 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Improving 2D face recognition via fine-level facial depth generation and RGB-D complementary feature learning
May 08, 2023
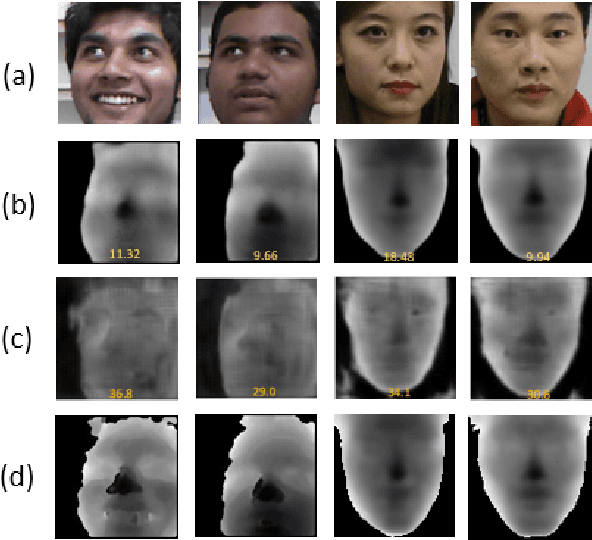

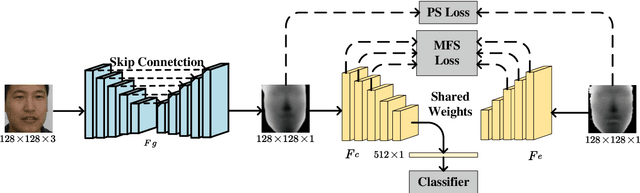

Face recognition in complex scenes suffers severe challenges coming from perturbations such as pose deformation, ill illumination, partial occlusion. Some methods utilize depth estimation to obtain depth corresponding to RGB to improve the accuracy of face recognition. However, the depth generated by them suffer from image blur, which introduces noise in subsequent RGB-D face recognition tasks. In addition, existing RGB-D face recognition methods are unable to fully extract complementary features. In this paper, we propose a fine-grained facial depth generation network and an improved multimodal complementary feature learning network. Extensive experiments on the Lock3DFace dataset and the IIIT-D dataset show that the proposed FFDGNet and I MCFLNet can improve the accuracy of RGB-D face recognition while achieving the state-of-the-art performance.
Screening Autism Spectrum Disorder in childrens using Deep Learning Approach : Evaluating the classification model of YOLOv8 by comparing with other models
Jun 25, 2023
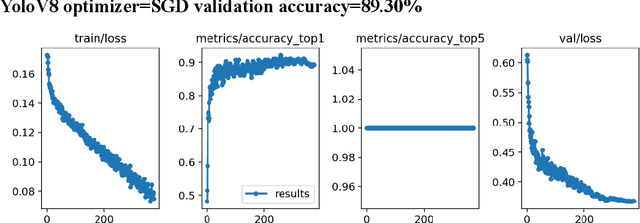
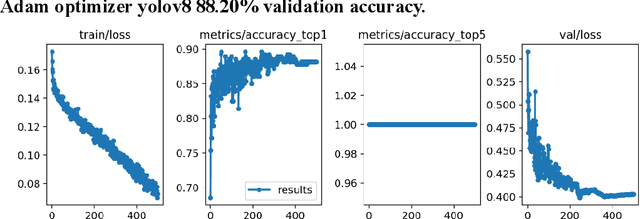
Autism spectrum disorder (ASD) is a developmental condition that presents significant challenges in social interaction, communication, and behavior. Early intervention plays a pivotal role in enhancing cognitive abilities and reducing autistic symptoms in children with ASD. Numerous clinical studies have highlighted distinctive facial characteristics that distinguish ASD children from typically developing (TD) children. In this study, we propose a practical solution for ASD screening using facial images using YoloV8 model. By employing YoloV8, a deep learning technique, on a dataset of Kaggle, we achieved exceptional results. Our model achieved a remarkable 89.64% accuracy in classification and an F1-score of 0.89. Our findings provide support for the clinical observations regarding facial feature discrepancies between children with ASD. The high F1-score obtained demonstrates the potential of deep learning models in screening children with ASD. We conclude that the newest version of YoloV8 which is usually used for object detection can be used for classification problem of Austistic and Non-autistic images.
