 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
SARGAN: Spatial Attention-based Residuals for Facial Expression Manipulation
Mar 30, 2023
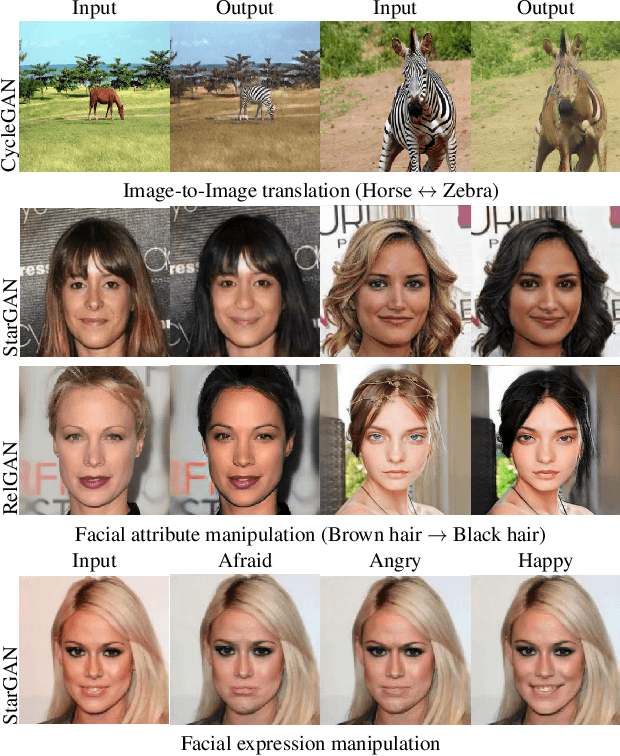
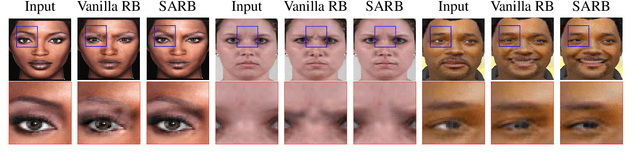


Encoder-decoder based architecture has been widely used in the generator of generative adversarial networks for facial manipulation. However, we observe that the current architecture fails to recover the input image color, rich facial details such as skin color or texture and introduces artifacts as well. In this paper, we present a novel method named SARGAN that addresses the above-mentioned limitations from three perspectives. First, we employed spatial attention-based residual block instead of vanilla residual blocks to properly capture the expression-related features to be changed while keeping the other features unchanged. Second, we exploited a symmetric encoder-decoder network to attend facial features at multiple scales. Third, we proposed to train the complete network with a residual connection which relieves the generator of pressure to generate the input face image thereby producing the desired expression by directly feeding the input image towards the end of the generator. Both qualitative and quantitative experimental results show that our proposed model performs significantly better than state-of-the-art methods. In addition, existing models require much larger datasets for training but their performance degrades on out-of-distribution images. In contrast, SARGAN can be trained on smaller facial expressions datasets, which generalizes well on out-of-distribution images including human photographs, portraits, avatars and statues.
