 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Embedding Aggregation for Forensic Facial Comparison
Apr 29, 2023
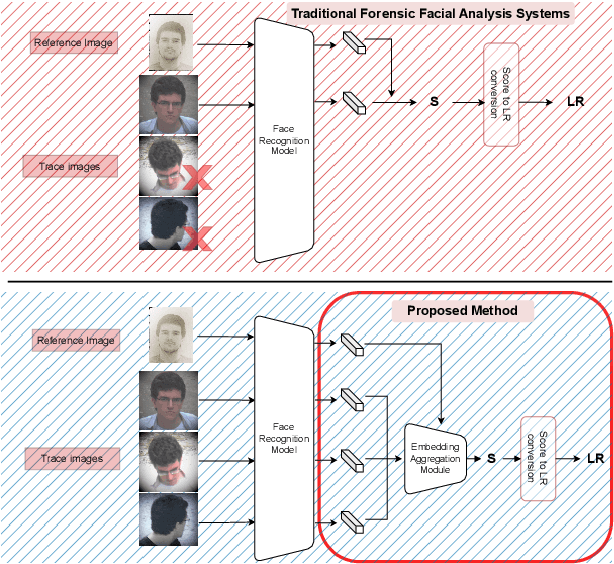
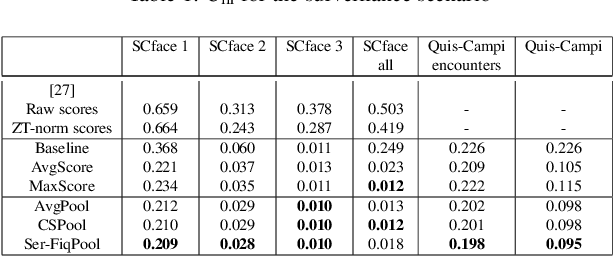

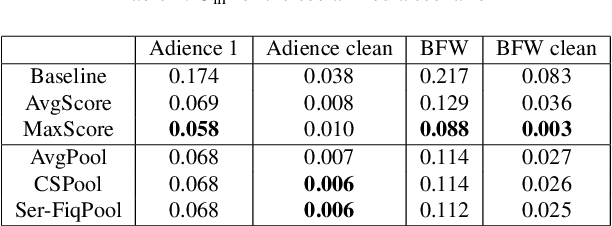
In forensic facial comparison, questioned-source images are usually captured in uncontrolled environments, with non-uniform lighting, and from non-cooperative subjects. The poor quality of such material usually compromises their value as evidence in legal matters. On the other hand, in forensic casework, multiple images of the person of interest are usually available. In this paper, we propose to aggregate deep neural network embeddings from various images of the same person to improve performance in facial verification. We observe significant performance improvements, especially for very low-quality images. Further improvements are obtained by aggregating embeddings of more images and by applying quality-weighted aggregation. We demonstrate the benefits of this approach in forensic evaluation settings with the development and validation of score-based likelihood ratio systems and report improvements in Cllr of up to 95% (from 0.249 to 0.012) for CCTV images and of up to 96% (from 0.083 to 0.003) for social media images.
ReliTalk: Relightable Talking Portrait Generation from a Single Video
Sep 05, 2023
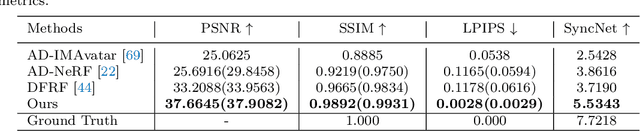
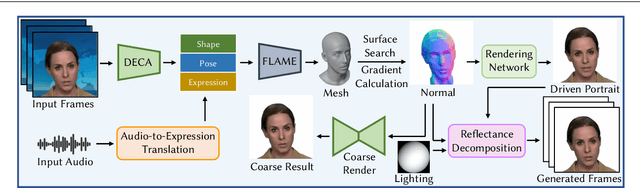
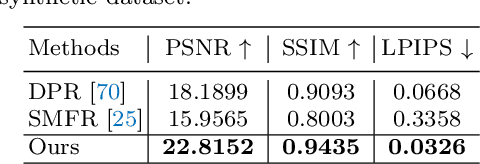
Recent years have witnessed great progress in creating vivid audio-driven portraits from monocular videos. However, how to seamlessly adapt the created video avatars to other scenarios with different backgrounds and lighting conditions remains unsolved. On the other hand, existing relighting studies mostly rely on dynamically lighted or multi-view data, which are too expensive for creating video portraits. To bridge this gap, we propose ReliTalk, a novel framework for relightable audio-driven talking portrait generation from monocular videos. Our key insight is to decompose the portrait's reflectance from implicitly learned audio-driven facial normals and images. Specifically, we involve 3D facial priors derived from audio features to predict delicate normal maps through implicit functions. These initially predicted normals then take a crucial part in reflectance decomposition by dynamically estimating the lighting condition of the given video. Moreover, the stereoscopic face representation is refined using the identity-consistent loss under simulated multiple lighting conditions, addressing the ill-posed problem caused by limited views available from a single monocular video. Extensive experiments validate the superiority of our proposed framework on both real and synthetic datasets. Our code is released in https://github.com/arthur-qiu/ReliTalk.
