 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Face-PAST: Facial Pose Awareness and Style Transfer Networks
Jul 18, 2023

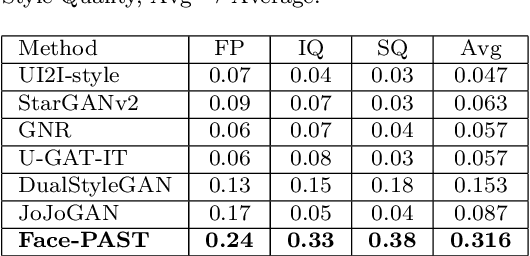
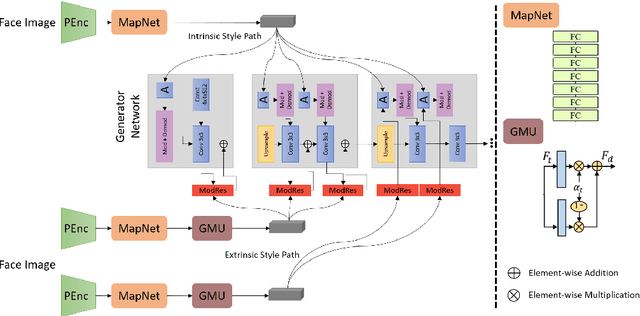
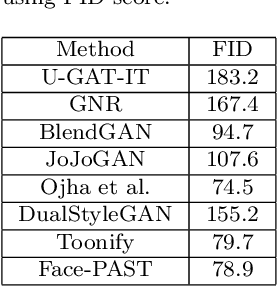
Facial style transfer has been quite popular among researchers due to the rise of emerging technologies such as eXtended Reality (XR), Metaverse, and Non-Fungible Tokens (NFTs). Furthermore, StyleGAN methods along with transfer-learning strategies have reduced the problem of limited data to some extent. However, most of the StyleGAN methods overfit the styles while adding artifacts to facial images. In this paper, we propose a facial pose awareness and style transfer (Face-PAST) network that preserves facial details and structures while generating high-quality stylized images. Dual StyleGAN inspires our work, but in contrast, our work uses a pre-trained style generation network in an external style pass with a residual modulation block instead of a transform coding block. Furthermore, we use the gated mapping unit and facial structure, identity, and segmentation losses to preserve the facial structure and details. This enables us to train the network with a very limited amount of data while generating high-quality stylized images. Our training process adapts curriculum learning strategy to perform efficient and flexible style mixing in the generative space. We perform extensive experiments to show the superiority of Face-PAST in comparison to existing state-of-the-art methods.
FurChat: An Embodied Conversational Agent using LLMs, Combining Open and Closed-Domain Dialogue with Facial Expressions
Aug 30, 2023
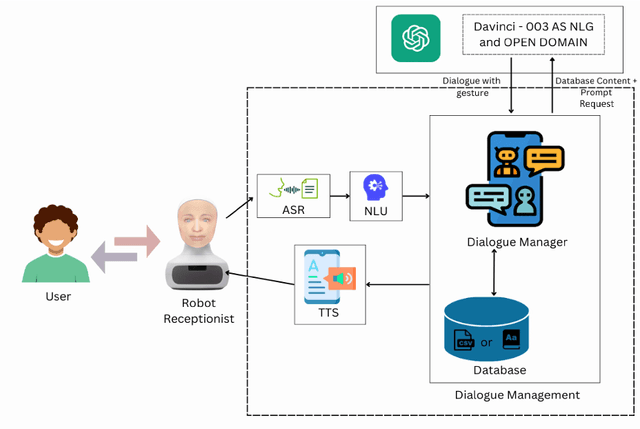
We demonstrate an embodied conversational agent that can function as a receptionist and generate a mixture of open and closed-domain dialogue along with facial expressions, by using a large language model (LLM) to develop an engaging conversation. We deployed the system onto a Furhat robot, which is highly expressive and capable of using both verbal and nonverbal cues during interaction. The system was designed specifically for the National Robotarium to interact with visitors through natural conversations, providing them with information about the facilities, research, news, upcoming events, etc. The system utilises the state-of-the-art GPT-3.5 model to generate such information along with domain-general conversations and facial expressions based on prompt engineering.
