 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
SyncTalk: The Devil is in the Synchronization for Talking Head Synthesis
Nov 29, 2023
Achieving high synchronization in the synthesis of realistic, speech-driven talking head videos presents a significant challenge. Traditional Generative Adversarial Networks (GAN) struggle to maintain consistent facial identity, while Neural Radiance Fields (NeRF) methods, although they can address this issue, often produce mismatched lip movements, inadequate facial expressions, and unstable head poses. A lifelike talking head requires synchronized coordination of subject identity, lip movements, facial expressions, and head poses. The absence of these synchronizations is a fundamental flaw, leading to unrealistic and artificial outcomes. To address the critical issue of synchronization, identified as the "devil" in creating realistic talking heads, we introduce SyncTalk. This NeRF-based method effectively maintains subject identity, enhancing synchronization and realism in talking head synthesis. SyncTalk employs a Face-Sync Controller to align lip movements with speech and innovatively uses a 3D facial blendshape model to capture accurate facial expressions. Our Head-Sync Stabilizer optimizes head poses, achieving more natural head movements. The Portrait-Sync Generator restores hair details and blends the generated head with the torso for a seamless visual experience. Extensive experiments and user studies demonstrate that SyncTalk outperforms state-of-the-art methods in synchronization and realism. We recommend watching the supplementary video: https://ziqiaopeng.github.io/synctalk
DiffusionTalker: Personalization and Acceleration for Speech-Driven 3D Face Diffuser
Nov 28, 2023Speech-driven 3D facial animation has been an attractive task in both academia and industry. Traditional methods mostly focus on learning a deterministic mapping from speech to animation. Recent approaches start to consider the non-deterministic fact of speech-driven 3D face animation and employ the diffusion model for the task. However, personalizing facial animation and accelerating animation generation are still two major limitations of existing diffusion-based methods. To address the above limitations, we propose DiffusionTalker, a diffusion-based method that utilizes contrastive learning to personalize 3D facial animation and knowledge distillation to accelerate 3D animation generation. Specifically, to enable personalization, we introduce a learnable talking identity to aggregate knowledge in audio sequences. The proposed identity embeddings extract customized facial cues across different people in a contrastive learning manner. During inference, users can obtain personalized facial animation based on input audio, reflecting a specific talking style. With a trained diffusion model with hundreds of steps, we distill it into a lightweight model with 8 steps for acceleration. Extensive experiments are conducted to demonstrate that our method outperforms state-of-the-art methods. The code will be released.
Towards Real-World Blind Face Restoration with Generative Diffusion Prior
Dec 25, 2023Blind face restoration is an important task in computer vision and has gained significant attention due to its wide-range applications. In this work, we delve into the potential of leveraging the pretrained Stable Diffusion for blind face restoration. We propose BFRffusion which is thoughtfully designed to effectively extract features from low-quality face images and could restore realistic and faithful facial details with the generative prior of the pretrained Stable Diffusion. In addition, we build a privacy-preserving face dataset called PFHQ with balanced attributes like race, gender, and age. This dataset can serve as a viable alternative for training blind face restoration methods, effectively addressing privacy and bias concerns usually associated with the real face datasets. Through an extensive series of experiments, we demonstrate that our BFRffusion achieves state-of-the-art performance on both synthetic and real-world public testing datasets for blind face restoration and our PFHQ dataset is an available resource for training blind face restoration networks. The codes, pretrained models, and dataset are released at https://github.com/chenxx89/BFRffusion.
Is It Possible to Backdoor Face Forgery Detection with Natural Triggers?
Dec 31, 2023Deep neural networks have significantly improved the performance of face forgery detection models in discriminating Artificial Intelligent Generated Content (AIGC). However, their security is significantly threatened by the injection of triggers during model training (i.e., backdoor attacks). Although existing backdoor defenses and manual data selection can mitigate those using human-eye-sensitive triggers, such as patches or adversarial noises, the more challenging natural backdoor triggers remain insufficiently researched. To further investigate natural triggers, we propose a novel analysis-by-synthesis backdoor attack against face forgery detection models, which embeds natural triggers in the latent space. We thoroughly study such backdoor vulnerability from two perspectives: (1) Model Discrimination (Optimization-Based Trigger): we adopt a substitute detection model and find the trigger by minimizing the cross-entropy loss; (2) Data Distribution (Custom Trigger): we manipulate the uncommon facial attributes in the long-tailed distribution to generate poisoned samples without the supervision from detection models. Furthermore, to completely evaluate the detection models towards the latest AIGC, we utilize both state-of-the-art StyleGAN and Stable Diffusion for trigger generation. Finally, these backdoor triggers introduce specific semantic features to the generated poisoned samples (e.g., skin textures and smile), which are more natural and robust. Extensive experiments show that our method is superior from three levels: (1) Attack Success Rate: ours achieves a high attack success rate (over 99%) and incurs a small model accuracy drop (below 0.2%) with a low poisoning rate (less than 3%); (2) Backdoor Defense: ours shows better robust performance when faced with existing backdoor defense methods; (3) Human Inspection: ours is less human-eye-sensitive from a comprehensive user study.
