 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Spiking-Fer: Spiking Neural Network for Facial Expression Recognition With Event Cameras
Apr 20, 2023

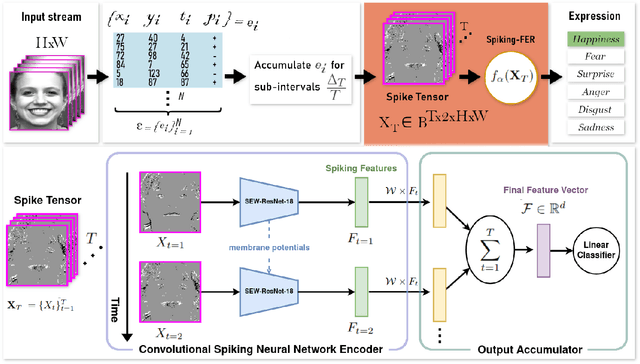
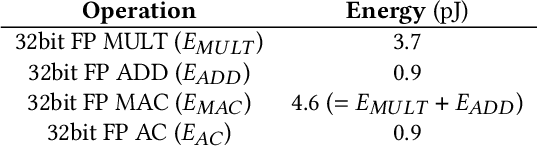
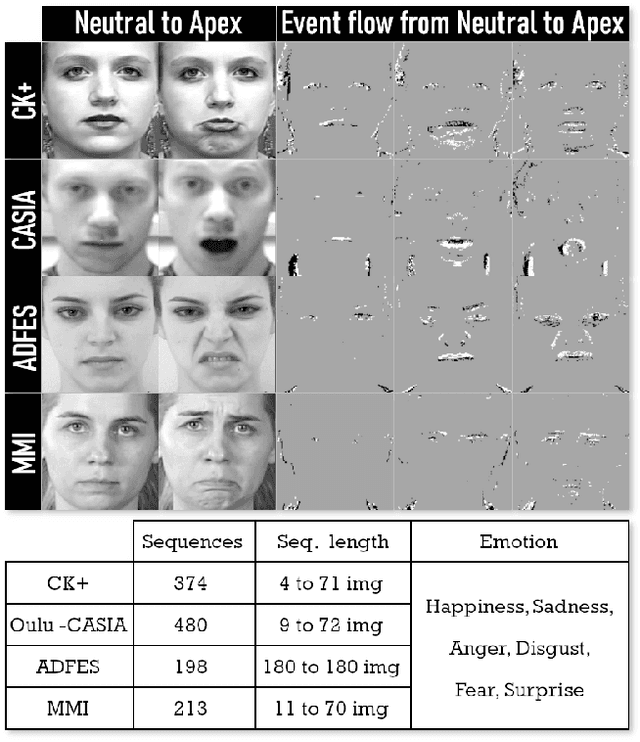
Facial Expression Recognition (FER) is an active research domain that has shown great progress recently, notably thanks to the use of large deep learning models. However, such approaches are particularly energy intensive, which makes their deployment difficult for edge devices. To address this issue, Spiking Neural Networks (SNNs) coupled with event cameras are a promising alternative, capable of processing sparse and asynchronous events with lower energy consumption. In this paper, we establish the first use of event cameras for FER, named "Event-based FER", and propose the first related benchmarks by converting popular video FER datasets to event streams. To deal with this new task, we propose "Spiking-FER", a deep convolutional SNN model, and compare it against a similar Artificial Neural Network (ANN). Experiments show that the proposed approach achieves comparable performance to the ANN architecture, while consuming less energy by orders of magnitude (up to 65.39x). In addition, an experimental study of various event-based data augmentation techniques is performed to provide insights into the efficient transformations specific to event-based FER.