ChildGAN: Large Scale Synthetic Child Facial Data Using Domain Adaptation in StyleGAN
Jul 25, 2023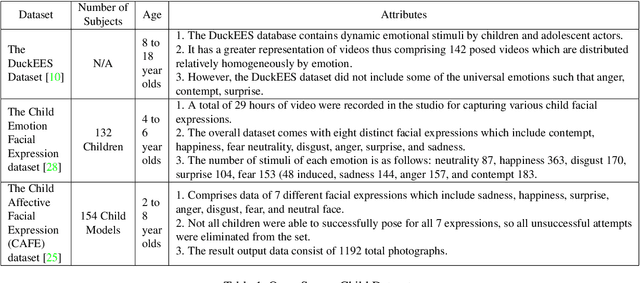
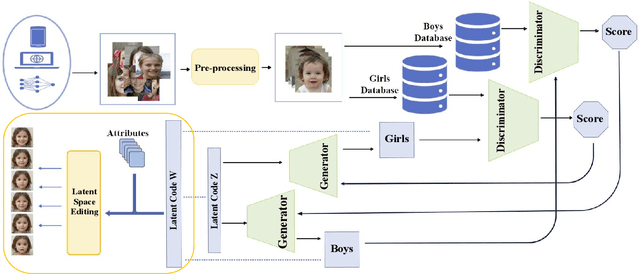
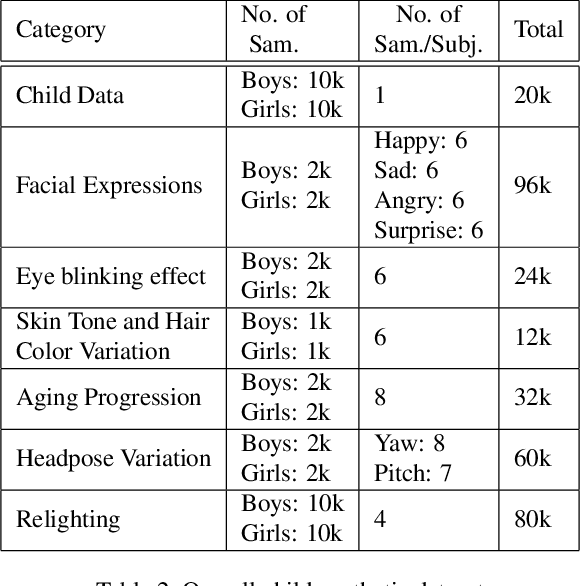

In this research work, we proposed a novel ChildGAN, a pair of GAN networks for generating synthetic boys and girls facial data derived from StyleGAN2. ChildGAN is built by performing smooth domain transfer using transfer learning. It provides photo-realistic, high-quality data samples. A large-scale dataset is rendered with a variety of smart facial transformations: facial expressions, age progression, eye blink effects, head pose, skin and hair color variations, and variable lighting conditions. The dataset comprises more than 300k distinct data samples. Further, the uniqueness and characteristics of the rendered facial features are validated by running different computer vision application tests which include CNN-based child gender classifier, face localization and facial landmarks detection test, identity similarity evaluation using ArcFace, and lastly running eye detection and eye aspect ratio tests. The results demonstrate that synthetic child facial data of high quality offers an alternative to the cost and complexity of collecting a large-scale dataset from real children.
