 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
3D Facial Expressions through Analysis-by-Neural-Synthesis
Apr 05, 2024
While existing methods for 3D face reconstruction from in-the-wild images excel at recovering the overall face shape, they commonly miss subtle, extreme, asymmetric, or rarely observed expressions. We improve upon these methods with SMIRK (Spatial Modeling for Image-based Reconstruction of Kinesics), which faithfully reconstructs expressive 3D faces from images. We identify two key limitations in existing methods: shortcomings in their self-supervised training formulation, and a lack of expression diversity in the training images. For training, most methods employ differentiable rendering to compare a predicted face mesh with the input image, along with a plethora of additional loss functions. This differentiable rendering loss not only has to provide supervision to optimize for 3D face geometry, camera, albedo, and lighting, which is an ill-posed optimization problem, but the domain gap between rendering and input image further hinders the learning process. Instead, SMIRK replaces the differentiable rendering with a neural rendering module that, given the rendered predicted mesh geometry, and sparsely sampled pixels of the input image, generates a face image. As the neural rendering gets color information from sampled image pixels, supervising with neural rendering-based reconstruction loss can focus solely on the geometry. Further, it enables us to generate images of the input identity with varying expressions while training. These are then utilized as input to the reconstruction model and used as supervision with ground truth geometry. This effectively augments the training data and enhances the generalization for diverse expressions. Our qualitative, quantitative and particularly our perceptual evaluations demonstrate that SMIRK achieves the new state-of-the art performance on accurate expression reconstruction. Project webpage: https://georgeretsi.github.io/smirk/.
Chaos in Motion: Unveiling Robustness in Remote Heart Rate Measurement through Brain-Inspired Skin Tracking
Apr 11, 2024Heart rate is an important physiological indicator of human health status. Existing remote heart rate measurement methods typically involve facial detection followed by signal extraction from the region of interest (ROI). These SOTA methods have three serious problems: (a) inaccuracies even failures in detection caused by environmental influences or subject movement; (b) failures for special patients such as infants and burn victims; (c) privacy leakage issues resulting from collecting face video. To address these issues, we regard the remote heart rate measurement as the process of analyzing the spatiotemporal characteristics of the optical flow signal in the video. We apply chaos theory to computer vision tasks for the first time, thus designing a brain-inspired framework. Firstly, using an artificial primary visual cortex model to extract the skin in the videos, and then calculate heart rate by time-frequency analysis on all pixels. Our method achieves Robust Skin Tracking for Heart Rate measurement, called HR-RST. The experimental results show that HR-RST overcomes the difficulty of environmental influences and effectively tracks the subject movement. Moreover, the method could extend to other body parts. Consequently, the method can be applied to special patients and effectively protect individual privacy, offering an innovative solution.
Deepfake Generation and Detection: A Benchmark and Survey
Apr 09, 2024In addition to the advancements in deepfake generation, corresponding detection technologies need to continuously evolve to regulate the potential misuse of deepfakes, such as for privacy invasion and phishing attacks. This survey comprehensively reviews the latest developments in deepfake generation and detection, summarizing and analyzing the current state of the art in this rapidly evolving field. We first unify task definitions, comprehensively introduce datasets and metrics, and discuss the development of generation and detection technology frameworks. Then, we discuss the development of several related sub-fields and focus on researching four mainstream deepfake fields: popular face swap, face reenactment, talking face generation, and facial attribute editing, as well as foreign detection. Subsequently, we comprehensively benchmark representative methods on popular datasets for each field, fully evaluating the latest and influential works published in top conferences/journals. Finally, we analyze the challenges and future research directions of the discussed fields. We closely follow the latest developments in https://github.com/flyingby/Awesome-Deepfake-Generation-and-Detection.
