 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Non-invasive Diabetes Detection using Gabor Filter: A Comparative Analysis of Different Cameras
Jul 28, 2023
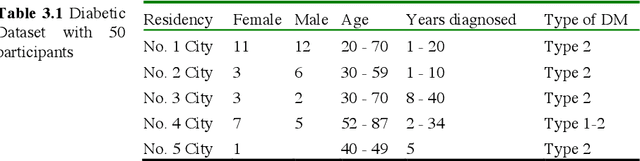

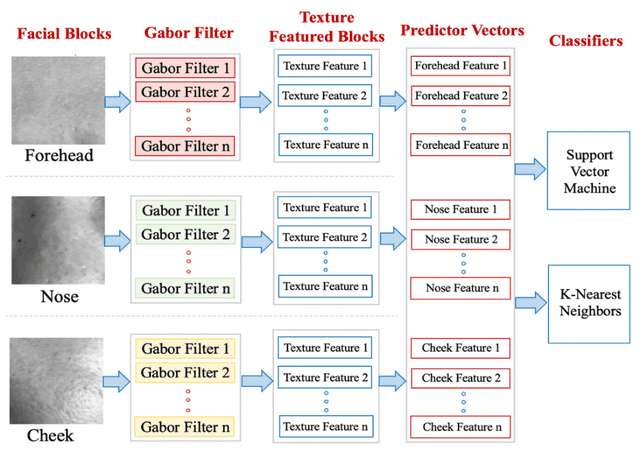
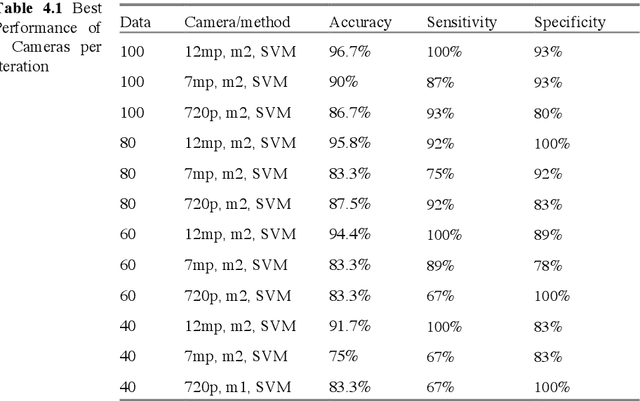
This paper compares and explores the performance of both mobile device camera and laptop camera as convenient tool for capturing images for non-invasive detection of Diabetes Mellitus (DM) using facial block texture features. Participants within age bracket 20 to 79 years old were chosen for the dataset. 12mp and 7mp mobile cameras, and a laptop camera were used to take the photo under normal lighting condition. Extracted facial blocks were classified using k-Nearest Neighbors (k-NN) and Support Vector Machine (SVM). 100 images were captured, preprocessed, filtered using Gabor, and iterated. Performance of the system was measured in terms of accuracy, specificity, and sensitivity. Best performance of 96.7% accuracy, 100% sensitivity, and 93% specificity were achieved from 12mp back camera using SVM with 100 images.
DiffProtect: Generate Adversarial Examples with Diffusion Models for Facial Privacy Protection
May 23, 2023
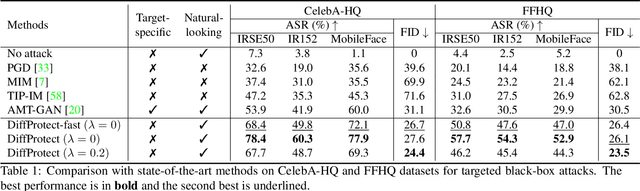
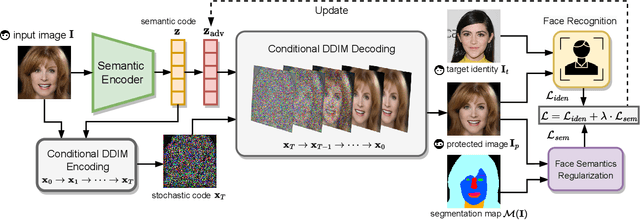

The increasingly pervasive facial recognition (FR) systems raise serious concerns about personal privacy, especially for billions of users who have publicly shared their photos on social media. Several attempts have been made to protect individuals from being identified by unauthorized FR systems utilizing adversarial attacks to generate encrypted face images. However, existing methods suffer from poor visual quality or low attack success rates, which limit their utility. Recently, diffusion models have achieved tremendous success in image generation. In this work, we ask: can diffusion models be used to generate adversarial examples to improve both visual quality and attack performance? We propose DiffProtect, which utilizes a diffusion autoencoder to generate semantically meaningful perturbations on FR systems. Extensive experiments demonstrate that DiffProtect produces more natural-looking encrypted images than state-of-the-art methods while achieving significantly higher attack success rates, e.g., 24.5% and 25.1% absolute improvements on the CelebA-HQ and FFHQ datasets.
