 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Fully automated landmarking and facial segmentation on 3D photographs
Sep 19, 2023
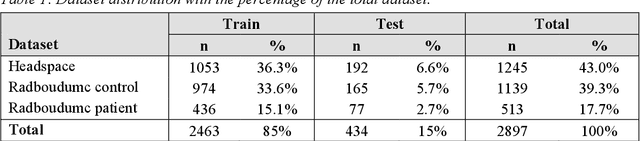
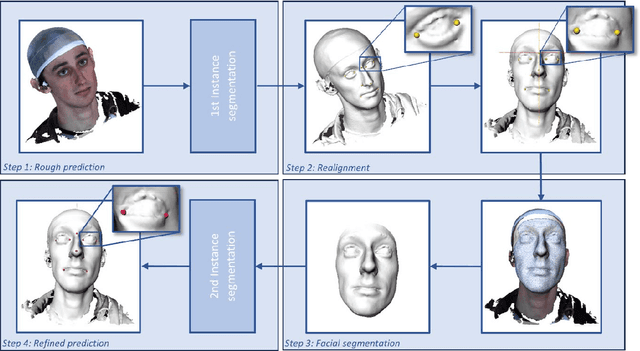
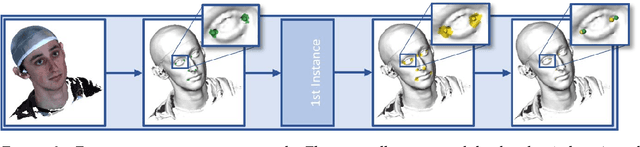

Three-dimensional facial stereophotogrammetry provides a detailed representation of craniofacial soft tissue without the use of ionizing radiation. While manual annotation of landmarks serves as the current gold standard for cephalometric analysis, it is a time-consuming process and is prone to human error. The aim in this study was to develop and evaluate an automated cephalometric annotation method using a deep learning-based approach. Ten landmarks were manually annotated on 2897 3D facial photographs by a single observer. The automated landmarking workflow involved two successive DiffusionNet models and additional algorithms for facial segmentation. The dataset was randomly divided into a training and test dataset. The training dataset was used to train the deep learning networks, whereas the test dataset was used to evaluate the performance of the automated workflow. The precision of the workflow was evaluated by calculating the Euclidean distances between the automated and manual landmarks and compared to the intra-observer and inter-observer variability of manual annotation and the semi-automated landmarking method. The workflow was successful in 98.6% of all test cases. The deep learning-based landmarking method achieved precise and consistent landmark annotation. The mean precision of 1.69 (+/-1.15) mm was comparable to the inter-observer variability (1.31 +/-0.91 mm) of manual annotation. The Euclidean distance between the automated and manual landmarks was within 2 mm in 69%. Automated landmark annotation on 3D photographs was achieved with the DiffusionNet-based approach. The proposed method allows quantitative analysis of large datasets and may be used in diagnosis, follow-up, and virtual surgical planning.
Video Face Re-Aging: Toward Temporally Consistent Face Re-Aging
Dec 07, 2023Video face re-aging deals with altering the apparent age of a person to the target age in videos. This problem is challenging due to the lack of paired video datasets maintaining temporal consistency in identity and age. Most re-aging methods process each image individually without considering the temporal consistency of videos. While some existing works address the issue of temporal coherence through video facial attribute manipulation in latent space, they often fail to deliver satisfactory performance in age transformation. To tackle the issues, we propose (1) a novel synthetic video dataset that features subjects across a diverse range of age groups; (2) a baseline architecture designed to validate the effectiveness of our proposed dataset, and (3) the development of three novel metrics tailored explicitly for evaluating the temporal consistency of video re-aging techniques. Our comprehensive experiments on public datasets, such as VFHQ and CelebV-HQ, show that our method outperforms the existing approaches in terms of both age transformation and temporal consistency.
