 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
GAN-Avatar: Controllable Personalized GAN-based Human Head Avatar
Nov 22, 2023
Digital humans and, especially, 3D facial avatars have raised a lot of attention in the past years, as they are the backbone of several applications like immersive telepresence in AR or VR. Despite the progress, facial avatars reconstructed from commodity hardware are incomplete and miss out on parts of the side and back of the head, severely limiting the usability of the avatar. This limitation in prior work stems from their requirement of face tracking, which fails for profile and back views. To address this issue, we propose to learn person-specific animatable avatars from images without assuming to have access to precise facial expression tracking. At the core of our method, we leverage a 3D-aware generative model that is trained to reproduce the distribution of facial expressions from the training data. To train this appearance model, we only assume to have a collection of 2D images with the corresponding camera parameters. For controlling the model, we learn a mapping from 3DMM facial expression parameters to the latent space of the generative model. This mapping can be learned by sampling the latent space of the appearance model and reconstructing the facial parameters from a normalized frontal view, where facial expression estimation performs well. With this scheme, we decouple 3D appearance reconstruction and animation control to achieve high fidelity in image synthesis. In a series of experiments, we compare our proposed technique to state-of-the-art monocular methods and show superior quality while not requiring expression tracking of the training data.
ASM: Adaptive Sample Mining for In-The-Wild Facial Expression Recognition
Oct 09, 2023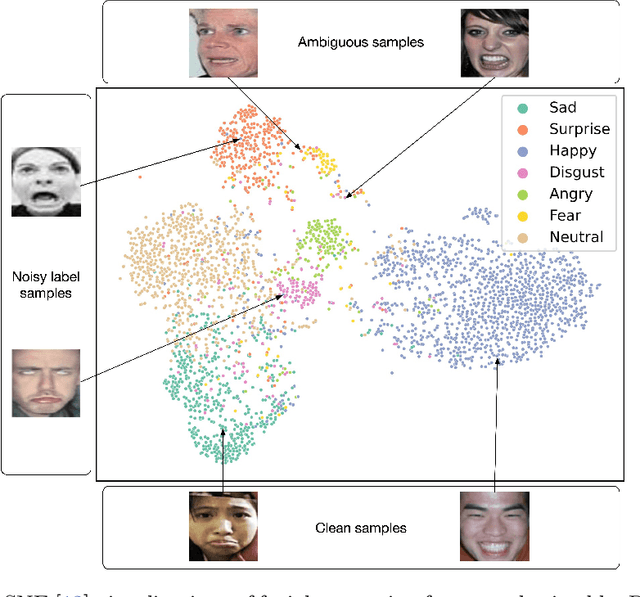
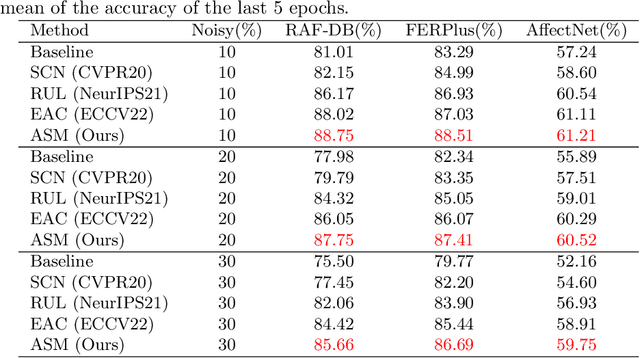
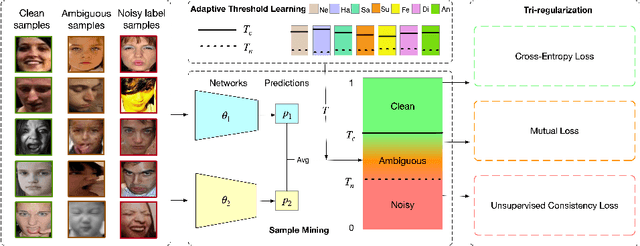

Given the similarity between facial expression categories, the presence of compound facial expressions, and the subjectivity of annotators, facial expression recognition (FER) datasets often suffer from ambiguity and noisy labels. Ambiguous expressions are challenging to differentiate from expressions with noisy labels, which hurt the robustness of FER models. Furthermore, the difficulty of recognition varies across different expression categories, rendering a uniform approach unfair for all expressions. In this paper, we introduce a novel approach called Adaptive Sample Mining (ASM) to dynamically address ambiguity and noise within each expression category. First, the Adaptive Threshold Learning module generates two thresholds, namely the clean and noisy thresholds, for each category. These thresholds are based on the mean class probabilities at each training epoch. Next, the Sample Mining module partitions the dataset into three subsets: clean, ambiguity, and noise, by comparing the sample confidence with the clean and noisy thresholds. Finally, the Tri-Regularization module employs a mutual learning strategy for the ambiguity subset to enhance discrimination ability, and an unsupervised learning strategy for the noise subset to mitigate the impact of noisy labels. Extensive experiments prove that our method can effectively mine both ambiguity and noise, and outperform SOTA methods on both synthetic noisy and original datasets. The supplement material is available at https://github.com/zzzzzzyang/ASM.
