 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Facial Expression Re-targeting from a Single Character
Jun 21, 2023


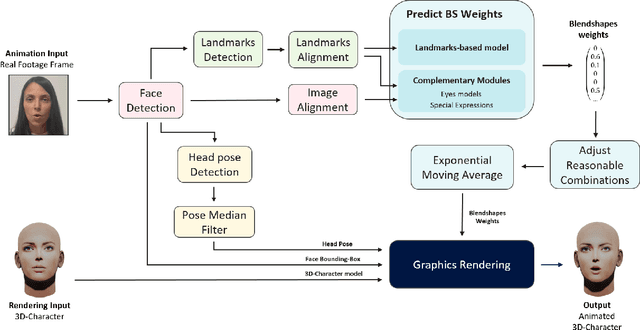

Video retargeting for digital face animation is used in virtual reality, social media, gaming, movies, and video conference, aiming to animate avatars' facial expressions based on videos of human faces. The standard method to represent facial expressions for 3D characters is by blendshapes, a vector of weights representing the avatar's neutral shape and its variations under facial expressions, e.g., smile, puff, blinking. Datasets of paired frames with blendshape vectors are rare, and labeling can be laborious, time-consuming, and subjective. In this work, we developed an approach that handles the lack of appropriate datasets. Instead, we used a synthetic dataset of only one character. To generalize various characters, we re-represented each frame to face landmarks. We developed a unique deep-learning architecture that groups landmarks for each facial organ and connects them to relevant blendshape weights. Additionally, we incorporated complementary methods for facial expressions that landmarks did not represent well and gave special attention to eye expressions. We have demonstrated the superiority of our approach to previous research in qualitative and quantitative metrics. Our approach achieved a higher MOS of 68% and a lower MSE of 44.2% when tested on videos with various users and expressions.
FACTS: Facial Animation Creation using the Transfer of Styles
Jul 18, 2023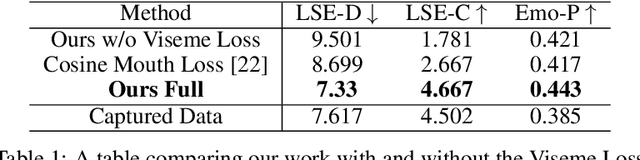
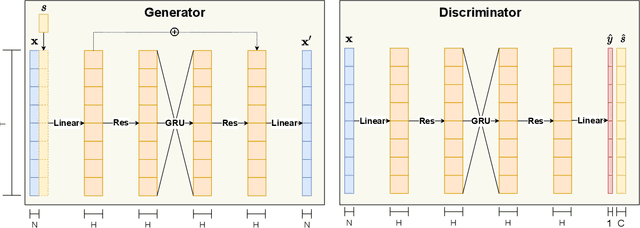
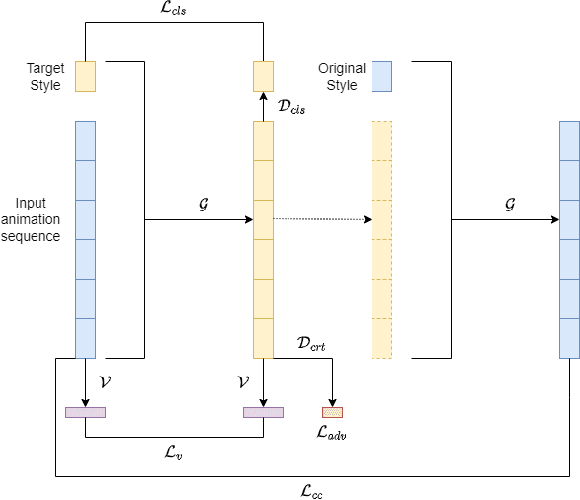

The ability to accurately capture and express emotions is a critical aspect of creating believable characters in video games and other forms of entertainment. Traditionally, this animation has been achieved with artistic effort or performance capture, both requiring costs in time and labor. More recently, audio-driven models have seen success, however, these often lack expressiveness in areas not correlated to the audio signal. In this paper, we present a novel approach to facial animation by taking existing animations and allowing for the modification of style characteristics. Specifically, we explore the use of a StarGAN to enable the conversion of 3D facial animations into different emotions and person-specific styles. We are able to maintain the lip-sync of the animations with this method thanks to the use of a novel viseme-preserving loss.