EmoCLIP: A Vision-Language Method for Zero-Shot Video Facial Expression Recognition
Oct 25, 2023Facial Expression Recognition (FER) is a crucial task in affective computing, but its conventional focus on the seven basic emotions limits its applicability to the complex and expanding emotional spectrum. To address the issue of new and unseen emotions present in dynamic in-the-wild FER, we propose a novel vision-language model that utilises sample-level text descriptions (i.e. captions of the context, expressions or emotional cues) as natural language supervision, aiming to enhance the learning of rich latent representations, for zero-shot classification. To test this, we evaluate using zero-shot classification of the model trained on sample-level descriptions on four popular dynamic FER datasets. Our findings show that this approach yields significant improvements when compared to baseline methods. Specifically, for zero-shot video FER, we outperform CLIP by over 10\% in terms of Weighted Average Recall and 5\% in terms of Unweighted Average Recall on several datasets. Furthermore, we evaluate the representations obtained from the network trained using sample-level descriptions on the downstream task of mental health symptom estimation, achieving performance comparable or superior to state-of-the-art methods and strong agreement with human experts. Namely, we achieve a Pearson's Correlation Coefficient of up to 0.85 on schizophrenia symptom severity estimation, which is comparable to human experts' agreement. The code is publicly available at: https://github.com/NickyFot/EmoCLIP.
Multi-Branch Network for Imagery Emotion Prediction
Dec 12, 2023For a long time, images have proved perfect at both storing and conveying rich semantics, especially human emotions. A lot of research has been conducted to provide machines with the ability to recognize emotions in photos of people. Previous methods mostly focus on facial expressions but fail to consider the scene context, meanwhile scene context plays an important role in predicting emotions, leading to more accurate results. In addition, Valence-Arousal-Dominance (VAD) values offer a more precise quantitative understanding of continuous emotions, yet there has been less emphasis on predicting them compared to discrete emotional categories. In this paper, we present a novel Multi-Branch Network (MBN), which utilizes various source information, including faces, bodies, and scene contexts to predict both discrete and continuous emotions in an image. Experimental results on EMOTIC dataset, which contains large-scale images of people in unconstrained situations labeled with 26 discrete categories of emotions and VAD values, show that our proposed method significantly outperforms state-of-the-art methods with 28.4% in mAP and 0.93 in MAE. The results highlight the importance of utilizing multiple contextual information in emotion prediction and illustrate the potential of our proposed method in a wide range of applications, such as effective computing, human-computer interaction, and social robotics. Source code: https://github.com/BaoNinh2808/Multi-Branch-Network-for-Imagery-Emotion-Prediction
LibreFace: An Open-Source Toolkit for Deep Facial Expression Analysis
Aug 24, 2023
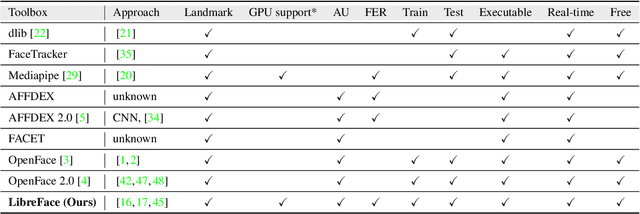
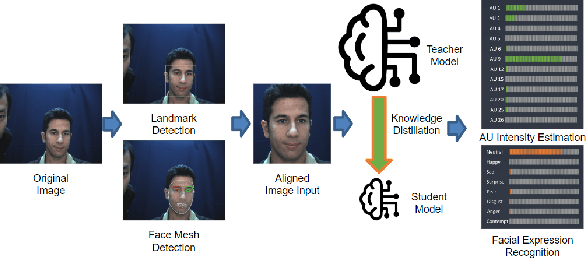

Facial expression analysis is an important tool for human-computer interaction. In this paper, we introduce LibreFace, an open-source toolkit for facial expression analysis. This open-source toolbox offers real-time and offline analysis of facial behavior through deep learning models, including facial action unit (AU) detection, AU intensity estimation, and facial expression recognition. To accomplish this, we employ several techniques, including the utilization of a large-scale pre-trained network, feature-wise knowledge distillation, and task-specific fine-tuning. These approaches are designed to effectively and accurately analyze facial expressions by leveraging visual information, thereby facilitating the implementation of real-time interactive applications. In terms of Action Unit (AU) intensity estimation, we achieve a Pearson Correlation Coefficient (PCC) of 0.63 on DISFA, which is 7% higher than the performance of OpenFace 2.0 while maintaining highly-efficient inference that runs two times faster than OpenFace 2.0. Despite being compact, our model also demonstrates competitive performance to state-of-the-art facial expression analysis methods on AffecNet, FFHQ, and RAF-DB. Our code will be released at https://github.com/ihp-lab/LibreFace