Dual-path TokenLearner for Remote Photoplethysmography-based Physiological Measurement with Facial Videos
Aug 15, 2023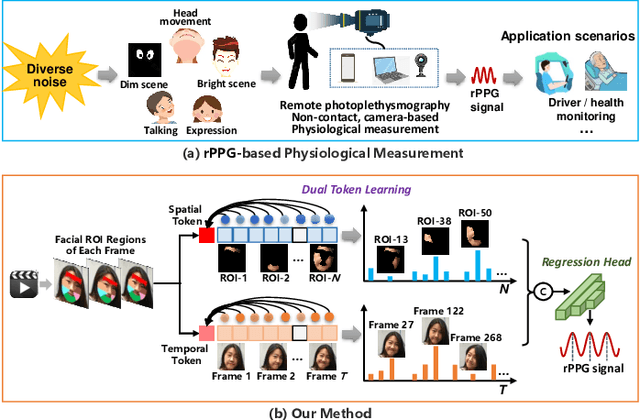
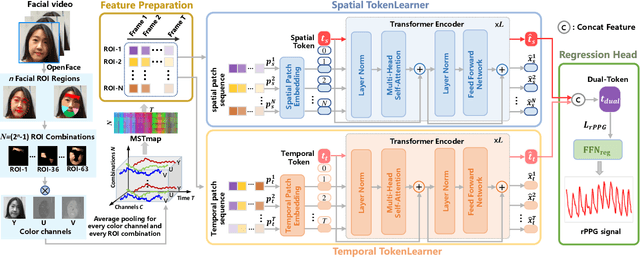


Remote photoplethysmography (rPPG) based physiological measurement is an emerging yet crucial vision task, whose challenge lies in exploring accurate rPPG prediction from facial videos accompanied by noises of illumination variations, facial occlusions, head movements, \etc, in a non-contact manner. Existing mainstream CNN-based models make efforts to detect physiological signals by capturing subtle color changes in facial regions of interest (ROI) caused by heartbeats. However, such models are constrained by the limited local spatial or temporal receptive fields in the neural units. Unlike them, a native Transformer-based framework called Dual-path TokenLearner (Dual-TL) is proposed in this paper, which utilizes the concept of learnable tokens to integrate both spatial and temporal informative contexts from the global perspective of the video. Specifically, the proposed Dual-TL uses a Spatial TokenLearner (S-TL) to explore associations in different facial ROIs, which promises the rPPG prediction far away from noisy ROI disturbances. Complementarily, a Temporal TokenLearner (T-TL) is designed to infer the quasi-periodic pattern of heartbeats, which eliminates temporal disturbances such as head movements. The two TokenLearners, S-TL and T-TL, are executed in a dual-path mode. This enables the model to reduce noise disturbances for final rPPG signal prediction. Extensive experiments on four physiological measurement benchmark datasets are conducted. The Dual-TL achieves state-of-the-art performances in both intra- and cross-dataset testings, demonstrating its immense potential as a basic backbone for rPPG measurement. The source code is available at \href{https://github.com/VUT-HFUT/Dual-TL}{https://github.com/VUT-HFUT/Dual-TL}
FIVA: Facial Image and Video Anonymization and Anonymization Defense
Sep 08, 2023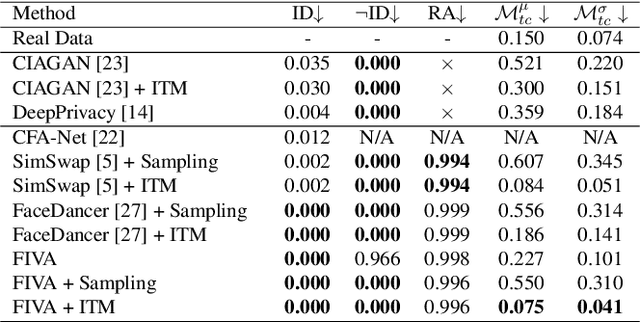
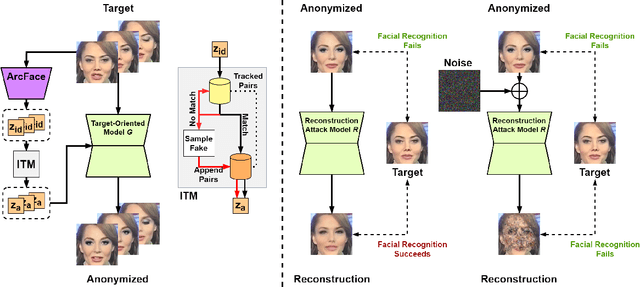
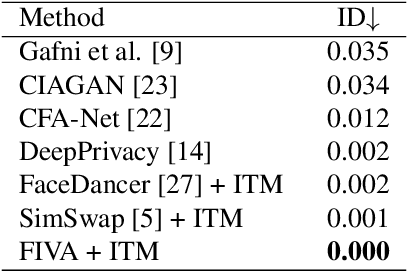
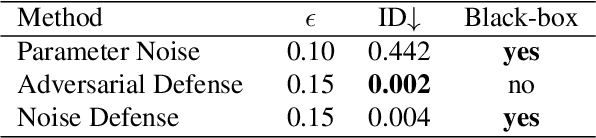
In this paper, we present a new approach for facial anonymization in images and videos, abbreviated as FIVA. Our proposed method is able to maintain the same face anonymization consistently over frames with our suggested identity-tracking and guarantees a strong difference from the original face. FIVA allows for 0 true positives for a false acceptance rate of 0.001. Our work considers the important security issue of reconstruction attacks and investigates adversarial noise, uniform noise, and parameter noise to disrupt reconstruction attacks. In this regard, we apply different defense and protection methods against these privacy threats to demonstrate the scalability of FIVA. On top of this, we also show that reconstruction attack models can be used for detection of deep fakes. Last but not least, we provide experimental results showing how FIVA can even enable face swapping, which is purely trained on a single target image.
