 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Controllable Dynamic Appearance for Neural 3D Portraits
Sep 20, 2023

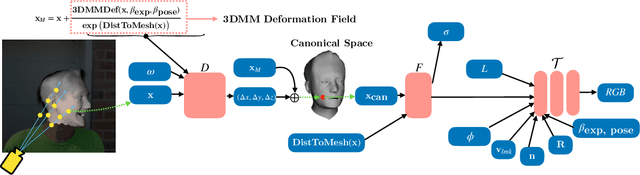
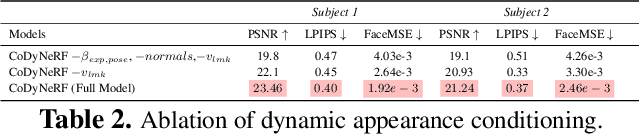
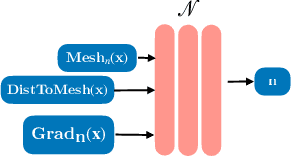
Recent advances in Neural Radiance Fields (NeRFs) have made it possible to reconstruct and reanimate dynamic portrait scenes with control over head-pose, facial expressions and viewing direction. However, training such models assumes photometric consistency over the deformed region e.g. the face must be evenly lit as it deforms with changing head-pose and facial expression. Such photometric consistency across frames of a video is hard to maintain, even in studio environments, thus making the created reanimatable neural portraits prone to artifacts during reanimation. In this work, we propose CoDyNeRF, a system that enables the creation of fully controllable 3D portraits in real-world capture conditions. CoDyNeRF learns to approximate illumination dependent effects via a dynamic appearance model in the canonical space that is conditioned on predicted surface normals and the facial expressions and head-pose deformations. The surface normals prediction is guided using 3DMM normals that act as a coarse prior for the normals of the human head, where direct prediction of normals is hard due to rigid and non-rigid deformations induced by head-pose and facial expression changes. Using only a smartphone-captured short video of a subject for training, we demonstrate the effectiveness of our method on free view synthesis of a portrait scene with explicit head pose and expression controls, and realistic lighting effects. The project page can be found here: http://shahrukhathar.github.io/2023/08/22/CoDyNeRF.html
Audio-Driven 3D Facial Animation from In-the-Wild Videos
Jun 20, 2023
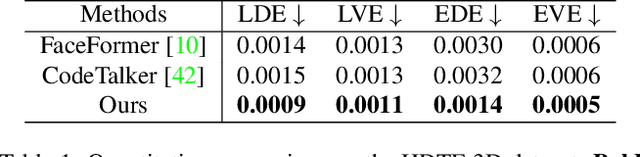
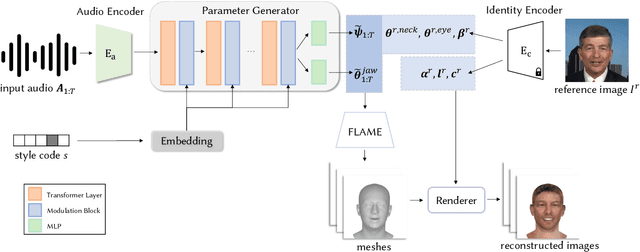
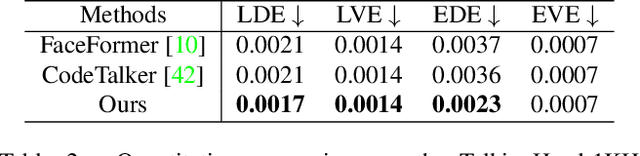
Given an arbitrary audio clip, audio-driven 3D facial animation aims to generate lifelike lip motions and facial expressions for a 3D head. Existing methods typically rely on training their models using limited public 3D datasets that contain a restricted number of audio-3D scan pairs. Consequently, their generalization capability remains limited. In this paper, we propose a novel method that leverages in-the-wild 2D talking-head videos to train our 3D facial animation model. The abundance of easily accessible 2D talking-head videos equips our model with a robust generalization capability. By combining these videos with existing 3D face reconstruction methods, our model excels in generating consistent and high-fidelity lip synchronization. Additionally, our model proficiently captures the speaking styles of different individuals, allowing it to generate 3D talking-heads with distinct personal styles. Extensive qualitative and quantitative experimental results demonstrate the superiority of our method.