Generation of artificial facial drug abuse images using Deep De-identified anonymous Dataset augmentation through Genetics Algorithm (3DG-GA)
Apr 12, 2023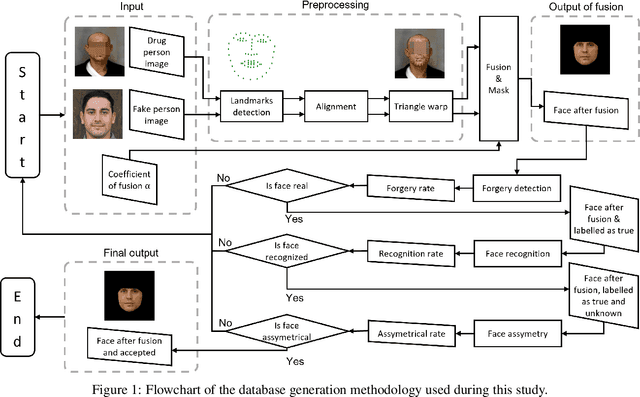


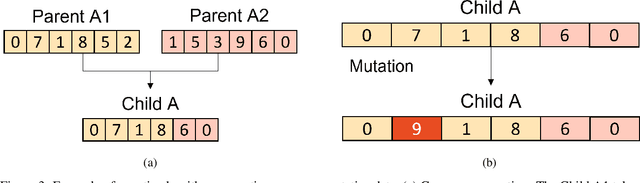
In biomedical research and artificial intelligence, access to large, well-balanced, and representative datasets is crucial for developing trustworthy applications that can be used in real-world scenarios. However, obtaining such datasets can be challenging, as they are often restricted to hospitals and specialized facilities. To address this issue, the study proposes to generate highly realistic synthetic faces exhibiting drug abuse traits through augmentation. The proposed method, called "3DG-GA", Deep De-identified anonymous Dataset Generation, uses Genetics Algorithm as a strategy for synthetic faces generation. The algorithm includes GAN artificial face generation, forgery detection, and face recognition. Initially, a dataset of 120 images of actual facial drug abuse is used. By preserving, the drug traits, the 3DG-GA provides a dataset containing 3000 synthetic facial drug abuse images. The dataset will be open to the scientific community, which can reproduce our results and benefit from the generated datasets while avoiding legal or ethical restrictions.
DIFAI: Diverse Facial Inpainting using StyleGAN Inversion
Jan 20, 2023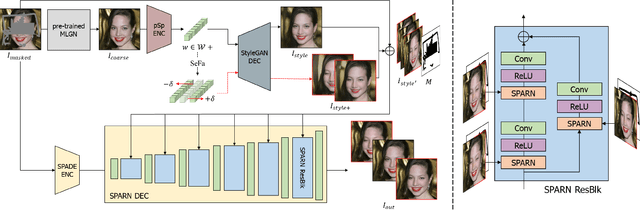
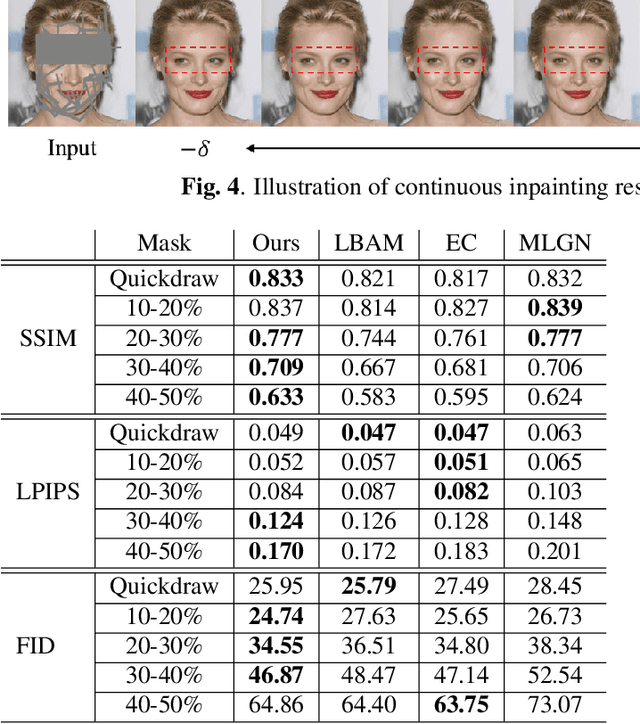

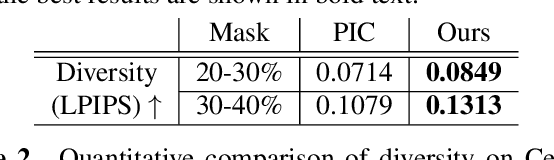
Image inpainting is an old problem in computer vision that restores occluded regions and completes damaged images. In the case of facial image inpainting, most of the methods generate only one result for each masked image, even though there are other reasonable possibilities. To prevent any potential biases and unnatural constraints stemming from generating only one image, we propose a novel framework for diverse facial inpainting exploiting the embedding space of StyleGAN. Our framework employs pSp encoder and SeFa algorithm to identify semantic components of the StyleGAN embeddings and feed them into our proposed SPARN decoder that adopts region normalization for plausible inpainting. We demonstrate that our proposed method outperforms several state-of-the-art methods.