R2-Talker: Realistic Real-Time Talking Head Synthesis with Hash Grid Landmarks Encoding and Progressive Multilayer Conditioning
Dec 09, 2023Dynamic NeRFs have recently garnered growing attention for 3D talking portrait synthesis. Despite advances in rendering speed and visual quality, challenges persist in enhancing efficiency and effectiveness. We present R2-Talker, an efficient and effective framework enabling realistic real-time talking head synthesis. Specifically, using multi-resolution hash grids, we introduce a novel approach for encoding facial landmarks as conditional features. This approach losslessly encodes landmark structures as conditional features, decoupling input diversity, and conditional spaces by mapping arbitrary landmarks to a unified feature space. We further propose a scheme of progressive multilayer conditioning in the NeRF rendering pipeline for effective conditional feature fusion. Our new approach has the following advantages as demonstrated by extensive experiments compared with the state-of-the-art works: 1) The lossless input encoding enables acquiring more precise features, yielding superior visual quality. The decoupling of inputs and conditional spaces improves generalizability. 2) The fusing of conditional features and MLP outputs at each MLP layer enhances conditional impact, resulting in more accurate lip synthesis and better visual quality. 3) It compactly structures the fusion of conditional features, significantly enhancing computational efficiency.
Enhancing Kinship Verification through Multiscale Retinex and Combined Deep-Shallow features
Dec 06, 2023The challenge of kinship verification from facial images represents a cutting-edge and formidable frontier in the realms of pattern recognition and computer vision. This area of study holds a myriad of potential applications, spanning from image annotation and forensic analysis to social media research. Our research stands out by integrating a preprocessing method named Multiscale Retinex (MSR), which elevates image quality and amplifies contrast, ultimately bolstering the end results. Strategically, our methodology capitalizes on the harmonious blend of deep and shallow texture descriptors, merging them proficiently at the score level through the Logistic Regression (LR) method. To elucidate, we employ the Local Phase Quantization (LPQ) descriptor to extract shallow texture characteristics. For deep feature extraction, we turn to the prowess of the VGG16 model, which is pre-trained on a convolutional neural network (CNN). The robustness and efficacy of our method have been put to the test through meticulous experiments on three rigorous kinship datasets, namely: Cornell Kin Face, UB Kin Face, and TS Kin Face.
Neural Text to Articulate Talk: Deep Text to Audiovisual Speech Synthesis achieving both Auditory and Photo-realism
Dec 11, 2023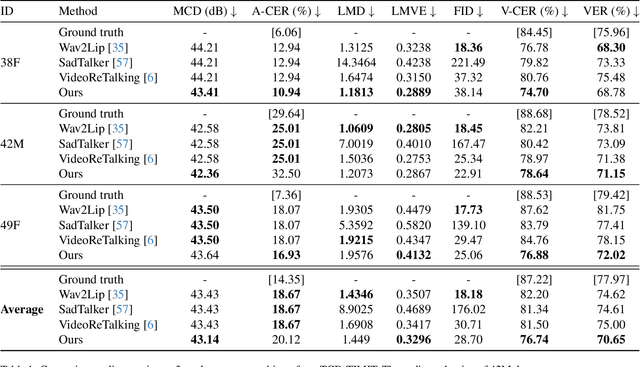
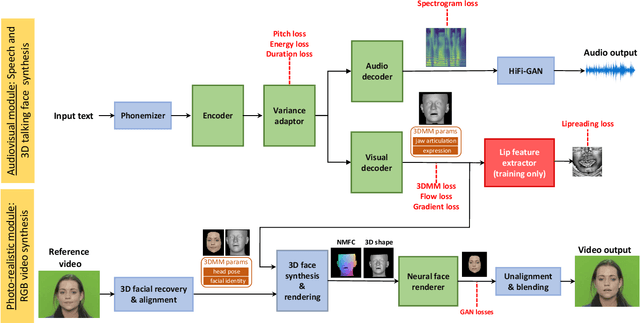
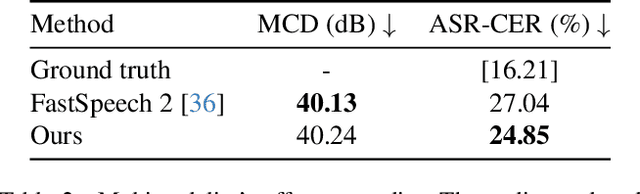

Recent advances in deep learning for sequential data have given rise to fast and powerful models that produce realistic videos of talking humans. The state of the art in talking face generation focuses mainly on lip-syncing, being conditioned on audio clips. However, having the ability to synthesize talking humans from text transcriptions rather than audio is particularly beneficial for many applications and is expected to receive more and more attention, following the recent breakthroughs in large language models. For that, most methods implement a cascaded 2-stage architecture of a text-to-speech module followed by an audio-driven talking face