 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
PrivacyGAN: robust generative image privacy
Oct 19, 2023
Classical techniques for protecting facial image privacy typically fall into two categories: data-poisoning methods, exemplified by Fawkes, which introduce subtle perturbations to images, or anonymization methods that generate images resembling the original only in several characteristics, such as gender, ethnicity, or facial expression.In this study, we introduce a novel approach, PrivacyGAN, that uses the power of image generation techniques, such as VQGAN and StyleGAN, to safeguard privacy while maintaining image usability, particularly for social media applications. Drawing inspiration from Fawkes, our method entails shifting the original image within the embedding space towards a decoy image.We evaluate our approach using privacy metrics on traditional and novel facial image datasets. Additionally, we propose new criteria for evaluating the robustness of privacy-protection methods against unknown image recognition techniques, and we demonstrate that our approach is effective even in unknown embedding transfer scenarios. We also provide a human evaluation that further proves that the modified image preserves its utility as it remains recognisable as an image of the same person by friends and family.
DF-TransFusion: Multimodal Deepfake Detection via Lip-Audio Cross-Attention and Facial Self-Attention
Sep 12, 2023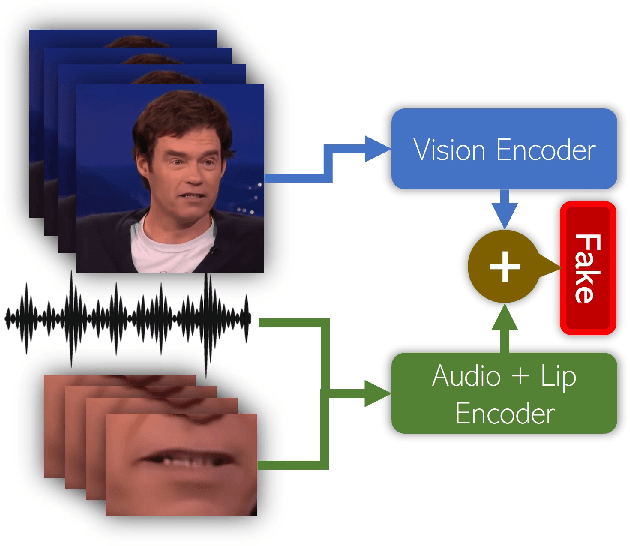
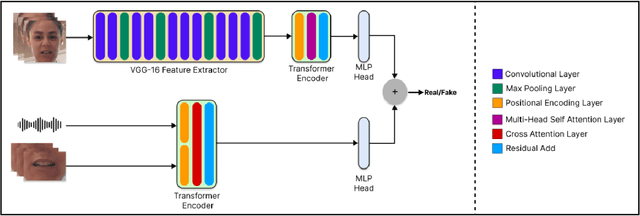
With the rise in manipulated media, deepfake detection has become an imperative task for preserving the authenticity of digital content. In this paper, we present a novel multi-modal audio-video framework designed to concurrently process audio and video inputs for deepfake detection tasks. Our model capitalizes on lip synchronization with input audio through a cross-attention mechanism while extracting visual cues via a fine-tuned VGG-16 network. Subsequently, a transformer encoder network is employed to perform facial self-attention. We conduct multiple ablation studies highlighting different strengths of our approach. Our multi-modal methodology outperforms state-of-the-art multi-modal deepfake detection techniques in terms of F-1 and per-video AUC scores.