Improving Face Recognition from Caption Supervision with Multi-Granular Contextual Feature Aggregation
Aug 13, 2023
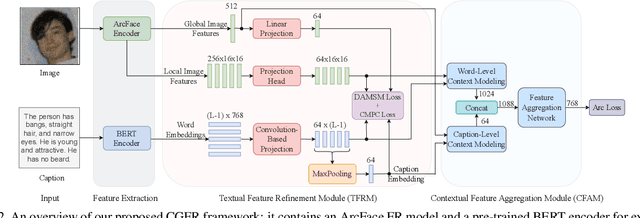
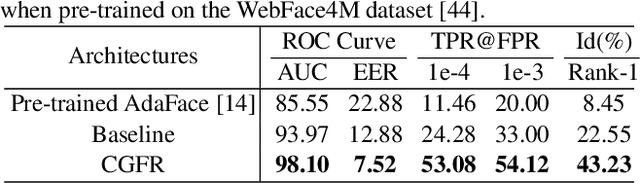
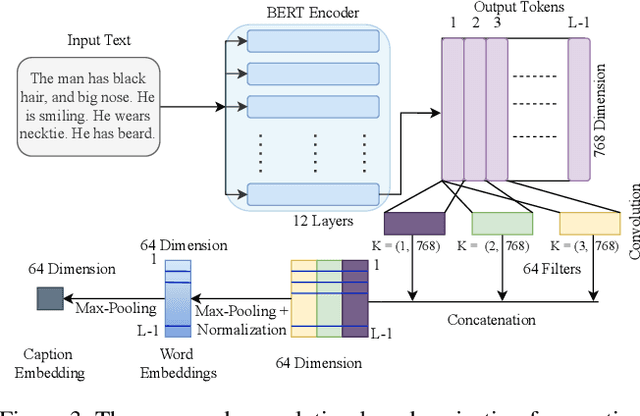
We introduce caption-guided face recognition (CGFR) as a new framework to improve the performance of commercial-off-the-shelf (COTS) face recognition (FR) systems. In contrast to combining soft biometrics (eg., facial marks, gender, and age) with face images, in this work, we use facial descriptions provided by face examiners as a piece of auxiliary information. However, due to the heterogeneity of the modalities, improving the performance by directly fusing the textual and facial features is very challenging, as both lie in different embedding spaces. In this paper, we propose a contextual feature aggregation module (CFAM) that addresses this issue by effectively exploiting the fine-grained word-region interaction and global image-caption association. Specifically, CFAM adopts a self-attention and a cross-attention scheme for improving the intra-modality and inter-modality relationship between the image and textual features, respectively. Additionally, we design a textual feature refinement module (TFRM) that refines the textual features of the pre-trained BERT encoder by updating the contextual embeddings. This module enhances the discriminative power of textual features with a cross-modal projection loss and realigns the word and caption embeddings with visual features by incorporating a visual-semantic alignment loss. We implemented the proposed CGFR framework on two face recognition models (ArcFace and AdaFace) and evaluated its performance on the Multi-Modal CelebA-HQ dataset. Our framework significantly improves the performance of ArcFace in both 1:1 verification and 1:N identification protocol.
