 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
EMS: 3D Eyebrow Modeling from Single-view Images
Sep 22, 2023
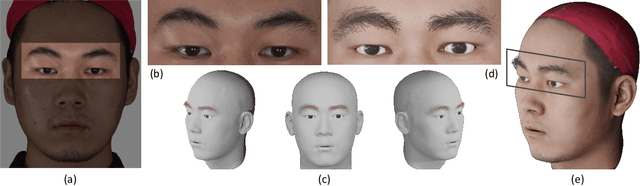

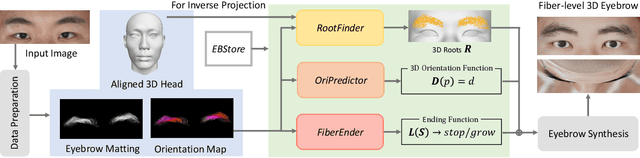

Eyebrows play a critical role in facial expression and appearance. Although the 3D digitization of faces is well explored, less attention has been drawn to 3D eyebrow modeling. In this work, we propose EMS, the first learning-based framework for single-view 3D eyebrow reconstruction. Following the methods of scalp hair reconstruction, we also represent the eyebrow as a set of fiber curves and convert the reconstruction to fibers growing problem. Three modules are then carefully designed: RootFinder firstly localizes the fiber root positions which indicates where to grow; OriPredictor predicts an orientation field in the 3D space to guide the growing of fibers; FiberEnder is designed to determine when to stop the growth of each fiber. Our OriPredictor is directly borrowing the method used in hair reconstruction. Considering the differences between hair and eyebrows, both RootFinder and FiberEnder are newly proposed. Specifically, to cope with the challenge that the root location is severely occluded, we formulate root localization as a density map estimation task. Given the predicted density map, a density-based clustering method is further used for finding the roots. For each fiber, the growth starts from the root point and moves step by step until the ending, where each step is defined as an oriented line with a constant length according to the predicted orientation field. To determine when to end, a pixel-aligned RNN architecture is designed to form a binary classifier, which outputs stop or not for each growing step. To support the training of all proposed networks, we build the first 3D synthetic eyebrow dataset that contains 400 high-quality eyebrow models manually created by artists. Extensive experiments have demonstrated the effectiveness of the proposed EMS pipeline on a variety of different eyebrow styles and lengths, ranging from short and sparse to long bushy eyebrows.
SwinFace: A Multi-task Transformer for Face Recognition, Expression Recognition, Age Estimation and Attribute Estimation
