 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Can Protective Perturbation Safeguard Personal Data from Being Exploited by Stable Diffusion?
Nov 30, 2023
Stable Diffusion has established itself as a foundation model in generative AI artistic applications, receiving widespread research and application. Some recent fine-tuning methods have made it feasible for individuals to implant personalized concepts onto the basic Stable Diffusion model with minimal computational costs on small datasets. However, these innovations have also given rise to issues like facial privacy forgery and artistic copyright infringement. In recent studies, researchers have explored the addition of imperceptible adversarial perturbations to images to prevent potential unauthorized exploitation and infringements when personal data is used for fine-tuning Stable Diffusion. Although these studies have demonstrated the ability to protect images, it is essential to consider that these methods may not be entirely applicable in real-world scenarios. In this paper, we systematically evaluate the use of perturbations to protect images within a practical threat model. The results suggest that these approaches may not be sufficient to safeguard image privacy and copyright effectively. Furthermore, we introduce a purification method capable of removing protected perturbations while preserving the original image structure to the greatest extent possible. Experiments reveal that Stable Diffusion can effectively learn from purified images over all protective methods.
Identity-preserving Editing of Multiple Facial Attributes by Learning Global Edit Directions and Local Adjustments
Sep 25, 2023
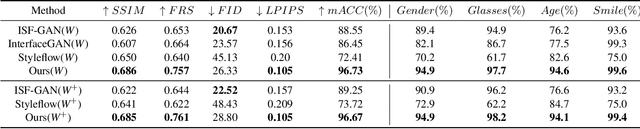
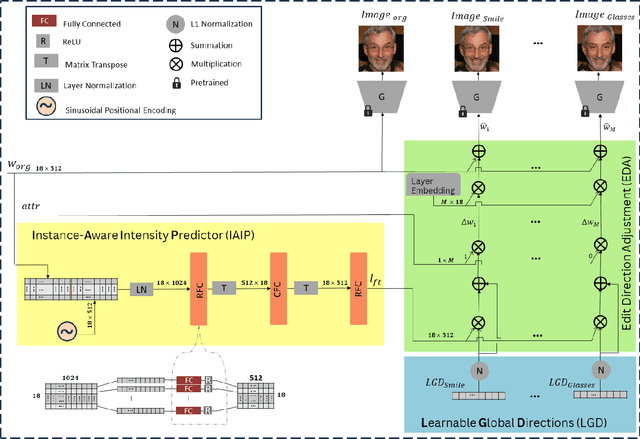
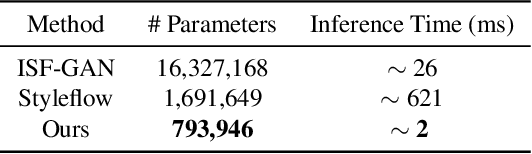
Semantic facial attribute editing using pre-trained Generative Adversarial Networks (GANs) has attracted a great deal of attention and effort from researchers in recent years. Due to the high quality of face images generated by StyleGANs, much work has focused on the StyleGANs' latent space and the proposed methods for facial image editing. Although these methods have achieved satisfying results for manipulating user-intended attributes, they have not fulfilled the goal of preserving the identity, which is an important challenge. We present ID-Style, a new architecture capable of addressing the problem of identity loss during attribute manipulation. The key components of ID-Style include Learnable Global Direction (LGD), which finds a shared and semi-sparse direction for each attribute, and an Instance-Aware Intensity Predictor (IAIP) network, which finetunes the global direction according to the input instance. Furthermore, we introduce two losses during training to enforce the LGD to find semi-sparse semantic directions, which along with the IAIP, preserve the identity of the input instance. Despite reducing the size of the network by roughly 95% as compared to similar state-of-the-art works, it outperforms baselines by 10% and 7% in Identity preserving metric (FRS) and average accuracy of manipulation (mACC), respectively.