Stealthy Physical Masked Face Recognition Attack via Adversarial Style Optimization
Sep 18, 2023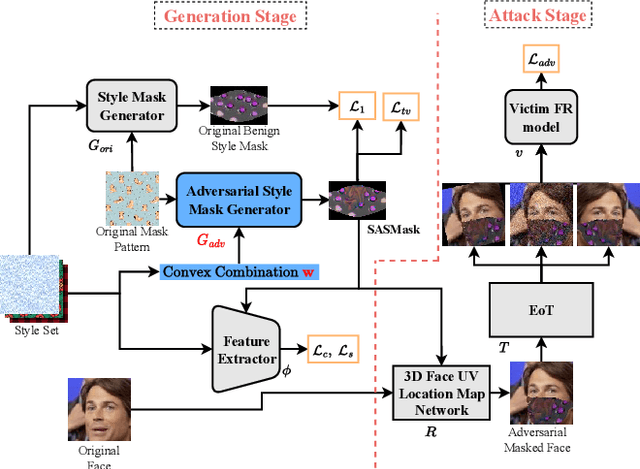
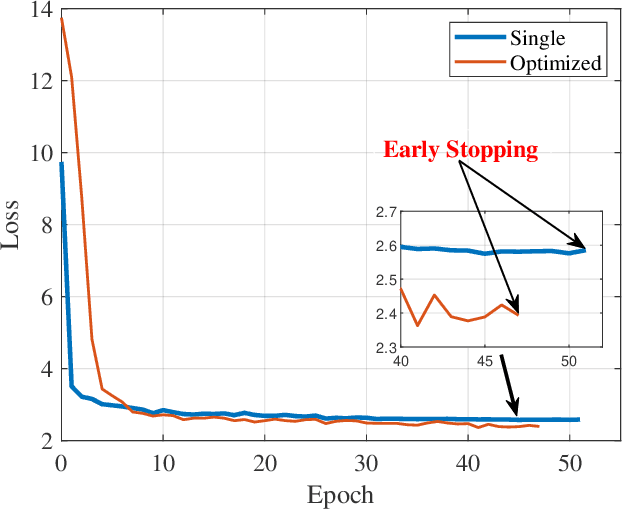

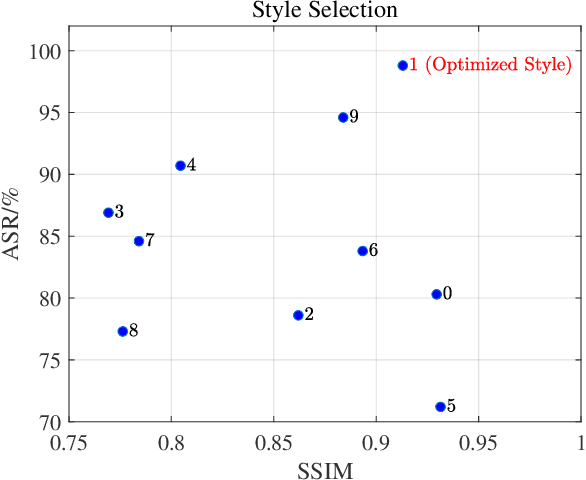
Deep neural networks (DNNs) have achieved state-of-the-art performance on face recognition (FR) tasks in the last decade. In real scenarios, the deployment of DNNs requires taking various face accessories into consideration, like glasses, hats, and masks. In the COVID-19 pandemic era, wearing face masks is one of the most effective ways to defend against the novel coronavirus. However, DNNs are known to be vulnerable to adversarial examples with a small but elaborated perturbation. Thus, a facial mask with adversarial perturbations may pose a great threat to the widely used deep learning-based FR models. In this paper, we consider a challenging adversarial setting: targeted attack against FR models. We propose a new stealthy physical masked FR attack via adversarial style optimization. Specifically, we train an adversarial style mask generator that hides adversarial perturbations inside style masks. Moreover, to ameliorate the phenomenon of sub-optimization with one fixed style, we propose to discover the optimal style given a target through style optimization in a continuous relaxation manner. We simultaneously optimize the generator and the style selection for generating strong and stealthy adversarial style masks. We evaluated the effectiveness and transferability of our proposed method via extensive white-box and black-box digital experiments. Furthermore, we also conducted physical attack experiments against local FR models and online platforms.