EDTalk: Efficient Disentanglement for Emotional Talking Head Synthesis
Apr 02, 2024Achieving disentangled control over multiple facial motions and accommodating diverse input modalities greatly enhances the application and entertainment of the talking head generation. This necessitates a deep exploration of the decoupling space for facial features, ensuring that they a) operate independently without mutual interference and b) can be preserved to share with different modal input, both aspects often neglected in existing methods. To address this gap, this paper proposes a novel Efficient Disentanglement framework for Talking head generation (EDTalk). Our framework enables individual manipulation of mouth shape, head pose, and emotional expression, conditioned on video or audio inputs. Specifically, we employ three lightweight modules to decompose the facial dynamics into three distinct latent spaces representing mouth, pose, and expression, respectively. Each space is characterized by a set of learnable bases whose linear combinations define specific motions. To ensure independence and accelerate training, we enforce orthogonality among bases and devise an efficient training strategy to allocate motion responsibilities to each space without relying on external knowledge. The learned bases are then stored in corresponding banks, enabling shared visual priors with audio input. Furthermore, considering the properties of each space, we propose an Audio-to-Motion module for audio-driven talking head synthesis. Experiments are conducted to demonstrate the effectiveness of EDTalk. We recommend watching the project website: https://tanshuai0219.github.io/EDTalk/
Contrastive Learning of Person-independent Representations for Facial Action Unit Detection
Mar 06, 2024
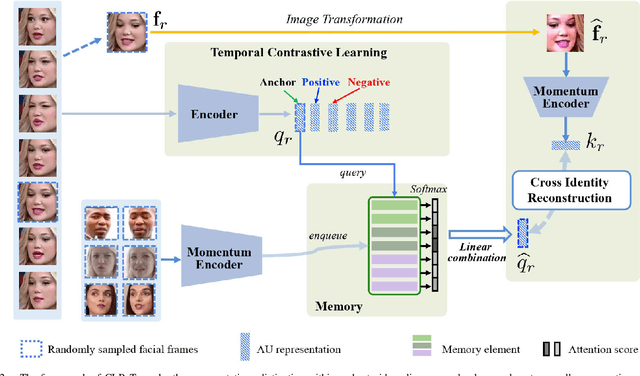

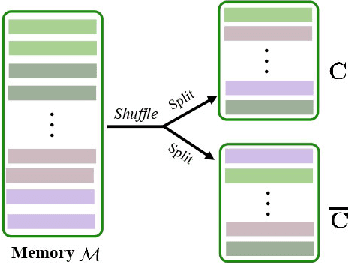
Facial action unit (AU) detection, aiming to classify AU present in the facial image, has long suffered from insufficient AU annotations. In this paper, we aim to mitigate this data scarcity issue by learning AU representations from a large number of unlabelled facial videos in a contrastive learning paradigm. We formulate the self-supervised AU representation learning signals in two-fold: (1) AU representation should be frame-wisely discriminative within a short video clip; (2) Facial frames sampled from different identities but show analogous facial AUs should have consistent AU representations. As to achieve these goals, we propose to contrastively learn the AU representation within a video clip and devise a cross-identity reconstruction mechanism to learn the person-independent representations. Specially, we adopt a margin-based temporal contrastive learning paradigm to perceive the temporal AU coherence and evolution characteristics within a clip that consists of consecutive input facial frames. Moreover, the cross-identity reconstruction mechanism facilitates pushing the faces from different identities but show analogous AUs close in the latent embedding space. Experimental results on three public AU datasets demonstrate that the learned AU representation is discriminative for AU detection. Our method outperforms other contrastive learning methods and significantly closes the performance gap between the self-supervised and supervised AU detection approaches.
Real, fake and synthetic faces -- does the coin have three sides?
Apr 02, 2024With the ever-growing power of generative artificial intelligence, deepfake and artificially generated (synthetic) media have continued to spread online, which creates various ethical and moral concerns regarding their usage. To tackle this, we thus present a novel exploration of the trends and patterns observed in real, deepfake and synthetic facial images. The proposed analysis is done in two parts: firstly, we incorporate eight deep learning models and analyze their performances in distinguishing between the three classes of images. Next, we look to further delve into the similarities and differences between these three sets of images by investigating their image properties both in the context of the entire image as well as in the context of specific regions within the image. ANOVA test was also performed and provided further clarity amongst the patterns associated between the images of the three classes. From our findings, we observe that the investigated deeplearning models found it easier to detect synthetic facial images, with the ViT Patch-16 model performing best on this task with a class-averaged sensitivity, specificity, precision, and accuracy of 97.37%, 98.69%, 97.48%, and 98.25%, respectively. This observation was supported by further analysis of various image properties. We saw noticeable differences across the three category of images. This analysis can help us build better algorithms for facial image generation, and also shows that synthetic, deepfake and real face images are indeed three different classes.
Spatio-Temporal Attention and Gaussian Processes for Personalized Video Gaze Estimation
Apr 10, 2024Gaze is an essential prompt for analyzing human behavior and attention. Recently, there has been an increasing interest in determining gaze direction from facial videos. However, video gaze estimation faces significant challenges, such as understanding the dynamic evolution of gaze in video sequences, dealing with static backgrounds, and adapting to variations in illumination. To address these challenges, we propose a simple and novel deep learning model designed to estimate gaze from videos, incorporating a specialized attention module. Our method employs a spatial attention mechanism that tracks spatial dynamics within videos. This technique enables accurate gaze direction prediction through a temporal sequence model, adeptly transforming spatial observations into temporal insights, thereby significantly improving gaze estimation accuracy. Additionally, our approach integrates Gaussian processes to include individual-specific traits, facilitating the personalization of our model with just a few labeled samples. Experimental results confirm the efficacy of the proposed approach, demonstrating its success in both within-dataset and cross-dataset settings. Specifically, our proposed approach achieves state-of-the-art performance on the Gaze360 dataset, improving by $2.5^\circ$ without personalization. Further, by personalizing the model with just three samples, we achieved an additional improvement of $0.8^\circ$. The code and pre-trained models are available at \url{https://github.com/jswati31/stage}.