Photorealistic Facial Wrinkles Removal
Nov 03, 2022

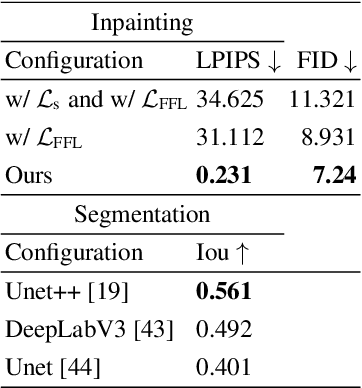
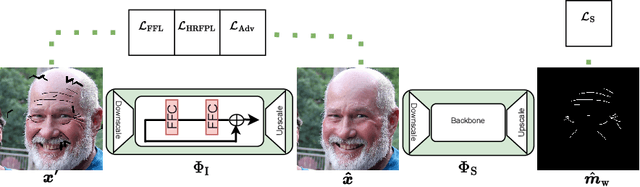
Editing and retouching facial attributes is a complex task that usually requires human artists to obtain photo-realistic results. Its applications are numerous and can be found in several contexts such as cosmetics or digital media retouching, to name a few. Recently, advancements in conditional generative modeling have shown astonishing results at modifying facial attributes in a realistic manner. However, current methods are still prone to artifacts, and focus on modifying global attributes like age and gender, or local mid-sized attributes like glasses or moustaches. In this work, we revisit a two-stage approach for retouching facial wrinkles and obtain results with unprecedented realism. First, a state of the art wrinkle segmentation network is used to detect the wrinkles within the facial region. Then, an inpainting module is used to remove the detected wrinkles, filling them in with a texture that is statistically consistent with the surrounding skin. To achieve this, we introduce a novel loss term that reuses the wrinkle segmentation network to penalize those regions that still contain wrinkles after the inpainting. We evaluate our method qualitatively and quantitatively, showing state of the art results for the task of wrinkle removal. Moreover, we introduce the first high-resolution dataset, named FFHQ-Wrinkles, to evaluate wrinkle detection methods.
Deep Ensemble Learning with Frame Skipping for Face Anti-Spoofing
Jul 11, 2023
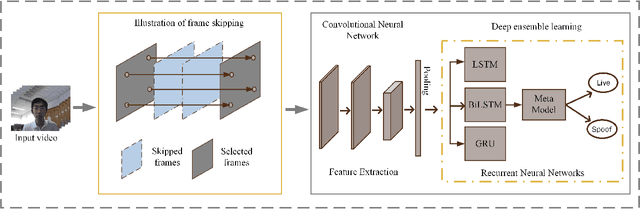
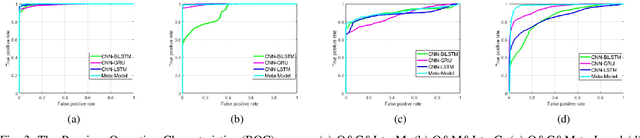
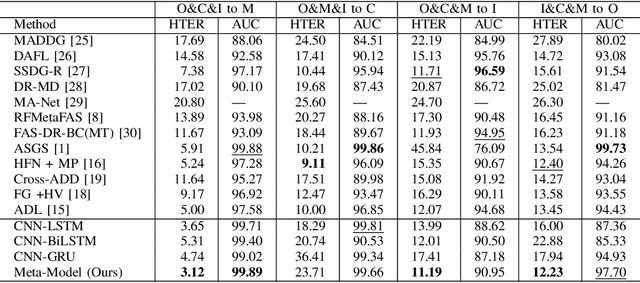
Face presentation attacks (PA), also known as spoofing attacks, pose a substantial threat to biometric systems that rely on facial recognition systems, such as access control systems, mobile payments, and identity verification systems. To mitigate the spoofing risk, several video-based methods have been presented in the literature that analyze facial motion in successive video frames. However, estimating the motion between adjacent frames is a challenging task and requires high computational cost. In this paper, we rephrase the face anti-spoofing task as a motion prediction problem and introduce a deep ensemble learning model with a frame skipping mechanism. In particular, the proposed frame skipping adopts a uniform sampling approach by dividing the original video into video clips of fixed size. By doing so, every nth frame of the clip is selected to ensure that the temporal patterns can easily be perceived during the training of three different recurrent neural networks (RNNs). Motivated by the performance of individual RNNs, a meta-model is developed to improve the overall detection performance by combining the prediction of individual RNNs. Extensive experiments were performed on four datasets, and state-of-the-art performance is reported on MSU-MFSD (3.12%), Replay-Attack (11.19%), and OULU-NPU (12.23%) databases by using half total error rates (HTERs) in the most challenging cross-dataset testing scenario.