NeutrEx: A 3D Quality Component Measure on Facial Expression Neutrality
Aug 19, 2023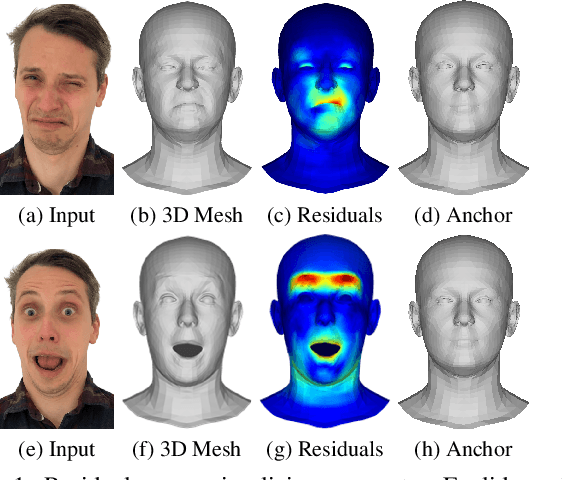
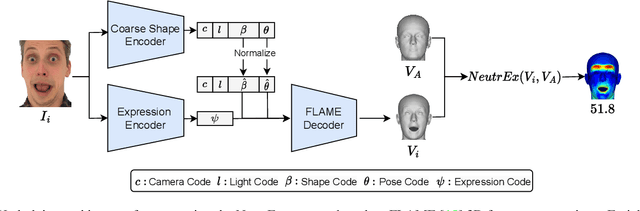
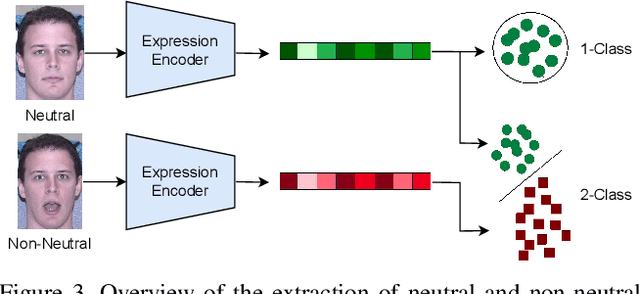

Accurate face recognition systems are increasingly important in sensitive applications like border control or migration management. Therefore, it becomes crucial to quantify the quality of facial images to ensure that low-quality images are not affecting recognition accuracy. In this context, the current draft of ISO/IEC 29794-5 introduces the concept of component quality to estimate how single factors of variation affect recognition outcomes. In this study, we propose a quality measure (NeutrEx) based on the accumulated distances of a 3D face reconstruction to a neutral expression anchor. Our evaluations demonstrate the superiority of our proposed method compared to baseline approaches obtained by training Support Vector Machines on face embeddings extracted from a pre-trained Convolutional Neural Network for facial expression classification. Furthermore, we highlight the explainable nature of our NeutrEx measures by computing per-vertex distances to unveil the most impactful face regions and allow operators to give actionable feedback to subjects.