A Generative Approach for Image Registration of Visible-Thermal (VT) Cancer Faces
Aug 23, 2023


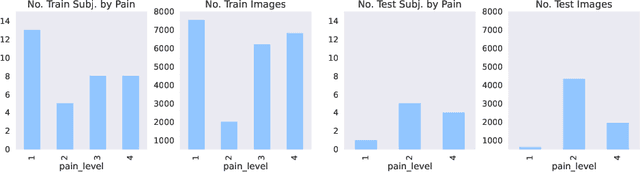
Since thermal imagery offers a unique modality to investigate pain, the U.S. National Institutes of Health (NIH) has collected a large and diverse set of cancer patient facial thermograms for AI-based pain research. However, differing angles from camera capture between thermal and visible sensors has led to misalignment between Visible-Thermal (VT) images. We modernize the classic computer vision task of image registration by applying and modifying a generative alignment algorithm to register VT cancer faces, without the need for a reference or alignment parameters. By registering VT faces, we demonstrate that the quality of thermal images produced in the generative AI downstream task of Visible-to-Thermal (V2T) image translation significantly improves up to 52.5\%, than without registration. Images in this paper have been approved by the NIH NCI for public dissemination.
* 2nd Annual Artificial Intelligence over Infrared Images for Medical Applications Workshop (AIIIMA) at the 26th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2023)
Advancing Wound Filling Extraction on 3D Faces: A Auto-Segmentation and Wound Face Regeneration Approach
Jul 04, 2023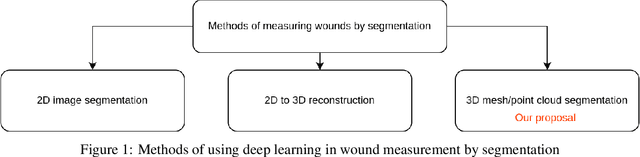
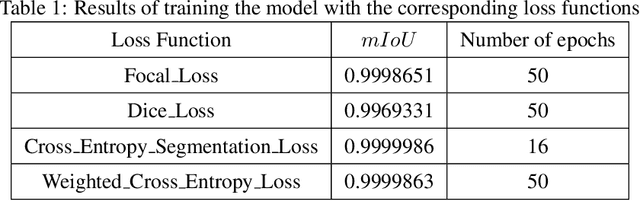
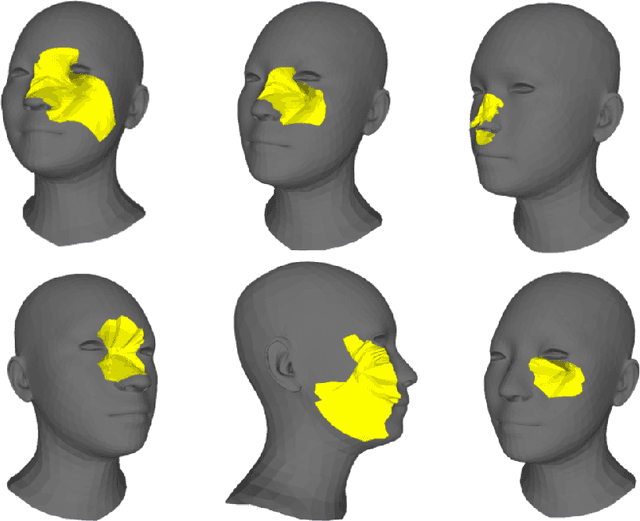
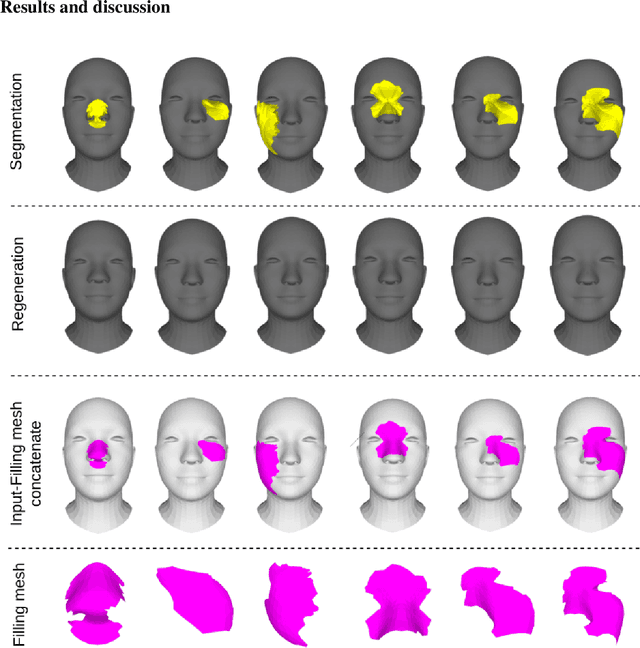
Facial wound segmentation plays a crucial role in preoperative planning and optimizing patient outcomes in various medical applications. In this paper, we propose an efficient approach for automating 3D facial wound segmentation using a two-stream graph convolutional network. Our method leverages the Cir3D-FaIR dataset and addresses the challenge of data imbalance through extensive experimentation with different loss functions. To achieve accurate segmentation, we conducted thorough experiments and selected a high-performing model from the trained models. The selected model demonstrates exceptional segmentation performance for complex 3D facial wounds. Furthermore, based on the segmentation model, we propose an improved