DiffFace: Diffusion-based Face Swapping with Facial Guidance
Dec 27, 2022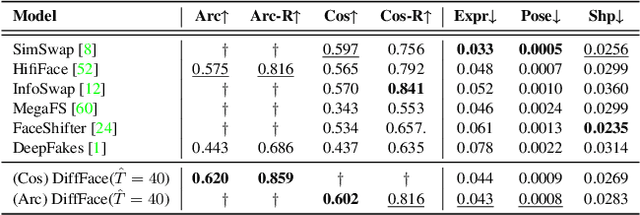

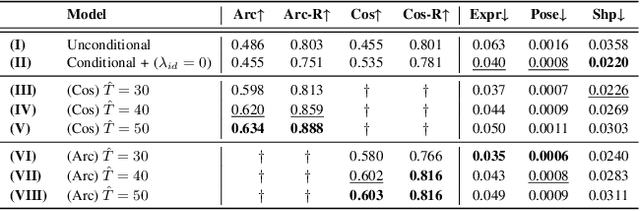
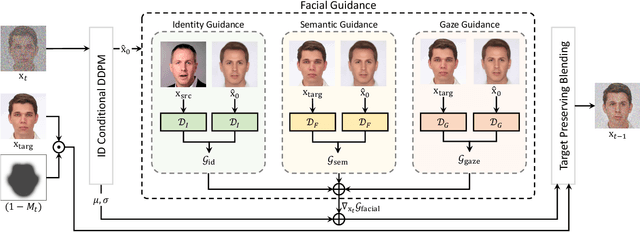
In this paper, we propose a diffusion-based face swapping framework for the first time, called DiffFace, composed of training ID conditional DDPM, sampling with facial guidance, and a target-preserving blending. In specific, in the training process, the ID conditional DDPM is trained to generate face images with the desired identity. In the sampling process, we use the off-the-shelf facial expert models to make the model transfer source identity while preserving target attributes faithfully. During this process, to preserve the background of the target image and obtain the desired face swapping result, we additionally propose a target-preserving blending strategy. It helps our model to keep the attributes of the target face from noise while transferring the source facial identity. In addition, without any re-training, our model can flexibly apply additional facial guidance and adaptively control the ID-attributes trade-off to achieve the desired results. To the best of our knowledge, this is the first approach that applies the diffusion model in face swapping task. Compared with previous GAN-based approaches, by taking advantage of the diffusion model for the face swapping task, DiffFace achieves better benefits such as training stability, high fidelity, diversity of the samples, and controllability. Extensive experiments show that our DiffFace is comparable or superior to the state-of-the-art methods on several standard face swapping benchmarks.