MI-NeRF: Learning a Single Face NeRF from Multiple Identities
Apr 03, 2024
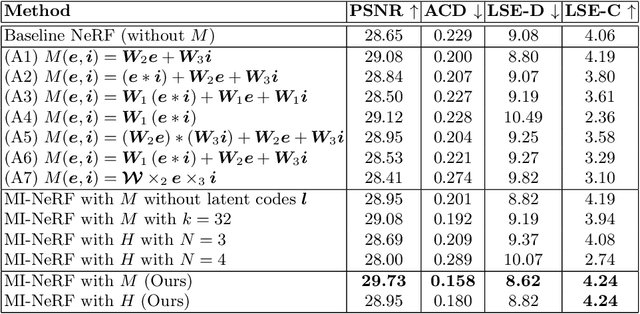
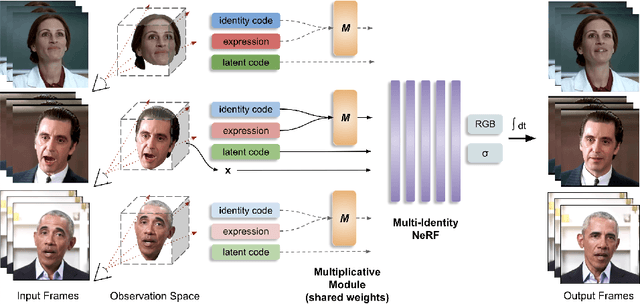
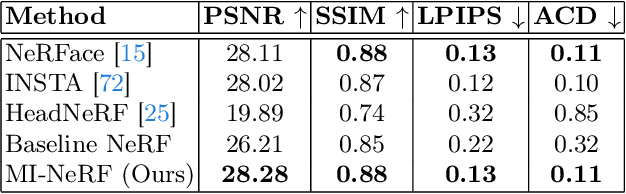
In this work, we introduce a method that learns a single dynamic neural radiance field (NeRF) from monocular talking face videos of multiple identities. NeRFs have shown remarkable results in modeling the 4D dynamics and appearance of human faces. However, they require per-identity optimization. Although recent approaches have proposed techniques to reduce the training and rendering time, increasing the number of identities can be expensive. We introduce MI-NeRF (multi-identity NeRF), a single unified network that models complex non-rigid facial motion for multiple identities, using only monocular videos of arbitrary length. The core premise in our method is to learn the non-linear interactions between identity and non-identity specific information with a multiplicative module. By training on multiple videos simultaneously, MI-NeRF not only reduces the total training time compared to standard single-identity NeRFs, but also demonstrates robustness in synthesizing novel expressions for any input identity. We present results for both facial expression transfer and talking face video synthesis. Our method can be further personalized for a target identity given only a short video.
RhythmMamba: Fast Remote Physiological Measurement with Arbitrary Length Videos
Apr 09, 2024Remote photoplethysmography (rPPG) is a non-contact method for detecting physiological signals from facial videos, holding great potential in various applications such as healthcare, affective computing, and anti-spoofing. Existing deep learning methods struggle to address two core issues of rPPG simultaneously: extracting weak rPPG signals from video segments with large spatiotemporal redundancy and understanding the periodic patterns of rPPG among long contexts. This represents a trade-off between computational complexity and the ability to capture long-range dependencies, posing a challenge for rPPG that is suitable for deployment on mobile devices. Based on the in-depth exploration of Mamba's comprehension of spatial and temporal information, this paper introduces RhythmMamba, an end-to-end Mamba-based method that employs multi-temporal Mamba to constrain both periodic patterns and short-term trends, coupled with frequency domain feed-forward to enable Mamba to robustly understand the quasi-periodic patterns of rPPG. Extensive experiments show that RhythmMamba achieves state-of-the-art performance with reduced parameters and lower computational complexity. The proposed RhythmMamba can be applied to video segments of any length without performance degradation. The codes are available at https://github.com/zizheng-guo/RhythmMamba.
A secure and private ensemble matcher using multi-vault obfuscated templates
Apr 08, 2024Given the irrevocability of biometric samples and mounting privacy concerns, biometric template security and secure matching are among the essential features of any well-designed modern biometric system. In this paper, we propose an obfuscation method that hides the biometric template information with just enough chaff. The main idea is to reduce the number of chaff points to a practical level by creating n sub-templates from the original template and hiding each sub-template with m chaff points. During verification, s closest vectors to the biometric query are retrieved from each vault and then combined to generate hash values that are compared with the stored hash value. We demonstrate the effectiveness of synthetic facial images, generated by a Generative Adversarial Network (GAN), as ``random chaff points'' within a secure-vault authorization system. This approach safeguards user identities during training and deployment. We tested our protocol using the AT&T, GT, and LFW face datasets, with the ROC areas under the curve being 0.99, 0.99, and 0.90, respectively. These numbers were close to those of the unprotected templates, showing that our method does not adversely affect accuracy.