 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Seeing and hearing what has not been said; A multimodal client behavior classifier in Motivational Interviewing with interpretable fusion
Sep 27, 2023
Motivational Interviewing (MI) is an approach to therapy that emphasizes collaboration and encourages behavioral change. To evaluate the quality of an MI conversation, client utterances can be classified using the MISC code as either change talk, sustain talk, or follow/neutral talk. The proportion of change talk in a MI conversation is positively correlated with therapy outcomes, making accurate classification of client utterances essential. In this paper, we present a classifier that accurately distinguishes between the three MISC classes (change talk, sustain talk, and follow/neutral talk) leveraging multimodal features such as text, prosody, facial expressivity, and body expressivity. To train our model, we perform annotations on the publicly available AnnoMI dataset to collect multimodal information, including text, audio, facial expressivity, and body expressivity. Furthermore, we identify the most important modalities in the decision-making process, providing valuable insights into the interplay of different modalities during a MI conversation.
Enhancing the Authenticity of Rendered Portraits with Identity-Consistent Transfer Learning
Oct 06, 2023Despite rapid advances in computer graphics, creating high-quality photo-realistic virtual portraits is prohibitively expensive. Furthermore, the well-know ''uncanny valley'' effect in rendered portraits has a significant impact on the user experience, especially when the depiction closely resembles a human likeness, where any minor artifacts can evoke feelings of eeriness and repulsiveness. In this paper, we present a novel photo-realistic portrait generation framework that can effectively mitigate the ''uncanny valley'' effect and improve the overall authenticity of rendered portraits. Our key idea is to employ transfer learning to learn an identity-consistent mapping from the latent space of rendered portraits to that of real portraits. During the inference stage, the input portrait of an avatar can be directly transferred to a realistic portrait by changing its appearance style while maintaining the facial identity. To this end, we collect a new dataset, Daz-Rendered-Faces-HQ (DRFHQ), that is specifically designed for rendering-style portraits. We leverage this dataset to fine-tune the StyleGAN2 generator, using our carefully crafted framework, which helps to preserve the geometric and color features relevant to facial identity. We evaluate our framework using portraits with diverse gender, age, and race variations. Qualitative and quantitative evaluations and ablation studies show the advantages of our method compared to state-of-the-art approaches.
New Benchmarks for Asian Facial Recognition Tasks: Face Classification with Large Foundation Models
Oct 15, 2023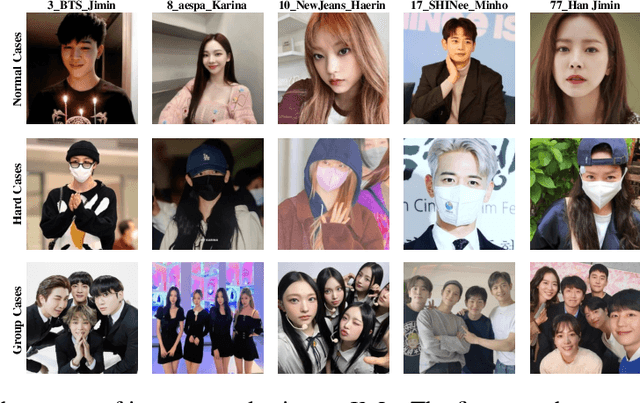
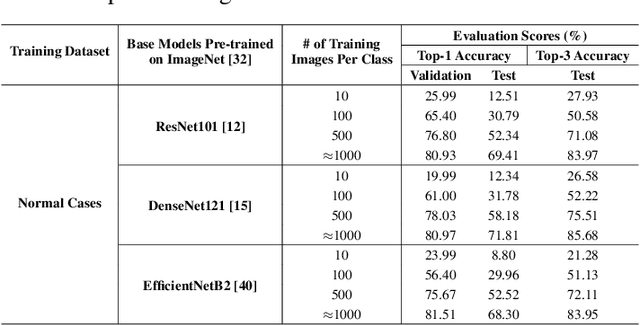
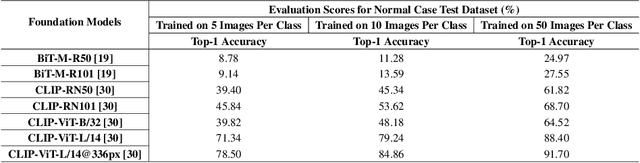

The face classification system is an important tool for recognizing personal identity properly. This paper introduces a new Large-Scale Korean Influencer Dataset named KoIn. Our presented dataset contains many real-world photos of Korean celebrities in various environments that might contain stage lighting, backup dancers, and background objects. These various images can be useful for training classification models classifying K-influencers. Most of the images in our proposed dataset have been collected from social network services (SNS) such as Instagram. Our dataset, KoIn, contains over 100,000 K-influencer photos from over 100 Korean celebrity classes. Moreover, our dataset provides additional hard case samples such as images including human faces with masks and hats. We note that the hard case samples are greatly useful in evaluating the robustness of the classification systems. We have extensively conducted several experiments utilizing various classification models to validate the effectiveness of our proposed dataset. Specifically, we demonstrate that recent state-of-the-art (SOTA) foundation architectures show decent classification performance when trained on our proposed dataset. In this paper, we also analyze the robustness performance against hard case samples of large-scale foundation models when we fine-tune the foundation models on the normal cases of the proposed dataset, KoIn. Our presented dataset and codes will be publicly available at https://github.com/dukong1/KoIn_Benchmark_Dataset.
