 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
DiffPoseTalk: Speech-Driven Stylistic 3D Facial Animation and Head Pose Generation via Diffusion Models
Sep 30, 2023
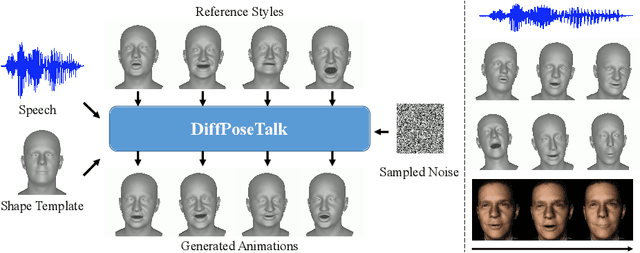
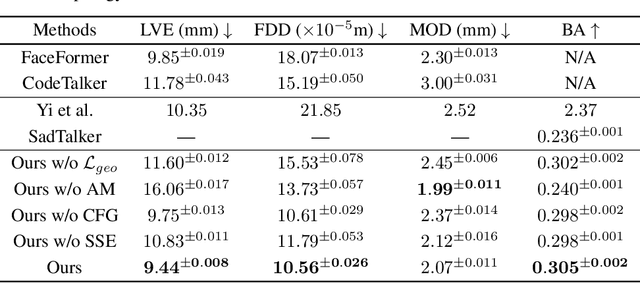
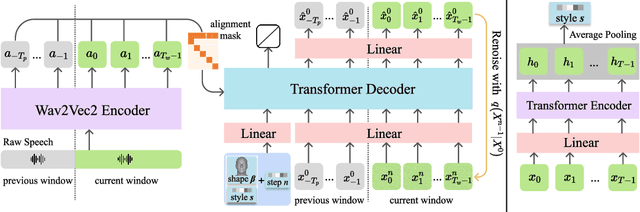
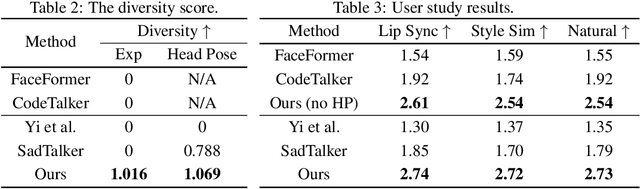
The generation of stylistic 3D facial animations driven by speech poses a significant challenge as it requires learning a many-to-many mapping between speech, style, and the corresponding natural facial motion. However, existing methods either employ a deterministic model for speech-to-motion mapping or encode the style using a one-hot encoding scheme. Notably, the one-hot encoding approach fails to capture the complexity of the style and thus limits generalization ability. In this paper, we propose DiffPoseTalk, a generative framework based on the diffusion model combined with a style encoder that extracts style embeddings from short reference videos. During inference, we employ classifier-free guidance to guide the generation process based on the speech and style. We extend this to include the generation of head poses, thereby enhancing user perception. Additionally, we address the shortage of scanned 3D talking face data by training our model on reconstructed 3DMM parameters from a high-quality, in-the-wild audio-visual dataset. Our extensive experiments and user study demonstrate that our approach outperforms state-of-the-art methods. The code and dataset will be made publicly available.
