 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Engagement Measurement Based on Facial Landmarks and Spatial-Temporal Graph Convolutional Networks
Mar 25, 2024
Engagement in virtual learning is crucial for a variety of factors including learner satisfaction, performance, and compliance with learning programs, but measuring it is a challenging task. There is therefore considerable interest in utilizing artificial intelligence and affective computing to measure engagement in natural settings as well as on a large scale. This paper introduces a novel, privacy-preserving method for engagement measurement from videos. It uses facial landmarks, which carry no personally identifiable information, extracted from videos via the MediaPipe deep learning solution. The extracted facial landmarks are fed to a Spatial-Temporal Graph Convolutional Network (ST-GCN) to output the engagement level of the learner in the video. To integrate the ordinal nature of the engagement variable into the training process, ST-GCNs undergo training in a novel ordinal learning framework based on transfer learning. Experimental results on two video student engagement measurement datasets show the superiority of the proposed method compared to previous methods with improved state-of-the-art on the EngageNet dataset with a %3.1 improvement in four-class engagement level classification accuracy and on the Online Student Engagement dataset with a %1.5 improvement in binary engagement classification accuracy. The relatively lightweight ST-GCN and its integration with the real-time MediaPipe deep learning solution make the proposed approach capable of being deployed on virtual learning platforms and measuring engagement in real time.
Exploring Facial Expression Recognition through Semi-Supervised Pretraining and Temporal Modeling
Mar 19, 2024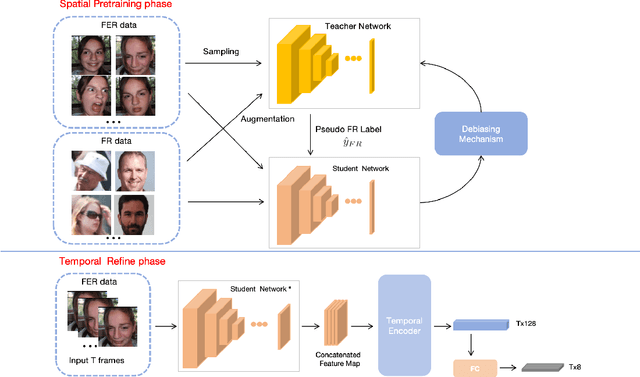

Facial Expression Recognition (FER) plays a crucial role in computer vision and finds extensive applications across various fields. This paper aims to present our approach for the upcoming 6th Affective Behavior Analysis in-the-Wild (ABAW) competition, scheduled to be held at CVPR2024. In the facial expression recognition task, The limited size of the FER dataset poses a challenge to the expression recognition model's generalization ability, resulting in subpar recognition performance. To address this problem, we employ a semi-supervised learning technique to generate expression category pseudo-labels for unlabeled face data. At the same time, we uniformly sampled the labeled facial expression samples and implemented a debiased feedback learning strategy to address the problem of category imbalance in the dataset and the possible data bias in semi-supervised learning. Moreover, to further compensate for the limitation and bias of features obtained only from static images, we introduced a Temporal Encoder to learn and capture temporal relationships between neighbouring expression image features. In the 6th ABAW competition, our method achieved outstanding results on the official validation set, a result that fully confirms the effectiveness and competitiveness of our proposed method.
Joint Physical-Digital Facial Attack Detection Via Simulating Spoofing Clues
Apr 12, 2024Face recognition systems are frequently subjected to a variety of physical and digital attacks of different types. Previous methods have achieved satisfactory performance in scenarios that address physical attacks and digital attacks, respectively. However, few methods are considered to integrate a model that simultaneously addresses both physical and digital attacks, implying the necessity to develop and maintain multiple models. To jointly detect physical and digital attacks within a single model, we propose an innovative approach that can adapt to any network architecture. Our approach mainly contains two types of data augmentation, which we call Simulated Physical Spoofing Clues augmentation (SPSC) and Simulated Digital Spoofing Clues augmentation (SDSC). SPSC and SDSC augment live samples into simulated attack samples by simulating spoofing clues of physical and digital attacks, respectively, which significantly improve the capability of the model to detect "unseen" attack types. Extensive experiments show that SPSC and SDSC can achieve state-of-the-art generalization in Protocols 2.1 and 2.2 of the UniAttackData dataset, respectively. Our method won first place in "Unified Physical-Digital Face Attack Detection" of the 5th Face Anti-spoofing Challenge@CVPR2024. Our final submission obtains 3.75% APCER, 0.93% BPCER, and 2.34% ACER, respectively. Our code is available at https://github.com/Xianhua-He/cvpr2024-face-anti-spoofing-challenge.
