 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
The Robot in the Room: Influence of Robot Facial Expressions and Gaze on Human-Human-Robot Collaboration
Mar 24, 2023

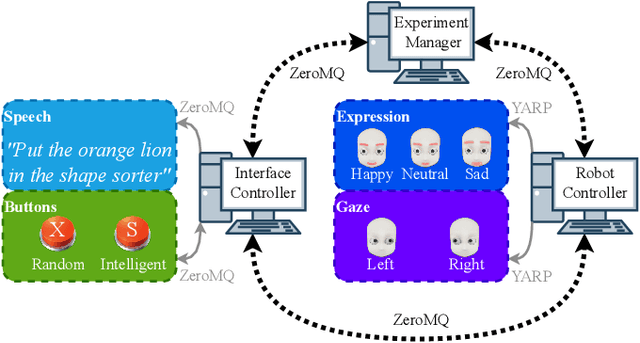
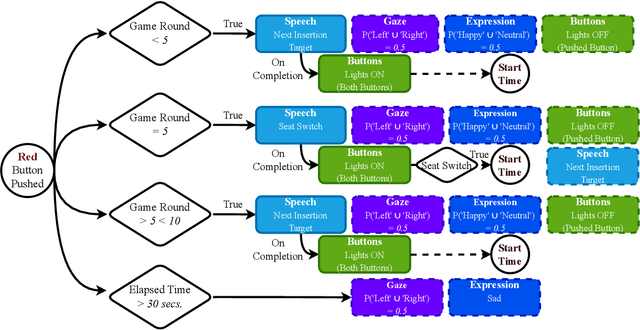
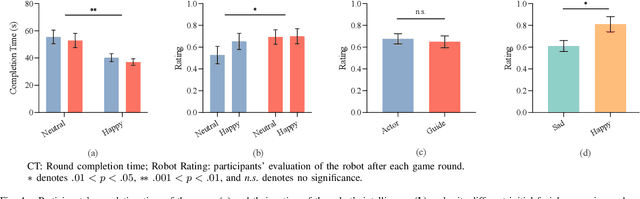
Robot facial expressions and gaze are important factors for enhancing human-robot interaction (HRI), but their effects on human collaboration and perception are not well understood, for instance, in collaborative game scenarios. In this study, we designed a collaborative triadic HRI game scenario, where two participants worked together to insert objects into a shape sorter. One participant assumed the role of a guide. The guide instructed the other participant, who played the role of an actor, by placing occluded objects into the sorter. A humanoid robot issued instructions, observed the interaction, and displayed social cues to elicit changes in the two participants' behavior. We measured human collaboration as a function of task completion time and the participants' perceptions of the robot by rating its behavior as intelligent or random. Participants also evaluated the robot by filling out the Godspeed questionnaire. We found that human collaboration was higher when the robot displayed a happy facial expression at the beginning of the game compared to a neutral facial expression. We also found that participants perceived the robot as more intelligent when it displayed a positive facial expression at the end of the game. The robot's behavior was also perceived as intelligent when directing its gaze toward the guide at the beginning of the interaction, not the actor. These findings provide insights into how robot facial expressions and gaze influence human behavior and perception in collaboration.
