 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Embedding Aggregation for Forensic Facial Comparison
Apr 29, 2023
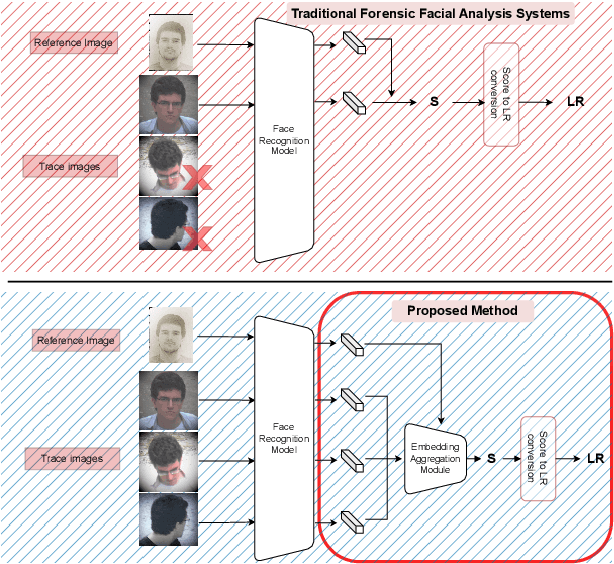
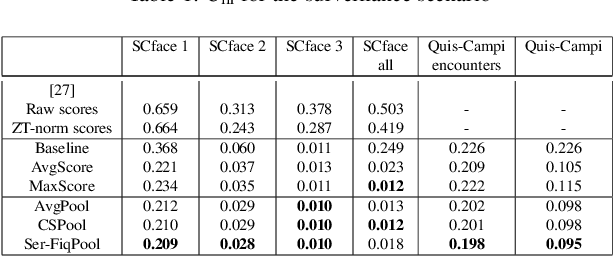

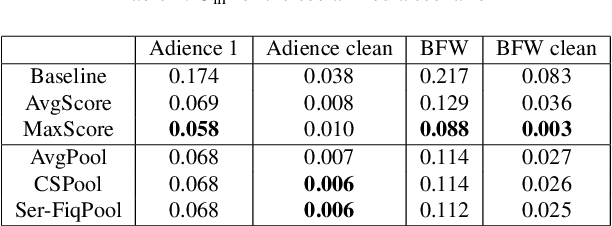
In forensic facial comparison, questioned-source images are usually captured in uncontrolled environments, with non-uniform lighting, and from non-cooperative subjects. The poor quality of such material usually compromises their value as evidence in legal matters. On the other hand, in forensic casework, multiple images of the person of interest are usually available. In this paper, we propose to aggregate deep neural network embeddings from various images of the same person to improve performance in facial verification. We observe significant performance improvements, especially for very low-quality images. Further improvements are obtained by aggregating embeddings of more images and by applying quality-weighted aggregation. We demonstrate the benefits of this approach in forensic evaluation settings with the development and validation of score-based likelihood ratio systems and report improvements in Cllr of up to 95% (from 0.249 to 0.012) for CCTV images and of up to 96% (from 0.083 to 0.003) for social media images.
Occlusion-Aware Deep Convolutional Neural Network via Homogeneous Tanh-transforms for Face Parsing
Aug 29, 2023Face parsing infers a pixel-wise label map for each semantic facial component. Previous methods generally work well for uncovered faces, however overlook the facial occlusion and ignore some contextual area outside a single face, especially when facial occlusion has become a common situation during the COVID-19 epidemic. Inspired by the illumination theory of image, we propose a novel homogeneous tanh-transforms for image preprocessing, which made up of four tanh-transforms, that fuse the central vision and the peripheral vision together. Our proposed method addresses the dilemma of face parsing under occlusion and compresses more information of surrounding context. Based on homogeneous tanh-transforms, we propose an occlusion-aware convolutional neural network for occluded face parsing. It combines the information both in Tanh-polar space and Tanh-Cartesian space, capable of enhancing receptive fields. Furthermore, we introduce an occlusion-aware loss to focus on the boundaries of occluded regions. The network is simple and flexible, and can be trained end-to-end. To facilitate future research of occluded face parsing, we also contribute a new cleaned face parsing dataset, which is manually purified from several academic or industrial datasets, including CelebAMask-HQ, Short-video Face Parsing as well as Helen dataset and will make it public. Experiments demonstrate that our method surpasses state-of-art methods of face parsing under occlusion.