NOFA: NeRF-based One-shot Facial Avatar Reconstruction
Jul 07, 2023
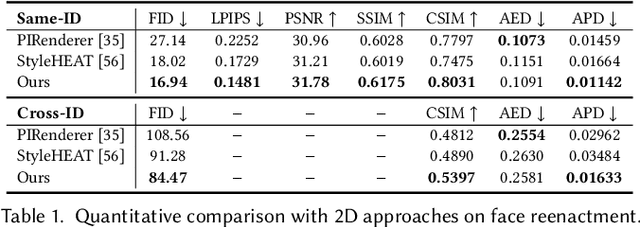
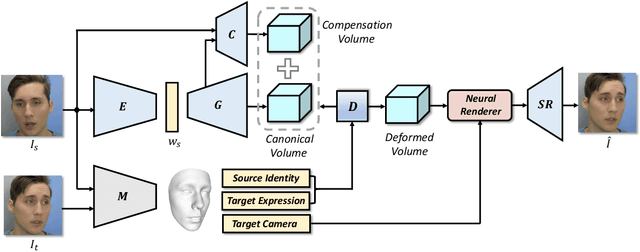
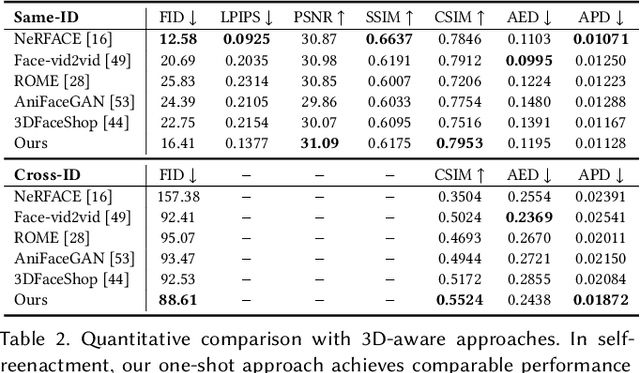
3D facial avatar reconstruction has been a significant research topic in computer graphics and computer vision, where photo-realistic rendering and flexible controls over poses and expressions are necessary for many related applications. Recently, its performance has been greatly improved with the development of neural radiance fields (NeRF). However, most existing NeRF-based facial avatars focus on subject-specific reconstruction and reenactment, requiring multi-shot images containing different views of the specific subject for training, and the learned model cannot generalize to new identities, limiting its further applications. In this work, we propose a one-shot 3D facial avatar reconstruction framework that only requires a single source image to reconstruct a high-fidelity 3D facial avatar. For the challenges of lacking generalization ability and missing multi-view information, we leverage the generative prior of 3D GAN and develop an efficient encoder-decoder network to reconstruct the canonical neural volume of the source image, and further propose a compensation network to complement facial details. To enable fine-grained control over facial dynamics, we propose a deformation field to warp the canonical volume into driven expressions. Through extensive experimental comparisons, we achieve superior synthesis results compared to several state-of-the-art methods.
DeepMetricEye: Metric Depth Estimation in Periocular VR Imagery
Nov 13, 2023
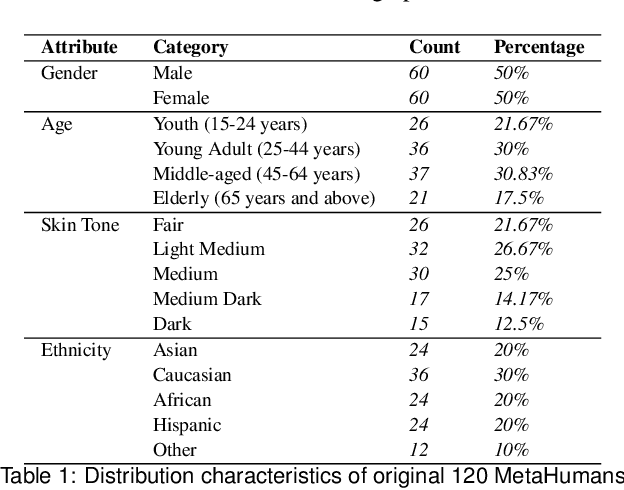

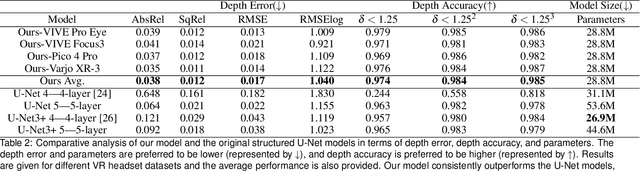
Despite the enhanced realism and immersion provided by VR headsets, users frequently encounter adverse effects such as digital eye strain (DES), dry eye, and potential long-term visual impairment due to excessive eye stimulation from VR displays and pressure from the mask. Recent VR headsets are increasingly equipped with eye-oriented monocular cameras to segment ocular feature maps. Yet, to compute the incident light stimulus and observe periocular condition alterations, it is imperative to transform these relative measurements into metric dimensions. To bridge this gap, we propose a lightweight framework derived from the U-Net 3+ deep learning backbone that we re-optimised, to estimate measurable periocular depth maps. Compatible with any VR headset equipped with an eye-oriented monocular camera, our method reconstructs three-dimensional periocular regions, providing a metric basis for related light stimulus calculation protocols and medical guidelines. Navigating the complexities of data collection, we introduce a Dynamic Periocular Data Generation (DPDG) environment based on UE MetaHuman, which synthesises thousands of training images from a small quantity of human facial scan data. Evaluated on a sample of 36 participants, our method exhibited notable efficacy in the periocular global precision evaluation experiment, and the pupil diameter measurement.
