 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
SketchMetaFace: A Learning-based Sketching Interface for High-fidelity 3D Character Face Modeling
Jul 04, 2023
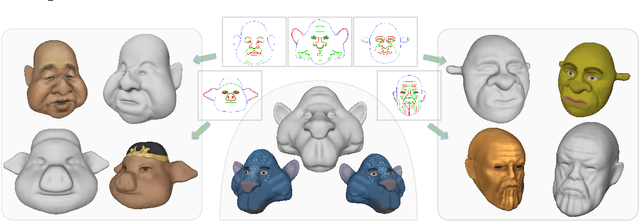
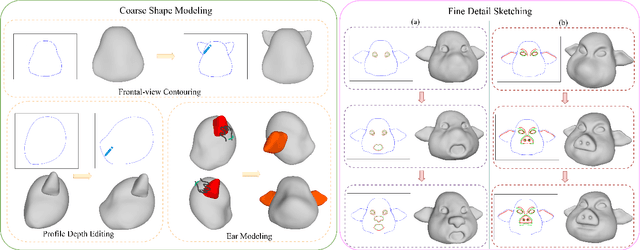
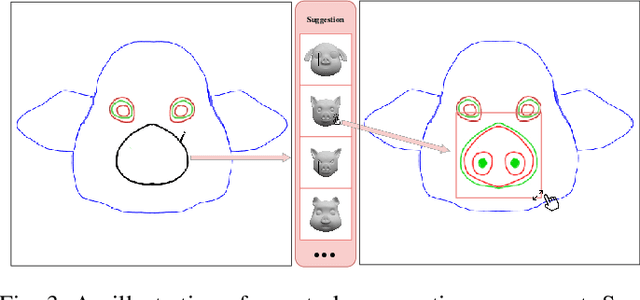
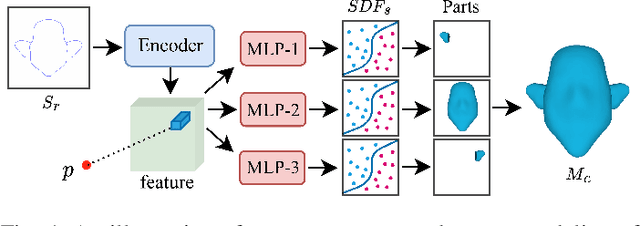
Modeling 3D avatars benefits various application scenarios such as AR/VR, gaming, and filming. Character faces contribute significant diversity and vividity as a vital component of avatars. However, building 3D character face models usually requires a heavy workload with commercial tools, even for experienced artists. Various existing sketch-based tools fail to support amateurs in modeling diverse facial shapes and rich geometric details. In this paper, we present SketchMetaFace - a sketching system targeting amateur users to model high-fidelity 3D faces in minutes. We carefully design both the user interface and the underlying algorithm. First, curvature-aware strokes are adopted to better support the controllability of carving facial details. Second, considering the key problem of mapping a 2D sketch map to a 3D model, we develop a novel learning-based method termed "Implicit and Depth Guided Mesh Modeling" (IDGMM). It fuses the advantages of mesh, implicit, and depth representations to achieve high-quality results with high efficiency. In addition, to further support usability, we present a coarse-to-fine 2D sketching interface design and a data-driven stroke suggestion tool. User studies demonstrate the superiority of our system over existing modeling tools in terms of the ease to use and visual quality of results. Experimental analyses also show that IDGMM reaches a better trade-off between accuracy and efficiency. SketchMetaFace is available at https://zhongjinluo.github.io/SketchMetaFace/.