approach for extracting 3D facial wound fillers and compare it to the results of the previous study. Our method achieved a remarkable accuracy of 0.9999986\% on the test suite, surpassing the performance of the previous method. From this result, we use 3D printing technology to illustrate the shape of the wound filling. The outcomes of this study have significant implications for physicians involved in preoperative planning and intervention design. By automating facial wound segmentation and improving the accuracy of wound-filling extraction, our approach can assist in carefully assessing and optimizing interventions, leading to enhanced patient outcomes. Additionally, it contributes to advancing facial reconstruction techniques by utilizing machine learning and 3D bioprinting for printing skin tissue implants. Our source code is available at \url{https://github.com/SIMOGroup/WoundFilling3D}.
Emoji Promotes Developer Participation and Issue Resolution on GitHub
Aug 30, 2023


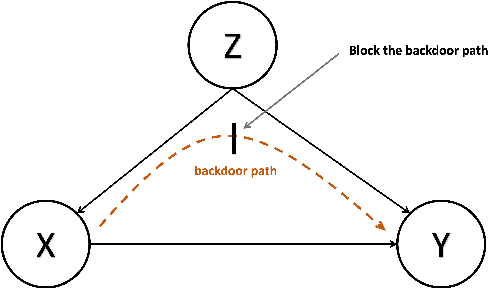
Although remote working is increasingly adopted during the pandemic, many are concerned by the low-efficiency in the remote working. Missing in text-based communication are non-verbal cues such as facial expressions and body language, which hinders the effective communication and negatively impacts the work outcomes. Prevalent on social media platforms, emojis, as alternative non-verbal cues, are gaining popularity in the virtual workspaces well. In this paper, we study how emoji usage influences developer participation and issue resolution in virtual workspaces. To this end, we collect GitHub issues for a one-year period and apply causal inference techniques to measure the causal effect of emojis on the outcome of issues, controlling for confounders such as issue content, repository, and author information. We find that emojis can significantly reduce the resolution time of issues and attract more user participation. We also compare the heterogeneous effect on different types of issues. These findings deepen our understanding of the developer communities, and they provide design implications on how to facilitate interactions and broaden developer participation.