Identity-Aware Semi-Supervised Learning for Comic Character Re-Identification
Aug 17, 2023
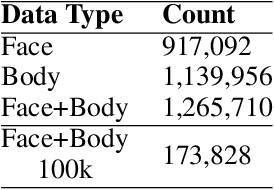
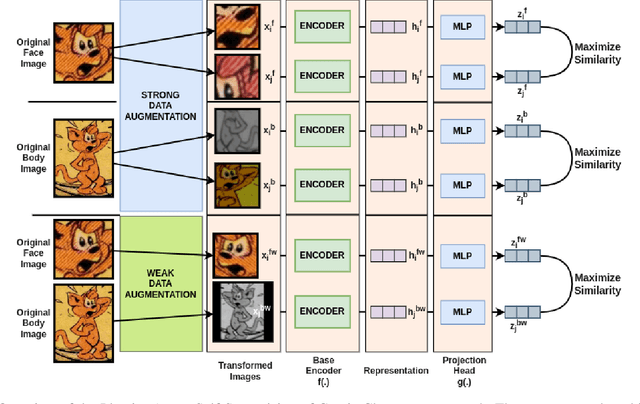

Character re-identification, recognizing characters consistently across different panels in comics, presents significant challenges due to limited annotated data and complex variations in character appearances. To tackle this issue, we introduce a robust semi-supervised framework that combines metric learning with a novel 'Identity-Aware' self-supervision method by contrastive learning of face and body pairs of characters. Our approach involves processing both facial and bodily features within a unified network architecture, facilitating the extraction of identity-aligned character embeddings that capture individual identities while preserving the effectiveness of face and body features. This integrated character representation enhances feature extraction and improves character re-identification compared to re-identification by face or body independently, offering a parameter-efficient solution. By extensively validating our method using in-series and inter-series evaluation metrics, we demonstrate its effectiveness in consistently re-identifying comic characters. Compared to existing methods, our approach not only addresses the challenge of character re-identification but also serves as a foundation for downstream tasks since it can produce character embeddings without restrictions of face and body availability, enriching the comprehension of comic books. In our experiments, we leverage two newly curated datasets: the 'Comic Character Instances Dataset', comprising over a million character instances and the 'Comic Sequence Identity Dataset', containing annotations of identities within more than 3000 sets of four consecutive comic panels that we collected.