Non-Contact Breathing Rate Detection Using Optical Flow
Nov 13, 2023Breathing rate is a vital health metric that is an invaluable indicator of the overall health of a person. In recent years, the non-contact measurement of health signals such as breathing rate has been a huge area of development, with a wide range of applications from telemedicine to driver monitoring systems. This paper presents an investigation into a method of non-contact breathing rate detection using a motion detection algorithm, optical flow. Optical flow is used to successfully measure breathing rate by tracking the motion of specific points on the body. In this study, the success of optical flow when using different sets of points is evaluated. Testing shows that both chest and facial movement can be used to determine breathing rate but to different degrees of success. The chest generates very accurate signals, with an RMSE of 0.63 on the tested videos. Facial points can also generate reliable signals when there is minimal head movement but are much more vulnerable to noise caused by head/body movements. These findings highlight the potential of optical flow as a non-invasive method for breathing rate detection and emphasize the importance of selecting appropriate points to optimize accuracy.
Facial Prior Based First Order Motion Model for Micro-expression Generation
Aug 08, 2023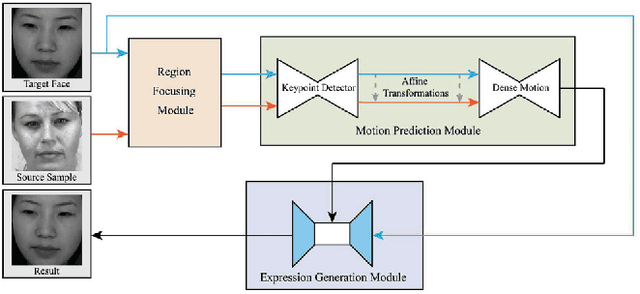

Spotting facial micro-expression from videos finds various potential applications in fields including clinical diagnosis and interrogation, meanwhile this task is still difficult due to the limited scale of training data. To solve this problem, this paper tries to formulate a new task called micro-expression generation and then presents a strong baseline which combines the first order motion model with facial prior knowledge. Given a target face, we intend to drive the face to generate micro-expression videos according to the motion patterns of source videos. Specifically, our new model involves three modules. First, we extract facial prior features from a region focusing module. Second, we estimate facial motion using key points and local affine transformations with a motion prediction module. Third, expression generation module is used to drive the target face to generate videos. We train our model on public CASME II, SAMM and SMIC datasets and then use the model to generate new micro-expression videos for evaluation. Our model achieves the first place in the Facial Micro-Expression Challenge 2021 (MEGC2021), where our superior performance is verified by three experts with Facial Action Coding System certification. Source code is provided in https://github.com/Necolizer/Facial-Prior-Based-FOMM.
Training Robust Deep Physiological Measurement Models with Synthetic Video-based Data
Nov 09, 2023Recent advances in supervised deep learning techniques have demonstrated the possibility to remotely measure human physiological vital signs (e.g., photoplethysmograph, heart rate) just from facial videos. However, the performance of these methods heavily relies on the availability and diversity of real labeled data. Yet, collecting large-scale real-world data with high-quality labels is typically challenging and resource intensive, which also raises privacy concerns when storing personal bio-metric data. Synthetic video-based datasets (e.g., SCAMPS~\cite{mcduff2022scamps}) with photo-realistic synthesized avatars are introduced to alleviate the issues while providing high-quality synthetic data. However, there exists a significant gap between synthetic and real-world data, which hinders the generalization of neural models trained on these synthetic datasets. In this paper, we proposed several measures to add real-world noise to synthetic physiological signals and corresponding facial videos. We experimented with individual and combined augmentation methods and evaluated our framework on three public real-world datasets. Our results show that we were able to reduce the average MAE from 6.9 to 2.0.
Self-similarity Prior Distillation for Unsupervised Remote Physiological Measurement
Nov 09, 2023Remote photoplethysmography (rPPG) is a noninvasive technique that aims to capture subtle variations in facial pixels caused by changes in blood volume resulting from cardiac activities. Most existing unsupervised methods for rPPG tasks focus on the contrastive learning between samples while neglecting the inherent self-similar prior in physiological signals. In this paper, we propose a Self-Similarity Prior Distillation (SSPD) framework for unsupervised rPPG estimation, which capitalizes on the intrinsic self-similarity of cardiac activities. Specifically, we first introduce a physical-prior embedded augmentation technique to mitigate the effect of various types of noise. Then, we tailor a self-similarity-aware network to extract more reliable self-similar physiological features. Finally, we develop a hierarchical self-distillation paradigm to assist the network in disentangling self-similar physiological patterns from facial videos. Comprehensive experiments demonstrate that the unsupervised SSPD framework achieves comparable or even superior performance compared to the state-of-the-art supervised methods. Meanwhile, SSPD maintains the lowest inference time and computation cost among end-to-end models. The source codes are available at https://github.com/LinXi1C/SSPD.