Survey on Deep Face Restoration: From Non-blind to Blind and Beyond
Sep 27, 2023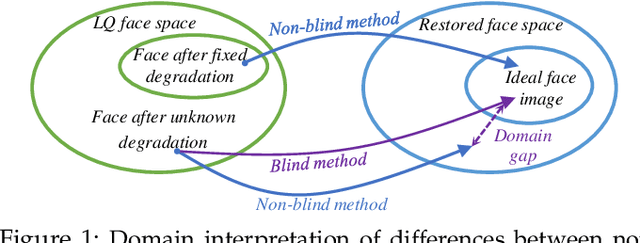

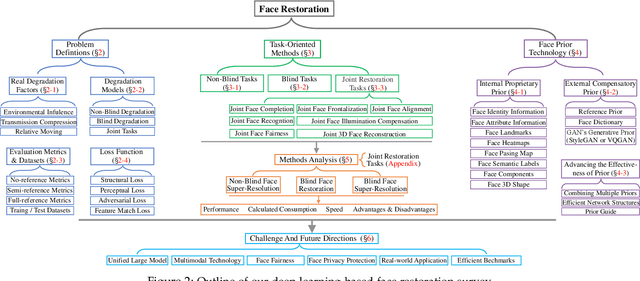

Face restoration (FR) is a specialized field within image restoration that aims to recover low-quality (LQ) face images into high-quality (HQ) face images. Recent advances in deep learning technology have led to significant progress in FR methods. In this paper, we begin by examining the prevalent factors responsible for real-world LQ images and introduce degradation techniques used to synthesize LQ images. We also discuss notable benchmarks commonly utilized in the field. Next, we categorize FR methods based on different tasks and explain their evolution over time. Furthermore, we explore the various facial priors commonly utilized in the restoration process and discuss strategies to enhance their effectiveness. In the experimental section, we thoroughly evaluate the performance of state-of-the-art FR methods across various tasks using a unified benchmark. We analyze their performance from different perspectives. Finally, we discuss the challenges faced in the field of FR and propose potential directions for future advancements. The open-source repository corresponding to this work can be found at https:// github.com/ 24wenjie-li/ Awesome-Face-Restoration.
Sarcasm in Sight and Sound: Benchmarking and Expansion to Improve Multimodal Sarcasm Detection
Sep 29, 2023
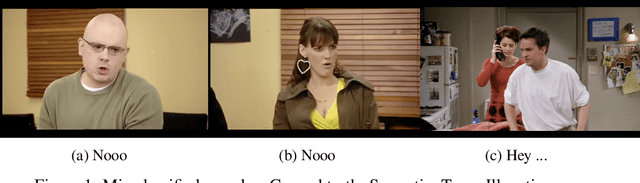

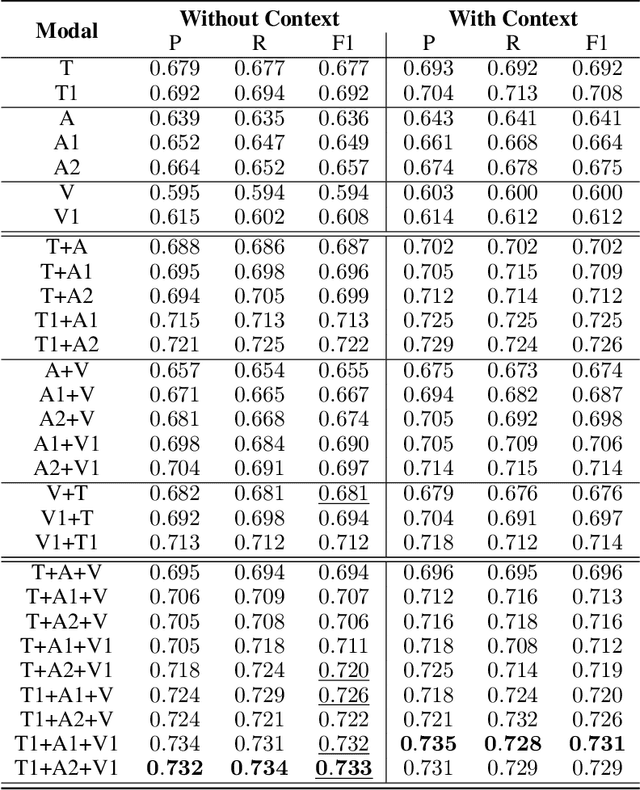
The introduction of the MUStARD dataset, and its emotion recognition extension MUStARD++, have identified sarcasm to be a multi-modal phenomenon -- expressed not only in natural language text, but also through manners of speech (like tonality and intonation) and visual cues (facial expression). With this work, we aim to perform a rigorous benchmarking of the MUStARD++ dataset by considering state-of-the-art language, speech, and visual encoders, for fully utilizing the totality of the multi-modal richness that it has to offer, achieving a 2\% improvement in macro-F1 over the existing benchmark. Additionally, to cure the imbalance in the `sarcasm type' category in MUStARD++, we propose an extension, which we call \emph{MUStARD++ Balanced}, benchmarking