 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Improving the Accuracy of Beauty Product Recommendations by Assessing Face Illumination Quality
Sep 07, 2023
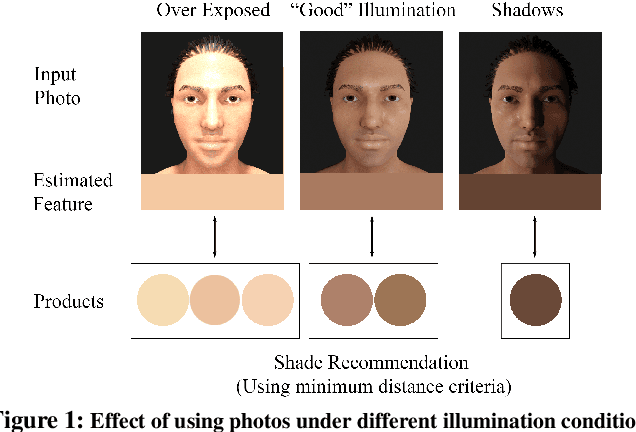
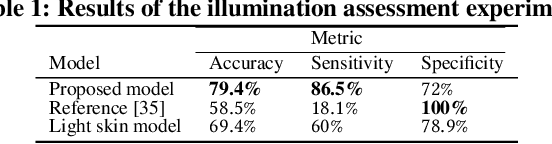
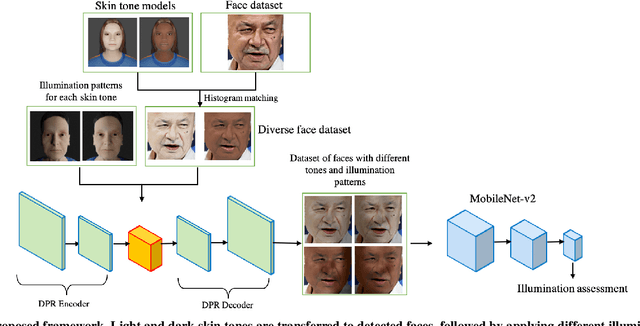
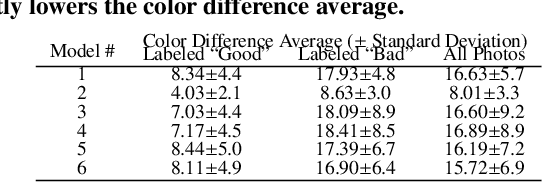
We focus on addressing the challenges in responsible beauty product recommendation, particularly when it involves comparing the product's color with a person's skin tone, such as for foundation and concealer products. To make accurate recommendations, it is crucial to infer both the product attributes and the product specific facial features such as skin conditions or tone. However, while many product photos are taken under good light conditions, face photos are taken from a wide range of conditions. The features extracted using the photos from ill-illuminated environment can be highly misleading or even be incompatible to be compared with the product attributes. Hence bad illumination condition can severely degrade quality of the recommendation. We introduce a machine learning framework for illumination assessment which classifies images into having either good or bad illumination condition. We then build an automatic user guidance tool which informs a user holding their camera if their illumination condition is good or bad. This way, the user is provided with rapid feedback and can interactively control how the photo is taken for their recommendation. Only a few studies are dedicated to this problem, mostly due to the lack of dataset that is large, labeled, and diverse both in terms of skin tones and light patterns. Lack of such dataset leads to neglecting skin tone diversity. Therefore, We begin by constructing a diverse synthetic dataset that simulates various skin tones and light patterns in addition to an existing facial image dataset. Next, we train a Convolutional Neural Network (CNN) for illumination assessment that outperforms the existing solutions using the synthetic dataset. Finally, we analyze how the our work improves the shade recommendation for various foundation products.
