 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Logical Consistency and Greater Descriptive Power for Facial Hair Attribute Learning
Feb 22, 2023
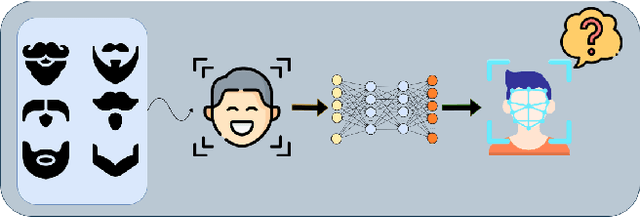
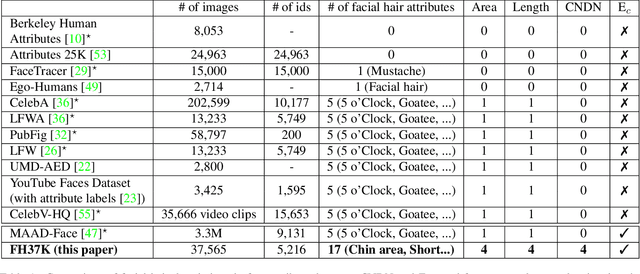

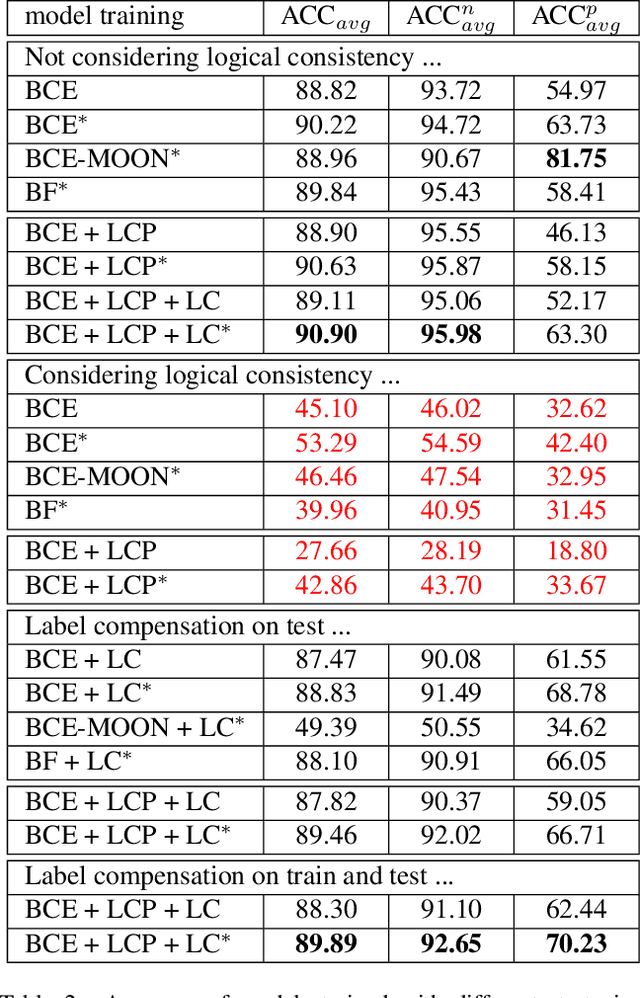
Face attribute research has so far used only simple binary attributes for facial hair; e.g., beard / no beard. We have created a new, more descriptive facial hair annotation scheme and applied it to create a new facial hair attribute dataset, FH37K. Face attribute research also so far has not dealt with logical consistency and completeness. For example, in prior research, an image might be classified as both having no beard and also having a goatee (a type of beard). We show that the test accuracy of previous classification methods on facial hair attribute classification drops significantly if logical consistency of classifications is enforced. We propose a logically consistent prediction loss, LCPLoss, to aid learning of logical consistency across attributes, and also a label compensation training strategy to eliminate the problem of no positive prediction across a set of related attributes. Using an attribute classifier trained on FH37K, we investigate how facial hair affects face recognition accuracy, including variation across demographics. Results show that similarity and difference in facial hairstyle have important effects on the impostor and genuine score distributions in face recognition.