Unsupervised Multimodal Deepfake Detection Using Intra- and Cross-Modal Inconsistencies
Nov 28, 2023Deepfake videos present an increasing threat to society with potentially negative impact on criminal justice, democracy, and personal safety and privacy. Meanwhile, detecting deepfakes, at scale, remains a very challenging tasks that often requires labeled training data from existing deepfake generation methods. Further, even the most accurate supervised learning, deepfake detection methods do not generalize to deepfakes generated using new generation methods. In this paper, we introduce a novel unsupervised approach for detecting deepfake videos by measuring of intra- and cross-modal consistency among multimodal features; specifically visual, audio, and identity features. The fundamental hypothesis behind the proposed detection method is that since deepfake generation attempts to transfer the facial motion of one identity to another, these methods will eventually encounter a trade-off between motion and identity that enviably leads to detectable inconsistencies. We validate our method through extensive experimentation, demonstrating the existence of significant intra- and cross- modal inconsistencies in deepfake videos, which can be effectively utilized to detect them with high accuracy. Our proposed method is scalable because it does not require pristine samples at inference, generalizable because it is trained only on real data, and is explainable since it can pinpoint the exact location of modality inconsistencies which are then verifiable by a human expert.
SpeechAct: Towards Generating Whole-body Motion from Speech
Nov 29, 2023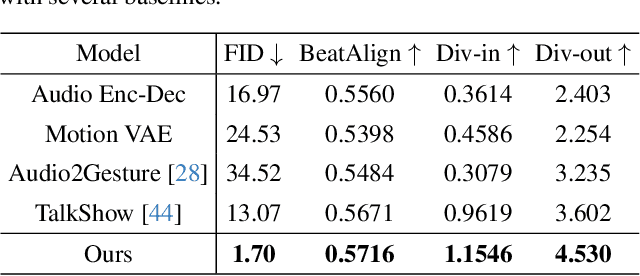
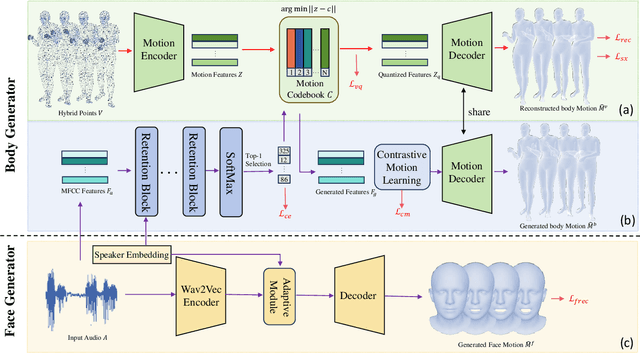
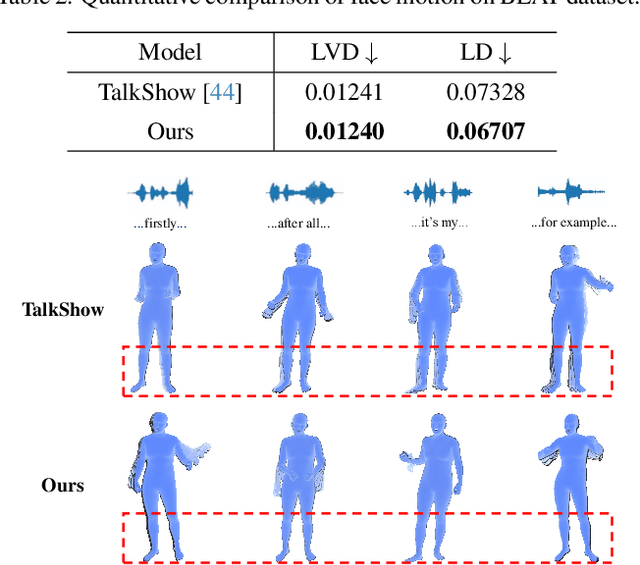
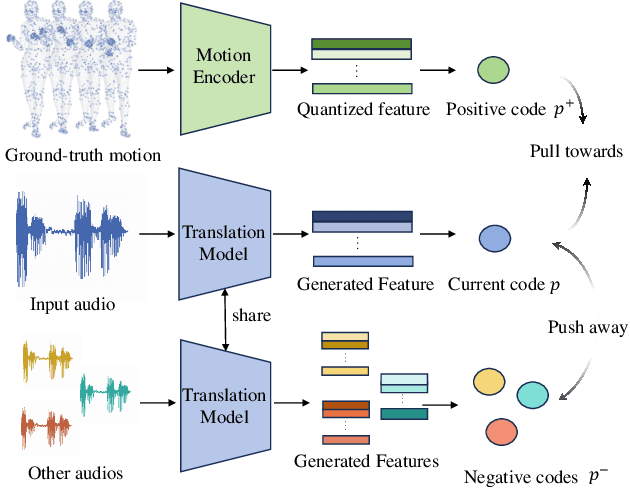
This paper addresses the problem of generating whole-body motion from speech. Despite great successes, prior methods still struggle to produce reasonable and diverse whole-body motions from speech. This is due to their reliance on suboptimal representations and a lack of strategies for generating diverse results. To address these challenges, we present a novel hybrid point representation to achieve accurate and continuous motion generation, e.g., avoiding foot skating, and this representation can be transformed into an easy-to-use representation, i.e., SMPL-X body mesh, for many applications. To generate whole-body motion from speech, for facial motion, closely tied to the audio signal, we introduce an encoder-decoder architecture to achieve deterministic outcomes. However, for the body and hands, which have weaker connections to the audio signal, we aim to generate diverse yet reasonable motions. To boost diversity in motion generation, we propose a contrastive motion learning method to encourage the model to produce more distinctive representations. Specifically, we