DrFER: Learning Disentangled Representations for 3D Facial Expression Recognition
Mar 13, 2024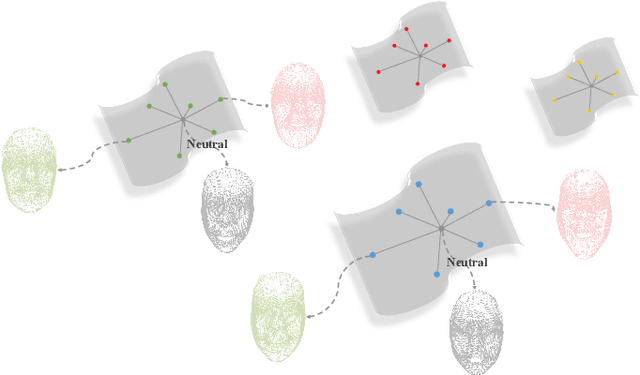
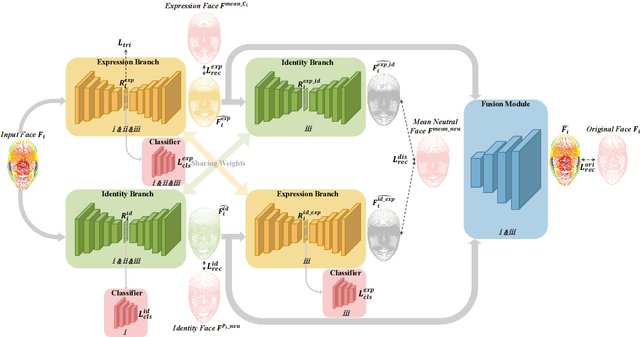
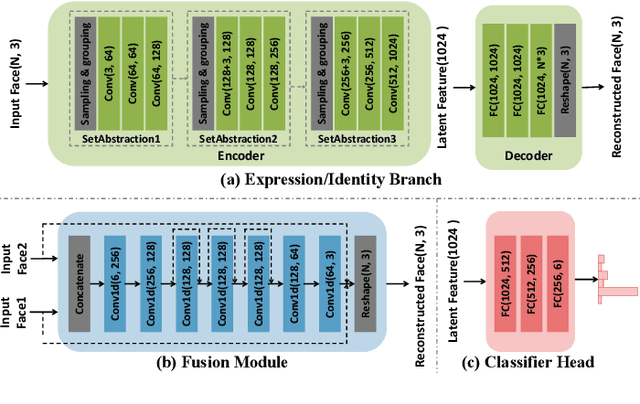
Facial Expression Recognition (FER) has consistently been a focal point in the field of facial analysis. In the context of existing methodologies for 3D FER or 2D+3D FER, the extraction of expression features often gets entangled with identity information, compromising the distinctiveness of these features. To tackle this challenge, we introduce the innovative DrFER method, which brings the concept of disentangled representation learning to the field of 3D FER. DrFER employs a dual-branch framework to effectively disentangle expression information from identity information. Diverging from prior disentanglement endeavors in the 3D facial domain, we have carefully reconfigured both the loss functions and network structure to make the overall framework adaptable to point cloud data. This adaptation enhances the capability of the framework in recognizing facial expressions, even in cases involving varying head poses. Extensive evaluations conducted on the BU-3DFE and Bosphorus datasets substantiate that DrFER surpasses the performance of other 3D FER methods.