the same with instances from the extension split across both train and test sets, achieving a further 2.4\% macro-F1 boost. The new clips were taken from a novel source -- the TV show, House MD, which adds to the diversity of the dataset, and were manually annotated by multiple annotators with substantial inter-annotator agreement in terms of Cohen's kappa and Krippendorf's alpha. Our code, extended data, and SOTA benchmark models are made public.
Acoustic and linguistic representations for speech continuous emotion recognition in call center conversations
Oct 06, 2023The goal of our research is to automatically retrieve the satisfaction and the frustration in real-life call-center conversations. This study focuses an industrial application in which the customer satisfaction is continuously tracked down to improve customer services. To compensate the lack of large annotated emotional databases, we explore the use of pre-trained speech representations as a form of transfer learning towards AlloSat corpus. Moreover, several studies have pointed out that emotion can be detected not only in speech but also in facial trait, in biological response or in textual information. In the context of telephone conversations, we can break down the audio information into acoustic and linguistic by using the speech signal and its transcription. Our experiments confirms the large gain in performance obtained with the use of pre-trained features. Surprisingly, we found that the linguistic content is clearly the major contributor for the prediction of satisfaction and best generalizes to unseen data. Our experiments conclude to the definitive advantage of using CamemBERT representations, however the benefit of the fusion of acoustic and linguistic modalities is not as obvious. With models learnt on individual annotations, we found that fusion approaches are more robust to the subjectivity of the annotation task. This study also tackles the problem of performances variability and intends to estimate this variability from different views: weights initialization, confidence intervals and annotation subjectivity. A deep analysis on the linguistic content investigates interpretable factors able to explain the high contribution of the linguistic modality for this task.