Self-supervised Facial Action Unit Detection with Region and Relation Learning
Mar 10, 2023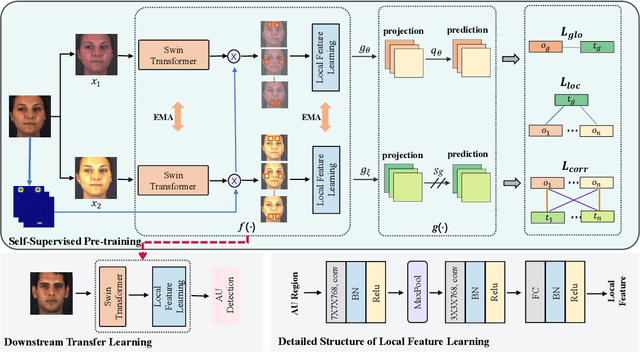
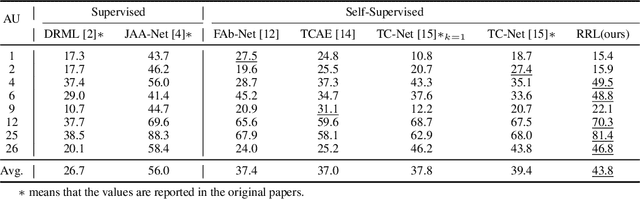
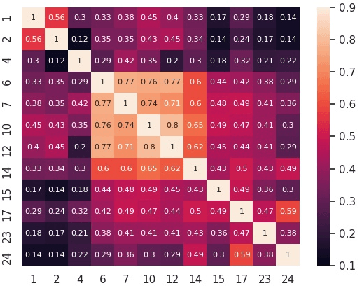
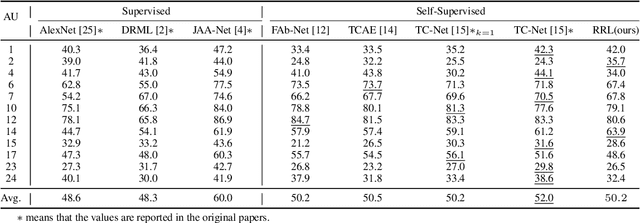
Facial action unit (AU) detection is a challenging task due to the scarcity of manual annotations. Recent works on AU detection with self-supervised learning have emerged to address this problem, aiming to learn meaningful AU representations from numerous unlabeled data. However, most existing AU detection works with self-supervised learning utilize global facial features only, while AU-related properties such as locality and relevance are not fully explored. In this paper, we propose a novel self-supervised framework for AU detection with the region and relation learning. In particular, AU related attention map is utilized to guide the model to focus more on AU-specific regions to enhance the integrity of AU local features. Meanwhile, an improved Optimal Transport (OT) algorithm is introduced to exploit the correlation characteristics among AUs. In addition, Swin Transformer is exploited to model the long-distance dependencies within each AU region during feature learning. The evaluation results on BP4D and DISFA demonstrate that our proposed method is comparable or even superior to the state-of-the-art self-supervised learning methods and supervised AU detection methods.