mEBAL2 Database and Benchmark: Image-based Multispectral Eyeblink Detection
Sep 14, 2023
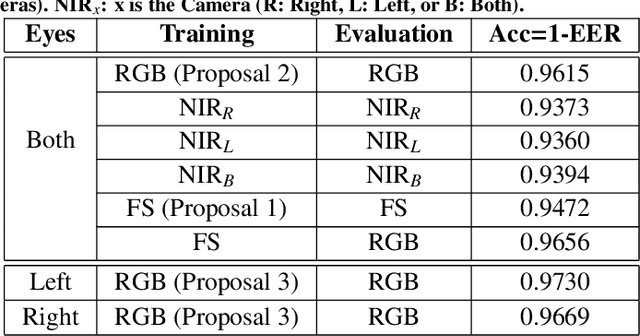
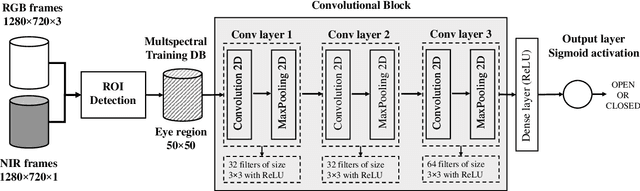
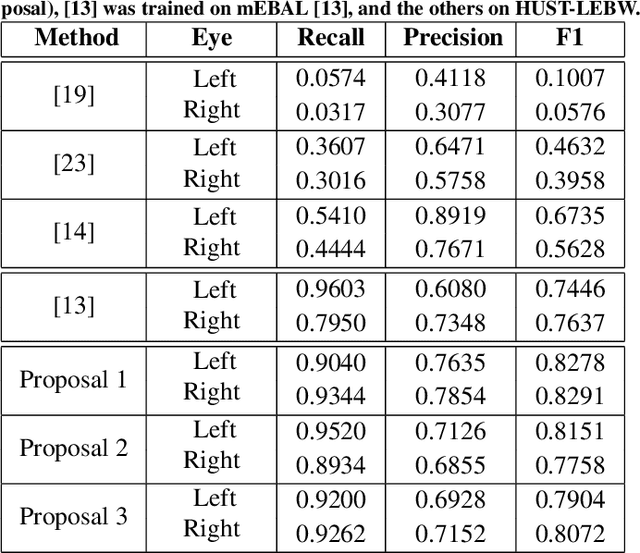
This work introduces a new multispectral database and novel approaches for eyeblink detection in RGB and Near-Infrared (NIR) individual images. Our contributed dataset (mEBAL2, multimodal Eye Blink and Attention Level estimation, Version 2) is the largest existing eyeblink database, representing a great opportunity to improve data-driven multispectral approaches for blink detection and related applications (e.g., attention level estimation and presentation attack detection in face biometrics). mEBAL2 includes 21,100 image sequences from 180 different students (more than 2 million labeled images in total) while conducting a number of e-learning tasks of varying difficulty or taking a real course on HTML initiation through the edX MOOC platform. mEBAL2 uses multiple sensors, including two Near-Infrared (NIR) and one RGB camera to capture facial gestures during the execution of the tasks, as well as an Electroencephalogram (EEG) band to get the cognitive activity of the user and blinking events. Furthermore, this work proposes a Convolutional Neural Network architecture as benchmark for blink detection on mEBAL2 with performances up to 97%. Different training methodologies are implemented using the RGB spectrum, NIR spectrum, and the combination of both to enhance the performance on existing eyeblink detectors. We demonstrate that combining NIR and RGB images during training improves the performance of RGB eyeblink detectors (i.e., detection based only on a RGB image). Finally, the generalization capacity of the proposed eyeblink detectors is validated in wilder and more challenging environments like the HUST-LEBW dataset to show the usefulness of mEBAL2 to train a new generation of data-driven approaches for eyeblink detection.