Comparative Analysis of Deep-Fake Algorithms
Sep 06, 2023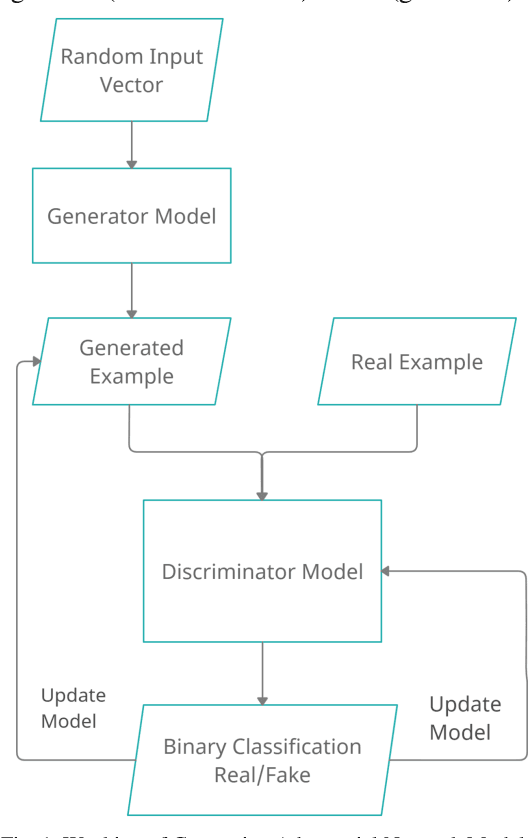
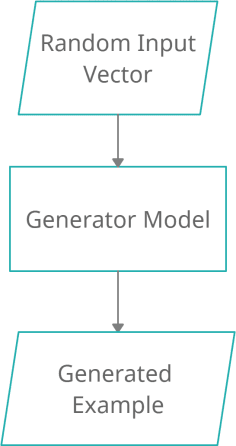
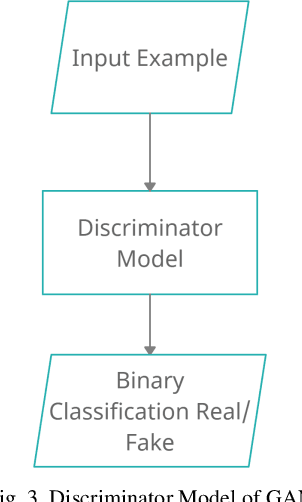
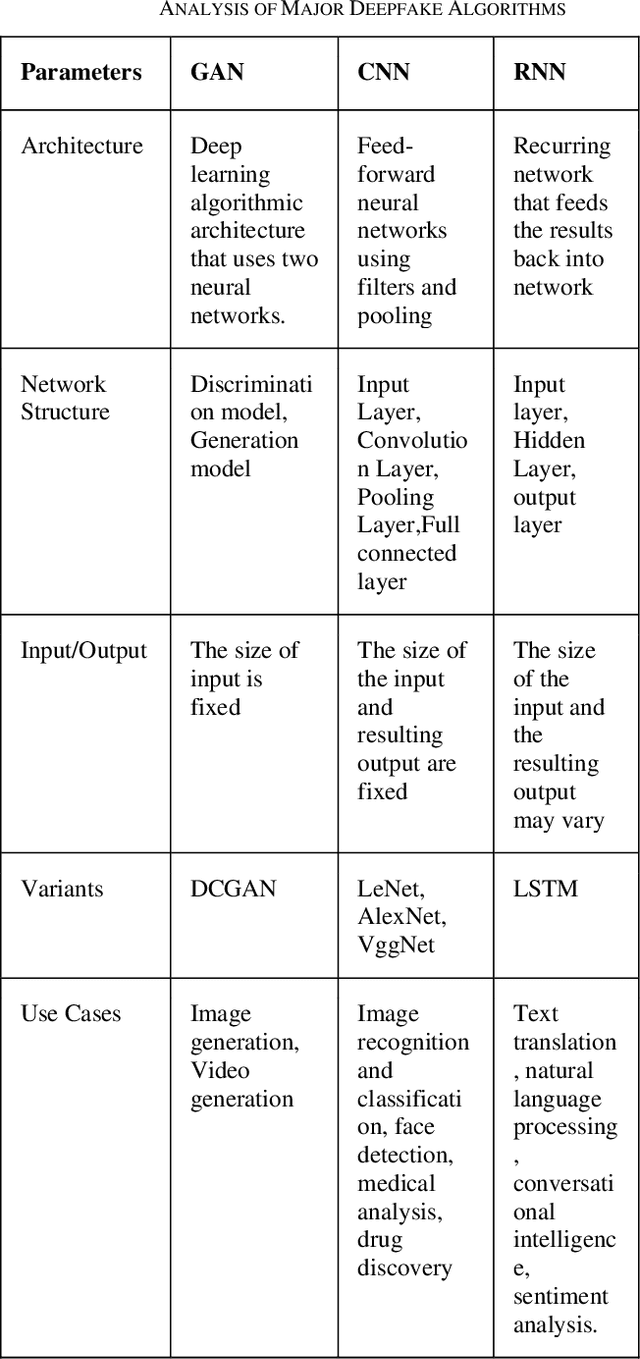
Due to the widespread use of smartphones with high-quality digital cameras and easy access to a wide range of software apps for recording, editing, and sharing videos and images, as well as the deep learning AI platforms, a new phenomenon of 'faking' videos has emerged. Deepfake algorithms can create fake images and videos that are virtually indistinguishable from authentic ones. Therefore, technologies that can detect and assess the integrity of digital visual media are crucial. Deepfakes, also known as deep learning-based fake videos, have become a major concern in recent years due to their ability to manipulate and alter images and videos in a way that is virtually indistinguishable from the original. These deepfake videos can be used for malicious purposes such as spreading misinformation, impersonating individuals, and creating fake news. Deepfake detection technologies use various approaches such as facial recognition, motion analysis, and audio-visual synchronization to identify and flag fake videos. However, the rapid advancement of deepfake technologies has made it increasingly difficult to detect these videos with high accuracy. In this paper, we aim to provide a comprehensive review of the current state of deepfake creation and detection technologies. We examine the various deep learning-based approaches used for