DPHMs: Diffusion Parametric Head Models for Depth-based Tracking
Dec 02, 2023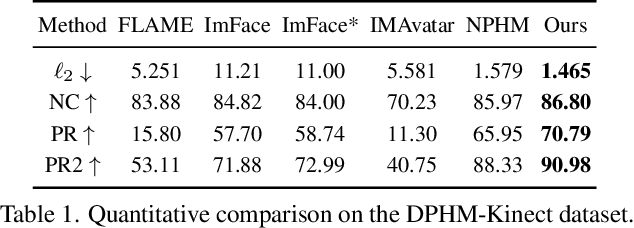
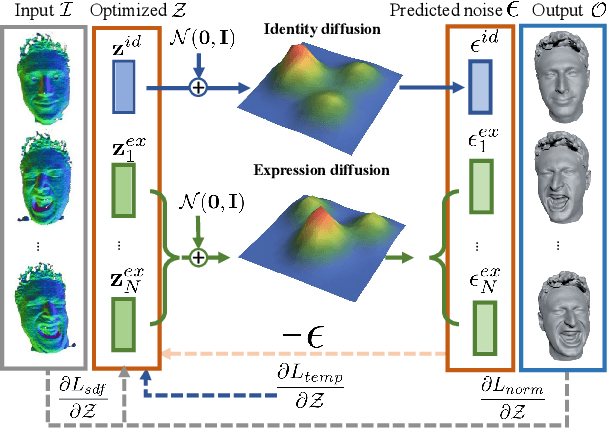
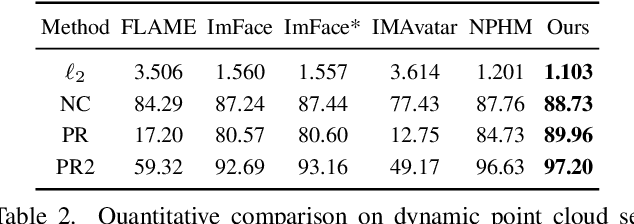

We introduce Diffusion Parametric Head Models (DPHMs), a generative model that enables robust volumetric head reconstruction and tracking from monocular depth sequences. While recent volumetric head models, such as NPHMs, can now excel in representing high-fidelity head geometries, tracking and reconstruction heads from real-world single-view depth sequences remains very challenging, as the fitting to partial and noisy observations is underconstrained. To tackle these challenges, we propose a latent diffusion-based prior to regularize volumetric head reconstruction and tracking. This prior-based regularizer effectively constrains the identity and expression codes to lie on the underlying latent manifold which represents plausible head shapes. To evaluate the effectiveness of the diffusion-based prior, we collect a dataset of monocular Kinect sequences consisting of various complex facial expression motions and rapid transitions. We compare our method to state-of-the-art tracking methods, and demonstrate improved head identity reconstruction as well as robust expression tracking.
A New Data-Driven Method to Identify Violent Facial Expression
Aug 16, 2023Human Facial Expressions plays an important role in identifying human actions or intention. Facial expressions can represent any specific action of any person and the pattern of violent behavior of any person strongly depends on the geographic region. Here we have designed an automated system by using a Convolutional Neural Network which can detect whether a person has any intention to commit any crime or not. Here we proposed a new method that can identify criminal intentions or violent behavior of any person before executing crimes more efficiently by using very little data on facial expressions before executing a crime or any violent tasks. Instead of using image features which is a time-consuming and faulty method we used an automated feature selector Convolutional Neural Network model which can capture exact facial expressions for training and then can predict that target facial expressions more accurately. Here we used only the facial data of a specific geographic region which can represent the violent and before-crime before-crime facial patterns of the people of the whole region.
Toward High Quality Facial Representation Learning
Sep 07, 2023
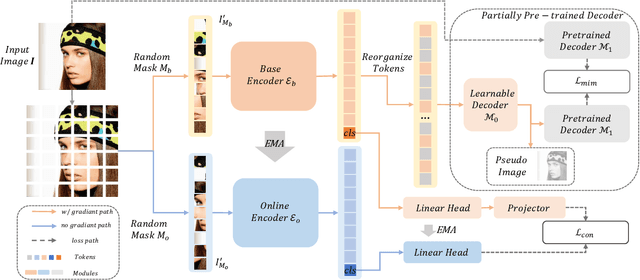

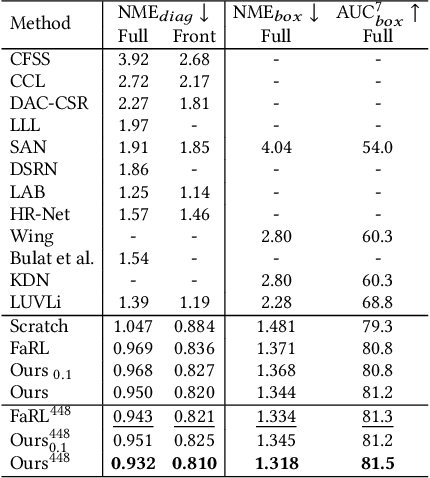
Face analysis tasks have a wide range of applications, but the universal facial representation has only been explored in a few works. In this paper, we explore high-performance pre-training methods to boost the face analysis tasks such as face alignment and face parsing. We propose a self-supervised pre-training framework, called \textbf{\it Mask Contrastive Face (MCF)}, with mask image modeling and a contrastive strategy specially adjusted for face domain tasks. To improve the facial representation quality, we use feature map of a pre-trained visual backbone as a supervision item and use a partially pre-trained decoder for mask image modeling. To handle the face identity during the pre-training stage, we further use random masks to build contrastive learning pairs. We conduct the pre-training on the LAION-FACE-cropped dataset, a variants of LAION-FACE 20M, which contains more than 20 million face images from Internet websites. For efficiency pre-training, we explore our framework pre-training performance on a small part of LAION-FACE-cropped and verify the superiority with different pre-training settings. Our model pre-trained with the full pre-training dataset outperforms the state-of-the-art methods on multiple downstream tasks. Our model achieves 0.932 NME$_{diag}$ for AFLW-19 face alignment and 93.96 F1 score for LaPa face parsing. Code is available at https://github.com/nomewang/MCF.