GAME: Generalized deep learning model towards multimodal data integration for early screening of adolescent mental disorders
Sep 18, 2023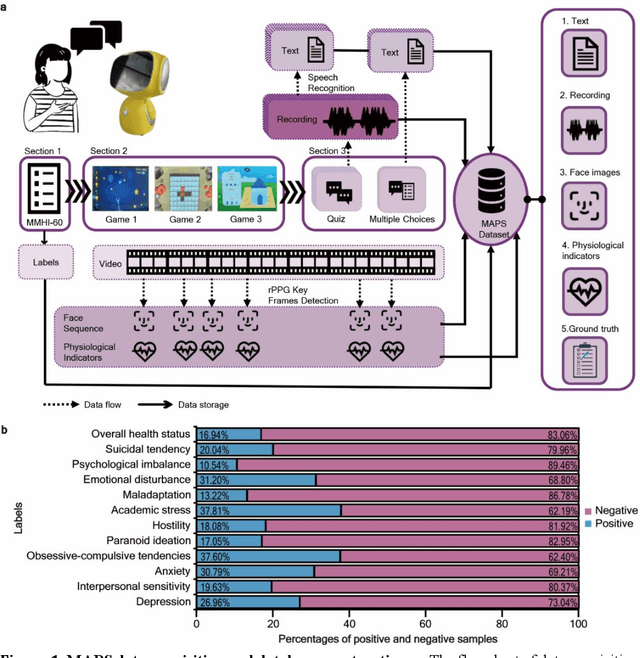
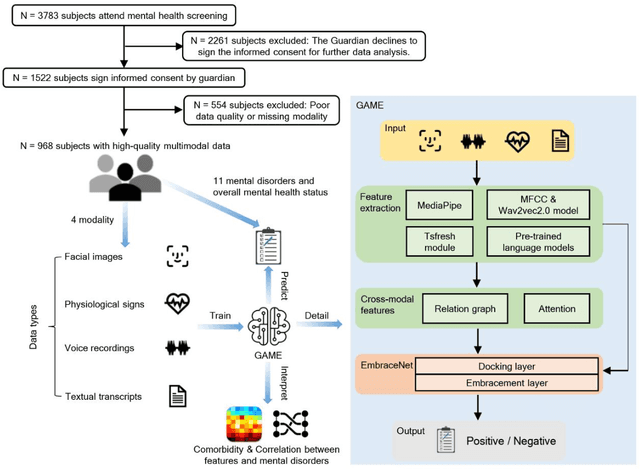
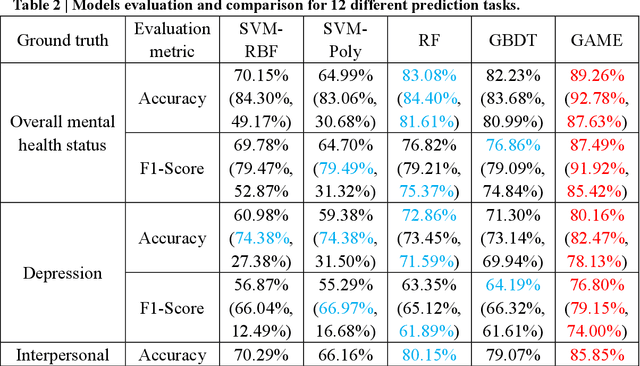
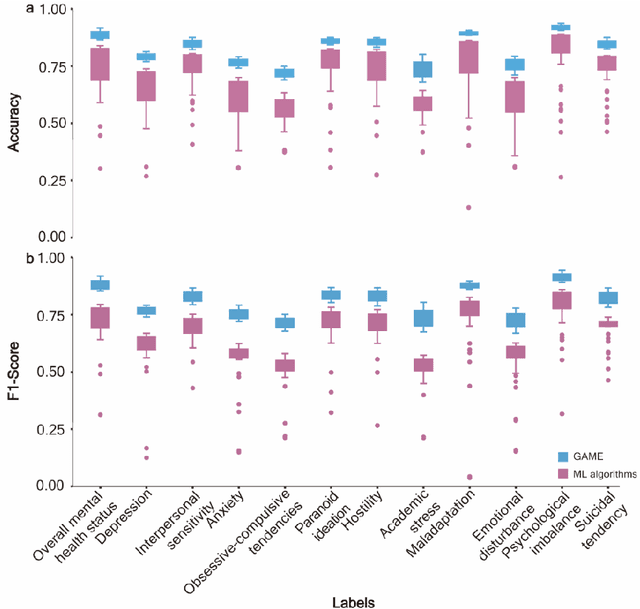
The timely identification of mental disorders in adolescents is a global public health challenge.Single factor is difficult to detect the abnormality due to its complex and subtle nature. Additionally, the generalized multimodal Computer-Aided Screening (CAS) systems with interactive robots for adolescent mental disorders are not available. Here, we design an android application with mini-games and chat recording deployed in a portable robot to screen 3,783 middle school students and construct the multimodal screening dataset, including facial images, physiological signs, voice recordings, and textual transcripts.We develop a model called GAME (Generalized Model with Attention and Multimodal EmbraceNet) with novel attention mechanism that integrates cross-modal features into the model. GAME evaluates adolescent mental conditions with high accuracy (73.34%-92.77%) and F1-Score (71.32%-91.06%).We find each modality contributes dynamically to the mental disorders screening and comorbidities among various mental disorders, indicating the feasibility of explainable model. This study provides a system capable of acquiring multimodal information and constructs a generalized multimodal integration algorithm with novel attention mechanisms for the early screening of adolescent mental disorders.