Dual-Path Temporal Map Optimization for Make-up Temporal Video Grounding
Sep 12, 2023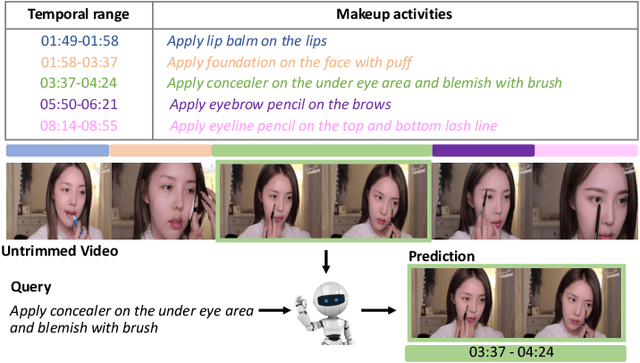
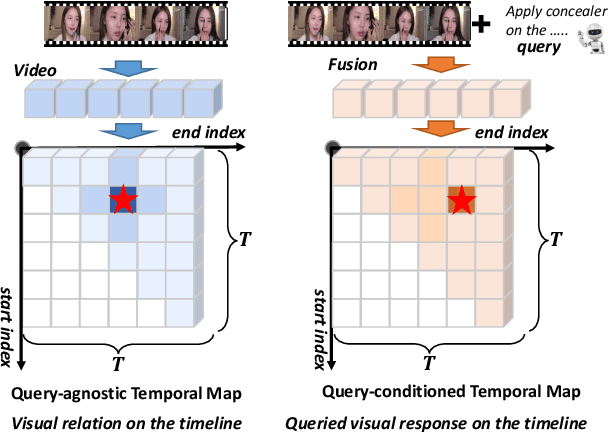
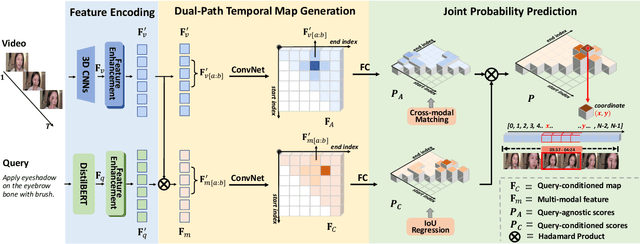
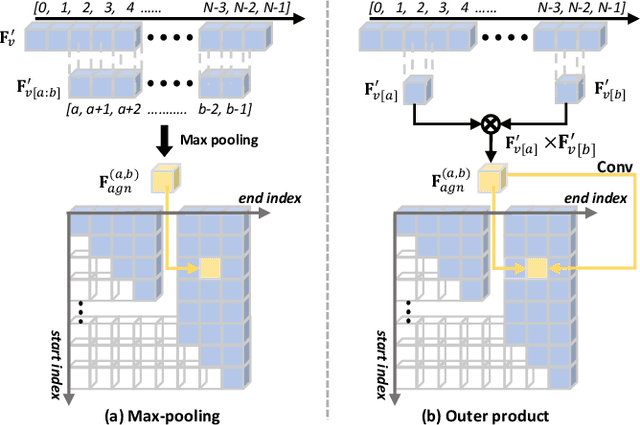
Make-up temporal video grounding (MTVG) aims to localize the target video segment which is semantically related to a sentence describing a make-up activity, given a long video. Compared with the general video grounding task, MTVG focuses on meticulous actions and changes on the face. The make-up instruction step, usually involving detailed differences in products and facial areas, is more fine-grained than general activities (e.g, cooking activity and furniture assembly). Thus, existing general approaches cannot locate the target activity effectually. More specifically, existing proposal generation modules are not yet fully developed in providing semantic cues for the more fine-grained make-up semantic comprehension. To tackle this issue, we propose an effective proposal-based framework named Dual-Path Temporal Map Optimization Network (DPTMO) to capture fine-grained multimodal semantic details of make-up activities. DPTMO extracts both query-agnostic and query-guided features to construct two proposal sets and uses specific evaluation methods for the two sets. Different from the commonly used single structure in previous methods, our dual-path structure can mine more semantic information in make-up videos and distinguish fine-grained actions well. These two candidate sets represent the cross-modal makeup video-text similarity and multi-modal fusion relationship, complementing each other. Each set corresponds to its respective optimization perspective, and their joint prediction enhances the accuracy of video timestamp prediction. Comprehensive experiments on the YouMakeup dataset demonstrate our proposed dual structure excels in fine-grained semantic comprehension.