creating deepfakes, as well as the techniques used for detecting them. Additionally, we analyze the limitations and challenges of current deepfake detection methods and discuss future research directions in this field. Overall, the paper highlights the importance of continued research and development in deepfake detection technologies in order to combat the negative impact of deepfakes on society and ensure the integrity of digital visual media.
* 7 pages, 4 figures, 2 tables, Published with International Journal of Computer Science Trends and Technology (IJCST)
Reinforced Disentanglement for Face Swapping without Skip Connection
Jul 19, 2023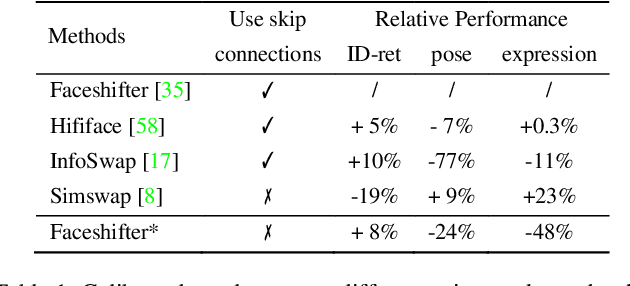
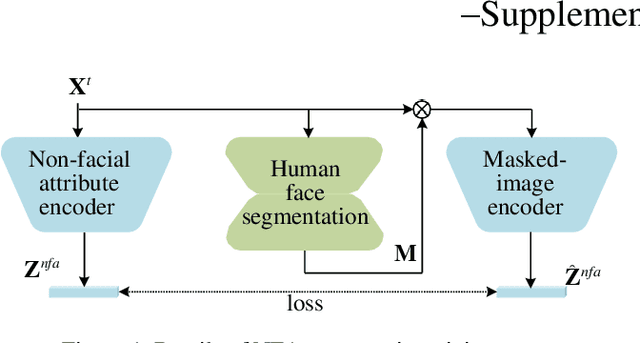
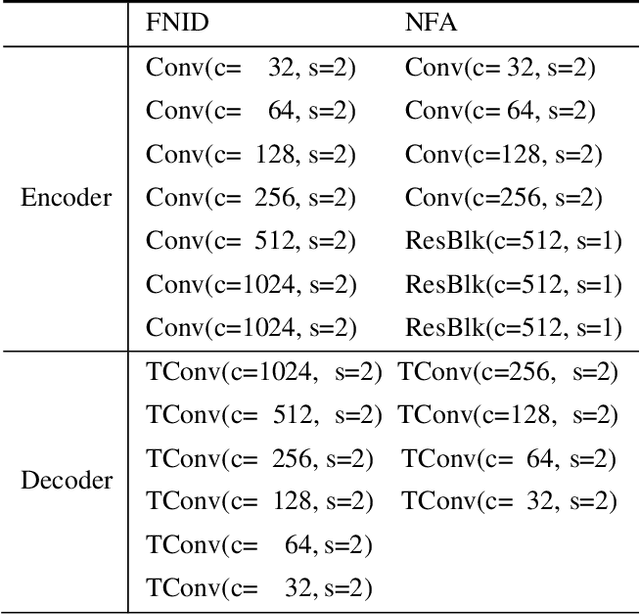

The SOTA face swap models still suffer the problem of either target identity (i.e., shape) being leaked or the target non-identity attributes (i.e., background, hair) failing to be fully preserved in the final results. We show that this insufficient disentanglement is caused by two flawed designs that were commonly adopted in prior models: (1) counting on only one compressed encoder to represent both the semantic-level non-identity facial attributes(i.e., pose) and the pixel-level non-facial region details, which is contradictory to satisfy at the same time; (2) highly relying on long skip-connections between the encoder and the final generator, leaking a certain amount of target face identity into the result. To fix them, we introduce a new face swap framework called 'WSC-swap' that