Precise Facial Landmark Detection by Reference Heatmap Transformer
Mar 14, 2023
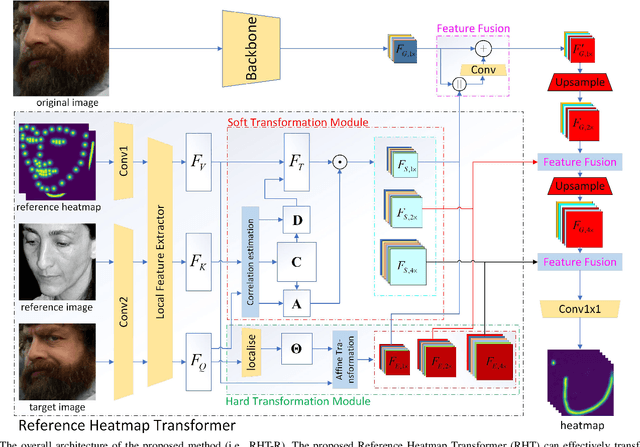
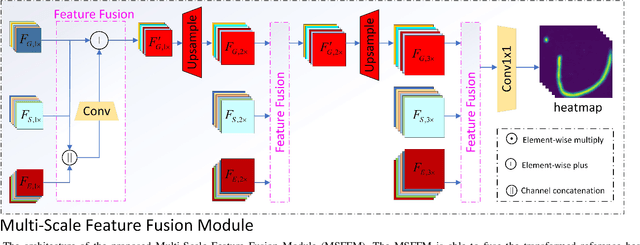

Most facial landmark detection methods predict landmarks by mapping the input facial appearance features to landmark heatmaps and have achieved promising results. However, when the face image is suffering from large poses, heavy occlusions and complicated illuminations, they cannot learn discriminative feature representations and effective facial shape constraints, nor can they accurately predict the value of each element in the landmark heatmap, limiting their detection accuracy. To address this problem, we propose a novel Reference Heatmap Transformer (RHT) by introducing reference heatmap information for more precise facial landmark detection. The proposed RHT consists of a Soft Transformation Module (STM) and a Hard Transformation Module (HTM), which can cooperate with each other to encourage the accurate transformation of the reference heatmap information and facial shape constraints. Then, a Multi-Scale Feature Fusion Module (MSFFM) is proposed to fuse the transformed heatmap features and the semantic features learned from the original face images to enhance feature representations for producing more accurate target heatmaps. To the best of our knowledge, this is the first study to explore how to enhance facial landmark detection by transforming the reference heatmap information. The experimental results from challenging benchmark datasets demonstrate that our proposed method outperforms the state-of-the-art methods in the literature.