RestoreFormer++: Towards Real-World Blind Face Restoration from Undegraded Key-Value Pairs
Aug 14, 2023
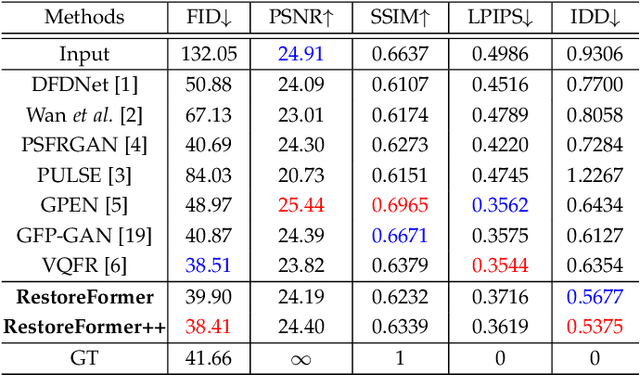
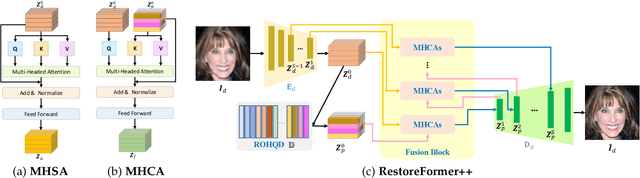
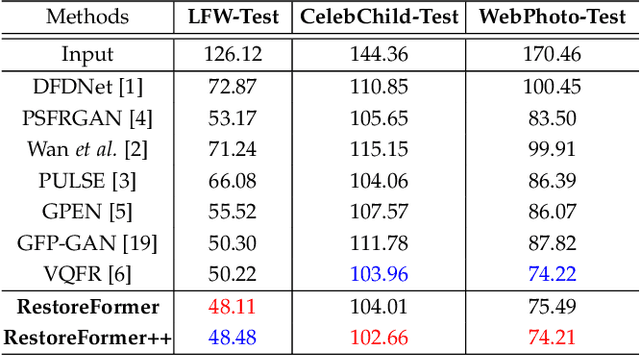
Blind face restoration aims at recovering high-quality face images from those with unknown degradations. Current algorithms mainly introduce priors to complement high-quality details and achieve impressive progress. However, most of these algorithms ignore abundant contextual information in the face and its interplay with the priors, leading to sub-optimal performance. Moreover, they pay less attention to the gap between the synthetic and real-world scenarios, limiting the robustness and generalization to real-world applications. In this work, we propose RestoreFormer++, which on the one hand introduces fully-spatial attention mechanisms to model the contextual information and the interplay with the priors, and on the other hand, explores an extending degrading model to help generate more realistic degraded face images to alleviate the synthetic-to-real-world gap. Compared with current algorithms, RestoreFormer++ has several crucial benefits. First, instead of using a multi-head self-attention mechanism like the traditional visual transformer, we introduce multi-head cross-attention over multi-scale features to fully explore spatial interactions between corrupted information and high-quality priors. In this way, it can facilitate RestoreFormer++ to restore face images with higher realness and fidelity. Second, in contrast to the recognition-oriented dictionary, we learn a reconstruction-oriented dictionary as priors, which contains more diverse high-quality facial details and better accords with the restoration target. Third, we introduce an extending degrading model that contains more realistic degraded scenarios for training data synthesizing, and thus helps to enhance the robustness and generalization of our RestoreFormer++ model. Extensive experiments show that RestoreFormer++ outperforms state-of-the-art algorithms on both synthetic and real-world datasets.
Two-in-one Knowledge Distillation for Efficient Facial Forgery Detection
Feb 21, 2023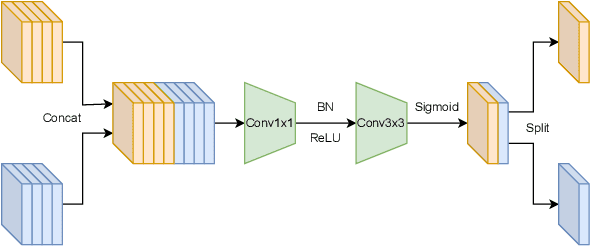

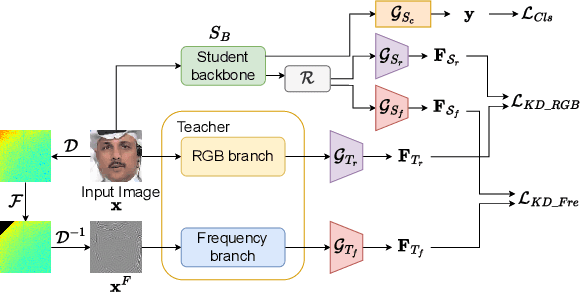
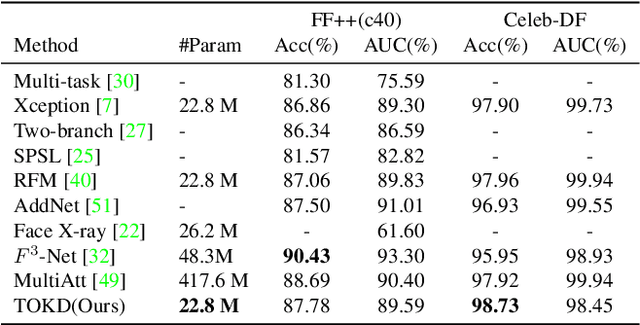