MIS-AVioDD: Modality Invariant and Specific Representation for Audio-Visual Deepfake Detection
Oct 03, 2023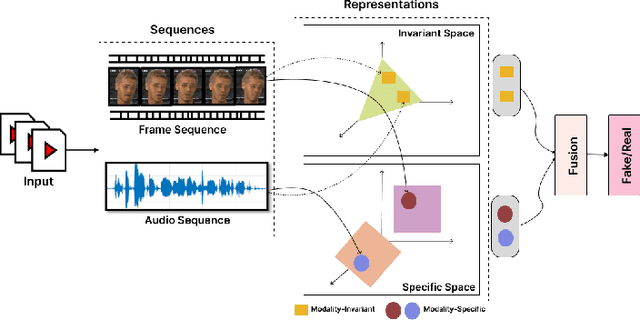
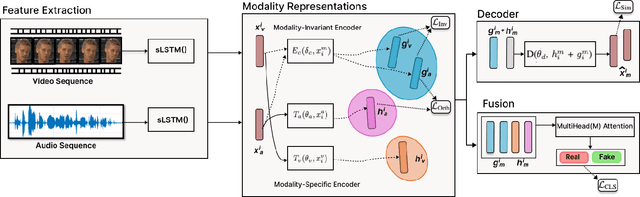

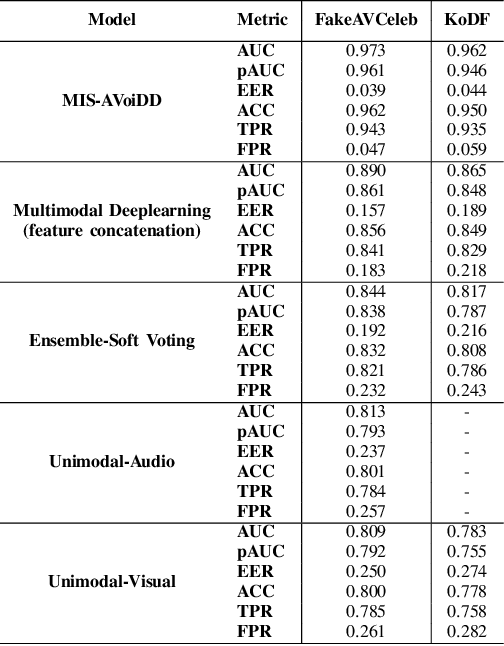
Deepfakes are synthetic media generated using deep generative algorithms and have posed a severe societal and political threat. Apart from facial manipulation and synthetic voice, recently, a novel kind of deepfakes has emerged with either audio or visual modalities manipulated. In this regard, a new generation of multimodal audio-visual deepfake detectors is being investigated to collectively focus on audio and visual data for multimodal manipulation detection. Existing multimodal (audio-visual) deepfake detectors are often based on the fusion of the audio and visual streams from the video. Existing studies suggest that these multimodal detectors often obtain equivalent performances with unimodal audio and visual deepfake detectors. We conjecture that the heterogeneous nature of the audio and visual signals creates distributional modality gaps and poses a significant challenge to effective fusion and efficient performance. In this paper, we tackle the problem at the representation level to aid the fusion of audio and visual streams for multimodal deepfake detection. Specifically, we propose the joint use of modality (audio and visual) invariant and specific representations. This ensures that the common patterns and patterns specific to each modality representing pristine or fake content are preserved and fused for multimodal deepfake manipulation detection. Our experimental results on FakeAVCeleb and KoDF audio-visual deepfake datasets suggest the enhanced accuracy of our proposed method over SOTA unimodal and multimodal audio-visual deepfake detectors by $17.8$% and $18.4$%, respectively. Thus, obtaining state-of-the-art performance.