Collaborative Feature Learning for Fine-grained Facial Forgery Detection and Segmentation
Apr 17, 2023
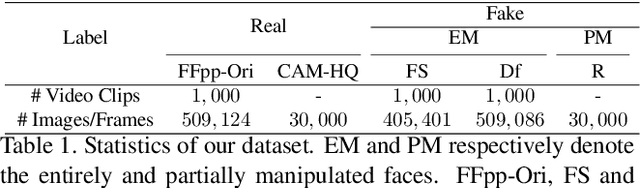

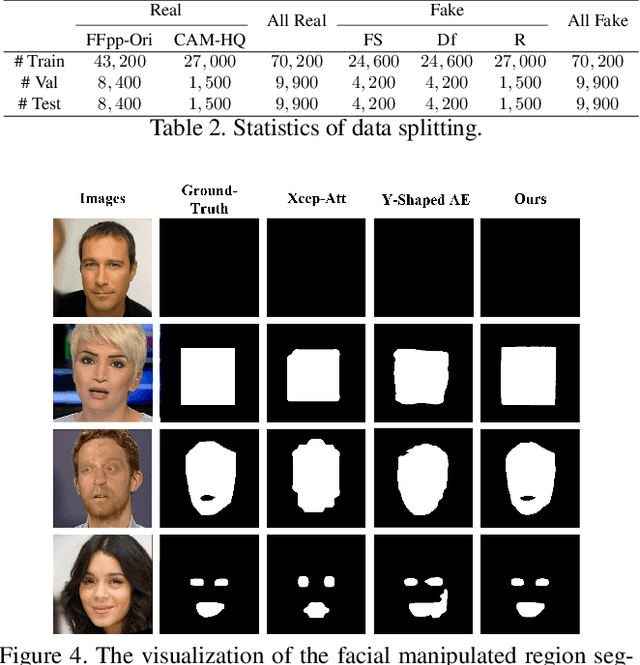
Detecting maliciously falsified facial images and videos has attracted extensive attention from digital-forensics and computer-vision communities. An important topic in manipulation detection is the localization of the fake regions. Previous work related to forgery detection mostly focuses on the entire faces. However, recent forgery methods have developed to edit important facial components while maintaining others unchanged. This drives us to not only focus on the forgery detection but also fine-grained falsified region segmentation. In this paper, we propose a collaborative feature learning approach to simultaneously detect manipulation and segment the falsified components. With the collaborative manner, detection and segmentation can boost each other efficiently. To enable our study of forgery detection and segmentation, we build a facial forgery dataset consisting of both entire and partial face forgeries with their pixel-level manipulation ground-truth. Experiment results have justified the mutual promotion between forgery detection and manipulated region segmentation. The overall performance of the proposed approach is better than the state-of-the-art detection or segmentation approaches. The visualization results have shown that our proposed model always captures the artifacts on facial regions, which is more reasonable.
