 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
DT-NeRF: Decomposed Triplane-Hash Neural Radiance Fields for High-Fidelity Talking Portrait Synthesis
Sep 14, 2023
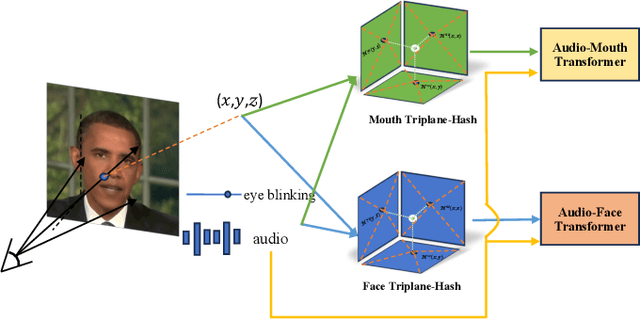
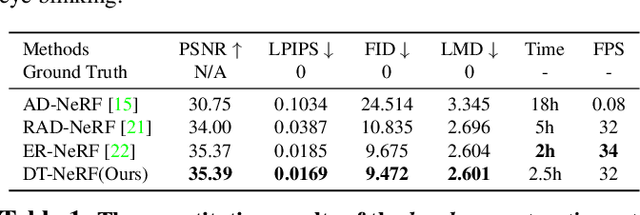
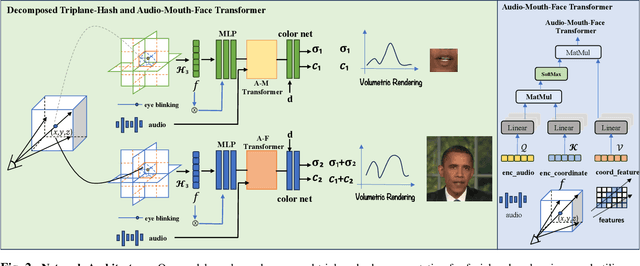
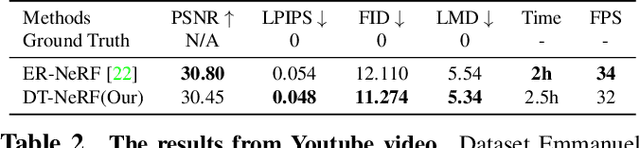
In this paper, we present the decomposed triplane-hash neural radiance fields (DT-NeRF), a framework that significantly improves the photorealistic rendering of talking faces and achieves state-of-the-art results on key evaluation datasets. Our architecture decomposes the facial region into two specialized triplanes: one specialized for representing the mouth, and the other for the broader facial features. We introduce audio features as residual terms and integrate them as query vectors into our model through an audio-mouth-face transformer. Additionally, our method leverages the capabilities of Neural Radiance Fields (NeRF) to enrich the volumetric representation of the entire face through additive volumetric rendering techniques. Comprehensive experimental evaluations corroborate the effectiveness and superiority of our proposed approach.
Face Aging via Diffusion-based Editing
Sep 20, 2023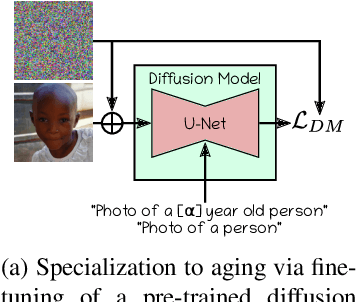
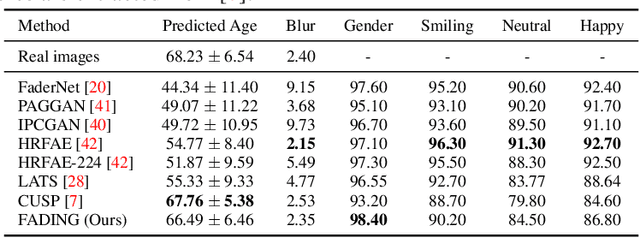


In this paper, we address the problem of face aging: generating past or future facial images by incorporating age-related changes to the given face. Previous aging methods rely solely on human facial image datasets and are thus constrained by their inherent scale and bias. This restricts their application to a limited generatable age range and the inability to handle large age gaps. We propose FADING, a novel approach to address Face Aging via DIffusion-based editiNG. We go beyond existing methods by leveraging the rich prior of large-scale language-image diffusion models. First, we specialize a pre-trained diffusion model for the task of face age editing by using an age-aware fine-tuning scheme. Next, we invert the input image to latent noise and obtain optimized null text embeddings. Finally, we perform text-guided local age editing via attention control. The quantitative and qualitative analyses demonstrate that our method outperforms existing approaches with respect to aging accuracy, attribute preservation, and aging quality.