Facial forgery detection is a crucial but extremely challenging topic, with the fast development of forgery techniques making the synthetic artefact highly indistinguishable. Prior works show that by mining both spatial and frequency information the forgery detection performance of deep learning models can be vastly improved. However, leveraging multiple types of information usually requires more than one branch in the neural network, which makes the model heavy and cumbersome. Knowledge distillation, as an important technique for efficient modelling, could be a possible remedy. We find that existing knowledge distillation methods have difficulties distilling a dual-branch model into a single-branch model. More specifically, knowledge distillation on both the spatial and frequency branches has degraded performance than distillation only on the spatial branch. To handle such problem, we propose a novel two-in-one knowledge distillation framework which can smoothly merge the information from a large dual-branch network into a small single-branch network, with the help of different dedicated feature projectors and the gradient homogenization technique. Experimental analysis on two datasets, FaceForensics++ and Celeb-DF, shows that our proposed framework achieves superior performance for facial forgery detection with much fewer parameters.
POSTER++: A simpler and stronger facial expression recognition network
Feb 12, 2023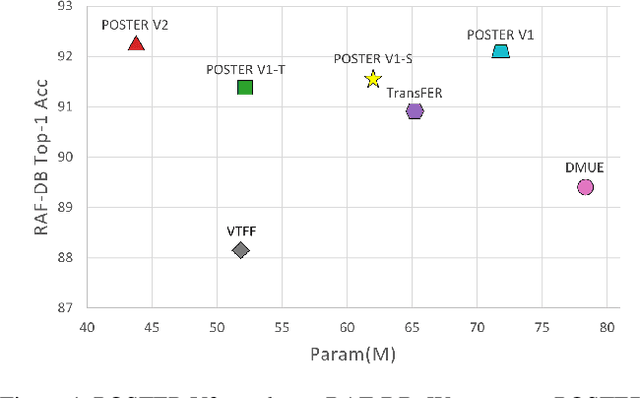

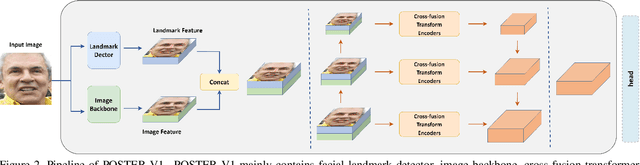
Facial expression recognition (FER) plays an important role in a variety of real-world applications such as human-computer interaction. POSTER achieves the state-of-the-art (SOTA) performance in FER by effectively combining facial landmark and image features through two-stream pyramid cross-fusion design. However, the architecture of POSTER is undoubtedly complex. It causes expensive computational costs. In order to relieve the computational pressure of POSTER, in this paper, we propose POSTER++. It improves POSTER in three directions: cross-fusion, two-stream, and multi-scale feature extraction. In cross-fusion, we use window-based cross-attention mechanism replacing vanilla cross-attention mechanism. We remove the image-to-landmark branch in the two-stream design. For multi-scale feature extraction, POSTER++ combines images with landmark's multi-scale features to replace POSTER's pyramid design. Extensive experiments on several standard datasets show that our POSTER++ achieves the SOTA FER performance with the minimum computational cost. For example, POSTER++ reached 92.21% on RAF-DB, 67.49% on AffectNet (7 cls) and 63.77% on AffectNet (8 cls), respectively, using only 8.4G floating point operations (FLOPs) and 43.7M parameters (Param). This demonstrates the effectiveness of our improvements.