Micron-BERT: BERT-based Facial Micro-Expression Recognition
Apr 06, 2023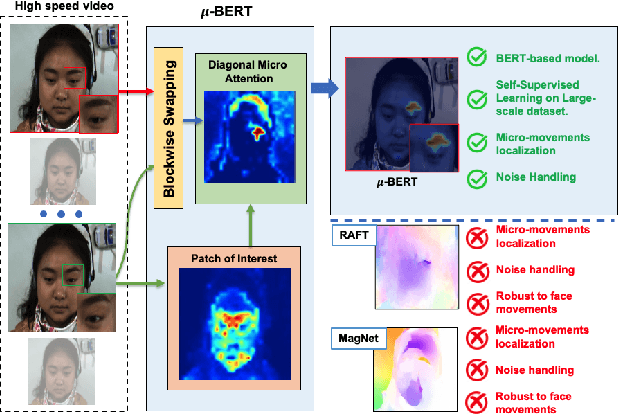
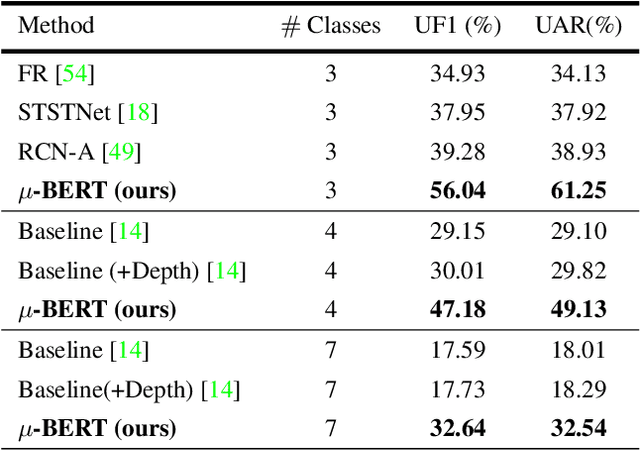
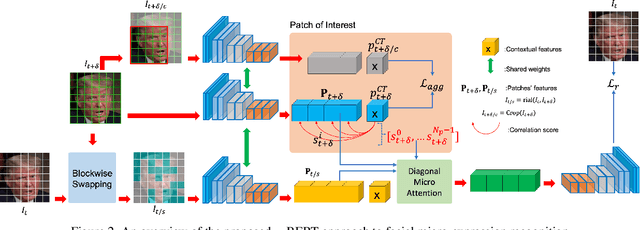
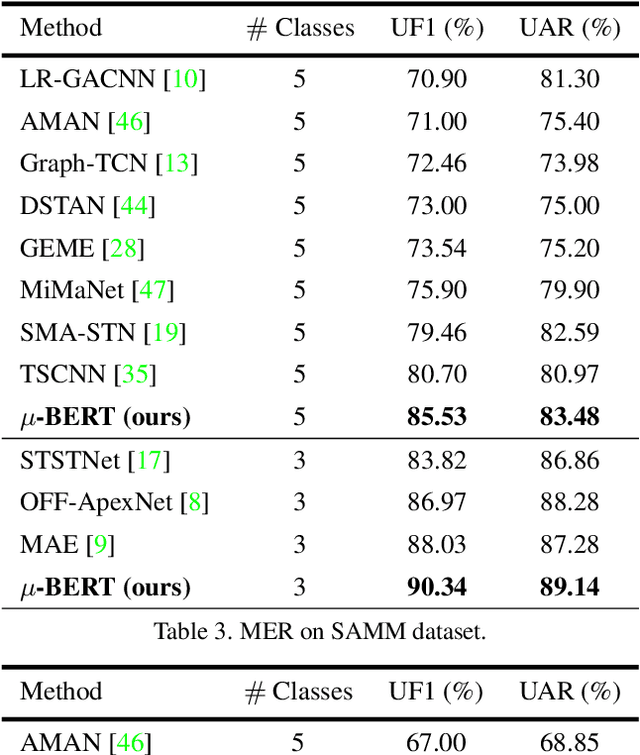
Micro-expression recognition is one of the most challenging topics in affective computing. It aims to recognize tiny facial movements difficult for humans to perceive in a brief period, i.e., 0.25 to 0.5 seconds. Recent advances in pre-training deep Bidirectional Transformers (BERT) have significantly improved self-supervised learning tasks in computer vision. However, the standard BERT in vision problems is designed to learn only from full images or videos, and the architecture cannot accurately detect details of facial micro-expressions. This paper presents Micron-BERT ($\mu$-BERT), a novel approach to facial micro-expression recognition. The proposed method can automatically capture these movements in an unsupervised manner based on two key ideas. First, we employ Diagonal Micro-Attention (DMA) to detect tiny differences between two frames. Second, we introduce a new Patch of Interest (PoI) module to localize and highlight micro-expression interest regions and simultaneously reduce noisy backgrounds and distractions. By incorporating these components into an end-to-end deep network, the proposed $\mu$-BERT significantly outperforms all previous work in various micro-expression tasks. $\mu$-BERT can be trained on a large-scale unlabeled dataset, i.e., up to 8 million images, and achieves high accuracy on new unseen facial micro-expression datasets. Empirical experiments show $\mu$-BERT consistently outperforms state-of-the-art performance on four micro-expression benchmarks, including SAMM, CASME II, SMIC, and CASME3, by significant margins. Code will be available at \url{https://github.com/uark-cviu/Micron-BERT}
Can Language Models Learn to Listen?