Speech2Lip: High-fidelity Speech to Lip Generation by Learning from a Short Video
Sep 09, 2023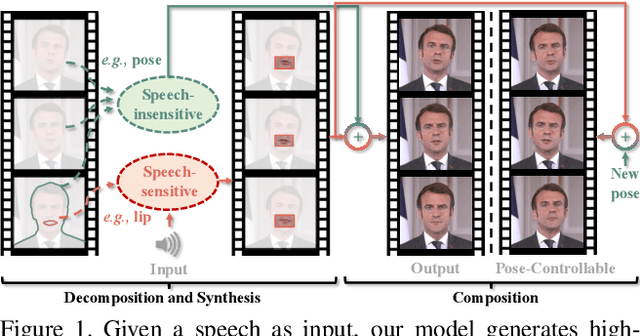
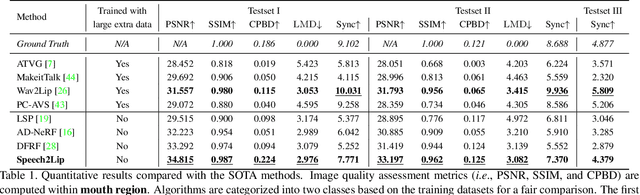

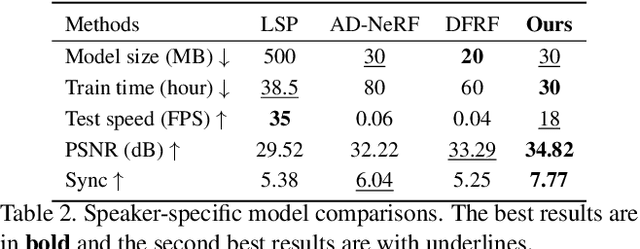
Synthesizing realistic videos according to a given speech is still an open challenge. Previous works have been plagued by issues such as inaccurate lip shape generation and poor image quality. The key reason is that only motions and appearances on limited facial areas (e.g., lip area) are mainly driven by the input speech. Therefore, directly learning a mapping function from speech to the entire head image is prone to ambiguity, particularly when using a short video for training. We thus propose a decomposition-synthesis-composition framework named Speech to Lip (Speech2Lip) that disentangles speech-sensitive and speech-insensitive motion/appearance to facilitate effective learning from limited training data, resulting in the generation of natural-looking videos. First, given a fixed head pose (i.e., canonical space), we present a speech-driven implicit model for lip image generation which concentrates on learning speech-sensitive motion and appearance. Next, to model the major speech-insensitive motion (i.e., head movement), we introduce a geometry-aware mutual explicit mapping (GAMEM) module that establishes geometric mappings between different head poses. This allows us to paste generated lip images at the canonical space onto head images with arbitrary poses and synthesize talking videos with natural head movements. In addition, a Blend-Net and a contrastive sync loss are introduced to enhance the overall synthesis performance. Quantitative and qualitative results on three benchmarks demonstrate that our model can be trained by a video of just a few minutes in length and achieve state-of-the-art performance in both visual quality and speech-visual synchronization. Code: https://github.com/CVMI-Lab/Speech2Lip.
Turn Fake into Real: Adversarial Head Turn Attacks Against Deepfake Detection
Sep 03, 2023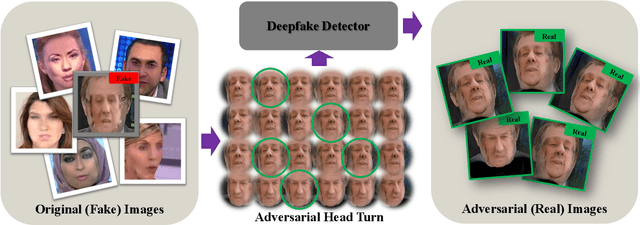
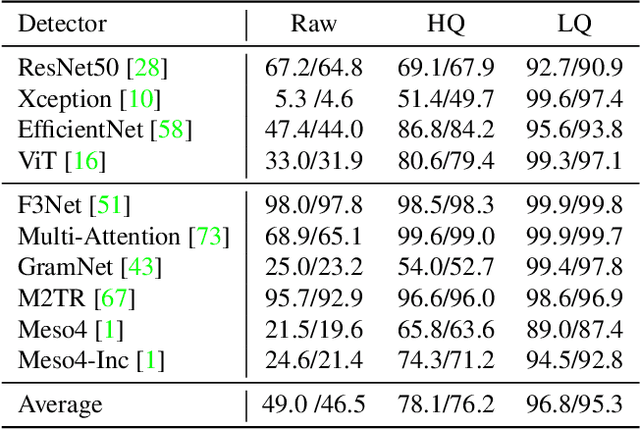


Malicious use of deepfakes leads to serious public concerns and reduces people's trust in digital media. Although effective deepfake detectors have been proposed, they are substantially vulnerable to adversarial attacks. To evaluate the detector's robustness, recent studies have explored various attacks. However, all existing attacks are limited to 2D image perturbations, which are hard to translate into real-world facial changes. In this paper, we propose adversarial head turn (AdvHeat), the first attempt at 3D adversarial face views against deepfake detectors, based on face view synthesis from a single-view fake image. Extensive experiments validate the vulnerability of various detectors to AdvHeat in realistic, black-box scenarios. For example, AdvHeat based on a simple random search yields a high attack success rate of 96.8% with 360 searching steps. When additional query access is allowed, we can further reduce the step budget to 50. Additional analyses demonstrate that AdvHeat is better than conventional attacks on both the cross-detector transferability and robustness to defenses. The adversarial images generated by AdvHeat are also shown to have natural looks. Our code, including that for generating a multi-view dataset consisting of 360 synthetic views for each of 1000 IDs from FaceForensics++, is available at https://github.com/twowwj/AdvHeaT.