Lightweight Facial Attractiveness Prediction Using Dual Label Distribution
Dec 04, 2022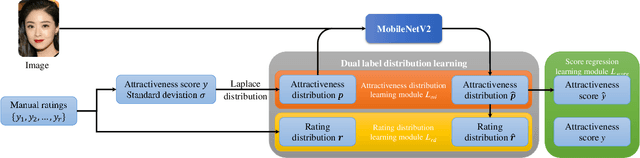
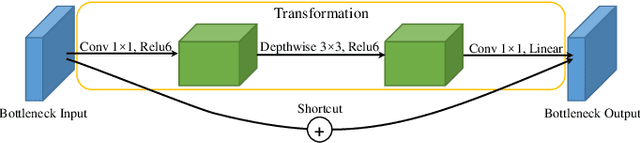
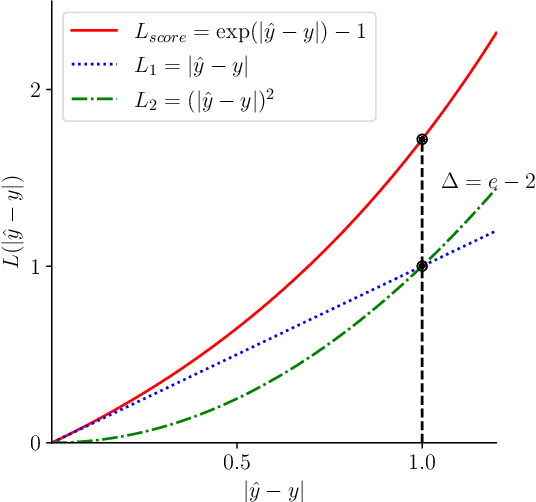
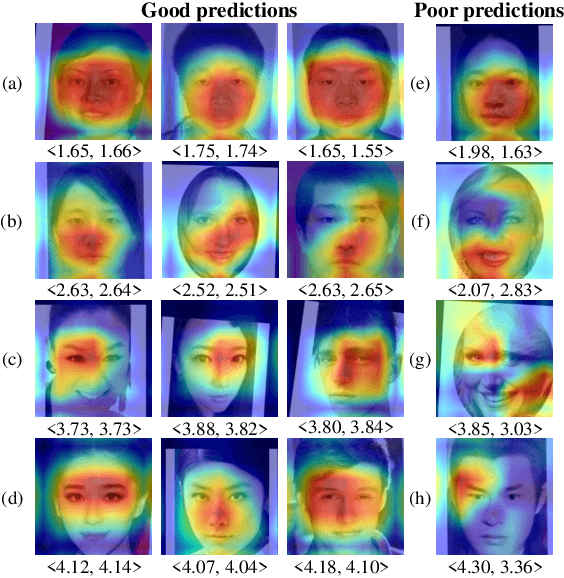
Facial attractiveness prediction (FAP) aims to assess the facial attractiveness automatically based on human aesthetic perception. Previous methods using deep convolutional neural networks have boosted the performance, but their giant models lead to a deficiency in flexibility. Besides, most of them fail to take full advantage of the dataset. In this paper, we present a novel end-to-end FAP approach integrating dual label distribution and lightweight design. To make the best use of the dataset, the manual ratings, attractiveness score, and standard deviation are aggregated explicitly to construct a dual label distribution, including the attractiveness distribution and the rating distribution. Such distributions, as well as the attractiveness score, are optimized under a joint learning framework based on the label distribution learning (LDL) paradigm. As for the lightweight design, the data processing is simplified to minimum, and MobileNetV2 is selected as our backbone. Extensive experiments are conducted on two benchmark datasets, where our approach achieves promising results and succeeds in striking a balance between performance and efficiency. Ablation studies demonstrate that our delicately designed learning modules are indispensable and correlated. Additionally, the visualization indicates that our approach is capable of perceiving facial attractiveness and capturing attractive facial regions to facilitate semantic predictions.