Aug 21, 2023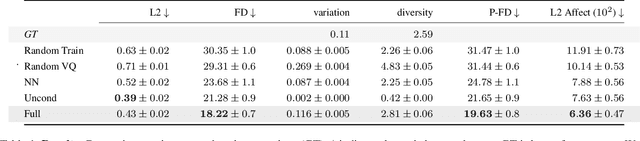
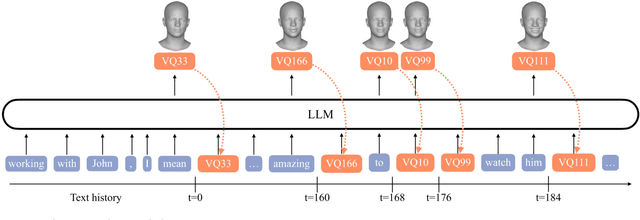

We present a framework for generating appropriate facial responses from a listener in dyadic social interactions based on the speaker's words. Given an input transcription of the speaker's words with their timestamps, our approach autoregressively predicts a response of a listener: a sequence of listener facial gestures, quantized using a VQ-VAE. Since gesture is a language component, we propose treating the quantized atomic motion elements as additional language token inputs to a transformer-based large language model. Initializing our transformer with the weights of a language model pre-trained only on text results in significantly higher quality listener responses than training a transformer from scratch. We show that our generated listener motion is fluent and reflective of language semantics through quantitative metrics and a qualitative user study. In our evaluation, we analyze the model's ability to utilize temporal and semantic aspects of spoken text. Project page: https://people.eecs.berkeley.edu/~evonne_ng/projects/text2listen/
GAN-based Algorithm for Efficient Image Inpainting
Sep 13, 2023Global pandemic due to the spread of COVID-19 has post challenges in a new dimension on facial recognition, where people start to wear masks. Under such condition, the authors consider utilizing machine learning in image inpainting to tackle the problem, by complete the possible face that is originally covered in mask. In particular, autoencoder has great potential on retaining important, general features of the image as well as the generative power of the generative adversarial network (GAN). The authors implement a combination of the two models, context encoders and explain how it combines the power of the two models and train the model with 50,000 images of influencers faces and yields a solid result that still contains space for improvements. Furthermore, the authors discuss some shortcomings with the model, their possible improvements, as well as some area of study for future investigation for applicative perspective, as well as directions to further enhance and refine the model.