Automated Deception Detection from Videos: Using End-to-End Learning Based High-Level Features and Classification Approaches
Jul 13, 2023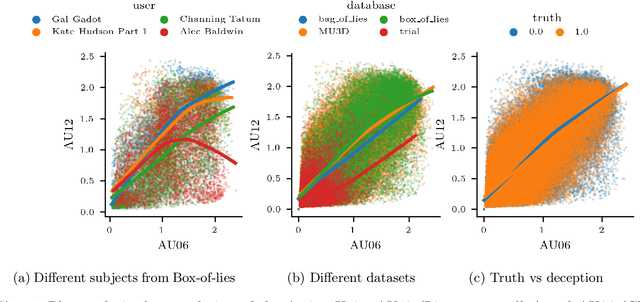
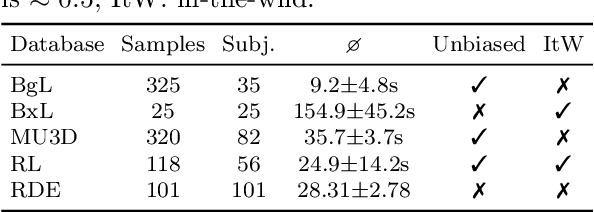
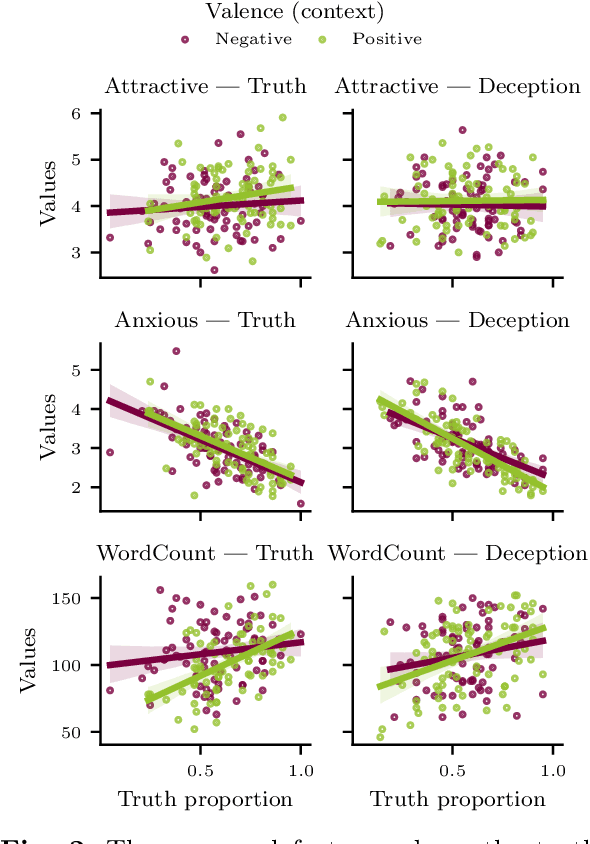
Deception detection is an interdisciplinary field attracting researchers from psychology, criminology, computer science, and economics. We propose a multimodal approach combining deep learning and discriminative models for automated deception detection. Using video modalities, we employ convolutional end-to-end learning to analyze gaze, head pose, and facial expressions, achieving promising results compared to state-of-the-art methods. Due to limited training data, we also utilize discriminative models for deception detection. Although sequence-to-class approaches are explored, discriminative models outperform them due to data scarcity. Our approach is evaluated on five datasets, including a new Rolling-Dice Experiment motivated by economic factors. Results indicate that facial expressions outperform gaze and head pose, and combining modalities with feature selection enhances detection performance. Differences in expressed features across datasets emphasize the importance of scenario-specific training data and the influence of context on deceptive behavior. Cross-dataset experiments reinforce these findings. Despite the challenges posed by low-stake datasets, including the Rolling-Dice Experiment, deception detection performance exceeds chance levels. Our proposed multimodal approach and comprehensive evaluation shed light on the potential of automating deception detection from video modalities, opening avenues for future research.