More comprehensive facial inversion for more effective expression recognition
Nov 24, 2022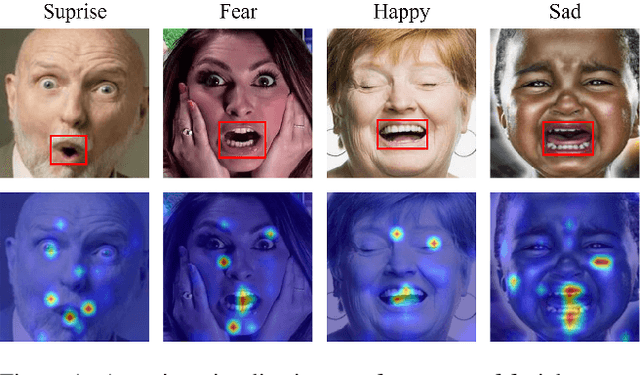
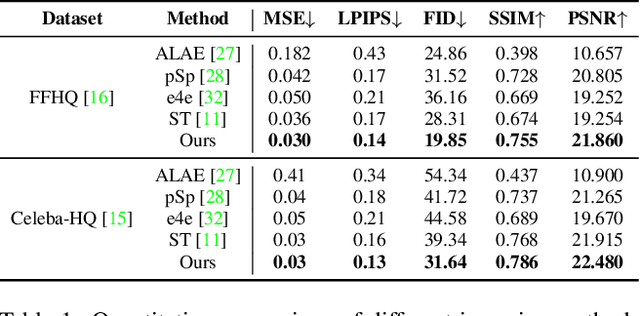

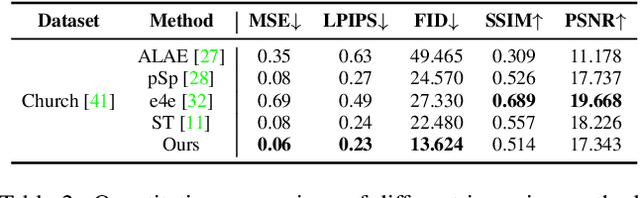
Facial expression recognition (FER) plays a significant role in the ubiquitous application of computer vision. We revisit this problem with a new perspective on whether it can acquire useful representations that improve FER performance in the image generation process, and propose a novel generative method based on the image inversion mechanism for the FER task, termed Inversion FER (IFER). Particularly, we devise a novel Adversarial Style Inversion Transformer (ASIT) towards IFER to comprehensively extract features of generated facial images. In addition, ASIT is equipped with an image inversion discriminator that measures the cosine similarity of semantic features between source and generated images, constrained by a distribution alignment loss. Finally, we introduce a feature modulation module to fuse the structural code and latent codes from ASIT for the subsequent FER work. We extensively evaluate ASIT on facial datasets such as FFHQ and CelebA-HQ, showing that our approach achieves state-of-the-art facial inversion performance. IFER also achieves competitive results in facial expression recognition datasets such as RAF-DB, SFEW and AffectNet. The code and models are available at https://github.com/Talented-Q/IFER-master.
An experimental study in Real-time Facial Emotion Recognition on new 3RL dataset