Multi-Task Faces (MTF) Data Set: A Legally and Ethically Compliant Collection of Face Images for Various Classification Tasks
Nov 20, 2023Human facial data hold tremendous potential to address a variety of classification problems, including face recognition, age estimation, gender identification, emotion analysis, and race classification. However, recent privacy regulations, such as the EU General Data Protection Regulation and others, have restricted the ways in which human images may be collected and used for research. As a result, several previously published data sets containing human faces have been removed from the internet due to inadequate data collection methods that failed to meet privacy regulations. Data sets consisting of synthetic data have been proposed as an alternative, but they fall short of accurately representing the real data distribution. On the other hand, most available data sets are labeled for just a single task, which limits their applicability. To address these issues, we present the Multi-Task Faces (MTF) image data set, a meticulously curated collection of face images designed for various classification tasks, including face recognition, as well as race, gender, and age classification. The MTF data set has been ethically gathered by leveraging publicly available images of celebrities and strictly adhering to copyright regulations. In this paper, we present this data set and provide detailed descriptions of the followed data collection and processing procedures. Furthermore, we evaluate the performance of five deep learning (DL) models on the MTF data set across the aforementioned classification tasks. Additionally, we compare the performance of DL models over the processed MTF data and over raw data crawled from the internet. The reported results constitute a baseline for further research employing these data. The MTF data set can be accessed through the following link (please cite the present paper if you use the data set): https://github.com/RamiHaf/MTF_data_set
Occlusion Aware Student Emotion Recognition based on Facial Action Unit Detection
Jul 18, 2023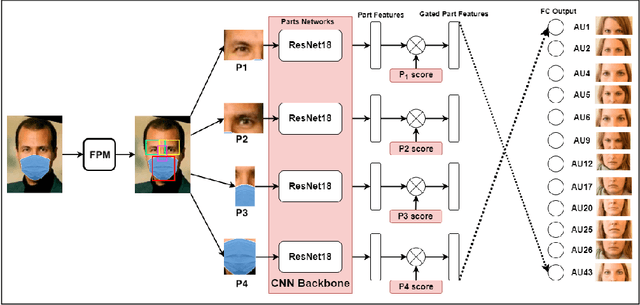
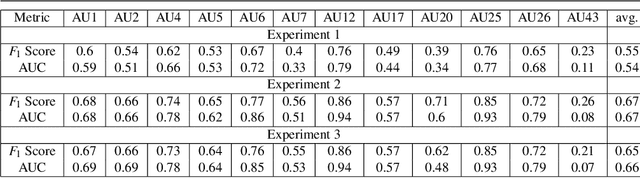

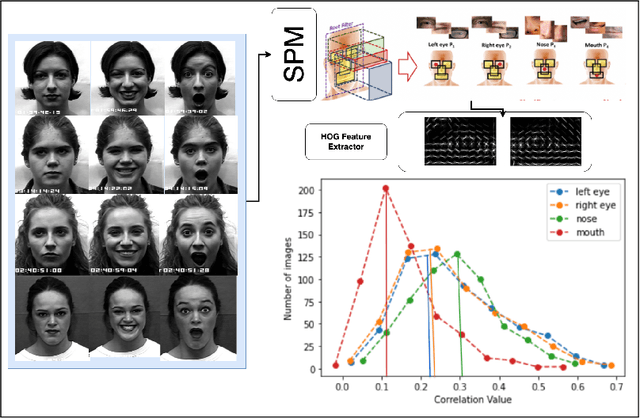