Unmasking Parkinson's Disease with Smile: An AI-enabled Screening Framework
Aug 03, 2023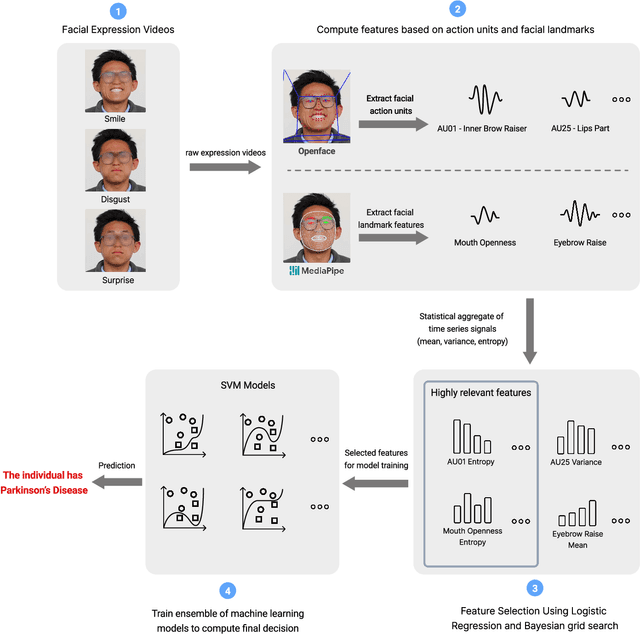
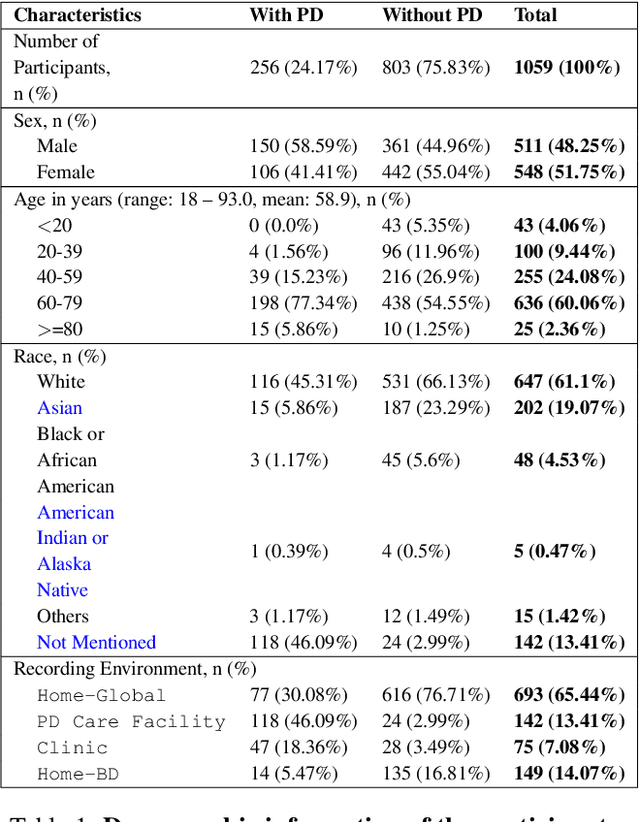
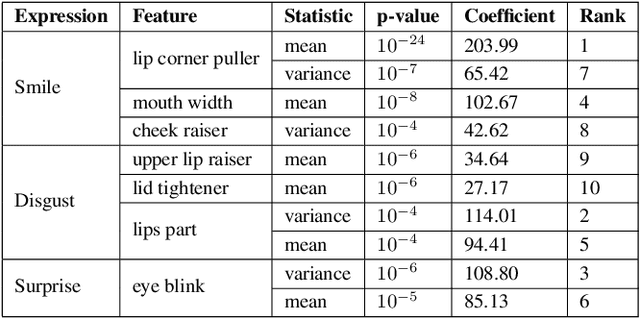
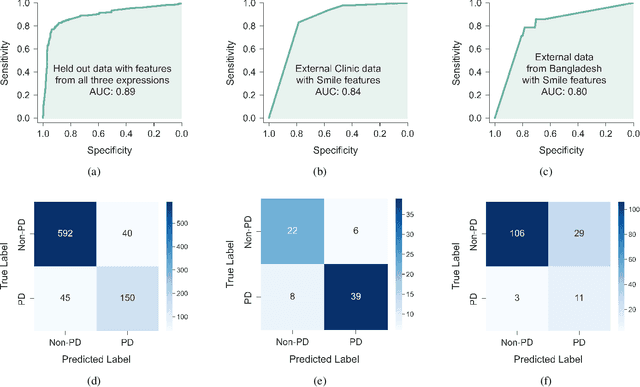
Parkinson's disease (PD) diagnosis remains challenging due to lacking a reliable biomarker and limited access to clinical care. In this study, we present an analysis of the largest video dataset containing micro-expressions to screen for PD. We collected 3,871 videos from 1,059 unique participants, including 256 self-reported PD patients. The recordings are from diverse sources encompassing participants' homes across multiple countries, a clinic, and a PD care facility in the US. Leveraging facial landmarks and action units, we extracted features relevant to Hypomimia, a prominent symptom of PD characterized by reduced facial expressions. An ensemble of AI models trained on these features achieved an accuracy of 89.7% and an Area Under the Receiver Operating Characteristic (AUROC) of 89.3% while being free from detectable bias across population subgroups based on sex and ethnicity on held-out data. Further analysis reveals that features from the smiling videos alone lead to comparable performance, even on two external test sets the model has never seen during training, suggesting the potential for PD risk assessment from smiling selfie videos.
Reinforced Disentanglement for Face Swapping without Skip Connection
Jul 26, 2023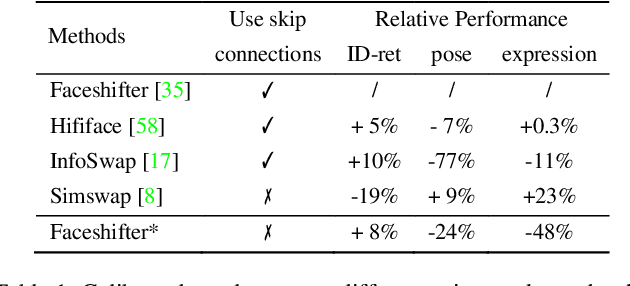