Introduction to Facial Micro Expressions Analysis Using Color and Depth Images: A Matlab Coding Approach (Second Edition, 2023)
Jun 19, 2023
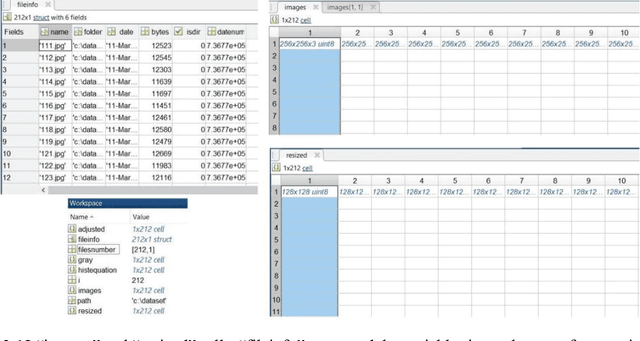
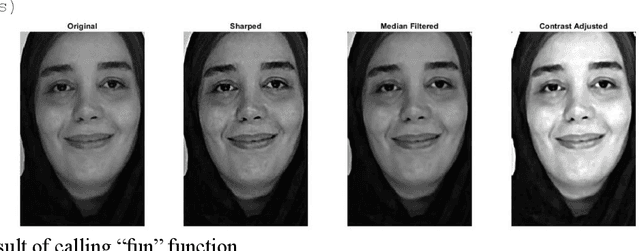
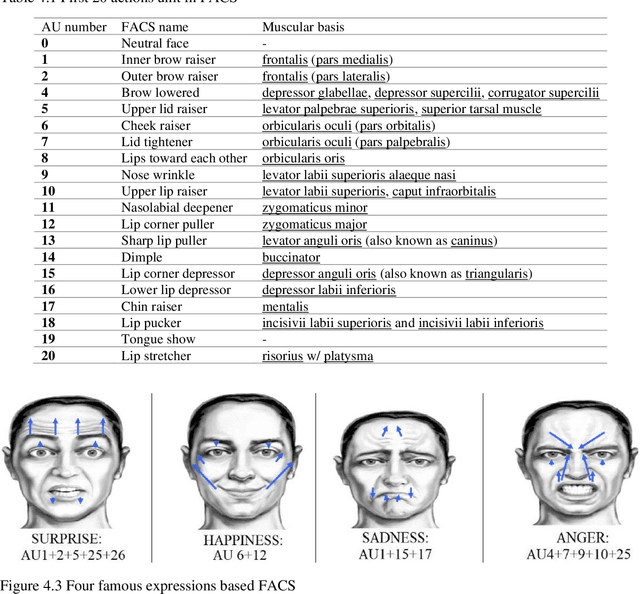
The book attempts to introduce a gentle introduction to the field of Facial Micro Expressions Recognition (FMER) using Color and Depth images, with the aid of MATLAB programming environment. FMER is a subset of image processing and it is a multidisciplinary topic to analysis. So, it requires familiarity with other topics of Artifactual Intelligence (AI) such as machine learning, digital image processing, psychology and more. So, it is a great opportunity to write a book which covers all of these topics for beginner to professional readers in the field of AI and even without having background of AI. Our goal is to provide a standalone introduction in the field of MFER analysis in the form of theorical descriptions for readers with no background in image processing with reproducible Matlab practical examples. Also, we describe any basic definitions for FMER analysis and MATLAB library which is used in the text, that helps final reader to apply the experiments in the real-world applications. We believe that this book is suitable for students, researchers, and professionals alike, who need to develop practical skills, along with a basic understanding of the field. We expect that, after reading this book, the reader feels comfortable with different key stages such as color and depth image processing, color and depth image representation, classification, machine learning, facial micro-expressions recognition, feature extraction and dimensionality reduction. The book attempts to introduce a gentle introduction to the field of Facial Micro Expressions Recognition (FMER) using Color and Depth images, with the aid of MATLAB programming environment.