TranSTYLer: Multimodal Behavioral Style Transfer for Facial and Body Gestures Generation
Aug 08, 2023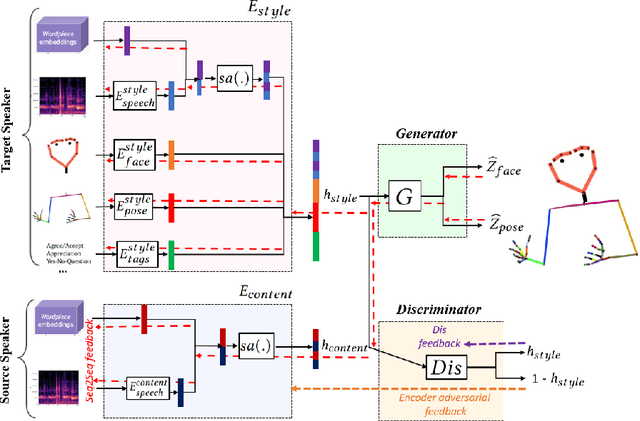

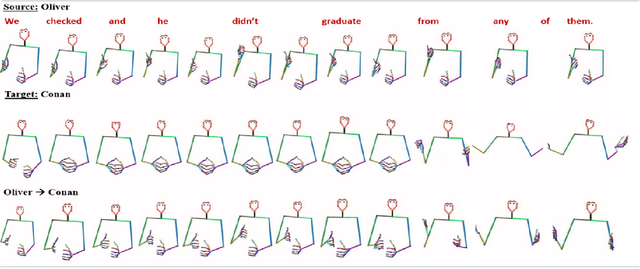
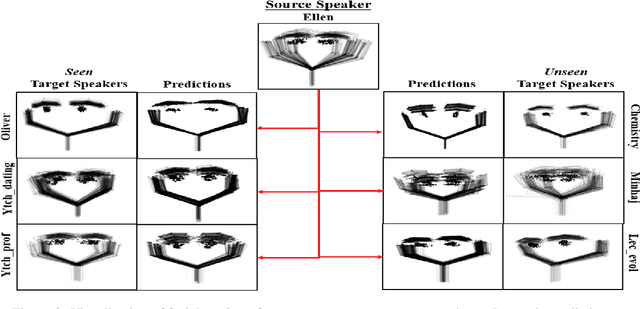
This paper addresses the challenge of transferring the behavior expressivity style of a virtual agent to another one while preserving behaviors shape as they carry communicative meaning. Behavior expressivity style is viewed here as the qualitative properties of behaviors. We propose TranSTYLer, a multimodal transformer based model that synthesizes the multimodal behaviors of a source speaker with the style of a target speaker. We assume that behavior expressivity style is encoded across various modalities of communication, including text, speech, body gestures, and facial expressions. The model employs a style and content disentanglement schema to ensure that the transferred style does not interfere with the meaning conveyed by the source behaviors. Our approach eliminates the need for style labels and allows the generalization to styles that have not been seen during the training phase. We train our model on the PATS corpus, which we extended to include dialog acts and 2D facial landmarks. Objective and subjective evaluations show that our model outperforms state of the art models in style transfer for both seen and unseen styles during training. To tackle the issues of style and content leakage that may arise, we propose a methodology to assess the degree to which behavior and gestures associated with the target style are successfully transferred, while ensuring the preservation of the ones related to the source content.