IFaceUV: Intuitive Motion Facial Image Generation by Identity Preservation via UV map
Jun 08, 2023
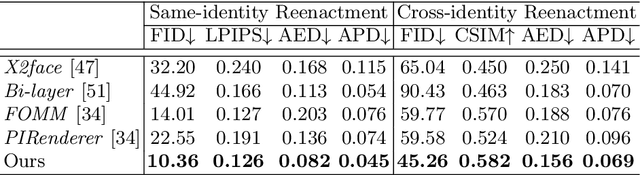
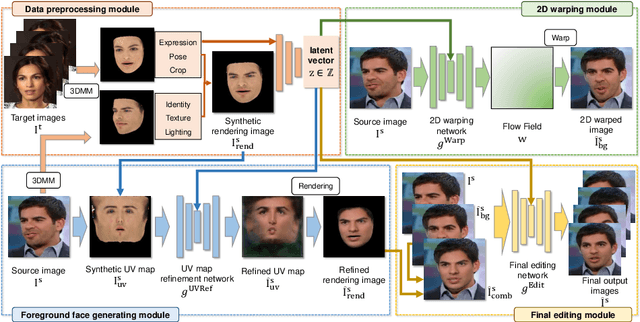
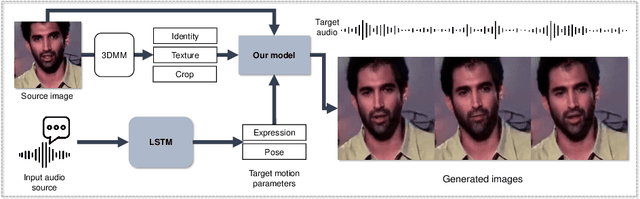
Reenacting facial images is an important task that can find numerous applications. We proposed IFaceUV, a fully differentiable pipeline that properly combines 2D and 3D information to conduct the facial reenactment task. The three-dimensional morphable face models (3DMMs) and corresponding UV maps are utilized to intuitively control facial motions and textures, respectively. Two-dimensional techniques based on 2D image warping is further required to compensate for missing components of the 3DMMs such as backgrounds, ear, hair and etc. In our pipeline, we first extract 3DMM parameters and corresponding UV maps from source and target images. Then, initial UV maps are refined by the UV map refinement network and it is rendered to the image with the motion manipulated 3DMM parameters. In parallel, we warp the source image according to the 2D flow field obtained from the 2D warping network. Rendered and warped images are combined in the final editing network to generate the final reenactment image. Additionally, we tested our model for the audio-driven facial reenactment task. Extensive qualitative and quantitative experiments illustrate the remarkable performance of our method compared to other state-of-the-art methods.