RIGID: Recurrent GAN Inversion and Editing of Real Face Videos
Aug 15, 2023
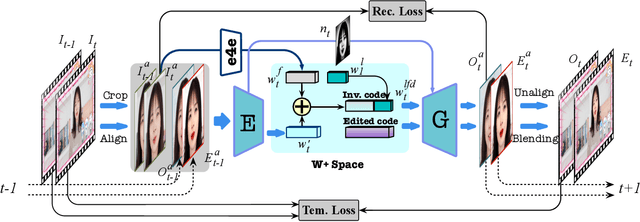
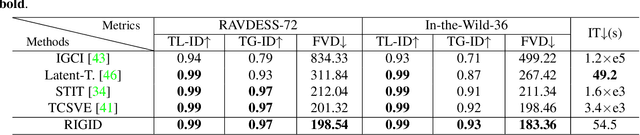
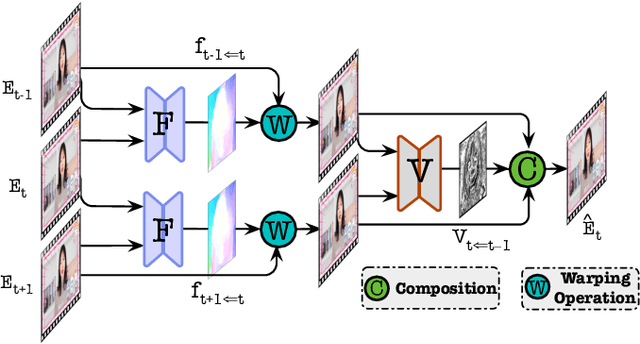
GAN inversion is indispensable for applying the powerful editability of GAN to real images. However, existing methods invert video frames individually often leading to undesired inconsistent results over time. In this paper, we propose a unified recurrent framework, named \textbf{R}ecurrent v\textbf{I}deo \textbf{G}AN \textbf{I}nversion and e\textbf{D}iting (RIGID), to explicitly and simultaneously enforce temporally coherent GAN inversion and facial editing of real videos. Our approach models the temporal relations between current and previous frames from three aspects. To enable a faithful real video reconstruction, we first maximize the inversion fidelity and consistency by learning a temporal compensated latent code. Second, we observe incoherent noises lie in the high-frequency domain that can be disentangled from the latent space. Third, to remove the inconsistency after attribute manipulation, we propose an \textit{in-between frame composition constraint} such that the arbitrary frame must be a direct composite of its neighboring frames. Our unified framework learns the inherent coherence between input frames in an end-to-end manner, and therefore it is agnostic to a specific attribute and can be applied to arbitrary editing of the same video without re-training. Extensive experiments demonstrate that RIGID outperforms state-of-the-art methods qualitatively and quantitatively in both inversion and editing tasks. The deliverables can be found in \url{https://cnnlstm.github.io/RIGID}
Adv-Inpainting: Generating Natural and Transferable Adversarial Patch via Attention-guided Feature Fusion
Aug 10, 2023

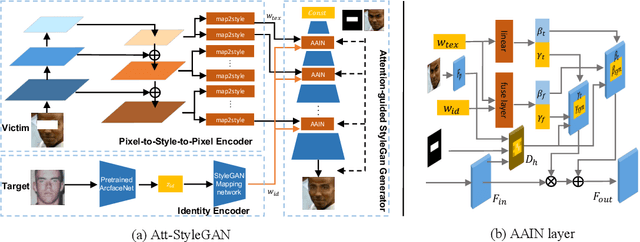
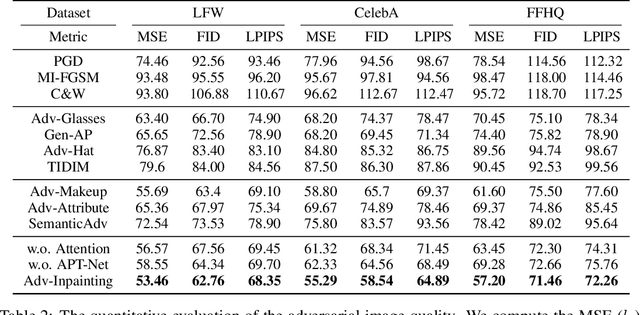
The rudimentary adversarial attacks utilize additive noise to attack facial recognition (FR) models. However, because manipulating the total face is impractical in the physical setting, most real-world FR attacks are based on adversarial patches, which limit perturbations to a small area. Previous adversarial patch attacks often resulted in unnatural patterns and clear boundaries that were easily noticeable. In this paper, we argue that generating adversarial patches with plausible content can result in stronger transferability than using additive noise or directly sampling from the latent space. To generate natural-looking and highly transferable adversarial patches, we propose an innovative two-stage coarse-to-fine attack framework called Adv-Inpainting. In the first stage, we propose an attention-guided StyleGAN (Att-StyleGAN) that adaptively combines texture and identity features based on the attention map to generate high-transferable and natural adversarial patches. In the second stage, we design a refinement network with a new boundary variance loss to further improve the coherence between the patch and its surrounding area. Experiment results demonstrate that Adv-Inpainting is stealthy and can produce adversarial patches with stronger transferability and improved visual quality than previous adversarial patch attacks.