Developing Social Robots with Empathetic Non-Verbal Cues Using Large Language Models
Aug 31, 2023We propose augmenting the empathetic capacities of social robots by integrating non-verbal cues. Our primary contribution is the design and labeling of four types of empathetic non-verbal cues, abbreviated as SAFE: Speech, Action (gesture), Facial expression, and Emotion, in a social robot. These cues are generated using a Large Language Model (LLM). We developed an LLM-based conversational system for the robot and assessed its alignment with social cues as defined by human counselors. Preliminary results show distinct patterns in the robot's responses, such as a preference for calm and positive social emotions like 'joy' and 'lively', and frequent nodding gestures. Despite these tendencies, our approach has led to the development of a social robot capable of context-aware and more authentic interactions. Our work lays the groundwork for future studies on human-robot interactions, emphasizing the essential role of both verbal and non-verbal cues in creating social and empathetic robots.
Text-Guided Generation and Editing of Compositional 3D Avatars
Sep 13, 2023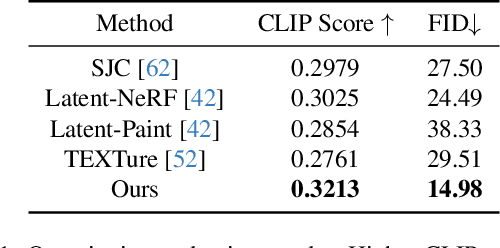
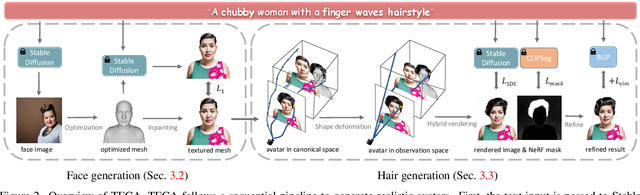
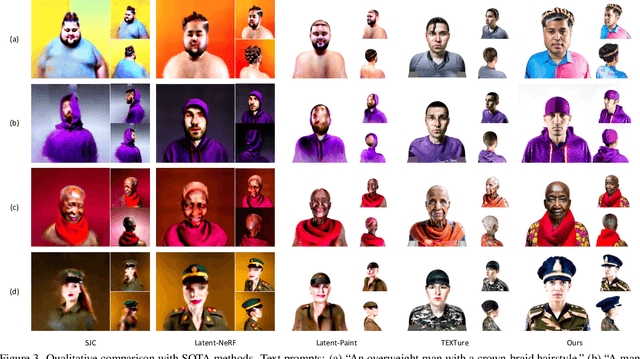
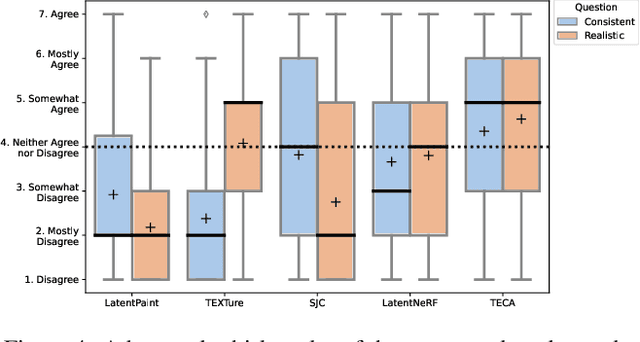
Our goal is to create a realistic 3D facial avatar with hair and accessories using only a text description. While this challenge has attracted significant recent interest, existing methods either lack realism, produce unrealistic shapes, or do not support editing, such as modifications to the hairstyle. We argue that existing methods are limited because they employ a monolithic modeling approach, using a single representation for the head, face, hair, and accessories. Our observation is that the hair and face, for example, have very different structural qualities that benefit from different representations. Building on this insight, we generate avatars with a compositional model, in which the head, face, and upper body are represented with traditional 3D meshes, and the hair, clothing, and accessories with neural radiance fields (NeRF). The model-based mesh representation provides a strong geometric prior for the face region, improving realism while enabling editing of the person's appearance. By using NeRFs to represent the remaining components, our method is able to model and synthesize parts with complex geometry and appearance, such as curly hair and fluffy scarves. Our novel system synthesizes these high-quality compositional avatars from text descriptions. The experimental results demonstrate that our method, Text-guided generation and Editing of Compositional Avatars (TECA), produces avatars that are more realistic than those of recent methods while being editable because of their compositional nature. For example, our TECA enables the seamless transfer of compositional features like hairstyles, scarves, and other accessories between avatars. This capability supports applications such as virtual try-on.