Aug 22, 2023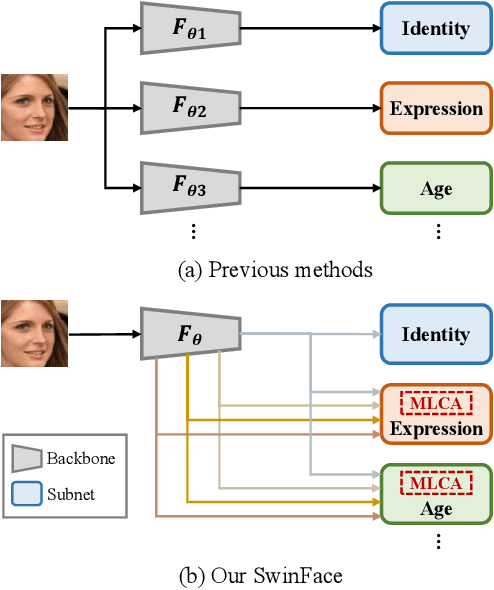
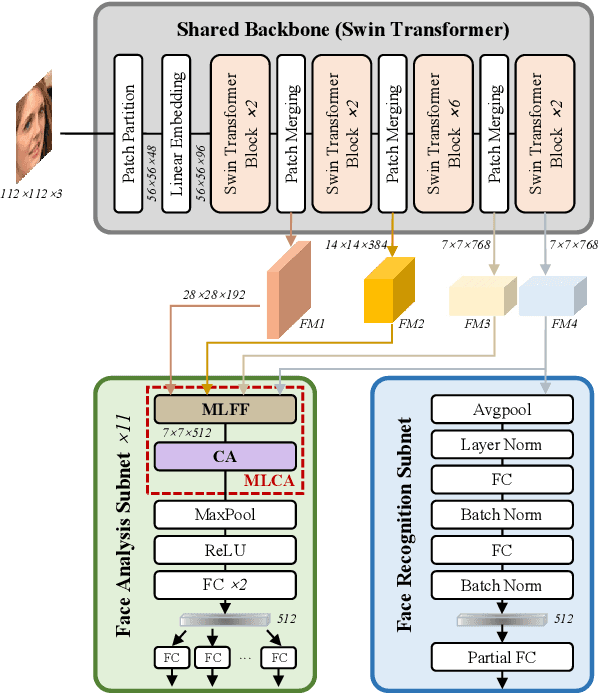
In recent years, vision transformers have been introduced into face recognition and analysis and have achieved performance breakthroughs. However, most previous methods generally train a single model or an ensemble of models to perform the desired task, which ignores the synergy among different tasks and fails to achieve improved prediction accuracy, increased data efficiency, and reduced training time. This paper presents a multi-purpose algorithm for simultaneous face recognition, facial expression recognition, age estimation, and face attribute estimation (40 attributes including gender) based on a single Swin Transformer. Our design, the SwinFace, consists of a single shared backbone together with a subnet for each set of related tasks. To address the conflicts among multiple tasks and meet the different demands of tasks, a Multi-Level Channel Attention (MLCA) module is integrated into each task-specific analysis subnet, which can adaptively select the features from optimal levels and channels to perform the desired tasks. Extensive experiments show that the proposed model has a better understanding of the face and achieves excellent performance for all tasks. Especially, it achieves 90.97% accuracy on RAF-DB and 0.22 $\epsilon$-error on CLAP2015, which are state-of-the-art results on facial expression recognition and age estimation respectively. The code and models will be made publicly available at https://github.com/lxq1000/SwinFace.
VEATIC: Video-based Emotion and Affect Tracking in Context Dataset
Sep 13, 2023
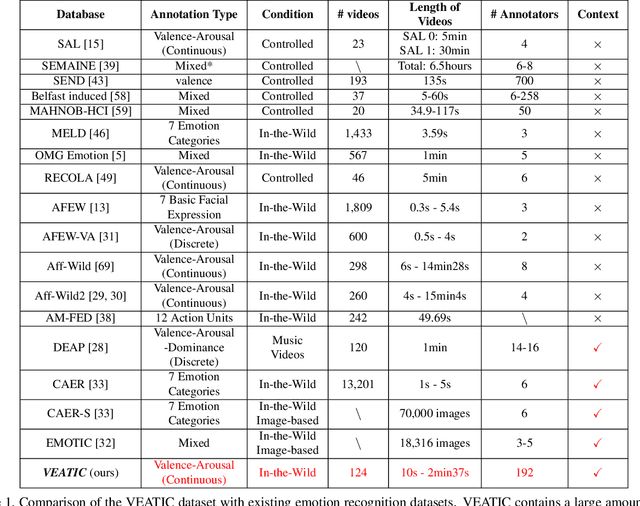

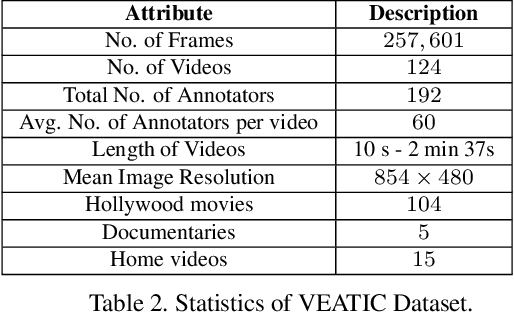
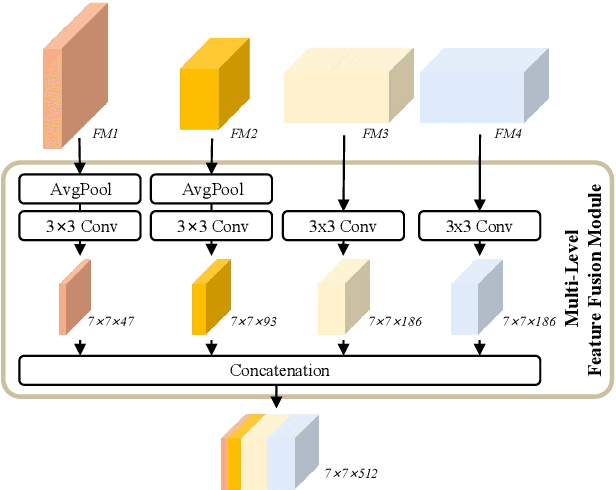
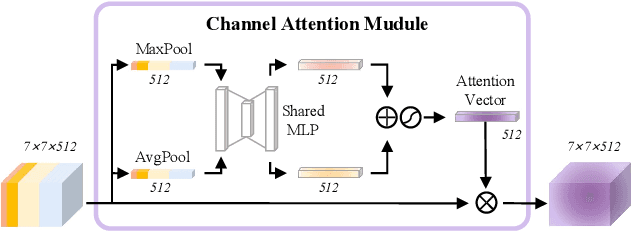
Human affect recognition has been a significant topic in psychophysics and computer vision. However, the currently published datasets have many limitations. For example, most datasets contain frames that contain only information about facial expressions. Due to the limitations of previous datasets, it is very hard to either understand the mechanisms for affect