FaceXFormer: A Unified Transformer for Facial Analysis
Mar 19, 2024
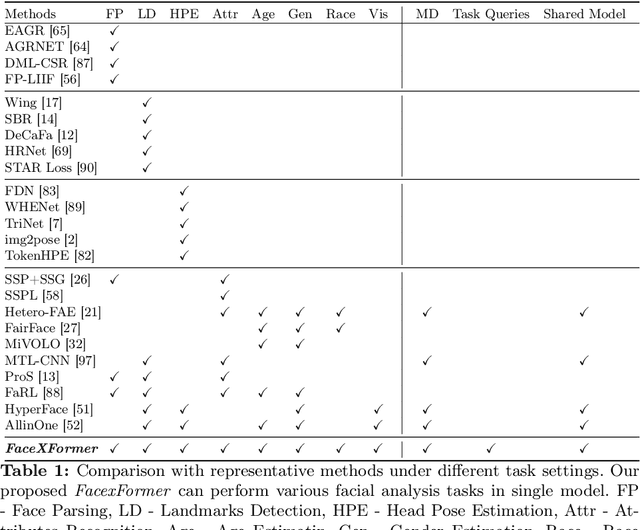
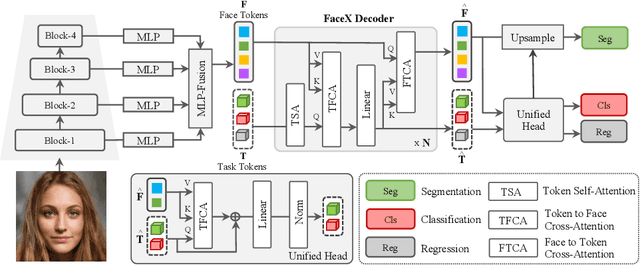
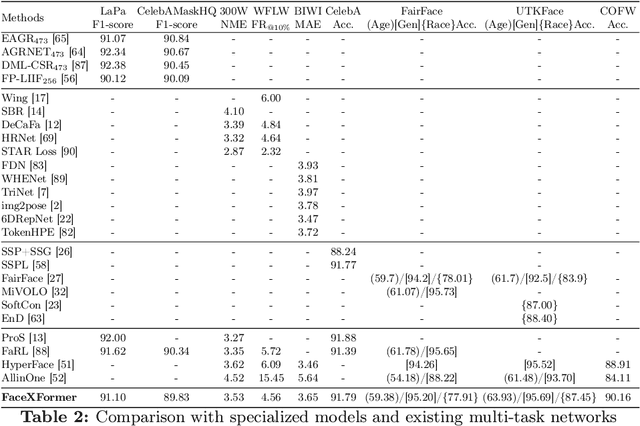
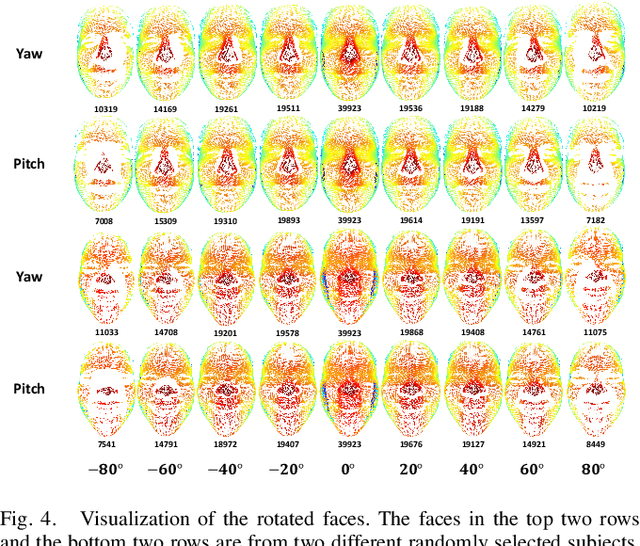
In this work, we introduce FaceXformer, an end-to-end unified transformer model for a comprehensive range of facial analysis tasks such as face parsing, landmark detection, head pose estimation, attributes recognition, and estimation of age, gender, race, and landmarks visibility. Conventional methods in face analysis have often relied on task-specific designs and preprocessing techniques, which limit their approach to a unified architecture. Unlike these conventional methods, our FaceXformer leverages a transformer-based encoder-decoder architecture where each task is treated as a learnable token, enabling the integration of multiple tasks within a single framework. Moreover, we propose a parameter-efficient decoder, FaceX, which jointly processes face and task tokens, thereby learning generalized and robust face representations across different tasks. To the best of our knowledge, this is the first work to propose a single model capable of handling all these facial analysis tasks using transformers. We conducted a comprehensive analysis of effective backbones for unified face task processing and evaluated different task queries and the synergy between them. We conduct experiments against state-of-the-art specialized models and previous multi-task models in both intra-dataset and cross-dataset evaluations across multiple benchmarks. Additionally, our model effectively handles images "in-the-wild," demonstrating its robustness and generalizability across eight different tasks, all while maintaining the real-time performance of 37 FPS.
AI-KD: Towards Alignment Invariant Face Image Quality Assessment Using Knowledge Distillation
Apr 15, 2024Face Image Quality Assessment (FIQA) techniques have seen steady improvements over recent years, but their performance still deteriorates if the input face samples are not properly aligned. This alignment sensitivity comes from the fact that most FIQA techniques are trained or designed using a specific face alignment procedure. If the alignment technique changes, the performance of most existing FIQA techniques quickly becomes suboptimal. To