Introduction to Facial Micro Expressions Analysis Using Color and Depth Images: A Matlab Coding Approach (Second Edition, 2023)
Jun 19, 2023
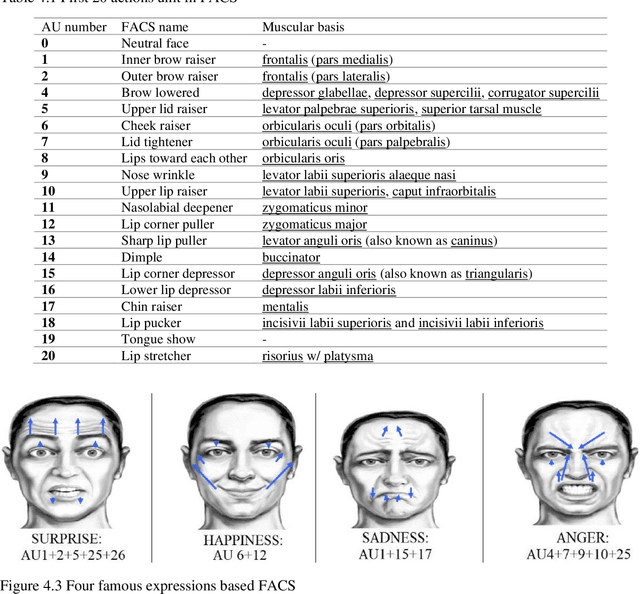
The book attempts to introduce a gentle introduction to the field of Facial Micro Expressions Recognition (FMER) using Color and Depth images, with the aid of MATLAB programming environment. FMER is a subset of image processing and it is a multidisciplinary topic to analysis. So, it requires familiarity with other topics of Artifactual Intelligence (AI) such as machine learning, digital image processing, psychology and more. So, it is a great opportunity to write a book which covers all of these topics for beginner to professional readers in the field of AI and even without having background of AI. Our goal is to provide a standalone introduction in the field of MFER analysis in the form of theorical descriptions for readers with no background in image processing with reproducible Matlab practical examples. Also, we describe any basic definitions for FMER analysis and MATLAB library which is used in the text, that helps final reader to apply the experiments in the real-world applications. We believe that this book is suitable for students, researchers, and professionals alike, who need to develop practical skills, along with a basic understanding of the field. We expect that, after reading this book, the reader feels comfortable with different key stages such as color and depth image processing, color and depth image representation, classification, machine learning, facial micro-expressions recognition, feature extraction and dimensionality reduction. The book attempts to introduce a gentle introduction to the field of Facial Micro Expressions Recognition (FMER) using Color and Depth images, with the aid of MATLAB programming environment.