generator, but this ignores the highly complex interplay between audio and visual streams that occurs during speaking. In this paper, we propose the first, to the best of our knowledge, text-driven audiovisual speech synthesizer that uses Transformers and does not follow a cascaded approach. Our method, which we call NEUral Text to ARticulate Talk (NEUTART), is a talking face generator that uses a joint audiovisual feature space, as well as speech-informed 3D facial reconstructions and a lip-reading loss for visual supervision. The proposed model produces photorealistic talking face videos with human-like articulation and well-synced audiovisual streams. Our experiments on audiovisual datasets as well as in-the-wild videos reveal state-of-the-art generation quality both in terms of objective metrics and human evaluation.
Segue: Side-information Guided Generative Unlearnable Examples for Facial Privacy Protection in Real World
Oct 24, 2023The widespread use of face recognition technology has given rise to privacy concerns, as many individuals are worried about the collection and utilization of their facial data. To address these concerns, researchers are actively exploring the concept of ``unlearnable examples", by adding imperceptible perturbation to data in the model training stage, which aims to prevent the model from learning discriminate features of the target face. However, current methods are inefficient and cannot guarantee transferability and robustness at the same time, causing impracticality in the real world. To remedy it, we propose a novel method called Segue: Side-information guided generative unlearnable examples. Specifically, we leverage a once-trained multiple-used model to generate the desired perturbation rather than the time-consuming gradient-based method. To improve transferability, we introduce side information such as true labels and pseudo labels, which are inherently consistent across different scenarios. For robustness enhancement, a distortion layer is integrated into the training pipeline. Extensive experiments demonstrate that the proposed Segue is much faster than previous methods (1000$\times$) and achieves transferable effectiveness across different datasets and model architectures. Furthermore, it can resist JPEG compression, adversarial training, and some standard data augmentations.
Multi Loss-based Feature Fusion and Top Two Voting Ensemble Decision Strategy for Facial Expression Recognition in the Wild
Nov 06, 2023Facial expression recognition (FER) in the wild is a challenging task affected by the image quality and has attracted broad interest in computer vision. There is no research using feature fusion and ensemble strategy for FER simultaneously. Different from previous studies, this paper applies both internal feature fusion for a single model and feature fusion among multiple networks, as well as the ensemble strategy. This paper proposes one novel single model named R18+FAML, as well as one ensemble model named R18+FAML-FGA-T2V to improve the performance of the FER in the wild. Based on the structure of ResNet18 (R18), R18+FAML combines internal Feature fusion and three Attention blocks using Multiple Loss functions (FAML) to improve the diversity of the feature extraction. To improve the performance of R18+FAML, we propose a Feature fusion among networks based on the Genetic Algorithm (FGA), which can fuse the convolution kernels for feature extraction of multiple networks. On the basis of R18+FAML and FGA, we propose one ensemble strategy, i.e., the Top Two Voting (T2V) to support the classification of FER, which can consider more classification information comprehensively. Combining the above strategies, R18+FAML-FGA-T2V can focus on the main expression-aware areas. Extensive experiments demonstrate that our single model R18+FAML and the ensemble model R18+FAML-FGA-T2V achieve the accuracies of $\left( 90.32, 62.17, 65.83 \right)\%$ and $\left( 91.59, 63.27, 66.63 \right)\%$ on three challenging unbalanced FER datasets RAF-DB, AffectNet-8 and AffectNet-7 respectively, both outperforming the state-of-the-art results.