A store-and-forward cloud-based telemonitoring system for automatic assessing dysarthria evolution in neurological diseases from video-recording analysis
Sep 16, 2023Background and objectives: Patients suffering from neurological diseases may develop dysarthria, a motor speech disorder affecting the execution of speech. Close and quantitative monitoring of dysarthria evolution is crucial for enabling clinicians to promptly implement patient management strategies and maximizing effectiveness and efficiency of communication functions in term of restoring, compensating or adjusting. In the clinical assessment of orofacial structures and functions, at rest condition or during speech and non-speech movements, a qualitative evaluation is usually performed, throughout visual observation. Methods: To overcome limitations posed by qualitative assessments, this work presents a store-and-forward self-service telemonitoring system that integrates, within its cloud architecture, a convolutional neural network (CNN) for analyzing video recordings acquired by individuals with dysarthria. This architecture, called facial landmark Mask RCNN, aims at locating facial landmarks as a prior for assessing the orofacial functions related to speech and examining dysarthria evolution in neurological diseases. Results: When tested on the Toronto NeuroFace dataset, a publicly available annotated dataset of video recordings from patients with amyotrophic lateral sclerosis (ALS) and stroke, the proposed CNN achieved a normalized mean error equal to 1.79 on localizing the facial landmarks. We also tested our system in a real-life scenario on 11 bulbar-onset ALS subjects, obtaining promising outcomes in terms of facial landmark position estimation. Discussion and conclusions: This preliminary study represents a relevant step towards the use of remote tools to support clinicians in monitoring the evolution of dysarthria.
Toward responsible face datasets: modeling the distribution of a disentangled latent space for sampling face images from demographic groups
Sep 15, 2023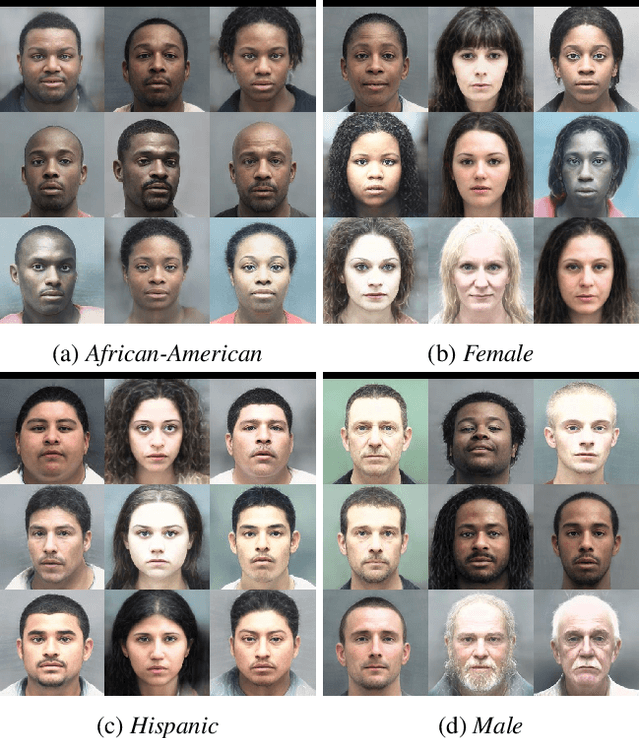
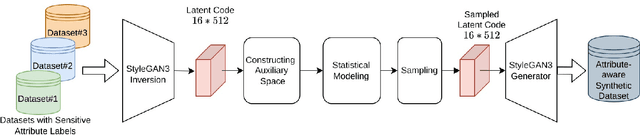
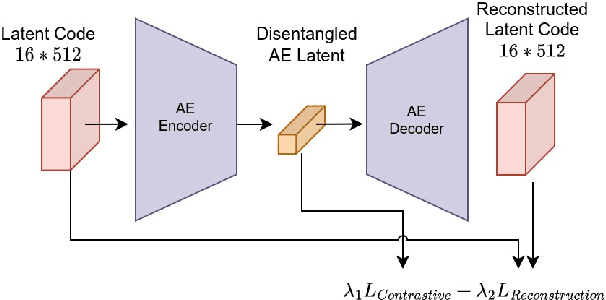

Recently, it has been exposed that some modern facial recognition systems could discriminate specific demographic groups and may lead to unfair attention with respect to various facial attributes such as gender and origin. The main reason are the biases inside datasets, unbalanced demographics, used to train theses models. Unfortunately, collecting a large-scale balanced dataset with respect to various demographics is impracticable. In this paper, we investigate as an alternative the generation of a balanced and possibly bias-free synthetic dataset that could be used to train, to regularize or to evaluate deep learning-based facial recognition models. We propose to use a simple method for modeling and sampling a disentangled projection of a StyleGAN latent space to generate any combination of demographic groups (e.g. $hispanic-female$). Our experiments show that we can synthesis any combination of demographic groups effectively and the identities are different from the original training dataset. We also released the source code.