address this problem, we present in this paper a novel knowledge distillation approach, termed AI-KD that can extend on any existing FIQA technique, improving its robustness to alignment variations and, in turn, performance with different alignment procedures. To validate the proposed distillation approach, we conduct comprehensive experiments on 6 face datasets with 4 recent face recognition models and in comparison to 7 state-of-the-art FIQA techniques. Our results show that AI-KD consistently improves performance of the initial FIQA techniques not only with misaligned samples, but also with properly aligned facial images. Furthermore, it leads to a new state-of-the-art, when used with a competitive initial FIQA approach. The code for AI-KD is made publicly available from: https://github.com/LSIbabnikz/AI-KD.
Toward Tiny and High-quality Facial Makeup with Data Amplify Learning
Mar 22, 2024Contemporary makeup approaches primarily hinge on unpaired learning paradigms, yet they grapple with the challenges of inaccurate supervision (e.g., face misalignment) and sophisticated facial prompts (including face parsing, and landmark detection). These challenges prohibit low-cost deployment of facial makeup models, especially on mobile devices. To solve above problems, we propose a brand-new learning paradigm, termed "Data Amplify Learning (DAL)," alongside a compact makeup model named "TinyBeauty." The core idea of DAL lies in employing a Diffusion-based Data Amplifier (DDA) to "amplify" limited images for the model training, thereby enabling accurate pixel-to-pixel supervision with merely a handful of annotations. Two pivotal innovations in DDA facilitate the above training approach: (1) A Residual Diffusion Model (RDM) is designed to generate high-fidelity detail and circumvent the detail vanishing problem in the vanilla diffusion models; (2) A Fine-Grained Makeup Module (FGMM) is proposed to achieve precise makeup control and combination while retaining face identity. Coupled with DAL, TinyBeauty necessitates merely 80K parameters to achieve a state-of-the-art performance without intricate face prompts. Meanwhile, TinyBeauty achieves a remarkable inference speed of up to 460 fps on the iPhone 13. Extensive experiments show that DAL can produce highly competitive makeup models using only 5 image pairs.