STAR Loss: Reducing Semantic Ambiguity in Facial Landmark Detection
Jun 05, 2023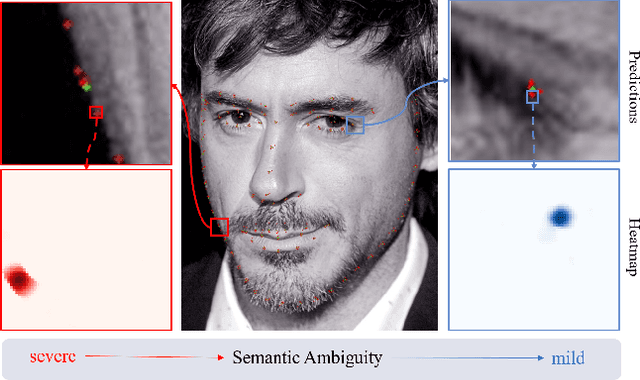
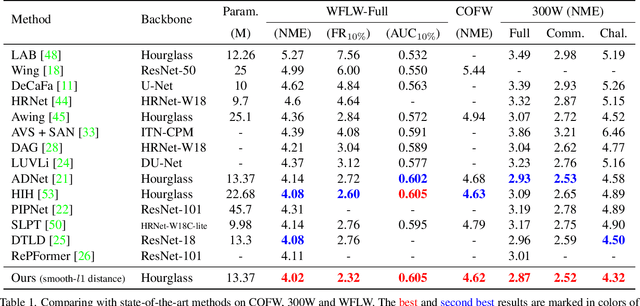
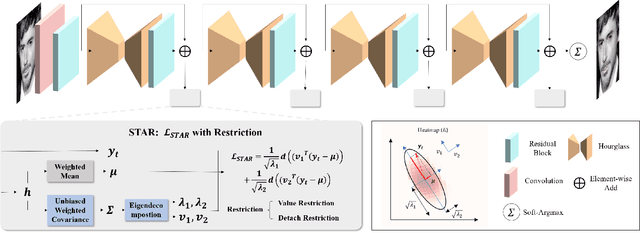
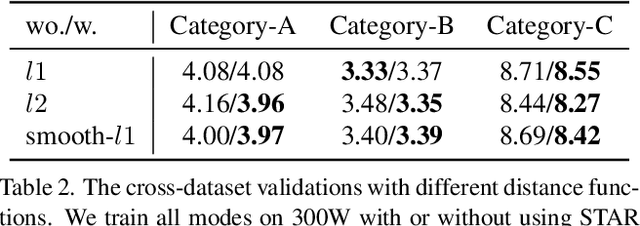
Recently, deep learning-based facial landmark detection has achieved significant improvement. However, the semantic ambiguity problem degrades detection performance. Specifically, the semantic ambiguity causes inconsistent annotation and negatively affects the model's convergence, leading to worse accuracy and instability prediction. To solve this problem, we propose a Self-adapTive Ambiguity Reduction (STAR) loss by exploiting the properties of semantic ambiguity. We find that semantic ambiguity results in the anisotropic predicted distribution, which inspires us to use predicted distribution to represent semantic ambiguity. Based on this, we design the STAR loss that measures the anisotropism of the predicted distribution. Compared with the standard regression loss, STAR loss is encouraged to be small when the predicted distribution is anisotropic and thus adaptively mitigates the impact of semantic ambiguity. Moreover, we propose two kinds of eigenvalue restriction methods that could avoid both distribution's abnormal change and the model's premature convergence. Finally, the comprehensive experiments demonstrate that STAR loss outperforms the state-of-the-art methods on three benchmarks, i.e., COFW, 300W, and WFLW, with negligible computation overhead. Code is at https://github.com/ZhenglinZhou/STAR.