CleftGAN: Adapting A Style-Based Generative Adversarial Network To Create Images Depicting Cleft Lip Deformity
Oct 12, 2023

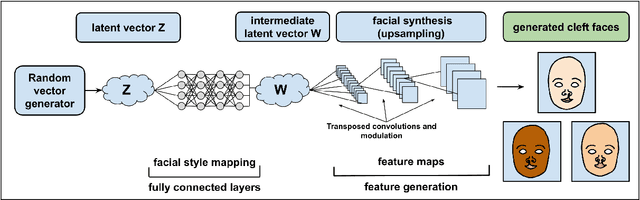
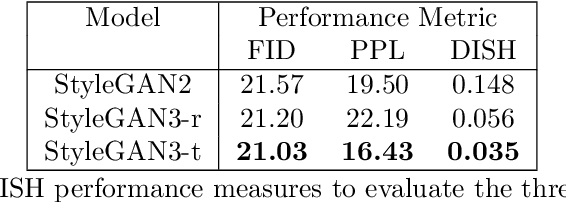
A major obstacle when attempting to train a machine learning system to evaluate facial clefts is the scarcity of large datasets of high-quality, ethics board-approved patient images. In response, we have built a deep learning-based cleft lip generator designed to produce an almost unlimited number of artificial images exhibiting high-fidelity facsimiles of cleft lip with wide variation. We undertook a transfer learning protocol testing different versions of StyleGAN-ADA (a generative adversarial network image generator incorporating adaptive data augmentation (ADA)) as the base model. Training images depicting a variety of cleft deformities were pre-processed to adjust for rotation, scaling, color adjustment and background blurring. The ADA modification of the primary algorithm permitted construction of our new generative model while requiring input of a relatively small number of training images. Adversarial training was carried out using 514 unique frontal photographs of cleft-affected faces to adapt a pre-trained model based on 70,000 normal faces. The Frechet Inception Distance (FID) was used to measure the similarity of the newly generated facial images to the cleft training dataset, while Perceptual Path Length (PPL) and the novel Divergence Index of Severity Histograms (DISH) measures were also used to assess the performance of the image generator that we dub CleftGAN. We found that StyleGAN3 with translation invariance (StyleGAN3-t) performed optimally as a base model. Generated images achieved a low FID reflecting a close similarity to our training input dataset of genuine cleft images. Low PPL and DISH measures reflected a smooth and semantically valid interpolation of images through the transfer learning process and a similar distribution of severity in the training and generated images, respectively.
Denoising total scattering data using Compressed Sensing
Oct 18, 2023To obtain the best resolution for any measurement there is an ever-present challenge to achieve maximal differentiation between signal and noise over as fine of sampling dimensions as possible. In diffraction science these issues are particularly pervasive when analyzing small crystals, systems with diffuse scattering, or other systems in which the signal of interest is extremely weak and incident flux and instrument time is limited. We here demonstrate that the tool of compressed sensing, which has successfully been applied to photography, facial recognition, and medical imaging, , can be effectively applied to diffraction images to dramatically improve the signal-to-noise ratio (SNR) in a data-driven fashion without the need for additional measurements or modification of existing hardware. We outline a technique that leverages compressive sensing to bootstrap a single diffraction measurement into an effectively arbitrary number of virtual measurements, thereby providing a means of super-resolution imaging.