LAFS: Landmark-based Facial Self-supervised Learning for Face Recognition
Mar 13, 2024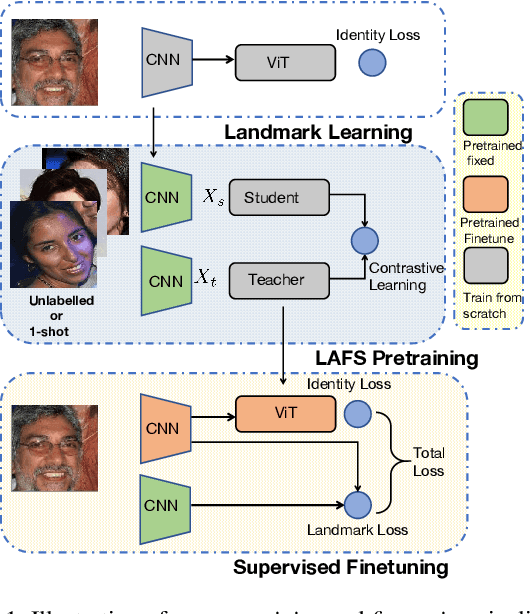
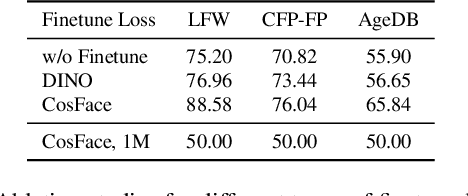
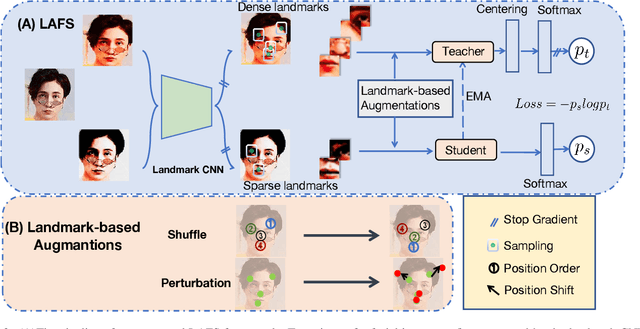
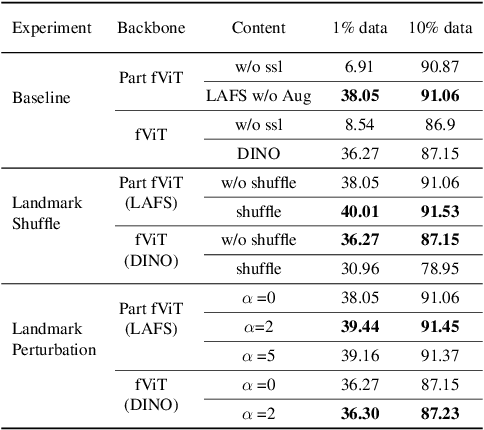
In this work we focus on learning facial representations that can be adapted to train effective face recognition models, particularly in the absence of labels. Firstly, compared with existing labelled face datasets, a vastly larger magnitude of unlabeled faces exists in the real world. We explore the learning strategy of these unlabeled facial images through self-supervised pretraining to transfer generalized face recognition performance. Moreover, motivated by one recent finding, that is, the face saliency area is critical for face recognition, in contrast to utilizing random cropped blocks of images for constructing augmentations in pretraining, we utilize patches localized by extracted facial landmarks. This enables our method - namely LAndmark-based Facial Self-supervised learning LAFS), to learn key representation that is more critical for face recognition. We also incorporate two landmark-specific augmentations which introduce more diversity of landmark information to further regularize the learning. With learned landmark-based facial representations, we further adapt the representation for face recognition with regularization mitigating variations in landmark positions. Our method achieves significant improvement over the state-of-the-art on multiple face recognition benchmarks, especially on more challenging few-shot scenarios.