Toward Fair Facial Expression Recognition with Improved Distribution Alignment
Jun 11, 2023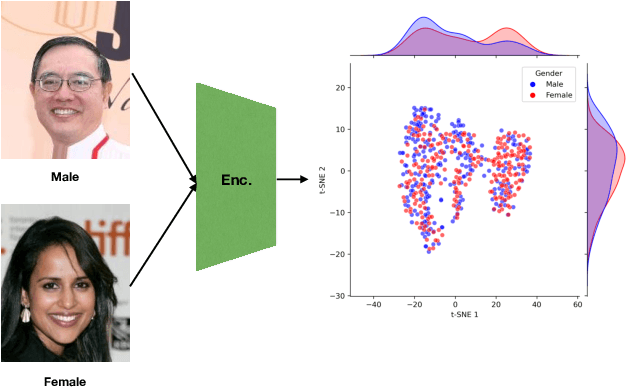
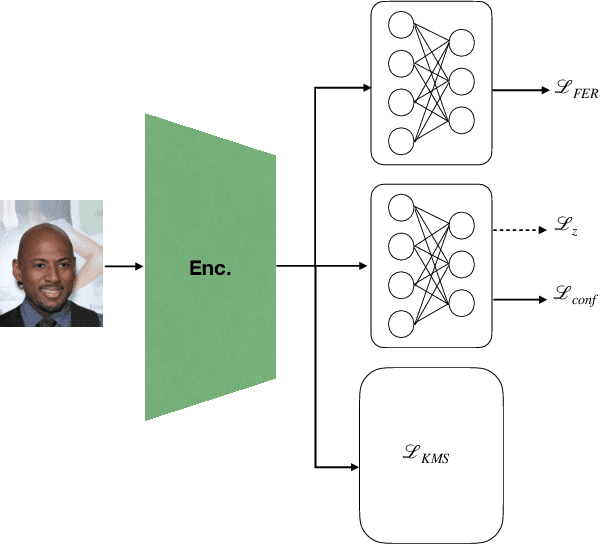
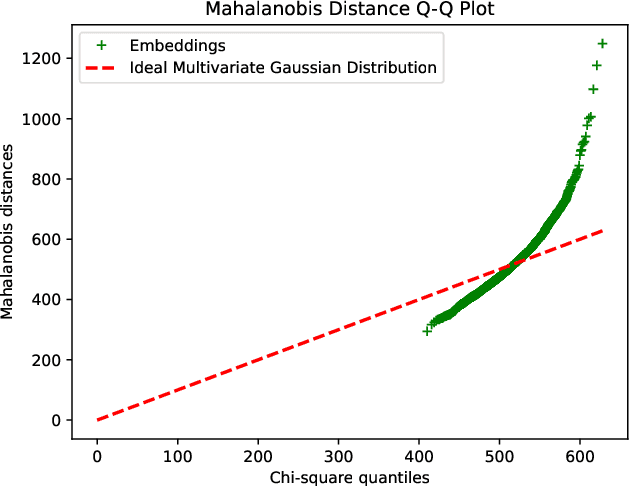
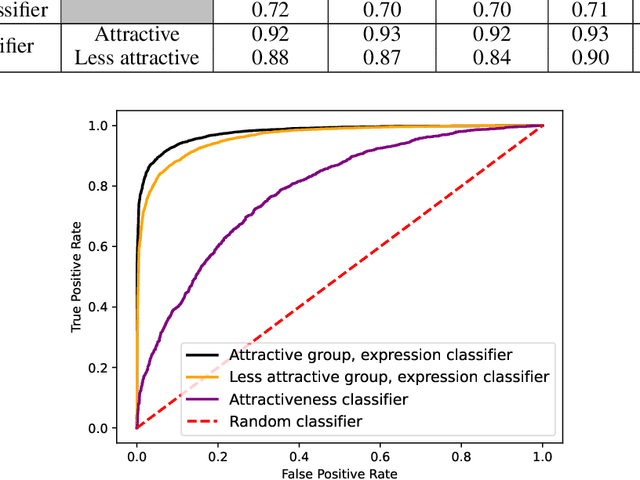
We present a novel approach to mitigate bias in facial expression recognition (FER) models. Our method aims to reduce sensitive attribute information such as gender, age, or race, in the embeddings produced by FER models. We employ a kernel mean shrinkage estimator to estimate the kernel mean of the distributions of the embeddings associated with different sensitive attribute groups, such as young and old, in the Hilbert space. Using this estimation, we calculate the maximum mean discrepancy (MMD) distance between the distributions and incorporate it in the classifier loss along with an adversarial loss, which is then minimized through the learning process to improve the distribution alignment. Our method makes sensitive attributes less recognizable for the model, which in turn promotes fairness. Additionally, for the first time, we analyze the notion of attractiveness as an important sensitive attribute in FER models and demonstrate that FER models can indeed exhibit biases towards more attractive faces. To prove the efficacy of our model in reducing bias regarding different sensitive attributes (including the newly proposed attractiveness attribute), we perform several experiments on two widely used datasets, CelebA and RAF-DB. The results in terms of both accuracy and fairness measures outperform the state-of-the-art in most cases, demonstrating the effectiveness of the proposed method.