ExpCLIP: Bridging Text and Facial Expressions via Semantic Alignment
Sep 11, 2023
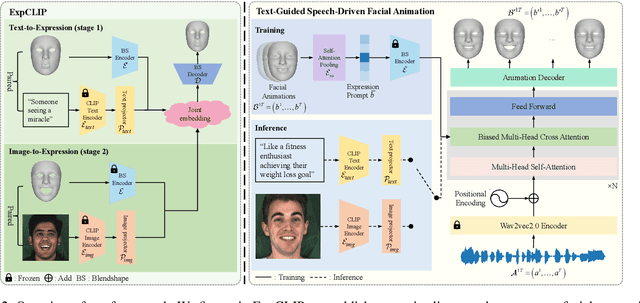
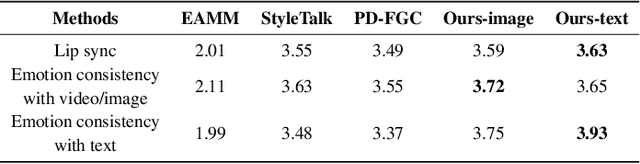
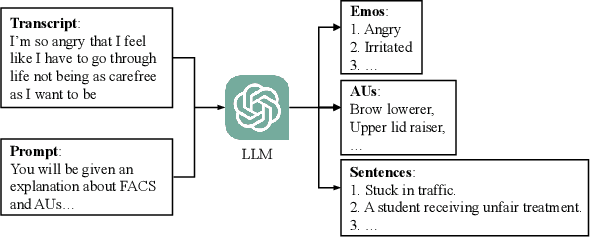
The objective of stylized speech-driven facial animation is to create animations that encapsulate specific emotional expressions. Existing methods often depend on pre-established emotional labels or facial expression templates, which may limit the necessary flexibility for accurately conveying user intent. In this research, we introduce a technique that enables the control of arbitrary styles by leveraging natural language as emotion prompts. This technique presents benefits in terms of both flexibility and user-friendliness. To realize this objective, we initially construct a Text-Expression Alignment Dataset (TEAD), wherein each facial expression is paired with several prompt-like descriptions.We propose an innovative automatic annotation method, supported by Large Language Models (LLMs), to expedite the dataset construction, thereby eliminating the substantial expense of manual annotation. Following this, we utilize TEAD to train a CLIP-based model, termed ExpCLIP, which encodes text and facial expressions into semantically aligned style embeddings. The embeddings are subsequently integrated into the facial animation generator to yield expressive and controllable facial animations. Given the limited diversity of facial emotions in existing speech-driven facial animation training data, we further introduce an effective Expression Prompt Augmentation (EPA) mechanism to enable the animation generator to support unprecedented richness in style control. Comprehensive experiments illustrate that our method accomplishes expressive facial animation generation and offers enhanced flexibility in effectively conveying the desired style.
Controllable 3D Face Generation with Conditional Style Code Diffusion
Dec 21, 2023Generating photorealistic 3D faces from given conditions is a challenging task. Existing methods often rely on time-consuming one-by-one optimization approaches, which are not efficient for modeling the same distribution content, e.g., faces. Additionally, an ideal controllable 3D face generation model should consider both facial attributes and expressions. Thus we propose a novel approach called TEx-Face(TExt & Expression-to-Face) that addresses these challenges by dividing the task into three components, i.e., 3D GAN Inversion, Conditional Style Code Diffusion, and 3D Face Decoding. For 3D GAN inversion, we introduce two methods which aim to enhance the representation of style codes and alleviate 3D inconsistencies. Furthermore, we design a style code denoiser to incorporate multiple conditions into the style code and propose a data augmentation strategy to address the issue of insufficient paired visual-language data. Extensive experiments conducted on FFHQ, CelebA-HQ, and CelebA-Dialog demonstrate the promising performance of our TEx-Face in achieving the efficient and controllable generation of photorealistic 3D faces. The code will be available at https://github.com/sxl142/TEx-Face.