Enhancing Student Engagement in Online Learning through Facial Expression Analysis and Complex Emotion Recognition using Deep Learning
Nov 17, 2023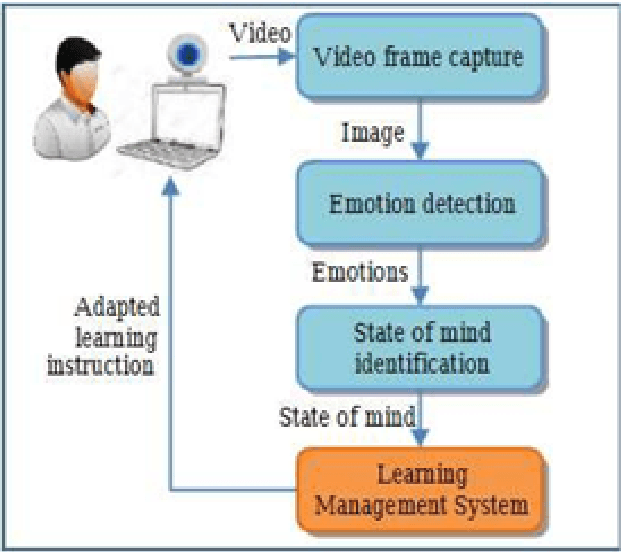

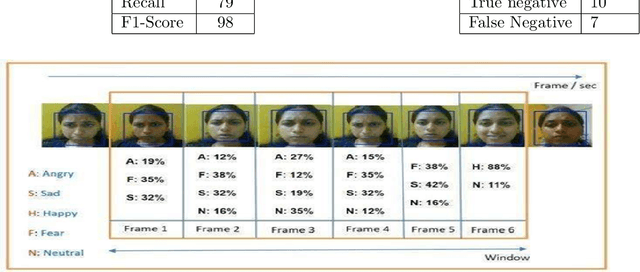
In response to the COVID-19 pandemic, traditional physical classrooms have transitioned to online environments, necessitating effective strategies to ensure sustained student engagement. A significant challenge in online teaching is the absence of real-time feedback from teachers on students learning progress. This paper introduces a novel approach employing deep learning techniques based on facial expressions to assess students engagement levels during online learning sessions. Human emotions cannot be adequately conveyed by a student using only the basic emotions, including anger, disgust, fear, joy, sadness, surprise, and neutrality. To address this challenge, proposed a generation of four complex emotions such as confusion, satisfaction, disappointment, and frustration by combining the basic emotions. These complex emotions are often experienced simultaneously by students during the learning session. To depict these emotions dynamically,utilized a continuous stream of image frames instead of discrete images. The proposed work utilized a Convolutional Neural Network (CNN) model to categorize the fundamental emotional states of learners accurately. The proposed CNN model demonstrates strong performance, achieving a 95% accuracy in precise categorization of learner emotions.
Towards Flexible, Scalable, and Adaptive Multi-Modal Conditioned Face Synthesis
Dec 26, 2023Recent progress in multi-modal conditioned face synthesis has enabled the creation of visually striking and accurately aligned facial images. Yet, current methods still face issues with scalability, limited flexibility, and a one-size-fits-all approach to control strength, not accounting for the differing levels of conditional entropy, a measure of unpredictability in data given some condition, across modalities. To address these challenges, we introduce a novel uni-modal training approach with modal surrogates, coupled with an entropy-aware modal-adaptive modulation, to support flexible, scalable, and scalable multi-modal conditioned face synthesis network. Our uni-modal training with modal surrogate that only leverage uni-modal data, use modal surrogate to decorate condition with modal-specific characteristic and serve as linker for inter-modal collaboration , fully learns each modality control in face synthesis process as well as inter-modal collaboration. The entropy-aware modal-adaptive modulation finely adjust diffusion noise according to modal-specific characteristics and given conditions, enabling well-informed step along denoising trajectory and ultimately leading to synthesis results of high fidelity and quality. Our framework improves multi-modal face synthesis under various conditions, surpassing current methods in image quality and fidelity, as demonstrated by our thorough experimental results.