Privacy-preserving Adversarial Facial Features
May 08, 2023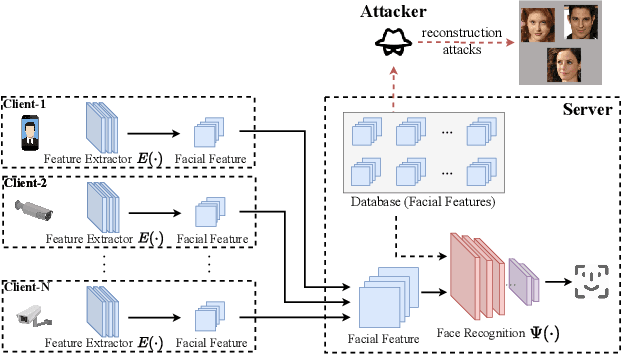

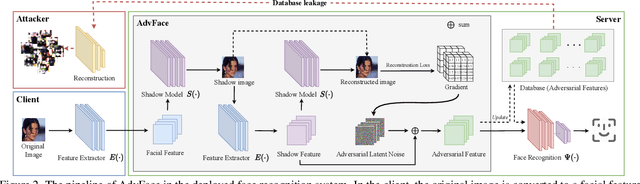

Face recognition service providers protect face privacy by extracting compact and discriminative facial features (representations) from images, and storing the facial features for real-time recognition. However, such features can still be exploited to recover the appearance of the original face by building a reconstruction network. Although several privacy-preserving methods have been proposed, the enhancement of face privacy protection is at the expense of accuracy degradation. In this paper, we propose an adversarial features-based face privacy protection (AdvFace) approach to generate privacy-preserving adversarial features, which can disrupt the mapping from adversarial features to facial images to defend against reconstruction attacks. To this end, we design a shadow model which simulates the attackers' behavior to capture the mapping function from facial features to images and generate adversarial latent noise to disrupt the mapping. The adversarial features rather than the original features are stored in the server's database to prevent leaked features from exposing facial information. Moreover, the AdvFace requires no changes to the face recognition network and can be implemented as a privacy-enhancing plugin in deployed face recognition systems. Extensive experimental results demonstrate that AdvFace outperforms the state-of-the-art face privacy-preserving methods in defending against reconstruction attacks while maintaining face recognition accuracy.
Enhancing the Authenticity of Rendered Portraits with Identity-Consistent Transfer Learning
Oct 06, 2023Despite rapid advances in computer graphics, creating high-quality photo-realistic virtual portraits is prohibitively expensive. Furthermore, the well-know ''uncanny valley'' effect in rendered portraits has a significant impact on the user experience, especially when the depiction closely resembles a human likeness, where any minor artifacts can evoke feelings of eeriness and repulsiveness. In this paper, we present a novel photo-realistic portrait generation framework that can effectively mitigate the ''uncanny valley'' effect and improve the overall authenticity of rendered portraits. Our key idea is to employ transfer learning to learn an identity-consistent mapping from the latent space of rendered portraits to that of real portraits. During the inference stage, the input portrait of an avatar can be directly transferred to a realistic portrait by changing its appearance style while maintaining the facial identity. To this end, we collect a new dataset, Daz-Rendered-Faces-HQ (DRFHQ), that is specifically designed for rendering-style portraits. We leverage this dataset to fine-tune the StyleGAN2 generator, using our carefully crafted framework, which helps to preserve the geometric and color features relevant to facial identity. We evaluate our framework using portraits with diverse gender, age, and race variations. Qualitative and quantitative evaluations and ablation studies show the advantages of our method compared to state-of-the-art approaches.
Parametric Implicit Face Representation for Audio-Driven Facial Reenactment
Jun 13, 2023
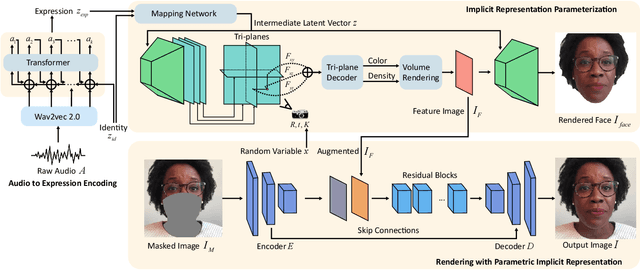

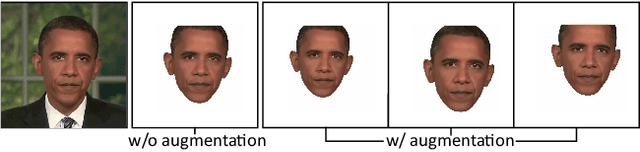
Audio-driven facial reenactment is a crucial technique that has a range of applications in film-making, virtual avatars and video conferences. Existing works either employ explicit intermediate face representations (e.g., 2D facial landmarks or 3D face models) or implicit ones (e.g., Neural Radiance Fields), thus suffering from the trade-offs between interpretability and expressive power, hence between controllability and quality of the results. In this work, we break these trade-offs with our novel parametric implicit face representation and propose a novel audio-driven facial reenactment framework that is both controllable and can generate high-quality talking heads. Specifically, our parametric implicit representation parameterizes the implicit representation with interpretable parameters of 3D face models, thereby taking the best of both explicit and implicit methods. In addition, we propose several new techniques to improve the three components of our framework, including i) incorporating contextual information into the audio-to-expression parameters encoding; ii) using conditional image synthesis to parameterize the implicit representation and implementing it with an innovative tri-plane structure for efficient learning; iii) formulating facial reenactment as a conditional image inpainting problem and proposing a novel data augmentation technique to improve model generalizability. Extensive experiments demonstrate that our method can generate more realistic results than previous methods with greater fidelity to the identities and talking styles of speakers.