KeyPosS: Plug-and-Play Facial Landmark Detection through GPS-Inspired True-Range Multilateration
May 25, 2023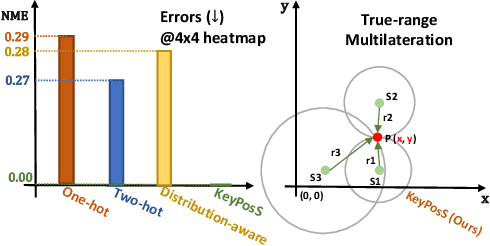

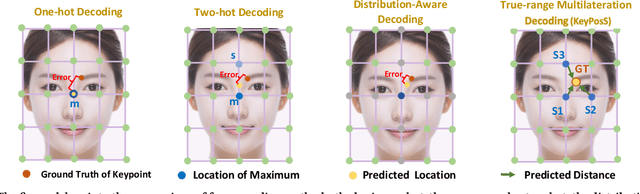
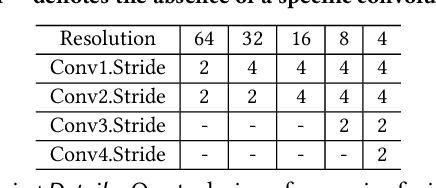
In the realm of facial analysis, accurate landmark detection is crucial for various applications, ranging from face recognition and expression analysis to animation. Conventional heatmap or coordinate regression-based techniques, however, often face challenges in terms of computational burden and quantization errors. To address these issues, we present the KeyPoint Positioning System (KeyPosS), a groundbreaking facial landmark detection framework that stands out from existing methods. For the first time, KeyPosS employs the True-range Multilateration algorithm, a technique originally used in GPS systems, to achieve rapid and precise facial landmark detection without relying on computationally intensive regression approaches. The framework utilizes a fully convolutional network to predict a distance map, which computes the distance between a Point of Interest (POI) and multiple anchor points. These anchor points are ingeniously harnessed to triangulate the POI's position through the True-range Multilateration algorithm. Notably, the plug-and-play nature of KeyPosS enables seamless integration into any decoding stage, ensuring a versatile and adaptable solution. We conducted a thorough evaluation of KeyPosS's performance by benchmarking it against state-of-the-art models on four different datasets. The results show that KeyPosS substantially outperforms leading methods in low-resolution settings while requiring a minimal time overhead. The code is available at https://github.com/zhiqic/KeyPosS.
ReliTalk: Relightable Talking Portrait Generation from a Single Video
Sep 05, 2023
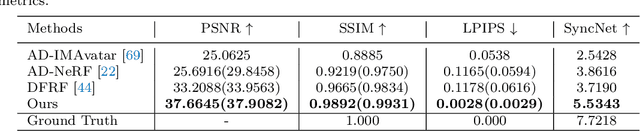
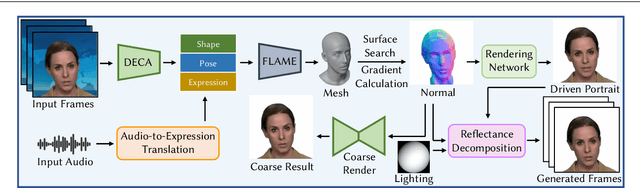
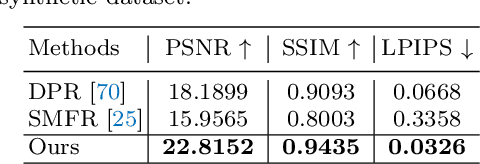
Recent years have witnessed great progress in creating vivid audio-driven portraits from monocular videos. However, how to seamlessly adapt the created video avatars to other scenarios with different backgrounds and lighting conditions remains unsolved. On the other hand, existing relighting studies mostly rely on dynamically lighted or multi-view data, which are too expensive for creating video portraits. To bridge this gap, we propose ReliTalk, a novel framework for relightable audio-driven talking portrait generation from monocular videos. Our key insight is to decompose the portrait's reflectance from implicitly learned audio-driven facial normals and images. Specifically, we involve 3D facial priors derived from audio features to predict delicate normal maps through implicit functions. These initially predicted normals then take a crucial part in reflectance decomposition by dynamically estimating the lighting condition of the given video. Moreover, the stereoscopic face representation is refined using the identity-consistent loss under simulated multiple lighting conditions, addressing the ill-posed problem caused by limited views available from a single monocular video. Extensive experiments validate the superiority of our proposed framework on both real and synthetic datasets. Our code is released in https://github.com/arthur-qiu/ReliTalk.