Deep Learning for Automatic Detection and Facial Recognition in Japanese Macaques: Illuminating Social Networks
Oct 10, 2023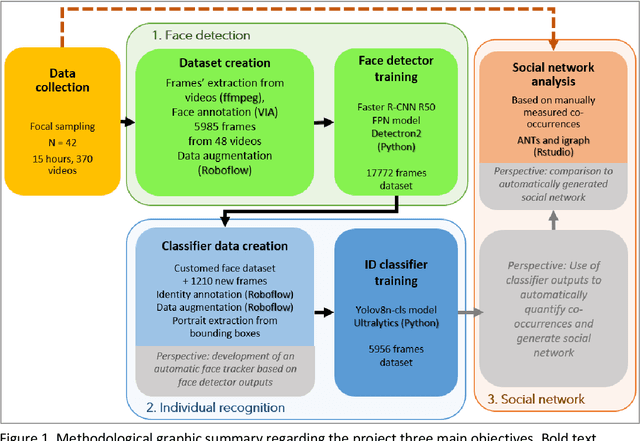


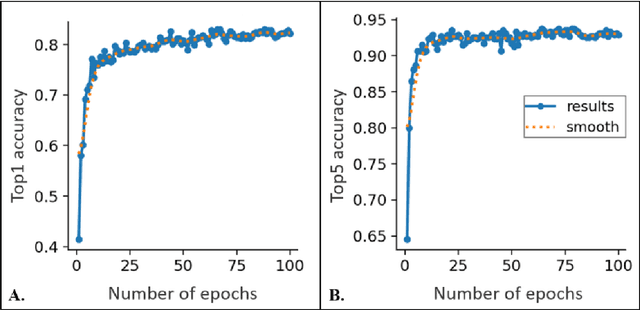
Individual identification plays a pivotal role in ecology and ethology, notably as a tool for complex social structures understanding. However, traditional identification methods often involve invasive physical tags and can prove both disruptive for animals and time-intensive for researchers. In recent years, the integration of deep learning in research offered new methodological perspectives through automatization of complex tasks. Harnessing object detection and recognition technologies is increasingly used by researchers to achieve identification on video footage. This study represents a preliminary exploration into the development of a non-invasive tool for face detection and individual identification of Japanese macaques (Macaca fuscata) through deep learning. The ultimate goal of this research is, using identifications done on the dataset, to automatically generate a social network representation of the studied population. The current main results are promising: (i) the creation of a Japanese macaques' face detector (Faster-RCNN model), reaching a 82.2% accuracy and (ii) the creation of an individual recognizer for K{\=o}jima island macaques population (YOLOv8n model), reaching a 83% accuracy. We also created a K{\=o}jima population social network by traditional methods, based on co-occurrences on videos. Thus, we provide a benchmark against which the automatically generated network will be assessed for reliability. These preliminary results are a testament to the potential of this innovative approach to provide the scientific community with a tool for tracking individuals and social network studies in Japanese macaques.
Diff-Privacy: Diffusion-based Face Privacy Protection
Sep 11, 2023
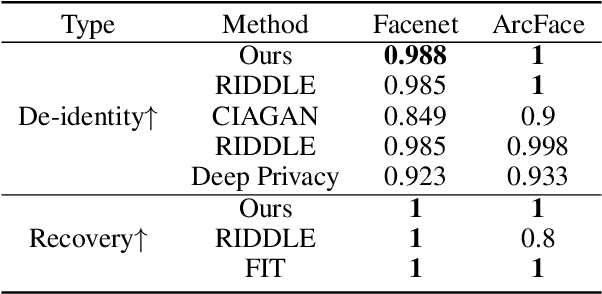
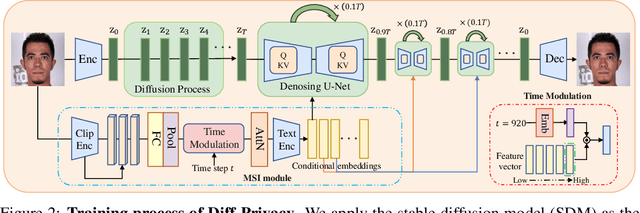
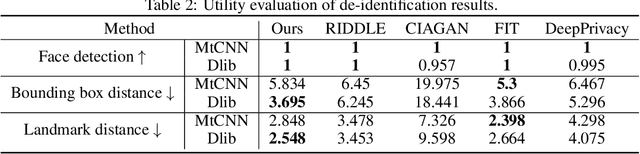
Privacy protection has become a top priority as the proliferation of AI techniques has led to widespread collection and misuse of personal data. Anonymization and visual identity information hiding are two important facial privacy protection tasks that aim to remove identification characteristics from facial images at the human perception level. However, they have a significant difference in that the former aims to prevent the machine from recognizing correctly, while the latter needs to ensure the accuracy of machine recognition. Therefore, it is difficult to train a model to complete these two tasks simultaneously. In this paper, we unify the task of anonymization and visual identity information hiding and propose a novel face privacy protection method based on diffusion models, dubbed Diff-Privacy. Specifically, we train our proposed multi-scale image inversion module (MSI) to obtain a set of SDM format conditional embeddings of the original image. Based on the conditional embeddings, we design corresponding embedding scheduling strategies and construct different energy functions during the denoising process to achieve anonymization and visual identity information hiding. Extensive experiments have been conducted to validate the effectiveness of our proposed framework in protecting facial privacy.