recognition of humans or generalize well on common cases for computer vision models trained on those datasets. In this work, we introduce a brand new large dataset, the Video-based Emotion and Affect Tracking in Context Dataset (VEATIC), that can conquer the limitations of the previous datasets. VEATIC has 124 video clips from Hollywood movies, documentaries, and home videos with continuous valence and arousal ratings of each frame via real-time annotation. Along with the dataset, we propose a new computer vision task to infer the affect of the selected character via both context and character information in each video frame. Additionally, we propose a simple model to benchmark this new computer vision task. We also compare the performance of the pretrained model using our dataset with other similar datasets. Experiments show the competing results of our pretrained model via VEATIC, indicating the generalizability of VEATIC. Our dataset is available at https://veatic.github.io.
UniFLG: Unified Facial Landmark Generator from Text or Speech
Feb 28, 2023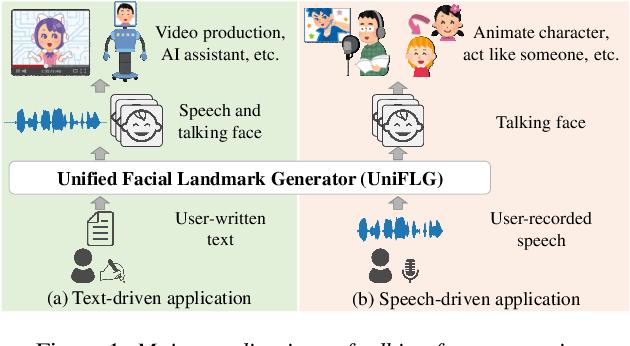
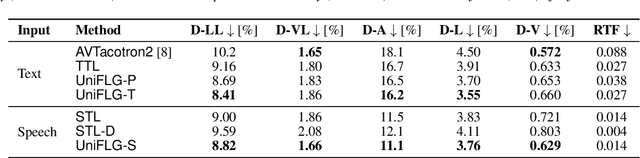
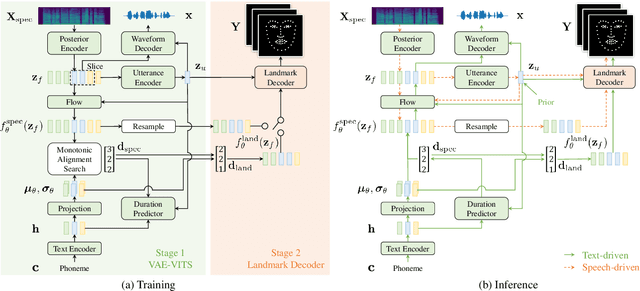
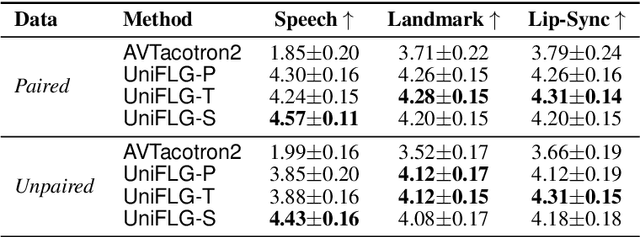
Talking face generation has been extensively investigated owing to its wide applicability. The two primary frameworks used for talking face generation comprise a text-driven framework, which generates synchronized speech and talking faces from text, and a speech-driven framework, which generates talking faces from speech. To integrate these frameworks, this paper proposes a unified facial landmark generator (UniFLG). The proposed system exploits end-to-end text-to-speech not only for synthesizing speech but also for extracting a series of latent representations that are common to text and speech, and feeds it to a landmark decoder to generate facial landmarks. We demonstrate that our system achieves higher naturalness in both speech synthesis and facial landmark generation compared to the state-of-the-art text-driven method. We further demonstrate that our system can generate facial landmarks from speech of speakers without facial video data or even speech data.