Learning Separable Hidden Unit Contributions for Speaker-Adaptive Lip-Reading
Oct 08, 2023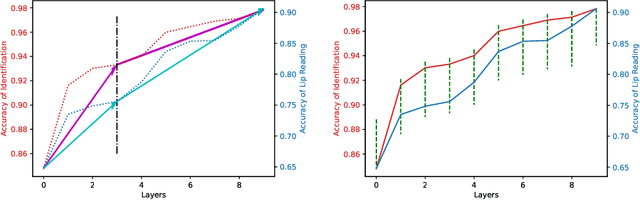
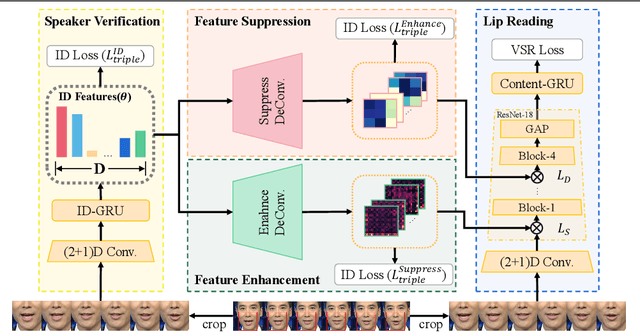
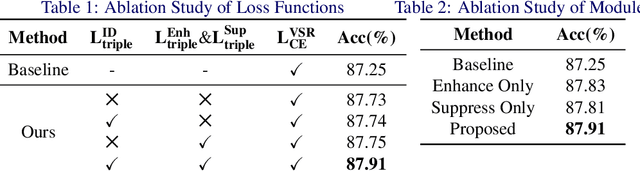
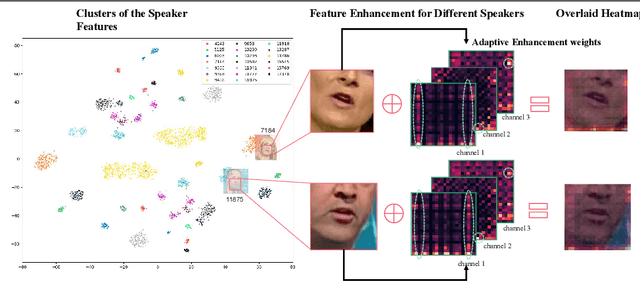
In this paper, we propose a novel method for speaker adaptation in lip reading, motivated by two observations. Firstly, a speaker's own characteristics can always be portrayed well by his/her few facial images or even a single image with shallow networks, while the fine-grained dynamic features associated with speech content expressed by the talking face always need deep sequential networks to represent accurately. Therefore, we treat the shallow and deep layers differently for speaker adaptive lip reading. Secondly, we observe that a speaker's unique characteristics ( e.g. prominent oral cavity and mandible) have varied effects on lip reading performance for different words and pronunciations, necessitating adaptive enhancement or suppression of the features for robust lip reading. Based on these two observations, we propose to take advantage of the speaker's own characteristics to automatically learn separable hidden unit contributions with different targets for shallow layers and deep layers respectively. For shallow layers where features related to the speaker's characteristics are stronger than the speech content related features, we introduce speaker-adaptive features to learn for enhancing the speech content features. For deep layers where both the speaker's features and the speech content features are all expressed well, we introduce the speaker-adaptive features to learn for suppressing the speech content irrelevant noise for robust lip reading. Our approach consistently outperforms existing methods, as confirmed by comprehensive analysis and comparison across different settings. Besides the evaluation on the popular LRW-ID and GRID datasets, we also release a new dataset for evaluation, CAS-VSR-S68h, to further assess the performance in an extreme setting where just a few speakers are available but the speech content covers a large and diversified range.