Unsupervised Facial Expression Representation Learning with Contrastive Local Warping
Mar 16, 2023
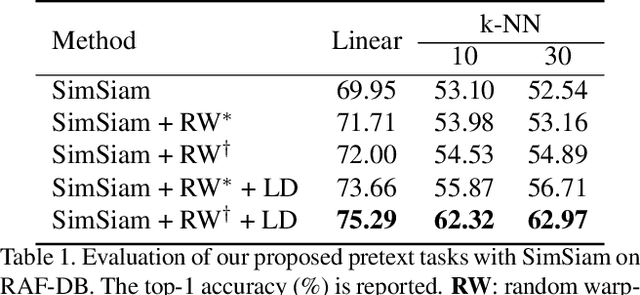
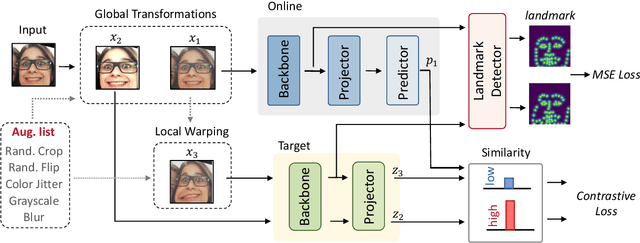
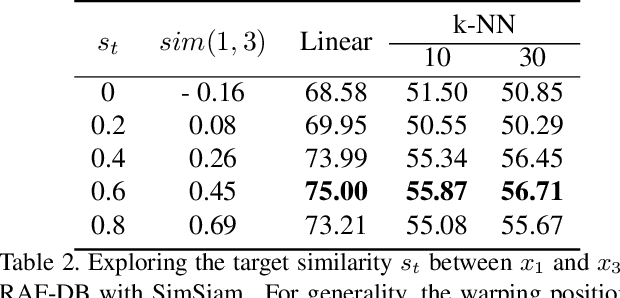
This paper investigates unsupervised representation learning for facial expression analysis. We think Unsupervised Facial Expression Representation (UFER) deserves exploration and has the potential to address some key challenges in facial expression analysis, such as scaling, annotation bias, the discrepancy between discrete labels and continuous emotions, and model pre-training. Such motivated, we propose a UFER method with contrastive local warping (ContraWarping), which leverages the insight that the emotional expression is robust to current global transformation (affine transformation, color jitter, etc.) but can be easily changed by random local warping. Therefore, given a facial image, ContraWarping employs some global transformations and local warping to generate its positive and negative samples and sets up a novel contrastive learning framework. Our in-depth investigation shows that: 1) the positive pairs from global transformations may be exploited with general self-supervised learning (e.g., BYOL) and already bring some informative features, and 2) the negative pairs from local warping explicitly introduce expression-related variation and further bring substantial improvement. Based on ContraWarping, we demonstrate the benefit of UFER under two facial expression analysis scenarios: facial expression recognition and image retrieval. For example, directly using ContraWarping features for linear probing achieves 79.14% accuracy on RAF-DB, significantly reducing the gap towards the full-supervised counterpart (88.92% / 84.81% with/without pre-training).
Hybrid Models for Facial Emotion Recognition in Children
Aug 24, 2023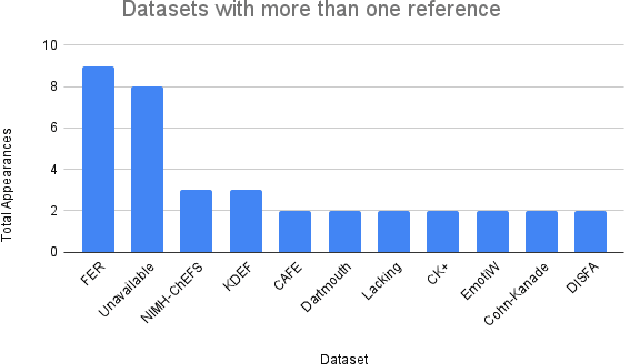
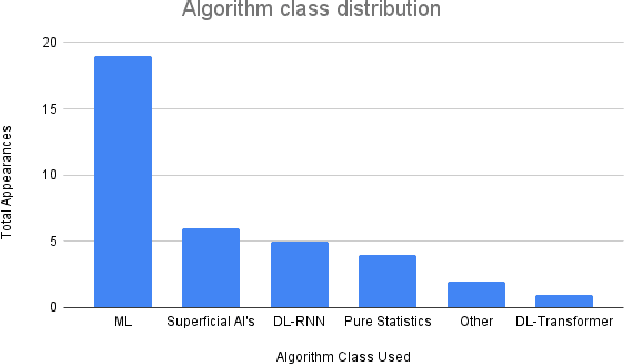
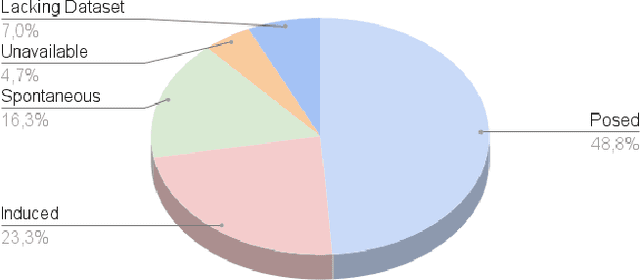
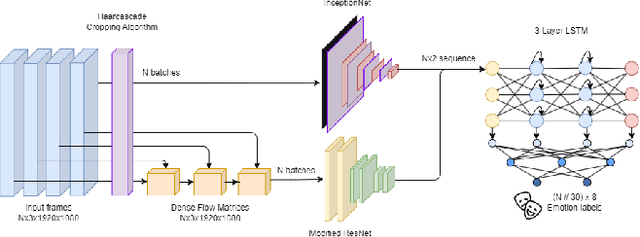
This paper focuses on the use of emotion recognition techniques to assist psychologists in performing children's therapy through remotely robot operated sessions. In the field of psychology, the use of agent-mediated therapy is growing increasingly given recent advances in robotics and computer science. Specifically, the use of Embodied Conversational Agents (ECA) as an intermediary tool can help professionals connect with children who face social challenges such as Attention Deficit Hyperactivity Disorder (ADHD), Autism Spectrum Disorder (ASD) or even who are physically unavailable due to