Non-invasive Diabetes Detection using Gabor Filter: A Comparative Analysis of Different Cameras
Jul 28, 2023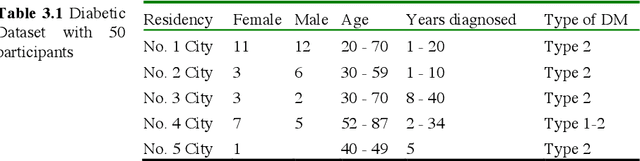

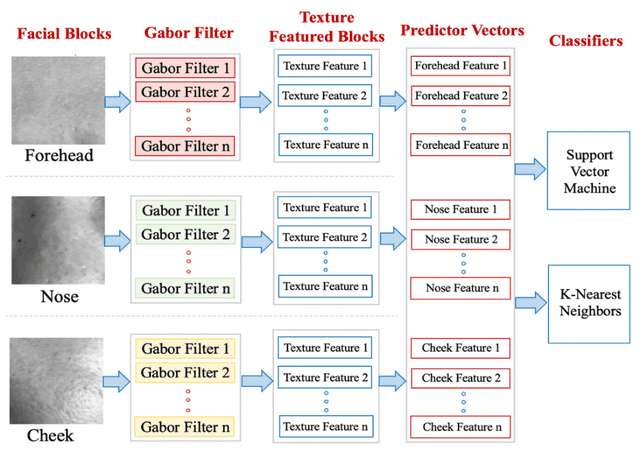
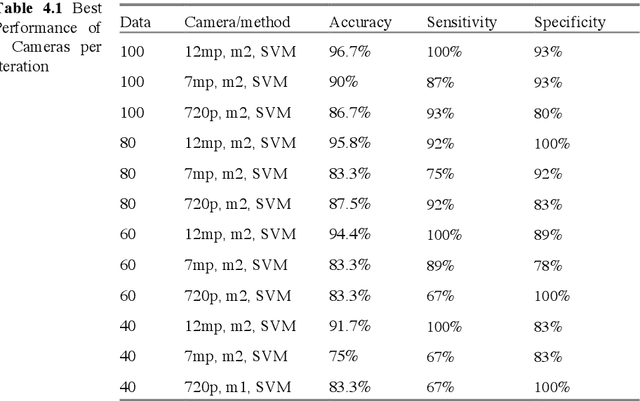
This paper compares and explores the performance of both mobile device camera and laptop camera as convenient tool for capturing images for non-invasive detection of Diabetes Mellitus (DM) using facial block texture features. Participants within age bracket 20 to 79 years old were chosen for the dataset. 12mp and 7mp mobile cameras, and a laptop camera were used to take the photo under normal lighting condition. Extracted facial blocks were classified using k-Nearest Neighbors (k-NN) and Support Vector Machine (SVM). 100 images were captured, preprocessed, filtered using Gabor, and iterated. Performance of the system was measured in terms of accuracy, specificity, and sensitivity. Best performance of 96.7% accuracy, 100% sensitivity, and 93% specificity were achieved from 12mp back camera using SVM with 100 images.