Neural Point-based Volumetric Avatar: Surface-guided Neural Points for Efficient and Photorealistic Volumetric Head Avatar
Jul 11, 2023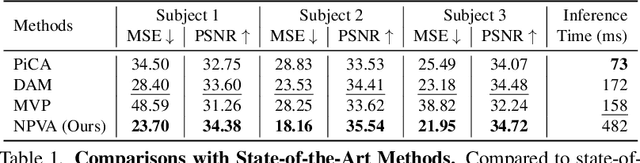
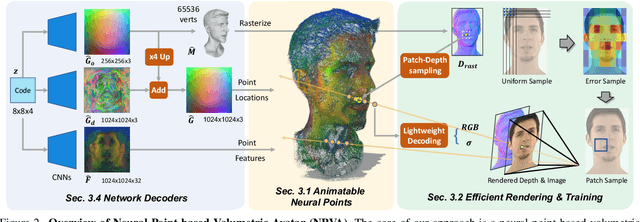
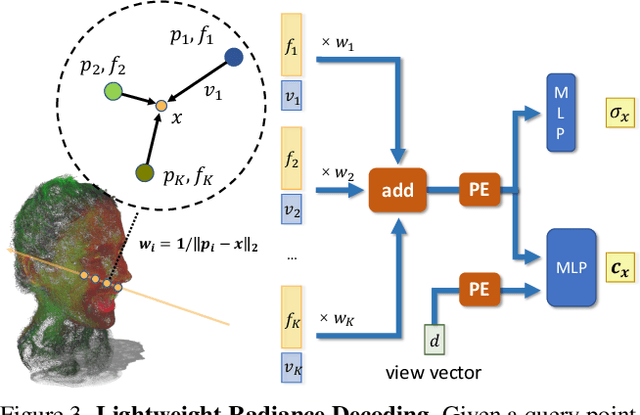
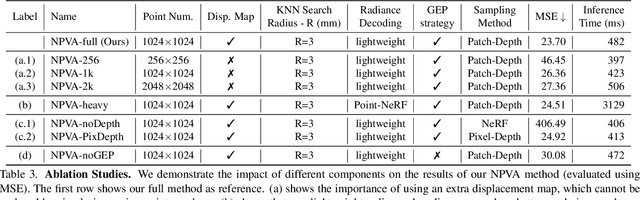
Rendering photorealistic and dynamically moving human heads is crucial for ensuring a pleasant and immersive experience in AR/VR and video conferencing applications. However, existing methods often struggle to model challenging facial regions (e.g., mouth interior, eyes, hair/beard), resulting in unrealistic and blurry results. In this paper, we propose {\fullname} ({\name}), a method that adopts the neural point representation as well as the neural volume rendering process and discards the predefined connectivity and hard correspondence imposed by mesh-based approaches. Specifically, the neural points are strategically constrained around the surface of the target expression via a high-resolution UV displacement map, achieving increased modeling capacity and more accurate control. We introduce three technical innovations to improve the rendering and training efficiency: a patch-wise depth-guided (shading point) sampling strategy, a lightweight radiance decoding process, and a Grid-Error-Patch (GEP) ray sampling strategy during training. By design, our {\name} is better equipped to handle topologically changing regions and thin structures while also ensuring accurate expression control when animating avatars. Experiments conducted on three subjects from the Multiface dataset demonstrate the effectiveness of our designs, outperforming previous state-of-the-art methods, especially in handling challenging facial regions.