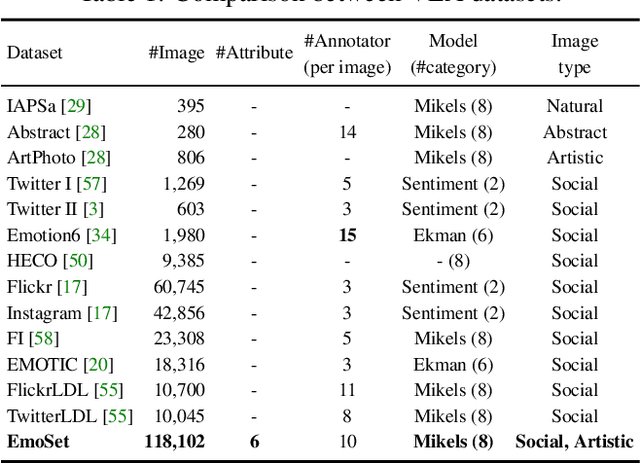
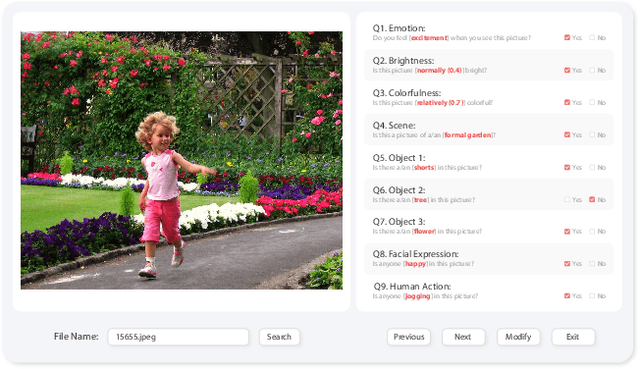
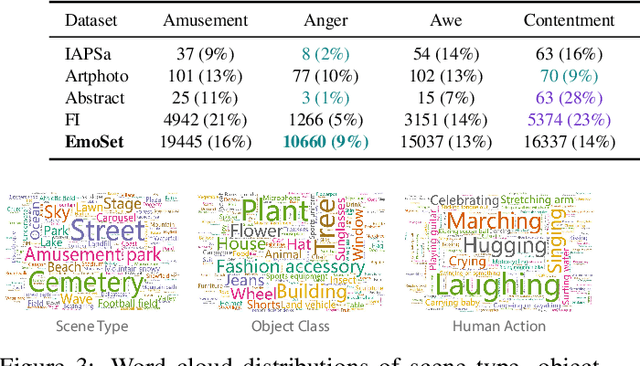
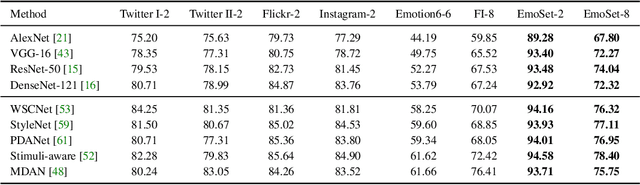
Visual Emotion Analysis (VEA) aims at predicting people's emotional responses to visual stimuli. This is a promising, yet challenging, task in affective computing, which has drawn increasing attention in recent years. Most of the existing work in this area focuses on feature design, while little attention has been paid to dataset construction. In this work, we introduce EmoSet, the first large-scale visual emotion dataset annotated with rich attributes, which is superior to existing datasets in four aspects: scale, annotation richness, diversity, and data balance. EmoSet comprises 3.3 million images in total, with 118,102 of these images carefully labeled by human annotators, making it five times larger than the largest existing dataset. EmoSet includes images from social networks, as well as artistic images, and it is well balanced between different emotion categories. Motivated by psychological studies, in addition to emotion category, each image is also annotated with a set of describable emotion attributes: brightness, colorfulness, scene type, object class, facial expression, and human action, which can help understand visual emotions in a precise and interpretable way. The relevance of these emotion attributes is validated by analyzing the correlations between them and visual emotion, as well as by designing an attribute module to help visual emotion recognition. We believe EmoSet will bring some key insights and encourage further research in visual emotion analysis and understanding. Project page: https://vcc.tech/EmoSet.
Is Facial Recognition Biased at Near-Infrared Spectrum As Well?