DiffProtect: Generate Adversarial Examples with Diffusion Models for Facial Privacy Protection
May 23, 2023
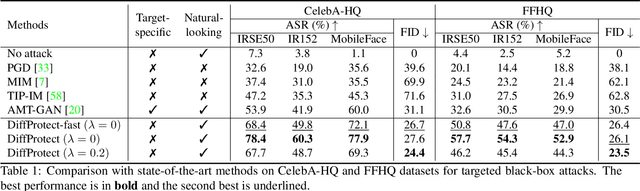
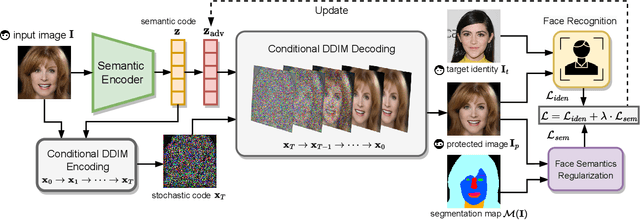

The increasingly pervasive facial recognition (FR) systems raise serious concerns about personal privacy, especially for billions of users who have publicly shared their photos on social media. Several attempts have been made to protect individuals from being identified by unauthorized FR systems utilizing adversarial attacks to generate encrypted face images. However, existing methods suffer from poor visual quality or low attack success rates, which limit their utility. Recently, diffusion models have achieved tremendous success in image generation. In this work, we ask: can diffusion models be used to generate adversarial examples to improve both visual quality and attack performance? We propose DiffProtect, which utilizes a diffusion autoencoder to generate semantically meaningful perturbations on FR systems. Extensive experiments demonstrate that DiffProtect produces more natural-looking encrypted images than state-of-the-art methods while achieving significantly higher attack success rates, e.g., 24.5% and 25.1% absolute improvements on the CelebA-HQ and FFHQ datasets.
Pose-Controllable 3D Facial Animation Synthesis using Hierarchical Audio-Vertex Attention
Feb 24, 2023
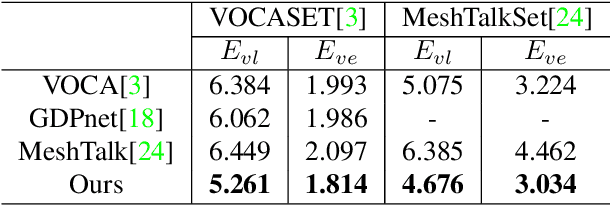
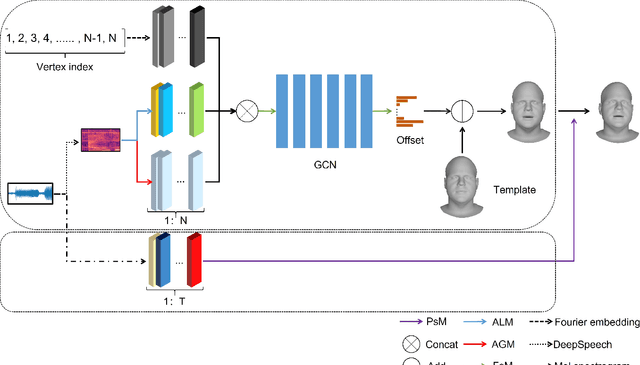
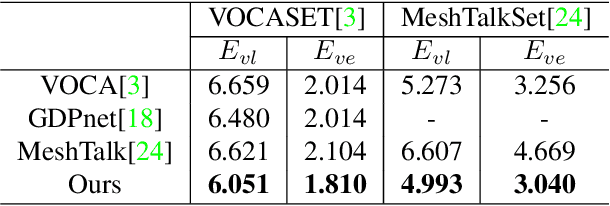
Most of the existing audio-driven 3D facial animation methods suffered from the lack of detailed facial expression and head pose, resulting in unsatisfactory experience of human-robot interaction. In this paper, a novel pose-controllable 3D facial animation synthesis method is proposed by utilizing hierarchical audio-vertex attention. To synthesize real and detailed expression, a hierarchical decomposition strategy is proposed to encode the audio signal into both a global latent feature and a local vertex-wise control feature. Then the local and global audio features combined with vertex spatial features are used to predict the final consistent facial animation via a graph convolutional neural network by fusing the intrinsic spatial topology structure of the face model and the corresponding semantic feature of the audio. To accomplish pose-controllable animation, we introduce a novel pose attribute augmentation method by utilizing the 2D talking face technique. Experimental results indicate that the proposed method can produce more realistic facial expressions and head posture movements. Qualitative and quantitative experiments show that the proposed method achieves competitive performance against state-of-the-art methods.