rFaceNet: An End-to-End Network for Enhanced Physiological Signal Extraction through Identity-Specific Facial Contours
Mar 14, 2024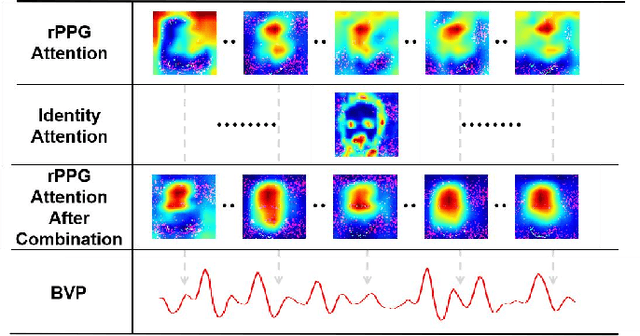
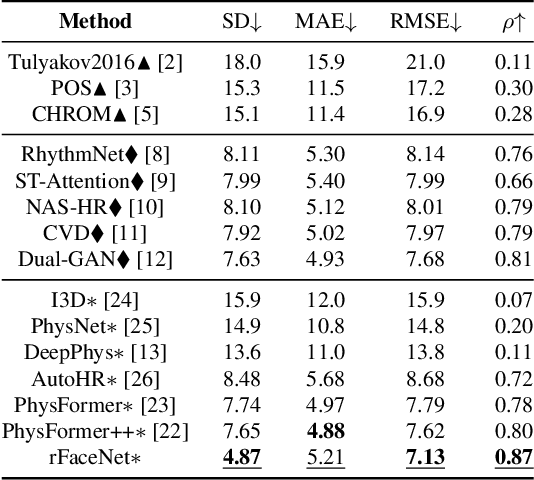
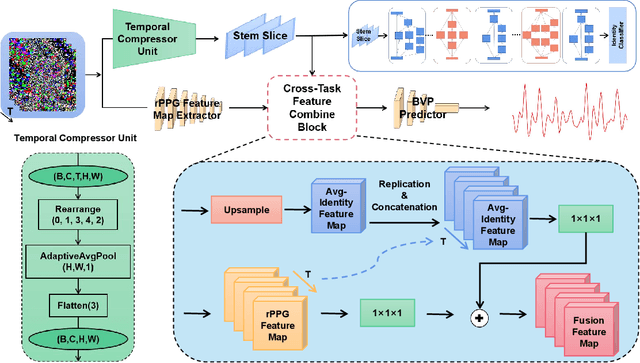
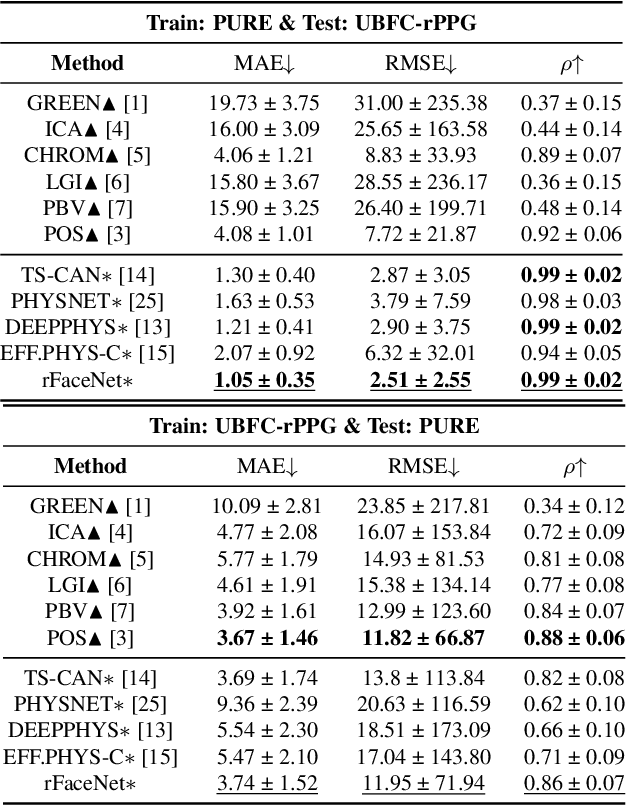
Remote photoplethysmography (rPPG) technique extracts blood volume pulse (BVP) signals from subtle pixel changes in video frames. This study introduces rFaceNet, an advanced rPPG method that enhances the extraction of facial BVP signals with a focus on facial contours. rFaceNet integrates identity-specific facial contour information and eliminates redundant data. It efficiently extracts facial contours from temporally normalized frame inputs through a Temporal Compressor Unit (TCU) and steers the model focus to relevant facial regions by using the Cross-Task Feature Combiner (CTFC). Through elaborate training, the quality and interpretability of facial physiological signals extracted by rFaceNet are greatly improved compared to previous methods. Moreover, our novel approach demonstrates superior performance than SOTA methods in various heart rate estimation benchmarks.