gets rid of skip connections and uses two target encoders to respectively capture the pixel-level non-facial region attributes and the semantic non-identity attributes in the face region. To further reinforce the disentanglement learning for the target encoder, we employ both identity removal loss via adversarial training (i.e., GAN) and the non-identity preservation loss via prior 3DMM models like [11]. Extensive experiments on both FaceForensics++ and CelebA-HQ show that our results significantly outperform previous works on a rich set of metrics, including one novel metric for measuring identity consistency that was completely neglected before.
Facial Emotion Recognition
Jan 26, 2023
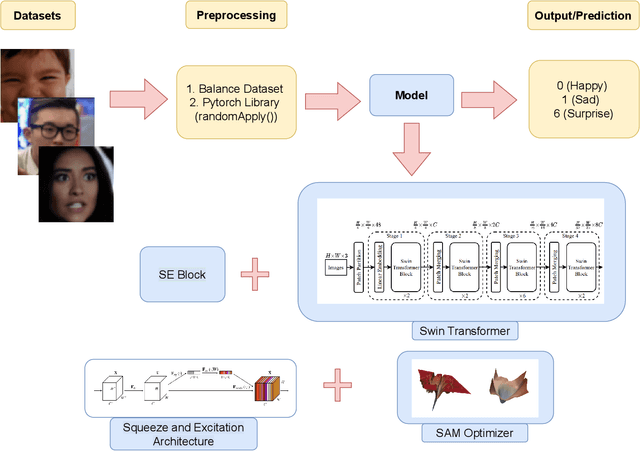
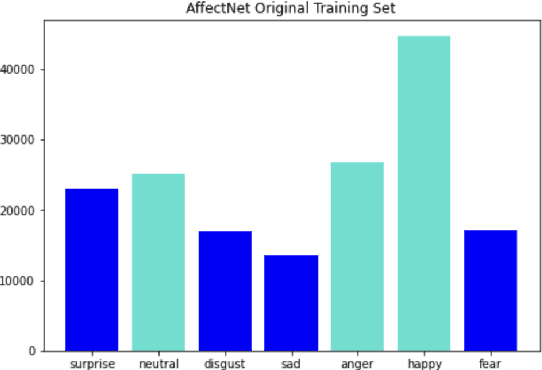
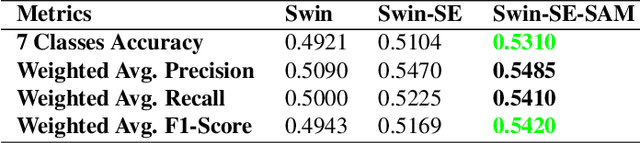
We present a facial emotion recognition framework, built upon Swin vision Transformers jointly with squeeze and excitation block (SE). A transformer model based on an attention mechanism has been presented recently to address vision tasks. Our method uses a vision transformer with a Squeeze excitation block (SE) and sharpness-aware minimizer (SAM). We have used a hybrid dataset, to train our model and the AffectNet dataset to evaluate the result of our model
HyperReenact: One-Shot Reenactment via Jointly Learning to Refine and Retarget Faces
Jul 20, 2023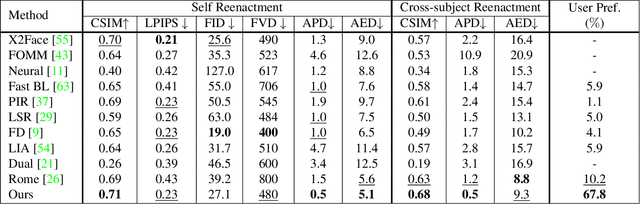
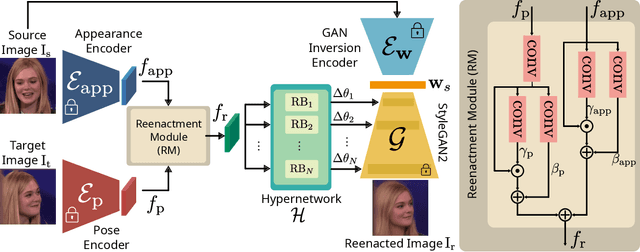
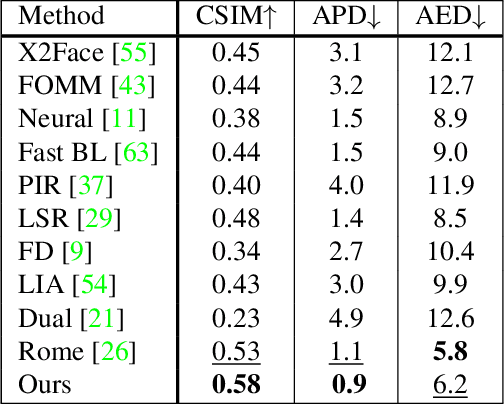

In this paper, we present our method for neural face reenactment, called HyperReenact, that aims to generate realistic talking head images of a source identity, driven by a target facial pose. Existing state-of-the-art face reenactment methods train controllable generative models that learn to synthesize realistic facial images, yet producing reenacted faces that are prone to significant visual artifacts, especially under the challenging condition of extreme head pose changes, or requiring expensive few-shot fine-tuning to better preserve the source identity characteristics. We propose to address these limitations by leveraging the photorealistic generation ability and the disentangled properties of a pretrained StyleGAN2 generator, by first inverting the real images into its latent space and then using a hypernetwork to perform: (i) refinement of the source identity characteristics and (ii) facial pose re-targeting, eliminating this way the dependence on external editing methods that typically produce artifacts. Our method operates under the one-shot setting (i.e., using a single source frame) and allows for cross-subject reenactment, without requiring any subject-specific fine-tuning. We compare our method both quantitatively and qualitatively against several state-of-the-art techniques on the standard benchmarks of VoxCeleb1 and VoxCeleb2, demonstrating the superiority of our approach in producing artifact-free images, exhibiting remarkable robustness even under extreme head pose changes. We make the code and the pretrained models publicly available at: https://github.com/StelaBou/HyperReenact .