Apr 06, 2023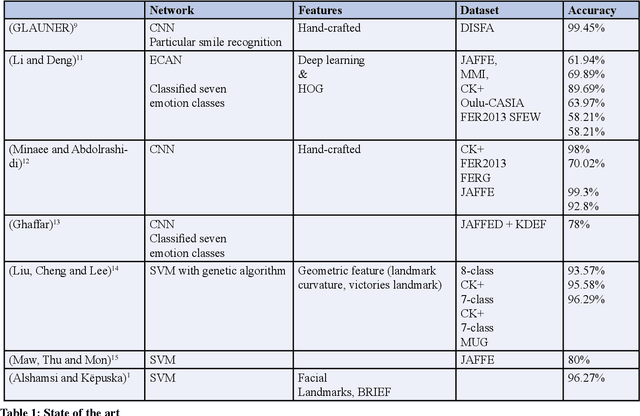
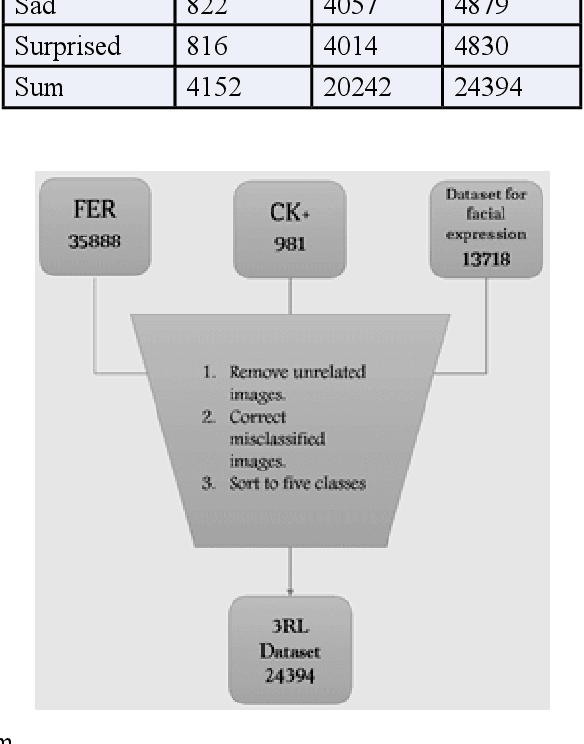
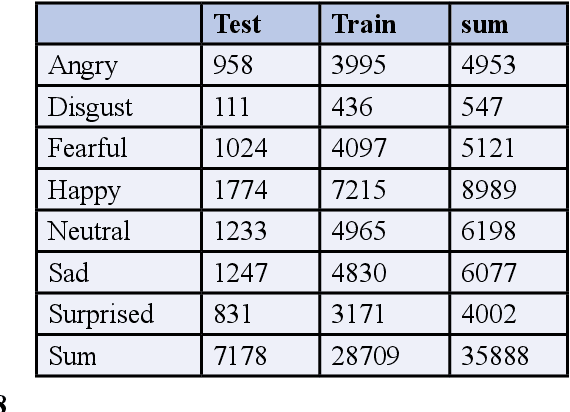

Although real-time facial emotion recognition is a hot topic research domain in the field of human-computer interaction, state-of the-art available datasets still suffer from various problems, such as some unrelated photos such as document photos, unbalanced numbers of photos in each class, and misleading images that can negatively affect correct classification. The 3RL dataset was created, which contains approximately 24K images and will be publicly available, to overcome previously available dataset problems. The 3RL dataset is labelled with five basic emotions: happiness, fear, sadness, disgust, and anger. Moreover, we compared the 3RL dataset with other famous state-of-the-art datasets (FER dataset, CK+ dataset), and we applied the most commonly used algorithms in previous works, SVM and CNN. The results show a noticeable improvement in generalization on the 3RL dataset. Experiments have shown an accuracy of up to 91.4% on 3RL dataset using CNN where results on FER2013, CK+ are, respectively (approximately from 60% to 85%).
InMyFace: Inertial and Mechanomyography-Based Sensor Fusion for Wearable Facial Activity Recognition
Feb 08, 2023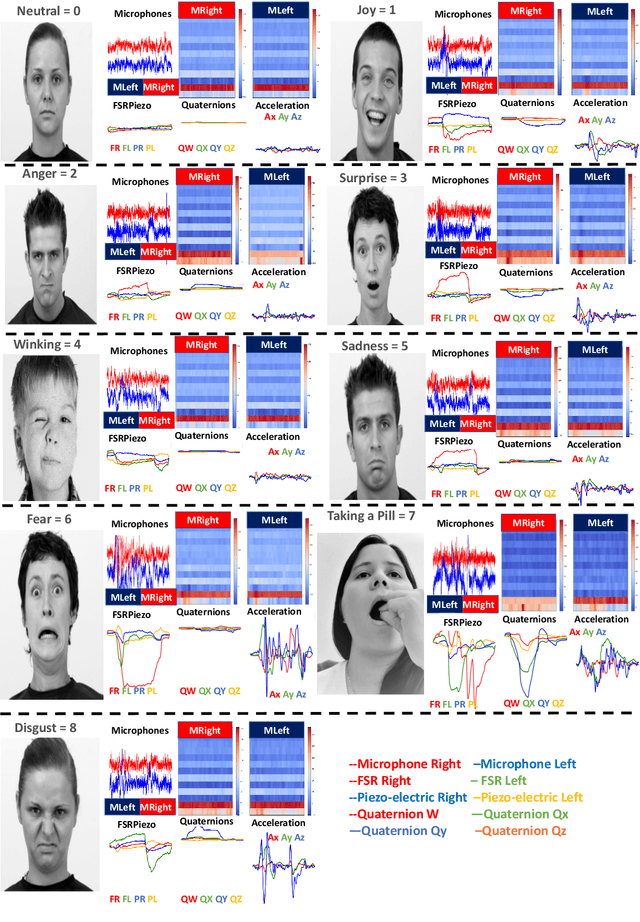
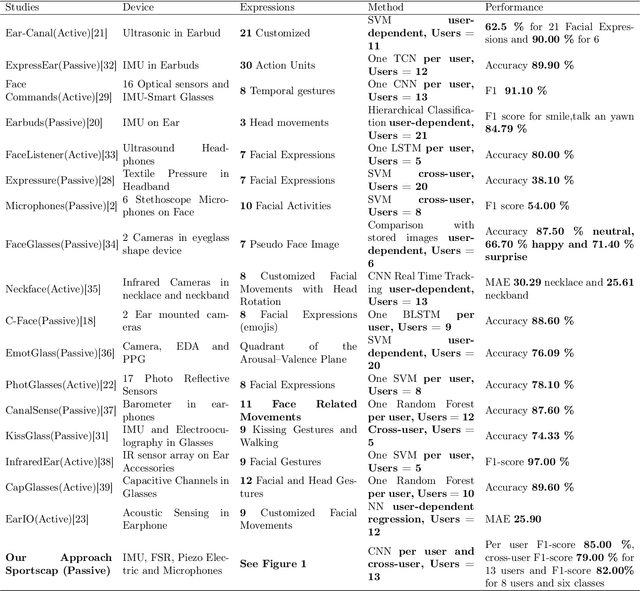
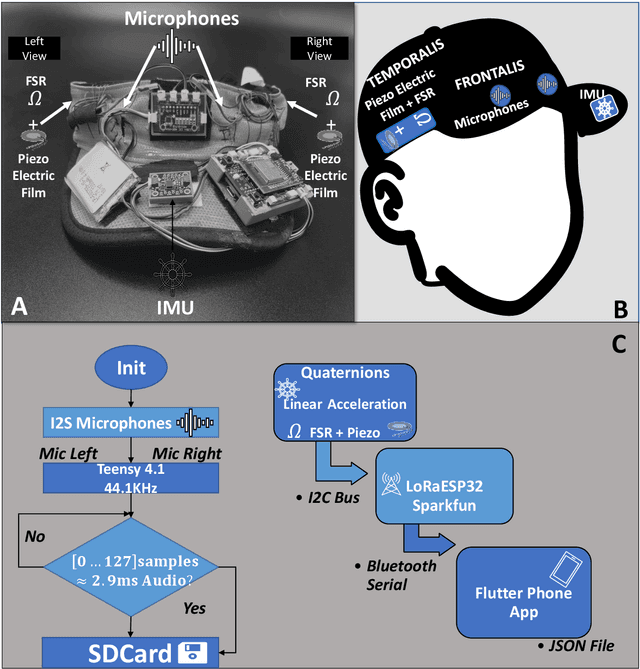
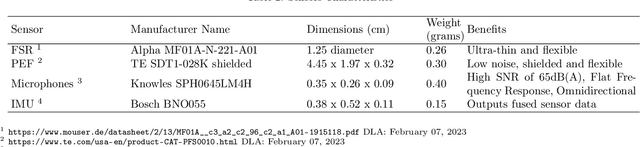
Recognizing facial activity is a well-understood (but non-trivial) computer vision problem. However, reliable solutions require a camera with a good view of the face, which is often unavailable in wearable settings. Furthermore, in wearable applications, where systems accompany users throughout their daily activities, a permanently running camera can be problematic for privacy (and legal) reasons. This work presents an alternative solution based on the fusion of wearable inertial sensors, planar pressure sensors, and acoustic mechanomyography (muscle sounds). The sensors were placed unobtrusively in a sports cap to monitor facial muscle activities related to facial expressions. We present our integrated wearable sensor system, describe data fusion and analysis methods, and evaluate the system in an experiment with thirteen subjects from different cultural backgrounds (eight countries) and both sexes (six women and seven men). In a one-model-per-user scheme and using a late fusion approach, the system yielded an average F1 score of 85.00% for the case where all sensing modalities are combined. With a cross-user validation and a one-model-for-all-user scheme, an F1 score of 79.00% was obtained for thirteen participants (six females and seven males). Moreover, in a hybrid fusion (cross-user) approach and six classes, an average F1 score of 82.00% was obtained for eight users. The results are competitive with state-of-the-art non-camera-based solutions for a cross-user study. In addition, our unique set of participants demonstrates the inclusiveness and generalizability of the approach.