Optimizing Key-Selection for Face-based One-Time Biometrics via Morphing
Oct 04, 2023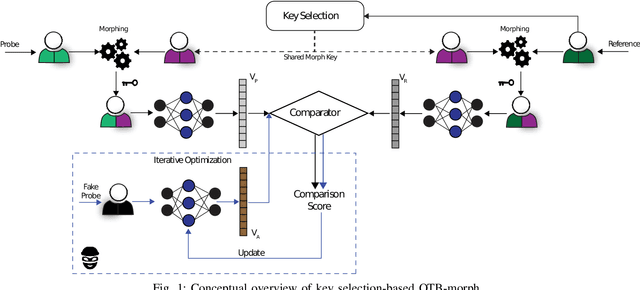

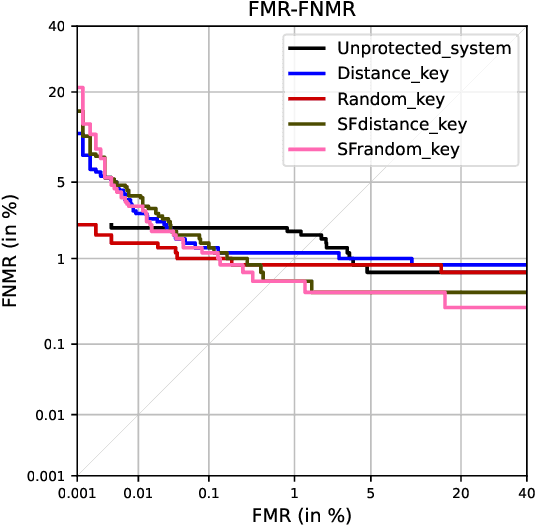
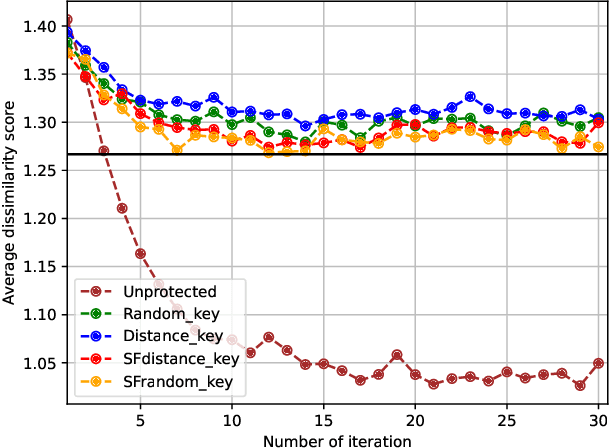
Nowadays, facial recognition systems are still vulnerable to adversarial attacks. These attacks vary from simple perturbations of the input image to modifying the parameters of the recognition model to impersonate an authorised subject. So-called privacy-enhancing facial recognition systems have been mostly developed to provide protection of stored biometric reference data, i.e. templates. In the literature, privacy-enhancing facial recognition approaches have focused solely on conventional security threats at the template level, ignoring the growing concern related to adversarial attacks. Up to now, few works have provided mechanisms to protect face recognition against adversarial attacks while maintaining high security at the template level. In this paper, we propose different key selection strategies to improve the security of a competitive cancelable scheme operating at the signal level. Experimental results show that certain strategies based on signal-level key selection can lead to complete blocking of the adversarial attack based on an iterative optimization for the most secure threshold, while for the most practical threshold, the attack success chance can be decreased to approximately 5.0%.