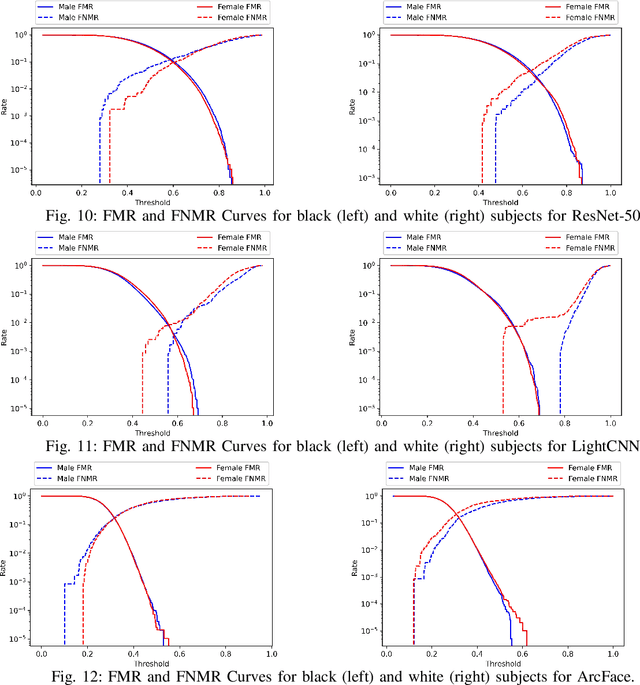
Oct 31, 2022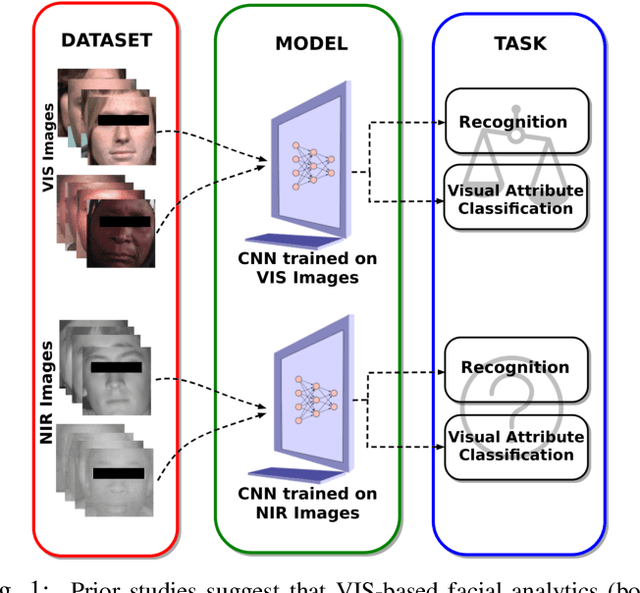
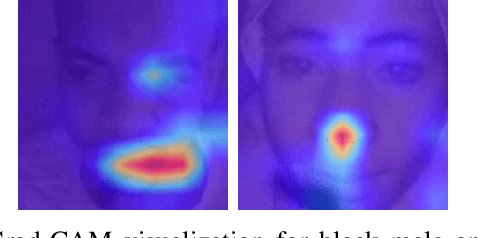
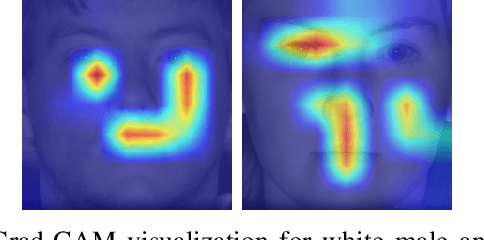
Published academic research and media articles suggest face recognition is biased across demographics. Specifically, unequal performance is obtained for women, dark-skinned people, and older adults. However, these published studies have examined the bias of facial recognition in the visible spectrum (VIS). Factors such as facial makeup, facial hair, skin color, and illumination variation have been attributed to the bias of this technology at the VIS. The near-infrared (NIR) spectrum offers an advantage over the VIS in terms of robustness to factors such as illumination changes, facial makeup, and skin color. Therefore, it is worthwhile to investigate the bias of facial recognition at the near-infrared spectrum (NIR). This first study investigates the bias of the face recognition systems at the NIR spectrum. To this aim, two popular NIR facial image datasets namely, CASIA-Face-Africa and Notre-Dame-NIVL consisting of African and Caucasian subjects, respectively, are used to investigate the bias of facial recognition technology across gender and race. Interestingly, experimental results suggest equitable face recognition performance across gender and race at the NIR spectrum.