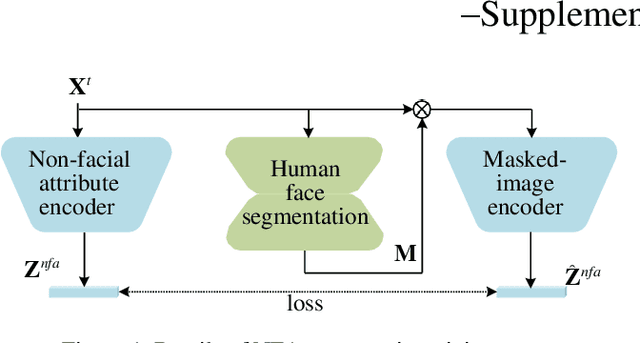
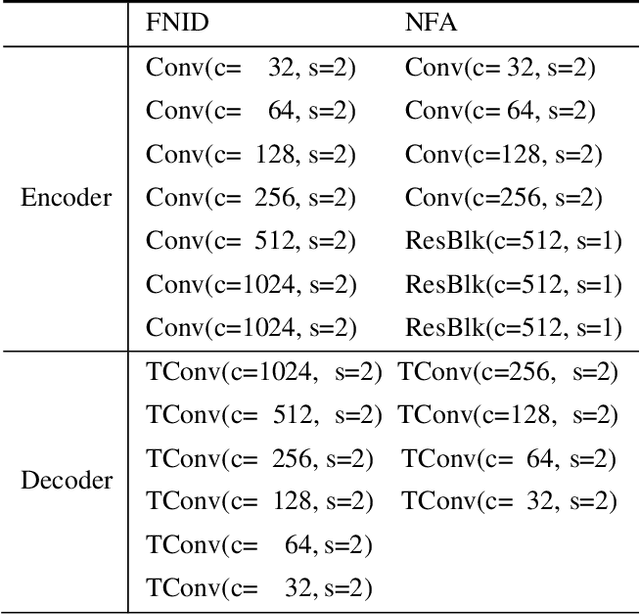

The SOTA face swap models still suffer the problem of either target identity (i.e., shape) being leaked or the target non-identity attributes (i.e., background, hair) failing to be fully preserved in the final results. We show that this insufficient disentanglement is caused by two flawed designs that were commonly adopted in prior models: (1) counting on only one compressed encoder to represent both the semantic-level non-identity facial attributes(i.e., pose) and the pixel-level non-facial region details, which is contradictory to satisfy at the same time; (2) highly relying on long skip-connections between the encoder and the final generator, leaking a certain amount of target face identity into the result. To fix them, we introduce a new face swap framework called 'WSC-swap' that gets rid of skip connections and uses two target encoders to respectively capture the pixel-level non-facial region attributes and the semantic non-identity attributes in the face region. To further reinforce the disentanglement learning for the target encoder, we employ both identity removal loss via adversarial training (i.e., GAN) and the non-identity preservation loss via prior 3DMM models like [11]. Extensive experiments on both FaceForensics++ and CelebA-HQ show that our results significantly outperform previous works on a rich set of metrics, including one novel metric for measuring identity consistency that was completely neglected before.