Rethinking Voice-Face Correlation: A Geometry View
Jul 26, 2023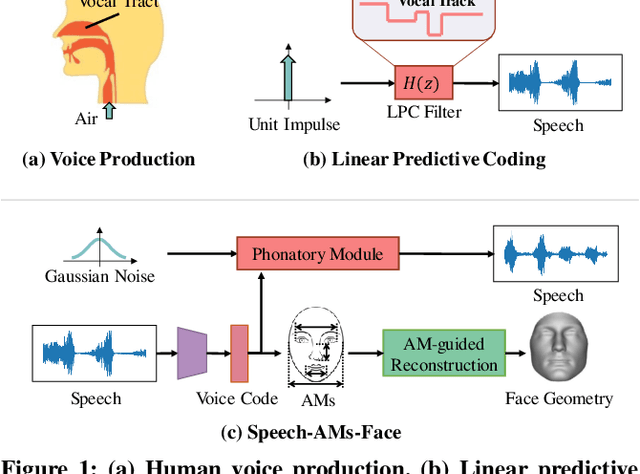

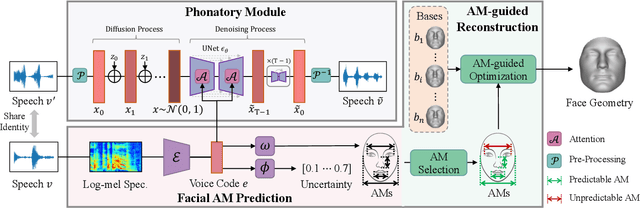

Previous works on voice-face matching and voice-guided face synthesis demonstrate strong correlations between voice and face, but mainly rely on coarse semantic cues such as gender, age, and emotion. In this paper, we aim to investigate the capability of reconstructing the 3D facial shape from voice from a geometry perspective without any semantic information. We propose a voice-anthropometric measurement (AM)-face paradigm, which identifies predictable facial AMs from the voice and uses them to guide 3D face reconstruction. By leveraging AMs as a proxy to link the voice and face geometry, we can eliminate the influence of unpredictable AMs and make the face geometry tractable. Our approach is evaluated on our proposed dataset with ground-truth 3D face scans and corresponding voice recordings, and we find significant correlations between voice and specific parts of the face geometry, such as the nasal cavity and cranium. Our work offers a new perspective on voice-face correlation and can serve as a good empirical study for anthropometry science.
Multi-modal Facial Action Unit Detection with Large Pre-trained Models for the 5th Competition on Affective Behavior Analysis in-the-wild
Mar 23, 2023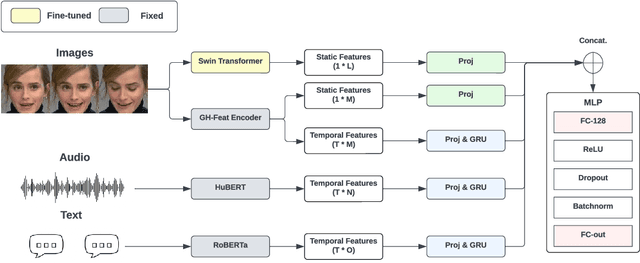


Facial action unit detection has emerged as an important task within facial expression analysis, aimed at detecting specific pre-defined, objective facial expressions, such as lip tightening and cheek raising. This paper presents our submission to the Affective Behavior Analysis in-the-wild (ABAW) 2023 Competition for AU detection. We propose a multi-modal method for facial action unit detection with visual, acoustic, and lexical features extracted from the large pre-trained models. To provide high-quality details for visual feature extraction, we apply super-resolution and face alignment to the training data and show potential performance gain. Our approach achieves the F1 score of 52.3% on the official validation set of the 5th ABAW Challenge.
WEARS: Wearable Emotion AI with Real-time Sensor data
Aug 22, 2023Emotion prediction is the field of study to understand human emotions. Existing methods focus on modalities like text, audio, facial expressions, etc., which could be private to the user. Emotion can be derived from the subject's psychological data as well. Various approaches that employ combinations of physiological sensors for emotion recognition have been proposed. Yet, not all sensors are simple to use and handy for individuals in their daily lives. Thus, we propose a system to predict user emotion using smartwatch sensors. We design a framework to collect ground truth in real-time utilizing a mix of English and regional language-based videos to invoke emotions in participants and collect the data. Further, we modeled the problem as binary classification due to the limited dataset size and experimented with multiple machine-learning models. We also did an ablation study to understand the impact of features including Heart Rate, Accelerometer, and Gyroscope sensor data on mood. From the experimental results, Multi-Layer Perceptron has shown a maximum accuracy of 93.75 percent for pleasant-unpleasant (high/low valence classification) moods.