SlowFast Network for Continuous Sign Language Recognition
Sep 21, 2023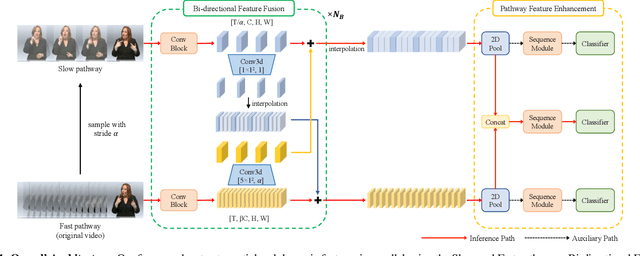
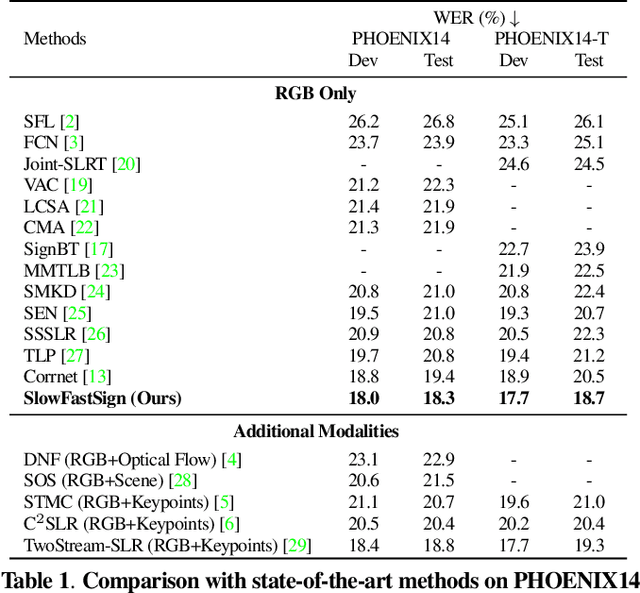


The objective of this work is the effective extraction of spatial and dynamic features for Continuous Sign Language Recognition (CSLR). To accomplish this, we utilise a two-pathway SlowFast network, where each pathway operates at distinct temporal resolutions to separately capture spatial (hand shapes, facial expressions) and dynamic (movements) information. In addition, we introduce two distinct feature fusion methods, carefully designed for the characteristics of CSLR: (1) Bi-directional Feature Fusion (BFF), which facilitates the transfer of dynamic semantics into spatial semantics and vice versa; and (2) Pathway Feature Enhancement (PFE), which enriches dynamic and spatial representations through auxiliary subnetworks, while avoiding the need for extra inference time. As a result, our model further strengthens spatial and dynamic representations in parallel. We demonstrate that the proposed framework outperforms the current state-of-the-art performance on popular CSLR datasets, including PHOENIX14, PHOENIX14-T, and CSL-Daily.
TalkNCE: Improving Active Speaker Detection with Talk-Aware Contrastive Learning
Sep 21, 2023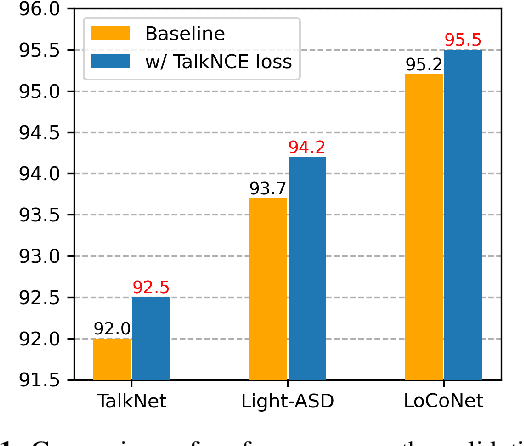
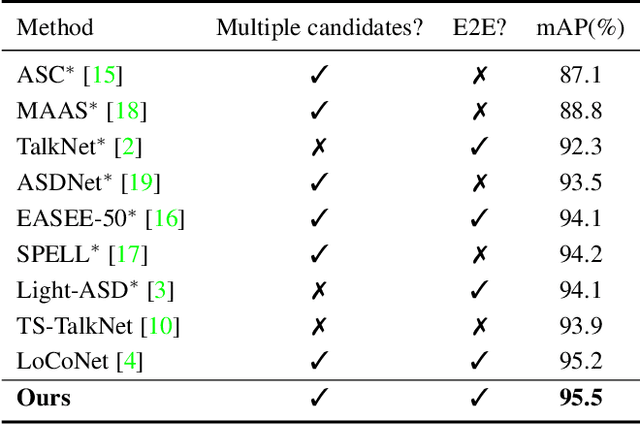
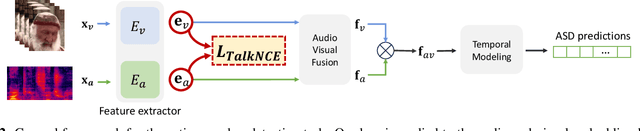
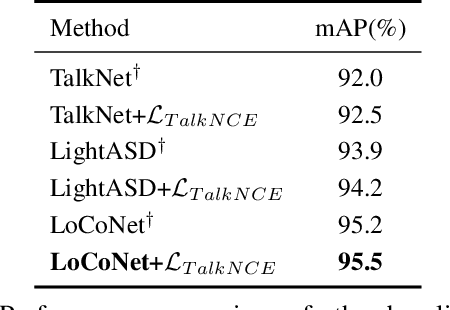
The goal of this work is Active Speaker Detection (ASD), a task to determine whether a person is speaking or not in a series of video frames. Previous works have dealt with the task by exploring network architectures while learning effective representations has been less explored. In this work, we propose TalkNCE, a novel talk-aware contrastive loss. The loss is only applied to part of the full segments where a person on the screen is actually speaking. This encourages the model to learn effective representations through the natural correspondence of speech and facial movements. Our loss can be jointly optimized with the existing objectives for training ASD models without the need for additional supervision or training data. The experiments demonstrate that our loss can be easily integrated into the existing ASD frameworks, improving their performance. Our method achieves state-of-the-art performances on AVA-ActiveSpeaker and ASW datasets.