When StyleGAN Meets Stable Diffusion: a $\mathscr{W}_+$ Adapter for Personalized Image Generation
Nov 29, 2023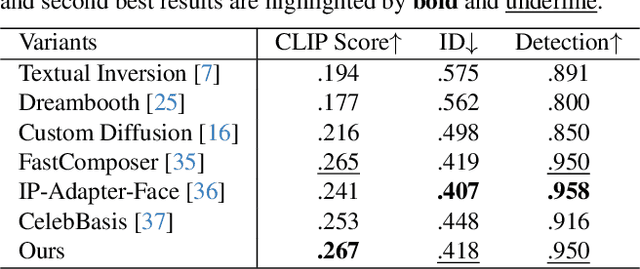
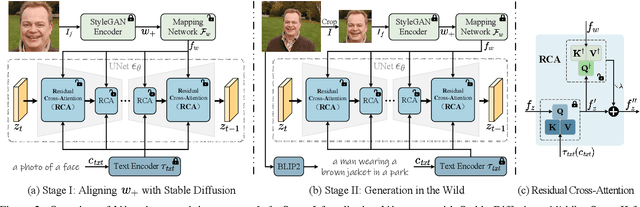
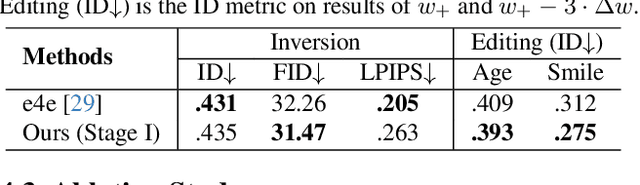

Text-to-image diffusion models have remarkably excelled in producing diverse, high-quality, and photo-realistic images. This advancement has spurred a growing interest in incorporating specific identities into generated content. Most current methods employ an inversion approach to embed a target visual concept into the text embedding space using a single reference image. However, the newly synthesized faces either closely resemble the reference image in terms of facial attributes, such as expression, or exhibit a reduced capacity for identity preservation. Text descriptions intended to guide the facial attributes of the synthesized face may fall short, owing to the intricate entanglement of identity information with identity-irrelevant facial attributes derived from the reference image. To address these issues, we present the novel use of the extended StyleGAN embedding space $\mathcal{W}_+$, to achieve enhanced identity preservation and disentanglement for diffusion models. By aligning this semantically meaningful human face latent space with text-to-image diffusion models, we succeed in maintaining high fidelity in identity preservation, coupled with the capacity for semantic editing. Additionally, we propose new training objectives to balance the influences of both prompt and identity conditions, ensuring that the identity-irrelevant background remains unaffected during facial attribute modifications. Extensive experiments reveal that our method adeptly generates personalized text-to-image outputs that are not only compatible with prompt descriptions but also amenable to common StyleGAN editing directions in diverse settings. Our source code will be available at \url{https://github.com/csxmli2016/w-plus-adapter}.