Interpretable Explainability in Facial Emotion Recognition and Gamification for Data Collection
Nov 09, 2022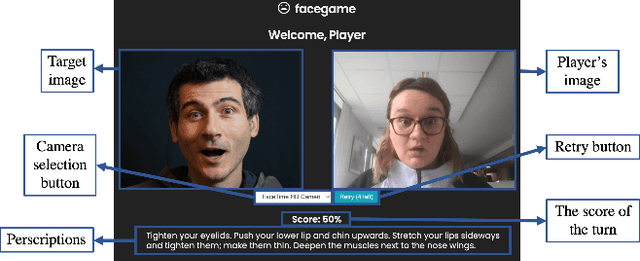
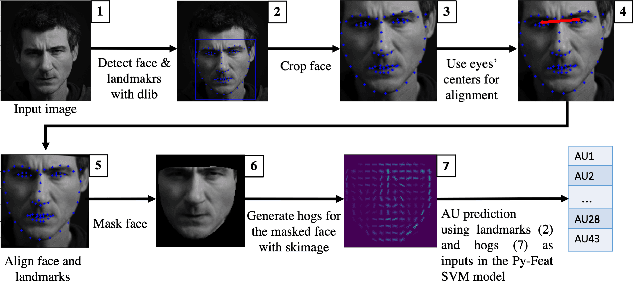
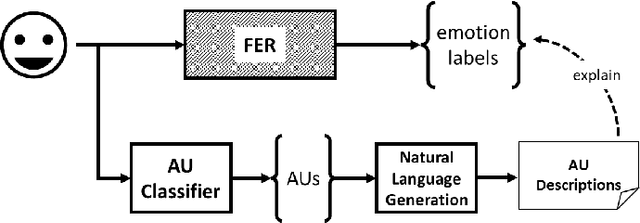
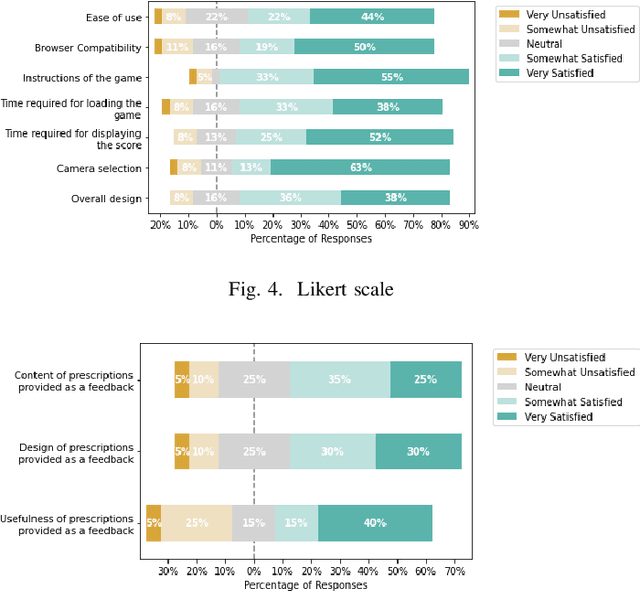
Training facial emotion recognition models requires large sets of data and costly annotation processes. To alleviate this problem, we developed a gamified method of acquiring annotated facial emotion data without an explicit labeling effort by humans. The game, which we named Facegame, challenges the players to imitate a displayed image of a face that portrays a particular basic emotion. Every round played by the player creates new data that consists of a set of facial features and landmarks, already annotated with the emotion label of the target facial expression. Such an approach effectively creates a robust, sustainable, and continuous machine learning training process. We evaluated Facegame with an experiment that revealed several contributions to the field of affective computing. First, the gamified data collection approach allowed us to access a rich variation of facial expressions of each basic emotion due to the natural variations in the players' facial expressions and their expressive abilities. We report improved accuracy when the collected data were used to enrich well-known in-the-wild facial emotion datasets and consecutively used for training facial emotion recognition models. Second, the natural language prescription method used by the Facegame constitutes a novel approach for interpretable explainability that can be applied to any facial emotion recognition model. Finally, we observed significant improvements in the facial emotion perception and expression skills of the players through repeated game play.