Using Positive Matching Contrastive Loss with Facial Action Units to mitigate bias in Facial Expression Recognition
Mar 08, 2023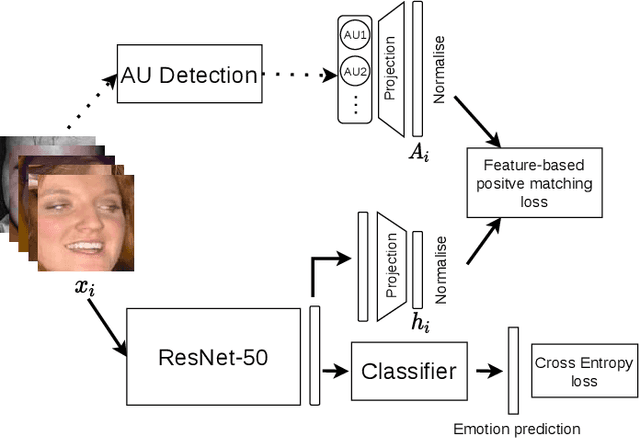
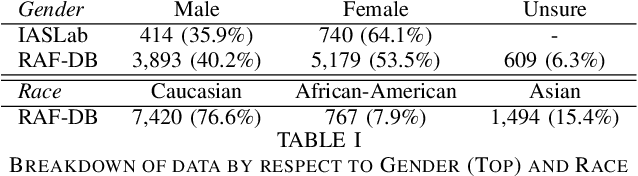
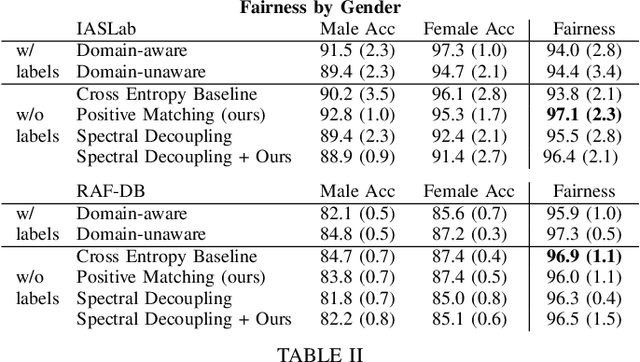
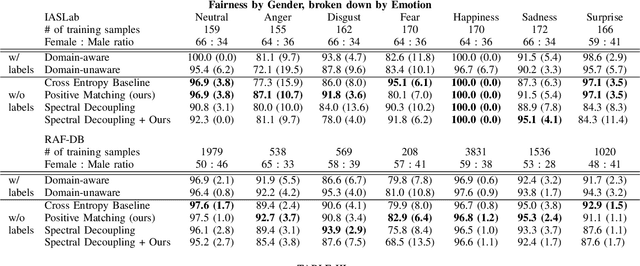
Machine learning models automatically learn discriminative features from the data, and are therefore susceptible to learn strongly-correlated biases, such as using protected attributes like gender and race. Most existing bias mitigation approaches aim to explicitly reduce the model's focus on these protected features. In this work, we propose to mitigate bias by explicitly guiding the model's focus towards task-relevant features using domain knowledge, and we hypothesize that this can indirectly reduce the dependence of the model on spurious correlations it learns from the data. We explore bias mitigation in facial expression recognition systems using facial Action Units (AUs) as the task-relevant feature. To this end, we introduce Feature-based Positive Matching Contrastive Loss which learns the distances between the positives of a sample based on the similarity between their corresponding AU embeddings. We compare our approach with representative baselines and show that incorporating task-relevant features via our method can improve model fairness at minimal cost to classification performance.