Face Encryption via Frequency-Restricted Identity-Agnostic Attacks
Aug 11, 2023
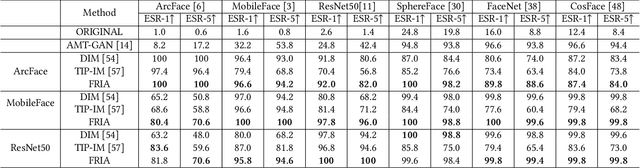
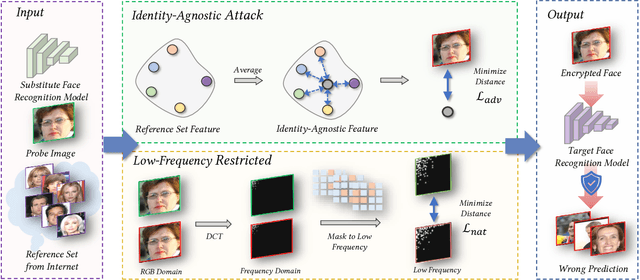
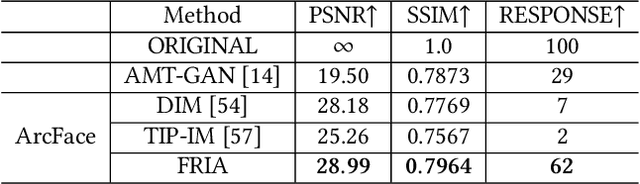
Billions of people are sharing their daily live images on social media everyday. However, malicious collectors use deep face recognition systems to easily steal their biometric information (e.g., faces) from these images. Some studies are being conducted to generate encrypted face photos using adversarial attacks by introducing imperceptible perturbations to reduce face information leakage. However, existing studies need stronger black-box scenario feasibility and more natural visual appearances, which challenge the feasibility of privacy protection. To address these problems, we propose a frequency-restricted identity-agnostic (FRIA) framework to encrypt face images from unauthorized face recognition without access to personal information. As for the weak black-box scenario feasibility, we obverse that representations of the average feature in multiple face recognition models are similar, thus we propose to utilize the average feature via the crawled dataset from the Internet as the target to guide the generation, which is also agnostic to identities of unknown face recognition systems; in nature, the low-frequency perturbations are more visually perceptible by the human vision system. Inspired by this, we restrict the perturbation in the low-frequency facial regions by discrete cosine transform to achieve the visual naturalness guarantee. Extensive experiments on several face recognition models demonstrate that our FRIA outperforms other state-of-the-art methods in generating more natural encrypted faces while attaining high black-box attack success rates of 96%. In addition, we validate the efficacy of FRIA using real-world black-box commercial API, which reveals the potential of FRIA in practice. Our codes can be found in https://github.com/XinDong10/FRIA.
Fake It Without Making It: Conditioned Face Generation for Accurate 3D Face Shape Estimation
Jul 25, 2023
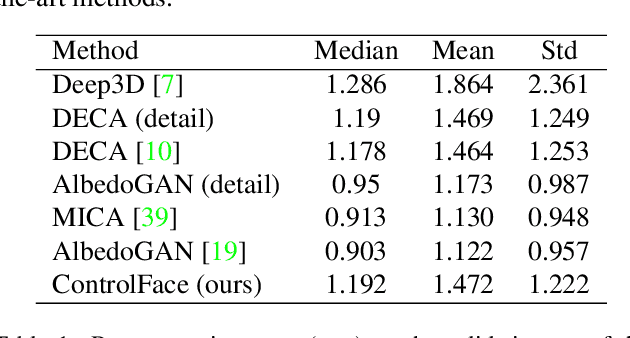
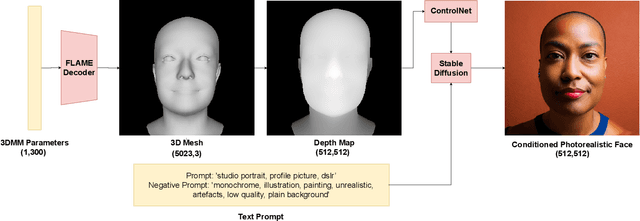

Accurate 3D face shape estimation is an enabling technology with applications in healthcare, security, and creative industries, yet current state-of-the-art methods either rely on self-supervised training with 2D image data or supervised training with very limited 3D data. To bridge this gap, we present a novel approach which uses a conditioned stable diffusion model for face image generation, leveraging the abundance of 2D facial information to inform 3D space. By conditioning stable diffusion on depth maps sampled from a 3D Morphable Model (3DMM) of the human face, we generate diverse and shape-consistent images, forming the basis of SynthFace. We introduce this large-scale synthesised dataset of 250K photorealistic images and corresponding 3DMM parameters. We further propose ControlFace, a deep neural network, trained on SynthFace, which achieves competitive performance on the NoW benchmark, without requiring 3D supervision or manual 3D asset creation.