SDeMorph: Towards Better Facial De-morphing from Single Morph
Aug 22, 2023

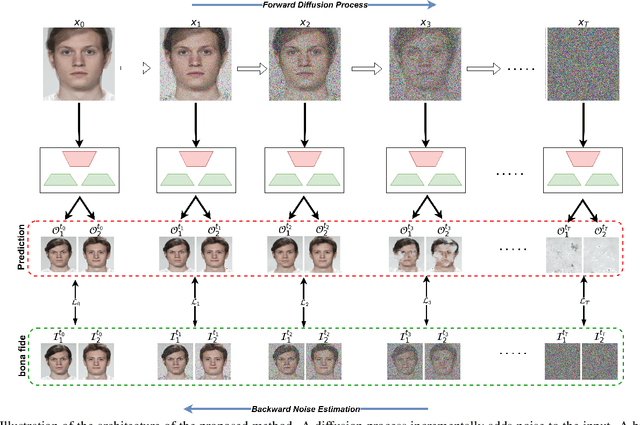

Face Recognition Systems (FRS) are vulnerable to morph attacks. A face morph is created by combining multiple identities with the intention to fool FRS and making it match the morph with multiple identities. Current Morph Attack Detection (MAD) can detect the morph but are unable to recover the identities used to create the morph with satisfactory outcomes. Existing work in de-morphing is mostly reference-based, i.e. they require the availability of one identity to recover the other. Sudipta et al. \cite{ref9} proposed a reference-free de-morphing technique but the visual realism of outputs produced were feeble. In this work, we propose SDeMorph (Stably Diffused De-morpher), a novel de-morphing method that is reference-free and recovers the identities of bona fides. Our method produces feature-rich outputs that are of significantly high quality in terms of definition and facial fidelity. Our method utilizes Denoising Diffusion Probabilistic Models (DDPM) by destroying the input morphed signal and then reconstructing it back using a branched-UNet. Experiments on ASML, FRLL-FaceMorph, FRLL-MorDIFF, and SMDD datasets support the effectiveness of the proposed method.
AV-Lip-Sync+: Leveraging AV-HuBERT to Exploit Multimodal Inconsistency for Video Deepfake Detection
Nov 05, 2023Multimodal manipulations (also known as audio-visual deepfakes) make it difficult for unimodal deepfake detectors to detect forgeries in multimedia content. To avoid the spread of false propaganda and fake news, timely detection is crucial. The damage to either modality (i.e., visual or audio) can only be discovered through multi-modal models that can exploit both pieces of information simultaneously. Previous methods mainly adopt uni-modal video forensics and use supervised pre-training for forgery detection. This study proposes a new method based on a multi-modal self-supervised-learning (SSL) feature extractor to exploit inconsistency between audio and visual modalities for multi-modal video forgery detection. We use the transformer-based SSL pre-trained Audio-Visual HuBERT (AV-HuBERT) model as a visual and acoustic feature extractor and a multi-scale temporal convolutional neural network to capture the temporal correlation between the audio and visual modalities. Since AV-HuBERT only extracts visual features from the lip region, we also adopt another transformer-based video model to exploit facial features and capture spatial and temporal artifacts caused during the deepfake generation process. Experimental results show that our model outperforms all existing models and achieves new state-of-the-art performance on the FakeAVCeleb and DeepfakeTIMIT datasets.
Towards Inferring Users' Impressions of Robot Performance in Navigation Scenarios
Oct 17, 2023Human impressions of robot performance are often measured through surveys. As a more scalable and cost-effective alternative, we study the possibility of predicting people's impressions of robot behavior using non-verbal behavioral cues and machine learning techniques. To this end, we first contribute the SEAN TOGETHER Dataset consisting of observations of an interaction between a person and a mobile robot in a Virtual Reality simulation, together with impressions of robot performance provided by users on a 5-point scale. Second, we contribute analyses of how well humans and supervised learning techniques can predict perceived robot performance based on different combinations of observation types (e.g., facial, spatial, and map features). Our results show that facial expressions alone provide useful information about human impressions of robot performance; but in the navigation scenarios we tested, spatial features are the most critical piece of information for this inference task. Also, when evaluating results as binary classification (rather than multiclass classification), the F1-Score of human predictions and machine learning models more than doubles, showing that both are better at telling the directionality of robot performance than predicting exact performance ratings. Based on our findings, we provide guidelines for implementing these predictions models in real-world navigation scenarios.