A survey on facial image deblurring
Feb 10, 2023
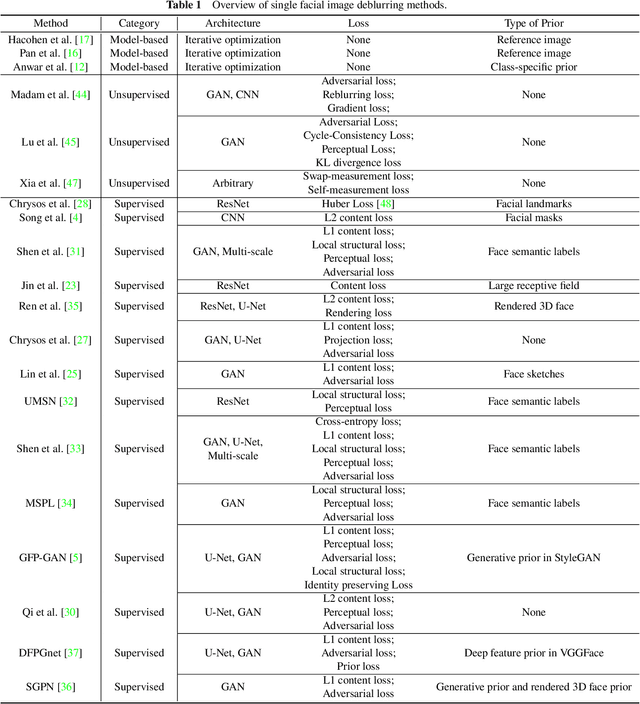
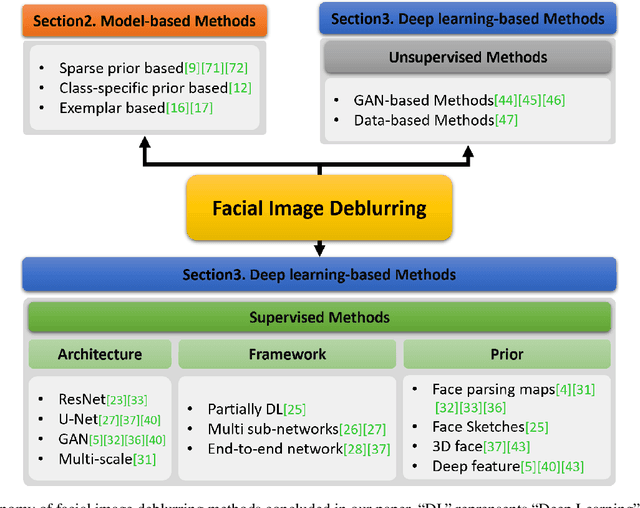
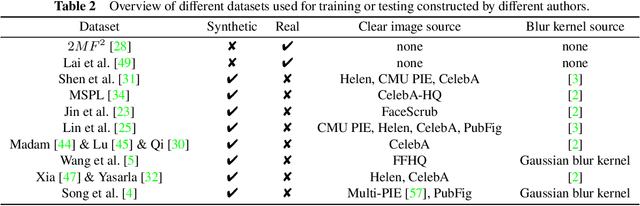
When the facial image is blurred, it has a great impact on high-level vision tasks such as face recognition. The purpose of facial image deblurring is to recover a clear image from a blurry input image, which can improve the recognition accuracy and so on. General deblurring methods can not perform well on facial images. So some face deblurring methods are proposed to improve the performance by adding semantic or structural information as specific priors according to the characteristics of facial images. This paper surveys and summarizes recently published methods for facial image deblurring, most of which are based on deep learning. Firstly, we give a brief introduction to the modeling of image blur. Next, we summarize face deblurring methods into two categories, namely model-based methods and deep learning-based methods. Furthermore, we summarize the datasets, loss functions, and performance evaluation metrics commonly used in the neural network training process. We show the performance of classical methods on these datasets and metrics and give a brief discussion on the differences of model-based and learning-based methods. Finally, we discuss current challenges and possible future research directions.