HSEmotion Team at the 6th ABAW Competition: Facial Expressions, Valence-Arousal and Emotion Intensity Prediction
Mar 18, 2024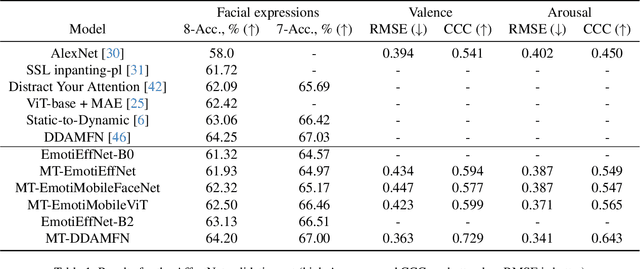
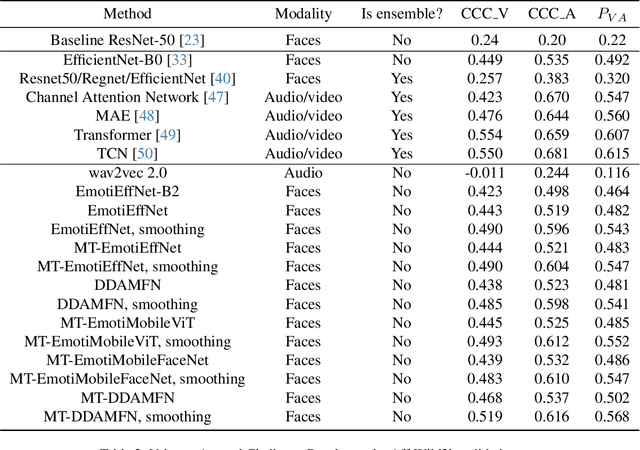
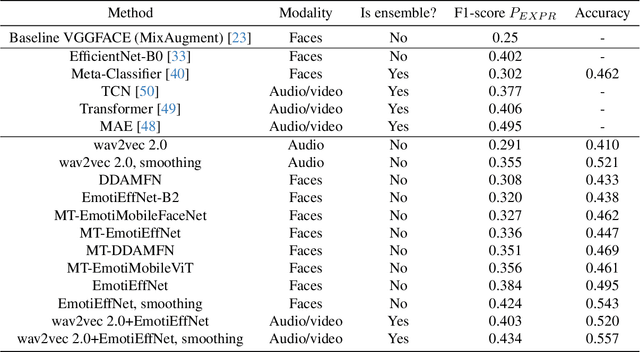
This article presents our results for the sixth Affective Behavior Analysis in-the-wild (ABAW) competition. To improve the trustworthiness of facial analysis, we study the possibility of using pre-trained deep models that extract reliable emotional features without the need to fine-tune the neural networks for a downstream task. In particular, we introduce several lightweight models based on MobileViT, MobileFaceNet, EfficientNet, and DDAMFN architectures trained in multi-task scenarios to recognize facial expressions, valence, and arousal on static photos. These neural networks extract frame-level features fed into a simple classifier, e.g., linear feed-forward neural network, to predict emotion intensity, compound expressions, action units, facial expressions, and valence/arousal. Experimental results for five tasks from the sixth ABAW challenge demonstrate that our approach lets us significantly improve quality metrics on validation sets compared to existing non-ensemble techniques.