Fuzzy-Conditioned Diffusion and Diffusion Projection Attention Applied to Facial Image Correction
Jul 01, 2023

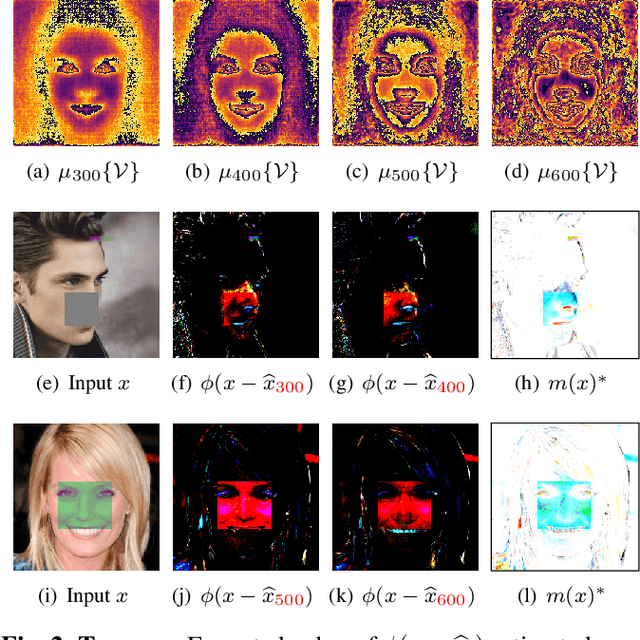
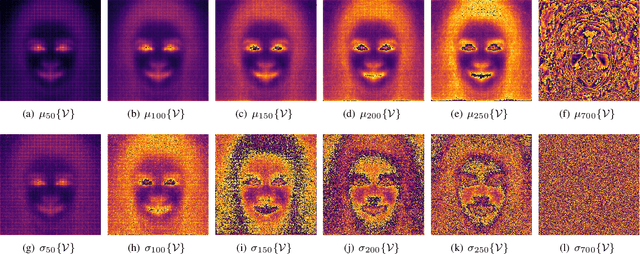
Image diffusion has recently shown remarkable performance in image synthesis and implicitly as an image prior. Such a prior has been used with conditioning to solve the inpainting problem, but only supporting binary user-based conditioning. We derive a fuzzy-conditioned diffusion, where implicit diffusion priors can be exploited with controllable strength. Our fuzzy conditioning can be applied pixel-wise, enabling the modification of different image components to varying degrees. Additionally, we propose an application to facial image correction, where we combine our fuzzy-conditioned diffusion with diffusion-derived attention maps. Our map estimates the degree of anomaly, and we obtain it by projecting on the diffusion space. We show how our approach also leads to interpretable and autonomous facial image correction.