RADIO: Reference-Agnostic Dubbing Video Synthesis
Sep 05, 2023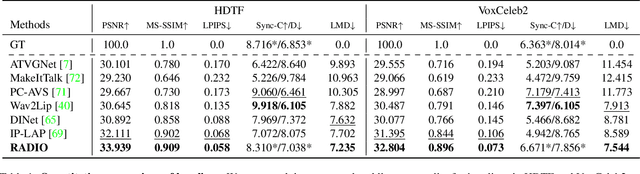
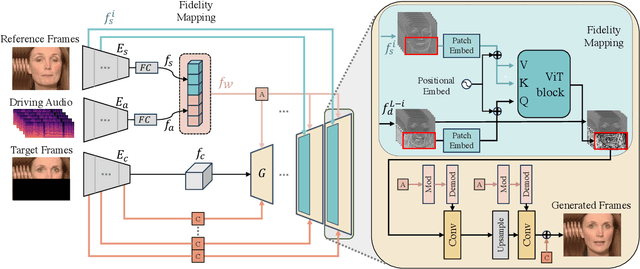
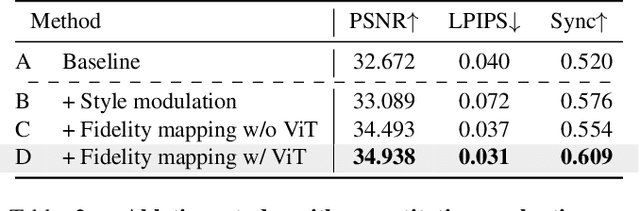
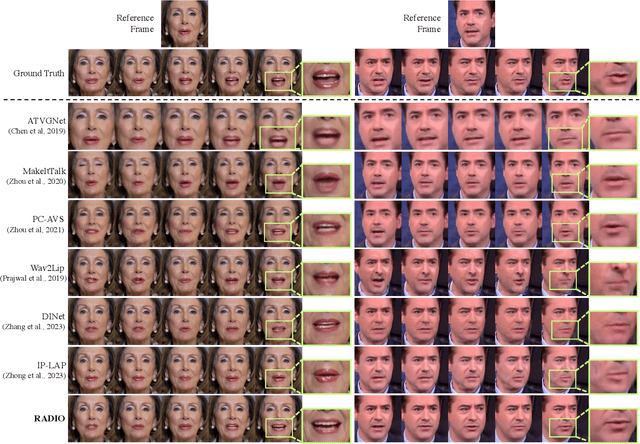
One of the most challenging problems in audio-driven talking head generation is achieving high-fidelity detail while ensuring precise synchronization. Given only a single reference image, extracting meaningful identity attributes becomes even more challenging, often causing the network to mirror the facial and lip structures too closely. To address these issues, we introduce RADIO, a framework engineered to yield high-quality dubbed videos regardless of the pose or expression in reference images. The key is to modulate the decoder layers using latent space composed of audio and reference features. Additionally, we incorporate ViT blocks into the decoder to emphasize high-fidelity details, especially in the lip region. Our experimental results demonstrate that RADIO displays high synchronization without the loss of fidelity. Especially in harsh scenarios where the reference frame deviates significantly from the ground truth, our method outperforms state-of-the-art methods, highlighting its robustness. Pre-trained model and codes will be made public after the review.