High-fidelity Facial Avatar Reconstruction from Monocular Video with Generative Priors
Nov 28, 2022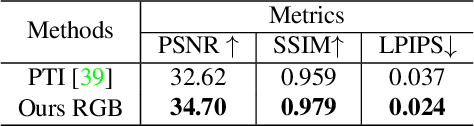
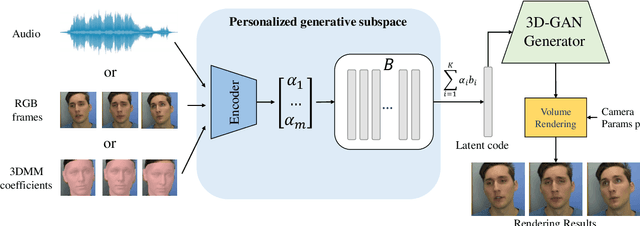
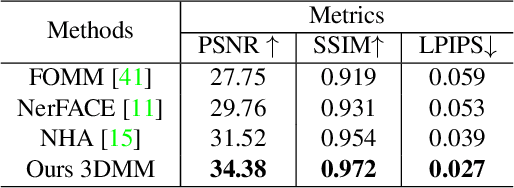
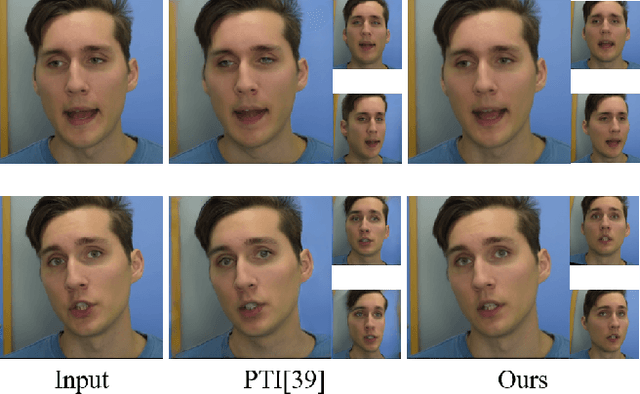
High-fidelity facial avatar reconstruction from a monocular video is a significant research problem in computer graphics and computer vision. Recently, Neural Radiance Field (NeRF) has shown impressive novel view rendering results and has been considered for facial avatar reconstruction. However, the complex facial dynamics and missing 3D information in monocular videos raise significant challenges for faithful facial reconstruction. In this work, we propose a new method for NeRF-based facial avatar reconstruction that utilizes 3D-aware generative prior. Different from existing works that depend on a conditional deformation field for dynamic modeling, we propose to learn a personalized generative prior, which is formulated as a local and low dimensional subspace in the latent space of 3D-GAN. We propose an efficient method to construct the personalized generative prior based on a small set of facial images of a given individual. After learning, it allows for photo-realistic rendering with novel views and the face reenactment can be realized by performing navigation in the latent space. Our proposed method is applicable for different driven signals, including RGB images, 3DMM coefficients, and audios. Compared with existing works, we obtain superior novel view synthesis results and faithfully face reenactment performance.
DaGAN++: Depth-Aware Generative Adversarial Network for Talking Head Video Generation
May 10, 2023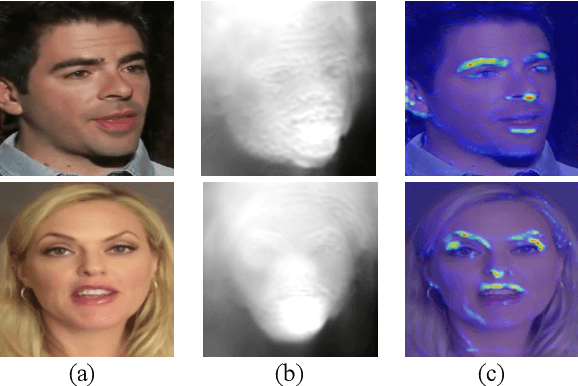
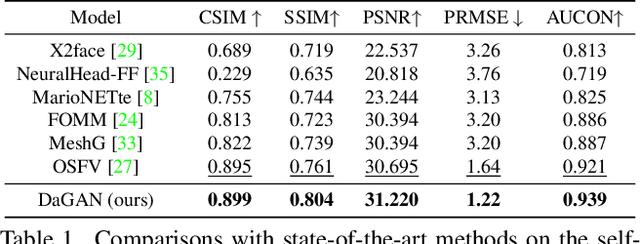
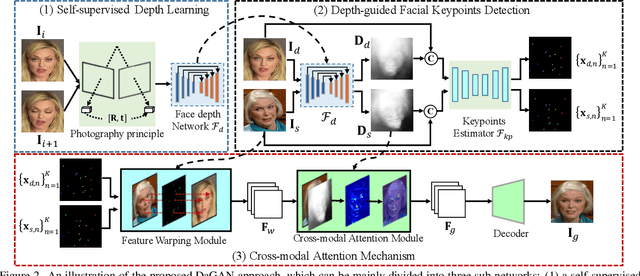
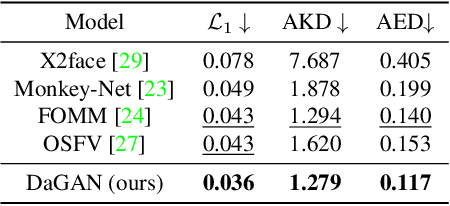
Predominant techniques on talking head generation largely depend on 2D information, including facial appearances and motions from input face images. Nevertheless, dense 3D facial geometry, such as pixel-wise depth, plays a critical role in constructing accurate 3D facial structures and suppressing complex background noises for generation. However, dense 3D annotations for facial videos is prohibitively costly to obtain. In this work, firstly, we present a novel self-supervised method for learning dense 3D facial geometry (ie, depth) from face videos, without requiring camera parameters and 3D geometry annotations in training. We further propose a strategy to learn pixel-level uncertainties to perceive more reliable rigid-motion pixels for geometry learning. Secondly, we design an effective geometry-guided facial keypoint estimation module, providing accurate keypoints for generating