GSmoothFace: Generalized Smooth Talking Face Generation via Fine Grained 3D Face Guidance
Dec 12, 2023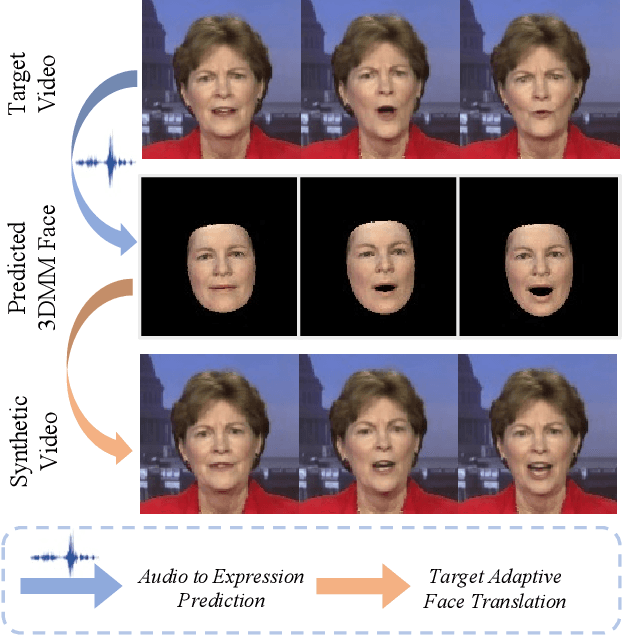
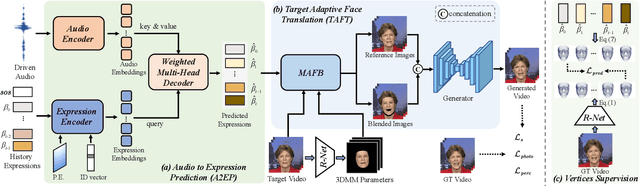
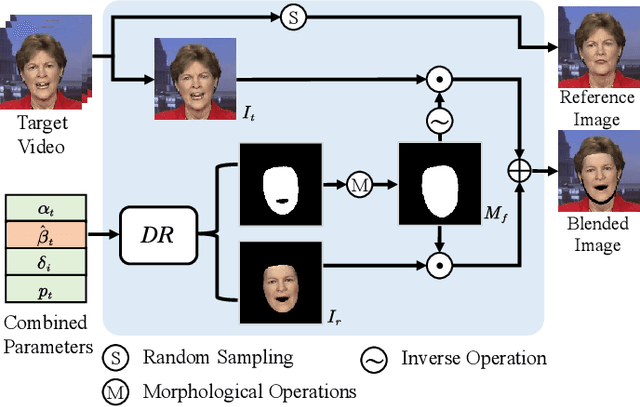
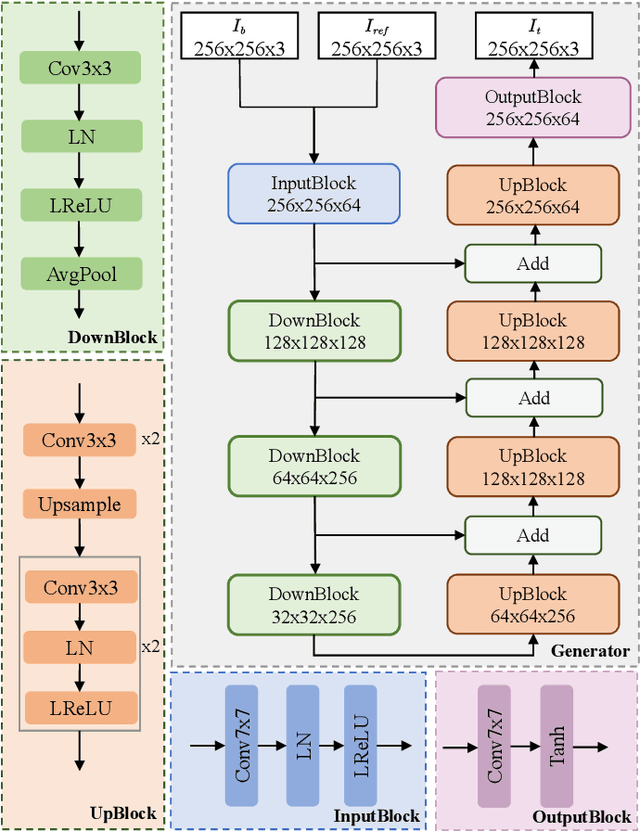
Although existing speech-driven talking face generation methods achieve significant progress, they are far from real-world application due to the avatar-specific training demand and unstable lip movements. To address the above issues, we propose the GSmoothFace, a novel two-stage generalized talking face generation model guided by a fine-grained 3d face model, which can synthesize smooth lip dynamics while preserving the speaker's identity. Our proposed GSmoothFace model mainly consists of the Audio to Expression Prediction (A2EP) module and the Target Adaptive Face Translation (TAFT) module. Specifically, we first develop the A2EP module to predict expression parameters synchronized with the driven speech. It uses a transformer to capture the long-term audio context and learns the parameters from the fine-grained 3D facial vertices, resulting in accurate and smooth lip-synchronization performance. Afterward, the well-designed TAFT module, empowered by Morphology Augmented Face Blending (MAFB), takes the predicted expression parameters and target video as inputs to modify the facial region of the target video without distorting the background content. The TAFT effectively exploits the identity appearance and background context in the target video, which makes it possible to generalize to different speakers without retraining. Both quantitative and qualitative experiments confirm the superiority of our method in terms of realism, lip synchronization, and visual quality. See the project page for code, data, and request pre-trained models: https://zhanghm1995.github.io/GSmoothFace.