Implicit Identity Representation Conditioned Memory Compensation Network for Talking Head video Generation
Jul 20, 2023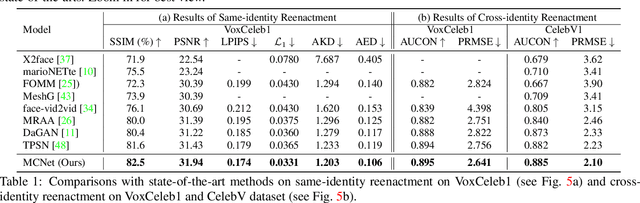
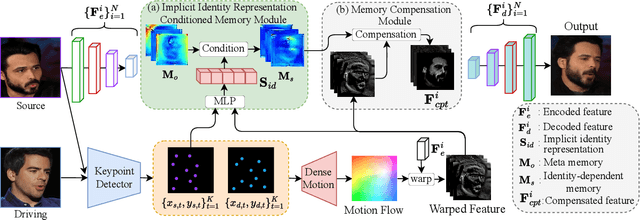
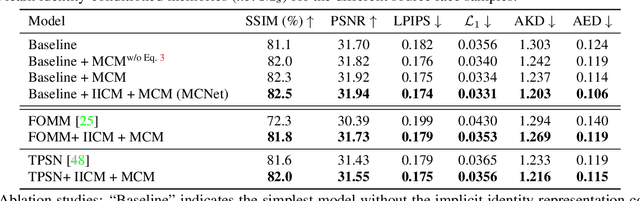
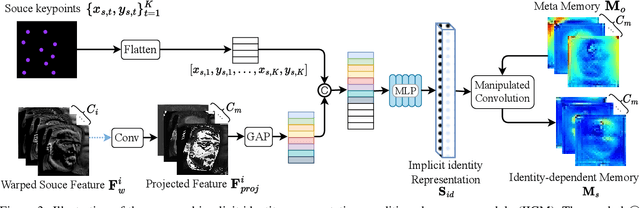
Talking head video generation aims to animate a human face in a still image with dynamic poses and expressions using motion information derived from a target-driving video, while maintaining the person's identity in the source image. However, dramatic and complex motions in the driving video cause ambiguous generation, because the still source image cannot provide sufficient appearance information for occluded regions or delicate expression variations, which produces severe artifacts and significantly degrades the generation quality. To tackle this problem, we propose to learn a global facial representation space, and design a novel implicit identity representation conditioned memory compensation network, coined as MCNet, for high-fidelity talking head generation.~Specifically, we devise a network module to learn a unified spatial facial meta-memory bank from all training samples, which can provide rich facial structure and appearance priors to compensate warped source facial features for the generation. Furthermore, we propose an effective query mechanism based on implicit identity representations learned from the discrete keypoints of the source image. It can greatly facilitate the retrieval of more correlated information from the memory bank for the compensation. Extensive experiments demonstrate that MCNet can learn representative and complementary facial memory, and can clearly outperform previous state-of-the-art talking head generation methods on VoxCeleb1 and CelebV datasets. Please check our \href{https://github.com/harlanhong/ICCV2023-MCNET}{Project}.
Emoji Promotes Developer Participation and Issue Resolution on GitHub
Sep 07, 2023


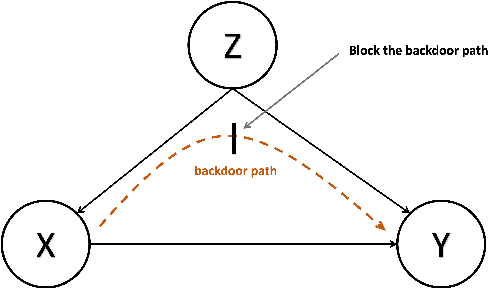
Although remote working is increasingly adopted during the pandemic, many are concerned by the low-efficiency in the remote working. Missing in text-based communication are non-verbal cues such as facial expressions and body language, which hinders the effective communication and negatively impacts the work outcomes. Prevalent on social media platforms, emojis, as alternative non-verbal cues, are gaining popularity in the virtual workspaces well. In this paper, we study how emoji usage influences developer participation and issue resolution in virtual workspaces. To this end, we collect GitHub issues for a one-year period and apply causal inference techniques to measure the causal effect of emojis on the outcome of issues, controlling for confounders such as issue content, repository, and author information. We find that emojis can significantly reduce the resolution time of issues and attract more user participation. We also compare the heterogeneous effect on different types of issues. These findings deepen our understanding of the developer communities, and they provide design implications on how to facilitate interactions and broaden developer participation.