FTFDNet: Learning to Detect Talking Face Video Manipulation with Tri-Modality Interaction
Jul 08, 2023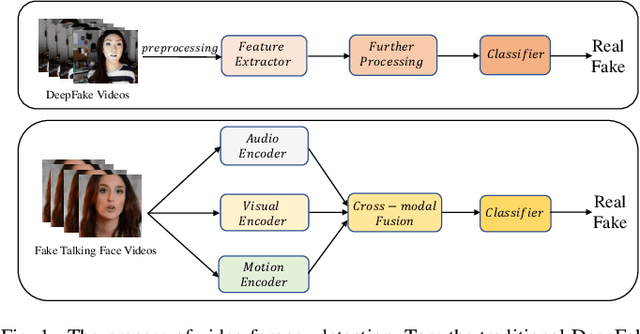
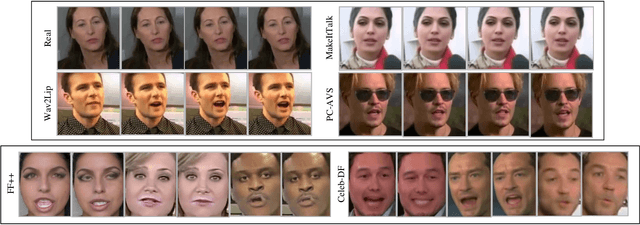

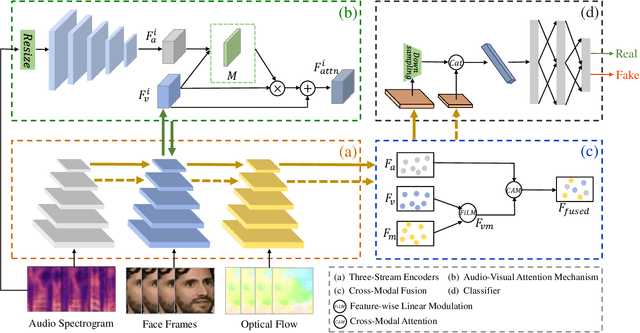
DeepFake based digital facial forgery is threatening public media security, especially when lip manipulation has been used in talking face generation, and the difficulty of fake video detection is further improved. By only changing lip shape to match the given speech, the facial features of identity are hard to be discriminated in such fake talking face videos. Together with the lack of attention on audio stream as the prior knowledge, the detection failure of fake talking face videos also becomes inevitable. It's found that the optical flow of the fake talking face video is disordered especially in the lip region while the optical flow of the real video changes regularly, which means the motion feature from optical flow is useful to capture manipulation cues. In this study, a fake talking face detection network (FTFDNet) is proposed by incorporating visual, audio and motion features using an efficient cross-modal fusion (CMF) module. Furthermore, a novel audio-visual attention mechanism (AVAM) is proposed to discover more informative features, which can be seamlessly integrated into any audio-visual CNN architecture by modularization. With the additional AVAM, the proposed FTFDNet is able to achieve a better detection performance than other state-of-the-art DeepFake video detection methods not only on the established fake talking face detection dataset (FTFDD) but also on the DeepFake video detection datasets (DFDC and DF-TIMIT).