CLIP2Protect: Protecting Facial Privacy using Text-Guided Makeup via Adversarial Latent Search
Jun 20, 2023
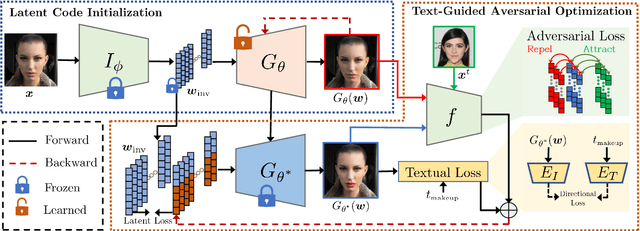

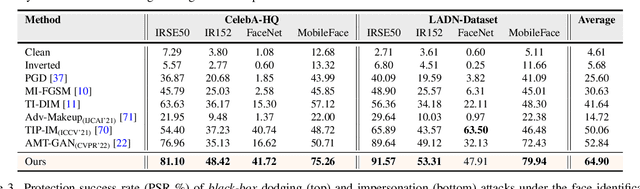
The success of deep learning based face recognition systems has given rise to serious privacy concerns due to their ability to enable unauthorized tracking of users in the digital world. Existing methods for enhancing privacy fail to generate naturalistic images that can protect facial privacy without compromising user experience. We propose a novel two-step approach for facial privacy protection that relies on finding adversarial latent codes in the low-dimensional manifold of a pretrained generative model. The first step inverts the given face image into the latent space and finetunes the generative model to achieve an accurate reconstruction of the given image from its latent code. This step produces a good initialization, aiding the generation of high-quality faces that resemble the given identity. Subsequently, user-defined makeup text prompts and identity-preserving regularization are used to guide the search for adversarial codes in the latent space. Extensive experiments demonstrate that faces generated by our approach have stronger black-box transferability with an absolute gain of 12.06% over the state-of-the-art facial privacy protection approach under the face verification task. Finally, we demonstrate the effectiveness of the proposed approach for commercial face recognition systems. Our code is available at https://github.com/fahadshamshad/Clip2Protect.
* Accepted in CVPR 2023. Project page: https://fahadshamshad.github.io/Clip2Protect/
PAtt-Lite: Lightweight Patch and Attention MobileNet for Challenging Facial Expression Recognition
Jun 16, 2023


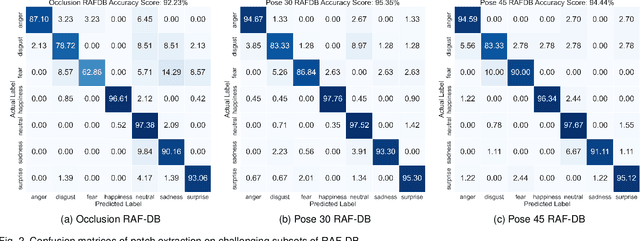
Facial Expression Recognition (FER) is a machine learning problem that deals with recognizing human facial expressions. While existing work has achieved performance improvements in recent years, FER in the wild and under challenging conditions remains a challenge. In this paper, a lightweight patch and attention network based on MobileNetV1, referred to as PAtt-Lite, is proposed to improve FER performance under challenging conditions. A truncated ImageNet-pre-trained MobileNetV1 is utilized as the backbone feature extractor of the proposed method. In place of the truncated layers is a patch extraction block that is proposed for extracting significant local facial features to enhance the representation from MobileNetV1, especially under challenging conditions. An attention classifier is also proposed to improve the learning of these patched feature maps from the extremely lightweight feature extractor. The experimental results on public benchmark databases proved the effectiveness of the proposed method. PAtt-Lite achieved state-of-the-art results on CK+, RAF-DB, FER2013, FERPlus, and the challenging conditions subsets for RAF-DB and FERPlus. The source code for the proposed method will be available at https://github.com/JLREx/PAtt-Lite.