Given that approximately half of science, technology, engineering, and mathematics (STEM) undergraduate students in U.S. colleges and universities leave by the end of the first year [15], it is crucial to improve the quality of classroom environments. This study focuses on monitoring students' emotions in the classroom as an indicator of their engagement and proposes an approach to address this issue. The impact of different facial parts on the performance of an emotional recognition model is evaluated through experimentation. To test the proposed model under partial occlusion, an artificially occluded dataset is introduced. The novelty of this work lies in the proposal of an occlusion-aware architecture for facial action units (AUs) extraction, which employs attention mechanism and adaptive feature learning. The AUs can be used later to classify facial expressions in classroom settings. This research paper's findings provide valuable insights into handling occlusion in analyzing facial images for emotional engagement analysis. The proposed experiments demonstrate the significance of considering occlusion and enhancing the reliability of facial analysis models in classroom environments. These findings can also be extended to other settings where occlusions are prevalent.
SAFER: Situation Aware Facial Emotion Recognition
Jun 14, 2023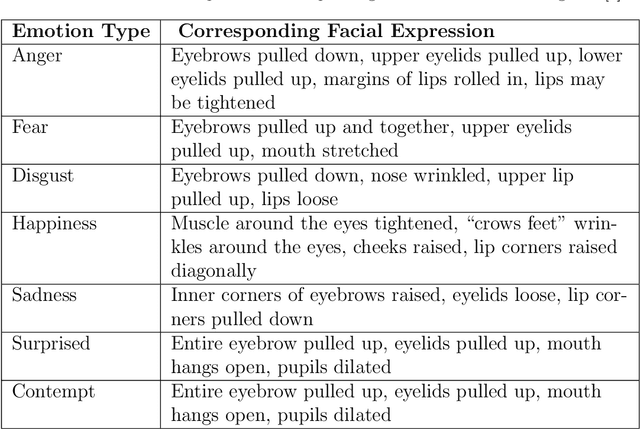


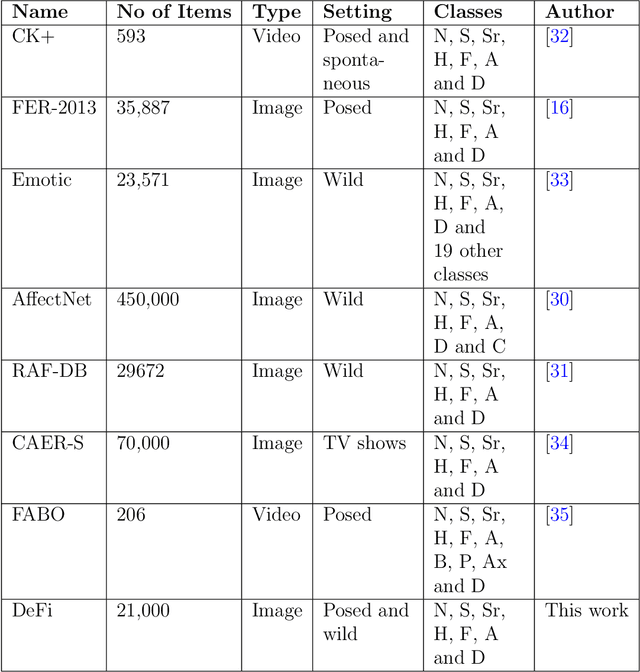
In this paper, we present SAFER, a novel system for emotion recognition from facial expressions. It employs state-of-the-art deep learning techniques to extract various features from facial images and incorporates contextual information, such as background and location type, to enhance its performance. The system has been designed to operate in an open-world setting, meaning it can adapt to unseen and varied facial expressions, making it suitable for real-world applications. An extensive evaluation of SAFER against existing works in the field demonstrates improved performance, achieving an accuracy of 91.4% on the CAER-S dataset. Additionally, the study investigates the effect of novelty such as face masks during the Covid-19 pandemic on facial emotion recognition and critically examines the limitations of mainstream facial expressions datasets. To address these limitations, a novel dataset for facial emotion recognition is proposed. The proposed dataset and the system are expected to be useful for various applications such as human-computer interaction, security, and surveillance.