design a robust VQ-VAE to learn a quantized motion codebook using our hybrid representation. Then, we regress the motion representation from the audio signal by a translation model employing our contrastive motion learning method. Experimental results validate the superior performance and the correctness of our model. The project page is available for research purposes at http://cic.tju.edu.cn/faculty/likun/projects/SpeechAct.
eMotions: A Large-Scale Dataset for Emotion Recognition in Short Videos
Nov 29, 2023Nowadays, short videos (SVs) are essential to information acquisition and sharing in our life. The prevailing use of SVs to spread emotions leads to the necessity of emotion recognition in SVs. Considering the lack of SVs emotion data, we introduce a large-scale dataset named eMotions, comprising 27,996 videos. Meanwhile, we alleviate the impact of subjectivities on labeling quality by emphasizing better personnel allocations and multi-stage annotations. In addition, we provide the category-balanced and test-oriented variants through targeted data sampling. Some commonly used videos (e.g., facial expressions and postures) have been well studied. However, it is still challenging to understand the emotions in SVs. Since the enhanced content diversity brings more distinct semantic gaps and difficulties in learning emotion-related features, and there exists information gaps caused by the emotion incompleteness under the prevalently audio-visual co-expressions. To tackle these problems, we present an end-to-end baseline method AV-CPNet that employs the video transformer to better learn semantically relevant representations. We further design the two-stage cross-modal fusion module to complementarily model the correlations of audio-visual features. The EP-CE Loss, incorporating three emotion polarities, is then applied to guide model optimization. Extensive experimental results on nine datasets verify the effectiveness of AV-CPNet. Datasets and code will be open on https://github.com/XuecWu/eMotions.
Data Center Audio/Video Intelligence on Device (DAVID) -- An Edge-AI Platform for Smart-Toys
Nov 18, 2023An overview is given of the DAVID Smart-Toy platform, one of the first Edge AI platform designs to incorporate advanced low-power data processing by neural inference models co-located with the relevant image or audio sensors. There is also on-board capability for in-device text-to-speech generation. Two alternative embodiments are presented: a smart Teddy-bear, and a roving dog-like robot. The platform offers a speech-driven user interface and can observe and interpret user actions and facial expressions via its computer vision sensor node. A particular benefit of this design is that no personally identifiable information passes beyond the neural inference nodes thus providing inbuilt compliance with data protection regulations.