Advancing Wound Filling Extraction on 3D Faces: A Auto-Segmentation and Wound Face Regeneration Approach
Jul 04, 2023
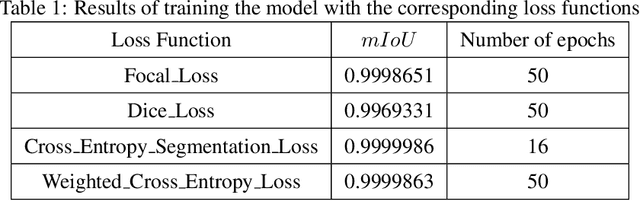
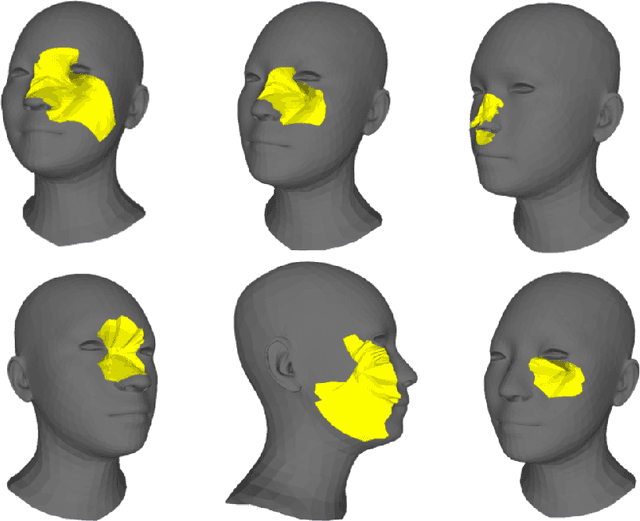
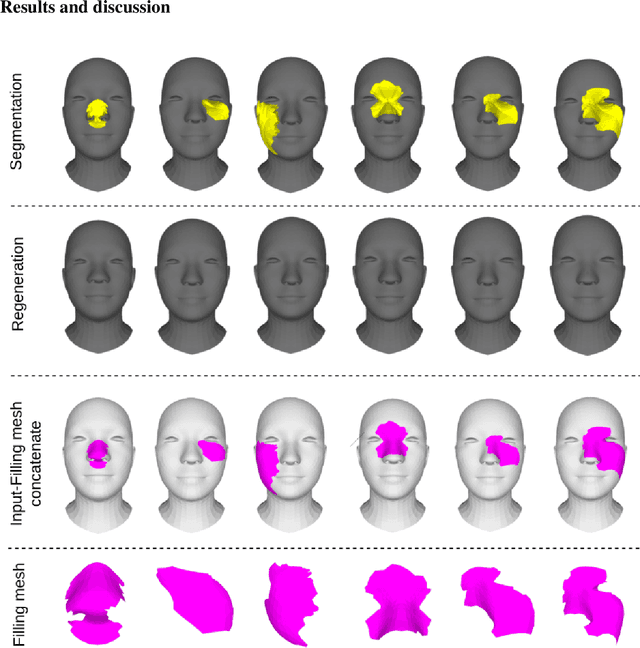
Facial wound segmentation plays a crucial role in preoperative planning and optimizing patient outcomes in various medical applications. In this paper, we propose an efficient approach for automating 3D facial wound segmentation using a two-stream graph convolutional network. Our method leverages the Cir3D-FaIR dataset and addresses the challenge of data imbalance through extensive experimentation with different loss functions. To achieve accurate segmentation, we conducted thorough experiments and selected a high-performing model from the trained models. The selected model demonstrates exceptional segmentation performance for complex 3D facial wounds. Furthermore, based on the segmentation model, we propose an improved approach for extracting 3D facial wound fillers and compare it to the results of the previous study. Our method achieved a remarkable accuracy of 0.9999986\% on the test suite, surpassing the performance of the previous method. From this result, we use 3D printing technology to illustrate the shape of the wound filling. The outcomes of this study have significant implications for physicians involved in preoperative planning and intervention design. By automating facial wound segmentation and improving the accuracy of wound-filling extraction, our approach can assist in carefully assessing and optimizing interventions, leading to enhanced patient outcomes. Additionally, it contributes to advancing facial reconstruction techniques by utilizing machine learning and 3D bioprinting for printing skin tissue implants. Our source code is available at \url{https://github.com/SIMOGroup/WoundFilling3D}.