Revisiting N-CNN for Clinical Practice
Aug 10, 2023This paper revisits the Neonatal Convolutional Neural Network (N-CNN) by optimizing its hyperparameters and evaluating how they affect its classification metrics, explainability and reliability, discussing their potential impact in clinical practice. We have chosen hyperparameters that do not modify the original N-CNN architecture, but mainly modify its learning rate and training regularization. The optimization was done by evaluating the improvement in F1 Score for each hyperparameter individually, and the best hyperparameters were chosen to create a Tuned N-CNN. We also applied soft labels derived from the Neonatal Facial Coding System, proposing a novel approach for training facial expression classification models for neonatal pain assessment. Interestingly, while the Tuned N-CNN results point towards improvements in classification metrics and explainability, these improvements did not directly translate to calibration performance. We believe that such insights might have the potential to contribute to the development of more reliable pain evaluation tools for newborns, aiding healthcare professionals in delivering appropriate interventions and improving patient outcomes.
Spatio-Temporal AU Relational Graph Representation Learning For Facial Action Units Detection
Mar 27, 2023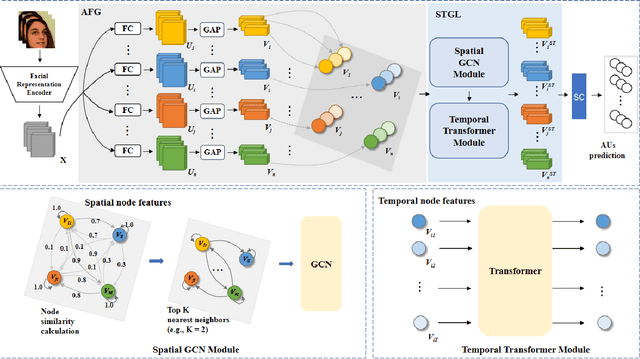

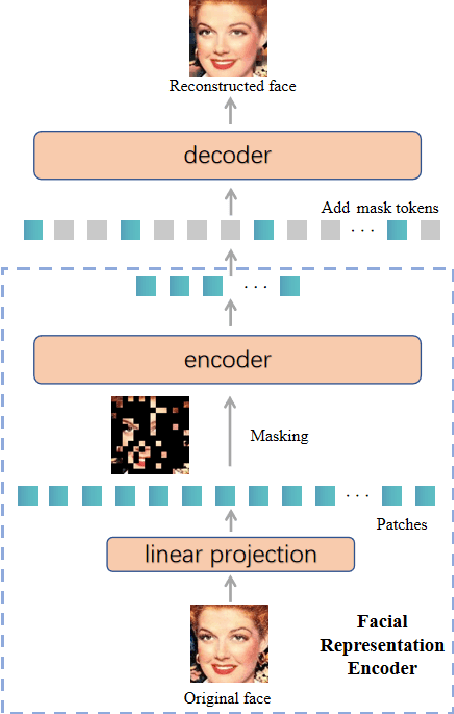

This paper presents our Facial Action Units (AUs) recognition submission to the fifth Affective Behavior Analysis in-the-wild Competition (ABAW). Our approach consists of three main modules: (i) a pre-trained facial representation encoder which produce a strong facial representation from each input face image in the input sequence; (ii) an AU-specific feature generator that specifically learns a set of AU features from each facial representation; and (iii) a spatio-temporal graph learning module that constructs a spatio-temporal graph representation. This graph representation describes AUs contained in all frames and predicts the occurrence of each AU based on both the modeled spatial information within the corresponding face and the learned temporal dynamics among frames. The experimental results show that our approach outperformed the baseline and the spatio-temporal graph representation learning allows our model to generate the best results among all ablated systems. Our model ranks at the 4th place in the AU recognition track at the 5th ABAW Competition.