Age Estimation Based on Graph Convolutional Networks and Multi-head Attention Mechanisms
Oct 12, 2023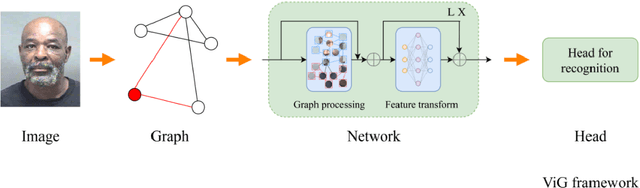
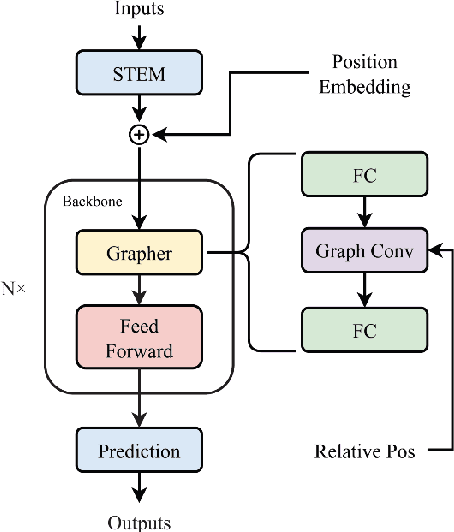
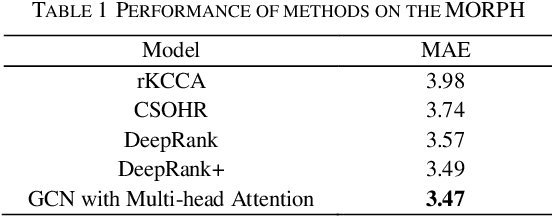
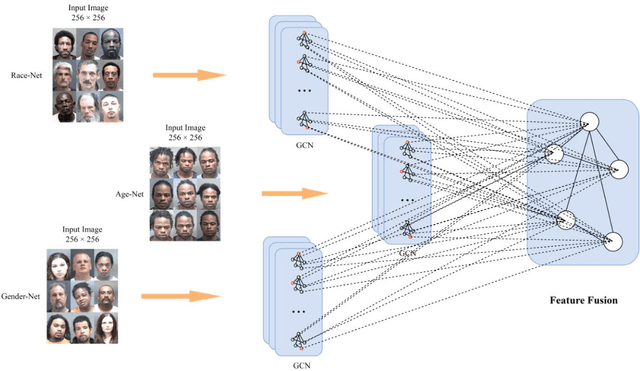
Age estimation technology is a part of facial recognition and has been applied to identity authentication. This technology achieves the development and application of a juvenile anti-addiction system by authenticating users in the game. Convolutional Neural Network (CNN) and Transformer algorithms are widely used in this application scenario. However, these two models cannot flexibly extract and model features of faces with irregular shapes, and they are ineffective in capturing key information. Furthermore, the above methods will contain a lot of background information while extracting features, which will interfere with the model. In consequence, it is easy to extract redundant information from images. In this paper, a new modeling idea is proposed to solve this problem, which can flexibly model irregular objects. The Graph Convolutional Network (GCN) is used to extract features from irregular face images effectively, and multi-head attention mechanisms are added to avoid redundant features and capture key region information in the image. This model can effectively improve the accuracy of age estimation and reduce the MAE error value to about 3.64, which is better than the effect of today's age estimation model, to improve the accuracy of face recognition and identity authentication.
Sound-Print: Generalised Face Presentation Attack Detection using Deep Representation of Sound Echoes
Sep 24, 2023Facial biometrics are widely deployed in smartphone-based applications because of their usability and increased verification accuracy in unconstrained scenarios. The evolving applications of smartphone-based facial recognition have also increased Presentation Attacks (PAs), where an attacker can present a Presentation Attack Instrument (PAI) to maliciously gain access to the application. Because the materials used to generate PAI are not deterministic, the detection of unknown presentation attacks is challenging. In this paper, we present an acoustic echo-based face Presentation Attack Detection (PAD) on a smartphone in which the PAs are detected based on the reflection profiles of the transmitted signal. We propose a novel transmission signal based on the wide pulse that allows us to model the background noise before transmitting the signal and increase the Signal-to-Noise Ratio (SNR). The received signal reflections were processed to remove background noise and accurately represent reflection characteristics. The reflection profiles of the bona fide and PAs are different owing to the different reflection characteristics of the human skin and artefact materials. Extensive experiments are presented using the newly collected Acoustic Sound Echo Dataset (ASED) with 4807 samples captured from bona fide and four different types of PAIs, including print (two types), display, and silicone face-mask attacks. The obtained results indicate the robustness of the proposed method for detecting unknown face presentation attacks.