Learning Triangular Distribution in Visual World
Nov 30, 2023Convolution neural network is successful in pervasive vision tasks, including label distribution learning, which usually takes the form of learning an injection from the non-linear visual features to the well-defined labels. However, how the discrepancy between features is mapped to the label discrepancy is ambient, and its correctness is not guaranteed.To address these problems, we study the mathematical connection between feature and its label, presenting a general and simple framework for label distribution learning. We propose a so-called Triangular Distribution Transform (TDT) to build an injective function between feature and label, guaranteeing that any symmetric feature discrepancy linearly reflects the difference between labels. The proposed TDT can be used as a plug-in in mainstream backbone networks to address different label distribution learning tasks. Experiments on Facial Age Recognition, Illumination Chromaticity Estimation, and Aesthetics assessment show that TDT achieves on-par or better results than the prior arts.
Personalized Face Inpainting with Diffusion Models by Parallel Visual Attention
Dec 06, 2023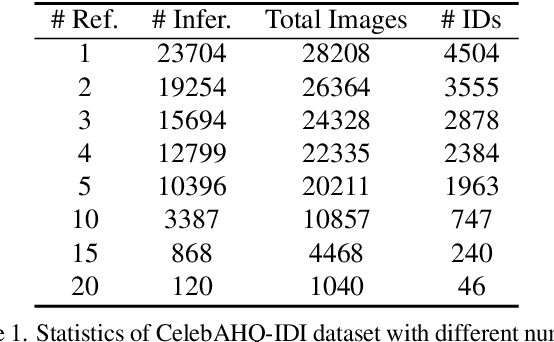
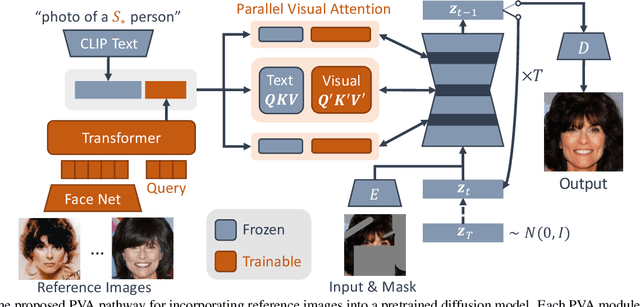


Face inpainting is important in various applications, such as photo restoration, image editing, and virtual reality. Despite the significant advances in face generative models, ensuring that a person's unique facial identity is maintained during the inpainting process is still an elusive goal. Current state-of-the-art techniques, exemplified by MyStyle, necessitate resource-intensive fine-tuning and a substantial number of images for each new identity. Furthermore, existing methods often fall short in accommodating user-specified semantic attributes, such as beard or expression. To improve inpainting results, and reduce the computational complexity during inference, this paper proposes the use of Parallel Visual Attention (PVA) in conjunction with diffusion models. Specifically, we insert parallel attention matrices to each cross-attention module in the denoising network, which attends to features extracted from reference images by an identity encoder. We train the added attention modules and identity encoder on CelebAHQ-IDI, a dataset proposed for identity-preserving face inpainting. Experiments demonstrate that PVA attains unparalleled identity resemblance in both face inpainting and face inpainting with language guidance tasks, in comparison to various benchmarks, including MyStyle, Paint by Example, and Custom Diffusion. Our findings reveal that PVA ensures good identity preservation while offering effective language-controllability. Additionally, in contrast to Custom Diffusion, PVA requires just 40 fine-tuning steps for each new identity, which translates to a significant speed increase of over 20 times.
