 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
HSEmotion Team at the 6th ABAW Competition: Facial Expressions, Valence-Arousal and Emotion Intensity Prediction
Mar 18, 2024
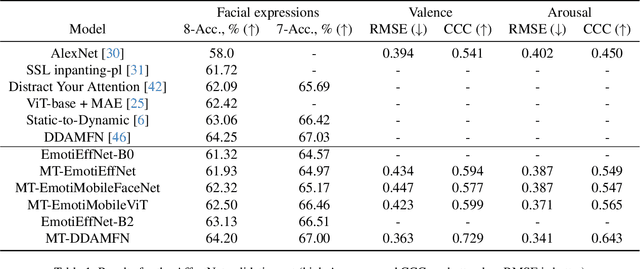
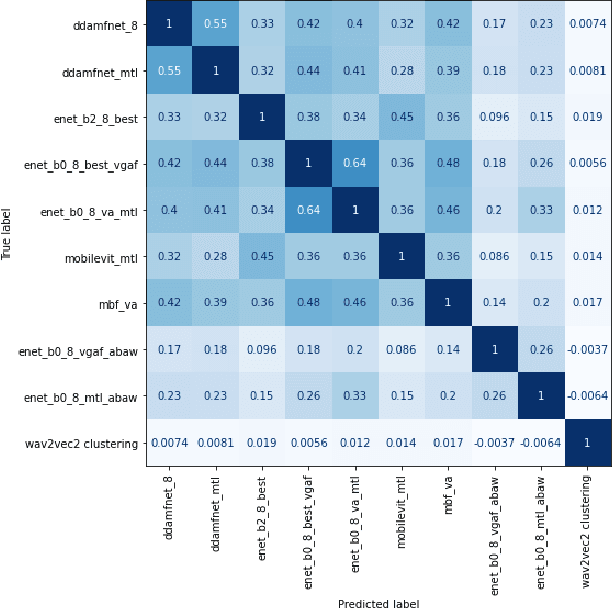
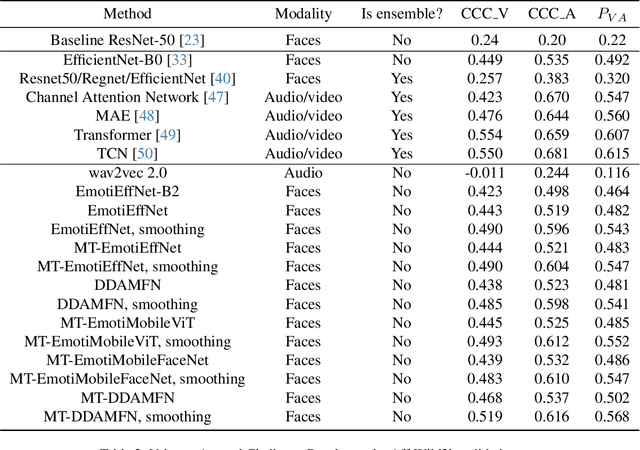
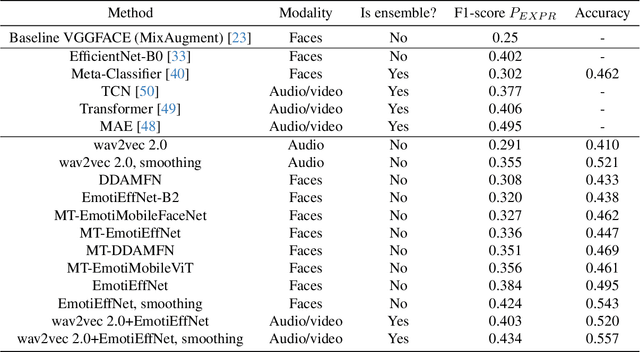
This article presents our results for the sixth Affective Behavior Analysis in-the-wild (ABAW) competition. To improve the trustworthiness of facial analysis, we study the possibility of using pre-trained deep models that extract reliable emotional features without the need to fine-tune the neural networks for a downstream task. In particular, we introduce several lightweight models based on MobileViT, MobileFaceNet, EfficientNet, and DDAMFN architectures trained in multi-task scenarios to recognize facial expressions, valence, and arousal on static photos. These neural networks extract frame-level features fed into a simple classifier, e.g., linear feed-forward neural network, to predict emotion intensity, compound expressions, action units, facial expressions, and valence/arousal. Experimental results for five tasks from the sixth ABAW challenge demonstrate that our approach lets us significantly improve quality metrics on validation sets compared to existing non-ensemble techniques.