Learning Motion Refinement for Unsupervised Face Animation
Oct 21, 2023Unsupervised face animation aims to generate a human face video based on the appearance of a source image, mimicking the motion from a driving video. Existing methods typically adopted a prior-based motion model (e.g., the local affine motion model or the local thin-plate-spline motion model). While it is able to capture the coarse facial motion, artifacts can often be observed around the tiny motion in local areas (e.g., lips and eyes), due to the limited ability of these methods to model the finer facial motions. In this work, we design a new unsupervised face animation approach to learn simultaneously the coarse and finer motions. In particular, while exploiting the local affine motion model to learn the global coarse facial motion, we design a novel motion refinement module to compensate for the local affine motion model for modeling finer face motions in local areas. The motion refinement is learned from the dense correlation between the source and driving images. Specifically, we first construct a structure correlation volume based on the keypoint features of the source and driving images. Then, we train a model to generate the tiny facial motions iteratively from low to high resolution. The learned motion refinements are combined with the coarse motion to generate the new image. Extensive experiments on widely used benchmarks demonstrate that our method achieves the best results among state-of-the-art baselines.
Facial Landmark Detection Evaluation on MOBIO Database
Jul 06, 2023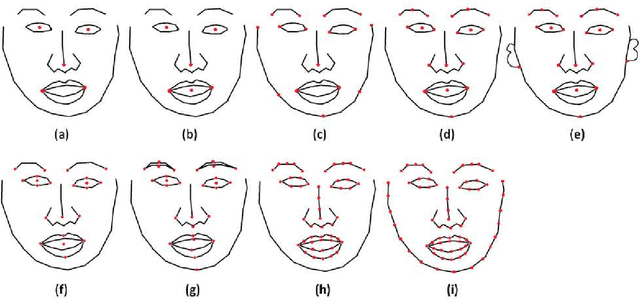
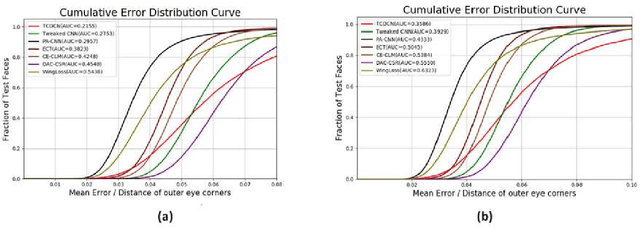
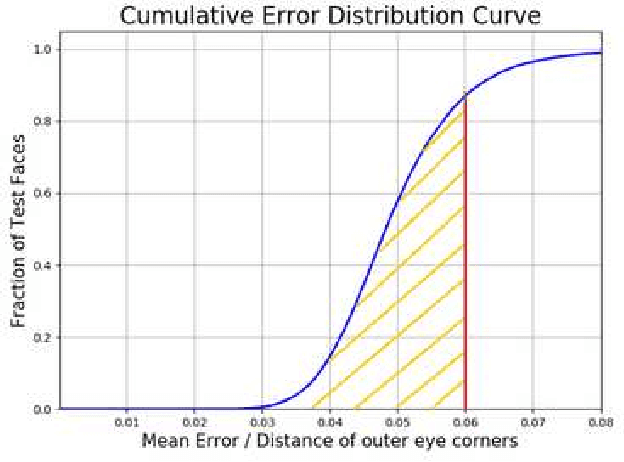
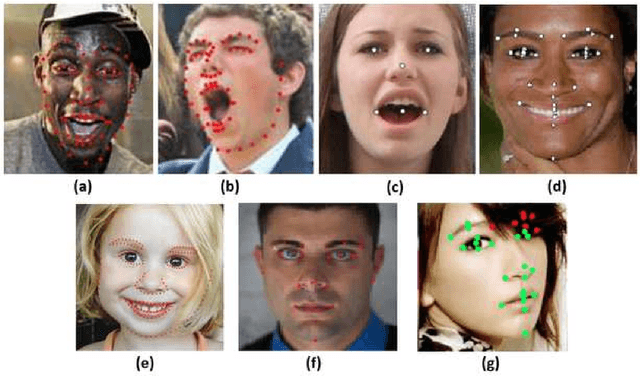
MOBIO is a bi-modal database that was captured almost exclusively on mobile phones. It aims to improve research into deploying biometric techniques to mobile devices. Research has been shown that face and speaker recognition can be performed in a mobile environment. Facial landmark localization aims at finding the coordinates of a set of pre-defined key points for 2D face images. A facial landmark usually has specific semantic meaning, e.g. nose tip or eye centre, which provides rich geometric information for other face analysis tasks such as face recognition, emotion estimation and 3D face reconstruction. Pretty much facial landmark detection methods adopt still face databases, such as 300W, AFW, AFLW, or COFW, for evaluation, but seldomly use mobile data. Our work is first to perform facial landmark detection evaluation on the mobile still data, i.e., face images from MOBIO database. About 20,600 face images have been extracted from this audio-visual database and manually labeled with 22 landmarks as the groundtruth. Several state-of-the-art facial landmark detection methods are adopted to evaluate their performance on these data. The result shows that the data from MOBIO database is pretty challenging. This database can be a new challenging one for facial landmark detection evaluation.