VOODOO 3D: Volumetric Portrait Disentanglement for One-Shot 3D Head Reenactment
Dec 07, 2023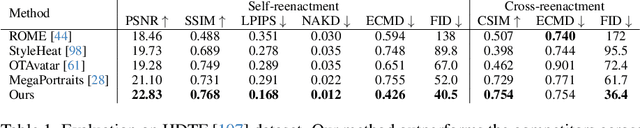
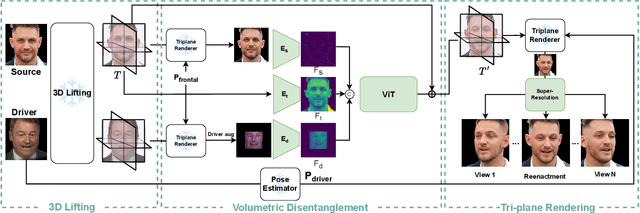
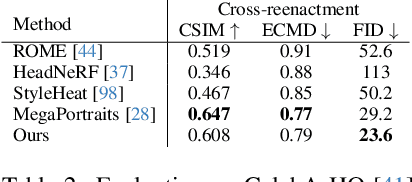

We present a 3D-aware one-shot head reenactment method based on a fully volumetric neural disentanglement framework for source appearance and driver expressions. Our method is real-time and produces high-fidelity and view-consistent output, suitable for 3D teleconferencing systems based on holographic displays. Existing cutting-edge 3D-aware reenactment methods often use neural radiance fields or 3D meshes to produce view-consistent appearance encoding, but, at the same time, they rely on linear face models, such as 3DMM, to achieve its disentanglement with facial expressions. As a result, their reenactment results often exhibit identity leakage from the driver or have unnatural expressions. To address these problems, we propose a neural self-supervised disentanglement approach that lifts both the source image and driver video frame into a shared 3D volumetric representation based on tri-planes. This representation can then be freely manipulated with expression tri-planes extracted from the driving images and rendered from an arbitrary view using neural radiance fields. We achieve this disentanglement via self-supervised learning on a large in-the-wild video dataset. We further introduce a highly effective fine-tuning approach to improve the generalizability of the 3D lifting using the same real-world data. We demonstrate state-of-the-art performance on a wide range of datasets, and also showcase high-quality 3D-aware head reenactment on highly challenging and diverse subjects, including non-frontal head poses and complex expressions for both source and driver.
NoiseCLR: A Contrastive Learning Approach for Unsupervised Discovery of Interpretable Directions in Diffusion Models
Dec 08, 2023Generative models have been very popular in the recent years for their image generation capabilities. GAN-based models are highly regarded for their disentangled latent space, which is a key feature contributing to their success in controlled image editing. On the other hand, diffusion models have emerged as powerful tools for generating high-quality images. However, the latent space of diffusion models is not as thoroughly explored or understood. Existing methods that aim to explore the latent space of diffusion models usually relies on text prompts to pinpoint specific semantics. However, this approach may be restrictive in areas such as art, fashion, or specialized fields like medicine, where suitable text prompts might not be available or easy to conceive thus limiting the scope of existing work. In this paper, we propose an unsupervised method to discover latent semantics in text-to-image diffusion models without relying on text prompts. Our method takes a small set of unlabeled images from specific domains, such as faces or cats, and a pre-trained diffusion model, and discovers diverse semantics in unsupervised fashion using a contrastive learning objective. Moreover, the learned directions can be applied simultaneously, either within the same domain (such as various types of facial edits) or across different domains (such as applying cat and face edits within the same image) without interfering with each other. Our extensive experiments show that our method achieves highly disentangled edits, outperforming existing approaches in both diffusion-based and GAN-based latent space editing methods.