Joint Contrastive Learning with Feature Alignment for Cross-Corpus EEG-based Emotion Recognition
Apr 15, 2024The integration of human emotions into multimedia applications shows great potential for enriching user experiences and enhancing engagement across various digital platforms. Unlike traditional methods such as questionnaires, facial expressions, and voice analysis, brain signals offer a more direct and objective understanding of emotional states. However, in the field of electroencephalography (EEG)-based emotion recognition, previous studies have primarily concentrated on training and testing EEG models within a single dataset, overlooking the variability across different datasets. This oversight leads to significant performance degradation when applying EEG models to cross-corpus scenarios. In this study, we propose a novel Joint Contrastive learning framework with Feature Alignment (JCFA) to address cross-corpus EEG-based emotion recognition. The JCFA model operates in two main stages. In the pre-training stage, a joint domain contrastive learning strategy is introduced to characterize generalizable time-frequency representations of EEG signals, without the use of labeled data. It extracts robust time-based and frequency-based embeddings for each EEG sample, and then aligns them within a shared latent time-frequency space. In the fine-tuning stage, JCFA is refined in conjunction with downstream tasks, where the structural connections among brain electrodes are considered. The model capability could be further enhanced for the application in emotion detection and interpretation. Extensive experimental results on two well-recognized emotional datasets show that the proposed JCFA model achieves state-of-the-art (SOTA) performance, outperforming the second-best method by an average accuracy increase of 4.09% in cross-corpus EEG-based emotion recognition tasks.
Leveraging Synthetic Data for Generalizable and Fair Facial Action Unit Detection
Mar 15, 2024

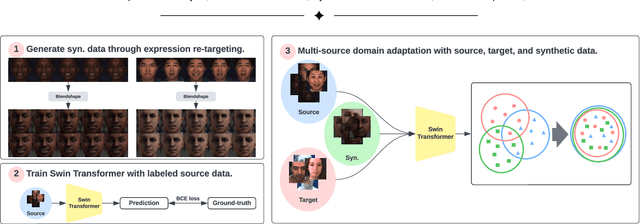
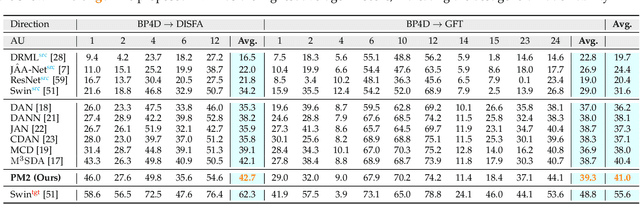
Facial action unit (AU) detection is a fundamental block for objective facial expression analysis. Supervised learning approaches require a large amount of manual labeling which is costly. The limited labeled data are also not diverse in terms of gender which can affect model fairness. In this paper, we propose to use synthetically generated data and multi-source domain adaptation (MSDA) to address the problems of the scarcity of labeled data and the diversity of subjects. Specifically, we propose to generate a diverse dataset through synthetic facial expression re-targeting by transferring the expressions from real faces to synthetic avatars. Then, we use MSDA to transfer the AU detection knowledge from a real dataset and the synthetic dataset to a target dataset. Instead of aligning the overall distributions of different domains, we propose Paired Moment Matching (PM2) to align the features of the paired real and synthetic data with the same facial expression. To further improve gender fairness, PM2 matches the features of the real data with a female and a male synthetic image. Our results indicate that synthetic data and the proposed model improve both AU detection performance and fairness across genders, demonstrating its potential to solve AU detection in-the-wild.