FDLS: A Deep Learning Approach to Production Quality, Controllable, and Retargetable Facial Performances
Sep 26, 2023
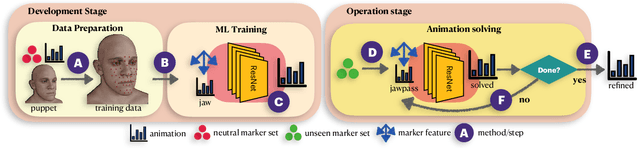
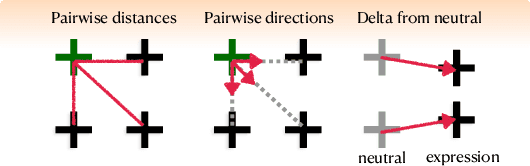
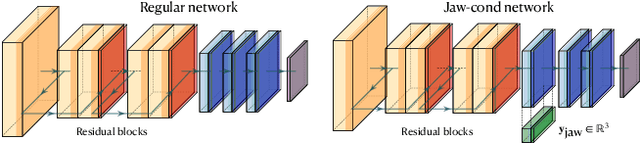
Visual effects commonly requires both the creation of realistic synthetic humans as well as retargeting actors' performances to humanoid characters such as aliens and monsters. Achieving the expressive performances demanded in entertainment requires manipulating complex models with hundreds of parameters. Full creative control requires the freedom to make edits at any stage of the production, which prohibits the use of a fully automatic ``black box'' solution with uninterpretable parameters. On the other hand, producing realistic animation with these sophisticated models is difficult and laborious. This paper describes FDLS (Facial Deep Learning Solver), which is Weta Digital's solution to these challenges. FDLS adopts a coarse-to-fine and human-in-the-loop strategy, allowing a solved performance to be verified and edited at several stages in the solving process. To train FDLS, we first transform the raw motion-captured data into robust graph features. Secondly, based on the observation that the artists typically finalize the jaw pass animation before proceeding to finer detail, we solve for the jaw motion first and predict fine expressions with region-based networks conditioned on the jaw position. Finally, artists can optionally invoke a non-linear finetuning process on top of the FDLS solution to follow the motion-captured virtual markers as closely as possible. FDLS supports editing if needed to improve the results of the deep learning solution and it can handle small daily changes in the actor's face shape. FDLS permits reliable and production-quality performance solving with minimal training and little or no manual effort in many cases, while also allowing the solve to be guided and edited in unusual and difficult cases. The system has been under development for several years and has been used in major movies.