DiffusionAvatars: Deferred Diffusion for High-fidelity 3D Head Avatars
Nov 30, 2023DiffusionAvatars synthesizes a high-fidelity 3D head avatar of a person, offering intuitive control over both pose and expression. We propose a diffusion-based neural renderer that leverages generic 2D priors to produce compelling images of faces. For coarse guidance of the expression and head pose, we render a neural parametric head model (NPHM) from the target viewpoint, which acts as a proxy geometry of the person. Additionally, to enhance the modeling of intricate facial expressions, we condition DiffusionAvatars directly on the expression codes obtained from NPHM via cross-attention. Finally, to synthesize consistent surface details across different viewpoints and expressions, we rig learnable spatial features to the head's surface via TriPlane lookup in NPHM's canonical space. We train DiffusionAvatars on RGB videos and corresponding tracked NPHM meshes of a person and test the obtained avatars in both self-reenactment and animation scenarios. Our experiments demonstrate that DiffusionAvatars generates temporally consistent and visually appealing videos for novel poses and expressions of a person, outperforming existing approaches.
Prompting Visual-Language Models for Dynamic Facial Expression Recognition
Aug 25, 2023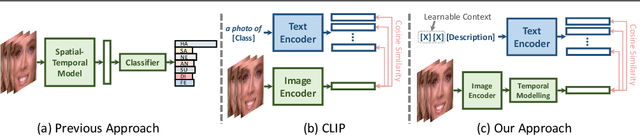
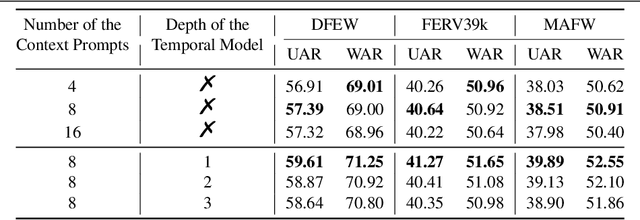
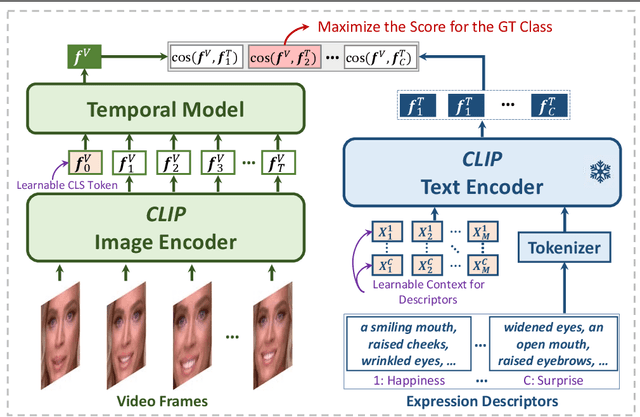
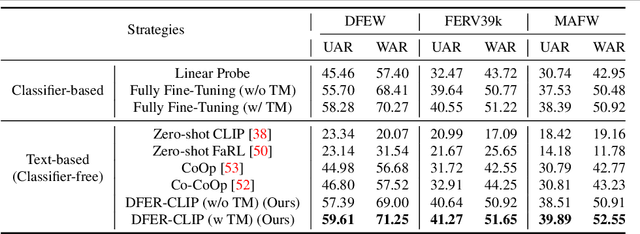
This paper presents a novel visual-language model called DFER-CLIP, which is based on the CLIP model and designed for in-the-wild Dynamic Facial Expression Recognition (DFER). Specifically, the proposed DFER-CLIP consists of a visual part and a textual part. For the visual part, based on the CLIP image encoder, a temporal model consisting of several Transformer encoders is introduced for extracting temporal facial expression features, and the final feature embedding is obtained as a learnable "class" token. For the textual part, we use as inputs textual descriptions of the facial behaviour that is related to the classes (facial expressions) that we are interested in recognising -- those descriptions are generated using large language models, like ChatGPT. This, in contrast to works that use only the class names and more accurately captures the relationship between them. Alongside the textual description, we introduce a learnable token which helps the model learn relevant context information for each expression during training. Extensive experiments demonstrate the effectiveness of the proposed method and show that our DFER-CLIP also achieves state-of-the-art results compared with the current supervised DFER methods on the DFEW, FERV39k, and MAFW benchmarks. Code is publicly available at https://github.com/zengqunzhao/DFER-CLIP.