Explaining with Attribute-based and Relational Near Misses: An Interpretable Approach to Distinguishing Facial Expressions of Pain and Disgust
Aug 27, 2023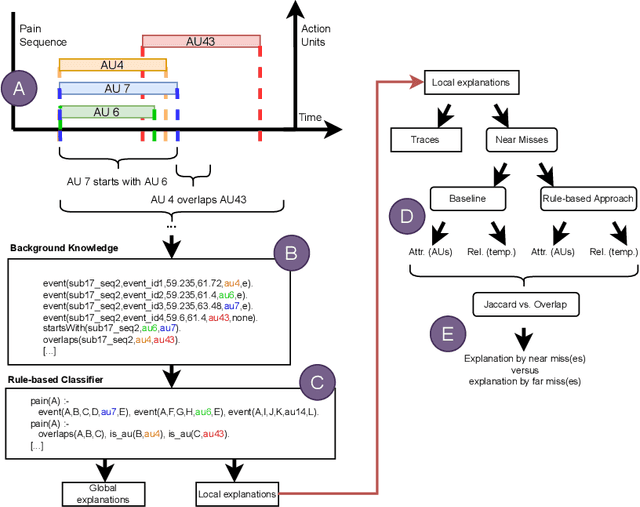

Explaining concepts by contrasting examples is an efficient and convenient way of giving insights into the reasons behind a classification decision. This is of particular interest in decision-critical domains, such as medical diagnostics. One particular challenging use case is to distinguish facial expressions of pain and other states, such as disgust, due to high similarity of manifestation. In this paper, we present an approach for generating contrastive explanations to explain facial expressions of pain and disgust shown in video sequences. We implement and compare two approaches for contrastive explanation generation. The first approach explains a specific pain instance in contrast to the most similar disgust instance(s) based on the occurrence of facial expressions (attributes). The second approach takes into account which temporal relations hold between intervals of facial expressions within a sequence (relations). The input to our explanation generation approach is the output of an interpretable rule-based classifier for pain and disgust.We utilize two different similarity metrics to determine near misses and far misses as contrasting instances. Our results show that near miss explanations are shorter than far miss explanations, independent from the applied similarity metric. The outcome of our evaluation indicates that pain and disgust can be distinguished with the help of temporal relations. We currently plan experiments to evaluate how the explanations help in teaching concepts and how they could be enhanced by further modalities and interaction.
Beyond Boundaries: A Comprehensive Survey of Transferable Attacks on AI Systems
Nov 20, 2023Artificial Intelligence (AI) systems such as autonomous vehicles, facial recognition, and speech recognition systems are increasingly integrated into our daily lives. However, despite their utility, these AI systems are vulnerable to a wide range of attacks such as adversarial, backdoor, data poisoning, membership inference, model inversion, and model stealing attacks. In particular, numerous attacks are designed to target a particular model or system, yet their effects can spread to additional targets, referred to as transferable attacks. Although considerable efforts have been directed toward developing transferable attacks, a holistic understanding of the advancements in transferable attacks remains elusive. In this paper, we comprehensively explore learning-based attacks from the perspective of transferability, particularly within the context of cyber-physical security. We delve into different domains -- the image, text, graph, audio, and video domains -- to highlight the ubiquitous and pervasive nature of transferable attacks. This paper categorizes and reviews the architecture of existing attacks from various viewpoints: data, process, model, and system. We further examine the implications of transferable attacks in practical scenarios such as autonomous driving, speech recognition, and large language models (LLMs). Additionally, we outline the potential research directions to encourage efforts in exploring the landscape of transferable attacks. This survey offers a holistic understanding of the prevailing transferable attacks and their impacts across different domains.