Enhancing Mobile Privacy and Security: A Face Skin Patch-Based Anti-Spoofing Approach
Aug 09, 2023
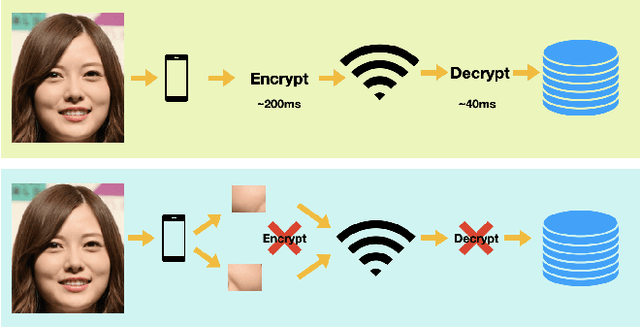
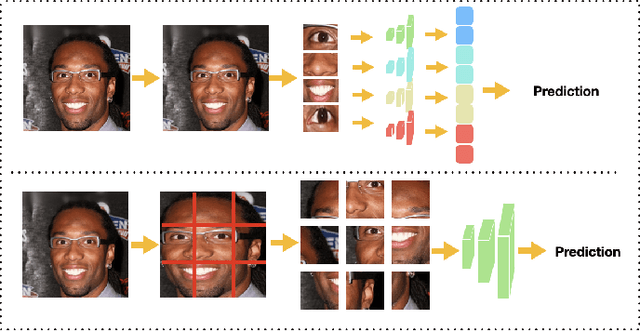
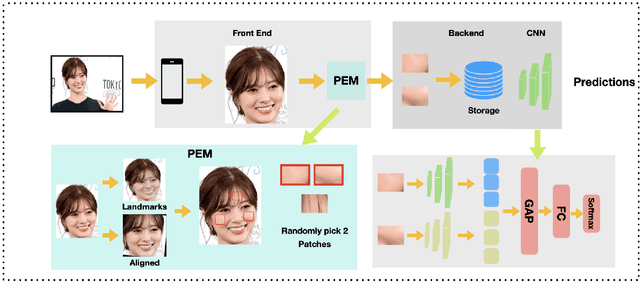
As Facial Recognition System(FRS) is widely applied in areas such as access control and mobile payments due to its convenience and high accuracy. The security of facial recognition is also highly regarded. The Face anti-spoofing system(FAS) for face recognition is an important component used to enhance the security of face recognition systems. Traditional FAS used images containing identity information to detect spoofing traces, however there is a risk of privacy leakage during the transmission and storage of these images. Besides, the encryption and decryption of these privacy-sensitive data takes too long compared to inference time by FAS model. To address the above issues, we propose a face anti-spoofing algorithm based on facial skin patches leveraging pure facial skin patch images as input, which contain no privacy information, no encryption or decryption is needed for these images. We conduct experiments on several public datasets, the results prove that our algorithm has demonstrated superiority in both accuracy and speed.