being in regions of armed conflict, natural disasters, or other circumstances. In this context, emotion recognition represents an important feedback for the psychotherapist. In this article, we initially present the result of a bibliographical research associated with emotion recognition in children. This research revealed an initial overview on algorithms and datasets widely used by the community. Then, based on the analysis carried out on the results of the bibliographical research, we used the technique of dense optical flow features to improve the ability of identifying emotions in children in uncontrolled environments. From the output of a hybrid model of Convolutional Neural Network, two intermediary features are fused before being processed by a final classifier. The proposed architecture was called HybridCNNFusion. Finally, we present the initial results achieved in the recognition of children's emotions using a dataset of Brazilian children.
Fuzzy Approach for Audio-Video Emotion Recognition in Computer Games for Children
Aug 31, 2023Computer games are widespread nowadays and enjoyed by people of all ages. But when it comes to kids, playing these games can be more than just fun, it is a way for them to develop important skills and build emotional intelligence. Facial expressions and sounds that kids produce during gameplay reflect their feelings, thoughts, and moods. In this paper, we propose a novel framework that integrates a fuzzy approach for the recognition of emotions through the analysis of audio and video data. Our focus lies within the specific context of computer games tailored for children, aiming to enhance their overall user experience. We use the FER dataset to detect facial emotions in video frames recorded from the screen during the game. For the audio emotion recognition of sounds a kid produces during the game, we use CREMA-D, TESS, RAVDESS, and Savee datasets. Next, a fuzzy inference system is used for the fusion of results. Besides this, our system can detect emotion stability and emotion diversity during gameplay, which, together with prevailing emotion report, can serve as valuable information for parents worrying about the effect of certain games on their kids. The proposed approach has shown promising results in the preliminary experiments we conducted, involving 3 different video games, namely fighting, racing, and logic games, and providing emotion-tracking results for kids in each game. Our study can contribute to the advancement of child-oriented game development, which is not only engaging but also accounts for children's cognitive and emotional states.