Bees Local Phase Quantization Feature Selection for RGB-D Facial Expressions Recognition
Aug 03, 2023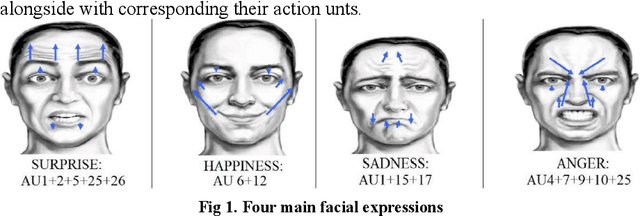
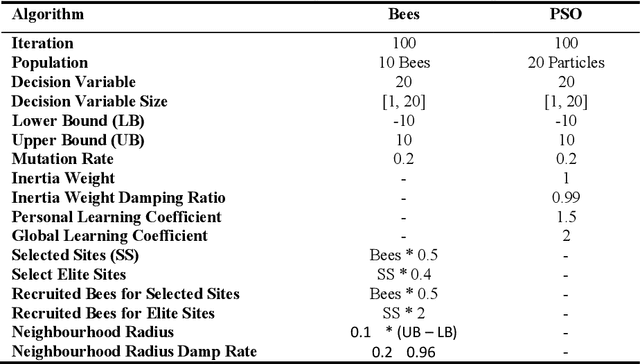
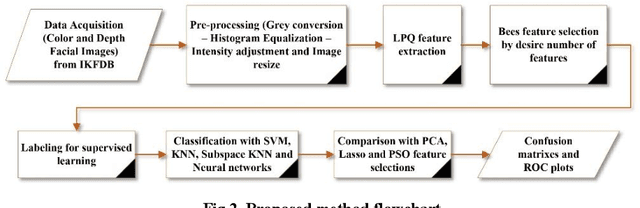
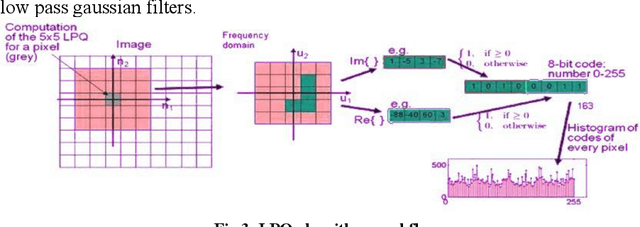
Feature selection could be defined as an optimization problem and solved by bio-inspired algorithms. Bees Algorithm (BA) shows decent performance in feature selection optimization tasks. On the other hand, Local Phase Quantization (LPQ) is a frequency domain feature which has excellent performance on Depth images. Here, after extracting LPQ features out of RGB (colour) and Depth images from the Iranian Kinect Face Database (IKFDB), the Bees feature selection algorithm applies to select the desired number of features for final classification tasks. IKFDB is recorded with Kinect sensor V.2 and contains colour and depth images for facial and facial micro-expressions recognition purposes. Here five facial expressions of Anger, Joy, Surprise, Disgust and Fear are used for final validation. The proposed Bees LPQ method is compared with Particle Swarm Optimization (PSO) LPQ, PCA LPQ, Lasso LPQ, and just LPQ features for classification tasks with Support Vector Machines (SVM), K-Nearest Neighbourhood (KNN), Shallow Neural Network and Ensemble Subspace KNN. Returned results, show a decent performance of the proposed algorithm (99 % accuracy) in comparison with others.
CalibrationPhys: Self-supervised Video-based Heart and Respiratory Rate Measurements by Calibrating Between Multiple Cameras
Oct 23, 2023Video-based heart and respiratory rate measurements using facial videos are more useful and user-friendly than traditional contact-based sensors. However, most of the current deep learning approaches require ground-truth pulse and respiratory waves for model training, which are expensive to collect. In this paper, we propose CalibrationPhys, a self-supervised video-based heart and respiratory rate measurement method that calibrates between multiple cameras. CalibrationPhys trains deep learning models without supervised labels by using facial videos captured simultaneously by multiple cameras. Contrastive learning is performed so that the pulse and respiratory waves predicted from the synchronized videos using multiple cameras are positive and those from different videos are negative. CalibrationPhys also improves the robustness of the models by means of a data augmentation technique and successfully leverages a pre-trained model for a particular camera. Experimental results utilizing two datasets demonstrate that CalibrationPhys outperforms state-of-the-art heart and respiratory rate measurement methods. Since we optimize camera-specific models using only videos from multiple cameras, our approach makes it easy to use arbitrary cameras for heart and respiratory rate measurements.