Trading-off Mutual Information on Feature Aggregation for Face Recognition
Sep 22, 2023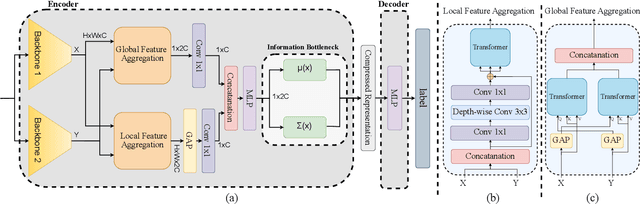
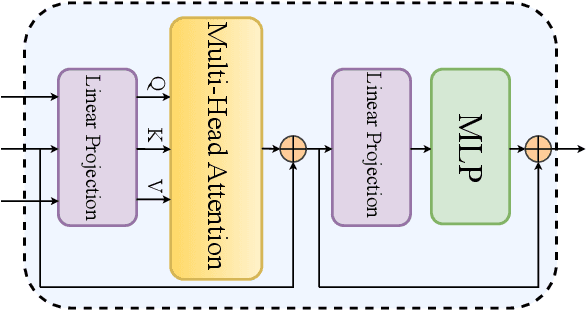
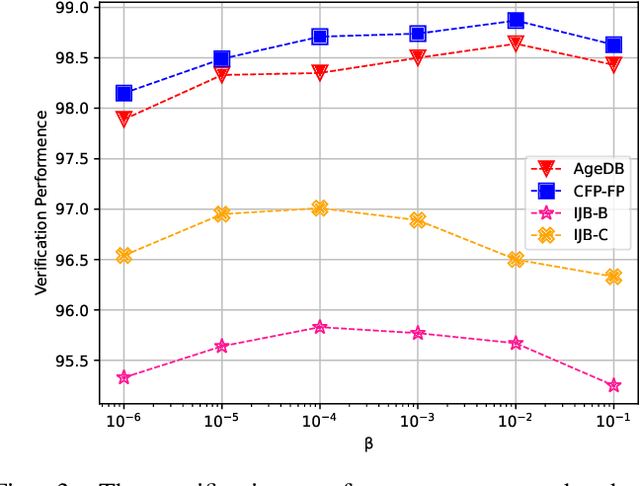
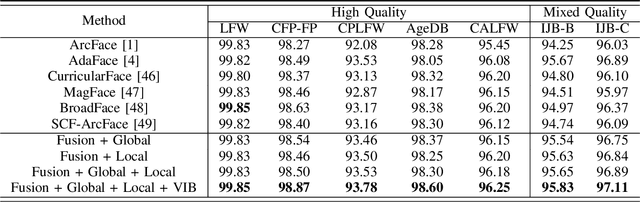
Despite the advances in the field of Face Recognition (FR), the precision of these methods is not yet sufficient. To improve the FR performance, this paper proposes a technique to aggregate the outputs of two state-of-the-art (SOTA) deep FR models, namely ArcFace and AdaFace. In our approach, we leverage the transformer attention mechanism to exploit the relationship between different parts of two feature maps. By doing so, we aim to enhance the overall discriminative power of the FR system. One of the challenges in feature aggregation is the effective modeling of both local and global dependencies. Conventional transformers are known for their ability to capture long-range dependencies, but they often struggle with modeling local dependencies accurately. To address this limitation, we augment the self-attention mechanism to capture both local and global dependencies effectively. This allows our model to take advantage of the overlapping receptive fields present in corresponding locations of the feature maps. However, fusing two feature maps from different FR models might introduce redundancies to the face embedding. Since these models often share identical backbone architectures, the resulting feature maps may contain overlapping information, which can mislead the training process. To overcome this problem, we leverage the principle of Information Bottleneck to obtain a maximally informative facial representation. This ensures that the aggregated features retain the most relevant and discriminative information while minimizing redundant or misleading details. To evaluate the effectiveness of our proposed method, we conducted experiments on popular benchmarks and compared our results with state-of-the-art algorithms. The consistent improvement we observed in these benchmarks demonstrates the efficacy of our approach in enhancing FR performance.