The Hidden Dance of Phonemes and Visage: Unveiling the Enigmatic Link between Phonemes and Facial Features
Jul 26, 2023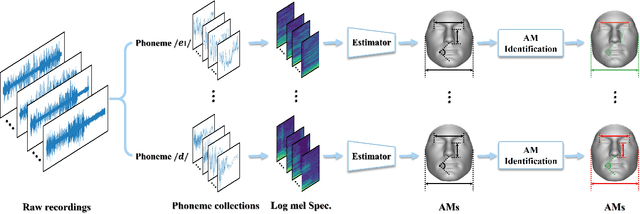
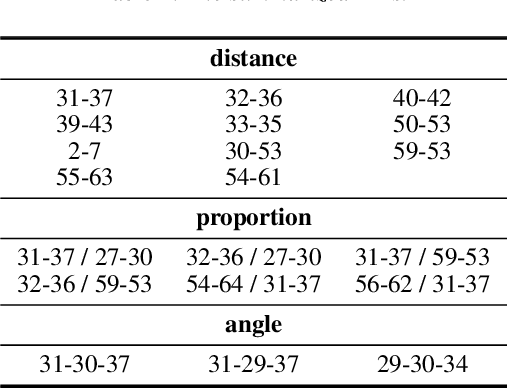
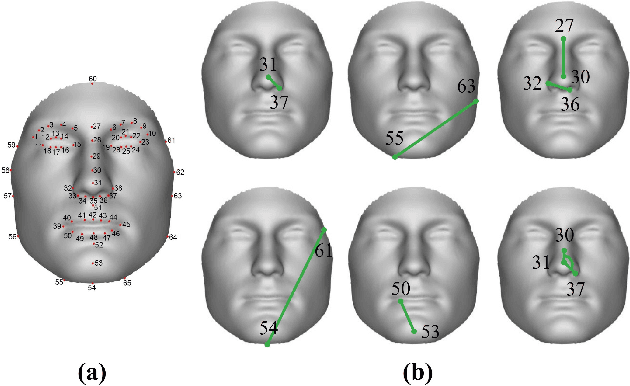
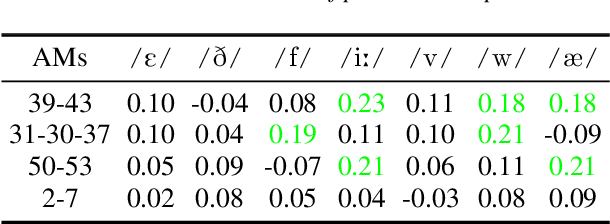
This work unveils the enigmatic link between phonemes and facial features. Traditional studies on voice-face correlations typically involve using a long period of voice input, including generating face images from voices and reconstructing 3D face meshes from voices. However, in situations like voice-based crimes, the available voice evidence may be short and limited. Additionally, from a physiological perspective, each segment of speech -- phoneme -- corresponds to different types of airflow and movements in the face. Therefore, it is advantageous to discover the hidden link between phonemes and face attributes. In this paper, we propose an analysis pipeline to help us explore the voice-face relationship in a fine-grained manner, i.e., phonemes v.s. facial anthropometric measurements (AM). We build an estimator for each phoneme-AM pair and evaluate the correlation through hypothesis testing. Our results indicate that AMs are more predictable from vowels compared to consonants, particularly with plosives. Additionally, we observe that if a specific AM exhibits more movement during phoneme pronunciation, it is more predictable. Our findings support those in physiology regarding correlation and lay the groundwork for future research on speech-face multimodal learning.
Reversible Graph Neural Network-based Reaction Distribution Learning for Multiple Appropriate Facial Reactions Generation
May 25, 2023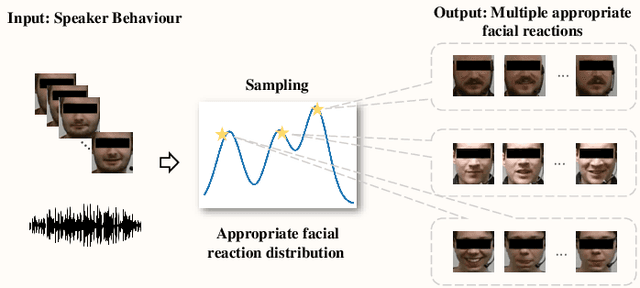
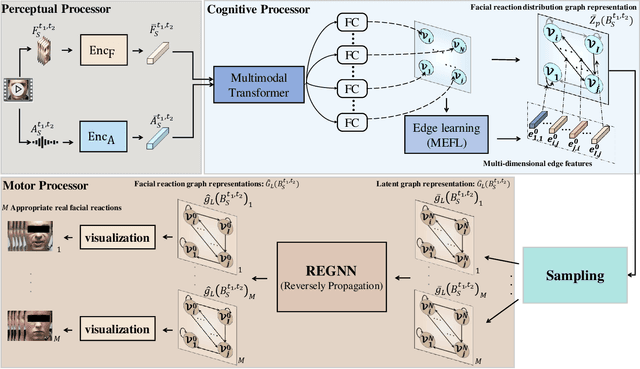

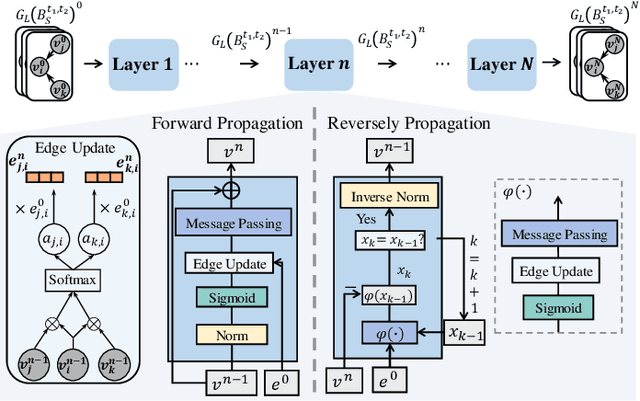
Generating facial reactions in a human-human dyadic interaction is complex and highly dependent on the context since more than one facial reactions can be appropriate for the speaker's behaviour. This has challenged existing machine learning (ML) methods, whose training strategies enforce models to reproduce a specific (not multiple) facial reaction from each input speaker behaviour. This paper proposes the first multiple appropriate facial reaction generation framework that re-formulates the one-to-many mapping facial reaction generation problem as a one-to-one mapping problem. This means that we approach this problem by considering the generation of a distribution of the listener's appropriate facial reactions instead of multiple different appropriate facial