KeyPosS: Plug-and-Play Facial Landmark Detection through GPS-Inspired True-Range Multilateration
May 25, 2023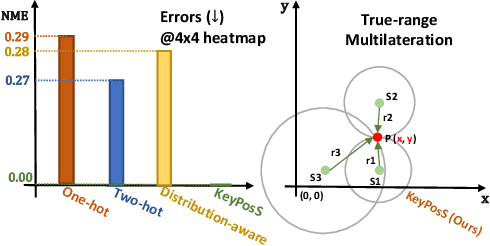

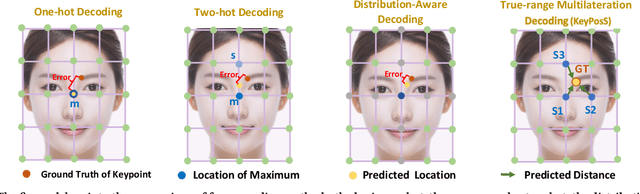
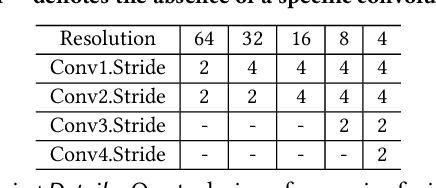
In the realm of facial analysis, accurate landmark detection is crucial for various applications, ranging from face recognition and expression analysis to animation. Conventional heatmap or coordinate regression-based techniques, however, often face challenges in terms of computational burden and quantization errors. To address these issues, we present the KeyPoint Positioning System (KeyPosS), a groundbreaking facial landmark detection framework that stands out from existing methods. For the first time, KeyPosS employs the True-range Multilateration algorithm, a technique originally used in GPS systems, to achieve rapid and precise facial landmark detection without relying on computationally intensive regression approaches. The framework utilizes a fully convolutional network to predict a distance map, which computes the distance between a Point of Interest (POI) and multiple anchor points. These anchor points are ingeniously harnessed to triangulate the POI's position through the True-range Multilateration algorithm. Notably, the plug-and-play nature of KeyPosS enables seamless integration into any decoding stage, ensuring a versatile and adaptable solution. We conducted a thorough evaluation of KeyPosS's performance by benchmarking it against state-of-the-art models on four different datasets. The results show that KeyPosS substantially outperforms leading methods in low-resolution settings while requiring a minimal time overhead. The code is available at https://github.com/zhiqic/KeyPosS.
FaceChain: A Playground for Identity-Preserving Portrait Generation
Aug 28, 2023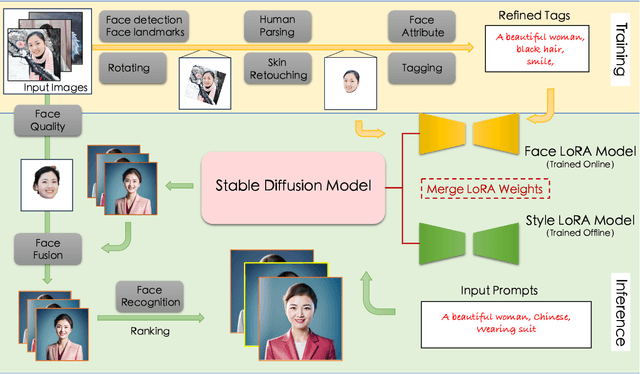

Recent advancement in personalized image generation have unveiled the intriguing capability of pre-trained text-to-image models on learning identity information from a collection of portrait images. However, existing solutions can be vulnerable in producing truthful details, and usually suffer from several defects such as (i) The generated face exhibit its own unique characteristics, \ie facial shape and facial feature positioning may not resemble key characteristics of the input, and (ii) The synthesized face may contain warped, blurred or corrupted regions. In this paper, we present FaceChain, a personalized portrait generation framework that combines a series of customized image-generation model and a rich set of face-related perceptual understanding models (\eg, face detection, deep face embedding extraction, and facial attribute recognition), to tackle aforementioned challenges and to generate truthful personalized portraits, with only a handful of portrait images as input. Concretely, we inject several SOTA face models into the generation procedure, achieving a more efficient label-tagging, data-processing, and model post-processing compared to previous solutions, such as DreamBooth ~\cite{ruiz2023dreambooth} , InstantBooth ~\cite{shi2023instantbooth} , or other LoRA-only approaches ~\cite{hu2021lora} . Through the development of FaceChain, we have identified several potential directions to accelerate development of Face/Human-Centric AIGC research and application. We have designed FaceChain as a framework comprised of pluggable components that can be easily adjusted to accommodate different styles and personalized needs. We hope it can grow to serve the burgeoning needs from the communities. FaceChain is open-sourced under Apache-2.0 license at \url{https://github.com/modelscope/facechain}.