VEATIC: Video-based Emotion and Affect Tracking in Context Dataset
Sep 15, 2023
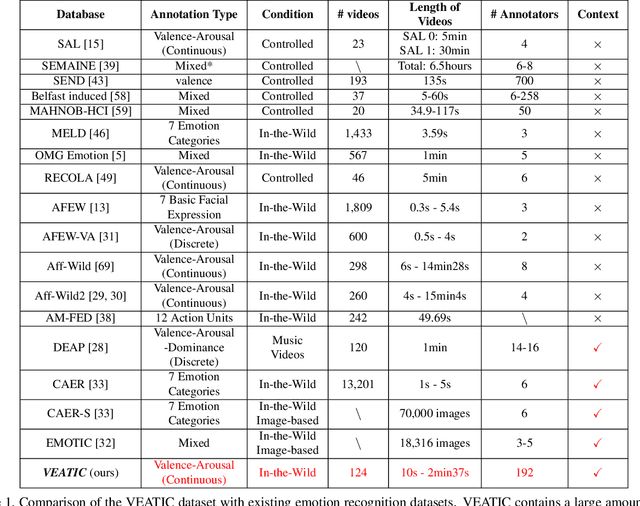

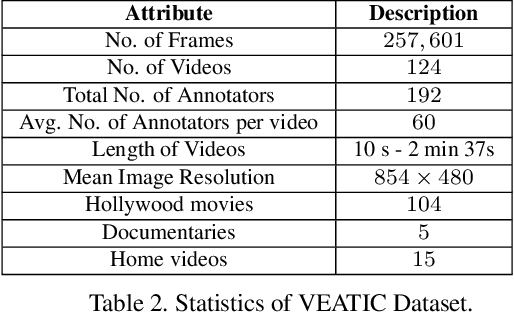
Human affect recognition has been a significant topic in psychophysics and computer vision. However, the currently published datasets have many limitations. For example, most datasets contain frames that contain only information about facial expressions. Due to the limitations of previous datasets, it is very hard to either understand the mechanisms for affect recognition of humans or generalize well on common cases for computer vision models trained on those datasets. In this work, we introduce a brand new large dataset, the Video-based Emotion and Affect Tracking in Context Dataset (VEATIC), that can conquer the limitations of the previous datasets. VEATIC has 124 video clips from Hollywood movies, documentaries, and home videos with continuous valence and arousal ratings of each frame via real-time annotation. Along with the dataset, we propose a new computer vision task to infer the affect of the selected character via both context and character information in each video frame. Additionally, we propose a simple model to benchmark this new computer vision task. We also compare the performance of the pretrained model using our dataset with other similar datasets. Experiments show the competing results of our pretrained model via VEATIC, indicating the generalizability of VEATIC. Our dataset is available at https://veatic.github.io.
Unsupervised Gaze-aware Contrastive Learning with Subject-specific Condition
Sep 08, 2023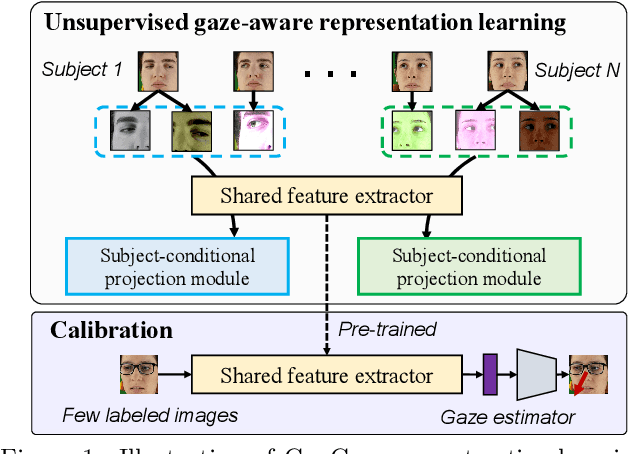
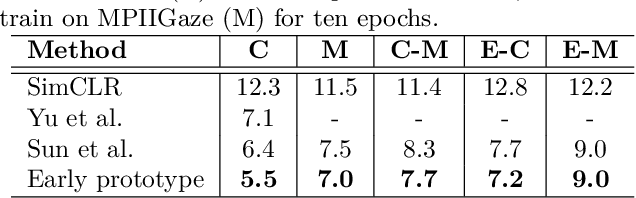
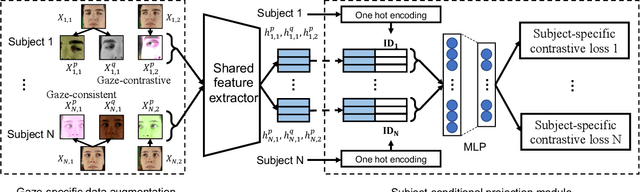
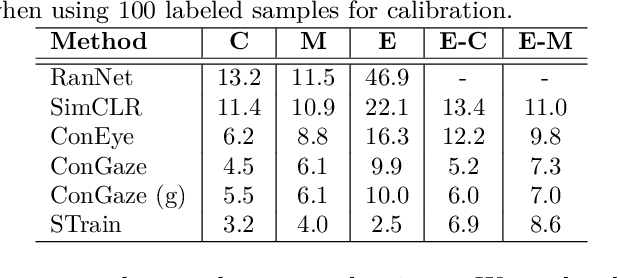