Seeing and hearing what has not been said; A multimodal client behavior classifier in Motivational Interviewing with interpretable fusion
Sep 27, 2023Motivational Interviewing (MI) is an approach to therapy that emphasizes collaboration and encourages behavioral change. To evaluate the quality of an MI conversation, client utterances can be classified using the MISC code as either change talk, sustain talk, or follow/neutral talk. The proportion of change talk in a MI conversation is positively correlated with therapy outcomes, making accurate classification of client utterances essential. In this paper, we present a classifier that accurately distinguishes between the three MISC classes (change talk, sustain talk, and follow/neutral talk) leveraging multimodal features such as text, prosody, facial expressivity, and body expressivity. To train our model, we perform annotations on the publicly available AnnoMI dataset to collect multimodal information, including text, audio, facial expressivity, and body expressivity. Furthermore, we identify the most important modalities in the decision-making process, providing valuable insights into the interplay of different modalities during a MI conversation.
Vista-Morph: Unsupervised Image Registration of Visible-Thermal Facial Pairs
Jun 10, 2023
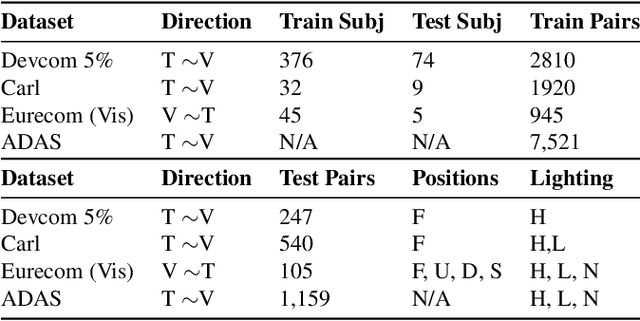
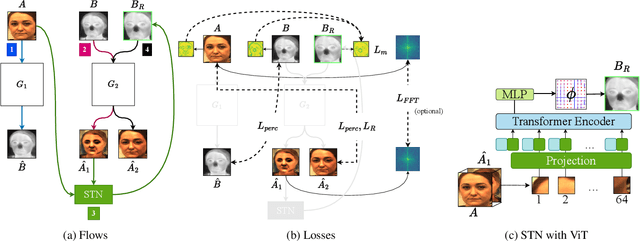
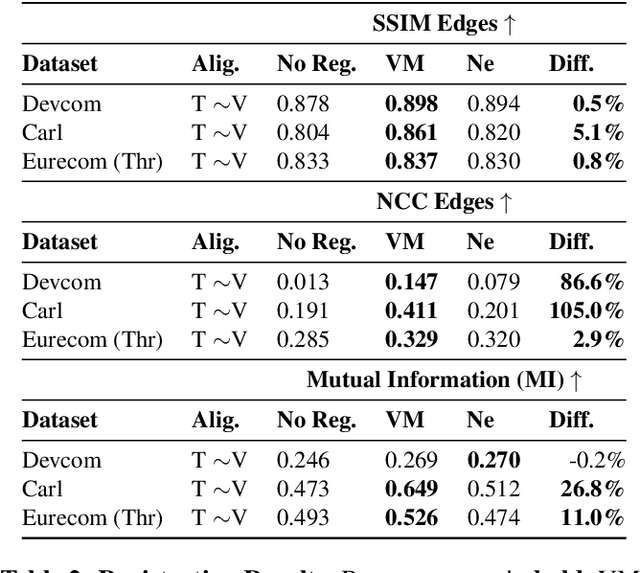
For a variety of biometric cross-spectral tasks, Visible-Thermal (VT) facial pairs are used. However, due to a lack of calibration in the lab, photographic capture between two different sensors leads to severely misaligned pairs that can lead to poor results for person re-identification and generative AI. To solve this problem, we introduce our approach for VT image registration called Vista Morph. Unlike existing VT facial registration that requires manual, hand-crafted features for pixel matching and/or a supervised thermal reference, Vista Morph is completely unsupervised without the need for a reference. By learning the affine matrix through a Vision Transformer (ViT)-based Spatial Transformer Network (STN) and Generative Adversarial Networks (GAN), Vista Morph successfully aligns facial and non-facial VT images. Our approach learns warps in Hard, No, and Low-light visual settings and is robust to geometric perturbations and erasure at test time. We conduct a downstream generative AI task to show that registering training data with Vista Morph improves subject identity of generated thermal faces when performing V2T image translation.