SRMAE: Masked Image Modeling for Scale-Invariant Deep Representations
Aug 17, 2023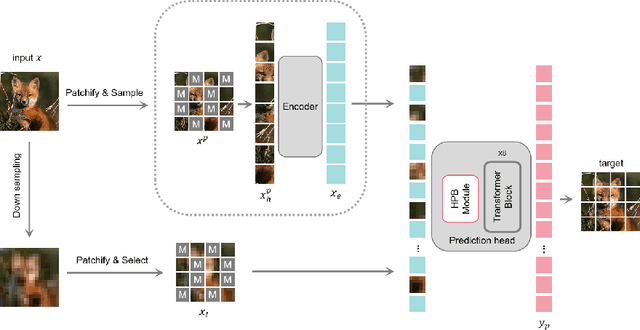


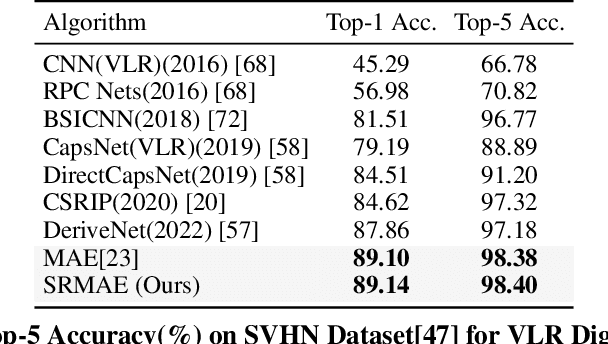
Due to the prevalence of scale variance in nature images, we propose to use image scale as a self-supervised signal for Masked Image Modeling (MIM). Our method involves selecting random patches from the input image and downsampling them to a low-resolution format. Our framework utilizes the latest advances in super-resolution (SR) to design the prediction head, which reconstructs the input from low-resolution clues and other patches. After 400 epochs of pre-training, our Super Resolution Masked Autoencoders (SRMAE) get an accuracy of 82.1% on the ImageNet-1K task. Image scale signal also allows our SRMAE to capture scale invariance representation. For the very low resolution (VLR) recognition task, our model achieves the best performance, surpassing DeriveNet by 1.3%. Our method also achieves an accuracy of 74.84% on the task of recognizing low-resolution facial expressions, surpassing the current state-of-the-art FMD by 9.48%.
VR Facial Animation for Immersive Telepresence Avatars
Apr 24, 2023

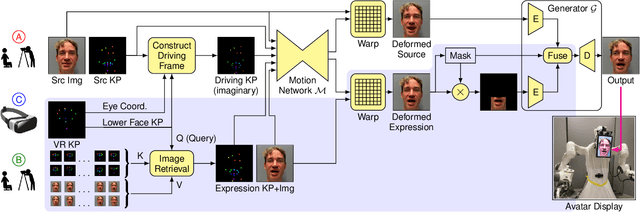
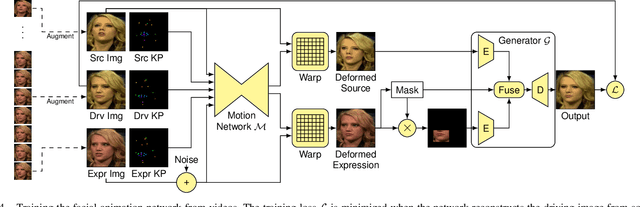
VR Facial Animation is necessary in applications requiring clear view of the face, even though a VR headset is worn. In our case, we aim to animate the face of an operator who is controlling our robotic avatar system. We propose a real-time capable pipeline with very fast adaptation for specific operators. In a quick enrollment step, we capture a sequence of source images from the operator without the VR headset which contain all the important operator-specific appearance information. During inference, we then use the operator keypoint information extracted from a mouth camera and two eye cameras to estimate the target expression and head pose, to which we map the appearance of a source still image. In order to enhance the mouth expression accuracy, we dynamically select an auxiliary expression frame from the captured sequence. This selection is done by learning to transform the current mouth keypoints into the source camera space, where the alignment can be determined accurately. We, furthermore, demonstrate an eye tracking pipeline that can be trained in less than a minute, a time efficient way to train the whole pipeline given a dataset that includes only complete faces, show exemplary results generated by our method, and discuss performance at the ANA Avatar XPRIZE semifinals.