Multi-scale Promoted Self-adjusting Correlation Learning for Facial Action Unit Detection
Aug 15, 2023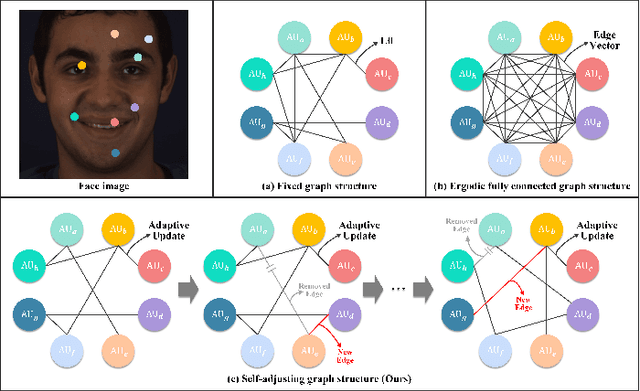
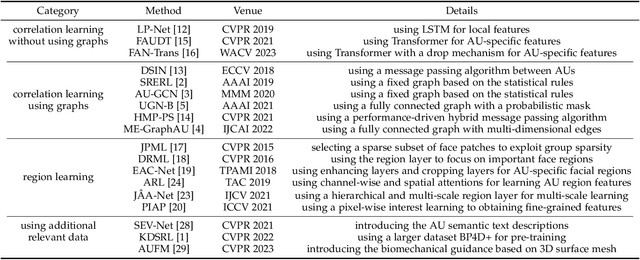
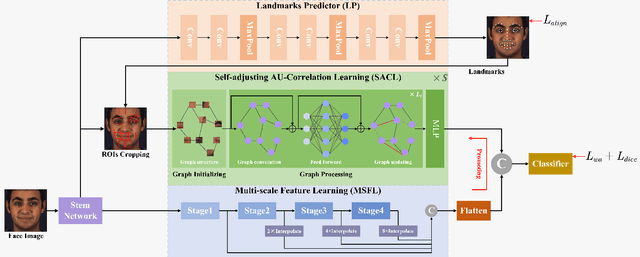
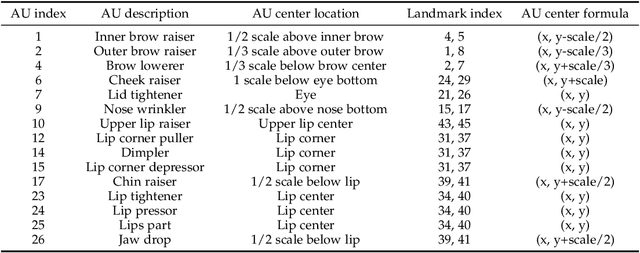
Facial Action Unit (AU) detection is a crucial task in affective computing and social robotics as it helps to identify emotions expressed through facial expressions. Anatomically, there are innumerable correlations between AUs, which contain rich information and are vital for AU detection. Previous methods used fixed AU correlations based on expert experience or statistical rules on specific benchmarks, but it is challenging to comprehensively reflect complex correlations between AUs via hand-crafted settings. There are alternative methods that employ a fully connected graph to learn these dependencies exhaustively. However, these approaches can result in a computational explosion and high dependency with a large dataset. To address these challenges, this paper proposes a novel self-adjusting AU-correlation learning (SACL) method with less computation for AU detection. This method adaptively learns and updates AU correlation graphs by efficiently leveraging the characteristics of different levels of AU motion and emotion representation information extracted in different stages of the network. Moreover, this paper explores the role of multi-scale learning in correlation information extraction, and design a simple yet effective multi-scale feature learning (MSFL) method to promote better performance in AU detection. By integrating AU correlation information with multi-scale features, the proposed method obtains a more robust feature representation for the final AU detection. Extensive experiments show that the proposed method outperforms the state-of-the-art methods on widely used AU detection benchmark datasets, with only 28.7\% and 12.0\% of the parameters and FLOPs of the best method, respectively. The code for this method is available at \url{https://github.com/linuxsino/Self-adjusting-AU}.