Customizable Avatars with Dynamic Facial Action Coded Expressions (CADyFACE) for Improved User Engagement
Mar 12, 2024

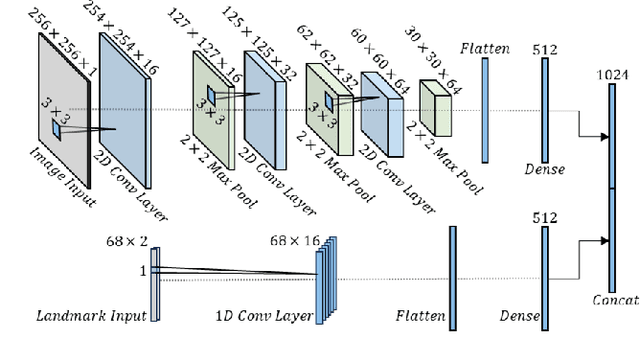
Customizable 3D avatar-based facial expression stimuli may improve user engagement in behavioral biomarker discovery and therapeutic intervention for autism, Alzheimer's disease, facial palsy, and more. However, there is a lack of customizable avatar-based stimuli with Facial Action Coding System (FACS) action unit (AU) labels. Therefore, this study focuses on (1) FACS-labeled, customizable avatar-based expression stimuli for maintaining subjects' engagement, (2) learning-based measurements that quantify subjects' facial responses to such stimuli, and (3) validation of constructs represented by stimulus-measurement pairs. We propose Customizable Avatars with Dynamic Facial Action Coded Expressions (CADyFACE) labeled with AUs by a certified FACS expert. To measure subjects' AUs in response to CADyFACE, we propose a novel Beta-guided Correlation and Multi-task Expression learning neural network (BeCoME-Net) for multi-label AU detection. The beta-guided correlation loss encourages feature correlation with AUs while discouraging correlation with subject identities for improved generalization. We train BeCoME-Net for unilateral and bilateral AU detection and compare with state-of-the-art approaches. To assess construct validity of CADyFACE and BeCoME-Net, twenty healthy adult volunteers complete expression recognition and mimicry tasks in an online feasibility study while webcam-based eye-tracking and video are collected. We test validity of multiple constructs, including face preference during recognition and AUs during mimicry.
Chaos in Motion: Unveiling Robustness in Remote Heart Rate Measurement through Brain-Inspired Skin Tracking
Apr 11, 2024Heart rate is an important physiological indicator of human health status. Existing remote heart rate measurement methods typically involve facial detection followed by signal extraction from the region of interest (ROI). These SOTA methods have three serious problems: (a) inaccuracies even failures in detection caused by environmental influences or subject movement; (b) failures for special patients such as infants and burn victims; (c) privacy leakage issues resulting from collecting face video. To address these issues, we regard the remote heart rate measurement as the process of analyzing the spatiotemporal characteristics of the optical flow signal in the video. We apply chaos theory to computer vision tasks for the first time, thus designing a brain-inspired framework. Firstly, using an artificial primary visual cortex model to extract the skin in the videos, and then calculate heart rate by time-frequency analysis on all pixels. Our method achieves Robust Skin Tracking for Heart Rate measurement, called HR-RST. The experimental results show that HR-RST overcomes the difficulty of environmental influences and effectively tracks the subject movement. Moreover, the method could extend to other body parts. Consequently, the method can be applied to special patients and effectively protect individual privacy, offering an innovative solution.
3D Facial Expressions through Analysis-by-Neural-Synthesis
Apr 05, 2024While existing methods for 3D face reconstruction from in-the-wild images excel at recovering the overall face shape, they commonly miss subtle, extreme, asymmetric, or rarely observed expressions. We improve upon these methods with SMIRK (Spatial Modeling for Image-based Reconstruction of Kinesics), which faithfully reconstructs expressive 3D faces from images. We identify two key limitations in existing methods: shortcomings in their self-supervised training formulation, and a lack of expression diversity in the training images. For training, most methods employ differentiable rendering to compare a predicted face mesh with the input image, along with a plethora of additional loss functions. This differentiable rendering loss not only has to provide supervision to optimize for 3D face geometry, camera, albedo, and lighting, which is an ill-posed optimization problem, but the domain gap between rendering and input image further hinders the learning process. Instead, SMIRK replaces the differentiable rendering with a neural rendering module that, given the rendered predicted mesh geometry, and sparsely sampled pixels of the input image, generates a face image. As the neural rendering gets color information from sampled image pixels, supervising with neural rendering-based reconstruction loss can focus solely on the geometry. Further, it enables us to generate images of the input identity with varying expressions while training. These are then utilized as input to the reconstruction model and used as supervision with ground truth geometry. This effectively augments the training data and enhances the generalization for diverse expressions. Our qualitative, quantitative and particularly our perceptual evaluations demonstrate that SMIRK achieves the new state-of-the art performance on accurate expression reconstruction. Project webpage: https://georgeretsi.github.io/smirk/.