Can we truly transfer an actor's genuine happiness to avatars? An investigation into virtual, real, posed and spontaneous faces
Dec 04, 2023A look is worth a thousand words is a popular phrase. And why is a simple look enough to portray our feelings about something or someone? Behind this question are the theoretical foundations of the field of psychology regarding social cognition and the studies of psychologist Paul Ekman. Facial expressions, as a form of non-verbal communication, are the primary way to transmit emotions between human beings. The set of movements and expressions of facial muscles that convey some emotional state of the individual to their observers are targets of studies in many areas. Our research aims to evaluate Ekman's action units in datasets of real human faces, posed and spontaneous, and virtual human faces resulting from transferring real faces into Computer Graphics faces. In addition, we also conducted a case study with specific movie characters, such as SheHulk and Genius. We intend to find differences and similarities in facial expressions between real and CG datasets, posed and spontaneous faces, and also to consider the actors' genders in the videos. This investigation can help several areas of knowledge, whether using real or virtual human beings, in education, health, entertainment, games, security, and even legal matters. Our results indicate that AU intensities are greater for posed than spontaneous datasets, regardless of gender. Furthermore, there is a smoothing of intensity up to 80 percent for AU6 and 45 percent for AU12 when a real face is transformed into CG.
Inclusive normalization of face images to passport format
Dec 22, 2023Face recognition has been used more and more in real world applications in recent years. However, when the skin color bias is coupled with intra-personal variations like harsh illumination, the face recognition task is more likely to fail, even during human inspection. Face normalization methods try to deal with such challenges by removing intra-personal variations from an input image while keeping the identity the same. However, most face normalization methods can only remove one or two variations and ignore dataset biases such as skin color bias. The outputs of many face normalization methods are also not realistic to human observers. In this work, a style based face normalization model (StyleFNM) is proposed to remove most intra-personal variations including large changes in pose, bad or harsh illumination, low resolution, blur, facial expressions, and accessories like sunglasses among others. The dataset bias is also dealt with in this paper by controlling a pretrained GAN to generate a balanced dataset of passport-like images. The experimental results show that StyleFNM can generate more realistic outputs and can improve significantly the accuracy and fairness of face recognition systems.
StyleRetoucher: Generalized Portrait Image Retouching with GAN Priors
Dec 22, 2023Creating fine-retouched portrait images is tedious and time-consuming even for professional artists. There exist automatic retouching methods, but they either suffer from over-smoothing artifacts or lack generalization ability. To address such issues, we present StyleRetoucher, a novel automatic portrait image retouching framework, leveraging StyleGAN's generation and generalization ability to improve an input portrait image's skin condition while preserving its facial details. Harnessing the priors of pretrained StyleGAN, our method shows superior robustness: a). performing stably with fewer training samples and b). generalizing well on the out-domain data. Moreover, by blending the spatial features of the input image and intermediate features of the StyleGAN layers, our method preserves the input characteristics to the largest extent. We further propose a novel blemish-aware feature selection mechanism to effectively identify and remove the skin blemishes, improving the image skin condition. Qualitative and quantitative evaluations validate the great generalization capability of our method. Further experiments show StyleRetoucher's superior performance to the alternative solutions in the image retouching task. We also conduct a user perceptive study to confirm the superior retouching performance of our method over the existing state-of-the-art alternatives.
MM-TTS: Multi-modal Prompt based Style Transfer for Expressive Text-to-Speech Synthesis
Dec 28, 2023The style transfer task in Text-to-Speech refers to the process of transferring style information into text content to generate corresponding speech with a specific style. However, most existing style transfer approaches are either based on fixed emotional labels or reference speech clips, which cannot achieve flexible style transfer. Recently, some methods have adopted text descriptions to guide style transfer. In this paper, we propose a more flexible multi-modal and style controllable TTS framework named MM-TTS. It can utilize any modality as the prompt in unified multi-modal prompt space, including reference speech, emotional facial images, and text descriptions, to control the style of the generated speech in a system. The challenges of modeling such a multi-modal style controllable TTS mainly lie in two aspects:1)aligning the multi-modal information into a unified style space to enable the input of arbitrary modality as the style prompt in a single system, and 2)efficiently transferring the unified style representation into the given text content, thereby empowering the ability to generate prompt style-related voice. To address these problems, we propose an aligned multi-modal prompt encoder that embeds different modalities into a unified style space, supporting style transfer for different modalities. Additionally, we present a new adaptive style transfer method named Style Adaptive Convolutions to achieve a better style representation. Furthermore, we design a Rectified Flow based Refiner to solve the problem of over-smoothing Mel-spectrogram and generate audio of higher fidelity. Since there is no public dataset for multi-modal TTS, we construct a dataset named MEAD-TTS, which is related to the field of expressive talking head. Our experiments on the MEAD-TTS dataset and out-of-domain datasets demonstrate that MM-TTS can achieve satisfactory results based on multi-modal prompts.