motion fields. Lastly, we develop a 3D-aware cross-modal (ie, appearance and depth) attention mechanism, which can be applied to each generation layer, to capture facial geometries in a coarse-to-fine manner. Extensive experiments are conducted on three challenging benchmarks (ie, VoxCeleb1, VoxCeleb2, and HDTF). The results demonstrate that our proposed framework can generate highly realistic-looking reenacted talking videos, with new state-of-the-art performances established on these benchmarks. The codes and trained models are publicly available on the GitHub project page at https://github.com/harlanhong/CVPR2022-DaGAN
MODA: Mapping-Once Audio-driven Portrait Animation with Dual Attentions
Jul 19, 2023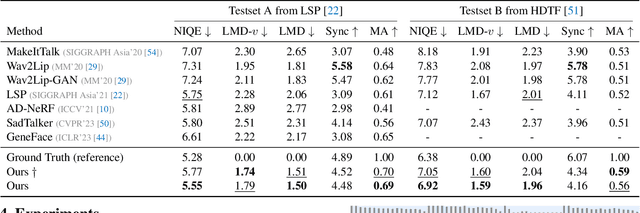

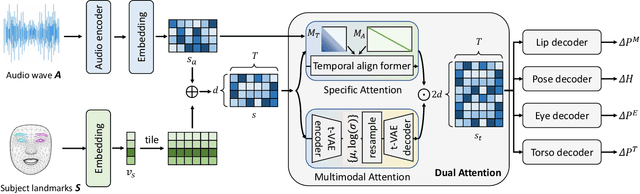

Audio-driven portrait animation aims to synthesize portrait videos that are conditioned by given audio. Animating high-fidelity and multimodal video portraits has a variety of applications. Previous methods have attempted to capture different motion modes and generate high-fidelity portrait videos by training different models or sampling signals from given videos. However, lacking correlation learning between lip-sync and other movements (e.g., head pose/eye blinking) usually leads to unnatural results. In this paper, we propose a unified system for multi-person, diverse, and high-fidelity talking portrait generation. Our method contains three stages, i.e., 1) Mapping-Once network with Dual Attentions (MODA) generates talking representation from given audio. In MODA, we design a dual-attention module to encode accurate mouth movements and diverse modalities. 2) Facial composer network generates dense and detailed face landmarks, and 3) temporal-guided renderer syntheses stable videos. Extensive evaluations demonstrate that the proposed system produces more natural and realistic video portraits compared to previous methods.
INCLG: Inpainting for Non-Cleft Lip Generation with a Multi-Task Image Processing Network
May 17, 2023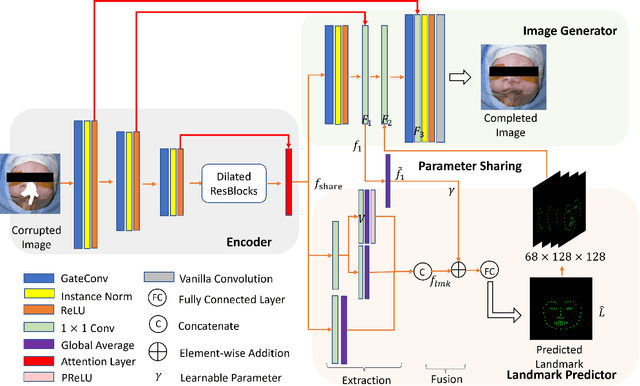
We present a software that predicts non-cleft facial images for patients with cleft lip, thereby facilitating the understanding, awareness and discussion of cleft lip surgeries. To protect patients privacy, we design a software framework using image inpainting, which does not require cleft lip images for training, thereby mitigating the risk of model leakage. We implement a novel multi-task architecture that predicts both the non-cleft facial image and facial landmarks, resulting in better performance as evaluated by surgeons. The software is implemented with PyTorch and is usable with consumer-level color images with a fast prediction speed, enabling effective deployment.