Deepfake Generation and Detection: A Benchmark and Survey
Apr 09, 2024In addition to the advancements in deepfake generation, corresponding detection technologies need to continuously evolve to regulate the potential misuse of deepfakes, such as for privacy invasion and phishing attacks. This survey comprehensively reviews the latest developments in deepfake generation and detection, summarizing and analyzing the current state of the art in this rapidly evolving field. We first unify task definitions, comprehensively introduce datasets and metrics, and discuss the development of generation and detection technology frameworks. Then, we discuss the development of several related sub-fields and focus on researching four mainstream deepfake fields: popular face swap, face reenactment, talking face generation, and facial attribute editing, as well as foreign detection. Subsequently, we comprehensively benchmark representative methods on popular datasets for each field, fully evaluating the latest and influential works published in top conferences/journals. Finally, we analyze the challenges and future research directions of the discussed fields. We closely follow the latest developments in https://github.com/flyingby/Awesome-Deepfake-Generation-and-Detection.
DiffusionFace: Towards a Comprehensive Dataset for Diffusion-Based Face Forgery Analysis
Mar 27, 2024The rapid progress in deep learning has given rise to hyper-realistic facial forgery methods, leading to concerns related to misinformation and security risks. Existing face forgery datasets have limitations in generating high-quality facial images and addressing the challenges posed by evolving generative techniques. To combat this, we present DiffusionFace, the first diffusion-based face forgery dataset, covering various forgery categories, including unconditional and Text Guide facial image generation, Img2Img, Inpaint, and Diffusion-based facial exchange algorithms. Our DiffusionFace dataset stands out with its extensive collection of 11 diffusion models and the high-quality of the generated images, providing essential metadata and a real-world internet-sourced forgery facial image dataset for evaluation. Additionally, we provide an in-depth analysis of the data and introduce practical evaluation protocols to rigorously assess discriminative models' effectiveness in detecting counterfeit facial images, aiming to enhance security in facial image authentication processes. The dataset is available for download at \url{https://github.com/Rapisurazurite/DiffFace}.
EDTalk: Efficient Disentanglement for Emotional Talking Head Synthesis
Apr 02, 2024Achieving disentangled control over multiple facial motions and accommodating diverse input modalities greatly enhances the application and entertainment of the talking head generation. This necessitates a deep exploration of the decoupling space for facial features, ensuring that they a) operate independently without mutual interference and b) can be preserved to share with different modal input, both aspects often neglected in existing methods. To address this gap, this paper proposes a novel Efficient Disentanglement framework for Talking head generation (EDTalk). Our framework enables individual manipulation of mouth shape, head pose, and emotional expression, conditioned on video or audio inputs. Specifically, we employ three lightweight modules to decompose the facial dynamics into three distinct latent spaces representing mouth, pose, and expression, respectively. Each space is characterized by a set of learnable bases whose linear combinations define specific motions. To ensure independence and accelerate training, we enforce orthogonality among bases and devise an efficient training strategy to allocate motion responsibilities to each space without relying on external knowledge. The learned bases are then stored in corresponding banks, enabling shared visual priors with audio input. Furthermore, considering the properties of each space, we propose an Audio-to-Motion module for audio-driven talking head synthesis. Experiments are conducted to demonstrate the effectiveness of EDTalk. We recommend watching the project website: https://tanshuai0219.github.io/EDTalk/
Spatio-Temporal Attention and Gaussian Processes for Personalized Video Gaze Estimation
Apr 10, 2024Gaze is an essential prompt for analyzing human behavior and attention. Recently, there has been an increasing interest in determining gaze direction from facial videos. However, video gaze estimation faces significant challenges, such as understanding the dynamic evolution of gaze in video sequences, dealing with static backgrounds, and adapting to variations in illumination. To address these challenges, we propose a simple and novel deep learning model designed to estimate gaze from videos, incorporating a specialized attention module. Our method employs a spatial attention mechanism that tracks spatial dynamics within videos. This technique enables accurate gaze direction prediction through a temporal sequence model, adeptly transforming spatial observations into temporal insights, thereby significantly improving gaze estimation accuracy. Additionally, our approach integrates Gaussian processes to include individual-specific traits, facilitating the personalization of our model with just a few labeled samples. Experimental results confirm the efficacy of the proposed approach, demonstrating its success in both within-dataset and cross-dataset settings. Specifically, our proposed approach achieves state-of-the-art performance on the Gaze360 dataset, improving by $2.5^\circ$ without personalization. Further, by personalizing the model with just three samples, we achieved an additional improvement of $0.8^\circ$. The code and pre-trained models are available at \url{https://github.com/jswati31/stage}.