reactions, i.e., 'many' appropriate facial reaction labels are summarised as 'one' distribution label during training. Our model consists of a perceptual processor, a cognitive processor, and a motor processor. The motor processor is implemented with a novel Reversible Multi-dimensional Edge Graph Neural Network (REGNN). This allows us to obtain a distribution of appropriate real facial reactions during the training process, enabling the cognitive processor to be trained to predict the appropriate facial reaction distribution. At the inference stage, the REGNN decodes an appropriate facial reaction by using this distribution as input. Experimental results demonstrate that our approach outperforms existing models in generating more appropriate, realistic, and synchronized facial reactions. The improved performance is largely attributed to the proposed appropriate facial reaction distribution learning strategy and the use of a REGNN. The code is available at https://github.com/TongXu-05/REGNN-Multiple-Appropriate-Facial-Reaction-Generation.
Attribute-Guided Encryption with Facial Texture Masking
May 22, 2023
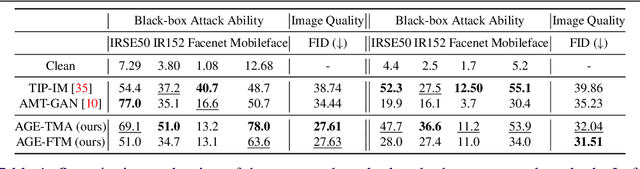
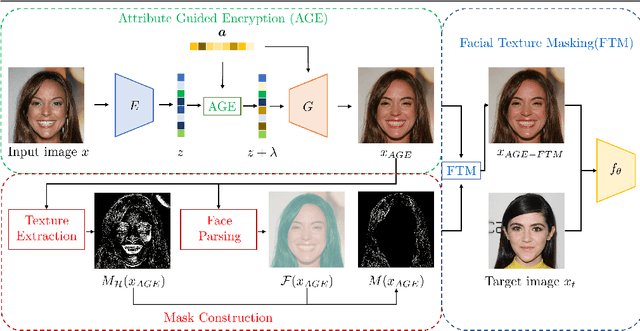

The increasingly pervasive facial recognition (FR) systems raise serious concerns about personal privacy, especially for billions of users who have publicly shared their photos on social media. Several attempts have been made to protect individuals from unauthorized FR systems utilizing adversarial attacks to generate encrypted face images to protect users from being identified by FR systems. However, existing methods suffer from poor visual quality or low attack success rates, which limit their usability in practice. In this paper, we propose Attribute Guided Encryption with Facial Texture Masking (AGE-FTM) that performs a dual manifold adversarial attack on FR systems to achieve both good visual quality and high black box attack success rates. In particular, AGE-FTM utilizes a high fidelity generative adversarial network (GAN) to generate natural on-manifold adversarial samples by modifying facial attributes, and performs the facial texture masking attack to generate imperceptible off-manifold adversarial samples. Extensive experiments on the CelebA-HQ dataset demonstrate that our proposed method produces more natural-looking encrypted images than state-of-the-art methods while achieving competitive attack performance. We further evaluate the effectiveness of AGE-FTM in the real world using a commercial FR API and validate its usefulness in practice through an user study.