Weakly-Supervised Text-driven Contrastive Learning for Facial Behavior Understanding
Mar 31, 2023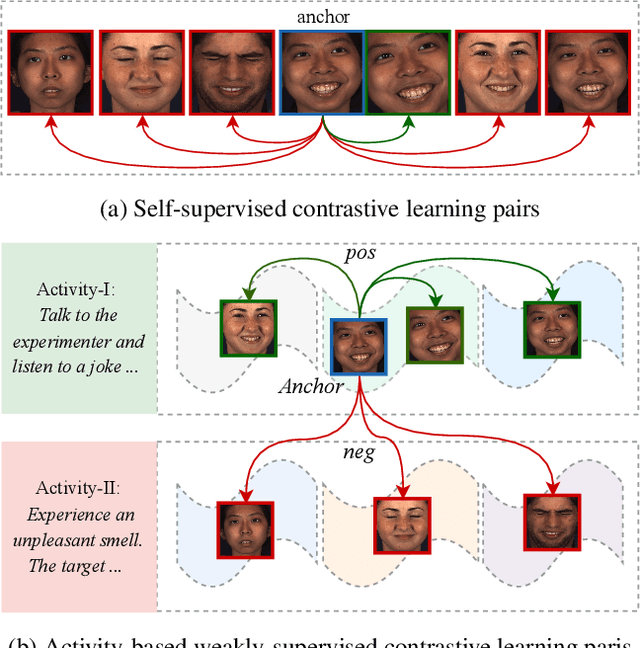
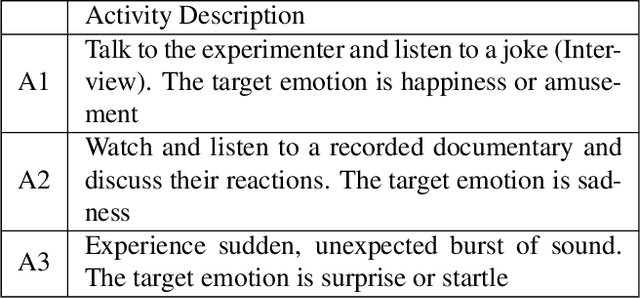
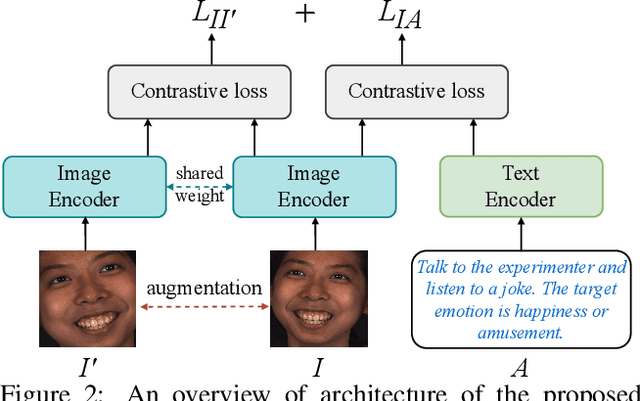
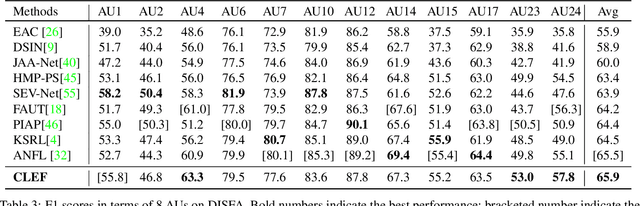
Contrastive learning has shown promising potential for learning robust representations by utilizing unlabeled data. However, constructing effective positive-negative pairs for contrastive learning on facial behavior datasets remains challenging. This is because such pairs inevitably encode the subject-ID information, and the randomly constructed pairs may push similar facial images away due to the limited number of subjects in facial behavior datasets. To address this issue, we propose to utilize activity descriptions, coarse-grained information provided in some datasets, which can provide high-level semantic information about the image sequences but is often neglected in previous studies. More specifically, we introduce a two-stage Contrastive Learning with Text-Embeded framework for Facial behavior understanding (CLEF). The first stage is a weakly-supervised contrastive learning method that learns representations from positive-negative pairs constructed using coarse-grained activity information. The second stage aims to train the recognition of facial expressions or facial action units by maximizing the similarity between image and the corresponding text label names. The proposed CLEF achieves state-of-the-art performance on three in-the-lab datasets for AU recognition and three in-the-wild datasets for facial expression recognition.