Weakly-Supervised Text-driven Contrastive Learning for Facial Behavior Understanding
Mar 31, 2023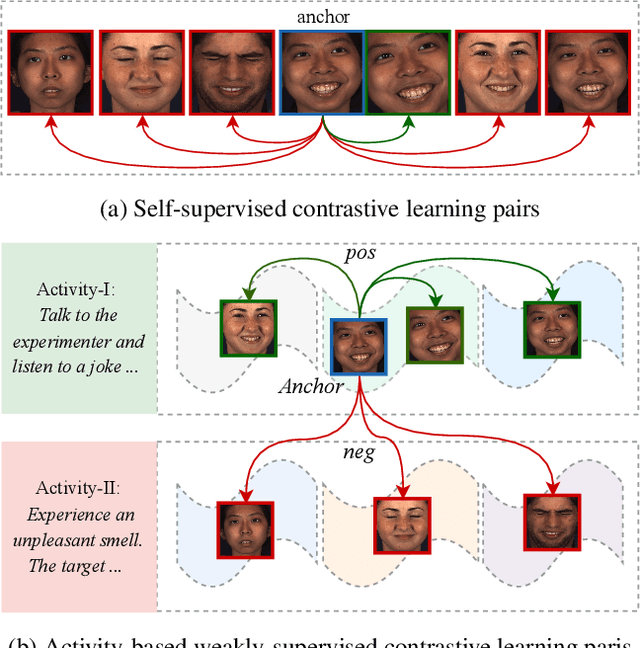
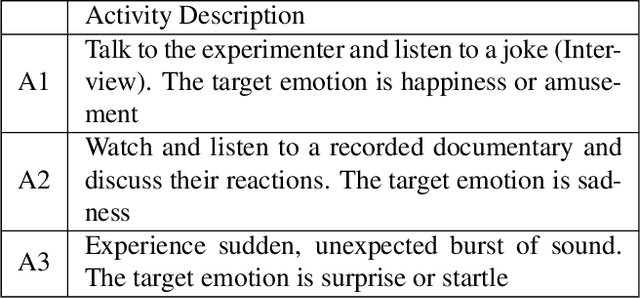
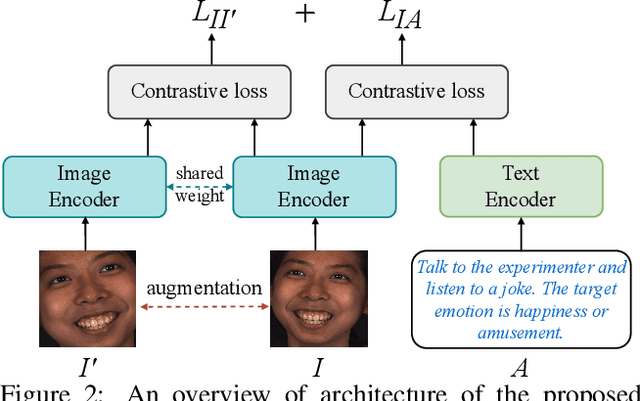
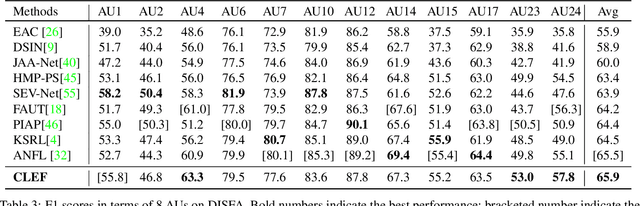
Contrastive learning has shown promising potential for learning robust representations by utilizing unlabeled data. However, constructing effective positive-negative pairs for contrastive learning on facial behavior datasets remains challenging. This is because such pairs inevitably encode the subject-ID information, and the randomly constructed pairs may push similar facial images away due to the limited number of subjects in facial behavior datasets. To address this issue, we propose to utilize activity descriptions, coarse-grained information provided in some datasets, which can provide high-level semantic information about the image sequences but is often neglected in previous studies. More specifically, we introduce a two-stage Contrastive Learning with Text-Embeded framework for Facial behavior understanding (CLEF). The first stage is a weakly-supervised contrastive learning method that learns representations from positive-negative pairs constructed using coarse-grained activity information. The second stage aims to train the recognition of facial expressions or facial action units by maximizing the similarity between image and the corresponding text label names. The proposed CLEF achieves state-of-the-art performance on three in-the-lab datasets for AU recognition and three in-the-wild datasets for facial expression recognition.