New Benchmarks for Asian Facial Recognition Tasks: Face Classification with Large Foundation Models
Oct 15, 2023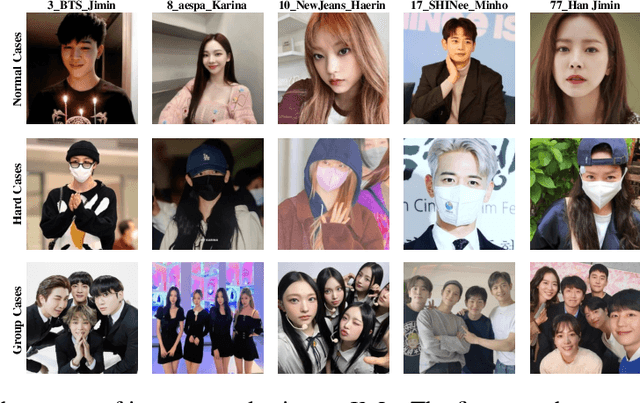
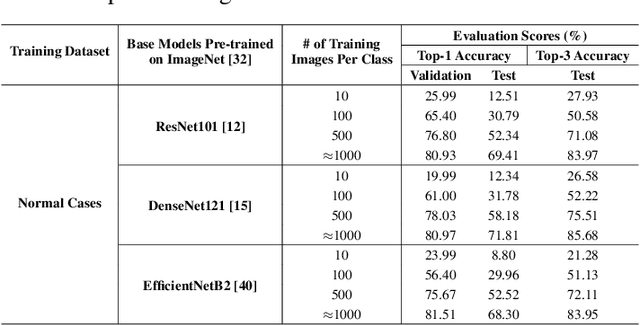
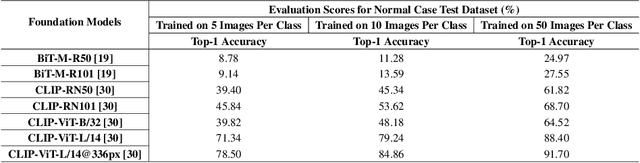

The face classification system is an important tool for recognizing personal identity properly. This paper introduces a new Large-Scale Korean Influencer Dataset named KoIn. Our presented dataset contains many real-world photos of Korean celebrities in various environments that might contain stage lighting, backup dancers, and background objects. These various images can be useful for training classification models classifying K-influencers. Most of the images in our proposed dataset have been collected from social network services (SNS) such as Instagram. Our dataset, KoIn, contains over 100,000 K-influencer photos from over 100 Korean celebrity classes. Moreover, our dataset provides additional hard case samples such as images including human faces with masks and hats. We note that the hard case samples are greatly useful in evaluating the robustness of the classification systems. We have extensively conducted several experiments utilizing various classification models to validate the effectiveness of our proposed dataset. Specifically, we demonstrate that recent state-of-the-art (SOTA) foundation architectures show decent classification performance when trained on our proposed dataset. In this paper, we also analyze the robustness performance against hard case samples of large-scale foundation models when we fine-tune the foundation models on the normal cases of the proposed dataset, KoIn. Our presented dataset and codes will be publicly available at https://github.com/dukong1/KoIn_Benchmark_Dataset.