Gaussian3Diff: 3D Gaussian Diffusion for 3D Full Head Synthesis and Editing
Dec 19, 2023
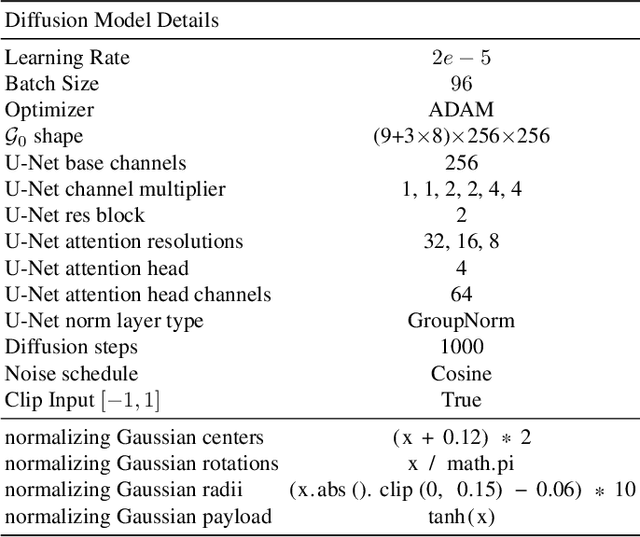
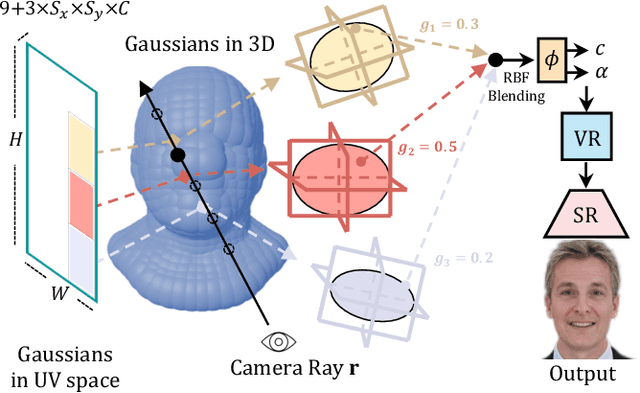

We present a novel framework for generating photorealistic 3D human head and subsequently manipulating and reposing them with remarkable flexibility. The proposed approach leverages an implicit function representation of 3D human heads, employing 3D Gaussians anchored on a parametric face model. To enhance representational capabilities and encode spatial information, we embed a lightweight tri-plane payload within each Gaussian rather than directly storing color and opacity. Additionally, we parameterize the Gaussians in a 2D UV space via a 3DMM, enabling effective utilization of the diffusion model for 3D head avatar generation. Our method facilitates the creation of diverse and realistic 3D human heads with fine-grained editing over facial features and expressions. Extensive experiments demonstrate the effectiveness of our method.
AdvCloak: Customized Adversarial Cloak for Privacy Protection
Dec 22, 2023With extensive face images being shared on social media, there has been a notable escalation in privacy concerns. In this paper, we propose AdvCloak, an innovative framework for privacy protection using generative models. AdvCloak is designed to automatically customize class-wise adversarial masks that can maintain superior image-level naturalness while providing enhanced feature-level generalization ability. Specifically, AdvCloak sequentially optimizes the generative adversarial networks by employing a two-stage training strategy. This strategy initially focuses on adapting the masks to the unique individual faces via image-specific training and then enhances their feature-level generalization ability to diverse facial variations of individuals via person-specific training. To fully utilize the limited training data, we combine AdvCloak with several general geometric modeling methods, to better describe the feature subspace of source identities. Extensive quantitative and qualitative evaluations on both common and celebrity datasets demonstrate that AdvCloak outperforms existing state-of-the-art methods in terms of efficiency and effectiveness.
GPT-4V with Emotion: A Zero-shot Benchmark for Multimodal Emotion Understanding
Dec 07, 2023Recently, GPT-4 with Vision (GPT-4V) has shown remarkable performance across various multimodal tasks. However, its efficacy in emotion recognition remains a question. This paper quantitatively evaluates GPT-4V's capabilities in multimodal emotion understanding, encompassing tasks such as facial emotion recognition, visual sentiment analysis, micro-expression recognition, dynamic facial emotion recognition, and multimodal emotion recognition. Our experiments show that GPT-4V exhibits impressive multimodal and temporal understanding capabilities, even surpassing supervised systems in some tasks. Despite these achievements, GPT-4V is currently tailored for general domains. It performs poorly in micro-expression recognition that requires specialized expertise. The main purpose of this paper is to present quantitative results of GPT-4V on emotion understanding and establish a zero-shot benchmark for future research. Code and evaluation results are available at: https://github.com/zeroQiaoba/gpt4v-emotion.
Leave No Stone Unturned: Mine Extra Knowledge for Imbalanced Facial Expression Recognition
Oct 30, 2023Facial expression data is characterized by a significant imbalance, with most collected data showing happy or neutral expressions and fewer instances of fear or disgust. This imbalance poses challenges to facial expression recognition (FER) models, hindering their ability to fully understand various human emotional states. Existing FER methods typically report overall accuracy on highly imbalanced test sets but exhibit low performance in terms of the mean accuracy across all expression classes. In this paper, our aim is to address the imbalanced FER problem. Existing methods primarily focus on learning knowledge of minor classes solely from minor-class samples. However, we propose a novel approach to extract extra knowledge related to the minor classes from both major and minor class samples. Our motivation stems from the belief that FER resembles a distribution learning task, wherein a sample may contain information about multiple classes. For instance, a sample from the major class surprise might also contain useful features of the minor class fear. Inspired by that, we propose a novel method that leverages re-balanced attention maps to regularize the model, enabling it to extract transformation invariant information about the minor classes from all training samples. Additionally, we introduce re-balanced smooth labels to regulate the cross-entropy loss, guiding the model to pay more attention to the minor classes by utilizing the extra information regarding the label distribution of the imbalanced training data. Extensive experiments on different datasets and backbones show that the two proposed modules work together to regularize the model and achieve state-of-the-art performance under the imbalanced FER task. Code is available at https://github.com/zyh-uaiaaaa.