Appearance-based gaze estimation has shown great promise in many applications by using a single general-purpose camera as the input device. However, its success is highly depending on the availability of large-scale well-annotated gaze datasets, which are sparse and expensive to collect. To alleviate this challenge we propose ConGaze, a contrastive learning-based framework that leverages unlabeled facial images to learn generic gaze-aware representations across subjects in an unsupervised way. Specifically, we introduce the gaze-specific data augmentation to preserve the gaze-semantic features and maintain the gaze consistency, which are proven to be crucial for effective contrastive gaze representation learning. Moreover, we devise a novel subject-conditional projection module that encourages a share feature extractor to learn gaze-aware and generic representations. Our experiments on three public gaze estimation datasets show that ConGaze outperforms existing unsupervised learning solutions by 6.7% to 22.5%; and achieves 15.1% to 24.6% improvement over its supervised learning-based counterpart in cross-dataset evaluations.
Dual Associated Encoder for Face Restoration
Aug 14, 2023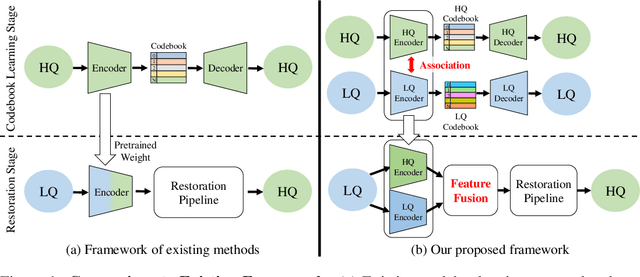

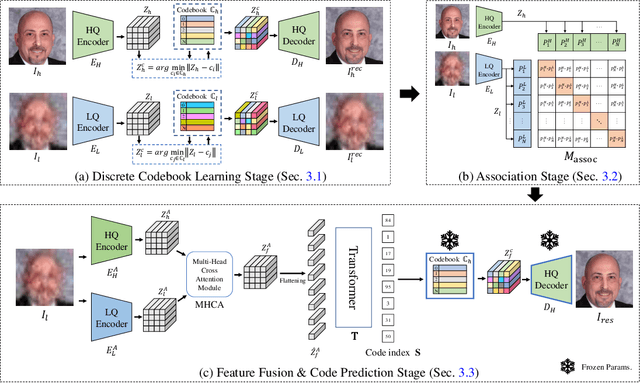

Restoring facial details from low-quality (LQ) images has remained a challenging problem due to its ill-posedness induced by various degradations in the wild. The existing codebook prior mitigates the ill-posedness by leveraging an autoencoder and learned codebook of high-quality (HQ) features, achieving remarkable quality. However, existing approaches in this paradigm frequently depend on a single encoder pre-trained on HQ data for restoring HQ images, disregarding the domain gap between LQ and HQ images. As a result, the encoding of LQ inputs may be insufficient, resulting in suboptimal performance. To tackle this problem, we propose a novel dual-branch framework named DAEFR. Our method introduces an auxiliary LQ branch that extracts crucial information from the LQ inputs. Additionally, we incorporate association training to promote effective synergy between the two branches, enhancing code prediction and output quality. We evaluate the effectiveness of DAEFR on both synthetic and real-world datasets, demonstrating its superior performance in restoring facial details.