Pose-Controllable 3D Facial Animation Synthesis using Hierarchical Audio-Vertex Attention
Feb 24, 2023
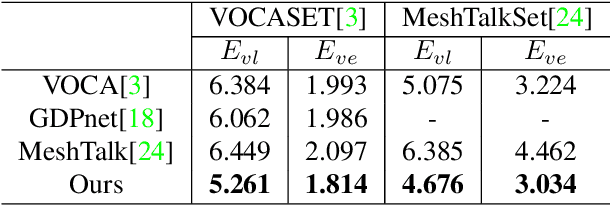
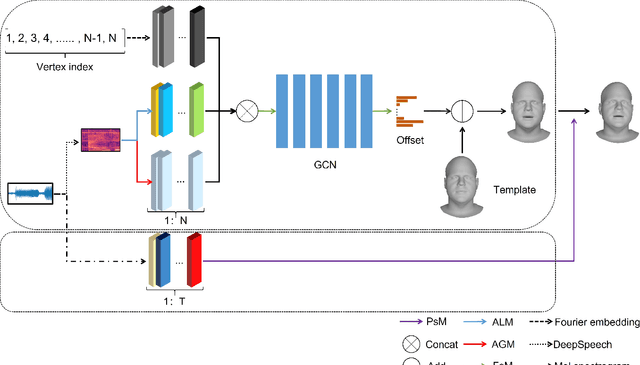
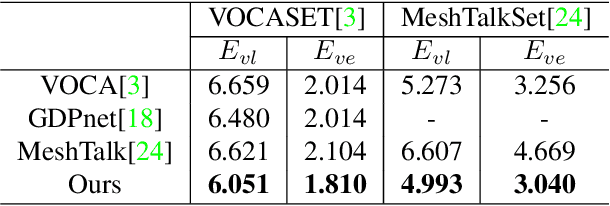
Most of the existing audio-driven 3D facial animation methods suffered from the lack of detailed facial expression and head pose, resulting in unsatisfactory experience of human-robot interaction. In this paper, a novel pose-controllable 3D facial animation synthesis method is proposed by utilizing hierarchical audio-vertex attention. To synthesize real and detailed expression, a hierarchical decomposition strategy is proposed to encode the audio signal into both a global latent feature and a local vertex-wise control feature. Then the local and global audio features combined with vertex spatial features are used to predict the final consistent facial animation via a graph convolutional neural network by fusing the intrinsic spatial topology structure of the face model and the corresponding semantic feature of the audio. To accomplish pose-controllable animation, we introduce a novel pose attribute augmentation method by utilizing the 2D talking face technique. Experimental results indicate that the proposed method can produce more realistic facial expressions and head posture movements. Qualitative and quantitative experiments show that the proposed method achieves competitive performance against state-of-the-art methods.