ReactFace: Multiple Appropriate Facial Reaction Generation in Dyadic Interactions
May 25, 2023
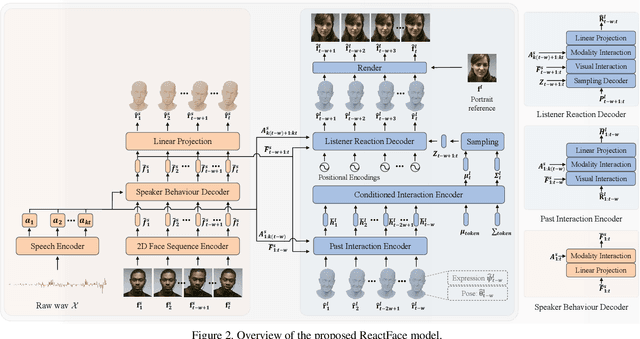

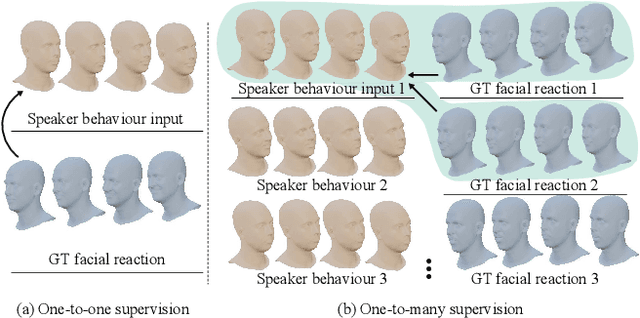
In dyadic interaction, predicting the listener's facial reactions is challenging as different reactions may be appropriate in response to the same speaker's behaviour. This paper presents a novel framework called ReactFace that learns an appropriate facial reaction distribution from a speaker's behaviour rather than replicating the real facial reaction of the listener. ReactFace generates multiple different but appropriate photo-realistic human facial reactions by (i) learning an appropriate facial reaction distribution representing multiple appropriate facial reactions; and (ii) synchronizing the generated facial reactions with the speaker's verbal and non-verbal behaviours at each time stamp, resulting in realistic 2D facial reaction sequences. Experimental results demonstrate the effectiveness of our approach in generating multiple diverse, synchronized, and appropriate facial reactions from each speaker's behaviour, with the quality of the generated reactions being influenced by the speaker's speech and facial behaviours. Our code is made publicly available at \url{https://github.com/lingjivoo/ReactFace}.
Perceptual Quality Improvement in Videoconferencing using Keyframes-based GAN
Nov 07, 2023In the latest years, videoconferencing has taken a fundamental role in interpersonal relations, both for personal and business purposes. Lossy video compression algorithms are the enabling technology for videoconferencing, as they reduce the bandwidth required for real-time video streaming. However, lossy video compression decreases the perceived visual quality. Thus, many techniques for reducing compression artifacts and improving video visual quality have been proposed in recent years. In this work, we propose a novel GAN-based method for compression artifacts reduction in videoconferencing. Given that, in this context, the speaker is typically in front of the camera and remains the same for the entire duration of the transmission, we can maintain a set of reference keyframes of the person from the higher-quality I-frames that are transmitted within the video stream and exploit them to guide the visual quality improvement; a novel aspect of this approach is the update policy that maintains and updates a compact and effective set of reference keyframes. First, we extract multi-scale features from the compressed and reference frames. Then, our architecture combines these features in a progressive manner according to facial landmarks. This allows the restoration of the high-frequency details lost after the video compression. Experiments show that the proposed approach improves visual quality and generates photo-realistic results even with high compression rates. Code and pre-trained networks are publicly available at https://github.com/LorenzoAgnolucci/Keyframes-GAN.